
Abstract
High-dimensional data analysis is quite inevitable due to emerging technologies in various domains such as finance, healthcare, genomics and signal processing. Though data sets generated in these domains are high-dimensional, intrinsic dimensions that provide meaningful information are often much smaller. Conventionally, unsupervised clustering methods known as subspace clustering are utilized for finding clusters in different subspaces of high dimensional data, by identifying relevant features, irrespective of labels associated with each instance. Available label information, if incorporated in clustering algorithm, can bias the algorithm towards solutions more consistent with our knowledge, leading to improved cluster quality. Therefore, an Information Gain based Semi-supervised- subspace Clustering (IGSC) is proposed that identifies a subset of important attributes based on the known label for each data instance. The information about the labels associated with data sets is integrated with the search strategy for subspaces to leverage them into a model based clustering approach. Our experimentation on 13 real world labeled data sets proves the feasibility of IGSC and we validate the clusters obtained, using an improvised Davies Bouldin Index (DBI) for semi-supervised clusters.
Introduction
The basic assumption of Subspace Clustering is that data often contains some types of hidden structures which can be revealed when projected onto various subspaces [1, 2]. This is in contrast to the traditional clustering algorithms that run through all dimensions to identify clusters in full dimensions. The irrelevant features can degrade the cluster quality by hiding clusters in noisy data and mask them as the points seem to be equidistant from each other when dimensions increase (Curse of dimensionality [3]). In order to adapt to such situations, subspace clustering approaches are employed to discover hidden patterns in data in various subspaces. One of the challenging phases of any subspace clustering is to identify a subset of features from data, to characterize different groups [22]. Some of the works related to feature extraction are [5, 22]. Different subsets of features may produce different important hidden structures. If data set is labeled fully or partially, then the labels can aid in the process of investigating different subsets of important features. Moreover, leveraging label information during the clustering process can also make the process of validation reliable. This type of subspace clustering where the information of labels, if available, is used in the process of feature selection, clustering process and cluster validation is called semi-supervised subspace clustering. Semi-supervised Learning [16] can work only if the knowledge about distribution of data obtained from unlabeled data carries the information about class of the data to which it belongs. This is based on the assumption that if points are in the same cluster, then they are most likely to be of the same class. Thus, devising a semi-supervised subspace clustering algorithm has two advantages. The first is the discovery of labels for unknown data and the second is the discovery of subspace clusters that may be more accurate and in accordance with our knowledge of the partially labeled data.
During the past decade, various types of subspace clustering techniques have been proposed. Based on the search strategy, each subspace clustering algorithm can be further divided into SSC (Soft subspace clustering) and HSC (Hard Subspace clustering) [17]. HSC algorithms follow either top down or bottom up approach for subspace clustering. While HSC [8, 10, 15] finds exact subspace clusters, SSC [4–6] attempts to find contribution of each dimension in the clustering process.
The above mentioned algorithms have two obvious disadvantages. The feature selection strategy used, do not leverage the label information, if available. The subspace clusters formed without considering the labels of the available data, D
l
, may be inconsistent with D
l
. Hence the clustering should be modified to achieve consistency with D
l
.
In order to overcome the above two problems, a top down semi-supervised subspace clustering approach is proposed in this paper that takes into consideration the available labels of the dataset, to rank each feature so as to find important subsets of features pertaining to each cluster. Instead of learning feature weight through an iterative process which is computationally expensive, we use information gain of each attribute, corresponding to available labels, proposed by Quinlan [7]. Hence the name IGSC (Information Gain based Semi-supervised-Subspace clustering). Thus the semi supervised approach, using information gain for selecting relevant attributes, will help us in finding better subspaces and hence clusters in high dimensional data. We conduct experiments on thirteen real world labeled datasets and our approach is compared with two subspace clustering algorithms, PROCLUS and CLIQUE, and a traditional clustering algorithm, K-means. The validity of our proposed approach is demonstrated by experimental results. The contributions of our work include the following. Formulation of a new strategy to find important features by explicitly incorporating the information about labels using the information theoretic approach of entropy and information gain. Integrating the feature selection process into a top down subspace clustering approach to form subspace clusters in consistence with the knowledge about the labeled dataset.
The rest of the paper is organized as follows. Section 2 briefly describes related work in this area. Section 3 introduces the new proposed model IGSC and devised algorithms. Extensive experiments conducted to prove the feasibility and effectiveness of proposed work, are explained in Section 4. We conclude the paper in Section 5.
Related work
In this section we brief the trends in subspace clustering by reviewing some of the relevant works in this area. We try to bring out the pros and cons in existing algorithms and explain how our approach differ from the existing works.
Based on the approach of finding subspaces, Subspace Clustering (SC) can be classified in to Soft Subspace Clustering (SSC) and Hard Subspace Clustering (HSC). While HSC finds exact subspaces, SSC can be considered as an extension of feature weighting clustering. HSC can be further classified into Bottom-up and Top-down approaches.
In Bottom-up approach, clusters are discovered from lower to higher dimensional space. Some of the Bottom-up approaches include, CLIQUE [15], SUBCLU [14] and MAFIA [18] These algorithms make use of downward closure property of density and hence reduces the search space. CLIQUE divides the number of dimensions into non-overlapping grids and finds the dense regions according to given threshold. On the other hand, SUBCLU searches for objects that are density-connected and in contrast to other grid-based algorithms, it detects arbitrarily shaped and positioned clusters in subspaces. The Top-down subspace clustering begins with a full dimensional search for clusters in the given data space. Subspaces are then identified in the corresponding iterations, by assigning weights for dimensions in each cluster. PROCLUS [8], FIND-IT [10] and δ-CLUSTERS [11] are some of the Top-down subspace clustering algorithms. PROCLUS finds initial clusters in full dimension and later appropriate subset of dimensions are determined. An extended version of PROCLUS, known as ORCLUS [9] is another top-down subspace clustering algorithm that identifies non-axis parallel subspaces. The strategy of finding relevant dimensions in FIND-IT is based on two ideas. First, using a Dimension-Oriented Distance (DOD) measure and second, a dimension voting policy. In δ-CLUSTERS, a cluster model is proposed that exhibits some coherent tendency.
Soft subspace clustering identifies the contribution of each dimensions in cluster generation. Various SSC algorithms assign weights to attributes depending on which the subspace clusters are formed. Some algorithms identify subspace first and later forms the clusters. Some assign weights to all dimensions according to the degree of relevance. Kohavi et al. [4] and Langley et al. [5] described the concept of relevance of attributes and have proposed the classical feature selection methods- Filter and Wrapper Model. Convex K-means [19] utilizes a separated feature weighting method by defining a set of viable weight groups before data clustering is performed. Fuzzy Subspace Clustering (FSC) [20] is another classical SSC where clustering is performed by assigning a fuzzy weight to each dimensions of different clusters. A method of attribute weighting was also described by Langley et al. [5]. Another approach of feature weighting method based on information gain was described by N.F. Ayan [6].
In all these works, the usage of labels, if available, are not taken into consideration. But if data labels are available then leveraging such information for subspace clustering can not only be useful for validating clusters, but can also enhance the learning process to be consistent with the available knowledge. Hence our work adopts entropy and information gain with respect to the knowledge about the available labels to guide the significance of important attributes leading to subspace clusters. Influenced by the concept of Soft subspace clustering, where contribution of each individual feature is taken into consideration, we propose IGSC, an Information Gain based Semi_supervised_subspace clustering algorithm that follows a top down approach similar to [8].
Background
In this section, we briefly describe Entropy and Information Gain, an information theoretic measure, which we utilize in our proposed model for finding significant features for a subspace cluster. This is followed by a short review of PROCLUS [8], which is adapted for our model.
Entropy and information gain
Entropy [7] can be defined as a measure of uncertainty of a probability distribution. It is also defined as the impurity of an arbitrary collection of examples. Let E = {E1, . . . , E
n
} be a set of events each with probability of occurrence p
i
such that
Information gain is a measure of change in entropy when new information is obtained. Thus it aims at reducing the entropy of system with availability of new information. We leverage the concept of information gain to find the significant attributes of a subspace cluster by partitioning the partially labelled dataset in an optimal way as explained in later sections. Formally, we define information gain as follows.
Information Gain: Let D denote a set of N examples and let P denote a set of c classes. Pr (p
i
, D) denotes the fraction of instances in D, which belongs to class p
i
∈ P. The included information is obtained by:
Let D
i
be the set of examples having value v
i
for attribute a
i
. Let v be the number of distinct values for attribute a
i
. Then, the information obtained by considering a
i
as a significant attribute, is achieved by:
The information gain is obtained by,
Review of projected clustering
Given a set of data points, D, the algorithms that aim at finding a unique assignment of each point to exactly one subspace cluster are called projected clustering algorithms [1]. PROCLUS [8], FIND-IT [10] and δ-CLUSTERS [11] are projected clusters. We adapt PROCLUS [8] to make it suitable for our proposed model. PROCLUS finds axis parallel subspaces by following a top down approach thereby conquering the exponential search space of all possible subspaces. The principle of top-down approaches is to do a initial clustering on full-dimensional space based on potential set of representative elements, such that the points meet the given cluster criterion when projected onto the corresponding subspace. Most top-down approaches assume that the subspace of a cluster can be derived from the local neighborhood (in the full-dimensional data space) of the cluster representative. Thus, broadly there are three main phases. First, to identify the potential cluster representatives for formation of initial clusters in full dimensions. Second, iteratively forming the local neighbourhood and finding the subspaces until the objective function is met. Third, to refine the subspace clusters formed.
Our proposed model differ from the above strategy in two aspects. The first one is leveraging the concept of information gain at the local neighbourhood to identify the important attributes that can help in the formation of subspace clusters. The second one is the objective function that aims at reducing the entropy of the subspace clusters. Thus we ensure that the information about labels, if available, are utilized to form subspace clusters in consistent with the knowledge about the dataset.
Semi-supervised subspace clustering
Semi-supervised subspace clustering can not only help in forming subspace clusters consistent with the labeled dataset, but can also aid in modifying and extending the labels to reflect the hidden structures in low dimensional data. The proposed model searches for a good partition by formulating an objective function that aims at minimizing the entropy of each cluster.
Problem formulation
Let D be a dataset in d dimensions with each element t ∈ D defined by a set of attributes A = a1, . . . , a d , y. Each instance t is labeled with y = p i or unlabeled with y = 0, where p i ∈ P = {p1, . . , p c }, with c being the total number of class labels. We define subspace cluster S i as a cluster of elements that are most similar to each other with respect to a representative element m i ∈ D, called medoid, with label p i along dimensions A i ⊂ A, where |A i | = l and l ≤ d. In this context, an objective function F is devised to find an optimal set of K subspace clusters S = {S1, . . . , S K } so as to reduce the entropy of each subspace cluster S i in A i dimensions with m i as the medoid.
Let K denote the number of clusters, M ⊂ D denote the set of potential representative elements called medoids and P denote the set of class labels with |P| = c. Each subspace cluster S
i
is defined by a subset of dimensions A
i
⊂ A and a medoid m
i
∈ M. Then, the objective function F is defined as a minimization function given by Equation 1.
Here, H (S i , P) is the entropy of the cluster S i with dimensions A i and medoid m i with respect to the available set of labels P. Pr (p j , S i ) is the probability of an instance being classified as p j , in cluster S i . The notations used in our paper are listed in Table 1.
Notations used in the Algorithm
The minimization of the objective function is primarily driven by the importance of features in each subspace cluster. Here we leverage the information about labels, if available, to seek important features that can aid in exploring hidden structures in subsets of features of dataset. This is achieved by finding the role of each attribute in labelling each instance. We use the theory of entropy and information gain to weight the significance of each attribute.
We propose an information theoretic approach, IGSC (Information Gain based Semi-supervised subspace Clustering) for formation of subspace clusters from partially labeled dataset. Our approach consists of three phases, namely, Medoid selection, Iterative semi supervised subspace extraction, and Cluster Refinement as given in Fig. 1. The process of finding semi-supervised subspace clusters involve two challenges. Firstly, a potential set of elements is to be sought to form representatives for each subspace cluster. Secondly, most informative attributes that forms the subspace clusters are to be found out. The solution approach follows a top down approach of subspace clustering.
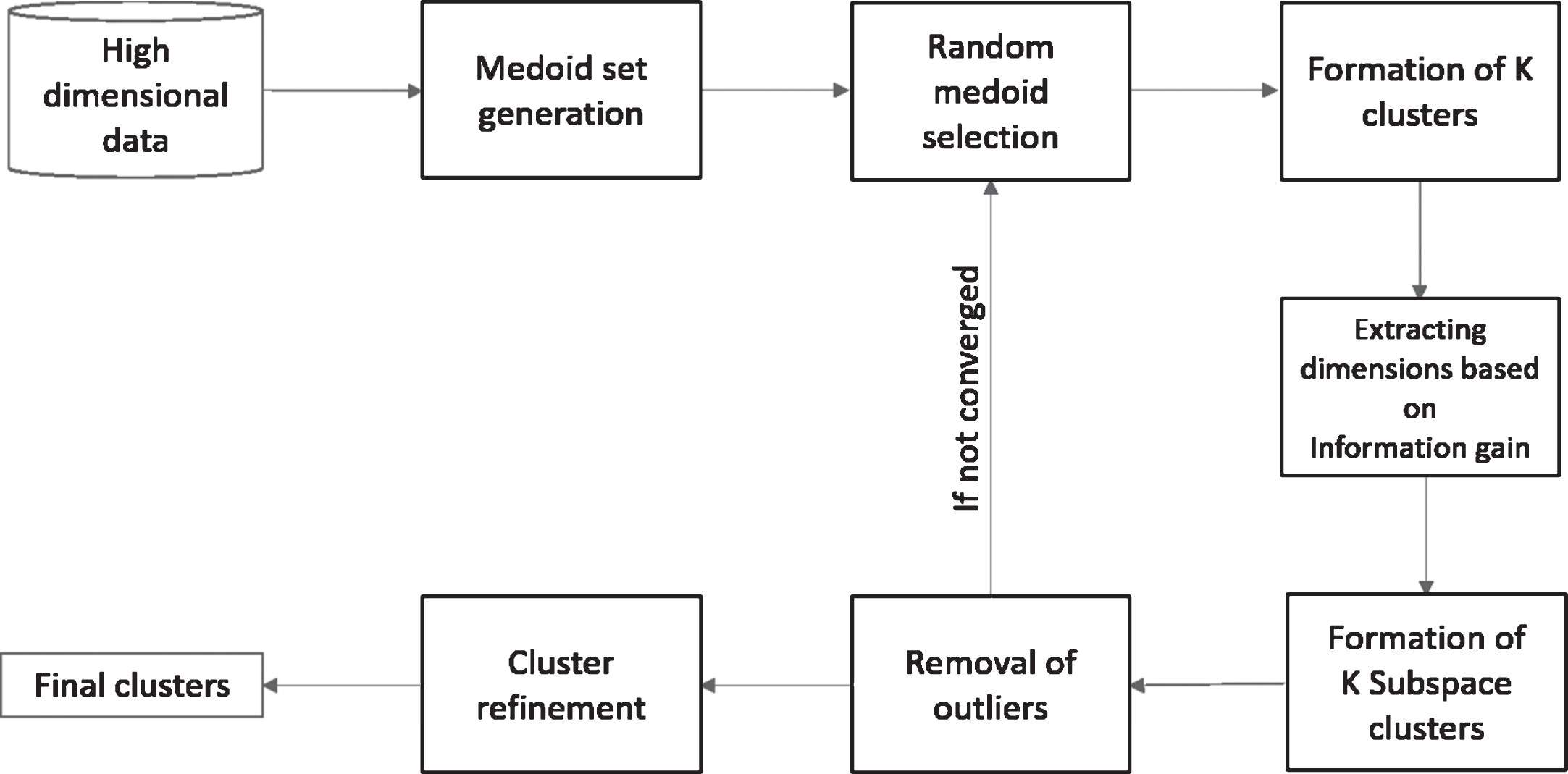
Block Diagram of proposed model for semi-supervised subspace clustering based on Information Gain (IGSC).
A) Initial Clustering: This phase is to find a potential set of elements that can serve as representatives for subspace clusters. We ensure that only labeled instances from D are used to form these representatives. This set of potential representatives called medoids are chosen in such a manner that each of the medoids are farthest from each other. We use L1 norm distance metric to find the farthest medoids in high dimensional dataset due to its characteristics like robustness to outliers and enforce sparsity. For high dimensional data, the meaningfulness of the L p norm worsens faster as p increases [23]. Hence in our approach we use L1 norm which is preferable than L2 norm in high dimensional data. A greedy technique [8] is adopted to extract maximum distant medoid set M of size |M| > K. This approach helps in forming the initial clustering in full dimensions.
B) Iterative Semi-supervised Subspace Extraction: Semi-supervised subspace clustering can not only help in forming subspace clusters consistent with the labeled data set, but can also aid in modifying and extending the labels to reflect the hidden structures in low dimensional data. The proposed model searches for a good partition by formulating the objective function that aims at minimizing the entropy of each cluster. The relevant features are found by measuring the uncertainty of each feature and information gained by including each feature in deciding the label of an instance.
In this phase, randomly K medoids are selected from medoid set M. Each of the K medoids are used to generate clusters in full dimensions. Based on this initial clustering, we apply information gain approach to rank each feature. For each cluster generated, we discretise the features in order to transform the continuous value to discrete ones. Discretization generally help to improve the classification performance of algorithms that are sensitive to the dimensionality of the data [13]. We use Fayyad and Irani’s MDL method [12] that is entropy- based supervised discretization algorithm. Discretization enhances the amount of information we get from the data. For each discretised features, we find the Information Gain. The feature with highest Information Gain is given highest weight (rank). The algorithm then advances as follows: Med current stores the randomly generated K medoids, and dimensionSets stores the relevant dimensions to generate subspaces with respect to each medoid. Each medoid is associated with respective subspaces and the formed semi-supervised subspace clusters are evaluated using Entropy as given in Equation 1. Those clusters that have data points less than 1% of |D| are considered as outliers and the corresponding medoids are replaced with new medoids, randomly selected from the M. These are then stored in Med best . This process continues iteratively until a termination criterion is reached as given in Algorithm 1. Algorithm 2 describes the selection of a set of attributes that contribute significant information about the dataset. We restrict the attribute selection using a minimum threshold, l thus, instead of undergoing a full dimensional comparison, now we only need to consider a subset of important attributes.


C) Final Refinement: Dimensions and cluster assignments from iterative phase are passed through another refinement phase (see Algorithm 3) to improve the cluster quality. For each medoid, m i and corresponding dimension A i , we find least Manhattan distance δ i to one of the (K - 1) medoids corresponding to A i . Points outside the sphere of influence with radius δ i and dimensions A i , are considered as outliers for the respective clusters.

In this section, we present our experimental results and comparison of our semi-supervised subspace clustering algorithm with two subspace clustering algorithms namely, PROCLUS and CLIQUE as well as with a traditional clustering approach K-means, to show the effectiveness of our proposed work.
The experimentations were conducted on a machine with 2.8 GHz/1.9 GHz AMD Quad-Core processor, with 6 GB of RAM. We used weka 3.8 together with OpenSubspace (Weka Subspace- Clustering Integration) for comparing various algorithms with our approach. The performance is measured in terms of Scalability and Cluster quality.
We used the following parameters in our empirical study: size of the dataset |D|, number of subspace clusters K and average dimensionality of each subspace cluster l to demonstrate the effectiveness of our proposed algorithm. For scalability, we replicated few datasets like Pen digits and Synthetic datasets both in terms of dimensions and number of instances. The proposed approach was then applied on the datasets to determine how the running time and the cluster quality varied with |D|, K and l.
These 12 real world data sets are high dimensional with dimensionality varying from 9 to 27, 680 and number of instances from 34 to 8000 as shown in Fig. 2. For scalability experiments, we replicated the instances of Pendigits and Synthetic datasets upto 400000 records. Multi-Interval discretization using MDL method [12] was used to discretize the continuous valued attributes of the datasets.

Data sets used for experimentation.
In this section the experimental results based on the observations are discussed.
For a given clustering, our custom DBindex is defined as follows,
Here, |K| is the total number of clusters,
Figures 3 and 4 represents the confusion matrix generated for Synthetic datasets and Pen digits with number of clusters equal to the original number of classes defined for the dataset.
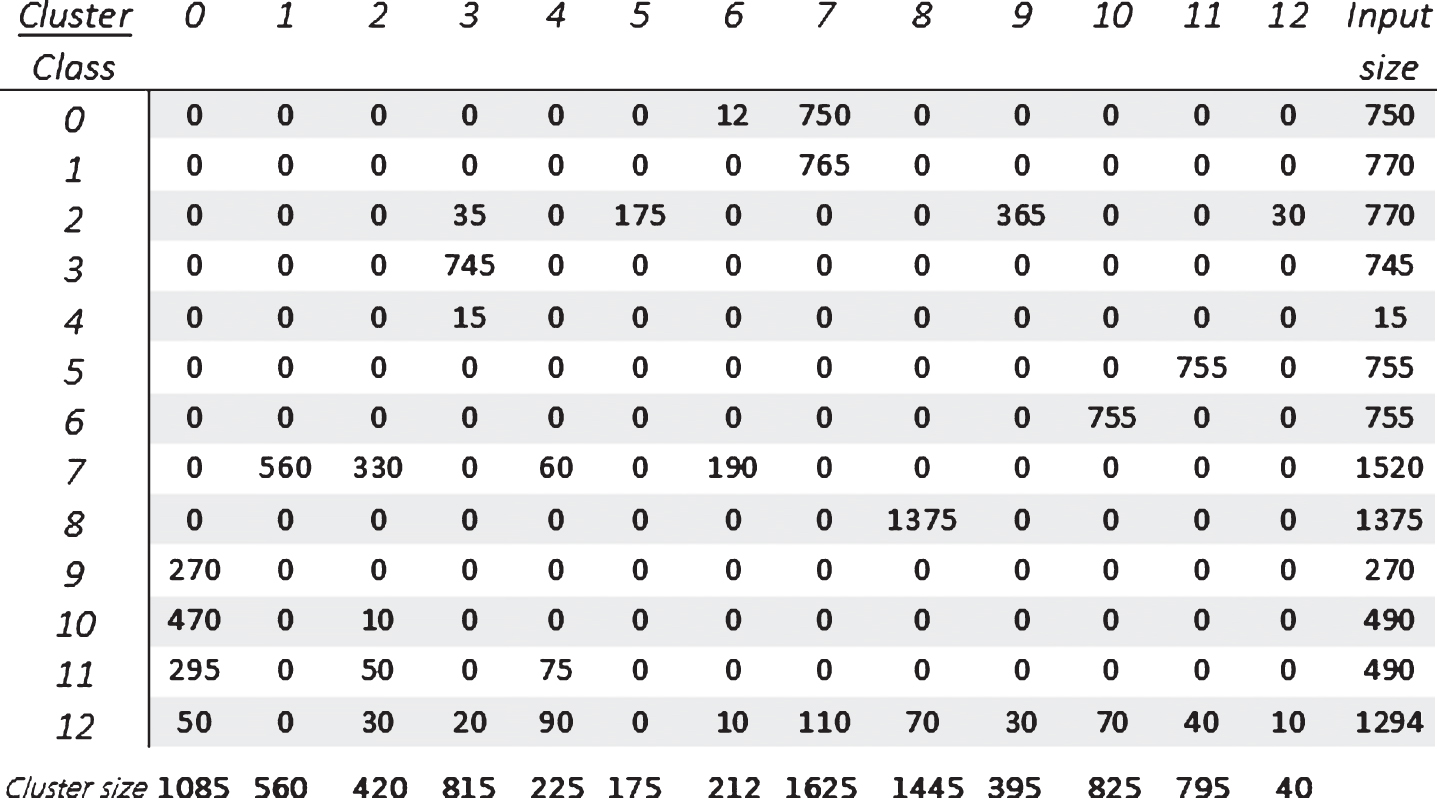
Confusion matrix with rows representing class labels p i and columns representing the number of instances in each cluster with class label p i of Synthetic dataset, with avg. dimensions l = 15.
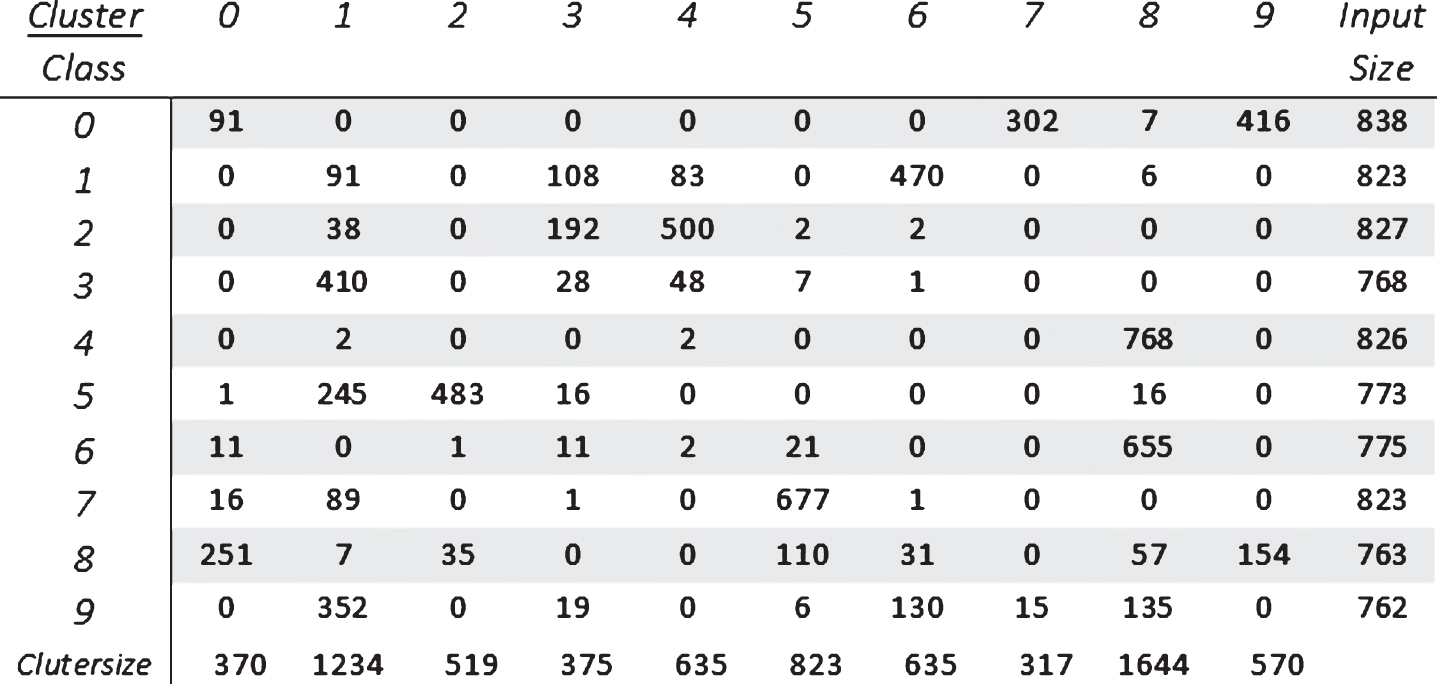
Confusion matrix with rows representing class labels p i and columns representing the number of instances in each cluster with class label p i of Pendigits dataset, with avg. dimensions l = 15.
Table 2 shows the purity and DBI measures of subspace clusters formed. IGSC outperforms subspace clustering algorithm PROCLUS when both the number of clusters and number of features are high for ECML and B_cell2 dataset. We find that purity measure of our proposed model IGSC is quite good for datasets with very high dimensions such as ECML and GCM. But for low dimensional dataset pen_digits and Glass, the information gain approach does not give very significant results. This is because for low dimensional dataset, the contribution of attributes are equally likely in knowing the labels of instances.
Comparison between clustering methods of IGSC, PROCLUS and K_Means approach on 13 datasets from UCI repository. Parameters K are tuned to be set as the number of classes P for each dataset and the average number of dimensions per subspace cluster l = d/3. † and ‡ shows that IGSC outperforms other methods in purity measure and DBI measure respectively

Comparison of Proposed approach with PROCLUS, KMEANS, and CLIQUE based on Accuracy measure F1-measure.
This empirically validates that the information gain for subspace clustering plays an important role in improving the accuracy.

Comparison of Proposed approach with PROCLUS, KMEANS, and CLIQUE based on Cluster evaluation metric Entropy.

Comparison of Proposed approach with PROCLUS, KMEANS, and CLIQUE based on Execution time in seconds.
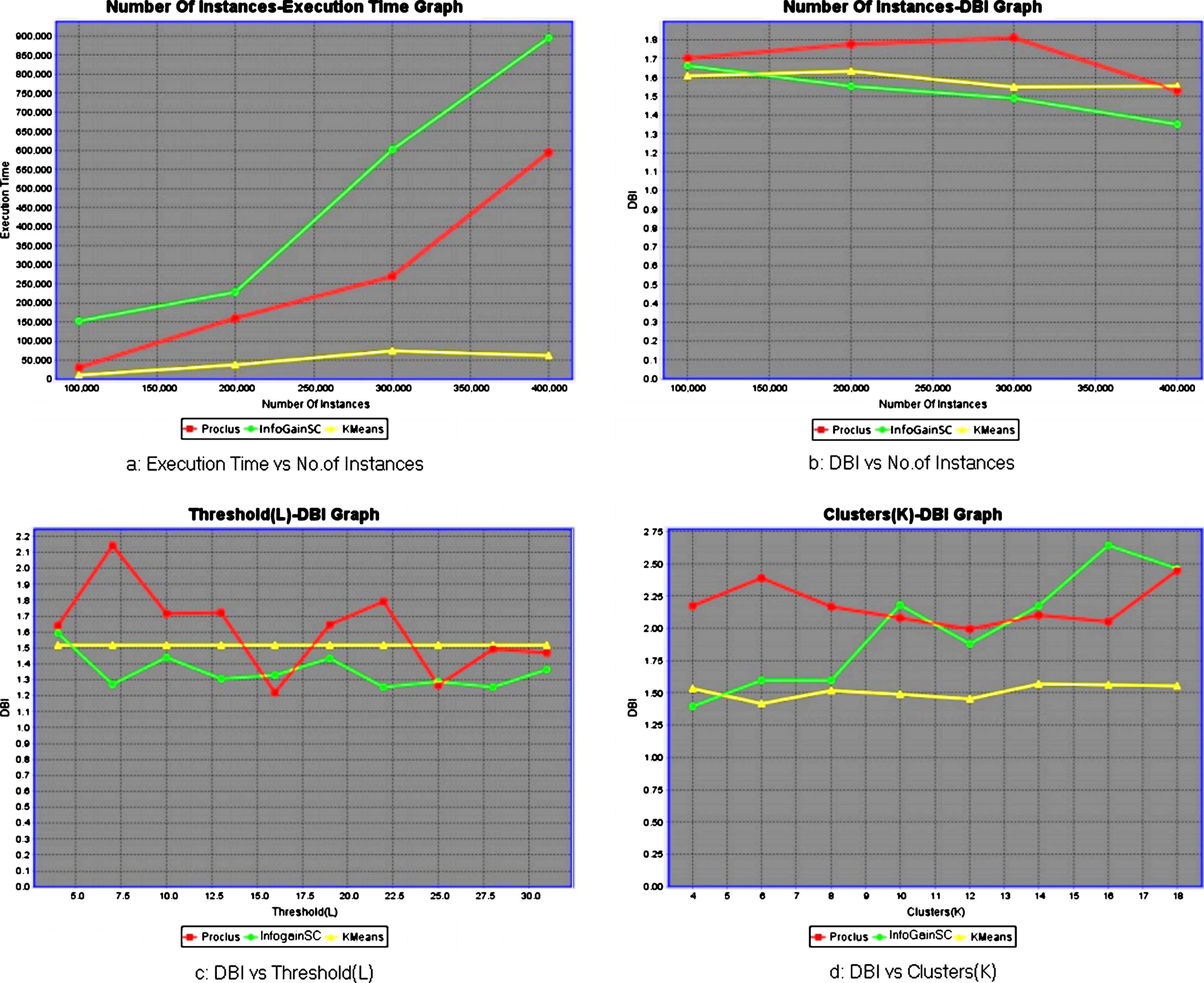
(a): Execution of IGSC by varying |D|, (b)– (d): Evaluation of subspace clusters, formed by proposed model IGSC for Pendigits dataset, based on modified DBI measure, by varying |D|, l, and K.
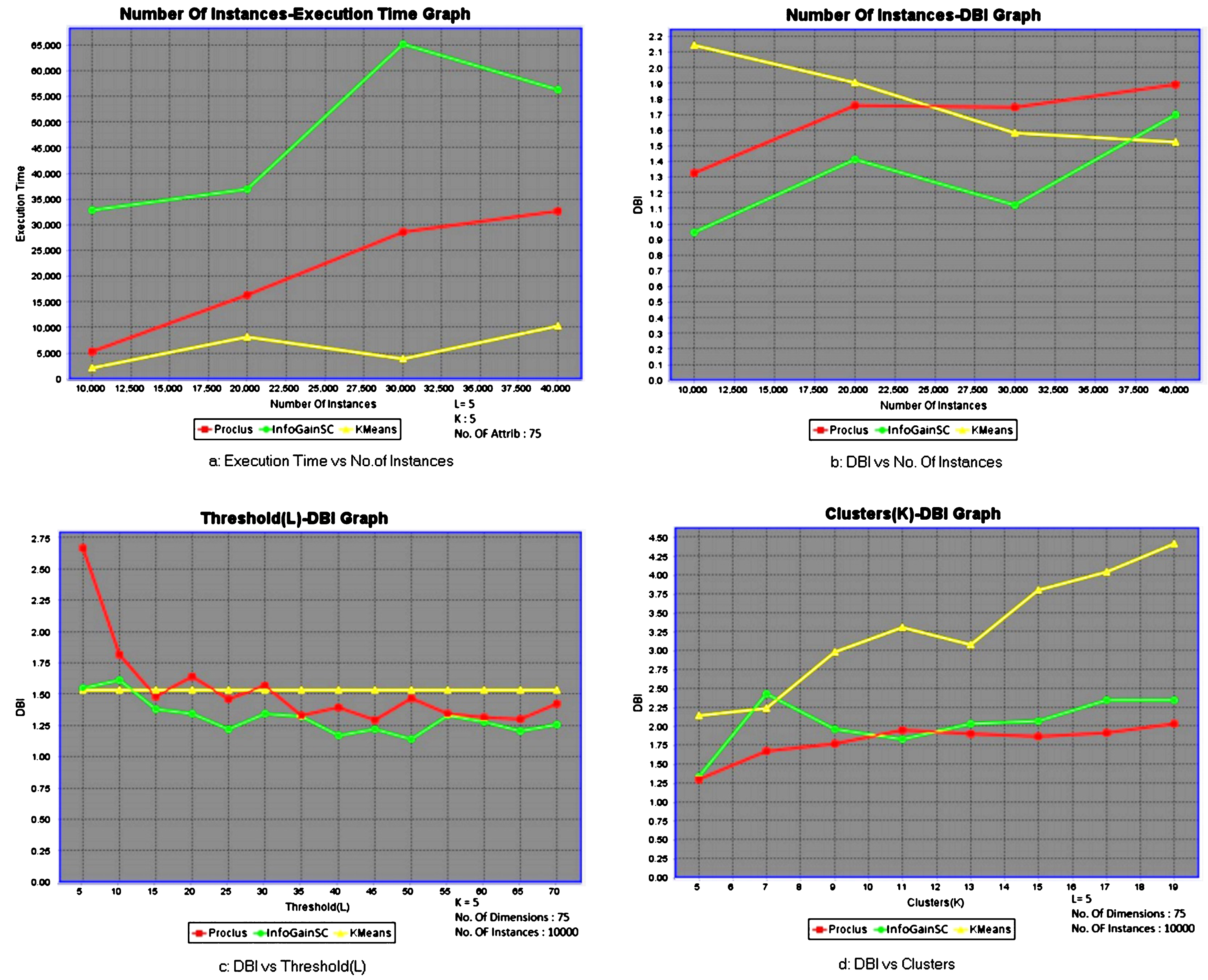
(a): Execution of IGSC by varying |D|, (b)– (d): Evaluation of subspace clusters, formed by proposed model IGSC for Synthetic dataset, based on modified DBI measure, by varying |D|, l, and K.
We presented a semi-supervised subspace clustering algorithm, by a novel attribute selection strategy, for high dimensional partially labeled datasets. A top down approach of subspace clustering using ranking for attribute extraction in high dimensions is introduced as a new concept. This novel attribute selection technique together with subspace extraction has been conducted in such a way that the data is neither transformed nor does it lose its structure. Rigorous experiments have been done to compare the performance of our proposed method with other subspace clustering algorithms. The feasibility of incorporating the concept of information theory for subspace selection into high dimensional dataspace is established by the experimental results. The empirical results indicate that our approach generated comparable results with respect to traditional methods. The future scope lies in improving the excecution time and extending the approach to non numerical datasets.
Footnotes
Acknowledgments
The authors would like to thank Dr. M.R. Kaimal of the department of Computer Science, Amrita Vishwa Vidyapeetham for his valuable suggestions in improving this paper.