
Abstract
Markov game based controllers are robust but lack guarantee on the stability of the designed controller. In this work, we attempt to address this shortcoming by proposing a lyapunov fuzzy Markov game controller for safe and stable tracking control of two link robotic manipulators. Lyapunov theory has been used to generate fuzzy linguistic rules for implementing a reinforcement learning (RL) based Markov game controller. We employ fuzzy inference system as a generic function approximator to deal with the “curse of dimensionality” issue. Proposed RL based Markov game controller is self-learning, adaptive and optimal. We implement the proposed control paradigm on: a) Two link robot manipulator and b) SCARA manipulator for the cases: i) controller handles disturbances and parameter variations, and ii) disturbances and no parameter variations. We give comparative evaluation of our approach against: a) fuzzy Q learning controller, and b) fuzzy Markov game controller. Simulation results illustrate stable and superior tracking performance and advantage in terms of lower control torque requirements.
Keywords
Introduction
Robotic manipulator control has been of keen interest to researchers for decades and continues to be of focal interest due to manipulator’s highly nonlinear and coupled dynamics [1, 2], e.g., in a recent approach authors have employed nonlinear adaptive fractional order fuzzy PID technique on two link robotic control [3]. RL is an online technique with roots in machine learning and has been used quite effectively for robot manipulator control [4]. However, majority of researches have attempted manipulator control either by assuming a priori knowledge of the manipulator model [3] or by assuming an approximate model of the manipulator [5, 6] or by linearizing its dynamics [7]. Some major drawbacks of these approaches are: approximate model would invariably have modeling errors while linearization doesn’t work effectively for a wide operational range [2, 8]. An observer based control scheme has been proposed in [9] with uncertain kinematics and dynamics. However, authors use two sliding mode observers to handle uncertainty in kinematics leading to slow convergence.
In model free RL or Q learning [4] based control, one doesn’t need model of the system to be controlled [10] and non-linearity is taken care of by use of appropriate function approximator, e.g., neural networks or fuzzy systems [4]. The flip side is that no convergence guarantees are available when a function approximator is employed for generalization. However, advantages of function approximation outweigh disadvantages and model free RL has been increasingly employed for control of robot manipulators [4, 11]. A single link flexible robot manipulator controller has been designed using RL in [12] where authors have tried to nullify the effect of vibrations. In [13], authors have proposed an RL based adaptive neural controller for robotic manipulators considering bounded dead zone. RL, off late, has been applied in several other fields as well, e.g., for stabilizing real-time power system and control of transient voltages [14], and for decentralized control for large scale nonlinear systems [15].
Typically, RL framework assumes Markov decision process (MDP) as the underlying model. Markov game (MG) based controller is a generalized and robust form of MDP based RL controller [16]. In a recent variation of the MG based control on a two link robotic manipulator [17]; authors have used kernel recursive least squares algorithm to approximate the value function. Although MG based controllers are adaptive, optimal and robust, they lack any stability guarantee on the designed controller. Our present attempt is to fill this lacuna in the MG based controller formulation [18].
Lyapunov theory [1] can be used to design controllers for robot manipulators with guaranteed tracking stability. In [5, 19] authors have used lyapunov theory to design neural network based controllers for robot manipulators. Actor-critic RL configuration using lyapunov theory with two neural networks has also been employed in [12, 13]: one to approximate action and other to approximate value function with consequent drawback of slow convergence. A recently proposed game theoretic controller [17] for robotic manipulators manages better tracking sans stability.
MG controller possess proven robustness to disturbances as it attempts to find best possible controller response to worst possible disturbances. However, ensuring stability of this otherwise robust controller is a research gap, which we intend to fill in our current work. This is sought to be achieved by playing a “layapunov constrained Markov game” at each state rather than “pure Markov game” as in [20]. In specific, controller is only allowed to choose actions dictated by lyapunov theory. With this lyapunov constrained action set it plays out a zero sum game against the disturber, eventually giving a stable and robust MG controller. A key difference between the proposed approach and the fuzzy Markov game approach [20] is that the rule consequents in our approach are linguistic [21] rather than crisp. We apply our proposed control scheme on two benchmark two link manipulator problems: a) Two link robot arm manipulator (TLRAM), and b) SCARA. We also consider payload variations along with external disturbances for a more realistic implementation.
Rest of the paper is structured as: Section 2 gives brief but relevant details on fuzzy Q learning and fuzzy Markov game and our proposed linguistic lyapunov fuzzy Markov game control. Details of the manipulators used to demonstrate the effectiveness of the proposed scheme, i.e., a) TLRAM and b) SCARA along with the parameters thereof are given in Section 3. Proposed approach is compared against fuzzy Q learning and fuzzy Markov game approaches in Section 4 and, Section 5 concludes the paper.
Theoretical background
We give a brief background on fuzzy Q learning (FQL) and fuzzy Markov games as a prelude to our approach.
Fuzzy Q learning
FQL envisages an agent receiving a reward r k on choosing an action a k ∈ A in state s k . The aim of the controller/agent is to discover an approximate optimal policy that optimizes long term cumulative reward. Principle idea is to use fuzzy inference systems (FIS) as an approximator for extending Q learning based RL to large or continuous state action space problems. For further details on FQL, we refer the interested reader to [22].
Fuzzy Markov games
Fuzzy Markov games generalize FQL to a two player scenario with controller and disturbances as opponents [20]. Disturber and controller are engaged in a two player zero sum dynamic game at each state. Fuzzy Markov game rule base is:
R j is the j th rule of rule base, action set for controller and disturber is denoted by A = {a1, a2, … a m } and D = {d1, d2, … d m }, respectively. q value corresponding to controller-disturber action pair for each rule R j is denoted by q (j, a j , d j ). For instance, if the cardinality of disturber action space D and that of controller action space A is 3 (as in our case), a game matrix can be constructed for each rule R j (Fig. 1).
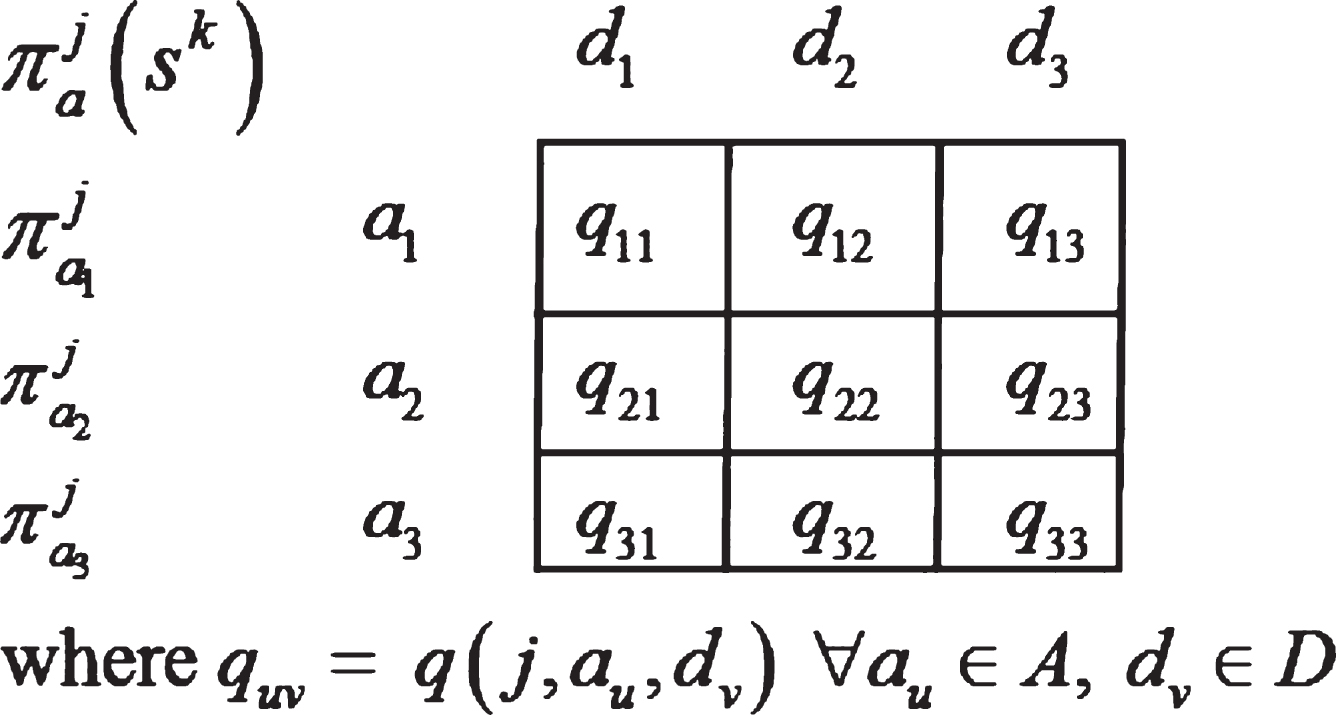
Game matrix.
At each state, the controller and disturber play out a game defined by the game matrix (Fig. 1). The solution of this game given best possible controller strategy against worst possible disturber. For further details on Markov games please see [20].
Lyapunov theory has been used extensively in stability analysis of nonlinear systems, and is based on defining a Lyapunov function (LF) [21]. A Lyapunov function P(s) should satisfy:
s = 0 is assumed to be the equilibrium state. Controller design involves choosing a positive definite LF (LC1 and LC2 conditions) and the controller chooses actions to ensure that the first derivative of LF turns out to be negative definite (LC3 condition). In this work, we use lyapunov theory to formulate a fuzzy rule base and use the MG controller design philosophy on this lyapunov constrained fuzzy rule base.
“Computing with words approach” [21, 23] has been used for designing the lyapunov fuzzy Markov game controller (LFMGC). Assuming
A lyapunov constrained linguistic control can be generated by defining a cost function as:
Obviously, conditions LC1 and LC2 (2) are satisfied by the this function P, so if the selected function has to be an LF it needs to satisfy only the L3 (2) condition, i.e.,
From the physics of manipulator like systems [20], we know that
From (6) it can be concluded that when e and
Using the “computing with words” paradigm [23]: specifying f as “Big Positive” (for negative e) makes f > - e. Also assigning “Big Negative” as linguistic variable to f makes f < - e (for positive e). Thus the lyapunov condition (2) can be interpreted linguistically as
Here Zero, PS, Big_PS NS, and Big_NS denote Linguistic variables representing Zero, Positive, Big Positive, Negative and Big Negative, respectively. We combine the above linguistic rules (7) to generate simplified linguistic rules (8):
We first combine (7a) and (7c) to get an aggregated linguistic rule (8a):
Next, combining (7b) and (7d), we get rule (8b):
We give a brief explanation as to how we get rule (8a) from rules (7a) and (7c):
Considering (7a) (when e is PS) and (7c) (when e is NS) it is clear that for both these rules
Similarly combining (7b) and (7d), we get
From the interpretation of linguistic rules (7a) and (7c) as discussed above, we can infer that for any e (i.e. “PS” or “NS”) and
Next step is to employ MG framework wherein a game is played between the controller (lyapunov constrained) and disturber that simultaneously ensures that
Using the procedure outlined above when
Here (a1L, a2L, . . . . . , a mL ) are actions belonging to the linguistic lyapunov action set A L at state s k corresponding to rule R j . q L denotes q value corresponding to linguistic lyapunov consequent.
Rule base (10) corresponds to linguistic lyapunov fuzzy MG. This linguistic lyapunov rule base (10) makes
In the roposed linguistic lyapunov Markov game, input state vector
PD(A L ) is probability distribution over action set A L of the controller.
Next ∈ - Minimax policy is used to implement EEP:
Global EEP π
La
†
(s
k
) is generated as:
Global continuous control action at each state s
k
is computed as:
Next game solver (linear program) is used to get
Global desired value function V
L
(sk+1) is obtained as:
Global Q value is calculated as:
Temporal difference (TD) error (ΔQ) is calculated as:
Finally, TD error is used for q-update as:
This q update, under favorable conditions, makes q values converge to lyapunov game dictated optimal values or ΔQ L → 0 and the corresponding controller is a linguistic lyapunov Markov game controller.
Robotic manipulator modeling
Dynamics of robot manipulator having n joints may be written as [20]:
Proposed LFMGC has been implemented as a decentralized controller whence each link of the manipulator has dedicated controller.
Here fuzzy label in ith joint for jth link is denoted by l
p
.
Centers of above mentioned fuzzy labels are defined as
e
t
(1) = φ
d
(1) - φ (1) , e
t
(2) = φ
d
(2) - φ (2) and cost function used is
Desired trajectory for robot manipulator is:
Consider a function
Quite clearly, condition LC1 and LC2 (2) are satisfied for the function F defined in (24). For making F, a lyapunov function, LC3 condition has to be satisfied, i.e.,
Though, exact model of manipulator is not known; dynamics of manipulator suggest that
Considering
Linguistic rules for stable manipulator control
To implement these lyapunov linguistic rules, two lyapunov linguistic action sets have been defined:
Next, we use Markov game to select most appropriate stochastic action from A
NL
or A
PL
(by using game the matrix) according to the case, i.e., if
Proposed controller has been simulated on two benchmark robot manipulators problems: i) TLRAM and ii) SCARA. Parameters used in simulations are: sampling time = 20 msec, learning rate = 0.05, discount factor = 0.9 and exploration rate decreases gradually from 0.4 to 0.01. Action sets used: A NL = [-20 - 10 0] Nm and A PL = [20 10 0] Nm. These parameters remain same for both manipulator problems.
Details for the two link robot arm manipulator and SCARA are provided in Appendix A. The manipulators are simulated by 4th order Runge–Kutta method for 20 s. We apply the proposed controller on TLRAM for two different cases: i) with fixed payload and external disturbances, and ii) with a varying payload and external disturbances, and compare its performance against baseline FQL and FMGC controllers. ±20% of the applied torque (Gaussian distributed around mean) has been used as external disturbances. Payload m2 variation for TLRAM are:
Two link robotic arm manipulator (disturbance only)
Figures 2 and 3 show trajectory tracking error (in degrees) for link1 & link2, respectively with disturbance only. It is evident from figures that the trajectory tracking error is least with the proposed controller as compared to fuzzy Q learning controller (FQLC) & fuzzy Markov game controllers (FMGC). Moreover, performance of LFMGC is significantly superior as compared to FMGC. Figures 4 and 5 give torque required to attain desired trajectory for link1 & link2. Torque requirement for our proposed controller is almost half as compared to torque required by FQLC. Torque required is higher in FMGC as compared to LFMGC, besides there is more chattering in FMGC than LFMGC. We conclude that LFMGC has superior trajectory tracking and requires less torque to achieve the required trajectory.

Trajectory tracking error for theta1 (TLRAM) with disturbances only.

Trajectory tracking error for theta2 (TLRAM) with disturbances only.

Torque required by link1 (TLRAM) with disturbances only.
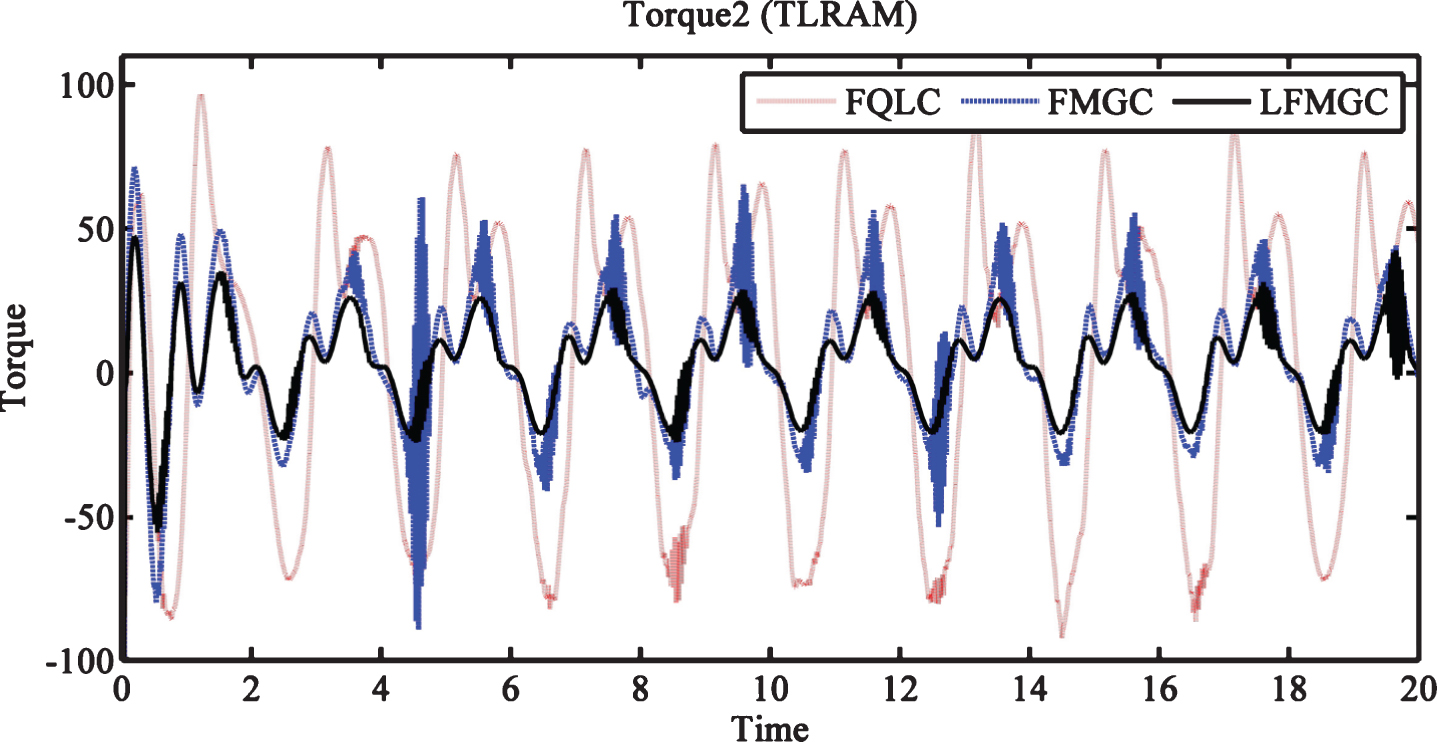
Torque required by link2 (TLRAM) with disturbances only.
Tracking errors for link1 & link2 with external disturbances and payload variations is shown in Figs. 6 and 7. Here also LFMGC exhibits superiority over baseline controllers, i.e., FQLC and FMGC. Figures 8 and 9 show torque requirements for link1 and link2. Least torque is required by LFMGC while FQLC and FMGC both exhibit more chattering as compared to LFMGC. This showcases superior disturbances and payload variation handling by LFMGC.
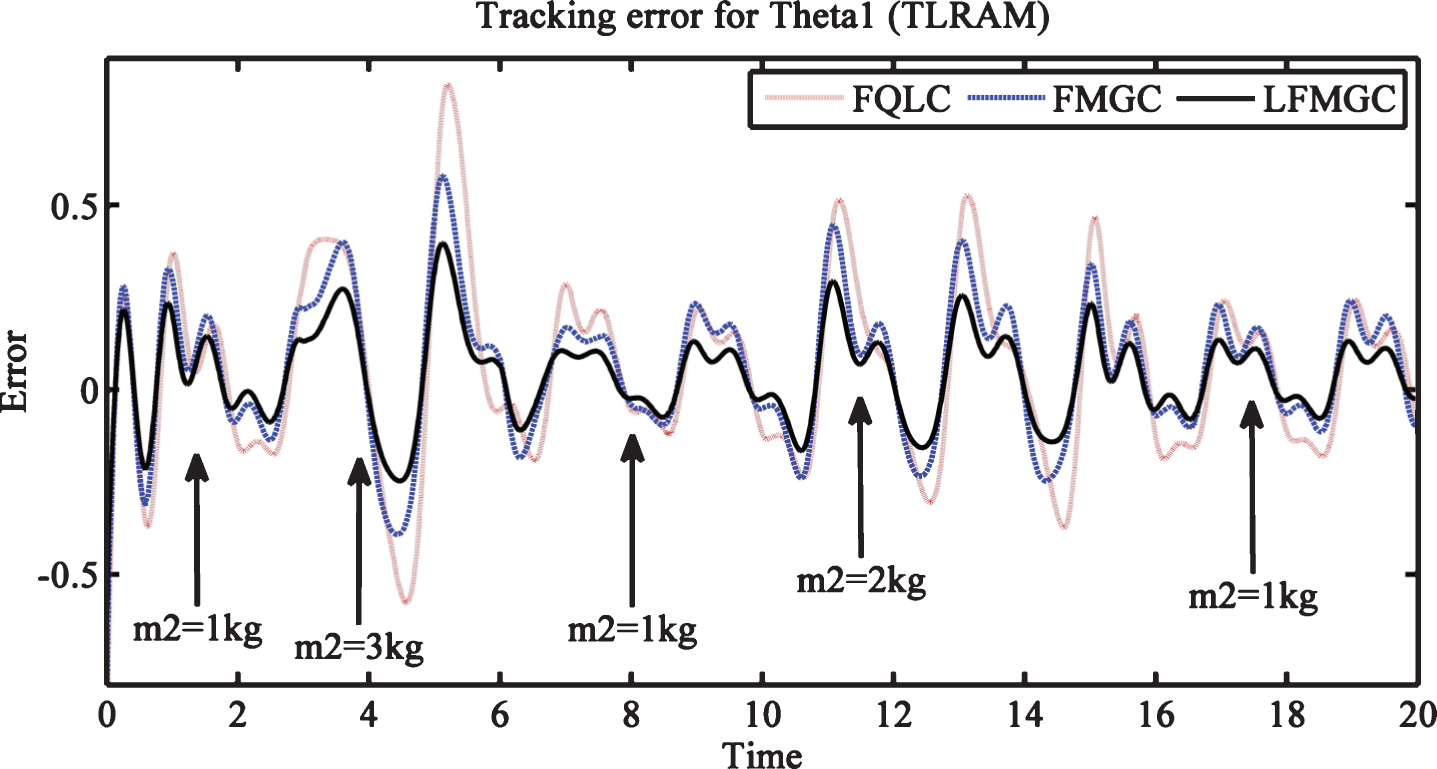
Trajectory tracking error for theta1 (TLRAM) with disturbances and payload variations.
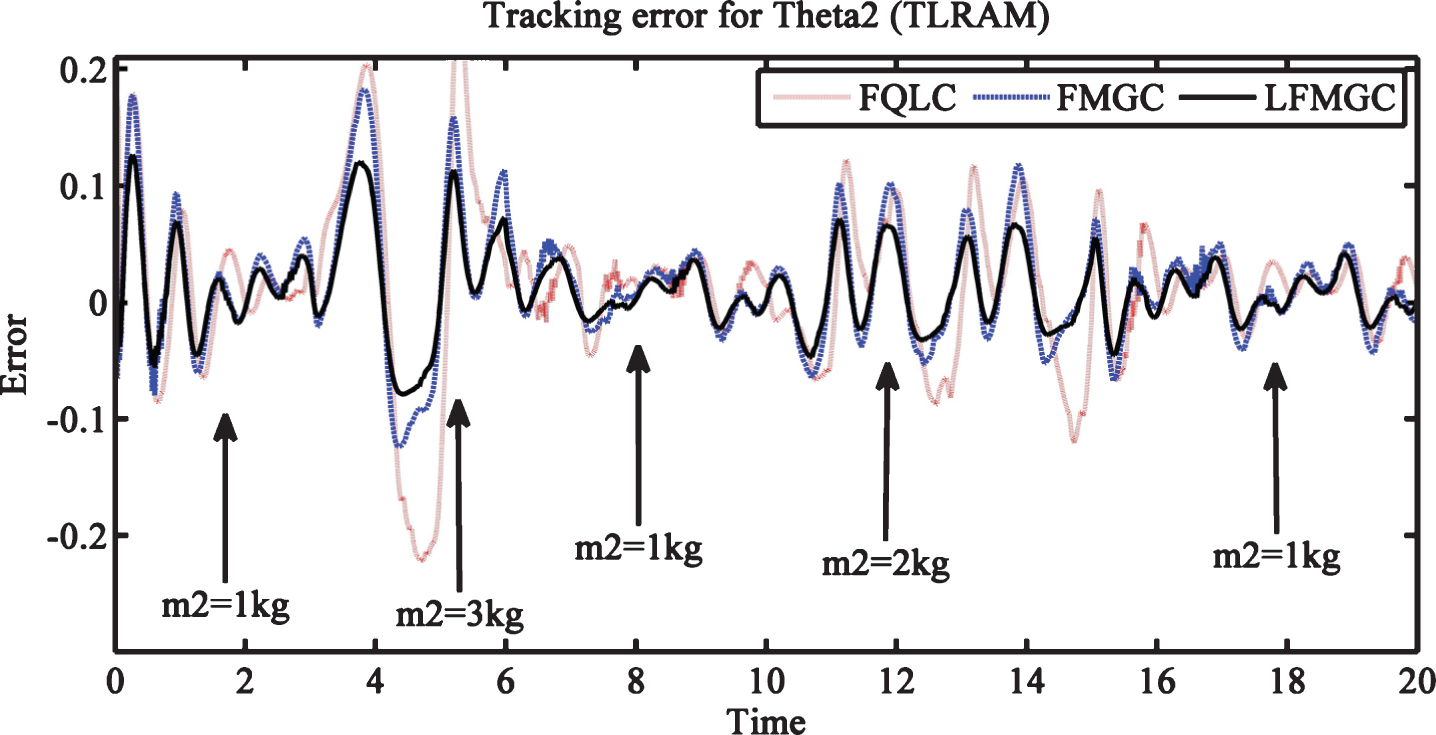
Trajectory tracking error for theta2 (TLRAM) with disturbances and payload variations.
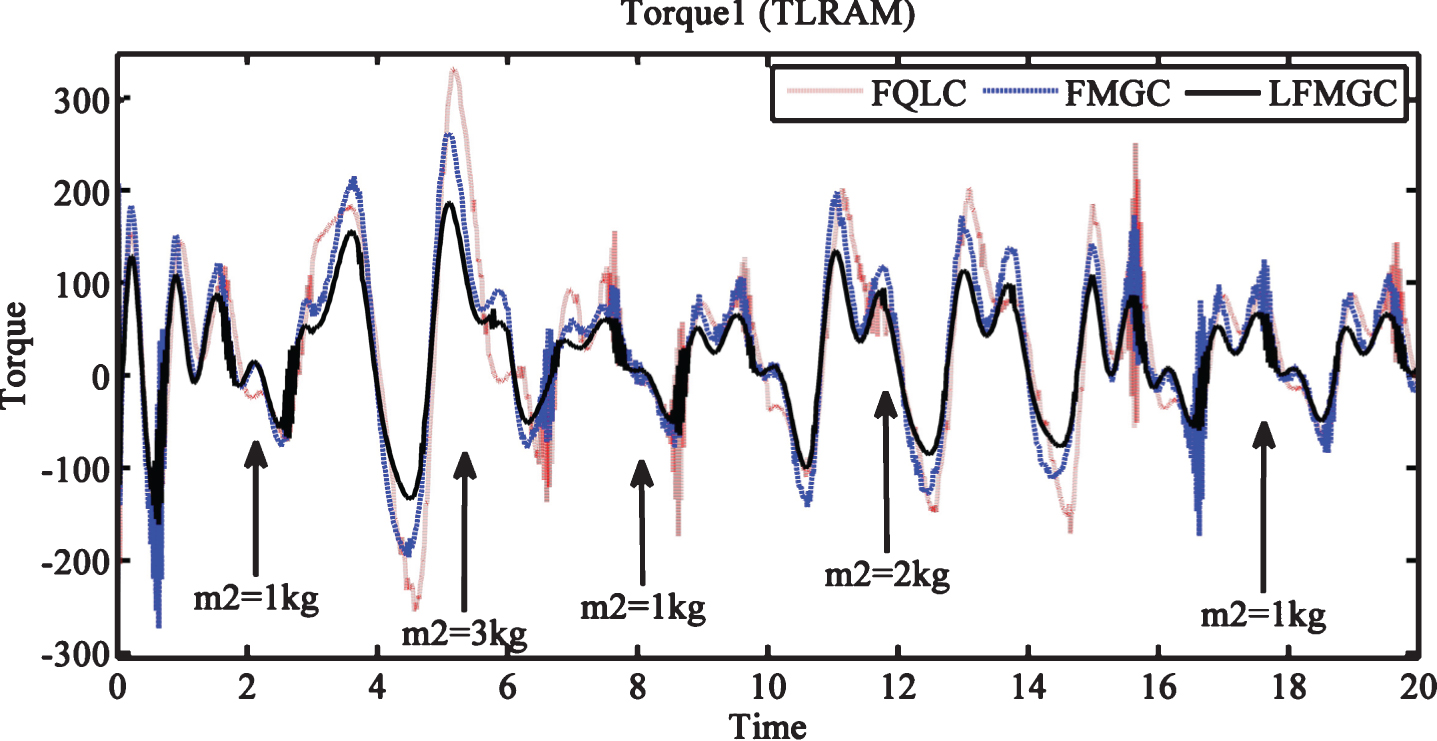
Torque required by link1 (TLRAM) with disturbances and payload variations.
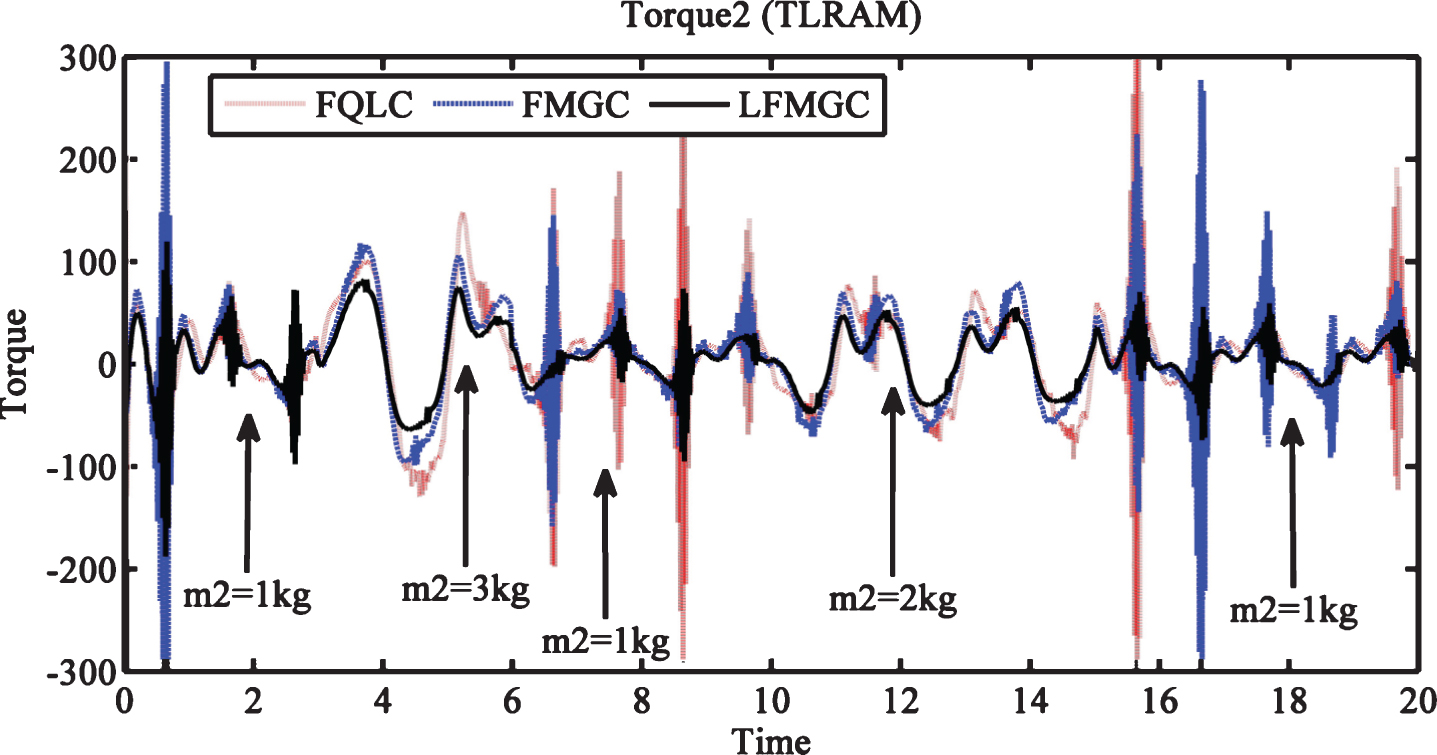
Torque required by link2 (TLRAM) with disturbances and payload variations.
Figures 10 and 11 give trajectory tracking efficiency for SCARA (with external disturbances only). We observe that tracking error is achieved by LFMGC is least. Moreover, this error is not very abrupt in nature as observed in the case of FQLC and FMGC. Figures 12 and 13 show torque requirement for link1 and link2 and indicates that LFMGC has chattering problems as compared to FQLC and FMGC. The required torque is comparable (and even greater for link2) to the FQLC and FMGC. We conclude that although our controller is good trajectory tracking but its performance is jerkier than others in case of SCARA.

Trajectory tracking error for theta1 (SCARA) with disturbances only.
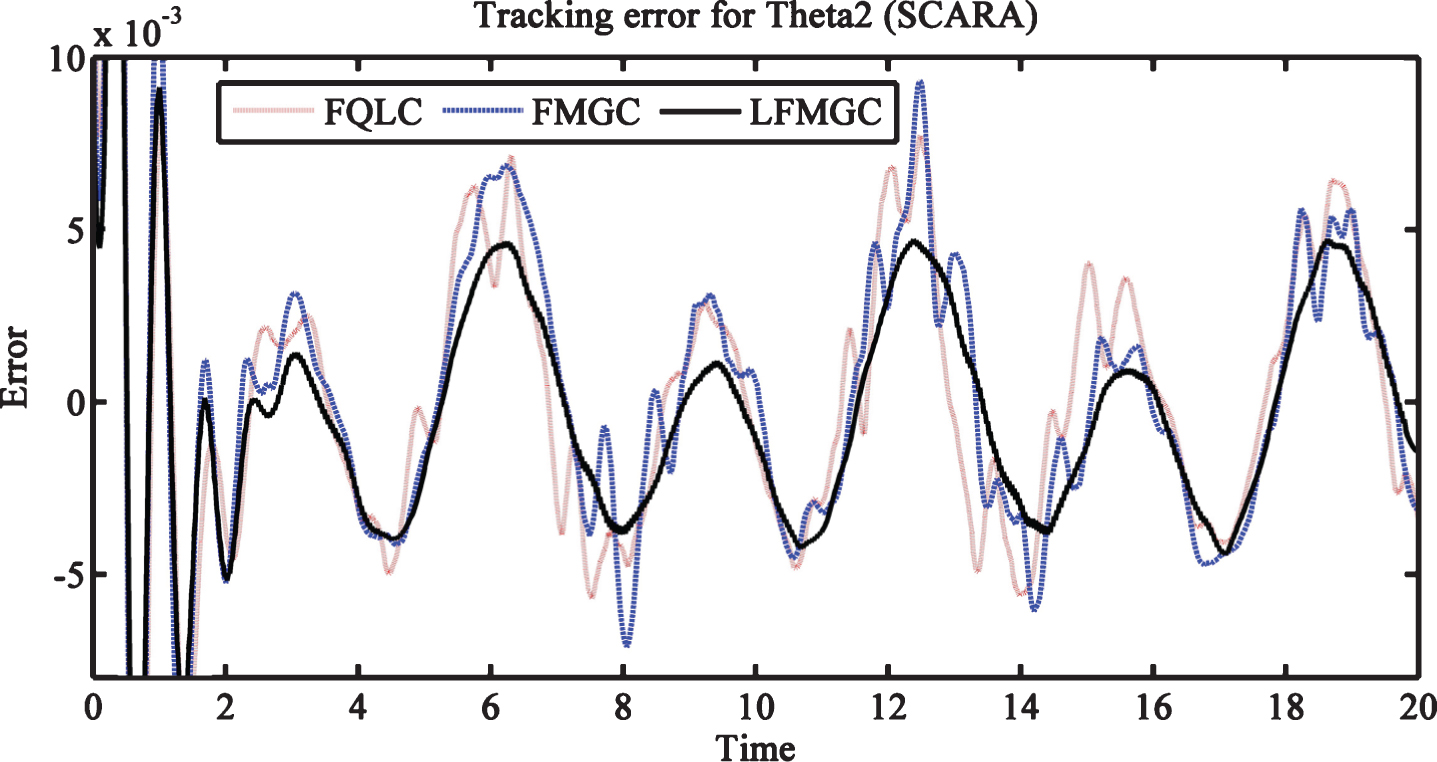
Trajectory tracking error for theta2 (SCARA) with disturbances only.

Torque required by link1 (SCARA) with disturbances only.
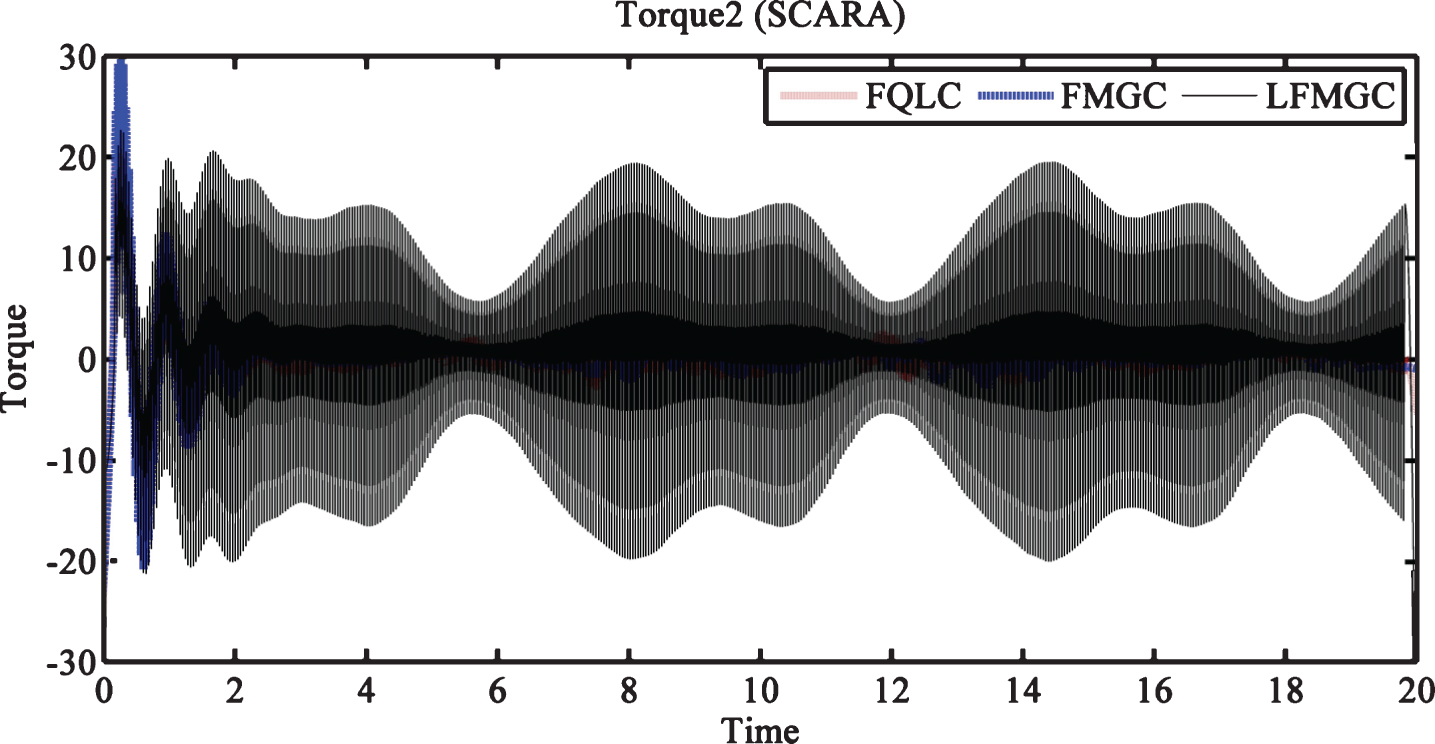
Torque required by link2 (SCARA) with disturbances only.
Tracking errors for link1 and link2 with varying pay load and external disturbances are least and pretty smooth for LFMGC (Figs. 14 and 15). Torque requirement for link1 is minimum with LFMGC (Fig. 16). Figure 17 gives torque required by link2 which is comparable to others and but has chattering, particularly when payload is minimal for LFMGC. Overall, with payload variations, LFMGC performs better in terms torque requirement and its performance is best amongst the three controller for trajectory tracking. Chattering can be overcome or reduced by use of appropriate filters in the control mechanism.
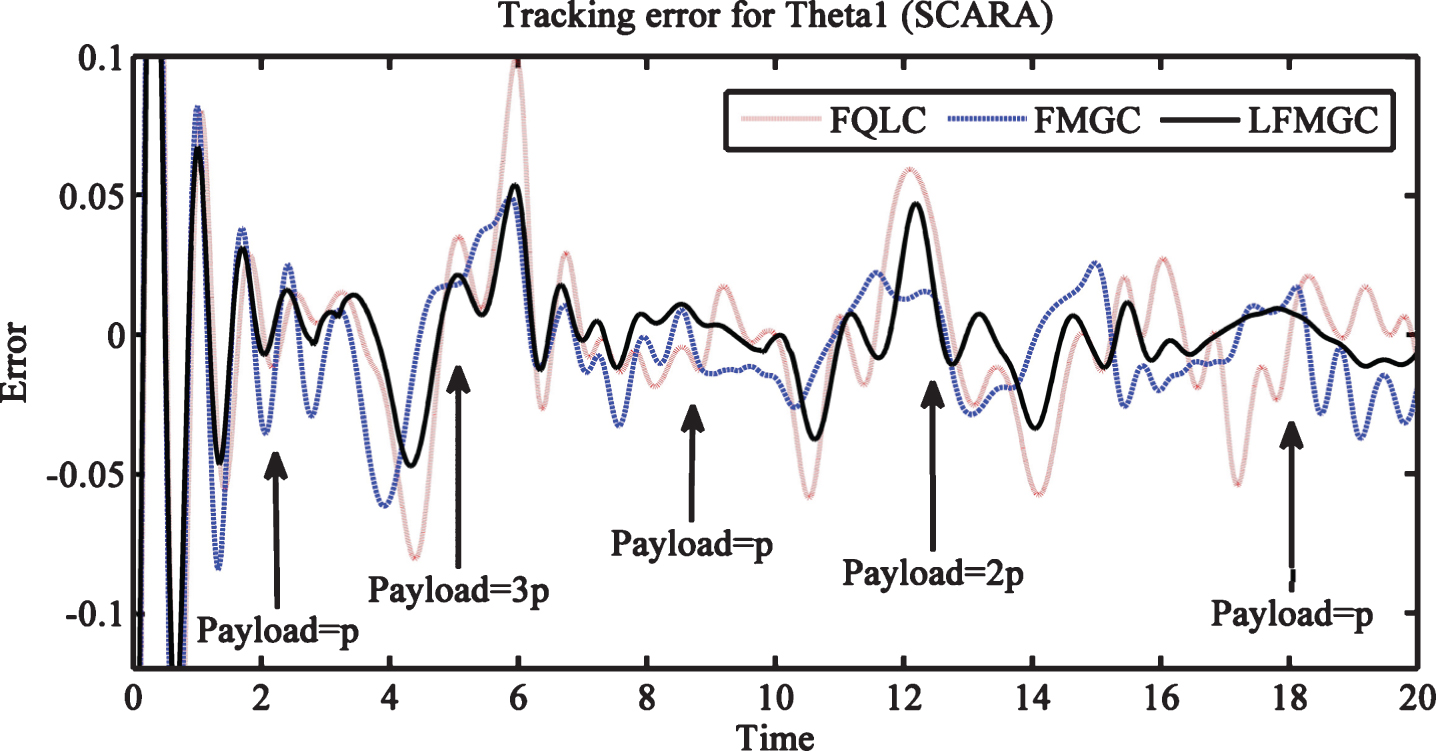
Trajectory tracking error for theta1 (SCARA) with disturbances and payload variations.
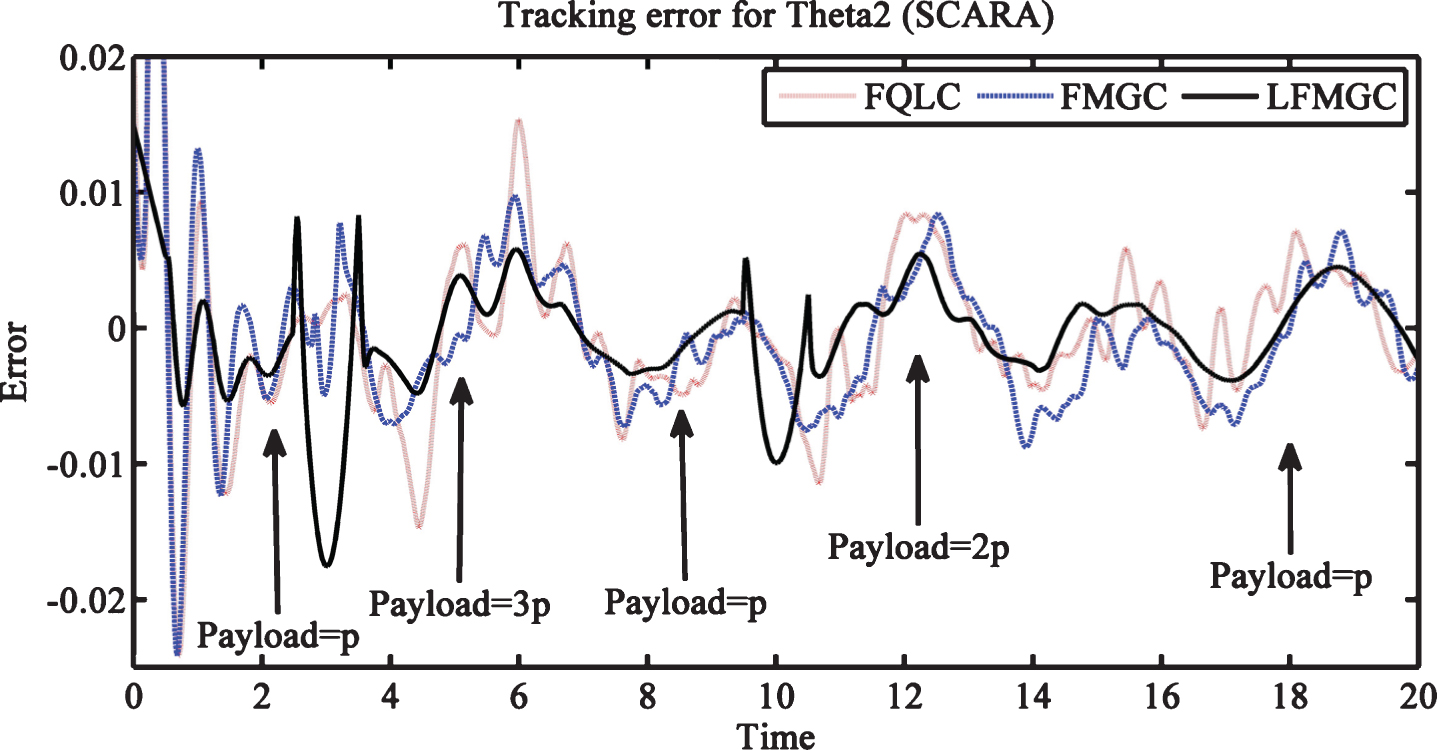
Trajectory tracking error for theta2 (SCARA) with disturbances and payload variation.

Torque required by link1 (SCARA) with disturbances and payload variations.
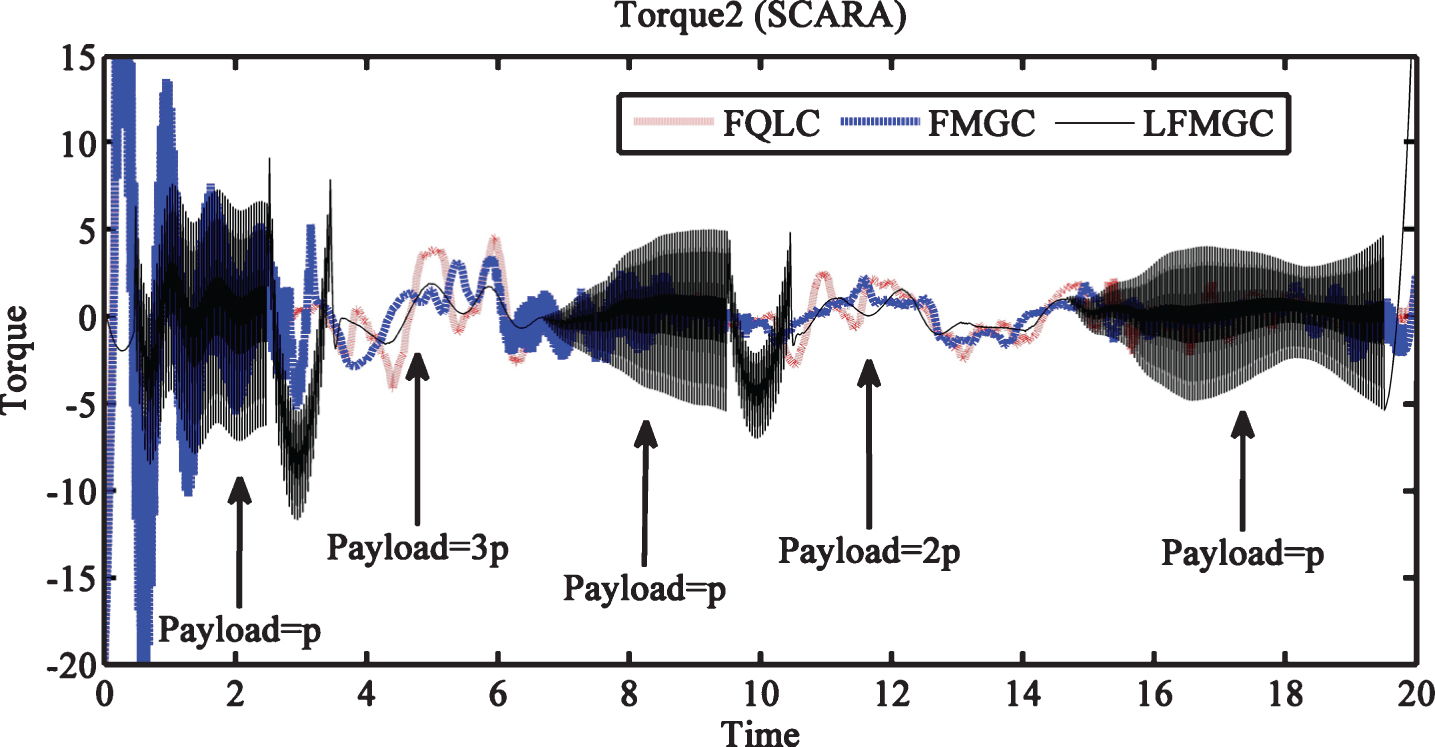
Torque required by link2 (SCARA) with disturbances and payload variations.
We proposed a fuzzy Markov game controller for robot manipulators wherein controller actions are lyapunov constrained. Lyapunov theory based action generation mechanism lends much needed stability to the robust Markov game framework. To the best of our knowledge, ours is a first attempt at framing a linguistic version of Markov game control for robot manipulators. Our proposed MG control achieves superior tracking, albeit with higher but comparable torque over the baseline FQLC and FMGC controllers. In future, we intend to incorporate fuzzy sliding-mode control (FSMC) [24] in our proposed scheme to eliminate torque chattering and employ it on two link manipulators in rotating co-ordinate systems [25] and for managing intelligent buildings [26].