
Abstract
Non-destructive techniques such as hyperspectral imaging, backscattering imaging are the advanced techniques used for predicting mechanical properties of horticulture products. They show relatively good performance but at the expense of costly measuring setups. This application-oriented paper investigates the feasibility of employing simple digital color camera imaging for prediction and fuzzy classification of firmness of tomatoes. Images acquired using digital color camera are preprocessed and subject to texture analysis in order to extract the number of features. The proposed approach exploits four texture feature extraction algorithms: three are based on statistical techniques viz. first order statistics (FOS), gray level co-occurrence matrix (GLCM), gray level run length matrix (GLRLM), and one is based on transform-based technique viz. wavelet-transform. Out of all extracted features, redundant features are eliminated using various attribute selection methods. Subsequently, prediction models are built and analyzed using regression analysis. Sample space has been split into two sets; 80% training and 20% testing data having tomatoes with almost identical formation. Experimental results illustrates that RBF regression gave the lowest RMSE of 0.174 and highest prediction correlation coefficient of 0.929 for wavelet feature set. Grounded on the prediction model, fuzzy rule based classification (FRBC) is proposed to classify tomatoes into three firmness categories soft, medium, and hard. Accuracy statistics of the proposed FRBCS are compared with the state-of-the-art result and highest classification accuracy of 92.68% is achieved by proposed FRBCS. The results exhibit the possibility of using a digital color imaging system for firmness estimation and further for classification.
Keywords
Introduction
Tomato is one of the most widely consumed fresh vegetables all over the world. Acceptability of tomato is based on two factors, external qualities including color, size, shape, and internal qualities including firmness, soluble solid content, acid, and juice. External feature color and internal feature firmness are the most imperative factors observed by the consumer (wholesaler or retailer) for determining the quality of tomatoes [1]. Color is the indicator of the ripeness stage of tomato whereas firmness serves as the measure for its textural quality. Texture has high influence on quality and consumers’ preference. Typically, it is preferred that whilst being ripe, the fruit preserves a high degree of strength to protect the fruit from damage such as breaking during handling and transport.
In recent years, computer vision has been widely used for the quality inspection of fruits and vegetables [2]. Some of the advantages that favor the application of computer vision to agricultural problems include speediness, non-destructive evaluation possibilities, and ease. The increased demand for high quality vegetable and food products and their safety compels the growth of accurate, fast, and objective quality determination of food and agricultural products [3].
Texture is an imperative image feature that has been applied significantly in the food industry for food and crop quality estimation [4]. Recent applications of texture-analysis techniques in the food industry have determined the mechanical properties of food materials non-destructively [5]. The advanced techniques show relatively good performance in predicting mechanical properties of horticulture products [6–12]. However, the requirement of a distinctive imaging apparatus and cost is the major drawback concerning these techniques [13]. Simple imaging techniques using digital camera, scanners have also been adopted for products such as chicken nuggets [14], bread [15], and tea [4]. Researchers have obtained good performance in envisaging the mechanical properties of the products using image texture-based analysis techniques such as wavelet-transform, or GLCM. Significant work has not been done for exploring simple imaging technique for estimating the mechanical properties of tomato using texture-based analysis. Authors Sehgal et al. [16] explored the viability of using digital camera for firmness estimation of tomatoes. Multiple linear regression (MLR) analysis was done to establish the relation between the instrumental firmness and texture features extracted from the texture analysis of tomato images captured. The results showed the satisfactory performance with correlation of 0.89 but the validation test was not conducted on independent sample sets.
To measure the food texture using non-destructive test i.e. imaging, the texture properties must be measured by well-established reference methods such as compression test (universal testing machine (UTM)) or puncture/penetration test (texture-analyzers) [17, 18] along with the measurement of non-destructive methods. After this, results of both the experiments are given as an input to various statistical methods or artificial neural networks (ANNs) for developing prediction models.
Machine vision (MV) provides a mechanism in which human process is simulated artificially. Until date, MV has been widely applied to solve various agricultural problems, ranging from simple quality evaluation [19, 20] to complex robot-steered applications [21–23]. Consumers on the other hand, grade quality of food products in a fuzzy way according to their senses such as sight, touch, smell etc.
Therefore, the objective of the present work is two-fold i.e. to predict the firmness of tomatoes non-destructively and classify them into logical classes using fuzzy logic. Since imaging is generally non-destructive reliable and rapid [24], henceforth, the proposed work is non-destructive in nature. Different image texture analysis techniques including statistical and transform-based techniques are examined. In addition, for exhibiting the prediction model, feature selection is performed using greedy approach, evolutionary search, and particle swarm optimization (PSO) search before applying regression analysis. For regression analysis, polykernel-based Gaussian process, RBFkernel-based Gaussian process, RBF regressor (radial basis function), polykernel-based SMOreg, RBFkernel-based SMOreg, and PLS regression approaches are compared and analyzed to produce the texture feature set that best predicts the firmness. After building the prediction model, FRBC model is proposed for classifying the firmness into three classes soft, medium, and hard. Hence, the viability of using simple imaging systems in real-time applications for tomato firmness prediction and fuzzy classification based on predicted firmness has been explored by exploiting the texture-based feature analysis.
Material and methods
Data set
In the experiments, around 150 samples of tomatoes were collected from an open farm during daytime under natural lighting conditions. Samples that were free from visual defects were selected for experiments.
Objective/instrumental texture evaluation
After acquisition of images, samples were subjected to penetration test for firmness measurement using TA.XT2 plus texture analyzer by Stable Micro Systems [18, 25]. Calibration of instrument was done (settings as shown in Table 1) and tests were carried out for the whole fruit. Penetration test is defined as one in which the depth of penetration or the time required to reach a certain depth is measured under a constant load. While performing experiments characteristic force-deformation curves are obtained as force-time graphs. Figure 1 displays the force-time graph obtained for a batch of six tomato samples. When the probe punctures through the skin and begins to penetrate into sample flesh, it is often called as “Bio yield point (BYP)”. The BYP occurs when the probe begins to penetrate into the fruit causing irreversible change in the sample being tested. The force profile after this point signifies penetration into the underlying flesh of the fruit and indicates that this is substantially softer than the fruit. Force values corresponding to BYP are noted as Newton (N). Table 2 reports the statistical data (few batches) for firmness of tomatoes measured using TA.XT2 analyzer.
Texture analyzer settings for the experiments
Texture analyzer settings for the experiments

Force-deformation curve obtained from the penetration test.
Statistical data (few batches) for measured instrumental firmness using TA.XT2 analyzer
Images of around 150 tomato samples were taken without any artificial lighting system. A CCD camera (Nikon Coolpix S220V1.0, resolution 3648×2736 pixels) has been used for capturing the tomato images. As the size of the captured images captured is very large (3648×2736 pixels), they are first scaled down to 1/8th of their size to expedite the calculations. Image processing is done using MATLAB R2009a. Hereafter, segmentation process [26] on captured images is applied to separate out the region of interest (ROI) from the background.
Image texture analysis
Methodologies used for texture analysis are broadly classified into four categories: statistical, structural, model-based, and transform-based or filter based. Among these, statistical texture [27] is the most widely used one in the food industry for its high accuracy and less computation time. Transform-based texture is also commonly used technique while model-based and structural texture technique are rarely used in the food industry [28].
Apart from features extracted in the work done [16] one more statistical texture-based features viz. gray level run length matrix (GLRLM), is also considered here to process the captured images. All these techniques are computationally efficient than other statistical and transform-based techniques [8]. Brief description of these techniques is provided in the following subsections.
First order statistics (FOS)
First order statistics are the most elementary texture features extraction methods based on the probability of pixel intensity values occurring in digital images. Before extracting texture features, it is essential to equalize the histogram of the image pixels to reduce the influence of changing illumination. First, the histogram of gray level images obtained in Section 2.3 is extracted. They are then normalized according to the formula given by Equation (1).
Where, H (x i ) is the image histogram, P (x i ) is the normalized histogram, and N is the total number of elements in the image matrix. Ten statistical features mean (μ), standard deviation (σ), skewness for red component (skewR), skewness for green component (skewG), skewness for blue component (skewB), entropy, kurtosis for red component (kurtR), kurtosis for green component (kurtG), kurtosis for blue component (kurtB), and coefficient of variation (Cv) were extracted from each image using its normalized histogram. The list of features is presented inTable 3.
Texture features using First order statistics (FOS) for image histogram
The gray level co-occurrence matrix (GLCM) is a statistical and one of the most commonly used texture feature extraction method [15]. For examining texture, this method considers the spatial relationship of pixels. It is an n×n matrix where n is the number of gray levels in an image. Each matrix entry describes the number of occurrences of two gray levels given a specific offset. These offsets define pixel relationships of direction, θ and distance, d. The comparison of the GLCM can be done with fourteen statistical features as suggested by Haralick [27]. To reduce the computational cost, only four commonly used features contrast, correlation, energy, and homogeneity were selected. The tomato images were analyzed using the distance, d = 1 pixel with angles θ = 0, 45, 90, and 135. Thus, 16 features (4 directions X 4 features) were extracted from each tomato image.
Gray level run length matrix (GLRLM)
This technique registers the roughness of a texture in specified directions based on the number each gray level appearing in the image. A GLRLM is a matrix in which each element a(i, j) determines the total number of occurrence of run lengths j in the gray level i in specified direction d. Run length matrices at four directions d = 0, 45, 90, and 135 were extracted for each captured image. 11 texture descriptors for GLRLM in each direction [29], were calculated to capture the texture properties. Thus, 44 features (11 features X 4 directions) were obtained from each tomato image.
Wavelet transform
Wavelet transform has been used for analyzing the texture of agricultural materials [4]. Mallat [30] developed an efficient way of implementing discrete wavelet transform (DWT) using filter banks that decomposes an image into multiple wavelet components. At each level of decomposition, two sets of coefficients are obtained, approximations and details (horizontal, vertical, diagonal), which in total make four coefficients. The approximations are in high-scale and low frequency components of the signal. Whereas, the details are in low-scale and high frequency components of the signal. Captured images were subject to four levels of wavelet decomposition using a fourth-order Daubechies mother wavelet (Db4) [31]. To determine optimum level of decomposition, images at each level of decomposition were compared to the original images. As shown in Fig. 2, afterwards fourth level of decomposition the extent of down sampling increases, causing lower resolutions in the samples. Thus, the wavelet coefficients from first level to the fourth level of decomposition were considered. At all the levels of decomposition, approximation coefficients and detail coefficients for horizontal, vertical, and diagonal orientations were obtained. Three statistical descriptors including mean, standard deviation, and entropy were extracted from each level of decomposition. Total of 48 features (3 statistical descriptors X 4 wavelet coefficients X 4 decomposition levels) were obtained from the DWT of each image.
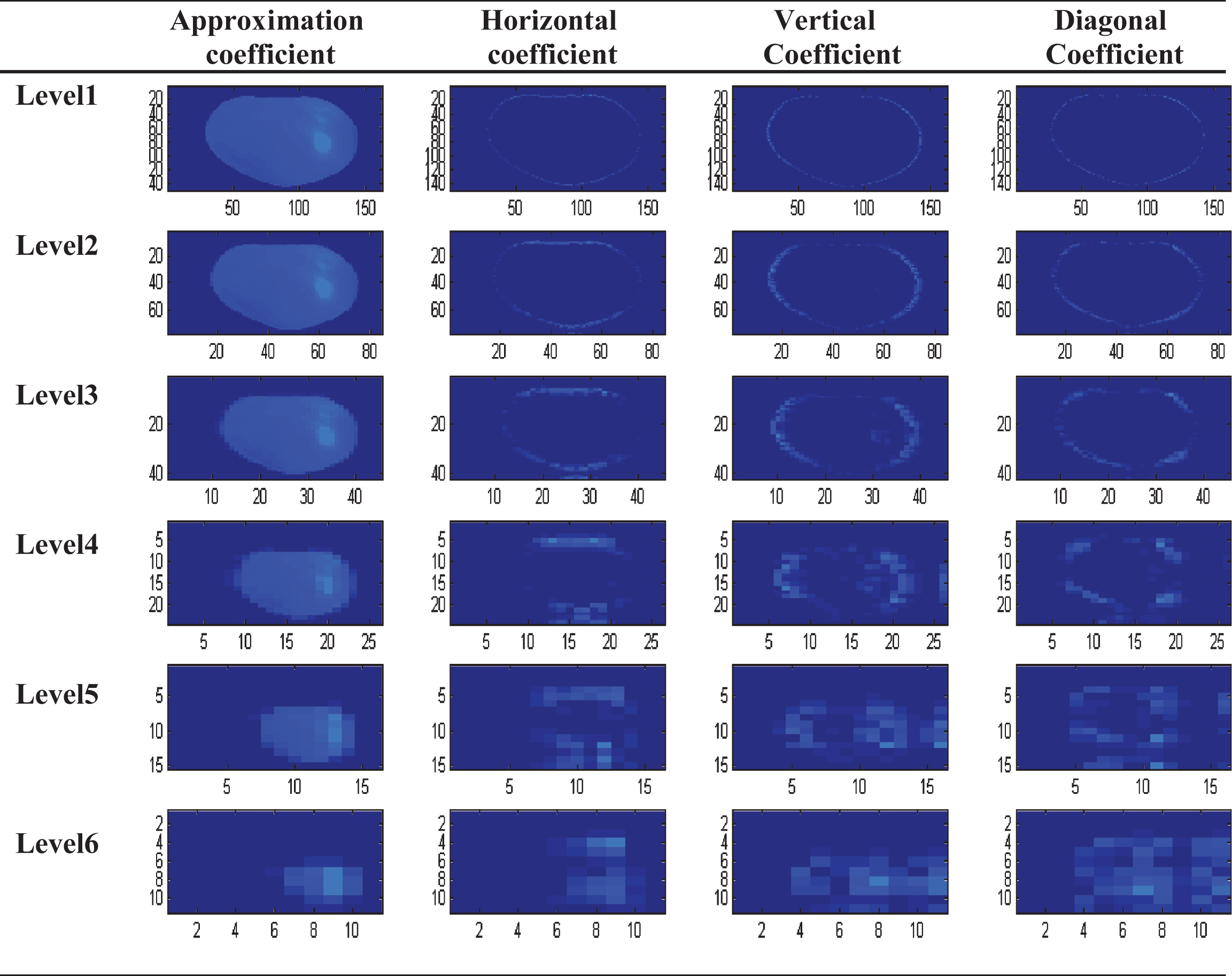
Six level Wavelet decomposition of tomato sample image using Db4 mother wavelet.
The feature extraction process leads to data sets with number of inputs as 7 for FOSH, 16 for GLCM, 44 for GLRLM and 48 for wavelet. Large number of model inputs may lead to increase in execution time and consequently reduces the predictive accuracy. Attribute selection methods such as greedy stepwise algorithm, evolutionary search, and PSO search decipher these problems by eliminating redundant features. In this study, all these three methods were compared and analyzed to obtain the optimum feature set that will be further used for predicting the firmness.
Prediction model
To ensure that models were not over-fitted and prediction results truly represent the model performance, the samples were first divided into two separate parts randomly. The first part (or 80% of all samples) was used for training, 20% of all samples were used for independent test or prediction. To select the best prediction model from the training samples, six state-of-the-art regression techniques; polykernel-based Gaussian process, RBFkernel-based Gaussian process, RBF regressor (radial basis function), polykernel-based SMOreg, RBFkernel-based SMOreg and partial least square (PLS) regression were compared and analyzed. The models were evaluated using root mean squares errors for prediction (RMSEP).
Where is the actual value, x i the predicted value, and n is the number of samples in prediction stage. In addition, correlation coefficient for prediction (Rp) has also been calculated. Since processing time is a significant factor in real-time applications, it was recorded to be used as an evaluation criterion for each feature extraction technique. WEKA was used for statistical analysis in a laptop computer with this configuration: Core 2Duo CPU, 1.53 GHz, 2 GB RAM, Windows 7 OS.
Firmness of tomato estimated through prediction model is in the form of crisp value. However, user tries to explain the firmness of fruit in a vague manner such as soft, slight soft or slight hard but medium or hard and so on. Therefore, this problem can be exhibited precisely using fuzzy logic.
To fuzzify the crisp values and represent them as classes, we earlier proposed a technique FRBCS [32] that provides a self-reliant decision-making resource for the harvesting robot to classify the tomatoes based on ripeness using color as their attribute without the need of any human expert. The FRBCS proposed earlier has been deployed here to classify the tomatoes based on their firmness. It depicts the problem in a manner closer to human thinking process. Figure 3 displays the flowchart for the classification using fuzzy rule based decision system. Detailed discussion of the steps from the perspective of classifying tomato images based on firmness is given as follows.

Flowchart for the classification using fuzzy rule based decision system.
Step 1: Define the input and output attributes.
The input is the training dataset i.e. the predicted firmness (“predFirm”) and their corresponding classes. The output attribute i.e. class attribute has three classes. Class C1 represents the hard or firm class (hard), C2 is the medium (med) class, and C3 is the soft class (soft).
Step 2: Feature space fuzzy partitioning
By outlining the proper interval values and boundaries of each region, fuzzy regions for the input attribute ‘predFirm’ are created. Initial intervals for the fuzzy regions in the universe of discourse X = [Xmin, Xmax] are given by Equations (3 and 4).
Where, u1 = Xmin, u2 = Incr (A) , …, and umax = Incr (A) * k and umax-1 < Amax ≤ umax
Xmin= minimum value of X, Xmax= maximum value of X
Amin= minimum value of A.
Amax= maximum value of A.
|A| = number of distinct values of A
w = is the positive integer user-defined weight.
k = is the positive integer (1, 2, 3 ... n)
In the proposed system, ‘A’ characterizes the feature vector “predFirm”, which is the predicted firmness. X = [0 ... 23.11] is the universe of discourse of attribute A. In accordance with the values obtained (as discussed in section 2) for input attribute A, Amin= 5.44, Amax= 23.11, |A| = 133. ‘w’ is a positive integer positioned to control the number of regions that needs to be created. Using Equation (4), for w = 15, Incr(A) = 3.22 and for w = 30, Incr(A) = 6.44, the choice w = 15 has been experimentally found to be the optimum choice as it will create reasonable number of fuzzy regions. Now according to Equation (3), u1 = 0, u2 = 3.22 * 1, u3 = 3.22 * 2, u4 = 3.22 * 3, u5 = 3.22 * 4, u6 = 3.22 * 5, u7 = 3.22 * 6, u8 = 3.22 * 7 u9 = 3.22 * 8. The last unit will be u9 = 3.22 * 8, since it satisfies the condition: 22.54 < Amax = 23.11 ≤ 25.76 as given in Equation (3). However, for k = 10 the condition is not satisfied because 25.76 ≮ Amax = 23.11 ≤ 28.98.
Henceforth, we get the initial intervals for the input attribute “predFirm” as Interval (predFirm) = {0, 3.22, 6.44, 9.66, 12.88, 16.1, 19.32, 22.54, 25.76}.
Divergent values of input attribute predFirm are now denoted by the set of fuzzy regions {R1, R2 … Rk}. Any kth region Rk is defined as the set of three parameters as , where, is the lower limit value, M k is the modal value, and is the upper limit value. The initial lower parameter, and upper parameter, obtained for the adjacent fuzzy regions R k and Rk+1 respectively are now tuned based on the overlap degree between them. Overlap (R k , Rk+1) is the metric which gives the degree of overlay between the adjacent fuzzy regions R k and R k + 1 [32].
The overlap degree for the input attribute “predFirm” between the adjacent regions is given in Table 4. In this table, column “Region” shows the initial regions for the input attribute “predFirm”, column “Classes” specifies the set of classes covered by the respective regions.
Overlap degree between the adjacent regions
The membership degree ‘μ’ of an input value, say x, is estimated by a triangular MF for computing the degree of value ‘x’ that belongs to region R k [32]. Figure 4 shows the partitions (initial MFs) obtained for the predFirm attribute without overlapping & Fig. 5 shows the fuzzy partitions (final MFs with overlapping) attained between the regions respectively.
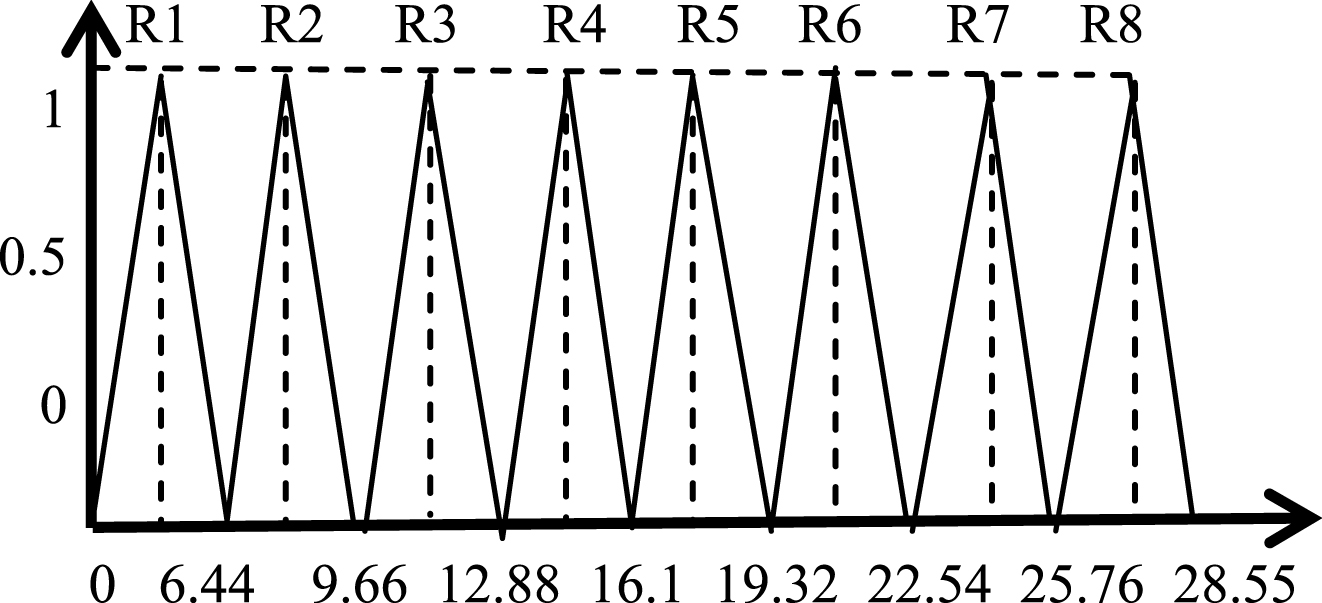
Initial MFs without overlapping.

Final MFs with overlapping.
Table 5 below displays few of the fuzzified values from the training dataset. Grounded on their degree of membership, crisp values are transformed to linguistic variables. Region names soft corresponds to region R1, soft-med to R2, med-hard to R3, and hard to R4. Column “predFirm” shows the crisp values of firmness from the training dataset and column “Region” shows the linguistic variables to which they are mapped according to their degree of membership.
Crisp values changes to fuzzy values (linguistic variables)
Step 3: Generate rule base using Decision Trees.
As described in [32], a rule bas e is formed using decision tree (DT) to produce the rules automatically from the feature set, which helps in eradicating the need of human expert for creating the rules. Rules obtained by traversing each branch of the decision tree are:-
If predFirm = soft then class = soft
If predFirm = soft-med then class = soft
If predFirm = med-hard then class = med
If predFirm = hard then class = hard
Step 4: Fuzzy Inference Process
Subsequently, next step is to feed the membership function (step 2) and generated “if-then” rules (step 3) to the fuzzy inference system (FIS). Output of the system is the firmness class of the tomato. Outline of the proposed fuzzy rule based classification system is shown in Fig. 6.
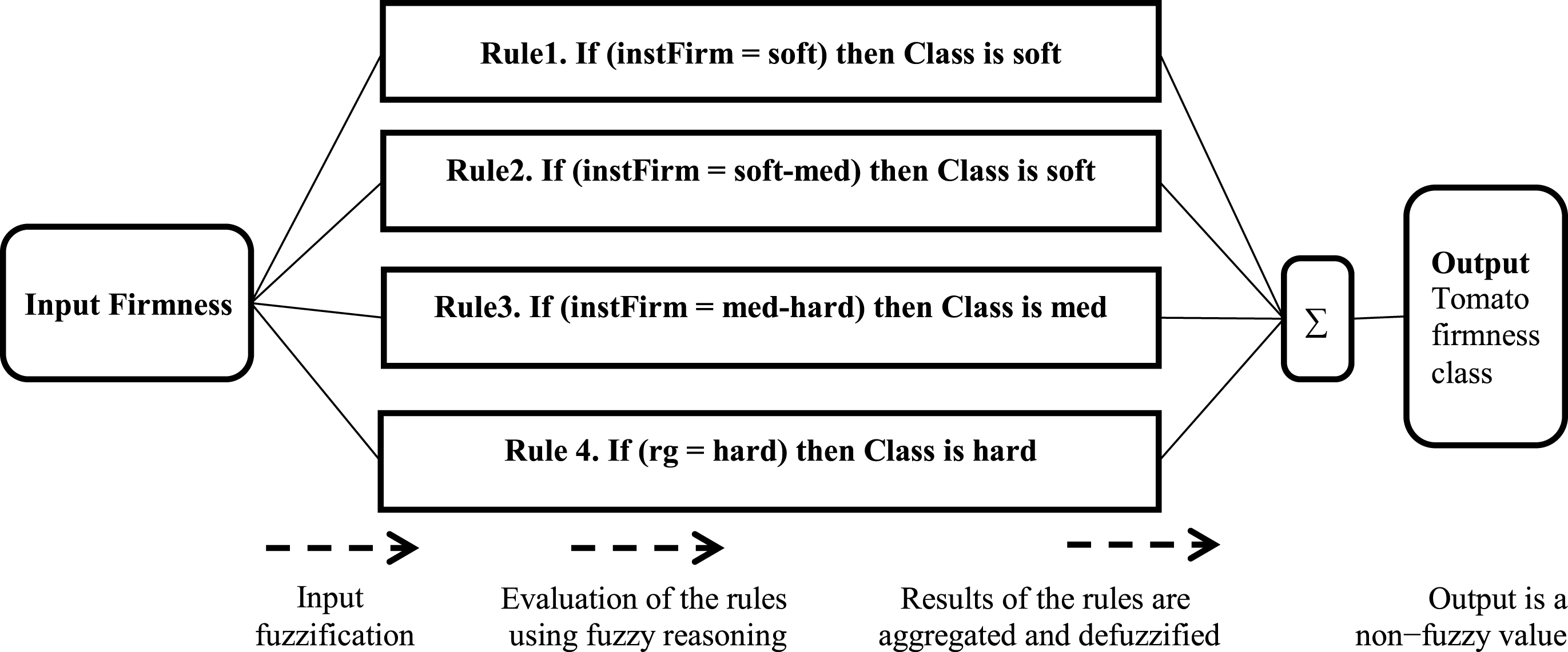
Structure of the proposed FRBCS.
Firmness prediction
In real-time applications, such as grading/sorting machines, two factors are important: prediction accuracy and processing time. To compare the capability of different texture techniques for real-time applications, processing time during feature extraction process for each technique was recorded. Figure 7 illustrates the time achieved by various texture methods on the study data set. Results show that GLRLM is unsuitable for real-time systems since it requires considerable much time for implementation. On the other hand, FOSH, GLCM, and wavelet, and were the fastest techniques because their processing time was less than 0.5 s.
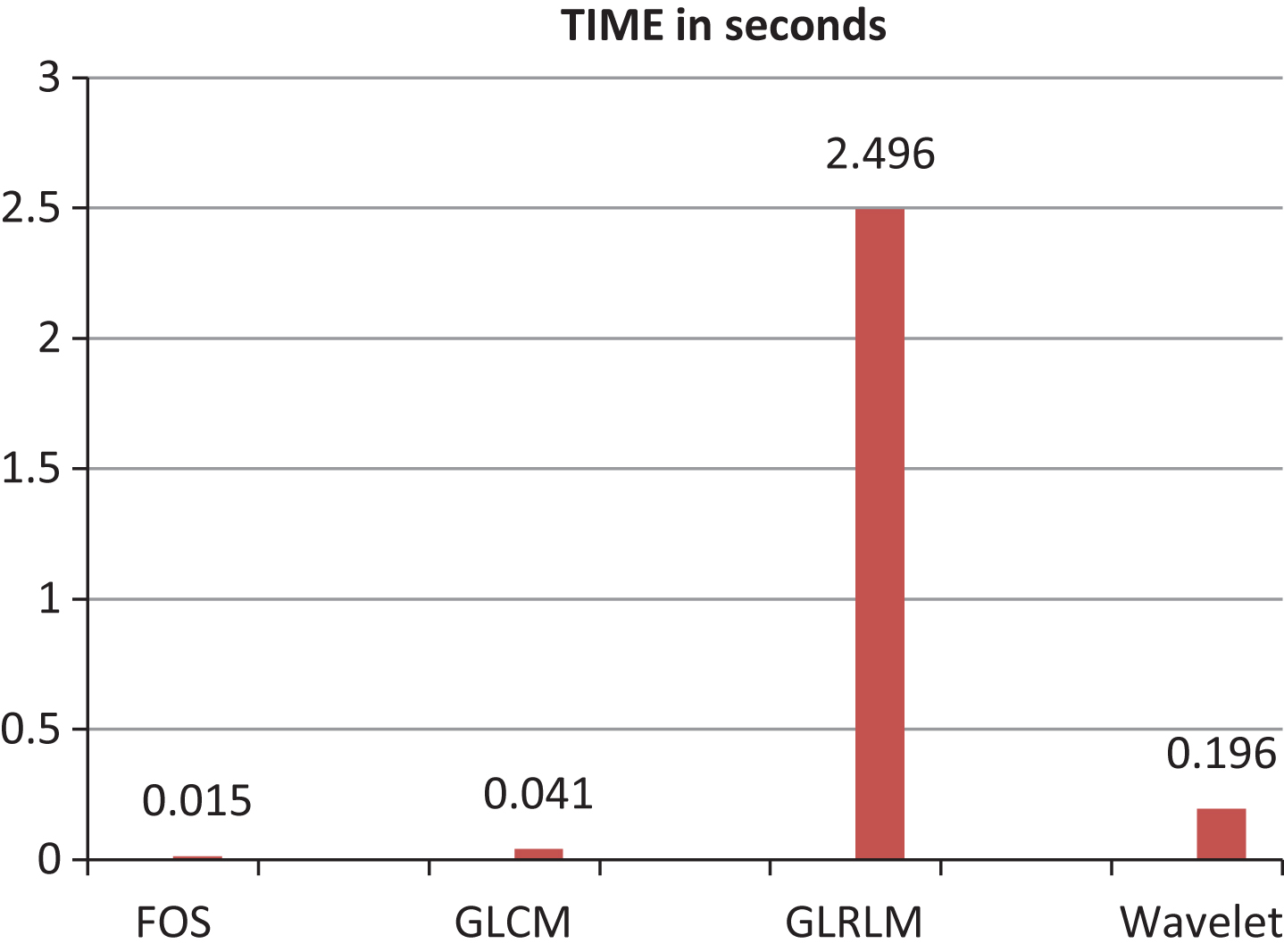
Time comparison (in seconds) of individual feature set models.
Table 6 shows the list of top texture analysis features obtained by three feature (attribute) selection methods for tomato. Different numbers of features were selected by three attribute selection techniques. This process considerably reduced the size of feature vectors.
Variable selection using greedy, Evolutionary search and PSO search algorithm
Statistical measures of individual texture-based feature models for predicting firmness of tomatoes by six regression techniques are presented in Tables 7–10.
RMSE and R value for Prediction model using FOS texture feature set
RMSE and R value for prediction model using GLCM texture feature set
RMSE and R value for prediction model using GLRLM texture feature set
RMSE and R value for prediction model using wavelet texture feature set
Comparing the performance of attribute selection methods, PSO search yielded in minimum RMSE 0.218, 0.175, 0.196, and 0.174 for all the regression techniques for FOS, GLCM, GLRLM, and wavelet feature set model respectively. For FOS feature set model, all three attribute selection techniques selected the same variable, henceforth, RMSE and R is same in all the cases (Table 7). Statistics in Table 7 shows that PLS Regression gave the minimum RMSE of 0.218 and maximum correlation coefficient (Rp) of 0.855 for FOS features set (Fig. 8(a)) followed by 0.869 for GLCM feature set shown in Table 8. Whereas, for GLRLM feature set RBF regressor gives the good performance (Rp = 0.891341 (Table 9)) followed by the wavelet feature set Rp = 0.928581 (Table 10). Figure 8 demonstrates the graph of RMSE comparison for prediction model using FOS, GLCM, GLRLM, and wavelet texture feature set.
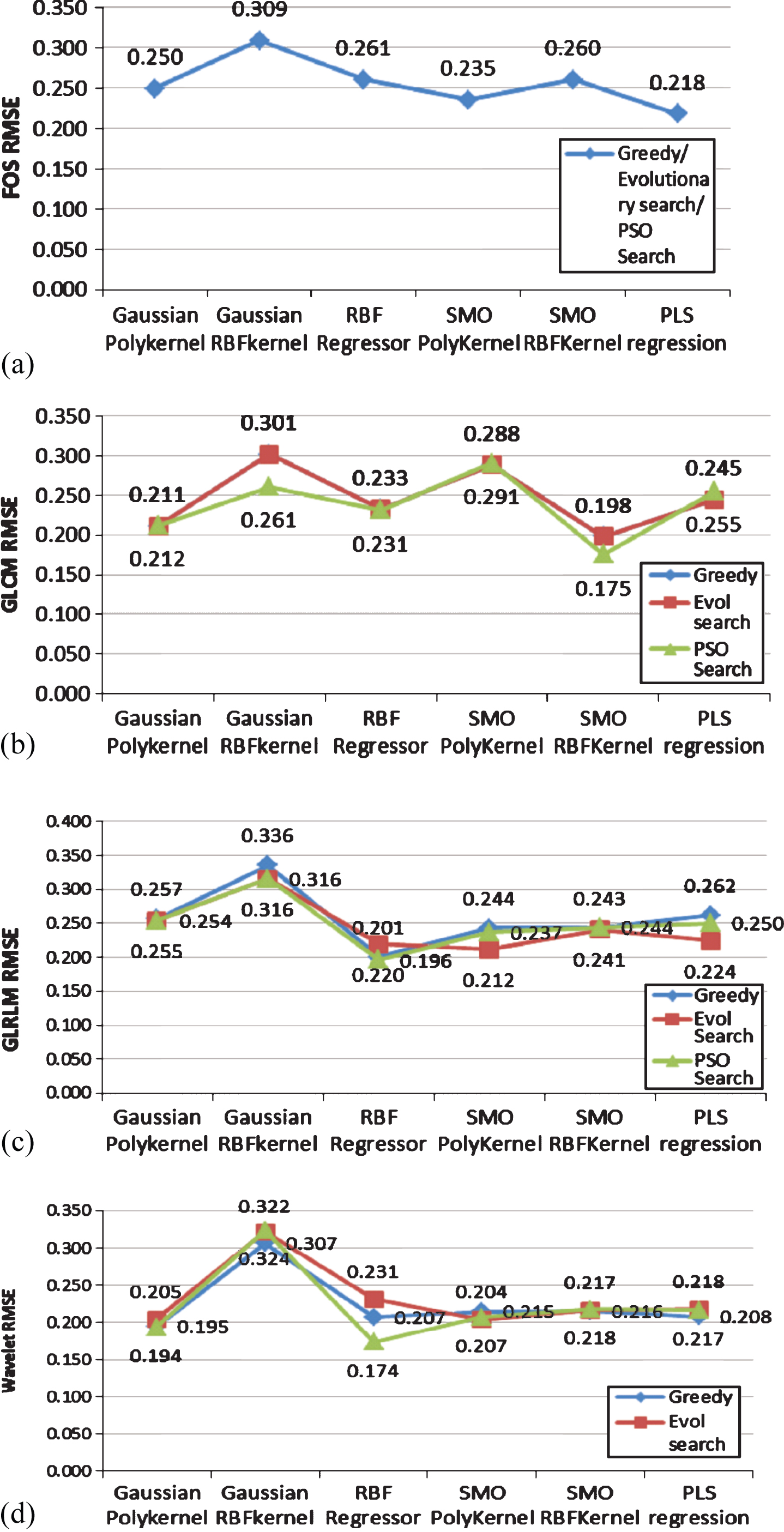
Graphs showing the RMSE comparison for prediction model using (a) FOS texture feature set (b) GLCM texture feature set (c) GLRLM texture feature set (d) wavelet texture feature set.
Gray portions highlight the techniques that attained lowest RMSE and highest R for a particular feature set. From the above tables it can be observed that PLS regression and RBF regressor performed almost equally for all the four feature sets. In addition, attribute selection performed through PSO search resulted in best accuracy statistics for all the regression techniques.
Since, PSO search ascertains to be the best feature selection criteria, all the regression techniques are compared against their R-value for four feature sets based on PSO search. It has been illustrated graphically through Fig. 9. From graph, it can be realized that RBF regression gave the highest prediction correlation coefficient of 0.929 for wavelet-transform feature set. In addition, RBF regression gave lowest RMSE of 0.174 for wavelet-transform feature set (Fig. 8). Hence, wavelet-transform can be selected as the best texture-based technique for analysis of images captured using digital camera because of their consistency in firmness prediction performance. Reason can be attributed to the capability of wavelet transform in analyzing the texture values of an image up at different scales. It gives more detailed information that relates well with mechanical firmness of the tomato. The decomposed sub-images at different scales offer unique textural features, which may not be visible in the original images and thus eliminates the redundancy of resolutions. While, statistical approaches are restricted only to spatial distribution analysis of textures.
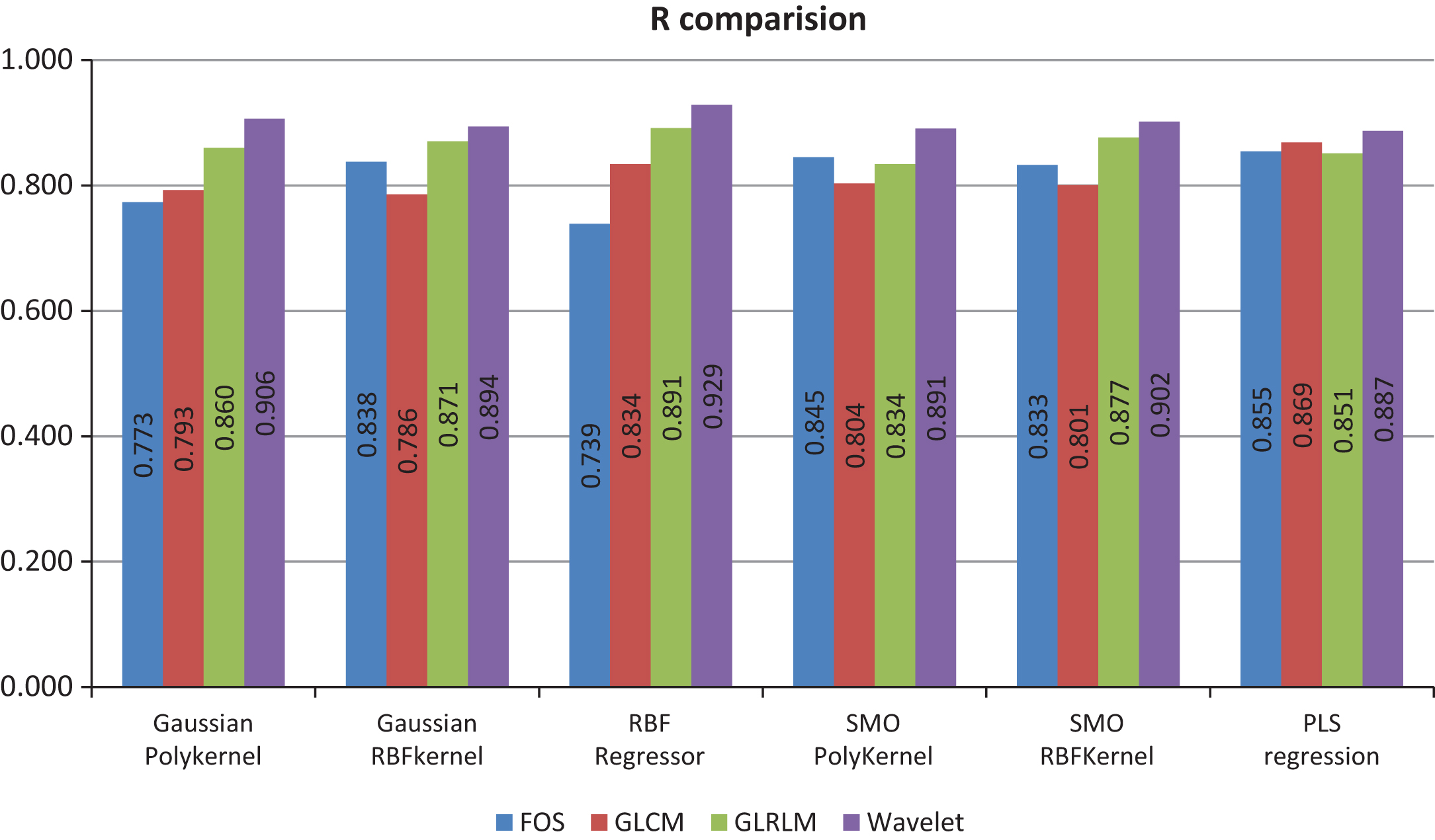
Correlation coefficient (R) comparison of FOS, GLCM, GLRLM, wavelet feature set obtained using PSO search.
For assessing the accuracy of proposed FRBCS for firmness classification, the sample dataset of tomato images is randomly split into two partitions viz. 80% of the dataset is used for training and 20% of the dataset is used for testing. Results obtained are listed in Tables 11–13. Table 11 shows the classification accuracy, and kappa statistics of the system. Kappa Statistic [33] is a measure of the agreement between the predicted and the true class, where value of 1.0 signifies complete agreement. For this purpose, a higher value was expected for a classifier having more coinciding predicted and actual values.
Evaluation metrics for the proposed FRBCS
Evaluation metrics for the proposed FRBCS
Detailed Accuracy by class
Performance comparison of proposed FRBCS for firmness with state-of-art learning algorithms
Table 12 displays the detailed accuracy for each of the three classes. For every class, True Positive rate (TP), False Positive Rate (FP), Precision, Recall, and F-measure is calculated.
From Table 12, we can observe that tomato images are correctly classified with the true positive rate of 1.0 for the hard class. However, false positive rate of 0.038 and 0.074 can be observed in the soft and med class. The reason behind this is that some tomatoes that belong to soft class were misclassified as medium and vice-versa. This error resulted in dropout in precision for both soft and medium class.
The proposed FRBCS for firmness is compared with other state-of-art learning algorithms such as NaiveBayes, SVM, Multilayer perceptron (MLP), decision tree, and RandomTree. Table 13 reports the performance statistics for proposed FRBCS and other state-of-art learning algorithms.
Figure 10 illustrates the comparison of the proposed system and other learning algorithms based on their classification accuracy and kappa statistics. From the graph, it can be observed that classification accuracy achieved by SVM and MLP is 90.86 and 90.66 respectively, which is comparable to the proposed algorithm i.e. 92.68. However, kappa statistics of proposed algorithm is much higher (0.927) as compared to SVM (0.862) and MLP (0.859). Highest classification accuracy of 92.68% (shown as bar graph) and kappa statistics of 0.93 (shown as line graph) is achieved by proposed FRBCS for firmness. This signifies that the settlement amongst the predicted and actual class is much improved in case of proposed FRBCS indicating the good classification competency of the proposed FRBCS for firmness.
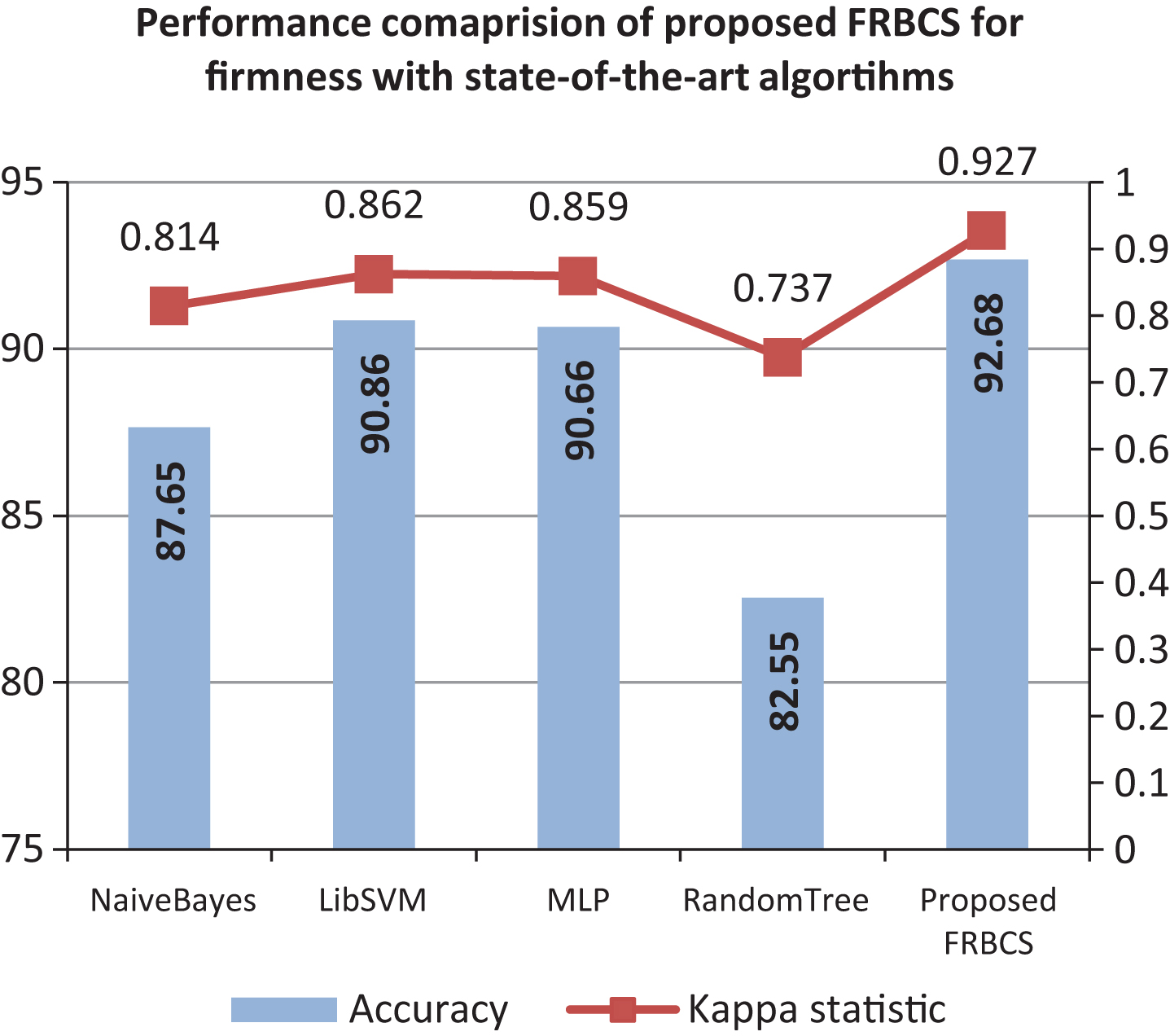
Performance comparison of proposed FRBCS with state-of-art algorithms.
The paper presents the two-fold work i.e. non-destructive prediction of firmness using a low cost digital color camera and fuzzy classification of predicted firmness. An empirical analysis of number of different texture analysis methods was carried out for predicting the mechanical property i.e. firmness of tomato. Prediction model was established using RBF regressor, which is a fully supervised approach, based on RBF networks for modeling. Wavelet texture feature showed best statistical performance amongst all the features. Furthermore, based on predicted firmness, proposed FRBCS classifies the tomatoes into three fuzzy classes i.e. soft, medium, and hard. The fuzzy classification aids in improved representation of the consumers’ fuzzy aspect of understanding the firmness. In whole, the system provides the self-sufficient system for estimating and classifying the tomatoes based on the firmness non-destructively and at a very low cost. The proposed approach brings out the viability of using simple imaging system for real-time applications in agriculture.