
Abstract
The anomaly localization in distributed networks can be treated as a multiple hypothesis testing (MHT) problem and the Bayesian test with 0 - 1 loss function is a standard solution to this problem. However, For the anomaly localization application, the cost of different false localization varies, which cannot be reflected by the 0 - 1 loss function while the quadratic loss function is more appropriate. The main contribution of the paper is the design of a Bayesian test with a quadratic loss function and its performance analysis. The non-asymptotic bounds of the misclassification probabilities of the proposed test and the standard one with 0 - 1 loss function are established and the relationship between their asymptotic equivalence with respect to signal-to-noise ratio and the geometry of the parameter space is analyzed. The effectiveness of the non-asymptotic bounds and the analysis on the asymptotic equivalence are verified by the simulation results.
Introduction
Anomalies are patterns in data that do not conform to a well defined notion of a normal behavior [6]. Therefore, the anomaly localization refers to the problem of identifying the sources that contribute most to the observed anomalies [16]. This kind of problem is prevalent within diverse domains, such as intrusion localization [14], structural damage localization [1], steganalysis [11], safety-critical system monitoring [13], infrastructure security in the wireless sensor network (WSN) [21], etc. The problem of anomaly localization is of great importance because the anomalies in data often translate to significant, and even critical, actionable information.
The problem of anomaly localization can be viewed as a multiple hypothesis testing (MHT) problem and solved by a statistical test [18]. In comparison with the traditional machine learning methods [7], the statistical methods can operate in unsupervised setting without any need for labeled training data. In addition, if the assumptions regarding the underlying data distribution hold true, they can provide a statistically justifiable solution for anomaly localization.
There are two kinds of statistical approaches for solving the MHT problem: the nonparametric and the parametric ones. Nonparametric approaches keep the probability of one or more false rejections less than a given level since controlling the probability of false rejection for each hypothesis turns to be misleading when the number of hypotheses is very large. The performance to be controlled by the nonparametric method can be familywise error rate (FWER) or false discovery rate (FDR). There are several pertinent procedures, such as Holm-Bonferroni procedure [15] and Benjamini-Hochberg procedure [4]. Generally, nonparametric approaches do not exploit a precise statistical model of the observations and they are well described in [8, 20].
Parametric approaches treat the MHT problem with statistical decision theory from the Bayesian point of view and the optimal tests have been studied respectively according to minimax and Bayesian criterion. In the minimax test where the a priori probabilities are unknown, the maximum error probability of the test is minimized and two representatives are proposed in [3, 12]. In the construction of Bayesian tests, the prior probabilities of hypotheses are predefined so that the Bayes risk is minimized.
This paper deals with a MHT problem in the Bayesian framework for which the following two main assumptions are satisfied. First, the prior probability of each hypothesis is assumed to be known. Second, the loss function is used to affect a certain cost to each possible localization error. In the decision theory, the conventional loss function is the 0 - 1 which affects the same cost 1 for each erroneous decision and the same cost 0 for each correct decision. This function can be easily manipulated and numerous decision rules are based on it [10]. However, for the anomaly localization application, the larger the distance between detected anomaly location and the true anomaly location, the larger loss caused. Therefore, the loss resulted by the false localization should change with the distance and the quadratic loss function is an appropriate choice.
The paper is organized as follows. Section 2 states the MHT problem based on a Gaussian distribution in the Bayesian framework, illustrates this problem with a typical anomaly localization application and then formulates the main contributions. Section 3 introduces the Bayesian test and derives the Bayes risk of the test with an arbitrary loss function for the MHT problem. The Bayesian test with 0 - 1 loss function is then briefly given. Section 4 is devoted to the Bayesian test with the quadratic loss function. The lower and upper bounds of the misclassification probability of the two aforementioned Bayesian tests are given explicitly and their asymptotic performance as the Signal-to-Noise Ratio (SNR) tends to infinity is also established, from which the asymptotic equivalence of the two Bayesian tests is studied. Section 5 presents numerical simulations based on the intrusion localization in a WSN to verify the theoretical results in Section 4. Finally, Section 6 concludes thepaper.
Motivation and contribution
Statement of multiple hypothesis testing problem
Assume n mutually independent random observations X1, . . . , X
n
are arranged in a random vector . There are n hypotheses H1,…, H
n
such that
The bias Δ > 0 represents the anomaly and ξ i ∼ N (0, σ2) denotes the ambient noise modeled as a Gaussian random variable. The values Δ and σ2 are known. Therefore, Equation (1) indicates that only one element of the observation vector X is affected by the anomaly under each hypothesis. It also indicates that, when the anomaly affects an element of the observation vector, its impact is the same whatever the true hypothesis. The objective is to find a test such that H j is accepted when δ (X) = j, which is able to determine the location of Δ while minimizing the following quadratic loss function.
A loss occurs when the accepted hypothesis Hδ(X) and the true one H
i
differ, i.e. δ (X) ≠ k. This paper considers that each hypothesis H
i
is associated to a unique vector parameter which characterizes the hypothesis. Let Θ = {θ1, θ2, . . . , θ
n
} be the parameter space. The loss related to an erroneous decision is defined as the Euclidean distance from the vector θδ(X) related with the decision to the vector θ
i
related with the true hypothesis, i.e., the loss is given by

Localization of an intruder in a WSN. The i-th sensor has the geographic location θ i .
Figure 1 shows a WSN of n = 5 seismo-acoustic sensors distributed arbitrarily along the boundary of a protected region for the surveillance purpose and a similar application has been discussed in [21]. The goal is to localize an intruder passing across the boundary. Each sensor transmits its measured seismo-acoustic signal to a monitoring center. The measurement transmitted by the i-th sensor during the sampling interval t is denoted by and the vector containing the measurements of all sensors is . When the intruder appears near the i-th sensor, it is assumed that where Δ > 0 represents the abnormal seismo-acoustic signal strength (the sound or vibration emitted by the moving intruder) and the environmental noise ξ i ∼ N (0, σ2) is modeled as a Gaussian random variable. This is hypothesis H i . The values Δ and σ2 are assumed to be known. In addition, all the ξ i ’s are assumed to be mutually independent since the sensors are far away from each other. Let be the known geographic position of thei-th sensor (this is the vector parameter of H i ). By processing X t , the monitoring center decides which sensor is located close to the intruder trajectory via the seismo-acoustic signals, i.e., it provides the user with the geographic location θδ(X) ∈ Θ of the sensor which has captured the intruder. A loss will be incurred when the decided target location θδ(X) and the true intruder location θ i differ.
Historically, the first solution to the MHT problem with 0 - 1 loss function has been given in [10]. The 0 - 1 loss function is given by
The Bayes risk of a test for the MHT problem is expressed as a function of the misclassification probabilities and the prior distribution. The Bayesian test with a quadratic loss function is designed and the asymptotic performance of the proposed test and the Bayesian test with 0 - 1 loss function is studied. When the SNR tends to infinity, the asymptotic equivalence between the proposed test and the Bayesian test with 0 - 1 loss function is studied.
Bayes risk and Bayesian test
In this paper, it is assumed that the prior probability p i > 0 of hypothesis H i is known, . A detailed introduction to the Bayesian framework can be found in [5, 18].
In the Bayesian framework, the quality of a test δ (X) is evaluated with the Bayes risk R (θ, δ (X)):
General results on the Bayesian test
Under hypothesis H
i
given by (1), X1,…,X
n
are independent, X1,…,Xi-1,Xi+1,…,X
n
are identically distributed with a common Gaussian density φ0 (x) while X
i
has another Gaussian density φ1 (x) = φ0 (x - Δ). Hence, the joint probability density function f (x|θ
i
) of the vector X = (X1, X2, . . . , X
n
) is
Let f (x) be the marginal density of X:
Then, the posterior probability π (θ
i
|x) of θ
i
given the sample observation x is
Then, it can be easily shown (see details in [5]) that the optimal Bayesian test is given by
In addition to the Bayes risk, the quality of a test δ (X) for the MHT problem can be also characterized by the misclassification probabilities defined by
When the 0 - 1 loss function depicted by Equation (3) is chosen, it has been proved that f (x|θ) and L0-1 (θ, θδ(X)) are invariant under a group of permutation, so the MHT problem with 0-1 loss function is invariant under . Thus an invariance method has been used to solve the MHT problem. Specifically, [10] has proposed a Bayesian test with respect to a prior distribution invariant under giving equal weight to θ1, . . . , θ
n
. However, in the case of a general prior distribution, the following theorem, derived from that established by [10], gives the Bayesian test with the 0 - 1 loss function based on a Gaussian distribution whose density is depicted by
According to Equation (5), the Bayes risk of is
Bayesian test for quadratic loss function
According to Equation (5), the Bayes risk of is
The misclassification probability αi,j reflects the quality of the Bayesian test δ (X). However, for the tests δ0-1 (X) and δ
Q
(X), and are difficult to calculate explicitly. For instance,
Non-asymptotic bounds
For the sake of simplicity, the distance between θ i and θ j is denoted by di,j =∥ θ i - θ j ∥, and respectively denote the minimum and maximum distance between all the vector labels. The ratio of Δ to σ is a meaningful parameter similar to the SNR, which is denoted by . Then, the lower bound and upper bound of and those of are respectively given in Theorems 3 and 4, whose proofs can be respectively found in Appendixes A and B.
It can be seen from Equations (8)–(11) that , , and are functions of SNR, so their asymptotic performance with respect to SNR is studied. On one hand, the following corollary shows that and are asymptotically equivalent.
On the other hand, the asymptotic performance of the bounds and is given by Corollary 2.
It can be seen that is independent of the parameter geometry while is not in the asymptotic sense. Specifically, if the following condition
Nevertheless, if the set is not empty, then
To verify these theoretical analyses, in the following section, a monte-carlo simulation is carried out in the context of the intruder localization in a WSN.
Numerical results
Three simulation experiments in the context of intruder localization in WSN are carried out to verify the performance analyses made in Section 4. In the first experiment, the main objective is to validate the non-asymptotic lower and upper bounds of and as well as their asymptotic performance with respect to SNR. In the second experiment, the role played by the quadratic loss function in discriminating all the misclassification probabilities is discussed in details based on the same WSN. In the third experiment, the lower and upper bounds of and are respectively compared to corroborate the influence of parameter geometry based on three network topologies.
Non-asymptotic lower and upper bounds
This experiment concerns the WSN with Θ = {(0.5, 5.8) , (5, 1) , (8.5, 3.5) , (8.5, 6) , (6, 8)} as is described in Fig. 1. Because these bounds also depend on the prior distribution, in order to eliminate its interference and to highlight the influence of the quadratic loss function, a uniform prior distribution is adopted, i.e. the prior probabilities p i ’s satisfy p i = 1/5 for all i = 1, …, 5. Because SNR is an important factor affecting the performance of the Bayesian test, it is taken as a variable whose functions are the misclassification probabilities as well as their lower and upper bounds. Note that all results in this experiment are obtained by using a 106-repetition Monte Carlo simulation.

Lower and upper bounds of .

Lower and upper bounds of .
Without loss of generality, Fig. 2 presents α1,2 as well as its lower and upper bounds. To better distinguish these curves, the vertical axis is logarithmic. It can be seen that , and converge to the same value when SNR increases, as is predicted in Corollary 1. Then, and its lower and upper bounds are observed in Fig. 3. In this geometry, , so and do not converge to the same value according to Corollary 2 and its relevant discussion. Therefore, unlike , the exact asymptotic value of bounded by and is difficult to predict in this case. All these are completely corroborated by the phenomena shown in Fig. 3.
Comparison between and when SNR = 1
Comparison between and when SNR = 1
In order to give a better illustration, a complete comparison on the empirical values with confidence intervals of all αi,j’s is shown in Table 1. SNR = 1so that these misclassification probabilities can be clearly distinguished. For each pair of (i, j), is listed above and below. The pairwise distances among these sensors are listed in Table 2 since the distance is an important factor in . Note that the results in Table 1 are based on a 107-repetition Monte Carlo simulation.
Distance among the sensors
1Without loss of generality, the unit of the distances is assumed to be kilometre.
In Table 1, it can be seen that all the probabilities of correct decision for i = 1, . . . , 5 are identical and all the misclassification probabilities ’s for i, j = 1, . . . , 5 and j ≠ i are identical. On the contrary, all the and are discriminated by the distance. On one hand, in the case of , the larger di,j, the smaller . From Tables 1 and 2, it can be inferred that guarantees a smaller probability for the misclassification which potentially results in a larger loss. On the other hand, in the case of , although it appears that the distance cannot directly pose an impact, the discrimination in the can be explained by another virtual distance, i.e. the distance from the sensor to the geometric center .
The distances between θ i and θ c for i = 1, . . . , 5 are listed along the principal diagonal of Table 2. If all the sensors are sorted in an ascending order in a list according to the their distance away from θ c , then an interesting phenomenon is that the sensor in the middle of the list, whose location is denoted by θ m , corresponds to the largest probability of correct decision while the probability of correct decision associated with other sensors are sorted according to two elements. The first element is the difference between θ i and θ c for i = 1, . . . , 5 and i ≠ m. The second element is the distance between θ m and θ c . For instance, the 5-th sensor is ranked in the 3-rd place among 5 sensors according to its distance away from θ c , so α5,5 is the largest. Then, the probability of correct decision αi,i, i = 1, . . . , 4 are sorted inversely according to the difference between ∥θ i - θ c ∥ and ∥θ5 - θ c ∥. Therefore, α3,3 is the second largest while α1,1 is the smallest. This particular phenomenon could be explained by the symmetry of the quadratic loss function with a negative second derivative as it can be seen that the extreme value always appears in the center of the domain and the farther it away from the center, the smaller the corresponding function value.
In the third experiment, the influence of parameter geometry on the lower and upper bounds for the proposed test is illustrated by the simulation results based on three network topologies. Each network is composed by three sensors. Specifically, d1,2 = d2,3 < d1,3 in Topology 1, d1,2 = d2,3 = d1,3 in Topology 2 and d1,2 = d2,3 > d1,3 in Topology 3. Without loss of generality, the lower and upper bounds of and are observed and a uniform prior distribution is also adopted for the same reason. Note that all results in this experiment are obtained by using a 106-repetition Monte Carlo simulation.
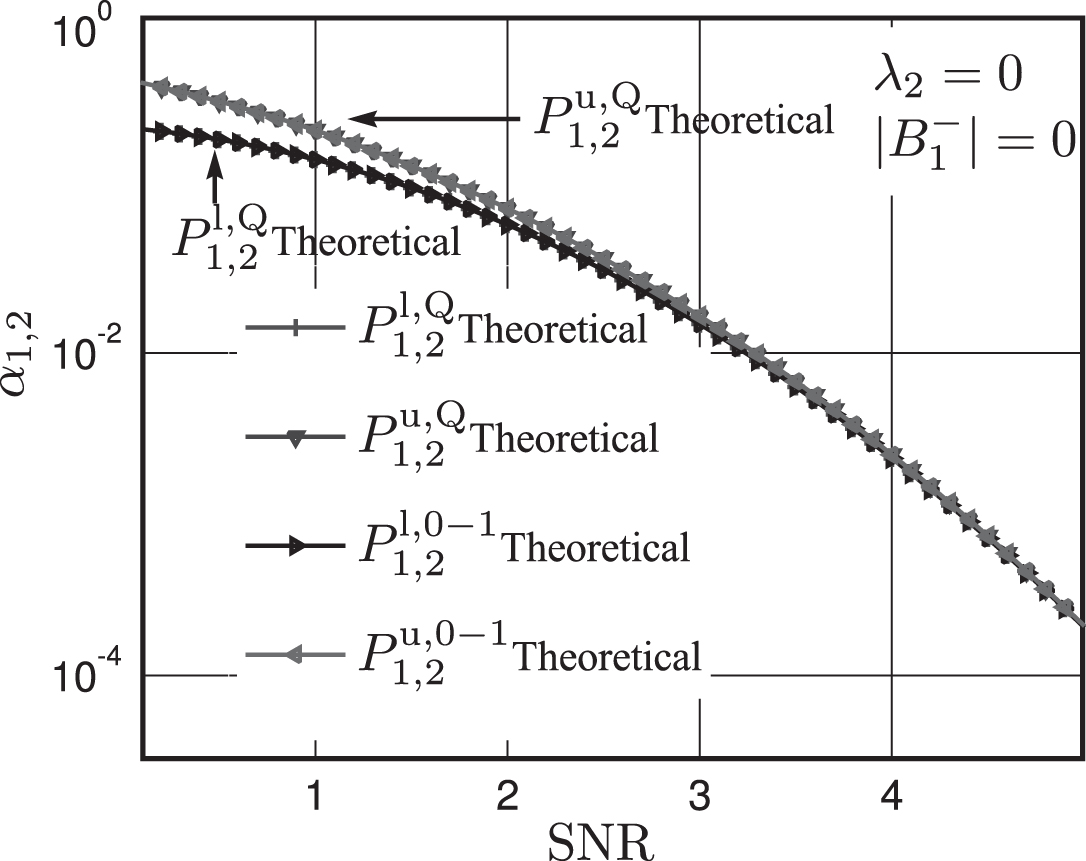
In Fig. 4, since it is calculated that λ2 = 0 in Topology 1 and a uniform prior distribution is assumed, . In addition, it is obtained that , so , . Then, according to Corollary 2, and do not converge to the same value as SNR increases.

Comparison between the bounds of and in Topology 1.
Comparison between the bounds of and in Topology 2.
Comparison between the bounds of and in Topology 3.
In Fig. 5, because all the for 1 ≤ k1 ≠ k2 ≠ k3 ≤ 3 in Topology 2, is reduced to . Therefore, , and .
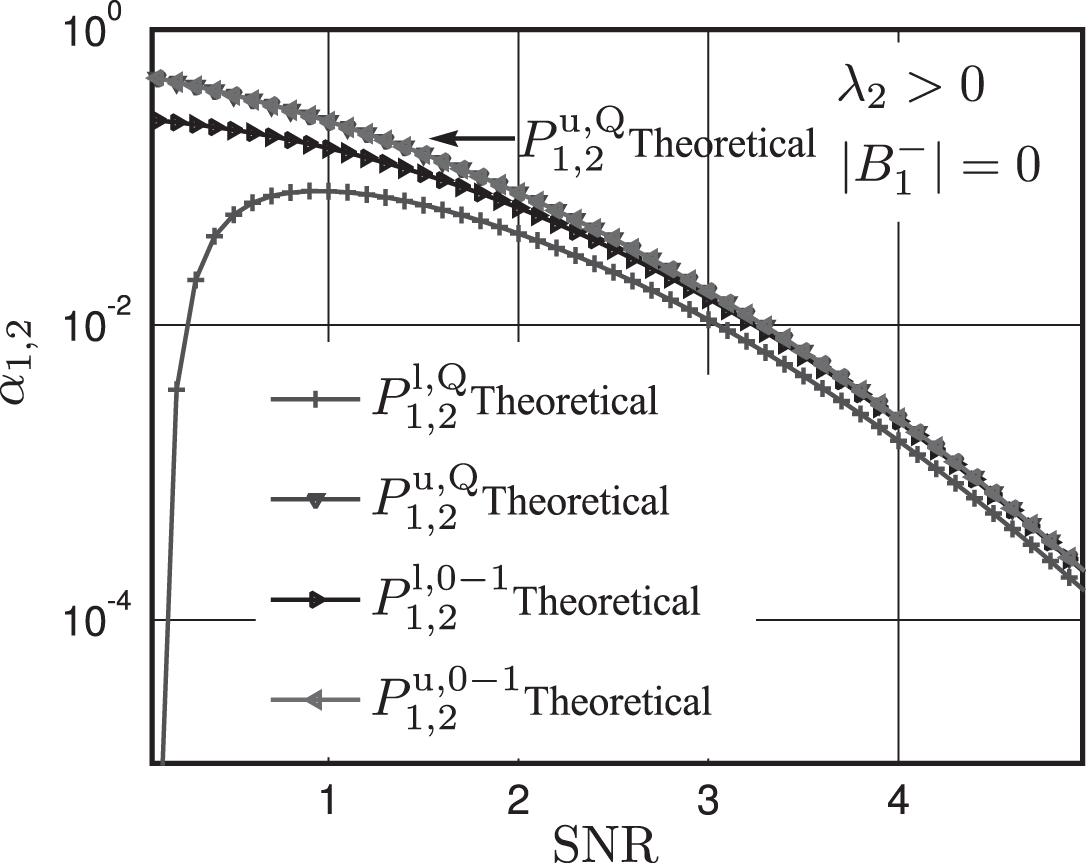
In Topology 3, it can be calculated that λ2 > 0, so . Additionally, ,so and . Therefore, . However, since λ2 > 0, although it does not ultimately change the asymptotic equivalence between and , it makes this phenomenon less remarkable as is shown in Fig. 6.
In this paper, the anomaly localization problem in distributed networks is treated as a multiple hypothesis testing problem and then a Bayesian test with a quadratic loss function has been proposed since the quadratic loss function is more suitable than the conventional 0 - 1 one in differentiating the losses caused by different false localizations. The Bayes risk of a test for the MHT problem has been expressed in a closed form as the sum of all misclassification probabilities weighted by the respective prior probabilities. The non-asymptotic bounds of the misclassification probabilities for the proposed test and the Bayesian test with the 0 - 1 loss function have been obtained to analyze their asymptotic performance from which it is derived that the asymptotic performance of the proposed test is influenced by the geometry of the parameter space associated with the hypotheses which further determines the conditional asymptotic equivalence between these two tests.
Acknowledgments
This work was supported by the China Scholarship Council between 2010 and 2014, and is now partly supported by the Fundamental Research Funds for the Central Universities (WUT: 153111003), by the National Science Foundation of China under Grant No. 71371148 and by the Project “the Fundamental Research Funds for the Central Universities” under Grant No. 2010-JL-22.