
Abstract
Intrusion detection is an important requirement in wireless mesh network and the intrusion detection system (IDS) provides security by monitoring data traffic in real time. This work proposes support vector machine (SVM) classifier to identify the intrusion in the network. The traffic data collected from the wireless mesh network (WMN) is given as input to the SVM. The irrelevant and redundant input variables increase the complexity of designing IDS and may degrade its performance. Hence, feature selection techniques, which select the relevant features from the original input is essential to improve the performance of IDS in WMN. In this work, a hybrid genetic algorithm (GA) and mutual information (MI) based feature selection technique is proposed for IDS. The performance of IDS with the proposed feature selection technique is analyzed with IDS having mutual information, genetic algorithm and GA+MI based feature selection techniques using ADFA-LD dataset. Experimental results have demonstrated the effectiveness of proposed intrusion detection system with hybrid feature selection technique in wireless mesh network. The superiority of SVM classifier with hybrid feature selection technique is also verified by comparing with artificial neural network classifier.
Introduction
The high speed data transmissions and cost-effectiveness have made the wireless mesh network as a suitable technology for various applications like smart grid, Internet of Things (IoT), etc [1]. The multi-hop nature of WMN increases the probability of attacks like denial of service, selective forwarding, worm-hole, sink-hole, black-hole, etc in the network. Intrusion detection system provides security against these attacks effectively. In WMN, intrusion detection algorithms are implemented in different fashions such as optimized monitoring functions [2], energy efficient monitoring [3], firewall [4], etc. Most of the available intrusion detection system (IDS) falls under the third category in which intrusions are detected by classifying traffic data into normal and attack data [5]. In some cases, combinations of optimal monitoring of traffic and energy level of node simultaneously have been applied as in [6]. Some of the traffic aware IDS like FADE [7] detects greyhole attacks using the acknowledgement information of transmitted packets. However, the accurate traffic knowledge may not be available in most of the networks. In that case, a traffic agnostic based approach like RAPID [8] is used to detect intrusions. It uses the link coverage knowledge of WMN to analyze traffic in centralized and distributed fashion.
Machine learning algorithms like learning automata [9], SVM [10], etc are used to detect intrusions by learning the traffic flow information of WMN. The major issue in the implementation of machine learning technique based IDS in WMN is dimensionality problem. The requirement of large amount of energy to deal with the dimensionality affects the efficiency of IDS in WMN. Another major drawback in the implementation of IDS with large number of features is the requirement of large execution time [11]. Hence, the large numbers of irrelevant features have to be removed from the traffic data for getting better detection accuracy.
Dimensionality reduction technique provides solution to that problem by identifying informative features and giving it as input to IDS. Feature extraction and feature selection are the two types of dimensionality reduction techniques. In feature extraction, the input variables are transformed into derived values which can be used for intrusion detection purpose [12]. It can be sub classified as linear methods like independent component analysis [13], partial least squares [14], principal component analyses [15], etc and non-linear methods like ensemble localized manifold [16], etc based on the implementation mechanism. In most of the real world applications, the features generated by feature extraction technique have no clear physical meaning and are very hard to interpret by classifier [17].
Feature selection technique is simple and easy to implement compared to the former technique. It is defined as the selection of ‘M’ optimal subset of features from the original feature set for increasing the performance of machine learning models [18]. It is generally classified as filter and wrapper method. Filter method select the subset of features by evaluating the mutual relationship between features during output prediction, whereas, wrapper method uses predictive models to select the optimal subset of features.
Mutual Information is one of the widely used filter method based feature selection technique. It selects the informative features based on the relations between the features with corresponding output. It has difficulty during implementation in some real world applications, so an equivalent form, Minimum redundancy maximum relevancy (mRmR) is used to implement MI. In [19], mRmR based feature selection technique is proposed to select the informative features without considering the properties of individual class. Several other methods like sparse kernel [20], SVM weight vector [21], etc are proposed to select the optimal features from the dataset. Most of the feature selection methods belong to the category of wrapper method in which classifiers like random forest [22], SVM [23], etc are used to select the optimized subset of features.
Recently, evolutionary techniques like GA and particle swarm optimization [24] have been applied to select the most informative features from the original features. Both filter and wrapper methods have merits and demerits and it is desirable to embed both wrapper and filter approach to get an effective feature selection algorithm. In the proposed work, a novel IDS is designed for WMN using a hybrid feature selection technique based on genetic algorithm and mutual information.
Intrusion detection in wireless mesh network
Intrusion detection is the process of identifying the occurrence of different attacks in a network by analyzing the features of network traffic for providing security to a network. WMN has advanced routing protocols for providing guaranteed communication with end devices. The attacks on routing protocols could damage the entire communication network. Thus the routing based impersonation attacks like black hole, grey hole, etc are frequently used by attackers against WMN. Traffic based IDS efficiently detects these attacks by analyzing the traffic data and routing information.
The IDS in WMN is categorized into cooperative IDS, monitored IDS and traffic aware IDS. In cooperative IDS, each node has some functions to detect intrusions and the detected information is shared periodically [25]. This mechanism requires limited energy compared to other approaches but also has low accuracy rate in the changing dynamic environment. In the monitored IDS, a small group of nodes are selected for monitoring the suspicious part of the network [26]. Large numbers of nodes are required to monitor some of the attacks like selective forwarding attack. Recently, traffic aware IDS gets much importance that monitors the entire communication links by placing IDS on WMN nodes along the routing path instead of IDS at particular nodes. The traffic aware IDS has good accuracy in attack detection because individual nodes monitor the network traffic based on traffic pattern.
The lack of single vantage point and limited resources of nodes requires an advanced intrusion detection system for monitoring the network traffic in WMN. The classifiers like SVM, ANN, etc support the IDS in the classification of traffic data as normal and attack data. The IDS are classified as anomaly and misuse based detection technique based on classifier training with normal and attack data respectively. Node failures and variation in link quality by noisy environment are some of the factors affecting the detection accuracy of intrusion detection system [27]. Sometimes missing and inclusion of some irrelevant features also affect the classification accuracy of traffic based IDS in a resource constraint WMN. The selection of informative features has various advantages like reducing false positive rate, cost effectiveness and energy conservation of WMN. Hence in the proposed work, the feature selection technique is applied to identify the relevant features, and the selected features are given to the IDS.
Proposed technique for intrusion detection
In WMN, attacks are of different types and multi attack detection classifier is required in most cases. SVM classifier can accurately detect multiple attacks and is suitable for WMN IDS [28]. The development of SVM has two stages, training and testing. The collected data is divided into training and testing data. Training data is used to train the SVM and the test data is used to evaluate the performance of the trained SVM.
Figure 1 shows the block diagram representation of the training stage of the SVM based IDS. Classifiers have low accuracy rate due to redundant and irrelevant features generated by the applications. Hence, feature selection techniques are necessary for selecting the informative features for accurate detection of attacks. In this work, the informative features are selected using hybrid GA and MI based feature selection technique and are used to train the SVM classifier. Feature selection techniques acts as a backbone for this kind of application because most of the features look like similar and some features affect the performance of classifier.
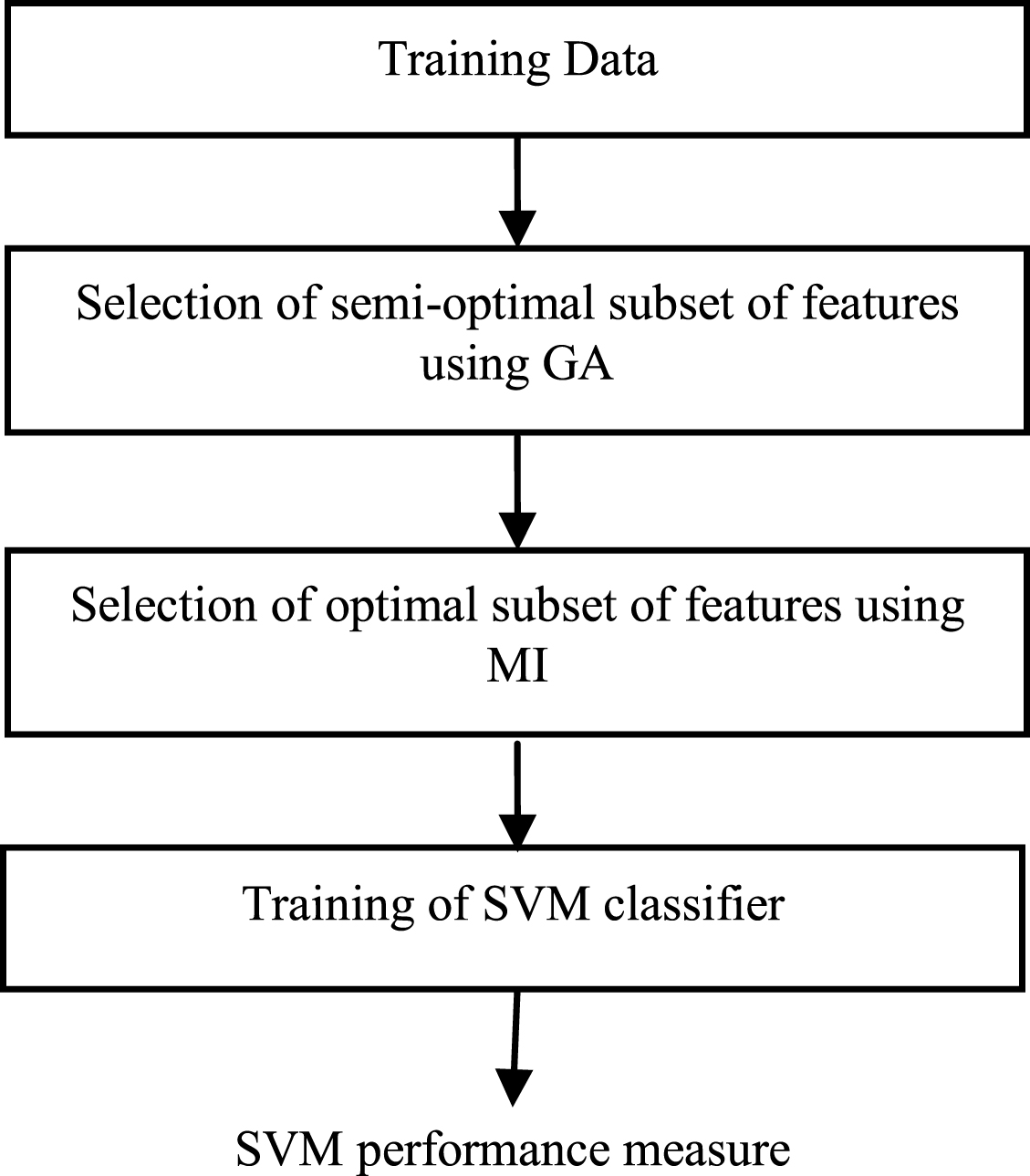
Training stage of the SVM based IDS.
The SVM classifier is trained with the optimal subset of features selected using hybrid GA and MI technique and is evaluated with testing data before being implemented in real environment. The details of the SVM classifier and feature selection technique are presented in the subsequent sections.
SVM classifier is a supervised learning algorithm based classifier that is designed with the basic idea of separating class with a straight line given by the Equation (1),
The mapping operation is carried out by ‘kernel’ function and choosing different kernel functions will produce different convergence rate. Linear, Quadratic, Polynomial, Multilayer Perceptron (MLP) and Gaussian are some of the widely used kernel functions in SVM classifier. The linear kernel function has low accuracy in the classification of complex datasets where some data cannot be separated linearly. So, the other kernel functions are used in most cases. The architecture of SVM is shown in Fig. 2, where X is the input data having ‘n’ number of features and is given to ‘m’ kernel functions. In this work, MLP kernel function [30] is used to map the input data into kernel space for finding the maximum margin hyperplane. The MLP kernel function of SVM has number of hidden layers that focus on the minimization of error functions with the help of support vector co-efficient ‘k’ and bias value ‘θ’. The kernel function maps the input data into the default scale value of [+1, –1]. The training of hidden layers for the input data Xi is represented in Equation (2),
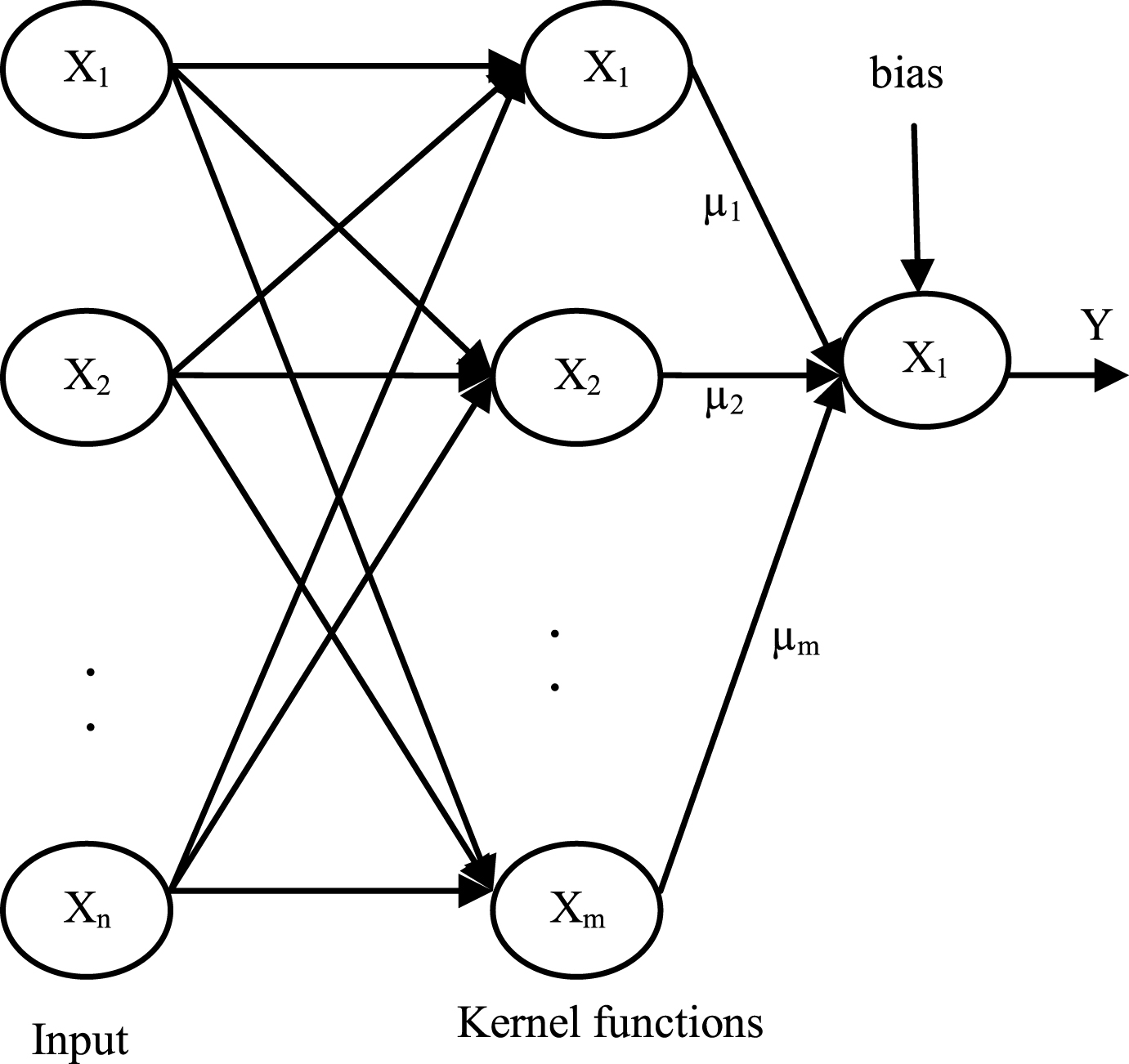
SVM Architecture.
The minimization of error tunes the hidden layer margin which is reflected in maximal margin of hyperplane. The training is repeated till each output data are correctly matched. In general, the separable line with global margin (2/||w||) is selected by most of the classifiers for classifying data with maximum accuracy [31].
SVM classifier is generally designed from known labeled training data and its accuracy is analyzed using testing data. The Multiclass SVM is proved to be as accurate in the classification of multiple classes than any other technique. The number of classifiers used in Multiclass SVM depends on the number of classes in the dataset. In this model each classifier is trained by the dataset with consideration of classifier’s corresponding class as ‘1’ and all other classes as ‘0’. The classifier trained with such kind of classification dataset produces high accuracy. The individual classifier output is noted for all dataset and the final prediction is based on the confidence value for each class. Mathematically it is represented as,
SVM classifier has good capability on dealing with nonlinear data that makes it as most suitable for intrusion detection systems [32]. SVM based IDS has excellent performance by implementing in various orders like distributed [26, 32], hierarchical [33], etc. The usage of SVM in IDS requires extensive memory because of large dimensionality in network datasets and also affects the accurate detection ratio.
The non relevant and redundant features decrease the accuracy of intrusion detection classifier along with increasing time and space complexity. Thus the selection of optimal features is essential to detect intrusions efficiently. A novel hybrid GA and MI based feature selection technique is used in this work to reduce the dimensionality and select the optimal subset of features for an intrusion detection system as shown in Fig. 3.
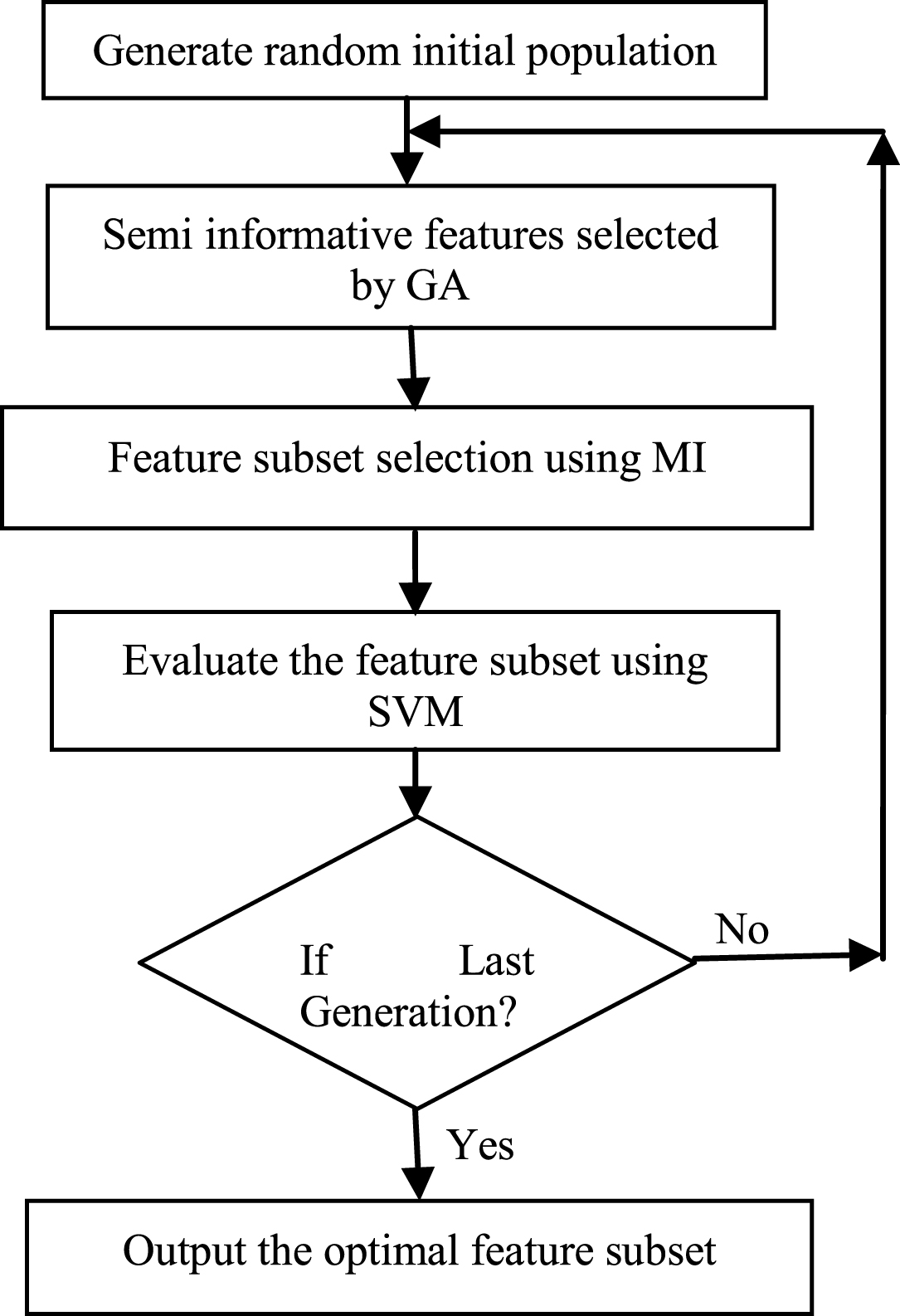
Proposed feature selection technique.
In this paper, the proposed IDS with feature selection technique uses accuracy rate of classifier as the objective. In the proposed feature selection technique, Genetic algorithm [34] initially generates the random chromosome of population from original features of the data and selects the semi informative features. Once the semi informative features are selected, the fitness level of each chromosome for that generation is calculated with the help of Mutual Information (MI) technique [35] and SVM classifier. The features are given as input to MI which selects features with high mutual information value from the individuals in the selected population. The mutual information is calculated as follows:
Where hy is entropy, Ny is number of classes included in the training data and P(yj) is the probability of individual class.
Where PYX = P (Yj/Xi) . log P (Yj/Xi) , h(y/x) is conditional entropy value, Nx is number of input variable and P (Yj/Xi) is the probability of individual input value to the corresponding output and P (Xi) is the probability of possible values in the input features.
Finally the mutual information value I(Y;X) of each feature is calculated by Equation (5). The features with high mutual information value will have high impact on intrusion detection that is marked as informative features. If an application has large number of features with low mutual information value those features will not have major impact on the accuracy of classifier and can be removed as non informative features.
The implementation mechanisms generally followed in the MI selection process is by selecting the features with high mutual information value as informative features. In this work, the top ‘m’ number of informative features is going to be selected by the proposed technique from a network data. The selected features are given as input to SVM classifier for the classification of normal and attack data. The accuracy of the classifier is used to evaluate the individuals in the population. After the fitness of all individuals is evaluated, the top chromosomes in the population are selected as parent chromosomes for next generation for further optimization process. In this work, tournament based selection technique is used to select the most optimal solutions from the population. After selecting the parent chromosomes for next generation, they will undergo crossover and mutation operations. In crossover operation, some blocks of the chromosomes are randomly swapped and in the mutation operation some bits of chromosomes are shifted from 1 to 0 or 0 to 1 based on the crossover and mutation rate respectively. The crossover operator helps to generate the new offspring for each generation whereas the mutation operator helps to avoid the problem from stucking at local minima. This process is repeated till the specified number of generations is reached.
The proposed hybrid feature selection technique combines the merits of both wrapper and filter method based feature selection techniques. The main features of the proposed method are, The usage of filter method based on mutual information helps to avoid the trapping of Generic algorithm based wrapper method at local minima. A good subset of features reduces the computational effort of training the classifier by removing less informative features. In the proposed hybrid technique, the most informative features are only selected because MI selects the features from the optimal features selected by GA. The optimal features selected by the proposed technique increase the correct classification ratio by reducing the error rate of classifier.
This section presents the details of the development of SVM-based IDS using ADFA-LD dataset. Most of the attacks in wireless mesh network are similar to this dataset and is most suitable to analyze the IDS of wireless mesh network with this dataset. The ADFA-LD dataset has 49 features to represent 9 attacks and a normal class data. But in this experiment, the dataset are reduced to 6 attacks and 1 normal class by combining similar category of attacks.
In this experiment, informative features of ADFA-LD intrusion dataset [36] are acquired with the help of proposed GA and MI based feature selection technique. Training and testing sets are randomly selected from ADFA-LD dataset and all the features are needed to be preprocessed before experimentation. The experiment has training data of size 300 dataset (41 normal, 73 Exploits, 7 DoS, 72 Fuzzers, 4 Backdoor, 102 Generic and 1 worm) over the testing data of 4002 dataset (1591 normal, 261 Exploits, 39 DoS, 313 Fuzzers, 4 Backdoor, 1792 Generic and 2 worms) are randomly selected to reduce the training time.
The experiment is carried out using Matlab in which the training and testing set are loaded in separate file. Initially after preprocessing the random population of chromosome is generated from the data of training set, the semi informative features are selected using genetic algorithm. The parameters of the GA are taken as population size: 20, generation: 10, mutation rate: 0.01 and crossover rate as 0.9. Then the random population of chromosome with selected features is given as input to mutual information technique for getting the compact most informative features. Then the compact informative features are given as input to SVM classifiers and the accuracy rate of classifiers is computed.
Based on the accuracy rate of classifiers as fitness level, the candidates feature used for next generation is further optimized by genetic algorithm. The chromosomes with large fitness value are selected as new parent for next generation and the process repeats till last generation. The optimal feature subset found by the hybrid feature selection technique is used to achieve maximum accuracy of classifier. The comparison of proposed technique based on detection ratio over other feature selection technique is shown in Table 1. Each column has filter based MI features, wrapper based GA features and GA+MI technique are used for comparison with proposed feature selection technique. The results clearly demonstrate the usage of feature selection techniques has high accuracy in attack detection than using with original features. The proposed feature selection technique with SVM and ANN classifiers on the basis of accuracy rate and training time are given in Fig. 4 and Table 2 respectively. In most of the cases, SVM classifier outperforms ANN classifier in all kinds of feature selection methods. It also indicates increasing the number of features does not increase the accuracy of classifier. The accuracy rate of hybrid feature selection has high accuracy over normal GA technique by using SVM classifier. Intrusion detection system requires large time for training with data because of classifier optimization and offline processing whereas the testing data does not require much time even for testing huge number of data [15]. Hence, in this paper training time gets much importance than testing time.
Comparison of proposed IDS with hybrid feature selection over other feature selection techniques
Comparison of proposed IDS with hybrid feature selection over other feature selection techniques
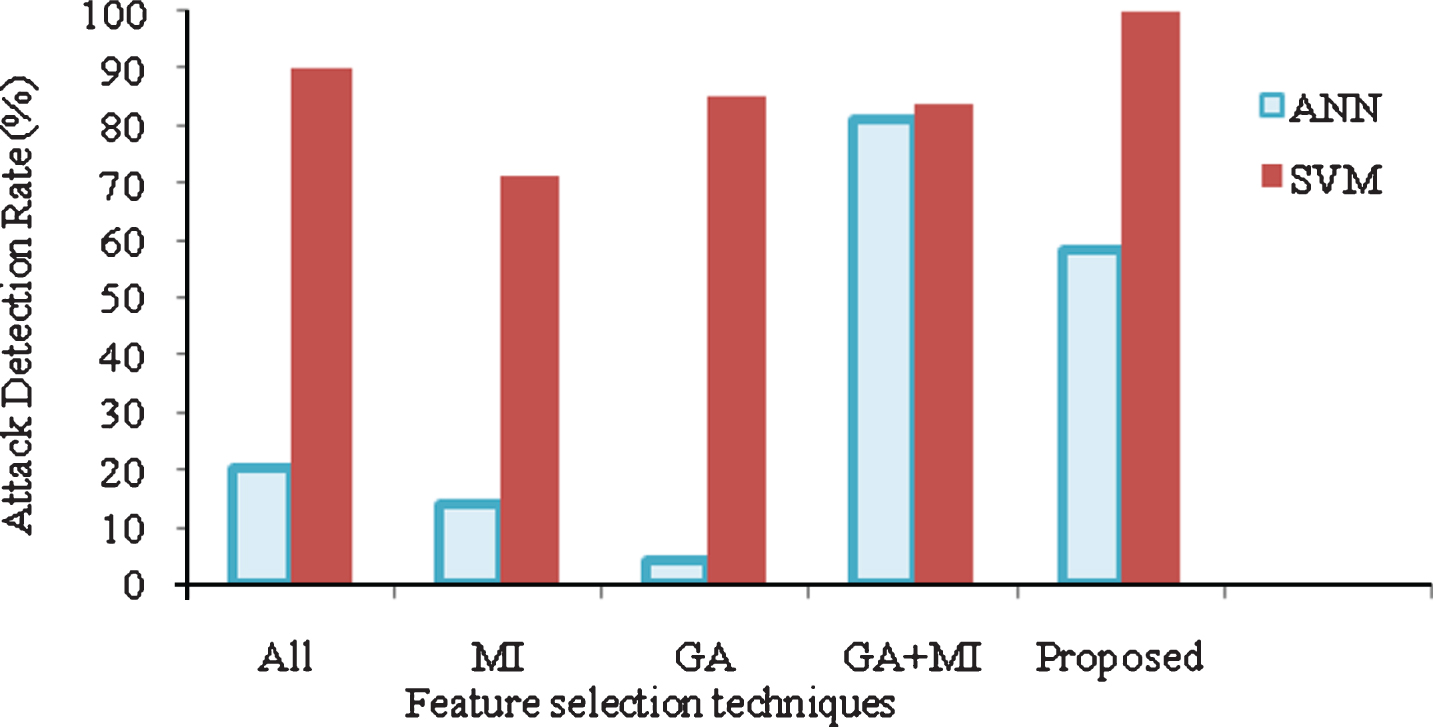
Performance analysis of proposed IDS over ANN classifier.
Comparison of SVM and ANN classifier based on training time (in second)
Table 2 verifies the proposed system has less training time than IDS with GA, MI and GA+MI techniques in both ANN and SVM classifiers. The proposed system is further validated by other standard datasets or cross validation of the dataset [37] or datasets generated as in [38] is essential to verify the performance in unseen data. In this work, widely used standard KDD cup ’99 dataset is used for validation and the results are given in Table 3. Thus from the results, the proposed IDS with hybrid feature selection technique detect the intrusions with high accuracy is verified. The selected optimal features reduce the computational effort of classifier and take less training time compared to the various available techniques. Eventhough the accuracy of classifier is improved by the proposed hybrid technique, the training time of the classifier need to be further reduced for WMN based sensitive applications like smart grid, IoT, etc.
Validation of proposed system using KDD cup’99 dataset
The usage of optimal features in the classification task is essential for designing good intrusion detection system in wireless mesh network. In this paper, a novel intrusion detection system with hybrid feature selection technique using genetic algorithm and mutual information technique is proposed. The wrapper method based genetic algorithm select the semi-optimal feature subset from the original subset. Then the mutual information technique placed inside the genetic algorithm selects the optimal feature subset with the help of SVM classifier and the process repeats till the maximum accuracy of IDS is achieved. The proposed IDS with hybrid feature selection technique is compared with the IDS using features selected by mutual information, genetic algorithm and GA+MI technique in SVM and ANN classifier. Experimental results have shown that the proposed intrusion detection system with hybrid GA and MI based technique with SVM classifier has high accuracy and can be suitable for intrusion detection system in wireless mesh network and other applications.