
Abstract
LBS (Location Based Services) have been a type of “killer application” for ongoing and upcoming internet services. ILBD (Indoor Location Big data) are extremely big multimedia data indeed. However, indoor location data are more complicated than outdoor. Lack of unified representation model and data redundancies make ILBD hard to cluster and mine location based values. Therefore, this paper proposes a new multi-dimensional features model and compacted clustering for ILBD. Unified ILBD model combines spatial and time features of different scales and states, which employs normalized data frames to pre-process original data. Scalable Euclidean extending distance is designed to characterize relationships between heterogeneous data and represent connection of different dimensions. In order to reduce ILBD redundancies and flaws, compacted clustering method are proposed, which construct location ontology and sensations parameters to determine ILBD main affecting elements, the sluggish elements would be filtered and shrink to decrease the amount of ILBD. The new multi-dimensional features model would be applied in LBS framework. The tests and simulations verify proposed model have enhanced 36.7% convergence estimation RMSE and 12.3% regional flow estimation accuracy performance, which improve accuracy of ILBD mining and reduce ILBD redundancies and flaws.
Introduction
Burst demand of LBS and ILBD big multimedia data
Benefited from the rapidly development of LTE (Long term evolution) and Big data, LBS (Location Based Services) have been a type of “killer application” for ongoing and upcoming internet services [1]. Especially, accuracy indoor positioning is truly expanding a much wider new internet service mode, such as O2O (Online to Offline). Imagine that you can book a discount e-voucher in an indoor restaurant for location finding, fireman can locate you around target room in a building when fires happen, or you can monitor your baby in the hospital to prevent missing care. According to data statistics, over 120 billion service requirements are launched from online booking car in China just in 2016 [2]. The crazy increasing demands for indoor LBS are taking up more throughout in network.
ILBD (Indoor Location Big data) are extremely big multimedia data indeed. First of all, great amount of services requirements surly demand high throughout and bandwidths to carry. It’ s hard to handle billions of data transition, analysis and mining, even the protocols carried in network, as Fig. 1 shown. Secondly, LBS data always consist of different sequences, files, pictures and videos, which are unstructured and of big difference size [3]. Current data models seem difficult to present the complicated correlations between locations and other information. Thirdly, the information from LBS data always are redundant, location can be found in the coordinates calculated, pictures users took or speech users talked. LBS data need great data clustering and simplify. At last, LBS data from heterogeneous network are not delay tolerant, a moving terminal would obviously miss the former seconds location coordinate, which cause low LBS QoS (Quality of Services) and vague recommendation.

ILBD big multimedia data.
LBS big multimedia data researches gain enough concerns from worldwide academies and institutions. Outdoor LBS data are the earliest cases to be researched. The location of targets are the first question users want to know, so coordinates would be calculated as the basis data [4]. As the development of GNSS (Global Navigation Satellite System), coordinates information is combined with geographic information to serve outdoor driving navigation, geospatial mapping and missile guidance. The introduce of customer relationships and pay information made LBS original value data business services [5]. Gradually, groups of business services have been binding with those potential to make more profits. Products and services recommendations combined with seller’s information, shopping malls discounts, goods advantages, provide merchants with a smarter or more convenience access to customers around offline locations. After a period of location track, an active customer behavior would be recorded, combined with indoor location map which are the distribution of shops and corridors, we can figure out the rules of customer shopping features. With the development of new internet applications and services, such as WeChat, Microblogging, Mobile payment, such mobile social networks are accelerated to fuse digital words, pictures, video into location to provide with more valuable information. Such ILBD always are unstructured and with sparse value for fragmentations location information.
In other to furtherly mine the value of ILBD, more efforts are given to compensate with the un-satisfied source location information [5, 14]. Data preprocess are firstly exploited to enhance location attributes associations by increase intricacy of maps. Grid-enable regions partition could group all information around different specified coordinates range, which are an original attempt for ILBD clustering. A scheme of data filter by pattern of road distribution was proposed to relate paths to enhance navigationperformance, which modified the accuracy of location estimation by paths predictions. DBSCAN (Density-Based Spatial Clustering of Applications with Noise) for indoor LBS seemed easier to mine data into heat concern shopping area, whose attributes of data around crowds would be considered [6]. Thiessen diagram was introduced to location data to calculate the optimal partition scheme for spatial clustering. Plenty of geographical features are taken into account to enhance the relevance between ILBD, which improve the data utilization and redundancy. Deeper features would be fused with several original features to achieve more precise LBS [7]. Regional static characteristics can be grouped around specified coordinates range not only maps information, but also roads, buildings, traffic facilities, gardens. The common features would be extracted from those static characteristics to strengthen the correlation and provide with earlier data sparse foundation. Regional transportation mechanics characteristics combine the moving features from target humans or vehicles, to generate an important dynamic information to represent crowds moving rules [8]. Moving behavior information can be widely used in monitoring and management. Individual moving patterns deserve the moving rules one person into crowds, which show the mean value of states transform probability. Dimensionality reductions are efficient for ILBD to be mine, which exploit hyperreal number or principal component regression to reduce each order and rank in features matrix. Combined spatial and time features contribute to better prediction performance, time features correlations methods such as hidden Markov model, conditional Markov model, conditional random fields are supplement the lost messages from discrete data collection, spatial features correlations such as Euclidean distance, Mahalanobis distance provide with spatial features convergence to reduce spatial samples. Those data processes can cluster certain ILBD to reduce matrixes dimensions and enhance data values[9, 11, 13].
However, indoor location data are more complicated than outdoor. Indoor positioning requirements are thousands times more than ever, which demands more ILBD processing and calculating resources. The difference scale of region static characteristics is extremely amplified, heterogeneous spatial features correlations are hard to be analyzed in a unified model. There are so much data redundancies and flaws that lots of ILBD should be re-cluster and re-mine again to improve the data value.
Brief state of art in proposed ILBD models
Therefore, focus on the serious problems caused by ILBD lack of unified representation model and data redundancies, this paper proposes a new multi-dimensional features model and compacted clustering for ILBD. Unified ILBD model combines spatial and time features of different scales and states, which employs normalized data frames to pre-process original data. Scalable Euclidean extending distance is designed to characterize relationships between heterogeneous data and represent connection of different dimensions. In order to reduce ILBD redundancies and flaws, compacted clustering method are proposed, which construct location ontology and sensations parameters to determine ILBD main affecting elements, the sluggish elements would be filtered or shrink to decrease the amount of ILBD. The new multi-dimensional features model would be applied in LBS framework. The tests and simulations verify proposed model have a better performance, which improve accuracy of ILBD mining and reduce ILBD redundanciesand flaws.
Multi-dimensional features model with normalized data frames and scalable Euclidean extending distance
Different from outdoor data features models, ILBD suffer from much more spatial and time heterogeneous data. Indoor location data are more complicated than outdoor. Therefore, new ILBD models have to satisfy several demands below.
ILBD models challenges and demands
Great capacity of data features: numerous devices would generate thousands of LBS requirements, imagine that IOT (Internet of Things) such as cellphones, RFIDs, sensors, blueteeth, computers, household appliances would connect each other by location findings, great capacity would be necessary for numerous data features. Extensible dimensional distance: different data types can extract the same features from different dimensions. In LBS, coordinates certainly show locations, we can also figure out locations by looking at pictures, locations can be described by speech. So, the relationships between locations and other features can be extended to different semantic dimensions. Scalable data representation: the same as maps, LBS would be represented in a full information maps. Users can watch a panorama view of ILBD, which are rough but brief. With larger scale, more detailed information not only locations would be shown in the full information maps [14].
Multi-dimensional features model
In other to describe the heterogeneous, unstructured and numerous ILBD, multi-dimensional features model is designed as features sets. The multi-dimensional features would be concluded as following concepts.

ILBD models challenges and demands.
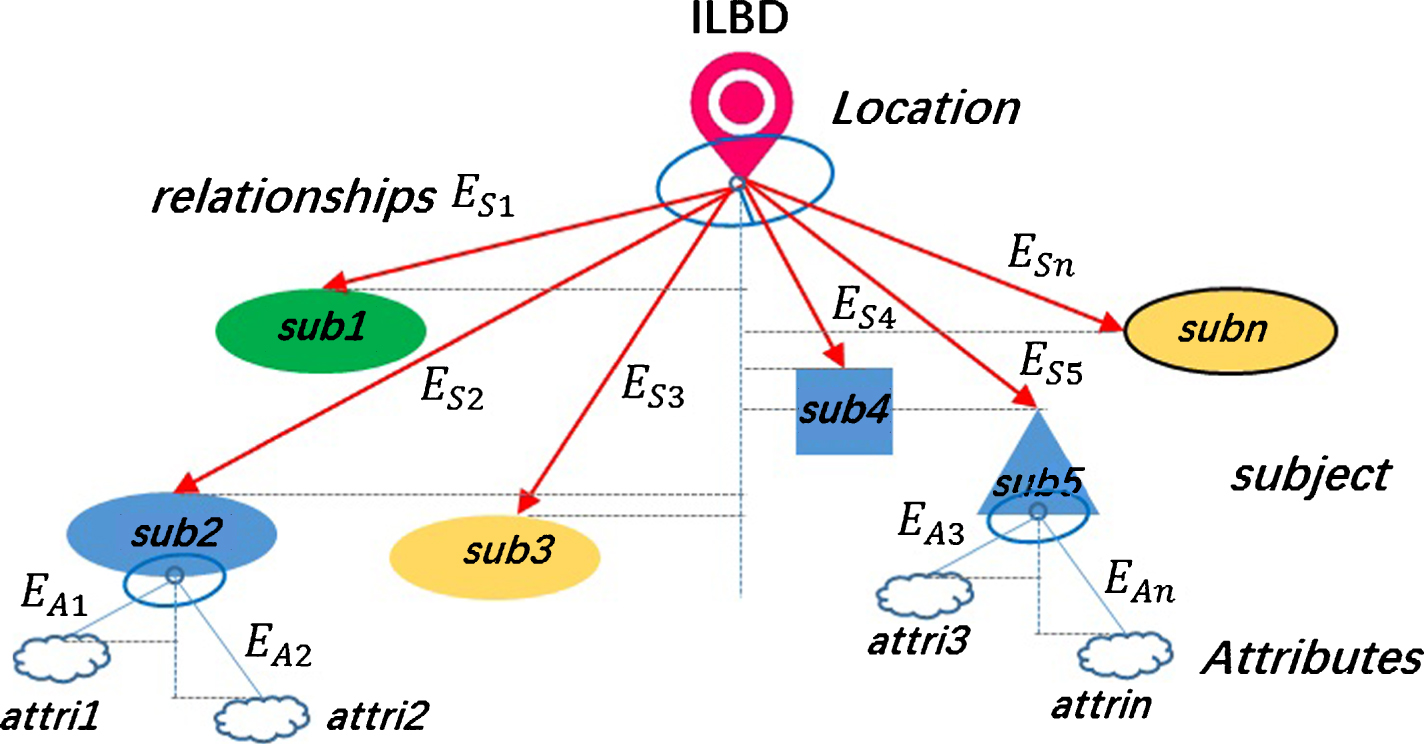
Multi-dimensional Features Model.
As Fig. 3 shown, multi-dimensional features model is constructed as the shape of tree. Location information L are considered as domain ontology. That is, the main body of LBS is location information, once location determined, ILBD would be basically structure confirmed. There can be many features in one location node. Subject features S link directly into Location information L with relationships E S , correlation distance and angle of E S are designed to characterize the relationships between locations and subject features, which provide with a 3 dimensions features plane. Each subject features have several attributes A to descript the conditions of current subject features, which also use E A to present the relationships between each subject features and attributes. The correlation distance and angle of E A extend the presentation dimensions of ILBD. Above all, multi-dimensional features model succeeds both exact relationships and extensible dimensions of ILBD at the same time. The concept ontology of big data sets would be described as follow.
Location information L = {L1, L2, ⋯, L n }, denotes n different types of location information, which extracted from coordinates, pictures, videos or voices. Adjacent location also would be recorded.
Time features T = {T1, T2, ⋯, T n }, all situations change in different periods T n , in addition, location information must be such real time data that ILBD would be valuable. ILBD are transformed into IBLD = <IBLD T 1 , IBLD T 2 ,⋯, IBLD T n >.
Relationships E S = {E S (d), E S (θ)}, distance d and angle θ are the correlation degree and deviation degree between locations and subject features, E S can describe as relation operators, such as compose operator, inclusion operator, effect operator.
Subject features S = {S1, S2, ⋯, S n }, comprise of different heterogeneous information, such as users, customers, merchants, goods, services, maps, which would be divided into sub-features.
Attributes = {A1, A2, …, A n }, which contain the size, capacity, number, speed, direction, height, weight and so on. Each attributes are mutual independent, but have relationships with center locations node.
Relationships E A ={ E A (d) , E A (θ) }, also can be control operator, need operator, assistance operator, interference operator and so on.
Multi-dimensional features model is abstracted from progressive logic layers. From services to elements, models transforming methods are designed with three steps. The methods procedures can be described in Fig. 4.
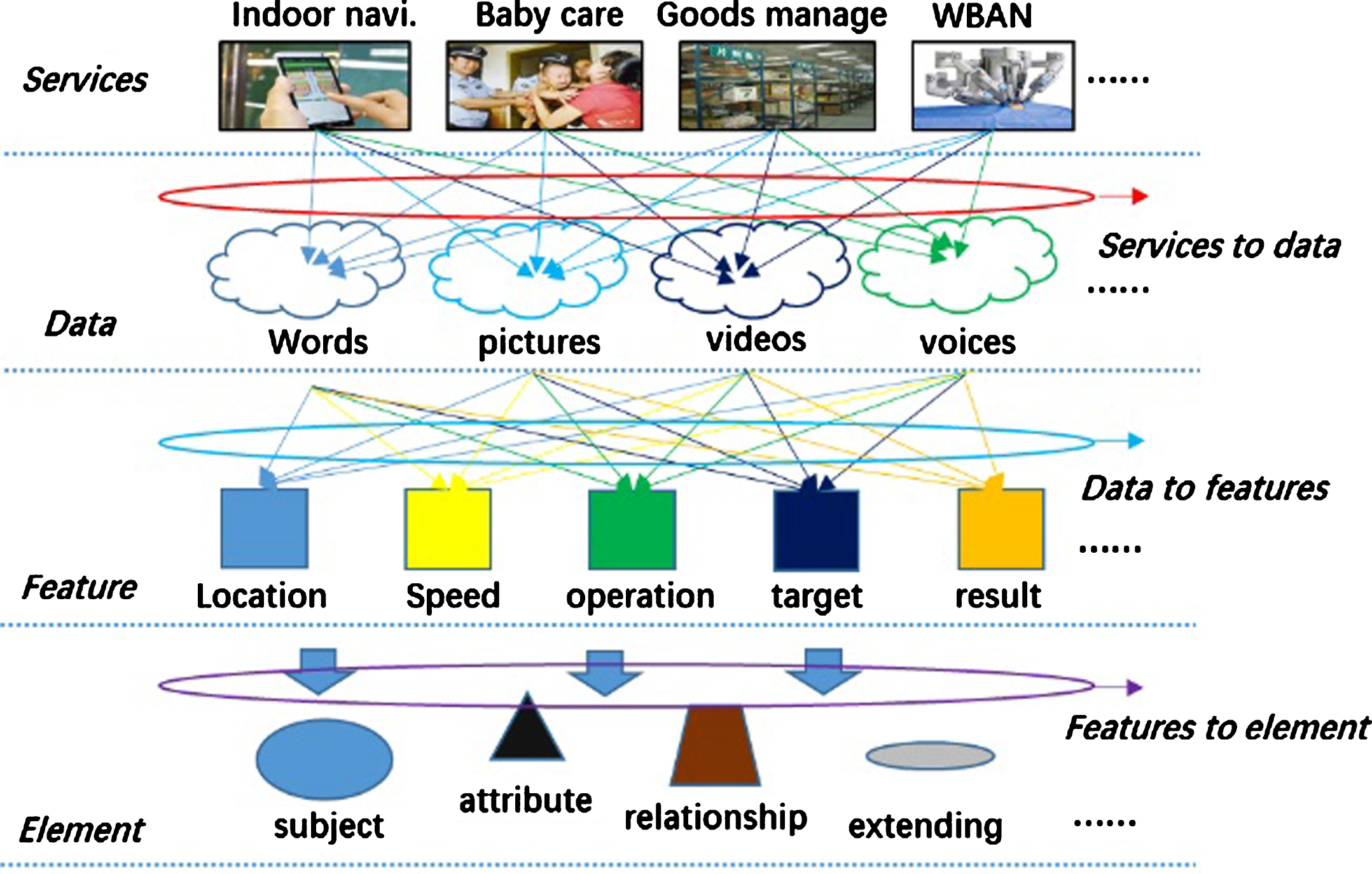
Services to elements models transforming methods.
As Fig. 4 shown, multi-dimensional features model is divided into four layers, which are services layer, data layer, feature layer and element layer. In sight, service layer presents directly the LBS compositions, which have complicated services flows to capture basic elements. Each LBS service comprises of words, pictures, videos and voices. We firstly extract data from LBS services, all types of data would be classified [16].
After services to data transforming, we exploit data to features mapping. Each data contains several features such as location, speed, operation, target and result, which are essential for multi-dimensional features model. For example, speed is the average distance between two locations. Features to element mapping are the last procedure, which separate important ontology elements from features layers. Multi-dimensional features model would be described as subject, attribute, relationship and extending, in other to represent ILBD.
Global efforts in form of data clustering and mining, the density of data values have been greatly improved. Contrast to our door LBS, lack of unified representation model and data redundancies make ILBD hard to cluster and mine location based values. Unified ILBD model combines spatial and time features of different scales and states, which employs normalized data frames to pre-process original data [17]. Scalable Euclidean extending distance is designed to characterize relationships between heterogeneous data and represent connection of different dimensions. In order to reduce ILBD redundancies and flaws, compacted clustering method are proposed, which construct location ontology and sensations parameters to determine ILBD main affecting elements, the sluggish elements would be filtered or shrink to decrease the amount of ILBD.
Scalable Euclidean extending distance
We design scalable Euclidean extending distance for ILBD Clustering, which comprises of scalable Euclidean extending distance Di,k, for the indoor location big data sets as IBLD = {L, T, S, E S , A, E A }, IBLD u and IBLD v are assumed as two specific ILBD. Location information L, Relationships E S and E A are observed by Euclidean distance with weighting parameters, as Fig. 5 shown.
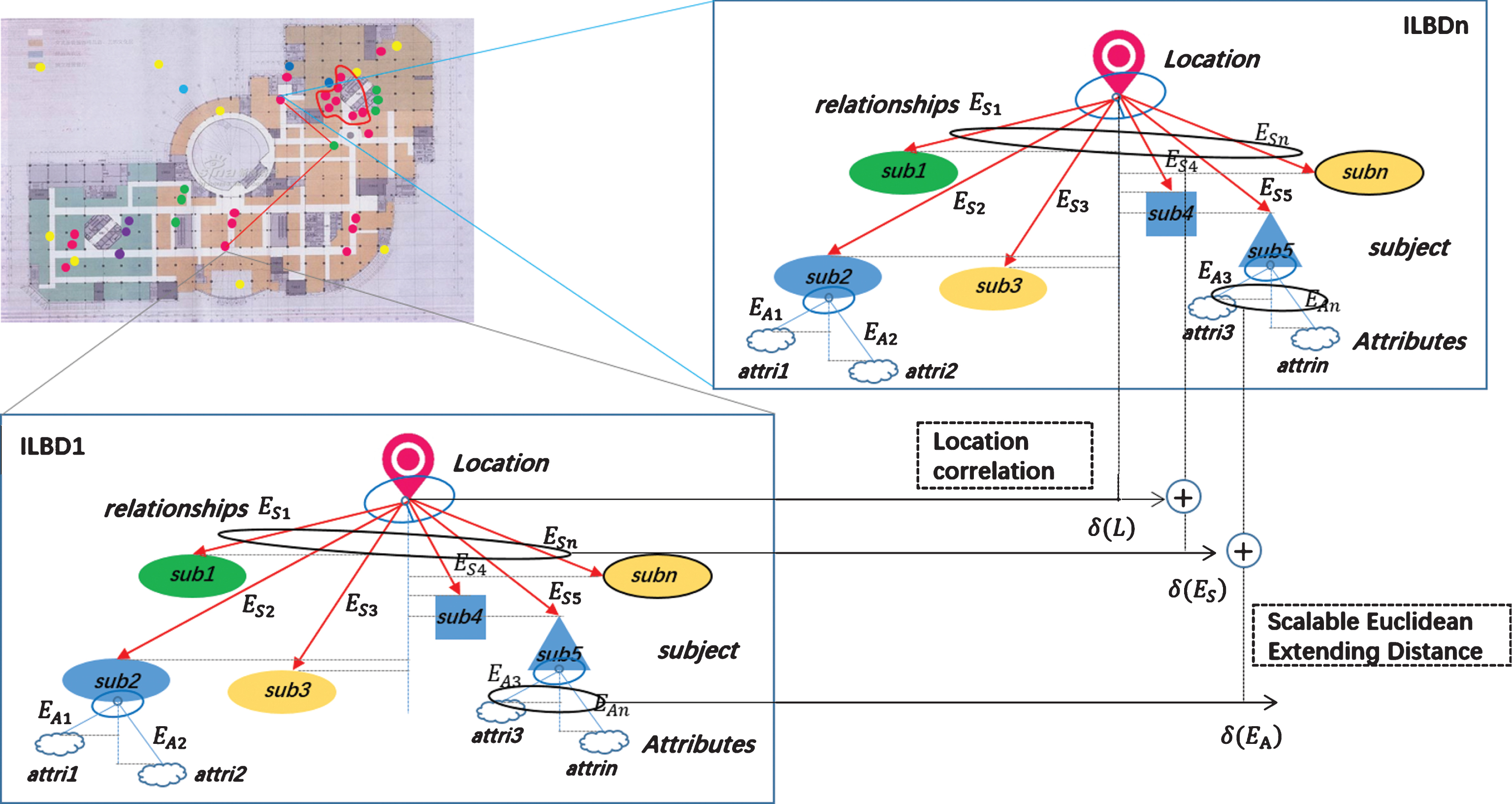
Scalable Euclidean extending distance for ILBD clustering.
Euclidean extending distance for ILBD Di,k can be calculated,
α1, α2, α3 are weighting parameters to adjust the influences by three features. The scale of location information L are much intensive, and have higher similarity. So, we operate semantic analysis to refine data items mapping to location information L, the mean square root variant of whole correlation distance are,
It has also been widely understood that time period T also plays a significant role in ILBD, so location information L cannot be effective aftera certain delay. We calculate the total correlation value between location and subject features in one ILBD case. Take the sensitive information entropy ratio of δ (L) under the correlation probability p
l
,that is,
The mean square root variant of relationships d
l
(E
S
) between locations and subject features are intimate with chained target function Jm,w [18], we set an sensitive parameter to calculate appropriated
l
(E
S
),
In LBS, what customers concern would change the value of ILBD, in addition, suitable relationships also change by different targets, different regions or different periods. We take the extremum of target function Jm,w, which contain serval customers aims under location L and time t. Constrained by the minimum of d l (L), d l (E S ) can be operated by inverse function of extremum of target function.
Relationships E
A
are limited within specific subject features S, self-correlation between attributes contribute more efforts to cross-correlation between features and attributes. So we make mixed mean square root d
l
(E
A
),
What’s more, d l (L), d l (E S ) and d l (E A ) substitute into Equation (1) to get the value of Euclidean extending distance for ILBD.
The value of ILBD always vary under different targets. In a shopping mall, not all the customers are eager to buy. Going to dinner, toilet or monitoring are also essential. So target function with extending location relationships are proposed to construct clustering threshold. Based on location ontology, ILBD have higher data density, that is, farther location points would be firstly filtered. Near location points would be operated in construction of chained target function Jm,w.
We take chained target function Jm,w as matrix of hyperplane features,
For m > 1, 0 ≤ u
ik
, t
ik
≤ 1, u
i
k and t
i
k are the spatial and time membership of ILBD, we have
After that, we observe the result under the value of zero equal to partial derivatives of Equation (7),
Equations (3–5) would substituted into Equations (8–10), for all the value of i and k, we design clustering method for reducing ILBD redundancies and flaws, the procedure of compacted clustering for ILBD are as following,
Experiment and analysis
Experimental environment
We have implemented indoor positioning systems in several shopping malls in China, which exploit TC-OFDM (Time-Code Orthogonal Frequency Division Multiplexing) [19] to provide with precise indoor location information, which are within 3 meters. All location information would be collected by LBS data center servers along with other shopping or customers’ information. We group five servers into a trunking calculation environment. Hadoop system would be installed to achieve cluster and mine location based values. One master server has 4.2 GHz CPU and 8 G Memory, four slave servers have 2.7 GHz CPU and 4 G Memory. Each server has 300 GB hard disk capacity, experimental environment in shown in Fig. 6.
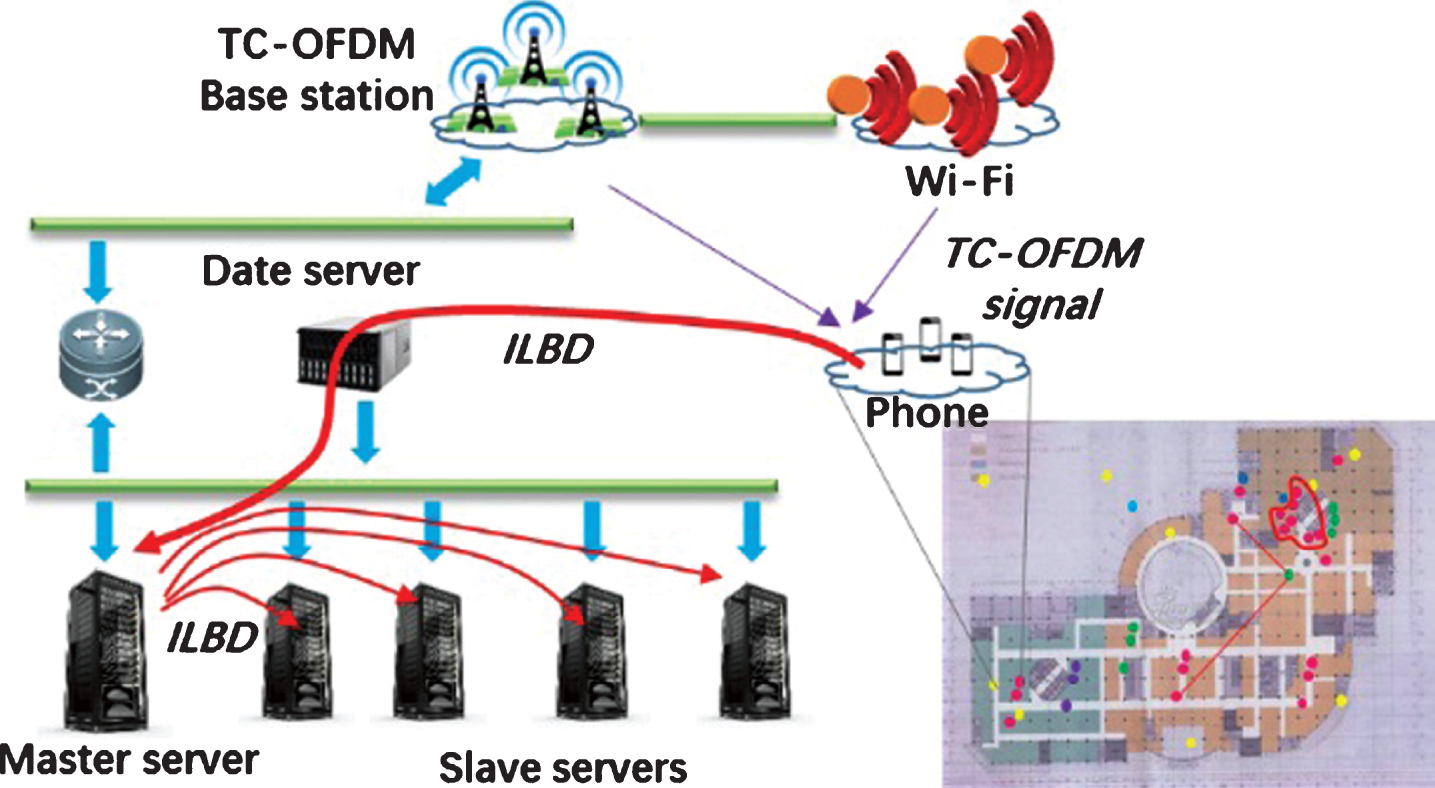
ILBD clustering experimental environment.
We collected about 500 million ILBDs in a shopping mall during 3day, unified ILBD model combines spatial and time features of different scales and states would be applied, compacted clustering method reduce ILBD redundancies and flaws. Crowds situation analysis and regional passenger flow analysis are observed in our tests.
Convergence and divergence situation analysis aims at calculating the customers gather locationdistribution. The precise indoor location information is organized by multi-dimensional features model. After reducing data redundancies and flaws by compacted clustering method, ILBD would be divided into N regions. Model of crowds’ situation analysis are based on customers visit probability

ILBD Convergence & Divergence Situation.
In Fig. 7, we can figure out that the different convergence and divergence situations in three different moments, which are weekday daytime, weekday night and weekend night. Deeper marked regions denote the more crowded convergence situations. In weekday daytime, customers seem more close to restaurants.
Likewise, clothing shops, watch stores, cafés and restaurants are most popular by ILBD data clustering and mining analysis. We also make a contrast with different location based data clustering methods, such as towards fusing uncertain location data from heterogeneous sources from reference [10] and Home location inference from sparse and noisy data from reference [11]. Through large amount of experimental samples, the accuracy of convergence and divergence situation estimations are shown in Fig. 8.
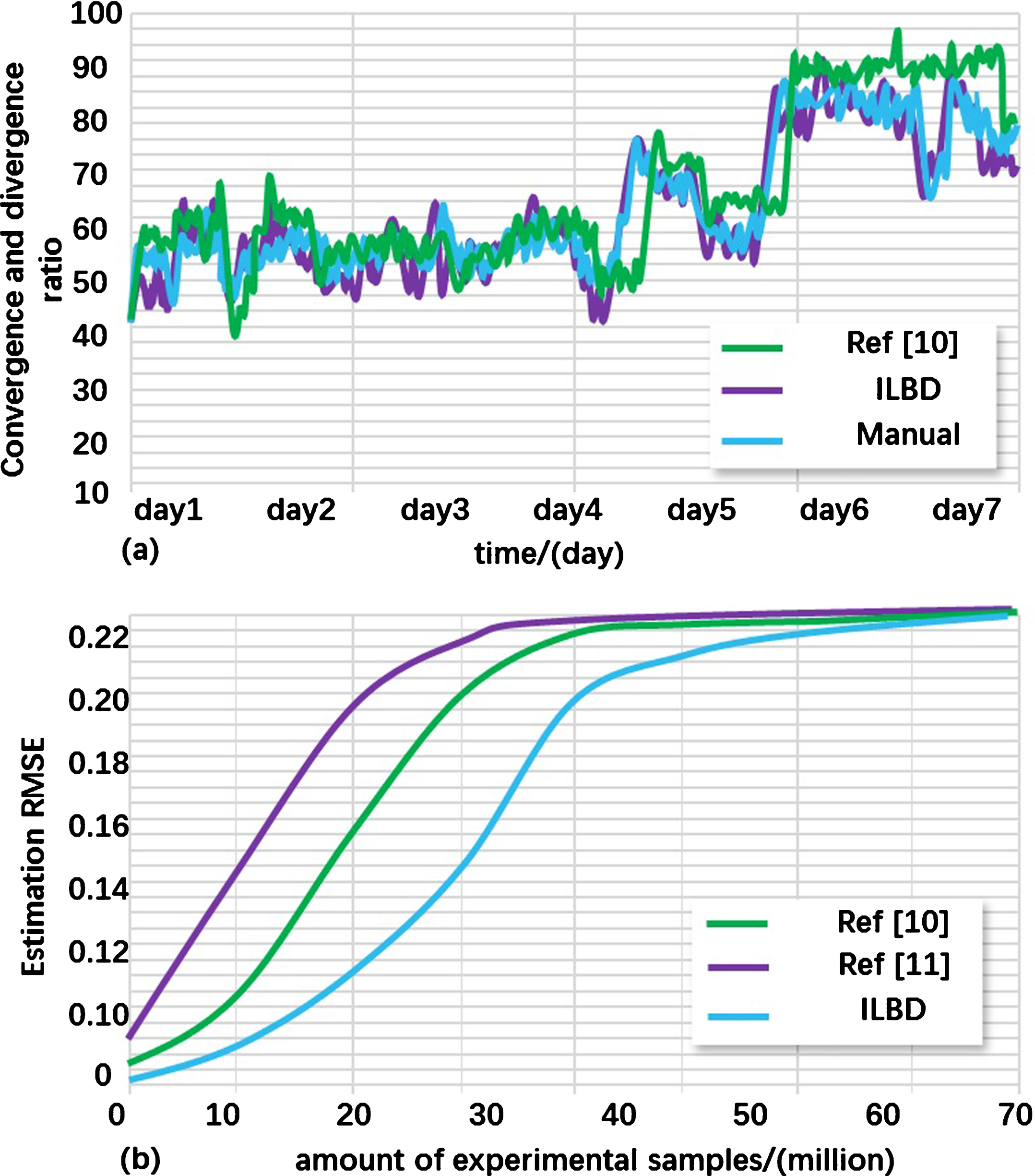
Performance of ILBD convergence & divergence situation estimation.
As Fig. 8(a) shown, convergence and divergence situation are obvious different in different time. We take manual statistics results as the normal value. Under the same moment, multi-dimensional features model for ILBD have better performance of convergence and divergence situation than those of methods in reference [10]. The real-time estimation results by proposed model are more close to the normal value by manual statistics results.
That’s because scalable data representation of multi-dimensional features model for ILBD, which provide with direct customers’ situation to data model transformation to reduce the process delay. Figure 8(b) shows different estimation RMSE (Root Mean Square Error) by different ILBD models and clustering method under different amount of experimental samples. We observe that, at the case of same amount of experimental samples 20 million, the estimation RMSE of proposed compacted clustering method is 0.179, which improve by 36.7% and 52.6% RMSE than that of reference [10] and reference [11]. The reason is that compacted clustering method constructs location ontology and sensations parameters to determine ILBD main affecting elements, which have reduced the data redundancies.
Regional flow analysis aims at getting statistical data to clear analyze regional customers flowing and lingering situations. In Fig. 7, we can also find that deeper marked regions denote longer lingering time in specific region, which means the lower flowing probability of customers flowing. In fact, the shopping and resting areas attract more customers to linger, while they don’t want to stay around the entrances and exits. Contrast with different location based data clustering methods, such as activity purposes using machine learning algorithms from reference [15] and New Spatial Transformation Scheme from reference [20], the estimations experimental data of regional flow analysis would be collected, which are processed by Monte Carlo method, and the root mean square error of subjective speech quality would be analyzed, as Fig. 9 shown.
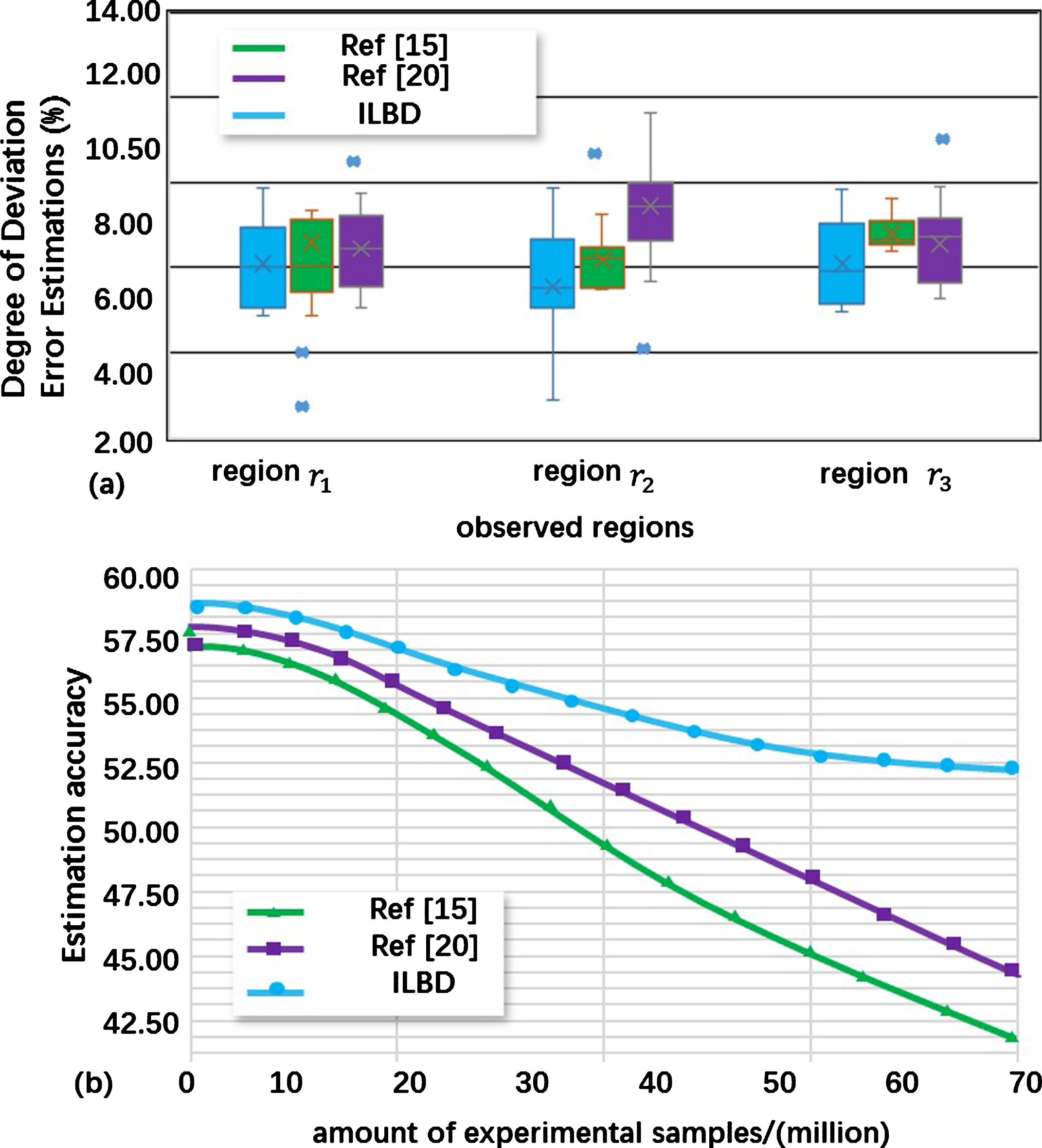
Performance of ILBD regional flow analysis estimation.
In Fig. 9(a), we can see degree of deviation error estimations performance by different data models and clustering methods. Proposed multi-dimensional features model for ILBD have lower deviation error estimations degree than that of reference [15] and reference [20] in region r_1, r_2 and r_3. There are rare deviated location estimations point in ILBD model. That’s because scalable Euclidean extending distance are effective to adjust the influences by subject, attribute, relationship, which improve the representation of complicated ILBD memberships. The estimation accuracy of regional flow analysis is shown in Fig. 9(b). As the increase of amount of experimental samples, estimation accuracy of three methods have performance degradation. Under the same amount of experimental samples, proposed multi-dimensional features model for ILBD have better estimation accuracy. When amount of experimental samples is 40 million, there is 55.61% estimation accuracy with proposed method, which are 12.3% higher than that of reference [20]. The reason is that target function with extending location relationships can reduce ILBD the data flaws.
This paper contributes a novel multi-dimensional features model and compacted clustering for ILBD. Unified ILBD model combines spatial and time features of different scales and states, which employs normalized data frames to pre-process original data. Scalable Euclidean extending distance is designed to characterize relationships between heterogeneous data and represent connection of different dimensions. In order to reduce ILBD redundancies and flaws, compacted clustering method are proposed, which construct location ontology and sensations parameters to determine ILBD main affecting elements, the sluggish elements would be filtered or shrink to decrease the amount of ILBD. The new multi-dimensional features model would be applied in LBS framework. The tests and simulations verify proposed model have a better performance, which improve accuracy of ILBD mining and reduce ILBD redundancies and flaws.
Footnotes
Acknowledgments
This work was supported by the China National support program (Grant No. 2014BAD10B06-03) and the National Natural Science Foundation of China (Grant No. 61271182, 61401040 and 61372110).