
Abstract
This paper presents a system for improving the quality of pronunciation error detection and correction for Qur’an recitation by Non-Arabic speakers. Most of the classical speech recognition systems are built using the Hidden Markov Model (HMM) with a Mixture of Gaussian Model (GMM). This paper attempts to enhance the GMM-HMM model’s performance by using Deep Neural Networks (DNNs). The major part of the work done in this paper is involved in the collection and processing of speakers’ data, and building and evaluation of baseline GMM system and the proposed DNN acoustic models for the Qur’an recitation framework. With the aim of solving some pronunciation problems and enhancing the overall performance of such a speech recognition system, we replace the mixture of Gaussians with a DNN. The DNN-HMM model outperforms the GMM-HMM model by 1.02% based on HTK’s word accuracy equation. By calculating the insertion results for both models, DNN-HMM showed progress by 2.59%. In addition, in substitution results, DNN-HMM shows progress with the confusion phonemes DAA by 15.09% and DHA by 17.28%. All experiments and results are presented and discussed in detail.
Keywords
Introduction
Speech recognition is a technique that enables a computer to receive, to analyze human speech, and to execute relevant procedures. Speech recognition is widely used in many applications around the world. Voice dialing [1], speech-to-text processing [2], and language learning [3] are some examples of these applications. Automatic Speech Recognition (ASR) can also play an important role in Qur’an recitation.
Problem’s domain and the importance of the idea
“The Holy Qur’an remains as the most read, revered, memorized, and respected book in the world” [4]. Another important field in the Qur’anic world is recitation. Millions of Muslims around the world are keen on reciting the Holy Qur’an every day. However, there are rules of pronunciation, intonation, and caesuras that must be respected by the reciter to perform the recitation correctly. These rules, known as Tajweed rules, are themselves a study [5]. Although there are numerous teachers who know these rules and can teach them, many people cannot recite the Qur’an correctly because of certain limitations and restrictions. Moreover, people who have already memorized the Holy Qur’an must recite it from memory and confirm that they do not miss any of the verses. Therefore, supporting this holy book and contributing to this field involves helping millions of people around the world.
Application to be enhanced
Many applications have been created to facilitate the recitation, the understanding, and the memorization of the Holy Qur’an. HAFSS© is one of the best applications handling most of the reciting rules. “HAFSS© is teaching the correct recitation of the Holy Qur’an” [6]. One of its features is to detect errors in user recitation [6]. The accuracy of error detection is one of the factors that differentiate between one ASR and another.
Another factor is the speed of input manipulation. The best application, yet to be developed, would act exactly like a human being. Existing applications must be improved in many ways to reach this level of accuracy and speed.
This research attempts to tackle some of the pronunciation problems with Qur’an recitation. Although these types of problems usually occur with non-Arabic speakers, native Arabic speakers also need some pronunciation correction in recitation. We will attempt to solve some of these problems and enhance the performance of the HAFSS© application using Deep Neural Networks (DNNs) [7], one of the best models used for speech recognition.
HAFSS© is a speech-enabled Computer-Aided Pronunciation Learning (CAPL) system. The Hidden Markov Model (HMM) used in HAFSS© is a triphone tied-state model [8], in which each state is modeled by a mixture of Gaussians [9]. GMM has some limitations and issues that will be discussed later. Therefore, replacing GMM with DNN can overcome some obstacles and enhance the accuracy. However, the most critical and complex part of using a DNN is its learning process.
To solve some recitation problems in the current version of HAFSS© and to enhance the performance of this system, the mixture of Gaussians will be replaced with a trained DNN [11]. Comparing the two techniques and showing some experiments and results will confirm the expected enhancement in performance.
In the following sections of this paper, Section two is about related work. Section three shows the data collection methods & preparation. Section four describes how to build an HMM with Gaussian Mixtures. Section five describes how to build an HMM with DNN Model. Section six includes experiments and results. Section seven includes conclusions and future work.
Related work
GMM-HMM is the most popular and the winner among all other models in ASR’s field, which started in the 80s till early 2000s. However, Li et al. [12] asserted, “GMMs are statistically inefficient for modeling data that lie on or near a nonlinear manifold in the data space” [12, p. 314]. DNN– HMM for speech recognition is the technique most discussed in recent studies. Mohamed, Dahl, & Hinton [13] represented two types of Deep Belief Networks (DBN). The two types are the backpropagation DBN (BP-DBN) and the associative memory DBN (AM-DBN). Both architectures have mechanisms to avoid overfitting. By changing model depth and hidden layer size both architectures could achieve the best results. Both types of DBN outperform other reported results on the TIMIT core test set by about 1%.
Two important results have been reported in [14]. First, DNN– HMMs outperformed GMM– HMMs in both syllable-based and phone-based ASR at different rates. Second, context-independent syllable-based DNN– HMMs obtained the best performance in experiments for left-context syllables. According to Pavelka & Ekštein [11], “the neural network triphone acoustic model clearly outperforms all other models,” [11, p. 297] a claim that remains to be verified.
The number of hidden layers to be used in each DNN application is problematic. However, Li et al. [12] exposed part of the mystery when they confirmed that the increase in hidden layers is not always directly proportional to the efficiency. On the contrary, at some point, it either has no effect or has negative consequences. Comparing with GMM– HMM and many other models, DNN– HMM models with discriminative pre-training and five hidden layers obtain the best results.
The most important resource that tends to be the foundation of this research is introduced by Abdou, et al. [6]. That work has a full description of HAFSS© , including the system’s structure, methodology, and evaluation. The work is targeting Arabic speakers as it was clearly mentioned. One of the factors in ASR is speech analytics or how speech is to be analyzed. Two approaches are discussed here, LVCSR and phonetics.
Although some studies, such as [15], verified that phonetics took precedence over LVCSR, the result depends on the ASR problem on hand. When the problem has limited grammar, and the performance is an important factor, then phonetics will be an excellent choice. LVCSR can be a good choice for an open domain with thousands of words requiring analysis.
Wu, C.-H. [16] discussed a system with long stages resulting from code-switching between English and Chinese. The integration of the acoustic and context-dependent articulatory features (AFs) has been installed in a phone set construction for a Chinese– English code-switching ASR. AFs are extracted using a DNN-based AF detector. Acoustics-based HMMs and AF-based GMMs are used in model training. The proposed method achieved better recognition accuracy and more stability with the help of context-dependent AFs than traditional phone set construction methods. The results were determined based on frame accuracy.
Although Alghamdi, El Hadj, & Alkanhal [17] have the same aim to automate the reciting process of the Holy Qur’an, they focus mainly on data preparation. They introduced a new transcription covering all Arabic phonemes to be used mainly on an HMM system. Gaikwad, Gawali, & Yannawar [18] also use Qur’an recitation in experiments to evaluate the results, but the primary aim of their paper is to present the feature extraction methods. Most of the extraction methods are discussed in detail with their strengths and weaknesses. Their study concludes that Mel-Frequency Cepstrum Coefficients (MFCC) with GMM– HMM provide the best model to use in speech recognition. However, there is no information about the number of reciters or the training data. Moreover, there are no tables or statistical results shown.
The study, [19] is related to our research domain since the Holy Qur’an is the main subject. The open source framework, Sphinx-4 [20] was used as the basis for that study. All Arabic phonemes were used as training data to train an HMM. The only recognition data was Surah “Al-Ikhlass,” which contains four verses. The previous Surah has been repeated by many speakers, many times by each speaker. Finally, two types of results were shown. One was a comparison of the two types of recitation, i.e., “Tajweed” and “Tarteel,” based on recognition ratio. The second was a comparison of the male and female waves also based on recognition ratio. The results showed a preference for “Tarteel” over “Tajweed” by 2% and male waves over female waves by 5%. The only disadvantage of that study is the dearth of training and recognition data.
Among the few studies that relate to our domain, Muhammad, et al. [21] is the most closely related. The paper has an objective to find a trustful electronic master or teacher for Qur’an. E-hafiz is the name of the proposal system that has been produced. The following training methods have been discussed in their related work section: Hidden Markov Model (HMM) Artificial Neural Network (ANN) Vector Quantization (VQ)
The authors recommended HMM for feature extraction. However, for training or testing either VQ or HMM can be used. In the recognition process, HMM was used for Arabic Language and VQ for the English language. However, the used training data was insufficient to establish a stable system and to adopt the results.
According to Chelba, Bikel, Shugrina, Nguyen, & Kumar [22] enhancing the above points can improve the word error rate (WER) by 6% to 10% relatively.
Data collection methods and preparation
Data definition
The main target of this research is to help people to read the Holy Qur’an correctly. There are common mistakes people make while reading the Qur’an based on their origin or country. The scope of this research will be limited only to Eastern Asia, specifically India, Bangladesh, and Sri Lanka. People in those countries have pronunciation problems with approximately ten Arabic letters, shown in Table 1, with our used phonetic symbols for them.
The ten most mispronounced letters in Arabic
The ten most mispronounced letters in Arabic
Al-Qaida Noorania, Haqqani [23], is an application used to teach children in Qur’anic schools at an early age, helping them learn to pronounce the letters with the correct Arabic accent according to standard Arabic. This method is also suitable for non-Arabic speakers and is used in many Islamic countries. The same methodology was used to train our system. The speaker must start with one letter and increase the number of letters to reach one word, and then one verse, until (s)he reaches one Surah. There are ten letter sets to be recorded based on Al-Qaida Noorania rules. Each set needs approximately five minutes to record, in case there are no mistakes made by the speaker. But practically there are many mistakes and retrials. Therefore, the recording task is very long and requires patience.
As mentioned above, there are ten sets of Arabic letters. Each set contains the following in sequence: One letter (6 Examples) Two letters (15 Examples) Three letters (19 Examples) Words (20 Words) Short Verses (6 Sentences)
Data collection
There are two primary methods for collecting data either directly by meeting session or indirectly through website. The recording session may take 60–80 minutes. Speakers who can read Arabic just need to read and record their voice. For speakers who can read, recorded instructions are used. A speaker should listen to the phoneme, and record it with his/ or her voice at the same time.
Adobe Audition CC 2015 was used for recording. The speakers were informed not to exceed the displayed boundaries as shown in Fig. 1 for a wrong recording.
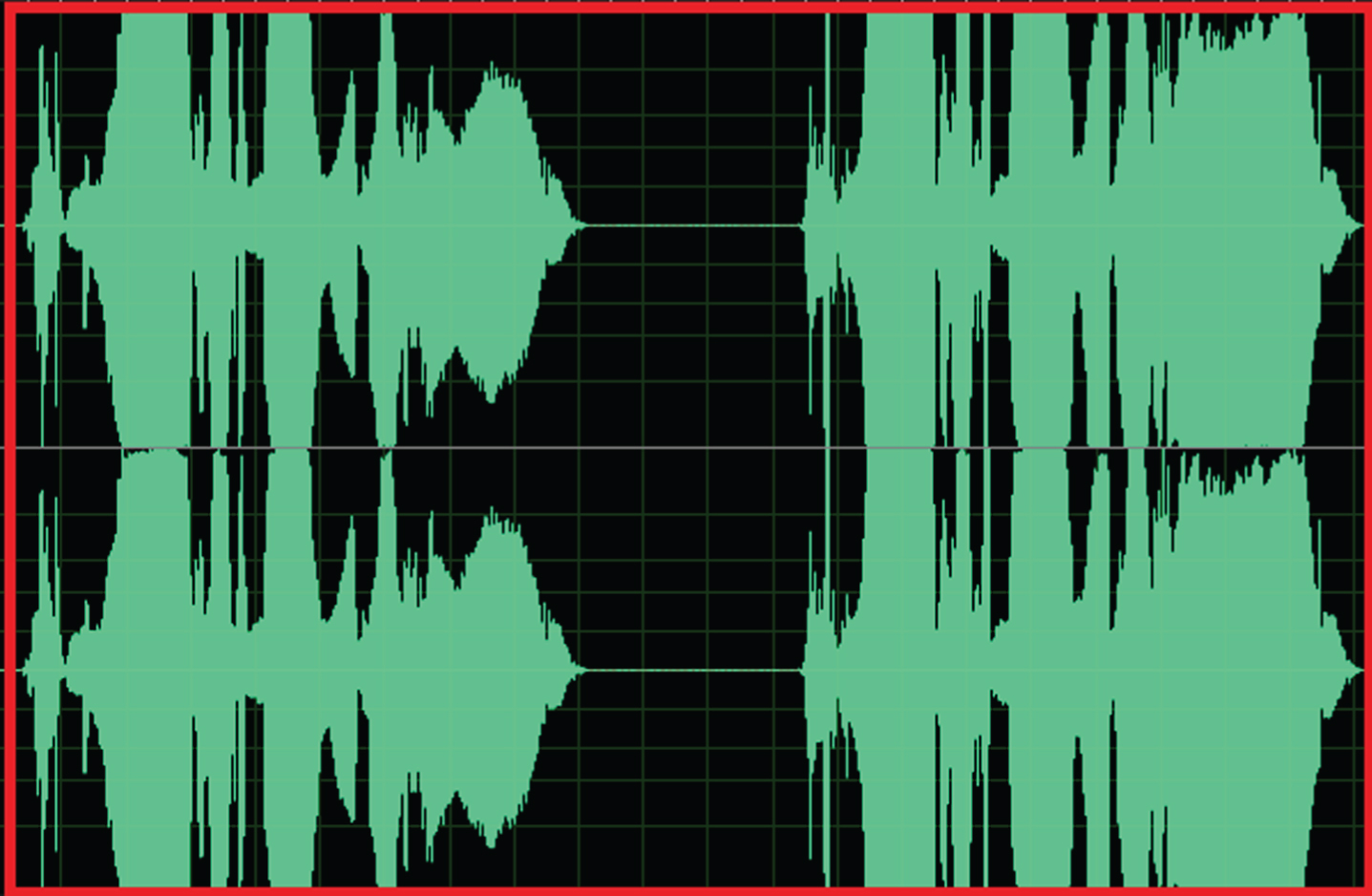
Signals Exceed the Boundaries.
Also the noisy recordings or recordings with merged utterances, without intermediate silence, were excluded. Then the recordings were segmented automatically based on the positions of the intermediate silences. The collected data for this paper has been also used in this paper [24].
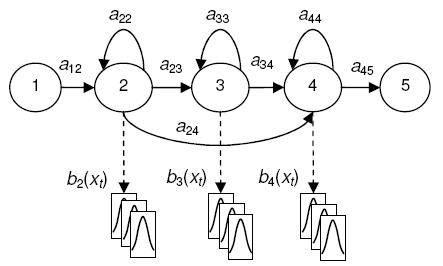
Figure 2 shows the structure of an HMM model. HMM state can have more than one GMM that represents the acoustic properties of each phoneme.
A training session simply adjusts weights to find the most accurate path to the phoneme. Figure 3 shows the training model components and dataflow.

The HMM States and Gaussians [25].

Training Model.
The primary components will be discussed in more details in the following sections.
An essential process in any ASR is the extraction of features from the wave signal. MFCC, introduced by Davis & Mermelstein (1980) [26], is the most popular ASR features in the field. The length of the vector of features that has been used was 42. Filter Bank (FBANK) is another important filter. According to Nadeu, Macho, & Hernando [27], FBANK provides a robust speech representation. The length of the vector of features that has been used was 123. A comparison with more details between the two features will be discussed later in Section 6.
Labels
A labeling tool developed by RDI®1 has been used at this stage as shown in Fig. 4. This tool generates the sequence of phoneme labels for each utterance in the training data. The tool uses several rules for converting Arabic letters to phonemes besides the special rules for reading Quran. The generated sequence is the ideal sequence according to correct recitation. In case of recitation errors, the tool allows the correction of the label sequence to match the user recitation.
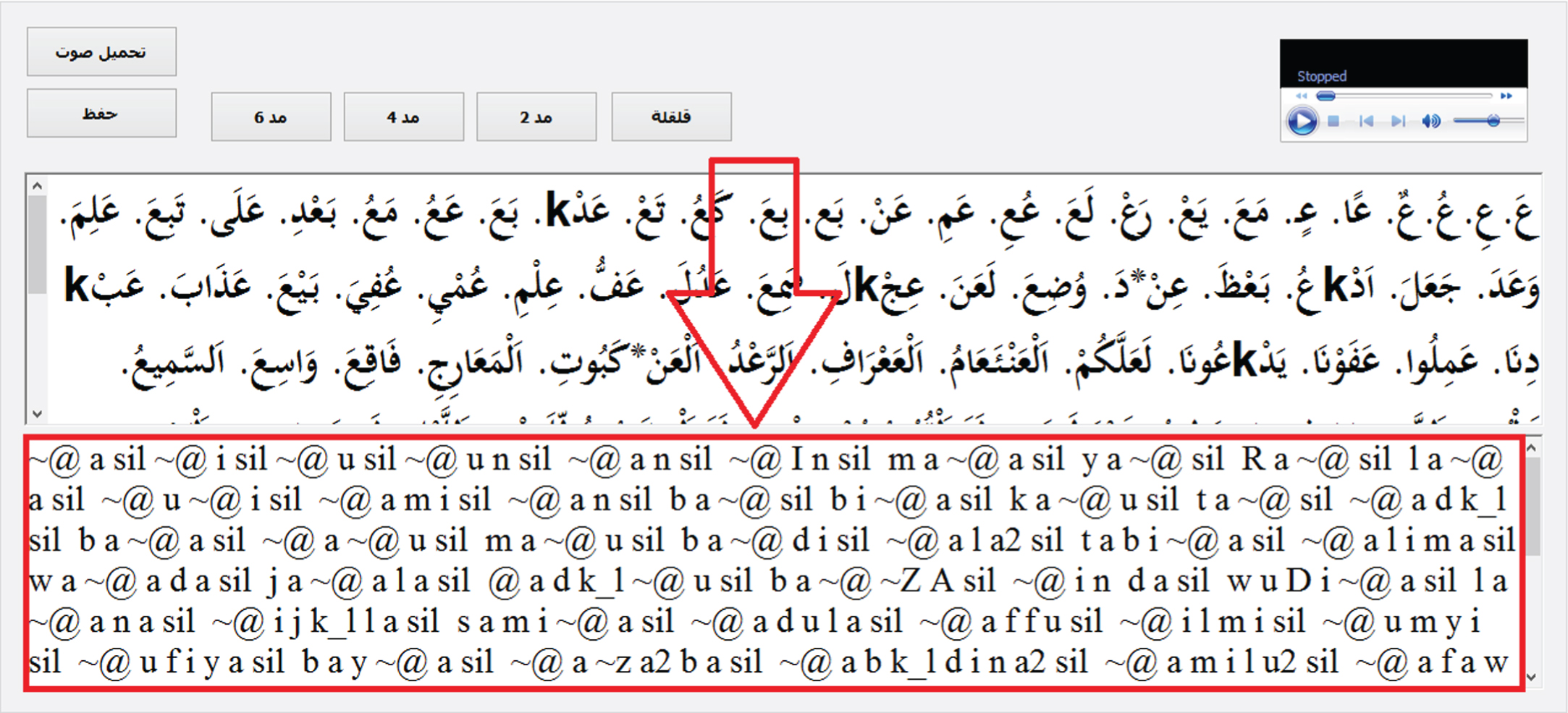
RDI Labeling Tool.
When all inputs are prepared and ready, the training process is ready to start. The aim of this process is to update means, variances, and transition matrices for all HMMs. Expectation-maximization algorithm will maximize the output probability at each state to match such label. The previous algorithm is a part of Baum– Welch algorithm [28]. Since the number of Gaussian mixtures has an impact on the model accuracy, a Gaussian splitting approach is used to reach the optimum number of Gaussians.
Grammar
Grammar rules are used to encode the correct pronunciations and the highly probable pronunciation errors. The used rules consider two main issues. The first is whether the test speaker is reading with Tajweed rules or not. The second factor is the speaker’s native language that affects the type of pronunciation errors. Figure 5 shows a sample of AIN grammar, or “ ” in Arabic.
” in Arabic.

Sample of Grammar Rules.
The area of red rectangle shows two grammars rules for one word which is “ ” in Arabic. The First rule, i.e. $w_Ain_42_1, represents the word with Tajweed rule by inserting the phoneme /l_k/. However, the second grammar rule shows the original word without Tajweed rule.
” in Arabic. The First rule, i.e. $w_Ain_42_1, represents the word with Tajweed rule by inserting the phoneme /l_k/. However, the second grammar rule shows the original word without Tajweed rule.
DNN model has different structure, concept, and algorithms. In the HMM-GMM model, each state fits a frame of acoustic input. However, in this model, the input could be several frames of coefficients, and the output is HMM states based on posterior probabilities [7]. Gaussian mixtures, which play a primary role in the previous model, especially to fit the acoustic input, are replaced in this model with one DNN that contains layers, nodes, and an activation function. The number of nodes in each layer can be as many as required, providing more flexibility for solving various and complex problems.
One of the disadvantages of DNN-HMM model is that HMM should be created and updated same as GMM-HMM model. Figure 6 shows the next steps in the model.
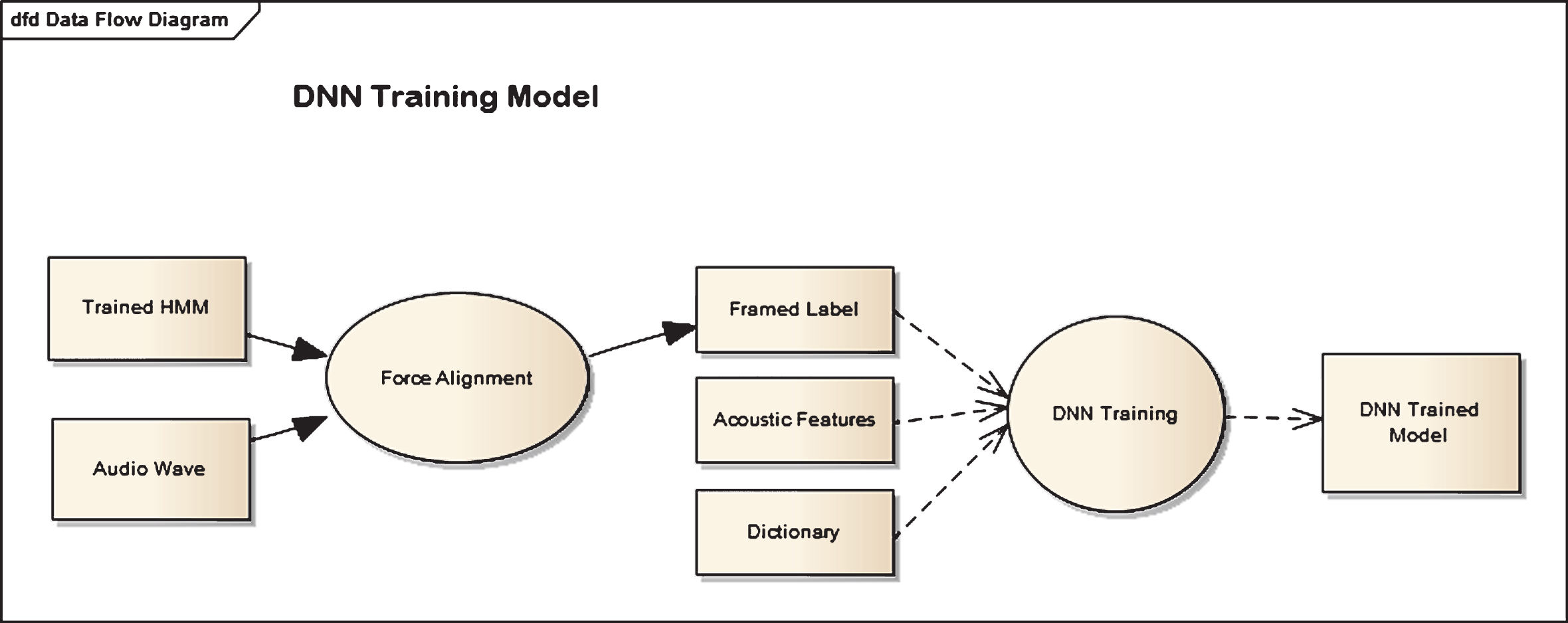
DNN Training Model.
A DNN is simply a multi-layer perceptron with large number of hidden layers, and this is how it got the name of deep networks. The main challenge in training this type of networks is finding efficient training strategies that can avoid falling in poor local optimum that usually results with the complicated nonlinear error surface due to the large number of hidden layers. A common practice to deal with this local optimal challenge is to initialize the DNN parameters greedily and generatively. This can be achieved by treating each pair of layers in the network as a restricted Boltzmann machine (RBM) as a pre-training step before doing the whole network training of all the layers. This learning strategy enables the DNN training to start with well initialized weights and makes the global network training a feasible process.
After the pre-training step of the DBN, a softmax layer is added on top of it and is trained using the classical back propagation approach. Given the model parameters θ fine-tuned over a pre-defined label set V = l1; l2;… ; l V , the DBN posteriorgram for a feature vector frame x i can be computed as DBN P x i = [p (l1|xi ; θ), p (l2|xi ; θ), … … , p (l V |x i ; θ)].
Where ∑ j P (l j |x i ; θ) = 1.
Figure 7 illustrates the architecture of the used DNN-HMMs model for our system.
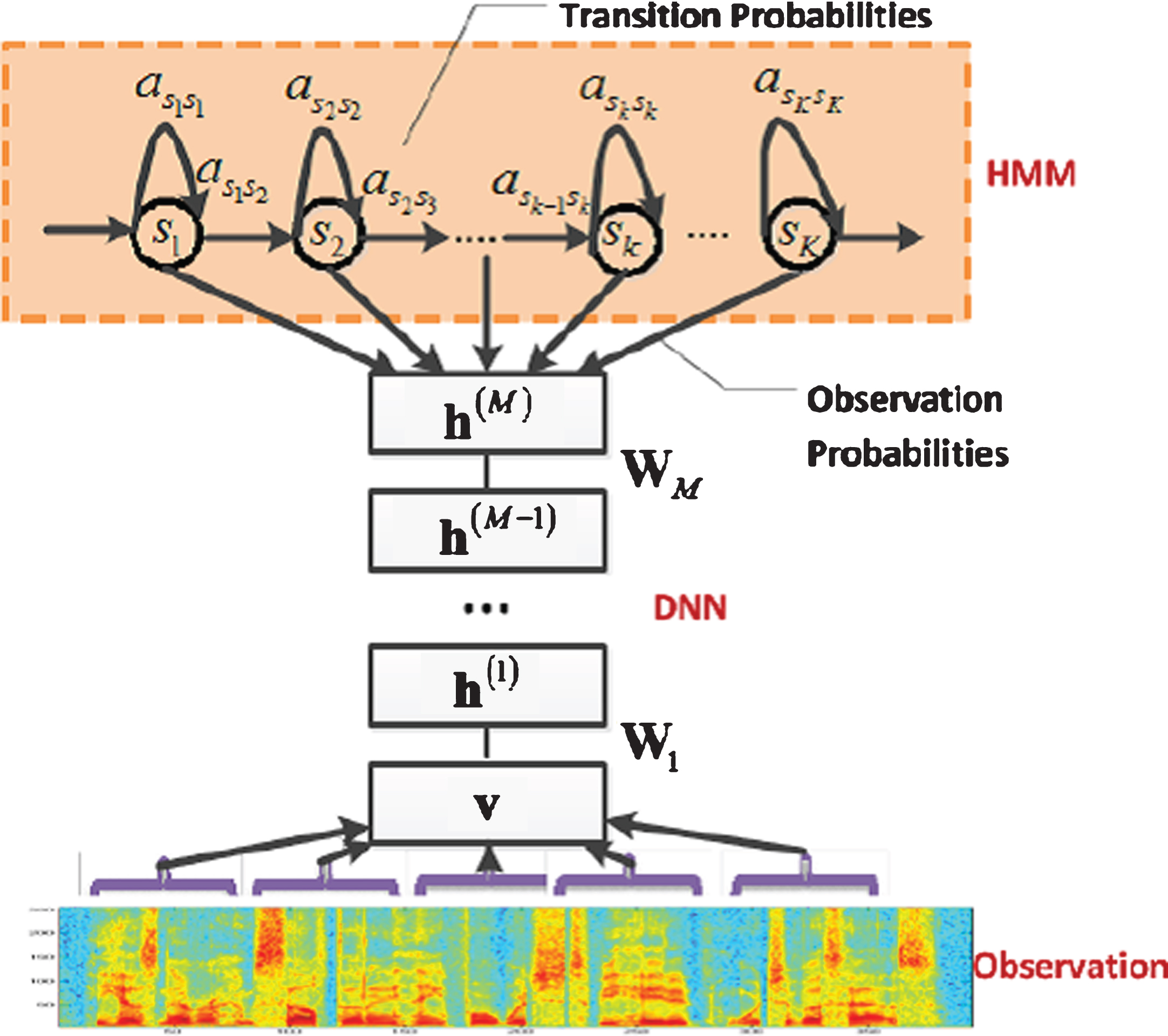
HMM-DNN Model.
The model uses the HMM structure to model the state transitions and DNN to model the state emissions. Two types of models were investigated in our system, the context independent mono-phone based DNN-HMM and a context-dependent tri-phone DNN-HMM model. We used a clustering decision tree based on linguistic questions to cluster the Tri-ligature HMM model states. For the hidden layers we experimented with several DNN structures that ranged from 3 to 5 layers, with each layer consisting of large number of nodes in the range 2000 to 4000 nodes.
The Viterbi algorithm is used to train the DNN-HMM model. A phone level decoder was integrated in the training process. The objective function is to find the determine the phone sequence Ph that maximizes:
Where aqt-1qt is the HMM state transition probability and p (x
t
|q
t
) is the observation probability that can be estimated by:
Where p (q t |x t ) is the state posterior probability that is estimated from the DNN, p (q t ) is the prior probability of each state estimated from the training data, and p (x t ) is independent from the ligature sequence and can be ignored.
The main steps of the training procedure for the DNN-HMM model are summarized as follows: Train the best HMM model (either CI or CD) using the full training dataset. Convert that HMM model to DNN-HMM model by borrowing the state transitions information (and state tying for the CD model). Pre-train each layer in the DNN bottom-up layer by layer using the unlabelled training data. Use the trained HMM to generate required labels for the training data frames up to the state level. Use these acquired labels to train the last layer of the DNN using the back-propagation approach and Viterbi approach. Use the trained DNN-HMM to generate new labels for the training data.
Repeat steps 5–6 for several iterations until the models converge.
This section contains all results of models that have been discussed in the previous sections, including the comparisons of all results. There are many methods that can measure the performance of each model. First, the word accuracy based on an equation that will be shown later. Second, the confusion matrix that shows the substitutions between phonemes. Finally, = comparing the models based on the number of deletions and insertions.
Database evaluation
The recorded number of data sets is 1000, 10 sets from 100 speakers as shown in Table 1. Two noisy waves have been excluded. The remaining 998 waves are divided randomly into 858 training waves and 140 testing waves. The total number of hours of all waves is nearly 83 hours.
GMM– HMM results
For a better understanding of the table results, a brief background will be presented first. The most important parameters in the HMM that can affect the results are the number of mixtures and number of states. Since the training session has been repeated 32 times based on the Gaussian mixtures, the “XX” in the term “HMMXX” in Fig. 9 represents the number of mixtures.
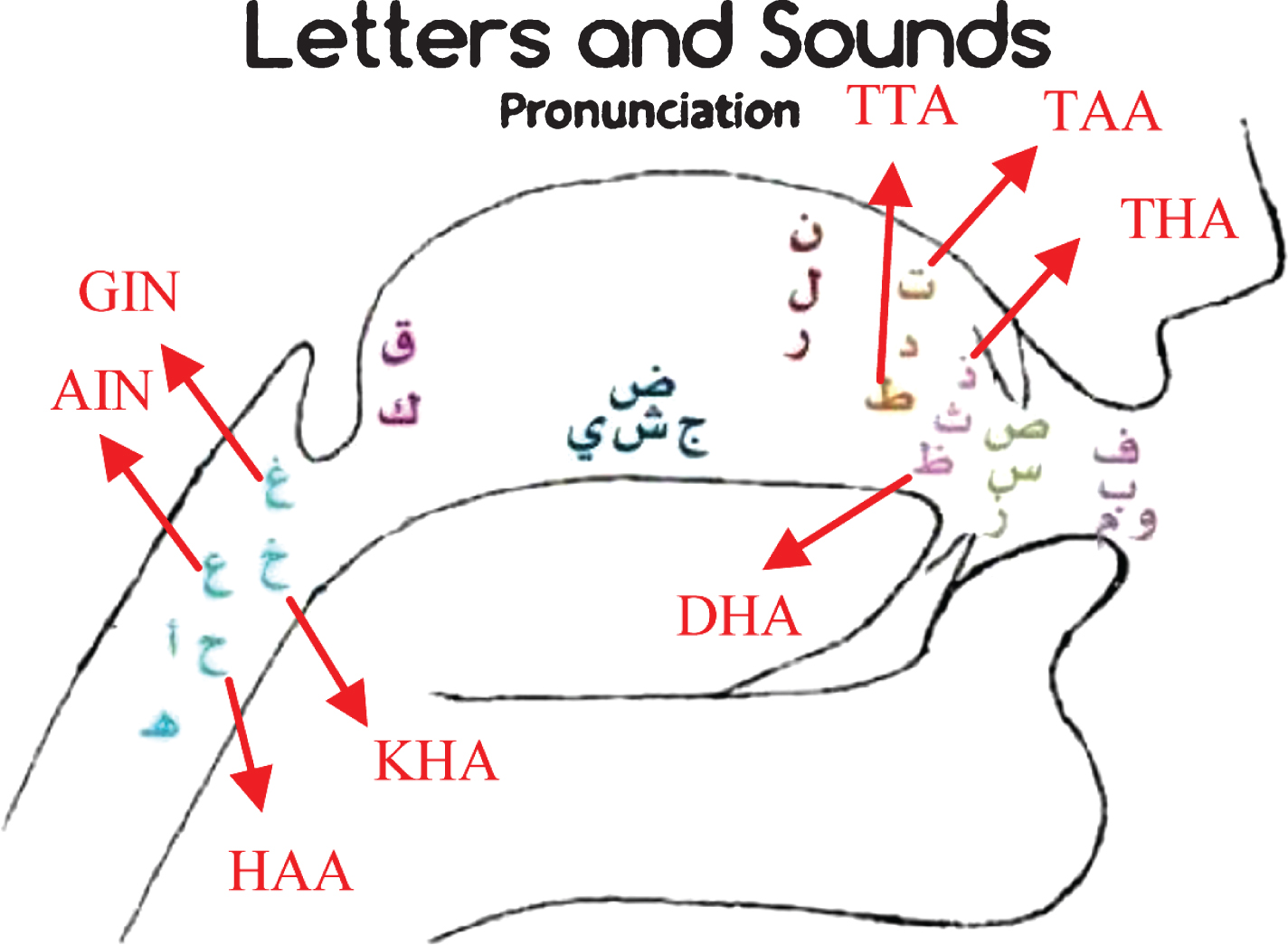
Anatomical View for Arabic Letters [30].
The main comparison between the MFCC and FBANKS filters is shown in Table 2, where MFCC (Three States), best result, clearly outperforms the competition by nearly 6.48%. Also, the worst result, 87.9% in MFCC (Four States), outperforms the competition with FBANK by 3.92%. All the calculations in Table 3 are based on HTK standard calculations stated in Salvi (2003), where the accuracy is calculated as follows:
HMM best results
Even though FBANK shows the worst result in GMM-HMM model, this is not the case in other models. One possible reason for this bad result according to Mohamed, Hinton, & Penn [29] is that GMM is using diagonal covariance while FBANK features are correlated. If a tied state number is chosen, then the rate difference among the mixtures is greater; otherwise, it is less or nearly stable. This is one of the observations that has been shown in Fig. 8, where MFCC (three states), which is tied, has fewer differences among its mixtures than the other filters.
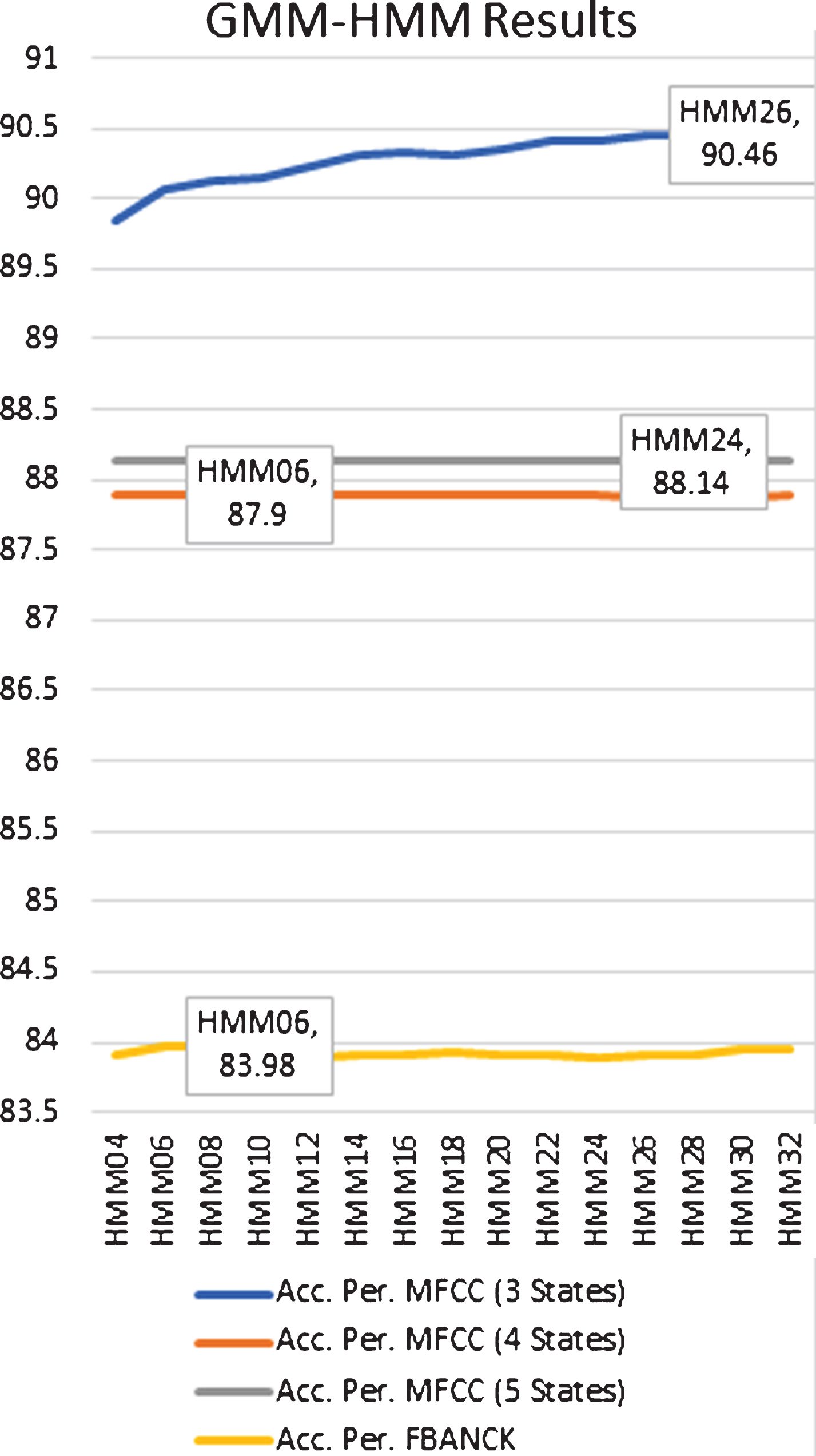
GMM-HMM Results.
MFCC (three States) achieved the top score for all models in all HMM mixture levels. MFCC (four States) and MFCC (five States) achieved nearly the same result, below MFCC (three States) by approximately 2% and above FBANK by approximately 4%. This result confirms a part of the claim [18] that MFCC with GMM– HMM achieves the best results among all feature extraction models.
The Confusion Matrix in Table 3 helps a lot to analyze the model’s results. The table shows the relationship between reference labels and the recognition result using HMM. Confusions can be categorized based on their causes as in Table 4. Category A is related to speakers’ mistakes. For example, and according to Table 3, the speaker usually substitutes the phoneme /D/, with the phoneme /d_z/; although the higher probability was for the phoneme /D/. In the application, an error message should be shown to alert the speaker about his or her mistake.
GMM confusion matrix
GMM confusion matrix
This type of confusion is not a real confusion since the system has chosen the right expected phoneme. Also, it is not an indication of the model’s quality or performance. Category B may occur when both phonemes are sharing the same point of articulation. Figure 9 shows groups and locations of points of articulation including the concerned Arabic letters as groups.
For example, the phonemes TTA, i.e. “ ,” and TAA, i.e. “
,” and TAA, i.e. “ ,” are sharing the same point of articulation, and they also have substitutions in the confusion matrix. Also, the phonemes THA, i.e. “
,” are sharing the same point of articulation, and they also have substitutions in the confusion matrix. Also, the phonemes THA, i.e. “ ,” and DHA, i.e. “
,” and DHA, i.e. “ ,” have the same case and so on. This type of confusion can be solved by increasing the training data. The third category of confusion, which is C, may occur when the probability calculation is not maintained properly. One reason could be the training data selection. For example, in Table 5, the last letter in the original phoneme is /D/. The previous phoneme should have the highest score in the probability matrix. However, suppose that most examples in training data are from the recorded phoneme. Then, the recorded phoneme will have the precedence over the original phoneme in the probability matrix.
,” have the same case and so on. This type of confusion can be solved by increasing the training data. The third category of confusion, which is C, may occur when the probability calculation is not maintained properly. One reason could be the training data selection. For example, in Table 5, the last letter in the original phoneme is /D/. The previous phoneme should have the highest score in the probability matrix. However, suppose that most examples in training data are from the recorded phoneme. Then, the recorded phoneme will have the precedence over the original phoneme in the probability matrix.
Confusion example
Consequently, whenever this phoneme, in Table 5, is recognized then the substitution between /D/ and /∼Z/ occurs. Therefore, the training data should be selected carefully in a way that the original phoneme should always have the precedence.
Figure 10 shows the result of substitutions between phonemes. The Arabic language is considered unique for having the letter “DAA” “ ”. The results in Table 4 reflect that fact since /D/ phoneme or DAA is very difficult for speakers to pronounce. Usually, speakers always substitute it with either /d_z/ or /∼Z/. From our experience, Arabic and non-Arabic speakers make the same mistake except that native Arabic speakers substitute DAA, “
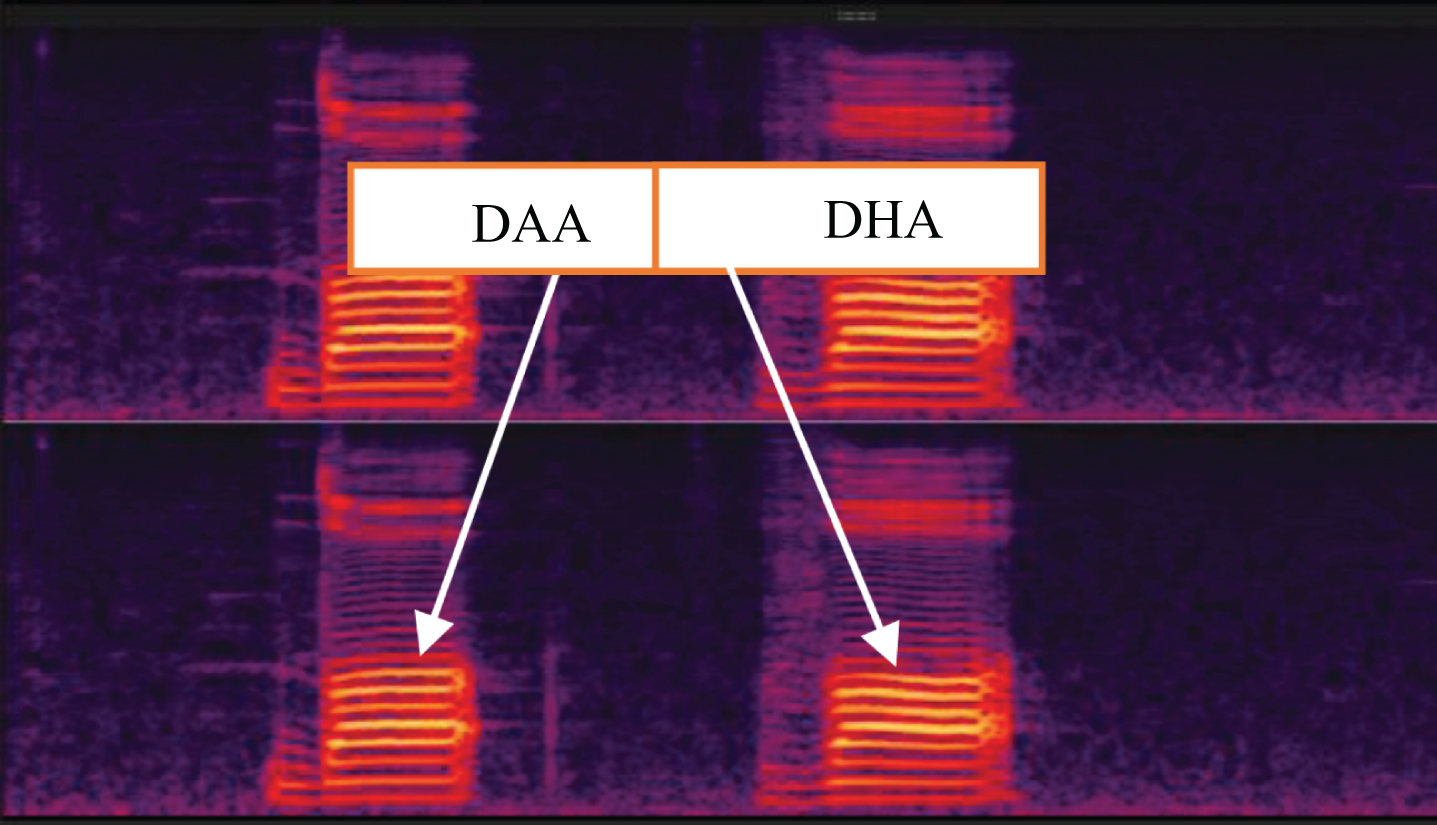
”. The results in Table 4 reflect that fact since /D/ phoneme or DAA is very difficult for speakers to pronounce. Usually, speakers always substitute it with either /d_z/ or /∼Z/. From our experience, Arabic and non-Arabic speakers make the same mistake except that native Arabic speakers substitute DAA, “ ,” with DHA or /∼Z/. Therefore, the DAA phoneme is confusing for speakers, but is it the same for the machine? Figure 11 shows that both phonemes /D/ and /∼Z/ have been pronounced ideally in the spectrogram domain. However, they have nearly the same form of waves! Thus, it is not easy even for the system to differentiate between the two phonemes. The previous confusion is the best description of category D. Also, categories A and C are involved in this situation as well. The best solution for /D/ issue is more training data considering data formulation that gives the high probability to original phonemes.
,” with DHA or /∼Z/. Therefore, the DAA phoneme is confusing for speakers, but is it the same for the machine? Figure 11 shows that both phonemes /D/ and /∼Z/ have been pronounced ideally in the spectrogram domain. However, they have nearly the same form of waves! Thus, it is not easy even for the system to differentiate between the two phonemes. The previous confusion is the best description of category D. Also, categories A and C are involved in this situation as well. The best solution for /D/ issue is more training data considering data formulation that gives the high probability to original phonemes.
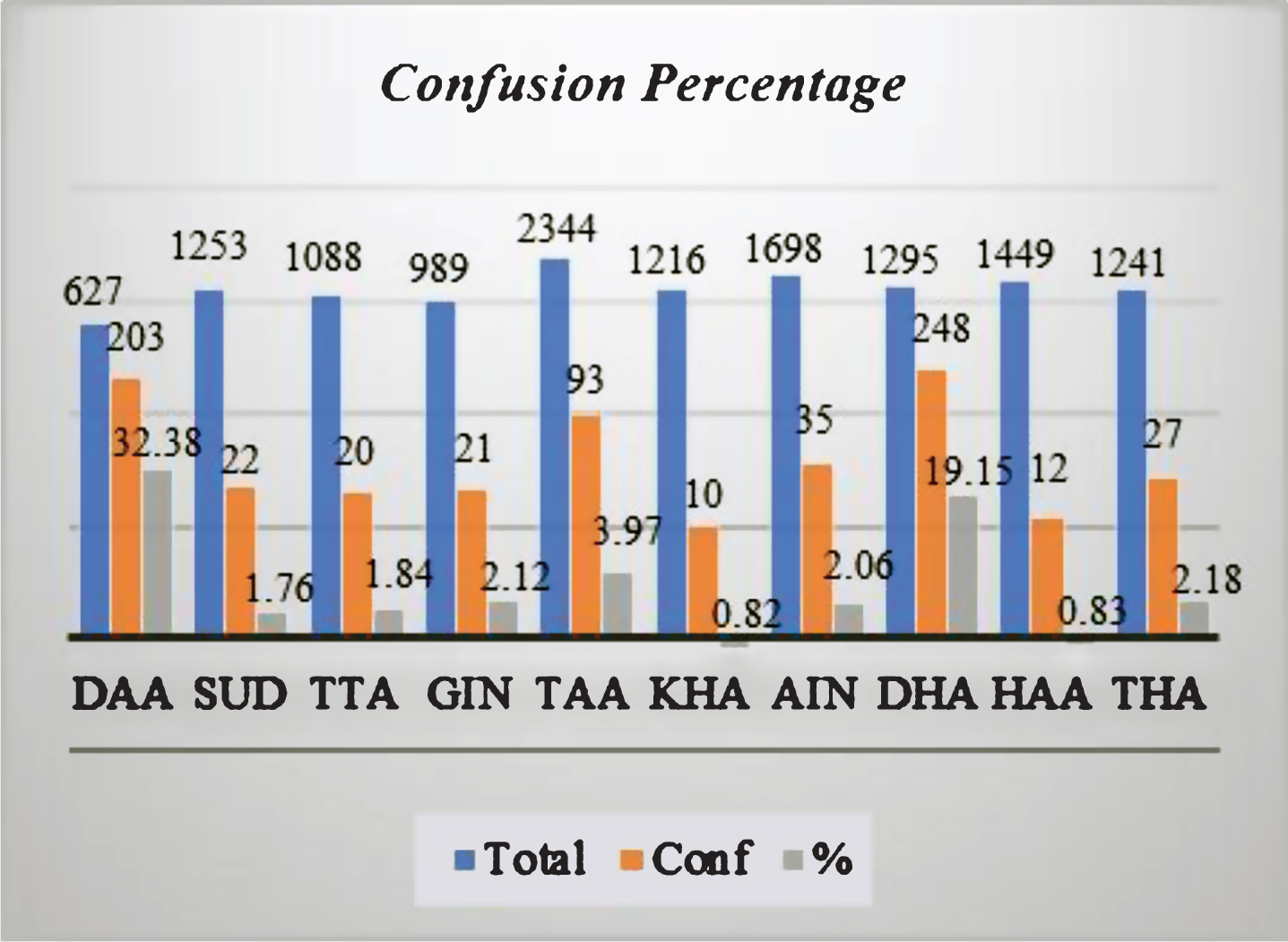
GMM Confusion Percentage.
Comparing Phonemes.
Categories of confusion
The main aim of LM is to help the algorithm to select the correct path. The definition of category E is when a model is trained very well, and the phoneme confusion still occurs.
Another factor to estimate the recognition quality is insertion and deletion results. The insertion occurred when some phonemes have been inserted in the original word during the recognition stage. For example, the original word was “x A y R,” or “ ” in Arabic but the recorded word became “x A y R u n,” or “
” in Arabic but the recorded word became “x A y R u n,” or “ ” so the phoneme “u n” or “” has been inserted. The inserted phoneme in the previous example is one of the alternative pronunciations of the word. However, the model has selected the wrong path, so one possible reason could be it is a result of an E error confusion. Deletion is happening when the phoneme is missing from the recorded output exactly the opposite of insertion. The same reason that caused the insertion has also caused deletion. Figure 12 shows insertion and deletion results that have been recorded per phoneme in GMM model.
” so the phoneme “u n” or “” has been inserted. The inserted phoneme in the previous example is one of the alternative pronunciations of the word. However, the model has selected the wrong path, so one possible reason could be it is a result of an E error confusion. Deletion is happening when the phoneme is missing from the recorded output exactly the opposite of insertion. The same reason that caused the insertion has also caused deletion. Figure 12 shows insertion and deletion results that have been recorded per phoneme in GMM model.

Insertion and Deletion Results in GMM.
There are different DNN architectures based on hidden layers’ numbers and number of nodes per hidden layers. Figure 13 shows that the accuracy is increasing when the number of nodes per hidden layer is increasing from 128 to 1000 nodes. Then accuracy is reaching the high rate from 1000 to 2000 nodes. By repeating the same process with a different number of layers and nodes, we’ve reached the best DNN architecture with three layers and 1024 nodes.
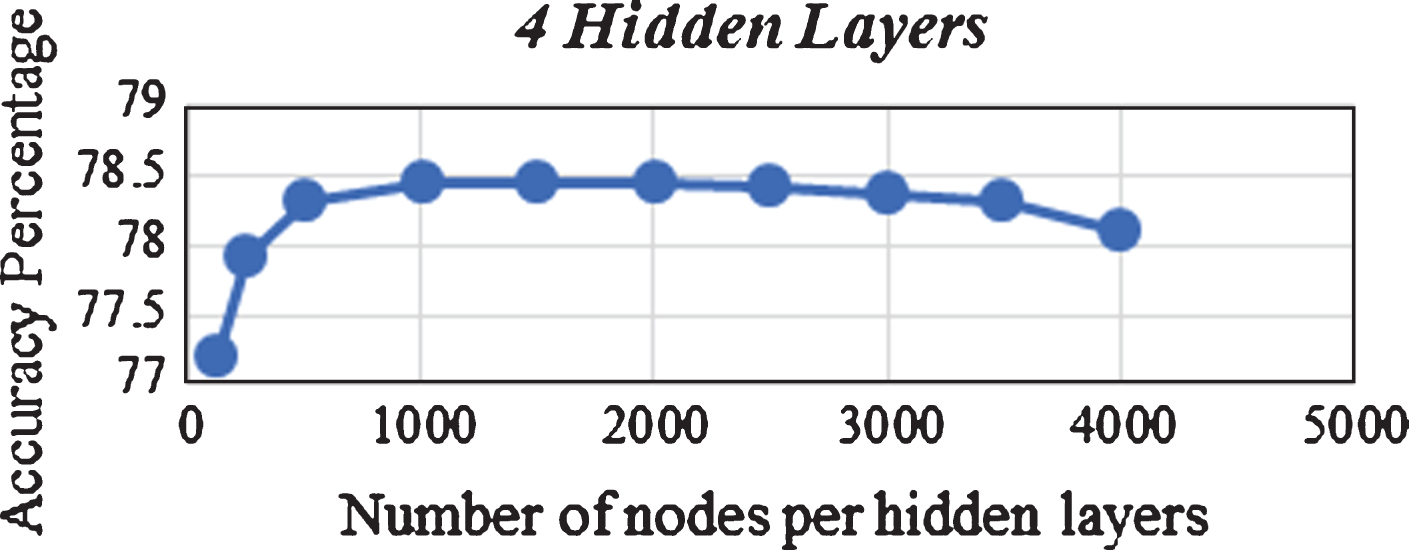
Effect of increasing number of nodes on accuracy percentage.
The DNN was designed based on an n-gram language model, as mentioned in Section 3. According to Kaur [31], “N-gram models can be imagined as placing a small window over a text, in which only n words are visible at the same time” (p. 853). The model mechanism is to find the probability of each possible transition among n phonemes. The results proved that the increasing of n ensures more accuracy. However, since the number of comparisons increases with n, the time also increases, and this is the only disadvantage of increasing n. Figure 14 shows a comparison between DNN– HMM and GMM– HMM based on the accuracy equation described at the end of Section 6.2. As expected, DNN– HMM shows superiority over GMM– HMM in all n-gram models. The difference between the two models started with 6.45% in a 2-gram and ended with 0.78% in a 9-gram.
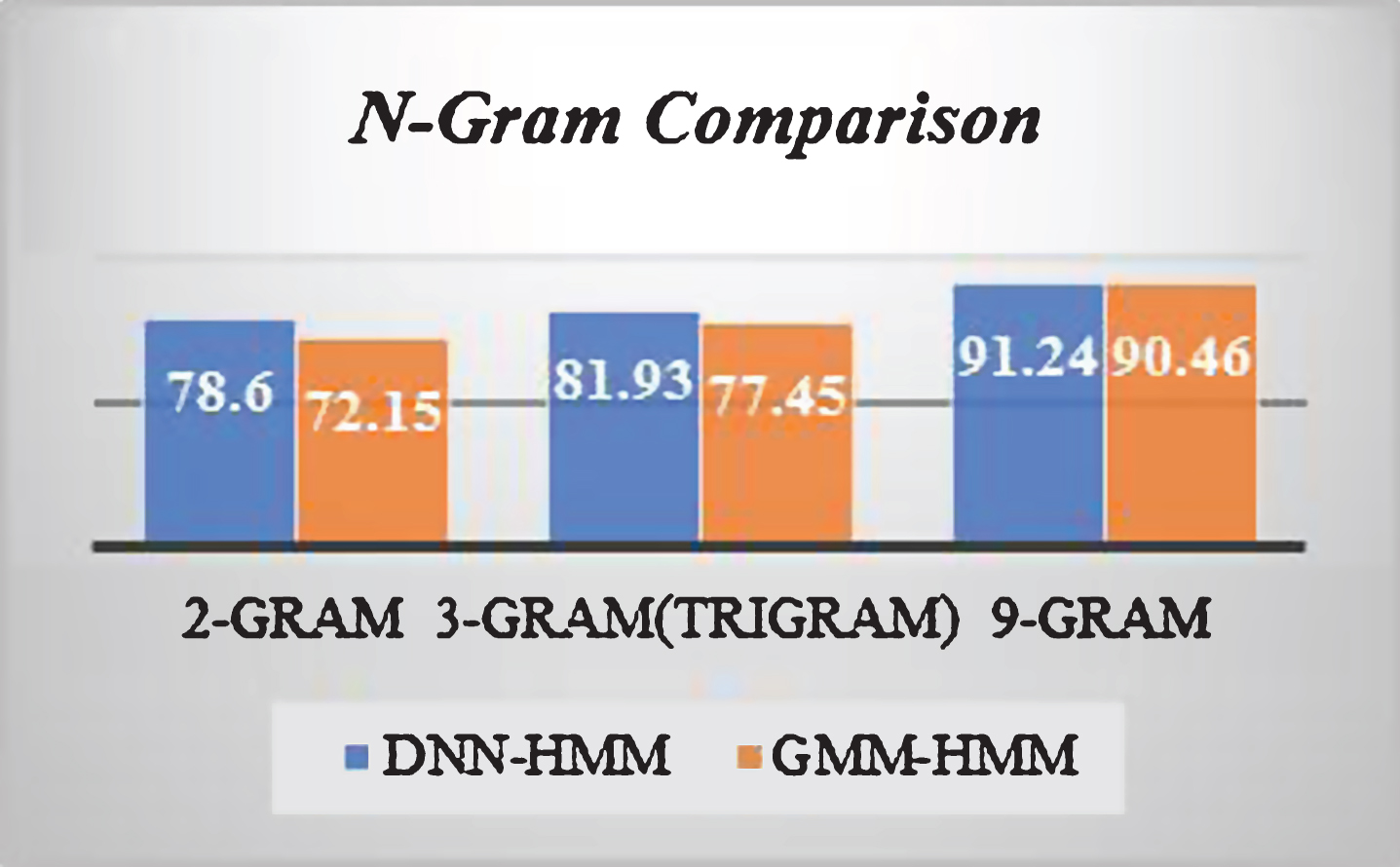
N-gram model comparison.
One of the techniques that has been used to enhance the overall accuracy was the HTK word lattice option. In fact, using a lattice of each word that contains all possible recitation and pronunciation errors might enhance the performance slightly. As shown in Fig. 15, DNN– HMM accuracy improved to reach nearly 1.02% over GMM– HMM.
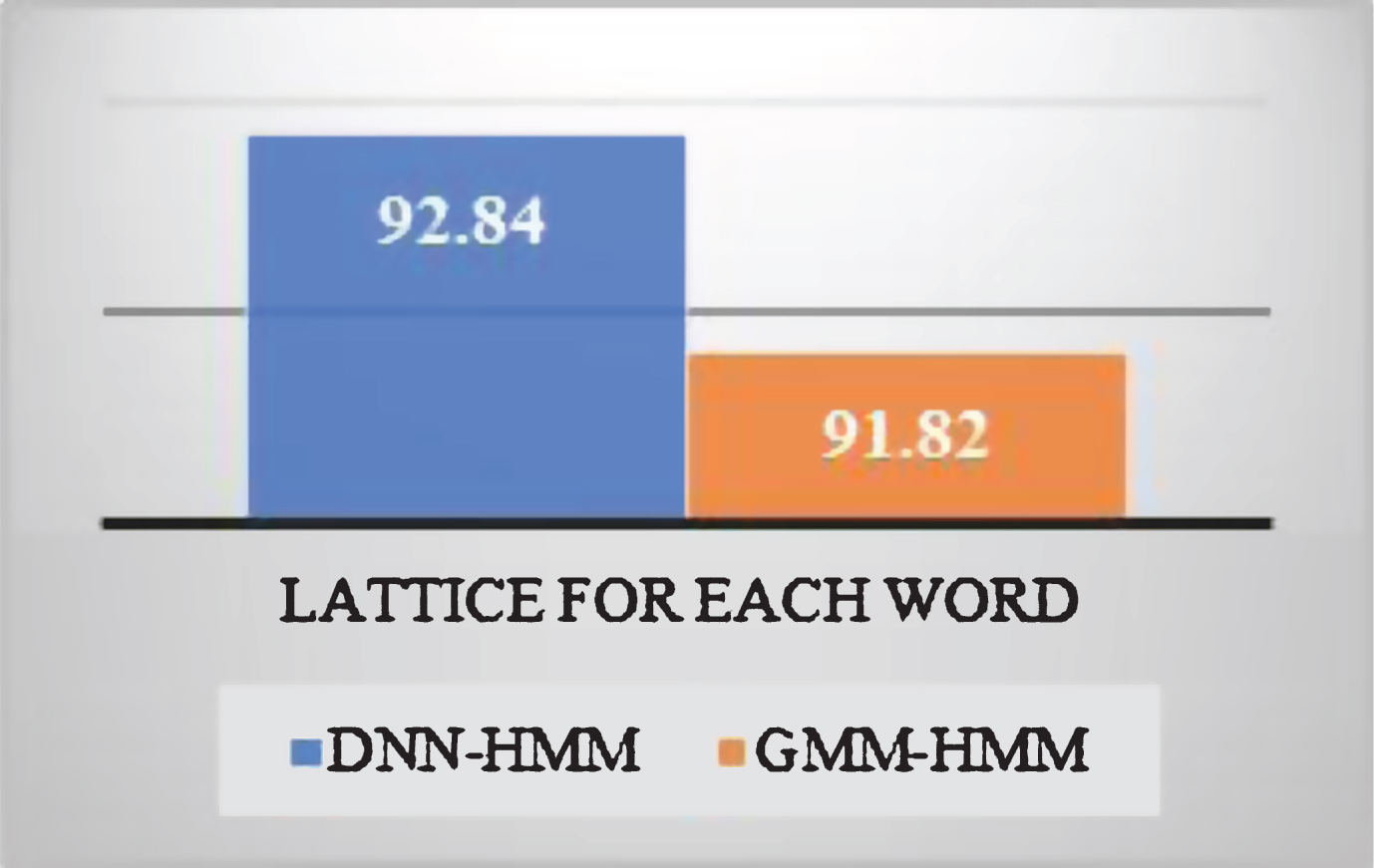
Lattice Comparison Regarding Accuracy.
Figures of the ten letters show different results based on the analyzed subject. High scores in this figure can be achieved because of the following reasons: Examples that have been used in the letter set were excellent. LM of this letter set is robust and tuned. The training session of this letter set is done very well.
Colors in Fig. 16 mean the following: Green: Excellent. Orange: Very Good. Blue: Normal. Red: Need to be enhanced.
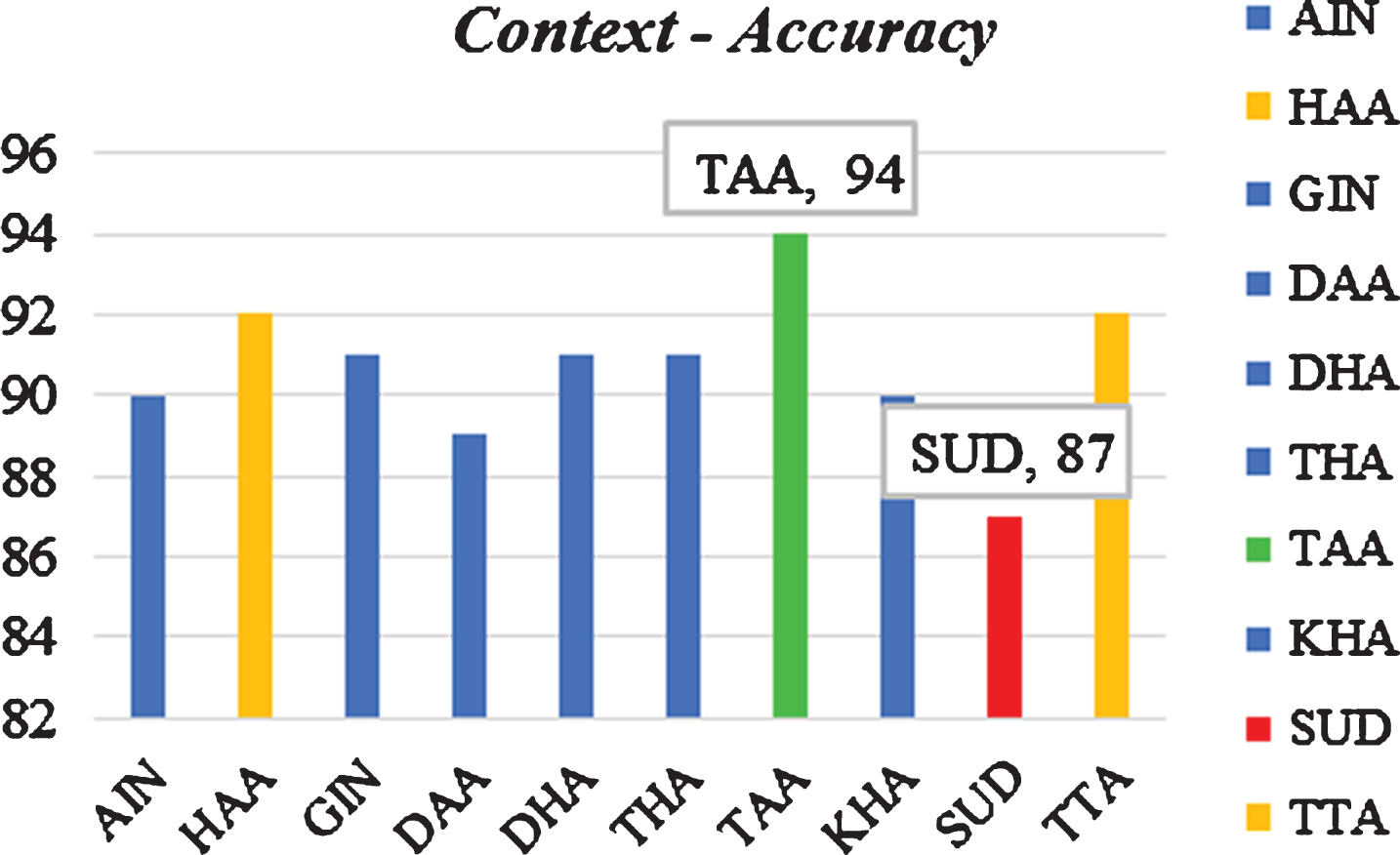
Accuracy of the Ten Letters.
The figure shows that there is a serious problem with SUD letter set. Therefore, the SUD letter set should be reviewed and corrected. One possible reason could be that “SUD” is one of the so-called wheezing sounds. There are some studies that suggested more effective methods to deal with this type of sound. However, it is too early to come to this conclusion. This part requires more investigation and analysis to achieve satisfactory results.
Talking about enhancement performance does not necessarily mean that all elements have been enhanced. Sometimes, enhancement in most elements can lead to an overall enhancement. Table 6 shows some enhancements in some phonemes and some declines in others.
DNN confusion matrix
DNN confusion matrix
However, most confusion phonemes have been decreased and that caused the overall result to be decreased.
Although the substitution percentage has been decreased, in general, there are some declines in the results of some phonemes. However, these confusions can be fixed by enhancing the training methods and with more data. Table 7 shows all changes that have occurred in each phoneme.
Comparison between models substitutions
Note: All percentages are absolute.
Another evidence that the DNN model is more accurate than the GMM model is the reduction that occurs in insertion. There are two reasons for insertion and deletion. The first reason was enhancing LM, but since both models are using the same LM and the same testing data, then this reason is excluded. The second reason seems to be more realistic, so paths’ weights have not been adjusted properly in the model.
Figure 17 reflects the real practice since it shows that DAA and DHA score the high value in deletion. Actually, solving the issue of the previous phonemes will reduce the deletion results significantly.
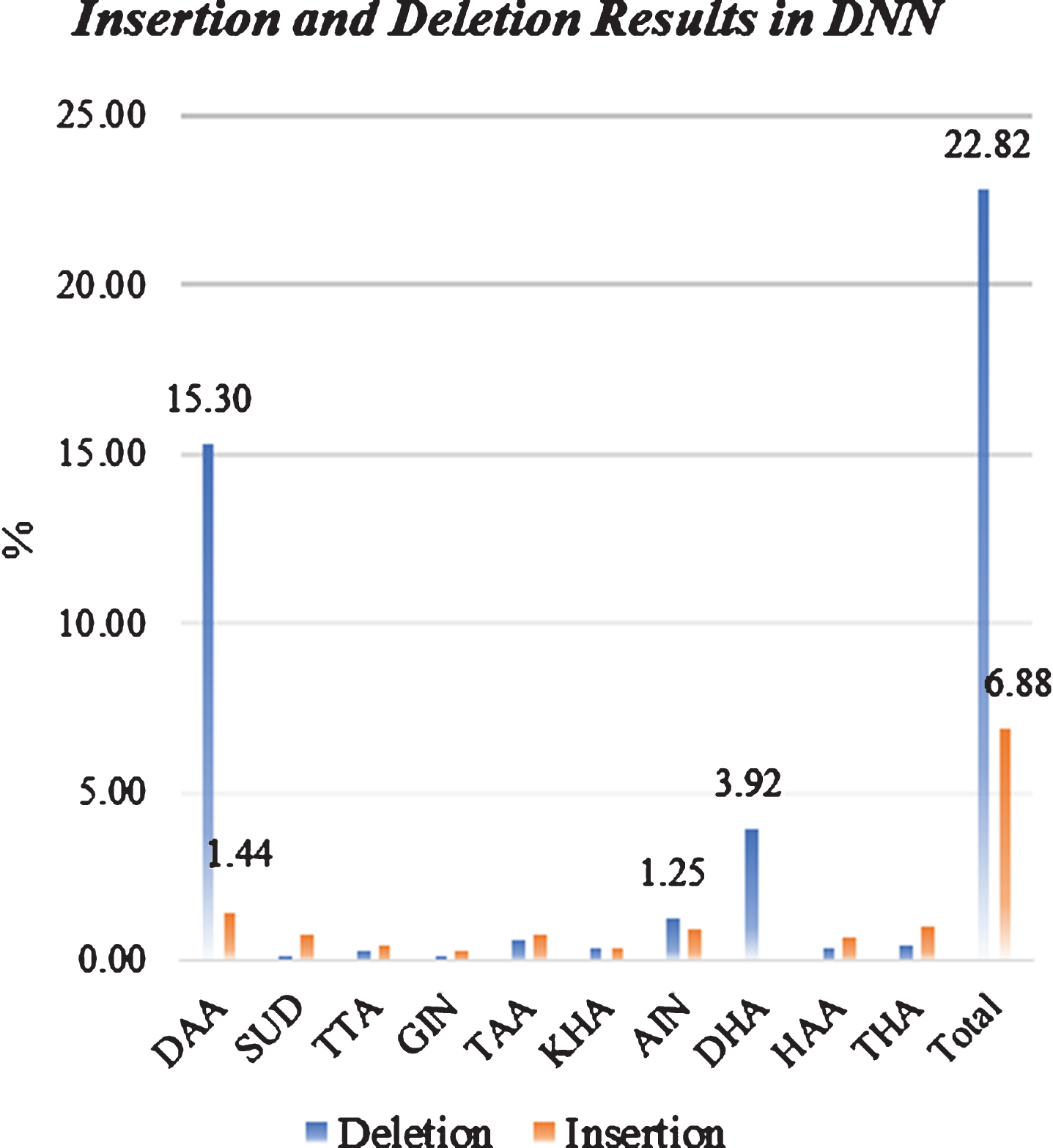
Insertion and Deletion Results in DNN.
Although DNN outperforms GMM in the overall result, it does not mean that it is doing so in all sub results. By comparing all sub results, i.e. substitution, insertion, and deletion, strengths, and weaknesses of each model will be exposed.
The main and huge difference is in substitution result. Figure 18 shows a comparison based on substitution results in percentage. The three main differences have been made with DAA, TAA, and DHA letters. However, KHA letter has been shown since it has achieved an ideal value which is null confusion or substitution! The great difference is made in DHA letter with 17.28% followed by DAA letter with 15.09%. Also, TAA letter has achieved progress with 3.16%. DNN model beats GMM model in substitution results.
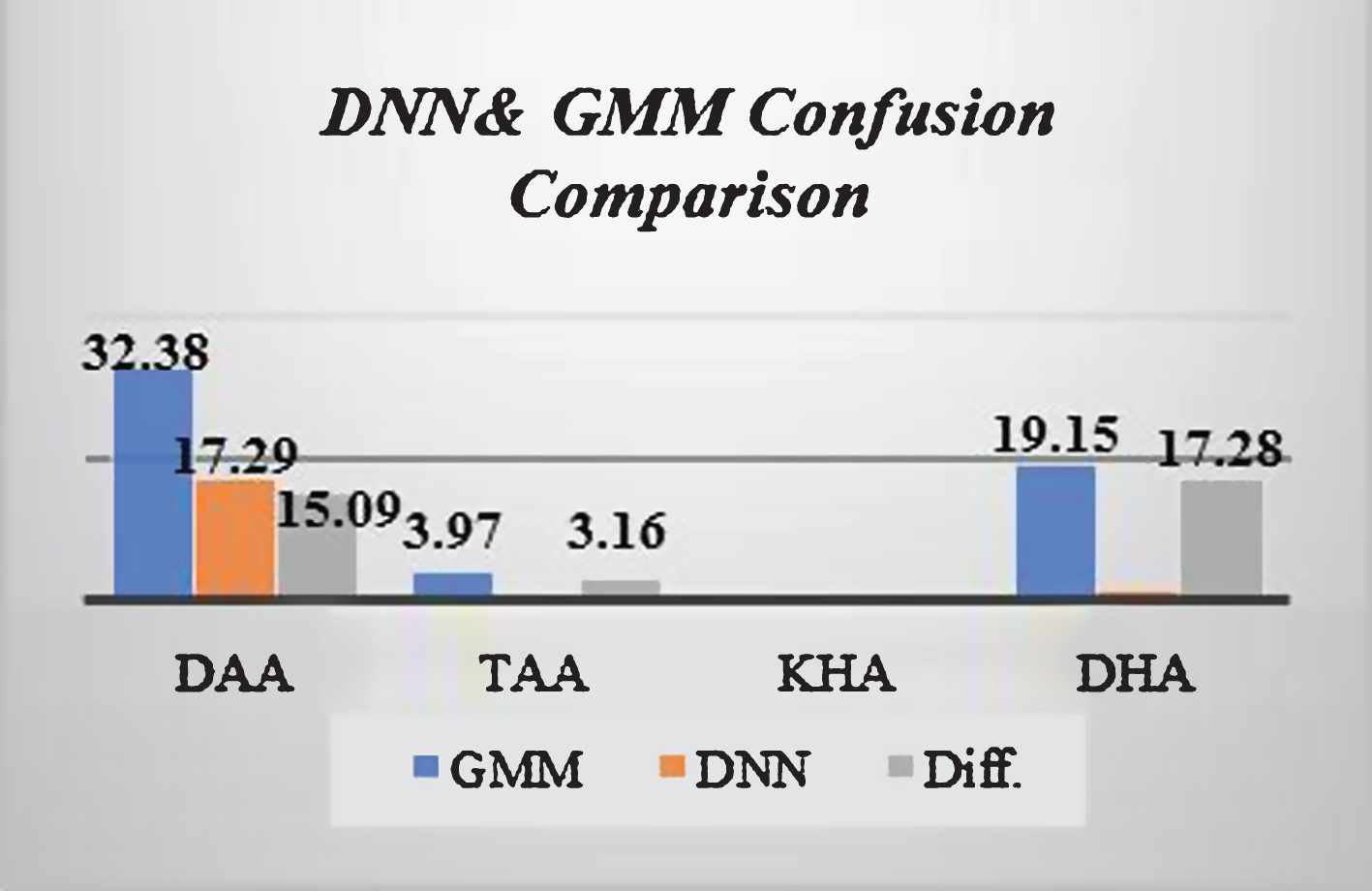
DNN & GMM Confusion Comparison.
The situation with the insertion result is nearly same as substitution, where DNN is still in the lead. According to Fig. 19, most insertion results for all letters have been enhanced with DNN model except the DAA letter. Comparing with GMM results, the total insertion result for DNN has been reduced by 2.59%.
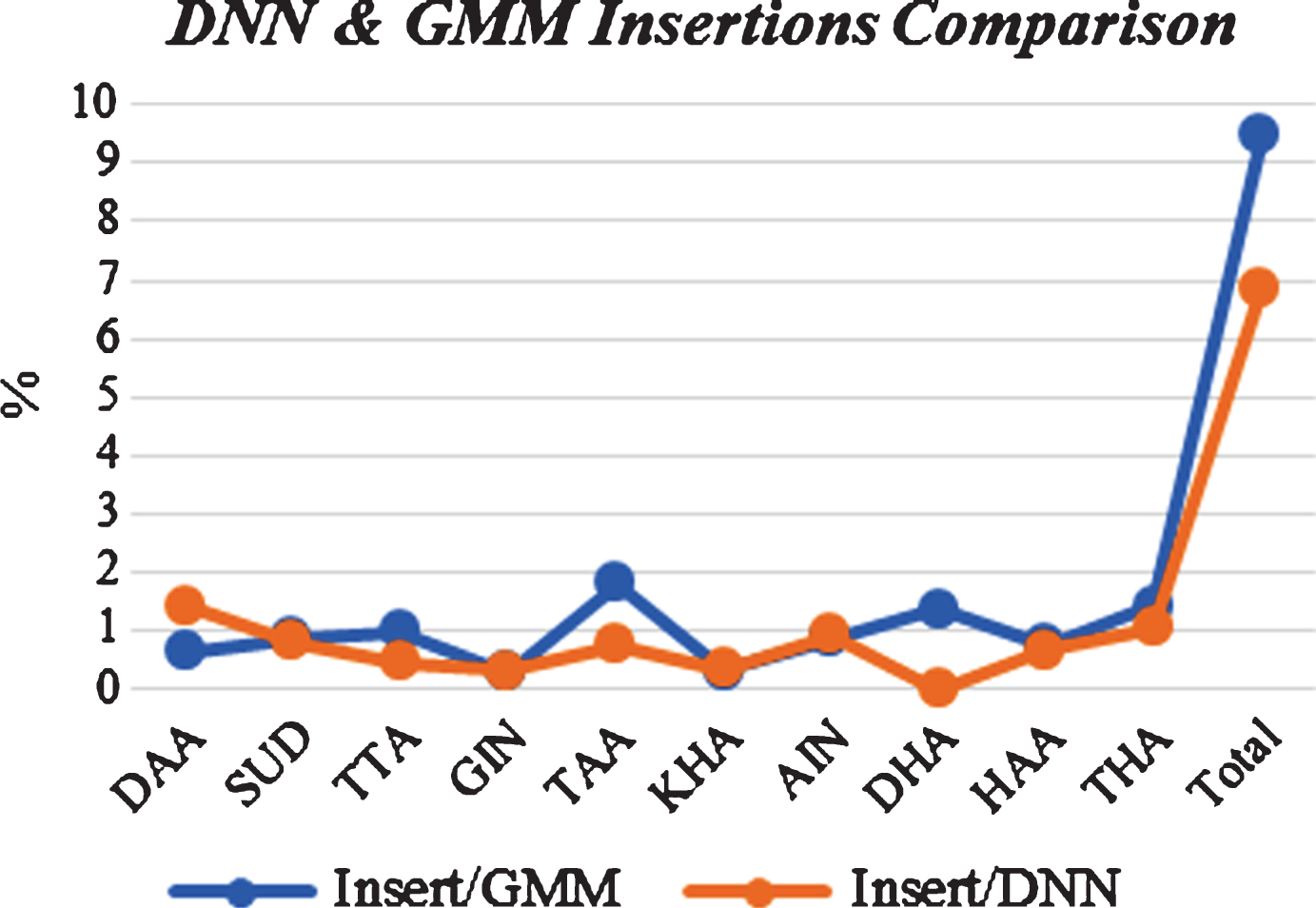
DNN & GMM Insertions Comparison.
According to Fig. 20, the deletion result has recorded an expected result, where GMM has been outperforming DNN by 5.79% ! This result needs more investigation to know the real reason. However, with solving D category issues and enhancing the initialization algorithm, deletion result for DNN may improve.

DNN & GMM Deletion Comparison.
Our reported results indicate progress in DNN’s performance over GMM except the deletion result. Practically, GMM is faster to compute, easy to learn, and reliable with clean data. GMM computation can be done on a normal PC or laptop. However, DNN is slow in computation and usually requires CPUs or Graphics Processing Unit (GPU), but it is more accurate. Also, due to complex computation, DNN is slow to decode. Theoretically, according to Hinton et al. [7] “GMMs have a serious shortcoming— they are statistically inefficient for modeling data that lie on or near a nonlinear manifold in the data space” (p. 83). The previous statement implies that DNN has the potential to perform much better with this type of data.
Conclusions and future work
This work is just a first step towards the final target, which is to have a system that acts as a Qur’anic teacher that can comment, correct, and guide the reciter. By replacing GMM-HMM with DNN-HMM in HAFSS© and comparing it with the original HAFSS© system, the following results are obtained. Based on HTK’s word accuracy equation, the DNN-HMM outperforms GMM-HMM by 1.02%. By calculating the insertion results for both models, DNN-HMM showed progress by 2.59%. Also, in substitution results, DNN-HMM shows progress with the confusion phonemes DAA by 15.09% and DHA by 17.28%. Although HAFSS© performance has been enhanced slightly by using DNN– HMM, we expect that the DNN– HMM has more capability and can achieve better results in the future.
{kind=link}
{kind=link}