
Abstract
To automatic detect and characterize paper impurities with computer vision, we present a novel two parts evaluation procedure with feature representations using Alternating Direction Method of Multipliers (ADMM) sparse codes. The method is based on an offline training step to obtain sparse coefficients and codebooks via learning extracted features with ADMM optimization, followed by an online detection step to use linear SVM classifier to assess defective paper samples from non-defective ones. Our approach bridges the gap between paper impurities evaluation and sparse feature representations, taking advantages of existing ADMM algorithms to handle sparse codes problem. We compare different feature descriptors and sparse code methods to implement the procedure and experimentally validate it on a dataset of 11 paper classes. Experiment results show that the proposed method is competitive and effective in terms of evaluation accuracy and speed.
Introduction
Quality control is an important part of modern industry, and the paper manufacturer is no different to any other manufacturer in this field. In the process of paper production, paper might contain various types of dirt influenced by temperature, humidity and other environmental conditions. In most conditions, the appeared impurities and surface defects need to be avoided immediately to control the quality of paper. The increasing attention to environment-friendly production policies and the rising in the production of recycled paper have made the paper quality control need more and more compelling [1]. Meanwhile, the detection of impure particles can help to find the source of impurities in the manufacturing process, which could be eliminated subsequently. This might reduce the chemicals usage in the bleaching process and have advantaged effects on the environment. Hence, paper manufacturer is more and more concerned about the development of a reliable and quick system to detect such impurities and defects automatically.
With the rapid development of image recognition technologies and hardware production, numbers of defect detection approaches based on compute vision have been proposed in recent years. These defect detection applications now contain a wide range of industrial products, such as fiber [2], textile [3], cold-formed micro-parts [4, 5], metal surface [6] and natural stone [7]. However, the application of computer vision is still not common in the papermaking industry as far as now. In many cases paper impurities evaluation is still conducted by humans with respect to the high detection accuracy but limited by inspection frequency, stability and costs. As a result, automatic computer vision paper impurities detection has a very broad application prospect.
Within paper impurities evaluation field, Bianconi et al. [1] presented a two steps approach based on machine vision to detect impurities. Their algorithm is based on an early classification step to distinguish defective paper parts from non-defective parts, and it followed by a threshold step to separate the impurite part from the background. Torniainen et al. [8] described an equipment to automatic count dirt parts on dry and wet pulp sheets with transmitted light. The accuracy of their method ranged from 75% to 90%. Similarly, Duarte et al. [9] introduced an automatic visual inspection system which aimed at dirt inspection in the pulp and paper manufacturing, and a new hierarchical region oriented segmentation algorithm was used in the method. To improve, Campoy et al. [10] proposed a machine vision system developed for on-line visual paper inspection under the critical lighting requirements of the UNE-ISO 5350-2 standard. Above former researches make a great contribution on the hardware design of the paper impurities inspection, however, the method used in impurities recognition is too simple to ensure high detection accuracy. To solve this problem, we propose a new approach for paper impurities assessing.
In this paper, we proposed a novel feature representations approach based on ADMM sparse codes for paper impurities evaluation. The method mainly divide into two parts: offline training and online detection. In offline training, the features are firstly extracted from the labelled image dataset, and then calculated sparse coefficients and codebooks via learning extracted features with ADMM optimization. In the online detection, the learned linear SVM classifier model used the extracted sparse features to predict whether a paper image belongs to the defect or non-defect class. Our approach bridges the gap between paper impurities evaluation and sparse feature representations, taking advantages of existing ADMM algorithms to handle sparse codes problem. Experiment results show that the proposed method is competitive and effective in terms of evaluation accuracy and computation speed.
The rest of the paper is organized as follows. In Section 2, we introduce the framework of proposed method and how to make linear classification with sparse coding feature representations. Section 3 shows how the codebook and coefficients solved by the ADMM, and gives the detail of optimization process. Section 4 reports experimental results and illustrates the performance of presented method. Finally, a conclusion is made in Section 5.
Problem description
Framework of proposed method
The scheme of proposed paper impurities evaluation method is shown in Fig. 1 which is composed of two major parts. In the offline training part, the method uses datasets of labelled training samples that contain both defect and non-defect paper images to make training. First, the features are extracted from the labelled dataset. Then each image is computed a spatial-pyramid image representation based on sparse codes of extracted features, which will discuss later. Furthermore, our approach uses max-spatial pooling that is more robust to local spatial translations and more biological plausible [11]. Finally, a codebook will be obtained through optimization to help classify in online detection.
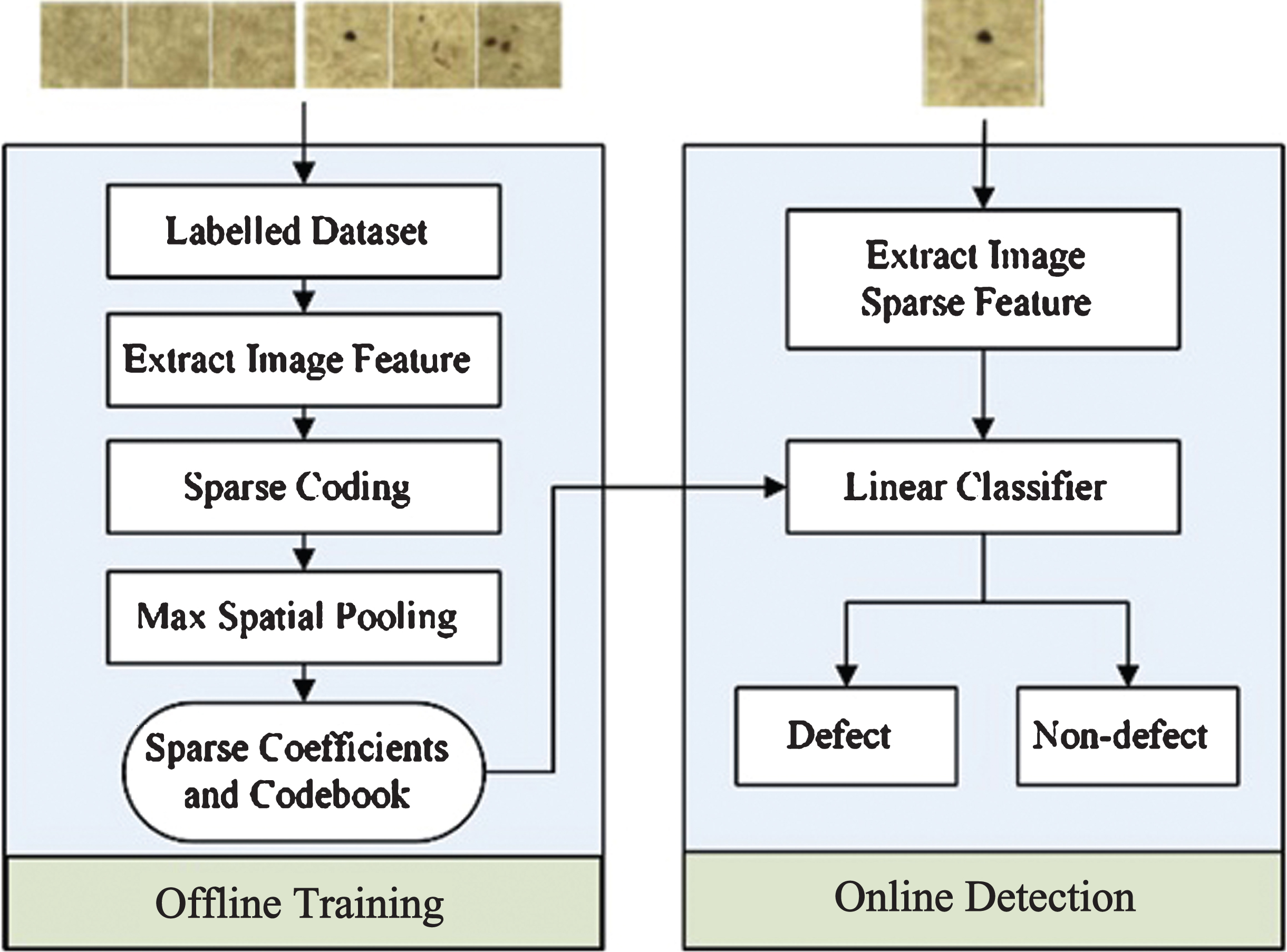
Paper impurities evaluation framework structure.
In the online detection part, we extract sparse features from the images that need to be evaluated firstly. The new sparse features capture more salient properties of visual patterns, and turns out to work surprisingly well with linear classifiers [12]. In the next step, the linear classifier uses all training examples to learn a model via learning procedure. At last, the learned linear classifier model uses the extracted sparse features and predicts whether an image belongs to the defect or non-defect class.
The set of features extracted from original image is important for final classification results. Here, we mainly introduce following four image descriptors which are rotation invariant, since in principle defects can occur at any orientation.
The first feature is the Histograms of Oriented Gradient (HOG) descriptors. The main idea behind HOG which introduced in [13, 14] is that the local appearance and shape of object in an image could be represented by the direction of the contours or the intensity distribution of gradients. The implementation of HOG descriptors can be first obtained by separating the image into small connected parts. Then we calculate a histogram of gradient directions or edge orientations for all pixels in it for each small part. The combination of these computed histograms is the descriptor. HOG method can maintain the invariance to geometric and photometric transformations.
Then, the Scale Invariant Feature Transform (SIFT) descriptors are also adopted in the paper. SIFT descriptor could transform an image into a large collection of local feature vectors, and each of which is invariant to image [15]. Commonly, SIFT features are extracted in four steps. The first step computes the positions of potential interest points through detecting the minima and maxima of a set of Difference of Gaussian filters which are applied at different scales over the image. Next, these positions are refined via abandoning points with low contrast. Then an orientation is given to each key point that depended on local image features. Finally, a local feature descriptor is computed at each key point. Every feature is a vector with 128 dimension identifying the neighborhood around the key point distinctively.
We also get the SIFT and HOG features that computed after Gabor filtering. Gabor filters could measure the response of an input image at different orientations and frequencies, and it can be regarded as two-dimensional sinusoids modulated by a Gaussian envelope [16]. Feature extraction with Gabor filters requires to make the filter bank meet the needs of the specific application domain. After Gabor filtering and normalization, SIFT and HOG features are calculated to represent an image.
Linear SVM classifier using sparse coding
In this part, we will concentrate on how to sparse code the extracted features and use a linear classifier to make distinguish on defect or non-defect papers with linear classifier. Let X be a set of feature descriptors extracted from an image in d-dimension, i.e.
First, we present the problem formulation with sparse coding below. Assume
Then we can define the objective function F as given in Equation (2):
Here we know that the objective function is non-convex if we solve the problem for both
In the next step, we need pool these features across different spatial locations over different spatial scales after obtaining sparse coding features of the image. For any image represented by a set of descriptors, we may compute a single feature vector based on some statistics of the descriptors’ codes [17]. Let
Finally, we can use linear SVM to make image classification. The SVM aims to learn a decision function:
Assuming
Looking on Equation (1), we see that the objective function is not convex if it need to be solved for
Solving for the coefficients
As mentioned above, iterative optimization is slow, so we turn to the ADMM algorithm in order to solve it more efficiently. Separate the variable from minimizing data term and regularizing term via assuming
Then, the augmented Lagrangian function is given:
Hence, the data term
Assume that the convolution is periodic and
The problem for optimizing for the codebook
Then, the augmented Lagrangian function is given:
In order to optimize the codebook with an ADMM solution, we reform the minimization problem which shown in Equation (1) using a heuristic solution. We change the non-degeneracy constraint and regularize the least-squares problem into a Frobenius norm [23]:
Now, we notice that the objective function is a convex function that could be nice solved. Taking the gradient with respect to
Looking for the global minimum, it can be found that:
This heuristic solution is equivalent to the original problem approximately and could give a suitable solution.
In this section, first, we compare the sparse feature represent of SIFT, HOG, Gabor + SIFT and Gabor + HOG with Local Binary Patterns (LBP) [24], Grey-level co-occurrence matrices (GLCM) [25], and statistical Gabor features (S-Gabor) [26] by learning a sparse coding dictionary from dataset images. Then, we also compared the efficiency of ADMM optimization method using SIFT, HOG, Gabor + SIFT and Gabor + HOG feature represents to other popular sparse coding algorithms, such as the feature-sign algorithm and SPAMS toolbox. All experiments were performed by MATLAB with an Intel(R) Core(TM) 2.00 GHz processor. It can be found that our proposed methods are able to speed up the sparse coding algorithm and our implementation is a useful tool for paper impurities evaluation.
Dataset
The dataset used in this work is provided by the Bianconi et al. [1]. The dataset consists of 11 different classes of paper image, and each class containing 2 different types with 48 positive examples (defect) and 48 negative examples (non-defect).
The characteristics of each class are reported in Table 1. These are 1056 examples in total with an image size of 128 pixel×128 pixel each. The images inside a single class are similar but all examples have a varying kinds of defects. The dataset provides labels for each training example to mark the defect. The dataset is obtained through an imaging system using either transmitted light or reflected light: when working by reflected light, the dome is on and the backlight illuminator is off; when operating by transmitted light the reverse occurs. For every class Table 1 reports two images of each of the defect and non-defect paper group. The dataset comprises a wide enough range of inclusions as for density, transparency and type.
The characteristics of each class in the dataset
The characteristics of each class in the dataset
We conducted a series of experiments to detect the robustness and performance of the proposed method. In the first experiment, we made a comparison experiments between feature represent of SIFT, HOG, Gabor + SIFT, Gabor + HOG, LBP, GLCM and S-Gabor with ADMM sparse coding. A common strategy is to divide a dataset in training and validation data. The images of each paper class are randomly split into two non-overlapping sub-sets, one for training and the other for evaluation.
In this experiment, the above feature descriptors were extracted from training images at the beginning. Then we used optimization process which discussed in Section 3.3 to calculate the codebook. Finally, remaining test images were computed to estimate the accuracy of detection. To get a stable accuracy evaluation, we repeat divide the dataset into training and evaluation set K times. In each problem a linear SVM classifier is trained using training set images, and then accuracy is evaluate as the percentage of images of the validation set classified correctly. The overall accuracy (ACU) is the average over the K repeats:
Table 2 demonstrates the accuracy of the different sparse coding feature descriptors for classification. The data show that high classification accuracy can be obtained in SIFT, HOG, Gabor + SIFT, Gabor + HOG cases. However, in LBP, GLCM and S-Gabor cases, the classification results are not ideal. Through the analysis we could found that the feature dimension of SIFT, HOG, Gabor + SIFT, Gabor + HOG is relatively high, and are more than 100 dimension. By contrast, the feature dimension of LBP, GLCM and S-Gabor is very low. It can be seen that the spares coding classification method are not suitable for those low dimension feature descriptors.
Classification accuracy of different sparse coding feature descriptors
Classification accuracy of different sparse coding feature descriptors
Figure 2 shows the comparison results. Gabor + SIFT is the most reliable method. In 1/2 training ratio, it can attain over 97% accuracy, on average. Even in 1/4 training ratio, it can still maintain, on average, over 94% accuracy. Meanwhile, the detection performance of Gabor + HOG, SIFT and HOG descriptors (ranking by precision) are all over 90% accuracy. Low dimension feature descriptor LBP, GLCM and S-Gabor do not work particularly well in this application.
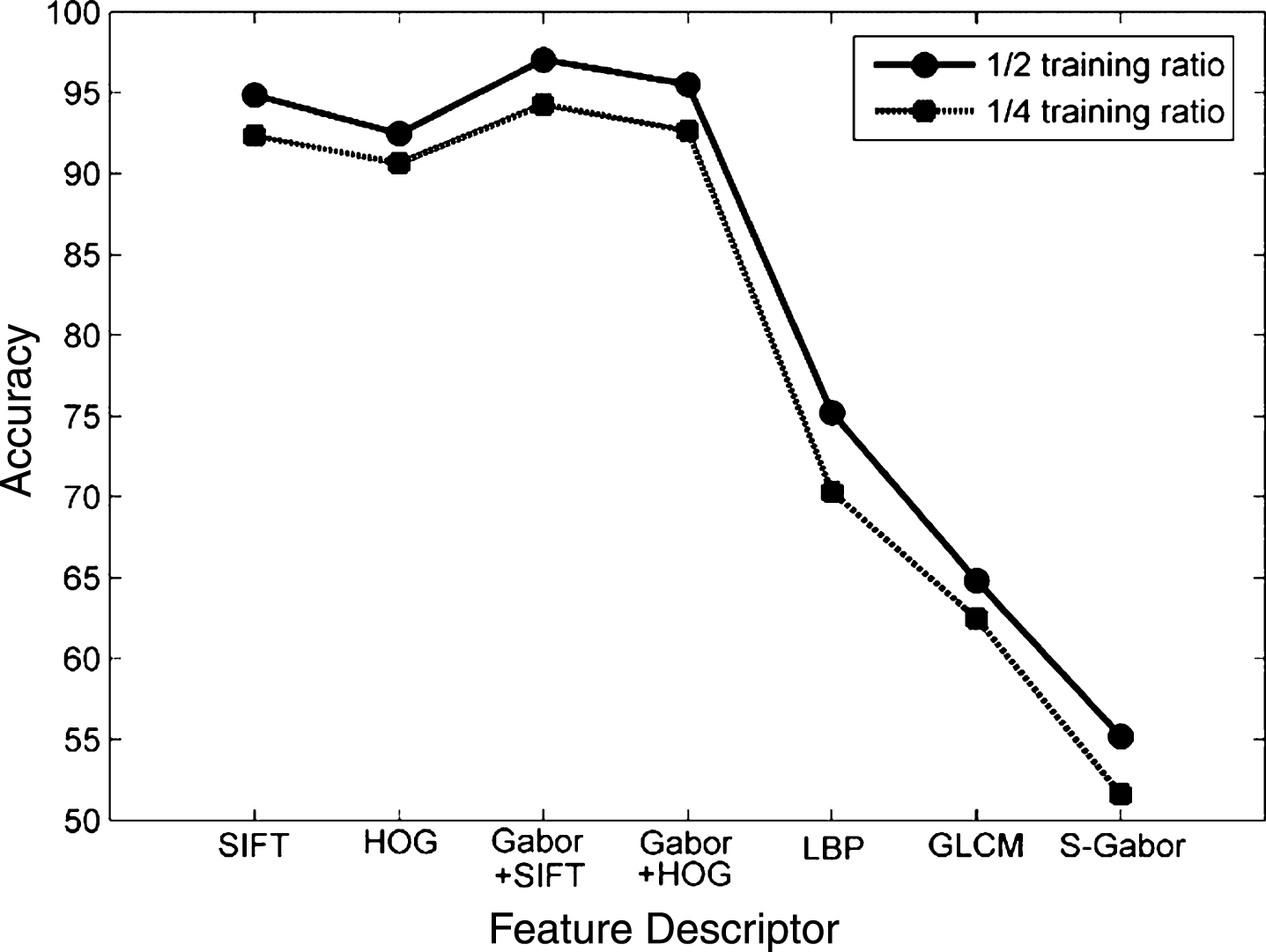
Comparison of different feature descriptors.
In the second experiment, we compared the efficiency of ADMM optimization algorithm with other popular sparse coding algorithms including the feature-sign algorithm and SPAMS toolbox. The feature adopted is Gabor + SIFT feature descriptor, which has shown to have the best classification result in first experiment.
Here, 48 paper images were extracted from each dataset to make training. We run sequential convex optimization for 50 iterations to learn the bases and coefficients. The dimension of the bases was setup as 512. Table 3 shows the computation time results (seconds) in one iteration for learning the dictionary with the same number of bases as the number of input dimensions. In Table 3, evaluation is performed against popular sparse coding algorithms: the feature-sign algorithm [27] and SPAMS toolbox [22].
Computation comparison between ADMM, feature-sign algorithm and SPAMS toolbox
Computation comparison between ADMM, feature-sign algorithm and SPAMS toolbox
The Feature-sign algorithm performs well when the number of bases is small. However, it becomes slower as the number of bases increase. Here, we use its results as the baseline. We can also found that the SPAMS sparse coding tool box works well through experiments, and it is 24 times faster than Feature-sign algorithm. In our method, using ADMM to quickly solve sub-problems of sparse coding enhances the speed of calculating coefficients significantly. The ADMM solver only needs to run about 5 to10 iterations to learn the dictionary efficiently. As can be seen in last row in Table 3, the method of solving for bases using the ADMM is 71 times faster than solving for the primal problem by feature-sign algorithm. Meanwhile, ADMM algorithm is 2.9 times faster than SPAMS algorithm. To summarize, our method performs reasonably well with a simple implementation.
In this paper, we proposed a feature representations approach based on ADMM sparse codes for paper impurities evaluation. The method mainly divide into two parts: offline training and online detection. In offline training, the features are firstly extracted from the labelled dataset, and then each image is computed a spatial-pyramid image representation based on sparse codes of feature representations. Finally, a codebook will be obtained through optimization to help classify in online detection. In the online detection, the learned linear classifier model uses the extracted sparse features and predicts whether an image belongs to the defect or non-defect class. The method uses ADMM algorithm instead of traditional methods to solve sparse coding problem. Two experiments have been conducted to show the accuracy and efficiency of the proposed method. Ongoing work involves applying the proposed method in other defect detection application.