
Abstract
Sometimes, people are prone to describe objects with natural languages including words and sentences, so it is useful to compute with words. However, it is obvious that words mean different to different people. Hence, linguistic information must be transformed into numerical forms before aggregation. To deal with this problem, we propose a novel transforming method based on sample survey. Firstly, through survey questionnaire, we collect the numerical data corresponding to each word. Then, we preprocess the collected data to remove those invalid or unreasonable points. Meanwhile, fuzzy sets are valid to present uncertainty, and the triangular fuzzy sets are the simplest one, which can capture the similarity and dissimilarity to the same word from different people. Therefore, based on means and deviations of the remaining data, we ultimately encode the linguistic terms into triangular fuzzy sets and establish the codebooks. The feasibility and effectiveness are illustrated through an application in the MADM problem about shopping online recommendation from real life.
Introduction
Computing with words (CWW) is a methodology in which the objects of computation are words and propositions drawn from a natural language [1]. More often than not, it is necessary when the available information is too imprecise to justify the use of numbers, and when there is a tolerance for imprecision which can be exploited to obtain tractability, robustness, low solution cost and better rapport with reality [2]. Not only that, even in coming years, computing with words is likely to evolve into a basic methodology in its own right with wide-ranging ramifications on both basic and applied levels [2].
In day-to-day activities, some problems present qualitative aspects that are complex to assess by means of precise numerical values [3]. Whereas, how to transform linguistic variables into the form of numerical values, which can be processed directly by computers, is another challenge to human beings. Fortunately, Zadeh [4] proposes the concept of fuzzy sets which consider the uncertainty in evaluation and judgment. And the use of the fuzzy linguistic approach [5] has provided very good results [3]. Since fuzzy sets can present the complexity of natural languages, then words in the computing with words (CWW) paradigm may be modeled by fuzzy sets [4, 6]. In recent years, some related research has been contributed. Linguistic term set [7–10] and fuzzy information aggregation methods [11, 12] are studied. And Computing with words in decision making is investigated in depth [13–17]. For example, Liu et al. encode words into interval type-2 fuzzy sets using an interval approach [18]. Then, Wu et al. enhance the interval approach for encoding words into interval type-2 fuzzy sets and discussed its convergence analysis [6].
However, in the literatures above, the linguistic variables are transformed into numerical values in some regular ways or in some formula. In fact, through sample survey, it is shown that people correspond the numerical values to linguistic terms irregularly, i.e., the differences of adjacent words from the same linguistic term set might be distinct [19]. For instance, the difference between “very good” and “good” might be less than the difference between “good” and “common”. Therefore, we present a sample survey based method to encode words into fuzzy sets. Specially, through sampling survey, we will establish a codebook, which maps each word in the linguistic term set S to a triangular fuzzy number, which is simple but valid in capturing the uncertainty from words. In the process of data collection, we have found that when expressing a linguistic variable, majority of subjects prefer a single point to an interval. So the method is called point approach (PA), which consists of two parts, the data part and the fuzzy set (FS) part. In the data part, the point data corresponding to each linguistic term are collected from a group of subjects respectively, then, the data are preprocessed with three steps. The first step is bad data processing, through which nonsensical data are removed. The second step is reasonable point processing, which discards those data points that are smaller/more in numbers, but superior/inferior to some others on the semantic. The third step is tolerance limit processing, which removes the numbers that are extremely smaller/more than others. After that, the remaining data are valid and reasonable. Ultimately, some data statistics are computed for the surviving points. In the FS part, the parameters of the triangular fuzzy number are determined using the data statistics, and the derived triangular fuzzy number is mapped to the linguistic term.
To illustrate the feasibility, we provide a real multi-attribute decision making (MADM) problem, in which both the weights and the assessments of the attributes are measured in the form of linguistic terms. Based on the established codebook aforementioned, we can transform the linguistic information into numerical values. Then, the alternatives are ranked according to the rules of fuzzy sets. Ultimately, the decision maker can make the optimal choice.
The remainder of the paper is organized as follows. In Section 2, some basic concepts are reviewed, which include fuzzy sets, triangular fuzzy numbers and the stags of sample survey. In Section 3, we design a survey questionnaire, through which we collect the numerical data which are corresponding to each word. In Section 4, we provide the detail steps of processing the collected data. In Section 5, the words are encoded into triangular fuzzy sets and the codebooks are established. In Section 6, an application in shopping online is provided to illustrate the availability of the proposed method. Finally, Section 7 draws conclusions and discusses some future researches.
Preliminaries
In this section, we introduce some basic concepts, operation rules and methods to be used.
Fuzzy sets and triangular fuzzy numbers
The operation rules of the triangular fuzzy numbers
Suppose that Addition rules:
Subtraction rules:
Multiplicative rules:
Inverse rules:
Division rules:
In the formulas above, all the elements in
The comparison method of the triangular fuzzy numbers
Suppose that
The comparison method [20] is defined as: If
Linguistic term sets
Zadeh [5] presented the concept of linguistic variables whose values are words or sentences in a natural language instead of numbers. The fuzzy linguistic approach represents qualitative suspects as linguistic values, which has successfully been applied to deal with decision making problems [22]. It is very important to choose appropriate way to describe linguistic term sets and their semantics.
On one side, the same word does not always signify the same thing to different persons. On the other side, there must be some similarity in the same word. That means the words include both similarity and dissimilarity to different people synchronously. For instance, in a scale of 0–10, “good” may be corresponding to “7.5” to an optimist, while corresponding to “8.2” to a pessimist. However, numerical values mapping to the word “good” from different people should be near to a certain number (for example, “8”).
In the literatures, linguistic variables are mapped into numerical values with some formulas in a regular way [23, 24]. For example, Rodriguez demonstrated a set of seven linguistic terms by means of an ordered structure approach. It is shown in Fig. 1 as follows: S = { s0, s1, s2, s3, s4, s5, s6 } = {nothing, very low, low, medium, high, veryhigh, perfect}.

The membership functions of the linguistic terms.
In Fig. 1, we can conclude that the degrees of dispersion of all the terms are the same, and the membership functions of the linguistic terms change uniformly from the lowest one “s0” to the highest one “s6”, i.e., the distinction between central points of adjoining linguistic terms is identical. However, it does not conform to the actual rating in decision making. When mapping the linguistic terms to numerical values, majority of people may appear evident diversity in the degrees of dispersion from different terms, and the membership functions of the linguistic terms change irregularly.
Therefore, in order to transform linguistic terms into numerical values more accurately, we present a novel method based on sample survey.
In order to translate the linguistic information into numerical values, we can establish a codebook, which maps words to fuzzy sets. Firstly, we design a sample survey through the questionnaire and print 40 copies, then distribute them to 40 subjects randomly. We did the sample survey at a classroom and a dining room in Southeast University, Nanjing city, China. The initial data are collected from 40 subjects After the data are collected, the codebook S can be established.
Survey design and questionnaire
The objective of the survey is to collect the point data corresponding to each word in the linguistic term sets. The subjects of the survey are undergraduates in Southeast University. We design a proper questionnaire shown in Appendix A and distribute it to 40 subjects.
It is notable that, in order to avoid the effect between the linguistic terms as far as possible, we arrange them randomly as far as possible.
Data collecting
At first, the scale of 0–10 is established and a vocabulary of words is created that is convinced to cover the entire scale, then the methodology for collecting point data from a group of subjects consists of two steps: (1) randomize the words, and (2) survey a group of subjects to provide point data for the words on the scale.
Words need to be randomized so that subjects will not correlate their points from one word to the next. For each word in the application-dependent encoding vocabulary, a group of n subjects are asked the following question:
On a scale of 0–10, what is the number that you associate to the word ____ ?
It is important to note that the number can be decimals between two integers. For example, the number of “Very good” might be 8.9.
Thus n data points a(i) (i = 1, 2, …, n) are collected from these subjects for the word through a survey questionnaire shown above. They are then preprocessed in the following step.
Data processing
In this section, we provide the detail data processing, which can remove those unreliable points.
Initial data display and rearrangement
After the data are collected through the survey questionnaire, they must be tabulated for statistical analysis. We construct a table for each group.
In the following, for convenience to present, we take the first group, for example, other two group data can be processed similarly.
Firstly, the data are rearranged from worst to best. After that, for the first group, the linguistic terms are respectively: Extremely bad, Very bad, Bad, Common, Good, Very good, Extremely good. They are processed and analyzed in following steps.
Data processing
Processing the n points a(i) (i = 1, 2, …, n) consists of three stages, and details are provided for each of these stages in the following.
(1) Bad data processing. Such processing removes nonsensical results (some subjects do not take a survey seriously and so provide useless results). Only the data with 0 ≤ a(i) ≤ 10 (i = 1, 2, …, n) are accepted; others are rejected.
After bad data processing, there will be n′ ≤ n remaining data points.
(2) Reasonable point processing: Reasonable point processing is performed on the remaining n′ a(i), i.e. for the two words s
j
and s
k
(j < k), only the points satisfying
After reasonable point processing, we discard those data points that are exceeding some others in linguistic essence, but smaller in numbers. And there will be n″ ≤ n′ remaining points shown in Appendix A, for which the following data statistics are then computed: m a and s a (sample mean and standard deviation of the n″ remaining points).
(3) Tolerance limit processing. Note that the point data have been collected from more than 30 subjects who are chosen independently, so we can assume the statistics to be approximately normal distributed. Then, tolerance limit processing is performed on the remaining n″ points a(i), and only points satisfying a(i)ɛ [m a - ks a , m a + ks a ] are kept, where the tolerance factor k is determined so that one can assert with 100 (1 - γ)% confidence that the given limits contain at least the proportion 1 - α of the measurements [25]. For example, when data have been collected from 30 subjects, using k = 2.549 means one can be 95% confident that 95% of the 30 data fall in the interval [m a - ks a , m a + ks a ]. The parameter k decreases with the increase of the remaining data number. Meanwhile, the remaining data is more than 30, so the parameter k is approximate to 2. For convenience, we assume k = 2 in this paper.
Finally, after the step of tolerance limit processing there will be m ≤ n″ remaining data points.
Obviously, through data processing, the surviving data are reliable and valid, thus they can be applied to encode words into numerical values.
Encoding words into triangular fuzzy sets—codebooks
In this section, we establish the codebooks, which map linguistic term sets to triangular fuzzy sets.
The statistics computing
The surviving m data are analyzed sequentially. For each word, we compute the following statistics: m
a
and s
a
(sample mean and standard deviation of the m remaining points), that are shown as Table 1. For the term “Very good”, we have collected 39 numbers, which are shown in Appendix A. Nevertheless, there might be some unreasonable points. For instance, the subject 7 corresponds “10” to “Good ”, but “8” to “Very good”, which are shown in Appendix A, obviously, it is not reasonable, so both of the numbers are removed. After that, for the remaining 35 numbers, we obtain the mean
The first group remaining data points and their statistics
The first group remaining data points and their statistics
Intuitively, the mean denotes the central point of numbers corresponding to some term. While, the standard deviation denotes the dispersion of the numbers. Therefore, the mean and the standard deviation imply similarity and dissimilarity of the same term to different people, respectively.
For each word, based on the statistics, the m surviving points a(i) (i = 1, 2, ⋯ , m) are mapped to the parameters of a triangular fuzzy number
For the term “Very good”, a L = 8.94 - 2 ×0.5 = 7.94, a M = 8.94 and a U = 8.94 + 2 ×0.5 = 9.94, respectively. Thus, the term “Very good” is transformed to the triangular fuzzy number (7.94, 8.94, 9.94). Other terms can be transformed similarly. Therefore, we can establish the first codebook S1 shown as Table 2. The membership functions of the linguistic terms in codebook S1 are illustrated in Fig. 2.
The first codebook S1
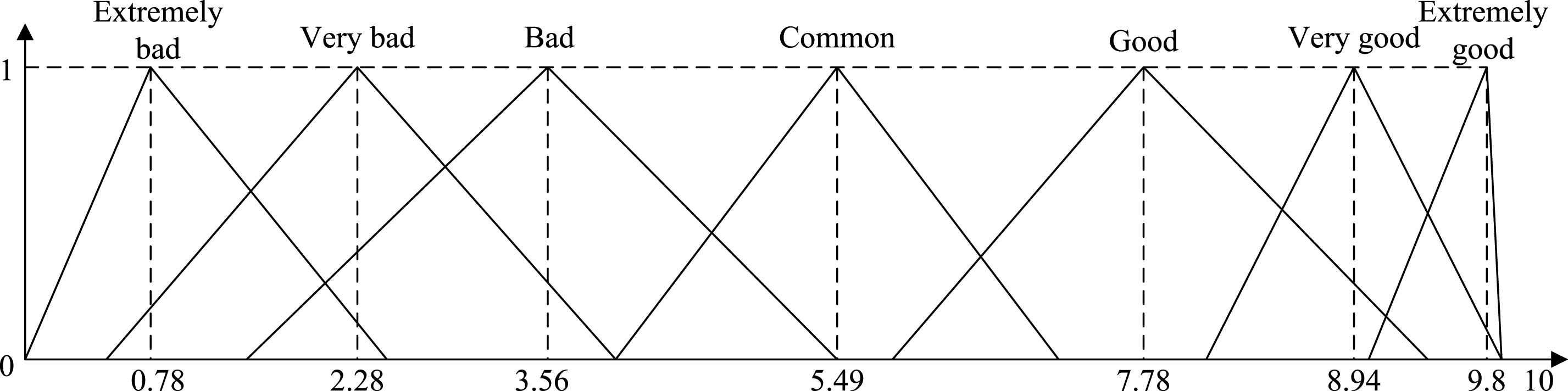
The membership functions of the linguistic terms in codebook S1.
In Fig. 2, the horizontal axis x denotes the numerical values on the scale 0–10 corresponding to each terms in the codebook S1, while vertical axis denotes the membership degree of the linguistic terms. The number in the x-axis corresponds to the numerical center point of each linguistic term.
Similarly, we can obtain other codebooks S2 and S3, which are shown in Tables 3, 4, respectively.
The second codebook S2
The third codebook S3
The membership functions of the terms in the codebook S2 and S3 are illustrated in Figs. 3 and 4, respectively.

The membership functions of the linguistic terms in codebook S2.
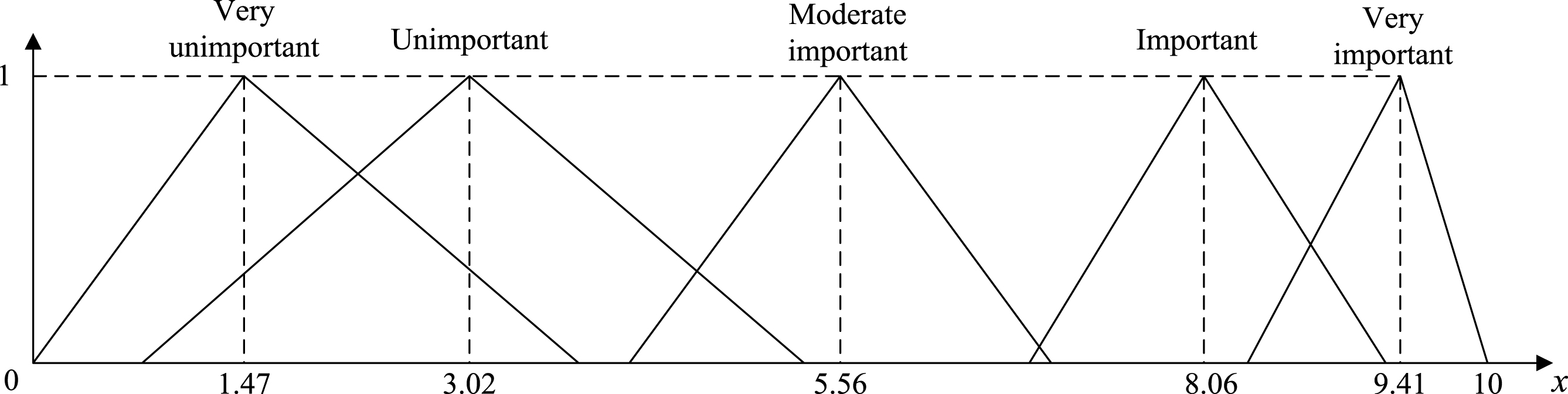
The membership functions of the linguistic terms in codebook S3.
In the traditional methods, linguistic variables are mapped into numerical values with some formulas in a regular way [23, 24]. However, in this paper, based on sample survey, we establish codebooks, which map words in the linguistic term set to triangular fuzzy numbers. The translating process consists of two parts, the data part and the fuzzy set (FS) part. In the data part, the data points corresponding to the linguistic terms are collected from a group of subjects respectively. Then, the data are preprocessed in order to guarantee that the remaining data are valid and reasonable. In the FS part, for the surviving points, the means and standard deviations are computed. Then the parameters of the triangular fuzzy number are determined based on the data statistics, and the derived triangular fuzzy numbers are mapped to the linguistic terms. The proposed method has some characteristics or advantages. The membership functions of the terms in the codebooks change irregularly, i.e., the distinction between central points of adjoining linguistic terms varies widely. The degrees of dispersion from the terms are distinct evidently. The dispersion degrees imply the uncertainty of the terms. Intuitively, different terms imply different uncertainty, even though they are from the same person. Except the first one and the last one in the linguistic term sets, the membership functions of the terms in the codebooks are symmetrical. The response values are between 0 and 10.
The characteristic can be illustrated via special examples in the codebook S1. For instance, the numerical values corresponding to the term “Common” focus on the near to the number “5.49”, similarly, “Extremely bad” corresponds to “0.78”, “Very bad” corresponds to “2.28”, “Bad” corresponds to “3.56”, “Good” corresponds to “7.78”, “Very good” corresponds to “8.94” and “Extremely good” corresponds to “9.8”,respectively. Obviously, the gaps between center points of the adjacent terms are varied. Specifically, the first three terms “Extremely bad” “Very bad” and “Bad” are relatively close to each other, meanwhile, the last three terms “Good” “Very good” and “Extremely good” are also relatively close to each other. However, the term “Common” is relatively far to its both neighbors. Intuitively, that is reasonable. In fact, the first three terms belong to the broad range of the term “Bad”, the difference between them is only the different extent, that could be seen as quantitative changes. Similarly, the last three terms belong to the broad range of the term “Good”. Nevertheless, it is qualitative changes from “Bad” to “Common” or from “Common” to “Good”, so the gap is much larger than the former.
So the proposed method seems to be more in line with the real world.
An application in E-commerce recommendation
Recently, it becomes more and more popular to go shopping online in China. We are so familiar to some online shopping websites, which include, www.amazon.com, www.jd.com, www.taobao.com and so on. On November 11, 2014, or called “singles day” in China, which is online shopping spree, all the e-commerce companies have harvested greatly. Especially, China’s largest Alibaba Group Holding Ltd broke a record when sales exceeded 10 billion Yuan ($1.6 billion) within 40 minutes after the start of its “11/11” online shopping spree, and hit a one-day sales record of 57.1 billion Yuan ($9.3 billion). To seize the foreign market, the shopping websites provide the services for shopping overseas, which attract much attention, especially from white-collar employees. www.amazon.com possesses the apparent advantages over the oversea shopping business due to its rich experience and reliable logistics. Overall, Black Friday sales declined about 11 percent compared with 2013, according to the National Retail Federation (NRF). Online sales, however, were up 14.3 percent, according to IBM Digital Analytics Benchmark.
Now, a sports enthusiast from the undergraduates plans to purchase a pair of sneakers on www.amazon.com. By primary election, there are still four remaining alternatives, which are a1 (Adidas: isolation low G66010), a2 (Nike: prime hype DF winterized 684892) a3 (Puma: trinomic XS 850 plus 35614306) and a4 (Mizuno: wave inspire 10 J1GC144402), respectively. He concerns three attributes: c1 (price), c2 (design) and c3 (evaluation), where price includes commodity price itself and the express fees, design includes color and trade dress, and evaluation includes assessments from product quality, performance and service. And he prefers to rate the attributes and their importance in natural languages instead of numerical values. His preferences to the alternatives with respect to different attributes are shown as Table 5, which can be regarded as linguistic decision making matrix (denoted by
Linguistic decision making matrix
Linguistic decision making matrix
Then, which one is the optimal choice? It can be considered as the MADM problem [26] with linguistic evaluations. We attempt to help him choose the most proper alternative. The decision making steps are follows.
For convenience, we denote linguistic decision making matrix with
For example, the element
Fuzzy decision making matrix
Though the attribute c1(price) is cost variable, which means the more, the inferior. Thus, the corresponding fuzzy numbers should be standardized so as to establish the normal fuzzy matrix
Similarly, we can obtain:
Nevertheless, the attributes c2 (design) and c3 (evaluation) are profit variables, so the normal values are same as the fuzzy numbers, i.e.,
Normal decision making matrix
The weighted value of the alternative a
i
is computed with the formula:
For example,
The weighted values of the alternative a2, a3 and a4 can be achieved similarly, which are shown in Table 8.
The decision result of the alternatives
Firstly, the defuzzified value of alternative a
i
is computed with the formula:
For example,
The defuzzified values of other alternatives can be acquired similarly, which are shown in Table 8.
The decision result is: a2 ≻ a1 ≻ a4 ≻ a3. So the alternative a2 (Nike: prime hype DF winterized 684892) is the optimal choice.
In this problem, all the attributes (c1 (price), c2 (design), c3 (evaluation)) are rated in linguistic terms, which can be transformed into fuzzy numbers based on the codebook. The codebook is established through sample survey. Then, based on the rules of fuzzy sets, the linguistic information is computed and aggregated. Ultimately, the alternatives are ranked according to the defuzzified values.
The proposed method transforms the linguistic terms into fuzzy numbers through actual survey. So the process of decision making seems to be more consistent with real behavior.
Notably, the sample survey is conducted in the campus, and subjects are undergraduates. So the obtained codebooks are suitable to the students. In fact, the sport enthusiast in the example is a student. Hence, the results are reasonable.
In this paper, we have provided a sample survey based method to transform words into numerical values, and established the codebooks, which map linguistic terms to fuzzy sets. Therefore, based on the rules of fuzzy sets, the natural language information can be computed and aggregated. The availability is illustrated through a real application in shopping online.
The novelties and/or characteristics in this paper are as follows. The weights and the assessments of the attributes are all represented with linguistic variables. In some cases, it is difficult to assess the attributes as well as the weights, thus, we can adopt natural languages, which are convenient and friendly to the decision makers. Even for the unfamiliar domain, people can provide their own assessments. The linguistic terms are transformed into numerical values based on sample survey, instead of some regular formula. In real evaluation, the words from the same linguistic term set change irregularly from worst to best, i.e., the differences between two adjacent words might be distinct. And the deviation degree of numerical values corresponding to each word might be distinct too. So the proposed transforming method is more consistent with real world in decision making.
In the future research, we will continue working on linguistic decision making problems, and applied the developed method to some other domains such as industrial structure evaluation [27], recommendation systems, behavioral decision making and so on.
Footnotes
Appendix A
Dear friends:
Good morning!
Thank you for your help! In order to transform words information to numerical values, we make the survey. Please answer the following questions.
Important to note that: ➀ The more the number is, the superior it means; ➁ The number can be decimals.
To you, on a scale of 0–10, what is the number that corresponds to the word good ?
Answer: ___.
Similarly, bad corresponds to ___; common corresponds to ___; very good corresponds to ___; extremely bad corresponds to ___; extremely good corresponds to ___; very bad corresponds to ___.
Similarly again, very high corresponds to ___; low corresponds to ___; somewhat high corresponds to ___; moderate corresponds to ___; somewhat low corresponds to ___; extremely high corresponds to ___; extremely low corresponds to ___; high corresponds to ___; very low corresponds to ___.
Similarly again, important corresponds to ___; very unimportant corresponds to ___; moderate important corresponds to ___; unimportant corresponds to ___; very important corresponds to ___.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (NSFC) (71771002).