
Abstract
The microblogging service Twitter has witnessed a rapid increase in its adopters ever since it’s discovery in October 2006. Today it has become a medium of communication as well as spread of information. Hashtags are created in twitter by users whenever an event of significant importance occurs and hence they become trending on twitter network. Once hashtags are created on twitter platform, the tweeters may communicate within a particular community of interest following and tweeting to any particular hashtag conversations. In this paper, we propose the design of Community based Hashtag Recommender System (CHRS) for twitter users. This will help the users by expanding their hashtag base and hence strengthening the hashtag conversation for a particular event. The tweets collected over a period of time for some particular hashtags have been categorised to communities based on sentiment analysis of the tweets. Once the process of community detection completes, the existing users are found in the tweets. Further the idea of Hashtag frequency- Inverse Community Frequency (HF-ICF) has been suggested and deployed to find hashtags which uniquely distinguish the users found earlier. Finally relevance score is computed based on the idea of collaborative filtering approach to recommendation, for various hashtags used by the users. A prototype of the system is developed using the statistical tool R and experimental analysis has been carried out. Tweets of national concern in India pertaining to ‘demonetisation’ have been collected and used for experimental purposes.
Introduction
Social networking websites are virtual communities which allow people to connect and interact with each other on a particular subject or to just hang out together online. They have become a medium of mass communication as well as entertainment in the past decade [15]. A number of Online Social Networking (OSNs) like Facebook, Twitter, Linkedin, MySpace etc. have emerged and gained massive popularity in this era. One of the major popular activities in social media is microblogging. It is the process of writing short text updates which may be information related; entertainment oriented or for the purposes of infotainment. Microblogs may contain text, URLs, images, videos etc. Twitter has emerged as one of the most popular microblogging services in the last decade. The twitter network has been evidently used in many real life scenarios like earthquakes, floods and in issues of national concerns like elections. The data available on Twitter may be effectively deployed for the understanding of development of major events, to comprehend the occurrence of happenings of international concern or even to predict the outcomes of major issues [7]. This work makes use of tweets collected from Twitter API on an issue of national concern in India i.e ‘demonetisation’.
The present work analyses the demonetisation movement on twitter to study and analyse the user’s opinions on the topic and eventually suggest them hashtags to follow. This is further discussed in the next section. An effort has been made to recommend hashtags to users, where first the communities of tweets are discovered via sentiment analysis. The hashtags to be suggested to these users are then discovered using the proposed idea of Hashtag Frequency-Inverse Community Frequency (HF-ICF). Subsequently the hashtags are recommended to the users. The contributions of this work may be summarised as below: We employ sentiment analysis to detect the communities of tweets based on the polarities of the tweets. We deploy Jaccard-distance as a metric to find the similar users. We propose Hashtag Frequency-Inverse Community Frequency (HF-ICF) to discover the tweets which may uniquely identify the items pertaining to a particular community. We put forward the design of a Community based Hashtag Recommender System (CHRS) to recommend hashtags to users. These are hashtags recommended to the user, have used by other similar members of the community. The performance of the system is henceforth evaluated using a tweet dataset collected for almost two months based on demonetisation.
As per our knowledge this work is a first attempt to combine sentiment analysis for community detection to generate community based recommendations using collaborative filtering for twitter dataset. We analyse the twitter users’s opinion on various other national concerns related to demonetisation. The paper has been given the following structure. Section 2 covers the basic concepts related to the work. In Section 3, we discuss similar work done by researchers in the past. Section 4 explains our proposed methodology used to build up the Recommender System (RS). In Section 5, we discuss the experiments and evaluate our results. The paper is concluded along with discussion of future directions in Section 6.
Basic concepts
This section describes the fundamental concepts which form the basis of the proposed work.
Demonetisation
“It is the action of shedding a currency unit of its position as legal tender” 1 . The current structures of money are dragged from flow and retired, generally to be substituted with fresh forms of currency and coins. In India, the demonetisation of currency notes was announced by Prime Minister Mr. Narendra Modi on 8th November 2016, in an unscheduled live television speech at 20:00 Indian Standard Time(IST). It instantly became a huge movement on twitter and gathered a lot of attention. The process of demonetisation aimed to tackle black money, corruption and the problems revolving around fake currency. In about 24 hours of announcement by the Prime Minister, there were 6.5 lakh tweets pertaining to the hashtag ‘#de-monetization’ in the twitter network.
The microblogging site, Twitter ever since it’s discovery in 2006, has been a popular and evident tool to reach out to a large amount of population at once. The standard form of communication on this microblogging service is a tweet, which is a maximum of a 140 character message. It may consist of hashtags, mentions, URLs. A tweet could be a reply or a retweet to an already existing tweet. A hashtag is a keyword in Twitter consisting of the symbol ‘#’. An example of a tweet is as given below: World Bank appreciates PM @Narendra Modi’s #Demonetisation #ITVideo.
Twitter API
Since the twitter network uses Oauth 2.0 for connection and authentication, the first thing to access data via the Twitter API 2 is to generate oauth keys. This is done by creating an application on apps.twitter.com. In twitter, two kinds of APIs exist. These are the REST and the Streaming APIs. The latter needs a connection that is continuous. While the Rest APIs are an access to read and write Twitter data, the Streaming API give continuous response to the REST API queries 3 . Search API is a part of REST API, with this we can perform queries for popular tweets. The Streaming API gives access to twitter’s global stream of tweet data. Various parts of the tweet like contributor, created at, entities etc. are detailed at the developer documentation available. The data from the connection to the API, is returned in JSON format.
Hashtag in a tweet
The hashtag function was created on Twitter to allow people to easily follow topics they are interested in. Hashtags are useful in emphasising the importance of a particular term or word. A hashtag is any keyword proceeded by the ‘#’ symbol in the twitter network. They are used by people in their tweets to refer to something specific. These tags are created by users whenever an event of significant importance occurs and hence they become trending on twitter network. Hashtags pertaining to some national/international events, disaster or major sports related events readily become popular on the twitter platform. For example #RioOlympics, #PrayforParis were globally popular hashtags. Once hashtags are created on twitter platform, they may be put to use by the twitter users and gain popularity accordingly to often become trending topics. As stated by Bruns et al. [6], “by following and tweeting to any particular hashtag conversations, the tweeters may communicate within a particular community of interest”. Also, this doesn’t require the users to be either followee or followers of each other. The ‘#’ symbol may be placed before any word or phrase in the tweet. This makes the keyword clickable and easily searchable in twitter. In this work, the Twitter API was used to crawl twitter and gather tweets around the hashtags as well as the keywords pertaining to the demonetisation saga in India. The tweets were collected for the hashtag and keyword demonetisation associated along with other issues of social concern.
Recommender systems
The massive growth of web and the expansion of the social media sites generates a huge amount of data. With the ease of access to the internet, online shopping has gained popularity. There are plethora of options available to the users. Recommender Systems(RSs) are software tools that assist the users in making the choice of selecting the most preferable item out of the pool of options available before them [2, 14]. RSs may be divided into three types based on the filtering technique they work on. These are Collaborative filtering based, Content based and Hybrid model based [24]. RSs that target the user specific choices, provide personalized recommendations while the RSs targeting towards a larger group to suggest the user with a generalized trend are termed as non-personalized RSs [4]. In this paper, we propose a Community based Hashtag Recommender System(CHRS). It uses the idea of finding users with similar opinions on any particular topic, grouping them together and then further suggesting them hashtags. We deploy jaccard similarity based collaborative filtering technique to develop the RS prototype.
Sentiment analysis
Sentiment Analysis is the process of finding the polarity associated with the words or the phrases. It has been handled as a Natural Language Processing(NLP) task at many levels of granularity [17]. It has found wide range of applications like marketing intelligence, question answering, making strategies for businesses and also an extensive application to politics. Kumar et al. [17] in their review stated that sentiment analysis deals with NLP, which is opinion oriented. In another work to analyze sentiment in Twitter network, Kumar et al. [16] have proposed a model that retrieves tweets on certain topics and then finds the sentiment scores. They did an extraction of opinion words and deployed a corpus based method in order to find the semantic nature of verbs and adverbs.
In this work, the sentiment analysis of tweets has been performed to find the polarity of the opinion in those tweets of the users. This has been done using Stanford NLP [20].
Community detection
A group of items with similar attributes, properties or likeminded users who share similar tastes comprise of a community. Community can be thought of to be a kind of an imaginary group formed by users/items on the grounds of some particular liking, attribute or similar interests to other members of the group. This process of discovering the virtual clusters is known as community detection [25]. A number of algorithms have been proposed for detecting communities and their description may be found in literature [3, 10]. In this work, community detection has been done using the well-known process of sentiment analysis. The users are divided into groups based on the polarity of their opinions about the the demonetisation process.
Related work
Hannon et al. [12] in their work on recommendation generation for twitter users, developed a twitter RS Twittomender. They have used user’s twitter social graph i.e the user’s tweets, the followers and the followee information. Zangerle et al. [26] in another work to suggest hashtags to the users, evaluated a number of similarity functions like cosine similarity, dice coefficient etc. to find similarity between the messages entered by the users and other messages existing in the dataset. They have further used number of different ranking measures to rank the hashtags and finally recommended them to the user. Zangerle et al. [27] have found suitable hashtags pertaining to any tweet the user enters. The hashtags are then suggested to the users when they are entering or composing any new tweet. This is done in three steps. Firstly the messages similar to the tweet are found, then hashtags are found which are similar to this tweet. They have proposed and used the idea of TF-IDF to find this. Then further ranking measures are used to find suitable hashtags for the user. Kywe et al. [18] have found similar user-tweet pairs and generated recommendations from these. Their method incorporates hashtags from similar users as well other similar tweets.
In their work, Elmongui et al. [9] have designed an RS named TRUPI. It suggests tweets to the users based on their dynamically discovered personal interests. Social interactions of the users combined with the existing history of the tweets of the user are utilised. Machine learning and NLP techniques are then applied to find the topics of the tweets. In our work we divide the users based on their opinions about certain national issues. Sentiment analysis has been used for the same. It helps dividing the set of tweets into groups or communities. Figure 1 depicts a diagrammatic view of the process. Otsuka et al. [21] in their work on hashtag recommendation system have introduced and applied the idea of Hashtag frequency- Inverse Hashtag Ubiquity (HF-IHU) to suggest suitable hashtags to the users. In a similar way we propose Hashtag Frequency-Inverse Community Frequency (HF-ICF) to find unique hashtags pertaining to users of the communities. In another work Otsuka et al. [22] have taken the above idea of RS to Hadoop-Mapreduce platform. In their work Kywe et al. [19] have combined similar hashtags from users with similar choices to the target user and from tweets that are alike to the target tweet. Further they have applied ranking mechanisms to the hashtags to sort them. The popular technique of TF-IDF has been used. Chen et al. [8] developed a twitter URL recommender. They have included the popular URLs as well as those from the followees of the the followee of any target user.
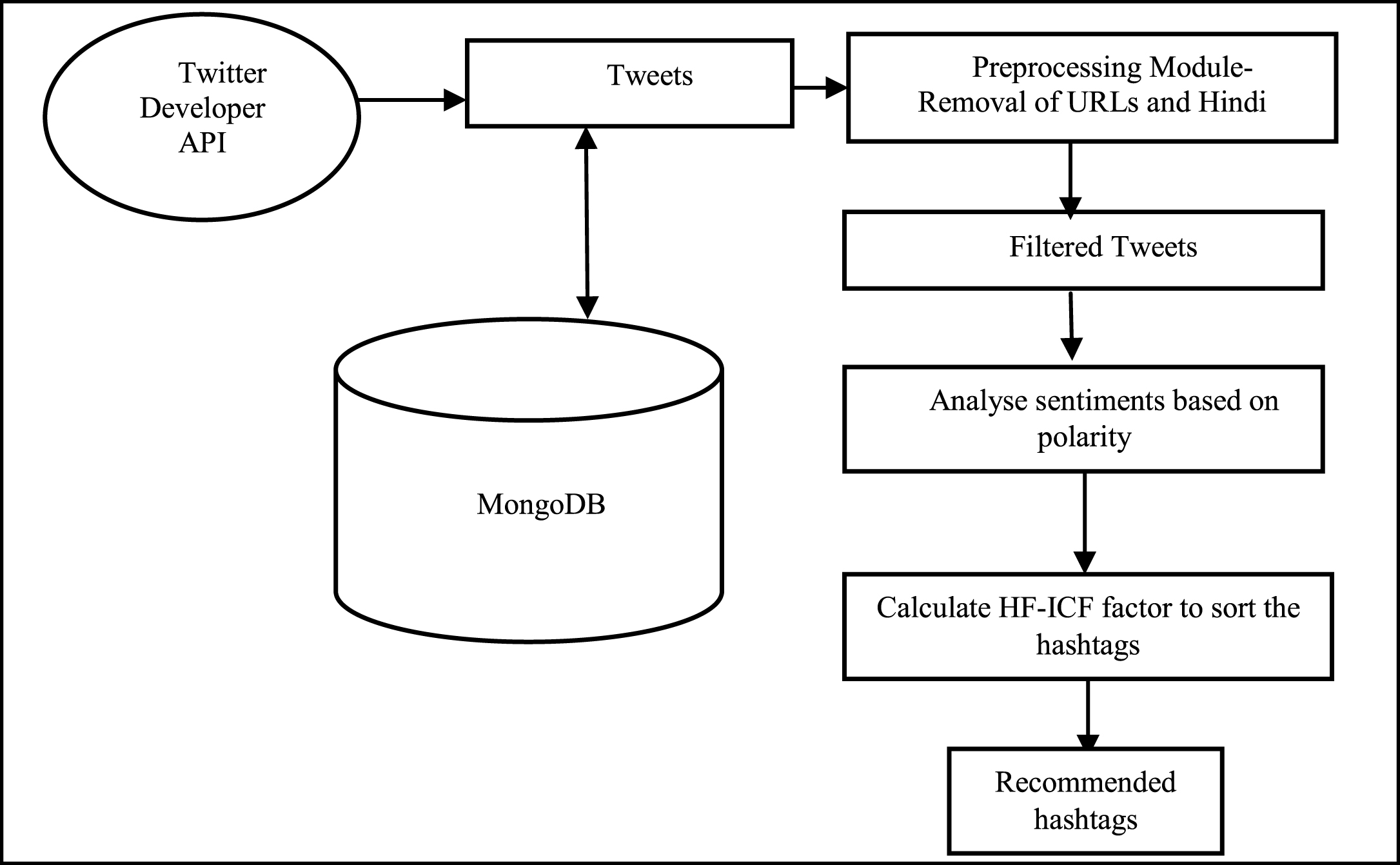
The proposed Community based Hashtag Recommender System (CHRS).
In order to collect data from Twitter, one needs to use the Twitter API and perform the collection process using some hashtags and keywords. In our work, the data have been collected for a significant event in India in 2016 i.e demonetisation. Tweets have been collected with respect to the keyword demonetisation and also for demonetisation associated with other issues like corruption, black money etc. The statistical tool R has been deployed for collecting the tweets and to perform further analysis. R is a language and environment for statistical computing and graphics [11]. R has a large number of statistical and graphical techniques like linear modelling, non- linear modelling, classification etc. In order to store the tweets, MongoDb database has been used. MongoDb is a NoSQL database. MongoDB has a document-oriented data model. The information is stored as documents, which are largely a set of property-names and their values [1]. Once the tweets were retrieved and saved in MongoDb, sentiment analysis was performed on those tweets. On the basis of the sentiment values, the tweets were divided into communities. In these communities, the usernames were discovered. The HF-ICF scores for various hashtags used by the users were calculated. The unseen or unused hashtags in the dataset were finally recommended to the users. This process is further explained in this section. Table 1 gives the detailed algorithm.
Algorithm
Algorithm

Number of tweets for various hashtags and keywords
To begin with the process of data collection, the Twitter app was created and using the API the tweets were collected for the time interval from 8th November 2016 to 30th December 2016. We collected 2,98,284 tweets for a period of almost two months for keywords and hashtags. The details are given in Table 2 above. On applying sentiment analysis, 1,13,810 tweets (after removal of tweets with URLs and tweets in Hindi language) were divided into communities. These communities had distinct usernames for whom the tweets were further collected. The number of hashtags existing in these tweets were found to be total of 14,627. The wordcloud for the collected tweets is depicted in Fig. 2. The structure of a tweet stored in MongoDb is shown by Fig. 3.

The wordcloud for collected tweets.

The tweet structure in MongoDb.
The sentiment analysis of the collected tweets was done using Stanford NLP. Sentiment analysis involves determining the evaluative nature of a piece of text. These may be positive, negative or neutral sentiment. We used the Stanford API to perform sentiment analysis on the tweets.
Calculating Jaccard similarity
The user profiles collected from the above process are arranged in a user-hashtag matrix. In the matrix, h1, h2, h3, h4 … h n ∈ H is the set of hashtags for which the tweets have been collected whereas u1, u2, u3, u4 … u m ∈ U is the number of users used for experiment. In present scenario, n = 9 and m = 28.
The calculation of jaccard similarity between two users is done to discover the user neighbourhood. Jaccard similarity between two users is given as
The user-hashtag matrix has been formulated in a binary format. As stated in their paper by Herlocker et al. [13] when the ratings are in 0-1 format, the 0 value doesn’t necessarily mean that the user won’t like that item. So in the present scenario, the term unary may be used instead of binary because if the user hasn’t used a particular hashtag that doesn’t imply that the user will not like it. Binary items on the other hand have different labels for disliked items.
We hereby propose the idea of Hashtag Frequency- Inverse Community Frequency (HF-ICF) analogous to the idea proposed by Kywe et al. [19] in their work. It is based on the well-known idea of Term Frequency- Inverse Document Frequency (TF-IDF) [23].
We have molded HF-ICF as a weighing model which helps to find the unique importance of any particular hashtag pertaining to the user belonging to community. If the hashtag is frequently used in the particular sentiment based tweets community, the chances for its recommendation are hence more. On the other hand, for the hashtag more commonly prevalent across communities, the chances of recommendation fall. For all the hashtags used by the target user, the product HF-ICF is calculated. The idea of HF-ICF is further explained below.
Hashtag Frequency (HF) – It is used to find the number of times a hashtag has been used by the user in ratio to all other hashtags the user has used in his/her tweets. It is given by
Inverse Community Frequency (ICF) – It is used to calculate the uniqueness of the item across the communities. A hashtag used more frequently gets a low ICF value.
The value of HF-ICF is next used to compute the relevance score of each of the hashtags for every user. The top hashtags are henceforth suggested to the users.
For every user, each hashtag which is unseen/ unused and marked with a ‘0’ in the user-hashtag matrix, the relevance score is found. It uses the factors like HF-ICF and jaccard similarity between two users calculated before. It is given as:
In the above equation,
Number of tweets in each community after sentiment analysis
For the collected dataset of 2,98,284 tweets, sentiment analysis was applied which resulted in a total of 1,13,810 tweets (after removal of tweets with URLs and tweets in Hindi language). The total number of tweets in each of the three categories i.e., positive, negative and neutral are listed in Table 3. The number of users and the number of tweets follows the power law like distribution [18] as depicted by the graph in Fig. 4.
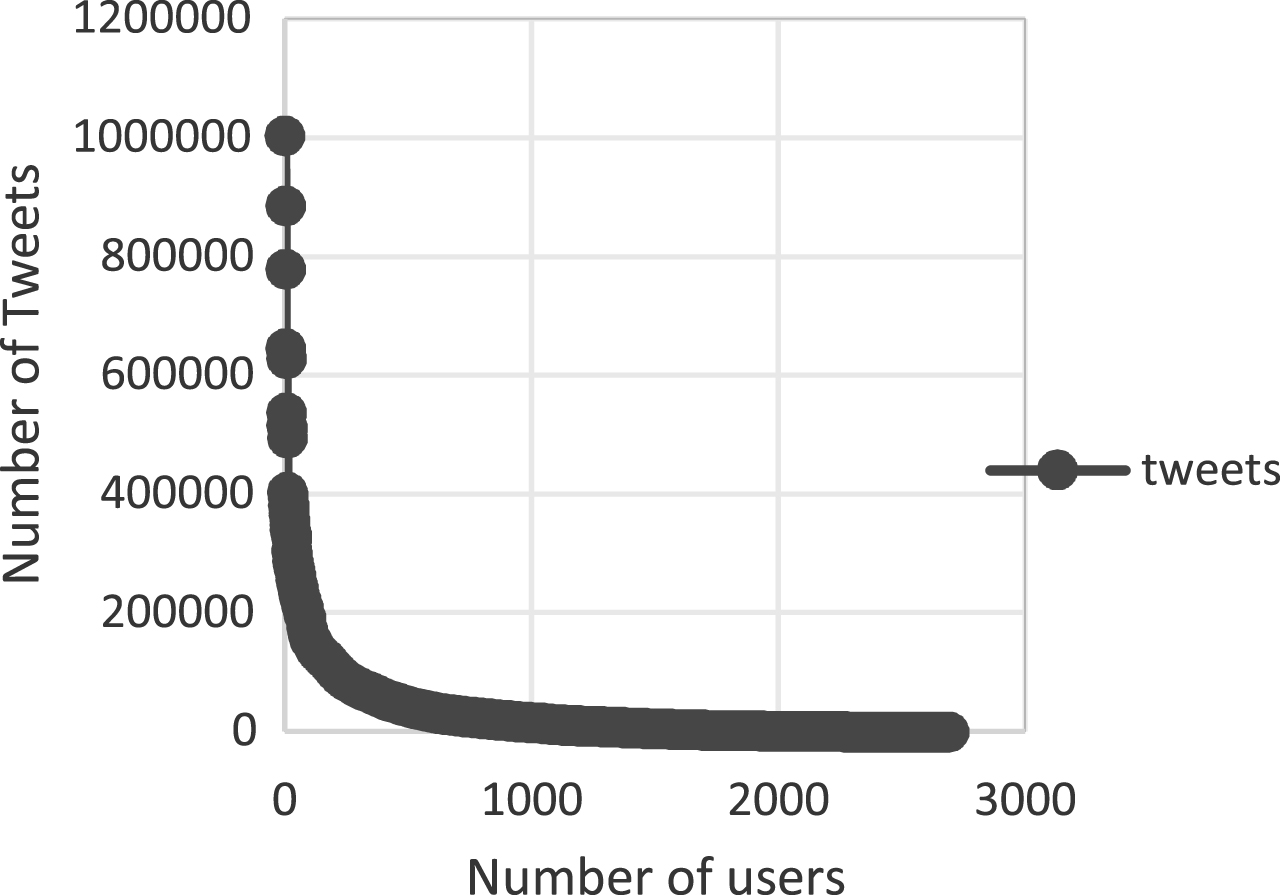
The number of users vs number of tweets.
Once sentiment analysis was performed, the usernames were discovered in the tweets of each three categories. The number of usernames found in each of the above three sentiment based communities are given by Table 4.
Number of users in each sentiment based community
Out of the existing dataset, 28 users were used for experimental analysis. For each user belonging to each of the sentiment based communities, and for every hashtag, the proposed score HF-ICF is found. Relevance score is further computed. Based on this score the hashtags are recommended to the users belonging to the communities.
To evaluate the recommendations, we have used a similar idea as done by Kywe et al. [19] in their work. A random number of tweets for any community are selected as the target tweet set. In these tweets the hashtags actually used by the users are defined as ‘ground truth hashtags’. A hit for a hashtag occurs when one of the ground truth hashtags belongs to the recommended hashtag set. For all the users the hashtags are recommended and then hit rate is computed as given below:
We also calculate the Precision and Recall values for the experiments performed. Precision [13] is defined as
In order to find relevant items, we have defined a certain threshold value for the relevance score. The hashtags above the threshold relevance score are considered as relevant for the users. The Table 5 gives the values of the three metrics used for evaluation.The graph depicting these values is given in Fig. 5.
Precision, recall and hit-rate
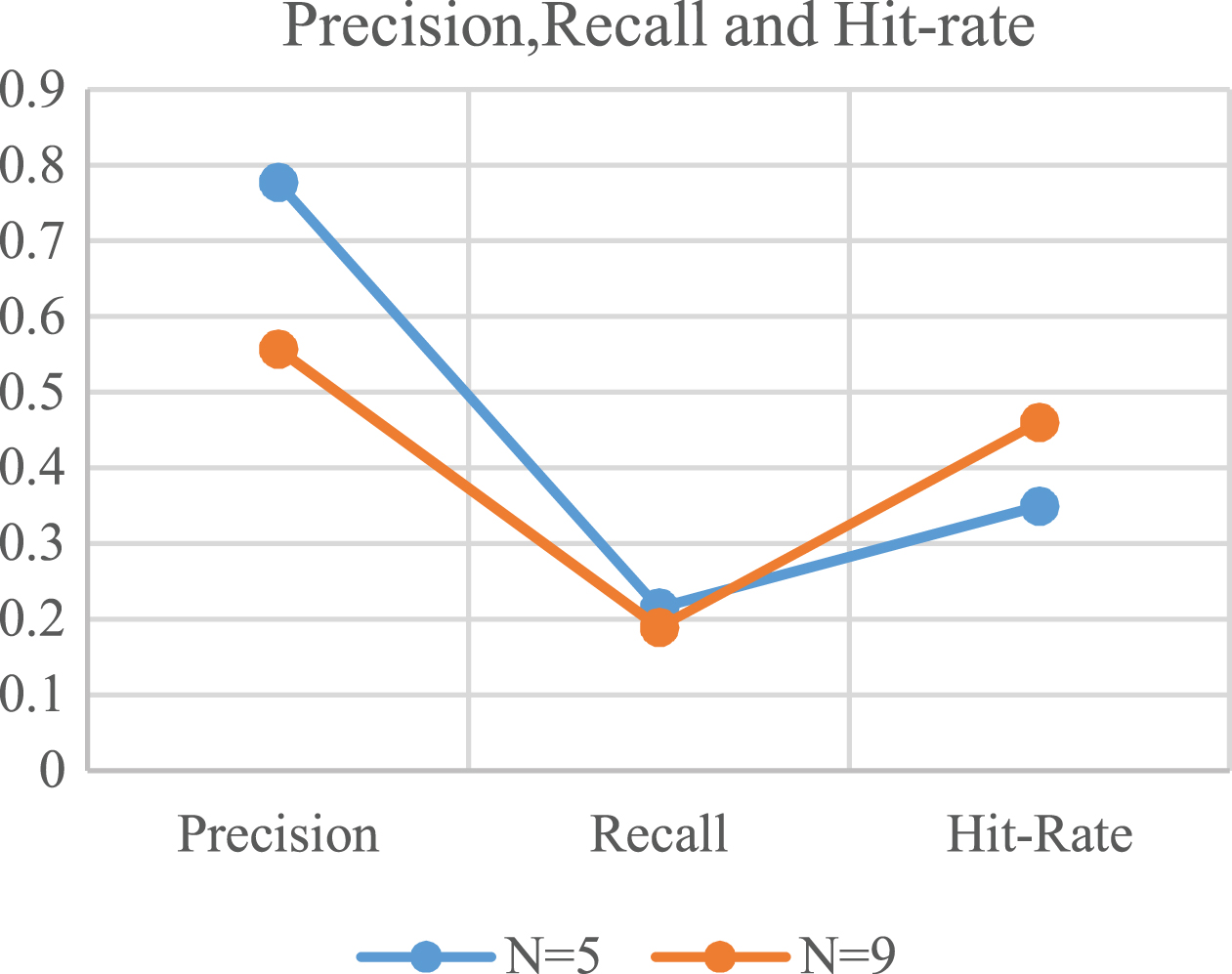
Precision- Recall and Hit-rate graph.
The number of users of the social network twitter, have outgrown the number of people at all other popular microblogging networks. In this work, we presented Community based Hashtag Recommender System (CHRS) to recommend hashtags to users discovered in the dataset extracted from Twitter network. Hashtags which are used to signify some events or specific topics in Twitter, have been used to collect the tweets. The tweets were divided into communities using the well-known process of sentiment analysis. It helps in identifying the polarity of the opinions of the tweets. The usernames were extracted from the tweets. Hence users were assigned to communities based on the polarities of their tweets. Furthermore we presented HF-ICF which is used to find suitable hashtags for each user belonging to various communities. Finally the relevance score was computed and the hashtags were recommended to the users. The idea has been implemented and experimentally evaluated using hit-rate, precision and recall measures. The work can be further extended to suggest recommendations for the community members as whole.