
Abstract
This work presents the application of a convolutional neural network (CNN) used to identify emotions through taken images to students, which are learning Java language with an Intelligent Learning Environment. The CNN contains three convolutional layers, three max-pooling layers, and three neural networks with intermediate dropout connections. The CNN was trained using different emotional databases. One of them was a posed database (RaFD) and two of them were spontaneous databases created specially by us with a content focused on learning-centered emotions. The results show a comparison among three emotion recognition systems. One applying a local binary pattern approach with facial patches, another applying a geometry-based method, and the last one applying the convolutional network. The analysis presented satisfactory results; the CNN obtained a 95% accuracy for the RaFD database, an 88% accuracy for a learning-centered emotion database and a 74% accuracy for a second learning-centered emotion database. Results are compared against the classifiers support vector machine, k-nearest neighbors, and artificial neural network.
Keywords
Introduction
Emotional recognition is the process of predicting affective content from low-level signals. These signs are manifested from physical expressions. These expressions have important features that help us how to differentiate an emotion from another. For example, in speech, we have features like loudness and pitch. In body expressions, we have features like the position of the body. Even, the heart rate and brain signals are features not detectable but they express emotions as well [1]. One of the most expressive parts of the human body is the face, being one of the main channels of communication to express emotions. Emotional recognition through the face is an issue that has been extensively addressed by researchers in the field of affective computing; this issue is usually named facial expression recognition.
To implement our facial expression recognizer we developed three different processes [2] explained below. The first step is the extraction of features where the facial image receives a set of operations; these operations generate a set of features expressed as a vector, a matrix or some computational data structure. The operators are based on the appearance (filters) or the geometry (distances) of the image and are usually handcrafted. The second stage is the selection of features where frequently repeated features are discarded because these features make the images have little difference among them confusing the classifier. In addition, this step also serves to decrease the dimensionality of feature vectors. The third step is the building or use of a classifier. Classifiers usually are designed for classifying discrete values that are represented by labels or classes. The most used approaches to create facial expressions recognizers are based on Ekman’s theory of emotions [2]. This theory explains how human beings express basic emotions. The basic emotions are feelings of short duration with clearly visible and well-defined expressions. Although the number of emotions may vary according to the author, usually the selected emotions are anger, joy, sadness, fear, contempt, disgust and surprise. In current research papers, databases of basic emotions are used in the three mentioned stages for building and testing an emotion recognizer.
In a previous work [3], we presented an intelligent learning environment (ILE) for the Java programming language. Intelligent learning environments provide personalized instruction in a particular domain. In addition, we added to the environment an emotion recognizer to provide the ability to use emotions as part of pedagogical strategies. In this paper, we present the design and implementation of a convolutional neuronal network to give our ILE the ability to recognize emotions with another type of classifier. It is worth mentioning that the work of creating an emotion recognizer was addressed twice before [4, 5]. The difference and main contribution of this work are that the convolutional neural network automatically performs the feature selection process avoiding the need to create a handmade process, which is not known with precision if it works properly for educational domains. In addition, we created a database with spontaneous facial images that represent emotions focused on learning. These emotions have a longer duration and occur when performing intellectual activities [6]. Some of the most common emotions of this type are frustration, engagement, excitement, boredom, and relaxation. Also in previous works, we built two classifiers to recognize learning-oriented emotions. All this work is explaining further on.
There has been research works in the area of machine learning based on the deep learning approach. One type of deep learning approach is the convolutional neural network which consists of a set of interconnected filters where an image is transformed retaining its most outstanding features [7]. These networks transform the images in each convolutional layer obtaining that the images retain their most outstanding features. With this, the need to define an extractor and a feature selector is avoided. This gives the possibility to build and test these types of networks on learning-oriented emotions and this way finding out the effectiveness to classify these emotions.
According to our knowledge, there are no works dealing with convolutional neural networks and educational issues together. This work presents a convolutional neural network architecture, tested with a database of basic emotions; and tested with two databases of learning-centered emotions designed and created by the authors of this work. In addition, we present a comparison of the results when using the local binary pattern and geometry-based approaches. This paper presents an approach based on convolutional neural networks to the recognition and use of learning-centered emotions and a comparison against other approaches that we have tested for facing this topic.
The paper is structured as follows: Section 2 shows the work related to the databases of facial expressions and the techniques used for the recognition of facial expressions. Section 3 presents the previous work we have done to create both databases and recognizers. Section 4 shows the test results of the recognizers as well as the discussion about those results. Finally, Section 5 presents conclusions and future work.
Related works
Related work is divided into two parts. The first part is about facial expression databases and the second part is about emotional recognition in facial expressions using different techniques and approaches. The database section includes posed and spontaneous expressions as well as basic and non-basic emotions. The emotional recognition section includes topics about appearance-based, geometric-based, and deep learning approaches.
Facial expression databases
Face expression databases are a set of images that express an emotion, a situation, or an experience. There are several available databases. Some of them contain posed faces to represent specific emotions; other ones contain spontaneous emotions where the face represent the facial reaction to a situation. Next, the most important databases are presented and explained. Cohn-Kanade (CK) [8] and CK plus (CK+) [9] are databases that represent 6 basic emotions and they include Action Units (AU) annotations. The images represent the image sequence inside the Facial Action Coding System (FACS). Each expression begins as a neutral expression and then move to a peak expression (more intense expression). Each expression can receive an emotion label. In the plus version were added spontaneous expressions recording 84 novel subjects while they were distracted among each photo session. Radboud Faces Database (RaFD) [10] also includes photos of eight basic emotions. The photos were taken using Caucasian Dutch adults and children. Participants showed the facial expressions with three gaze direction and five camera angles. In addition, they complied requisites as wearing a type of shirt and having no hair on the face. In other works like SEMAINE [11] in addition to expressing six basic emotions, the database contains four dimensions of an emotion which are Valence, Activation, Power, and Anticipation/Expectation. In addition, spontaneous emotions were added taking photos while participants talked to an agent system. M&M Initiative (MMI) [12] contains image sequences of faces in frontal and profile view. MMI contains more than 1500 samples and the database is contained in a web-based direct-manipulation application. Two FACS coders labeled the images and videos. Geneva Multimodal Emotion Portrayals Core Set (GEMEP) includes an important set of images [13]. In total, it contains 18 portrayed discrete emotions labeled using FACS. The databases were built using 10 professional French-speaking theater actors who were trained by a professional director. The corpus is comprised of over 7000 audiovisual emotion representations.
Table 1 shows 6 of the most popular datasets for facial expressions. We can see that most of the datasets only contain images of facial expressions representing the basic emotions. In addition, most of these emotions are not spontaneous (they are actuated emotions). The work of building an own database fills the gap of not having a set of data with emotions related to education which is necessary for the training and construction of a new recognizer for leraning-centered emotions.
Facial Expression Datasets
Facial Expression Datasets
Appearance-based techniques apply operators and filters over the pixels of the image in order to obtain a set of representative features of the face. Local Binary Pattern (LBP) is a method that takes the pixel value of the image center as the threshold [14]. Each pixel value is compared against the threshold; if the threshold is bigger than the pixel value then the resulted is zero, otherwise, it is one. This technique was applied to identify face expressions in [15], and the results were satisfactory. Local Phase Quantization (LPQ) uses blur insensitive texture classification through local Fourier transformation neighborhood by computing its local Zernike moments. The process generates LPQ codes, and collect them into a histogram. This descriptor is ideal for image blurring. Some works have proven LPQ can be used for expression recognition with FACS [16]. Histograms can reach up to 25,000 features so that indicates that LPQ covers an extension area of the face. Gabor representation [17] is a representation of a convolving of an input image using a set of Gabor filters with various scales and orientations. Gabor filters encode componential information, and depending on the registration scheme. The overall representation may implicitly convey configurable information. This technique can be used with simple dimensionality reduction techniques such min, max and mean grouping. The representation is robust to registration errors to an extent as the filters are smooth and the magnitude of filtered images are robust to small translation and rotations. The feature amount can reach up to 165,000 values.
Geometric-based techniques [18] frequently represent faces as a facial point representation. These points describe a face by a concatenation of X and Y coordinates of fiducial points. To represent a face in these techniques there is two type of representations of models: the first is the free model which detects feature points individually by performing a local search. The located points are called facial landmarks. The second is model-based focuses on measuring distances between the real face and a template. The template represents the most of the cases a neutral expression. Conditions as illumination variations are not an issue because the intensity of the pixels is ignored, unlike appearance-based techniques. The most of the research work complement their extraction feature techniques adding facial points as additional data for improving the recognition. Majumder et al. [19] present a model of emotional recognition using a Kohonen self-organization map (KSOM) which is trained with 26 dimensional geometric feature vector. The vectors are built from feature points on eyes, lips, and eyebrows. The nose is the central part of measurements. The facial movements are measured as a reference using the neutral expression. Some features are measured using the calculation of the area at the opening of the eyes, the distance from the opening of the mouth from lip to lip, and the distance between the corners of the lip and the edges of the nose. Salmam et al. [20] focus on introducing a new extraction feature technique using a geometry-based approach. They used the Supervised Decentration Method (SDM) for nonlinear least squares (NLS) problems. In their extraction technique of facial points, they obtain up to 80 features points of the face, eyes, lips, eyebrows, mouth, and nose. After distances are measured, they use the three types of formulas on measurements Euclidiana, Manhattan and Minkowski.
A convolutional neural network is composed of multiple processing layers which are used to learn data representation with multiple levels of abstraction. The method does not necessarily perform feature extraction or feature selection. A proposal of identification of high-level features is presented in [21]. The authors introduces their new deep learning approach which consists of adding a new layer named Deep hidden IDentity features (DeepID) which identifies a large number of classes using def-pooling. The work follows a normal configuration of a convolutional network with the difference that DeepID layer is located between the last convolutional layer and the soft-max layer. In [22], the authors present a method to reduce the complexity of the problem domain removing confounding factors. The authors used the feature extraction method local binary pattern (LBP). They preprocessed images transforming them in gray scale images and cropping the region of the face. LBP codes are mapped to a 3D space applying multi-dimensional scaling which is a code-to-code dissimilarity scores based on an approximation to the Earth Mover’s Distance. Kim in [23] presents an interesting analysis of convolutional neural networks. They present a new pattern recognition framework. The pattern consists of a set of deep CNNs that are interconnected with various committee machines (also known as classifier ensembles). Each CNN is independently configured; this means that each CNN is an individual member inside of the framework; also, each CNN was trained using different datasets where each dataset is created using a distinct preprocessed for the original image dataset. The work in [24] the authors presented a method to recognize static facial expressions; they use three techniques to detect faces in the SFEW 2.0 dataset: the joint cascade detection and alignment, the Deep-CNN-based, and the mixtures of trees. They applied a pre-processing over the images; each one is resized to 48×48 and transformed to grayscale. They propose a CNN architecture of five convolutional layers but instead of adding pooling layers in each connection among convolutional layers, they use stochastic pooling because it has proven giving a good performance with limited training data. The techniques used for building the CNN are the use of generating randomized perturbation in the dataset, the modification of the loss function for considering the perturbation, a pre-training of CNN using the FER dataset, a fine-tuning of the CNN using the SFEW dataset, and multiple networks for learning.
As we can see, the previous works are oriented to the recognition of basic emotions, predominating the emotions of the Ekman model. On the other hand, although the works have tried to improve the algorithms for convolutional neural networks, an architecture for an educational domain has not been designed and implemented, which is the main point of our work.
Facial expression recognition
Next, we present three methods for recognizing facial expressions. The first two methods were previously reported in other works. These methods are explained to give a proper context of how to they work. The third method is a CNN and we describe the features and parameters used in its architecture.
Local binary pattern
In the work reported in [4] we described how the pattern recognizer was created using LBP. This method is based on the work of Happy [12]. The method detects the nose, mouth, eyebrows, and eyes as separate objects. Those objects are transformed into six separate images. For each image, the following filters are applied (in the order they appear): Gaussian Blur, Sobel, Otsu’s Threshold, Binary Dilation, and Removing Small Objects. Then, the last pixels on left and right ends from eyebrows are established as key points. In the case of nose and eyes, their central positions are established as key points. Using each key point on face, facial patches are calculated. These facial patches has a proportion of one sixteenth of the face width. A LBP uniform operator is applied to each facial patch. The operator has a configuration of 9 neighborhoods with a radius of 2. A LBP operator is applied to each pixel in the facial patch. This action generates a binary number by comparing each pixel value against the center pixel value. When the pixel value is less than the center pixel value then the result is zero, else is one. The histograms obtained from LBP images are utilized as features descriptors. Each histogram is generated with 256 bins. Histograms are concatenated and normalized in a vector. A support vector machine (SVM) classifier receives the histogram and uses a one-vs-the-rest scheme to take multi-class decisions. Figure 1 shows the left-to-right process for extracting features using LBP.

Process to extract features using LBP operator and Facial Patches.
Our work reported in [5] explains how the geometry-based recognizer was developed. First, 68 landmark points are located on the face. These points are located using a template previously trained by dlib software [25]. The points are related to areas of the human face that express an emotion. In these areas of the human face are the lip, eyes, eyebrows, and nose. The face landmarks are a part of all the face features (X and Y coordinate values). However, one problem is that coordinate values may change depending on where the face is located in the photo. To solve that problem, the average value of both axes (X and Y) are calculated, so the center of gravity of all face landmarks is obtained. Those values represent the position of all points relative to the central point. The distances from the center to every landmark points are obtained. Each line has a magnitude (distance between both points) and a direction whose value is an angle in relation to the image where a 0° is the value of a horizontal line. Another issue to consider is that of the tilted faces. It is normal that users move their necks during computing activities. The rotations are corrected by offsetting all calculated angles by the angle of the nose bridge. This rotates the set of feature so that tilted faces become similar to non-tilted faces with the same expression. In this case, the angle is calculated with function arctangent, depending on if the nose bridge is perpendicular to the horizontal plane, for adding or subtracting a compensation value (90 degrees). Coordinates, distances, and angles are concatenated as input inside a support vector machine. Figure 2 shows the feature extraction procedure in this method.

Process to extract features using geometric-based approach.
Convolutional Neural Networks (CNNs) are represented in a multi-layer architecture. Each layer has a specialized function. The convolutional layers have the goal of extracting features and patterns from the images. The pooling layers have the goal of decreasing the number of final features and reducing bias problems. The neural network layers have the goal of classifying the data obtained from the previous ad-jacent layers. After trying several architectures and based on a similar work (LeNet [27], which uses 2 convolutional layers, 2 max-pooling, and 3 fully connected). The architecture that showed a better performance consists of nine layers (excluding dropout connections); each convolutional layer contains 64 filters. Figure 3 shows the architecture designed, which consists of three convolutional layers, 3 max-pooling layers and 3 fully connected neural networks layers.
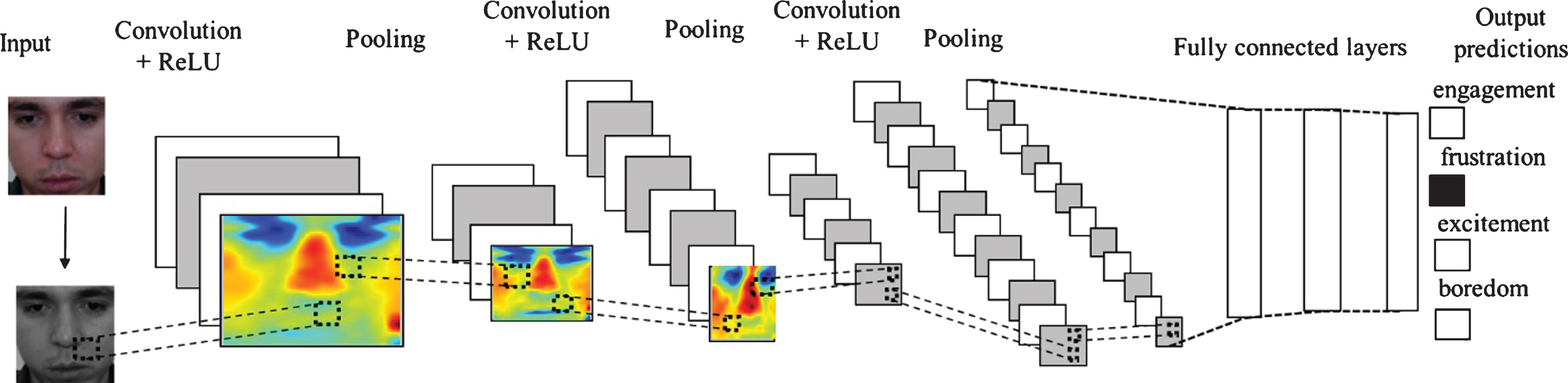
Convolutional neural network architecture.
Preprocessing is not a part of the architecture. However, a CNN has the inconvenience of needing a powerful hardware. The use of filters in a large number of images with multiple dimensionalities causes an important workload on the CPU. Applying a preprocessing step help to achieve converging a CNN model adequately. The process consists of locating a region of interest (ROI) in every facial image. The viola-jones method [26] and OpenCV software were used. After the ROI is located, it is subtracted from the image and transformed to a size of 75×75 pixels. At the end, the image is converted to a grayscale image and saved into a new database.
The convolutional layer
As mentioned above, a convolutional layer applies the mathematical convolution operation or process which consists of 3 elements: one is the data input which is usually expressed as a multidimensional array of data. Another one is the kernel which is a multidimensional array of parameters that are adapted by the learning algorithm. The last element is the output which is known as the feature map. Multidimensional arrays are called tensors. The main idea behind the network is that the kernel can identify the visual patterns that come from the input (edges, lines, colors, etc.) and thus be able to differentiate the visual pattern between the different objects. In the convolutional process, the kernel is overlapped on the input and then a crossover operation is performed, which is equivalent to a convolutional operation. Each value of the input is multiplied by the value at the same position in the kernel and the resulting values are sums that are placed in the output. The process is as follows: first, the kernel is overlapped on top of the input image; second, the product between each number in the kernel and each number in the overlapped input is computed; third, a single number by summing these products together is obtained; fourth, the obtained number is set in a convolutional output; fifth and last, the kernel is moved to the next section in the input image. An example of the convolution process for a part of the face is shown in Fig. 4, where the numbers shown in the figure are just to simplify the example. The patterns we need to detect are more related to the shapes rather than to the colors, so that the images are preprocessed to black and white. This also helps to decrease the dimensionality of both the inputs and the kernel. In addition, a ReLU (Rectified Linear Units) function was added which modifies the values in the convolutional layer without affecting its important properties. The function takes the values of the output and in case they are less than zero, it leaves them in zero. One of the characteristics of the function ReLU is that it has a non-linear property. We consider the function ReLU as part of the activation function of the convolutional layers. The pixel values of the face is interpreted as an array and the kernel is overlapped with an output. In the architecture we placed 3 convolutional layers with the activation function ReLU. The configuration used is a kernel of size 3×3, 64 filters for each one, and a stride of size 1.
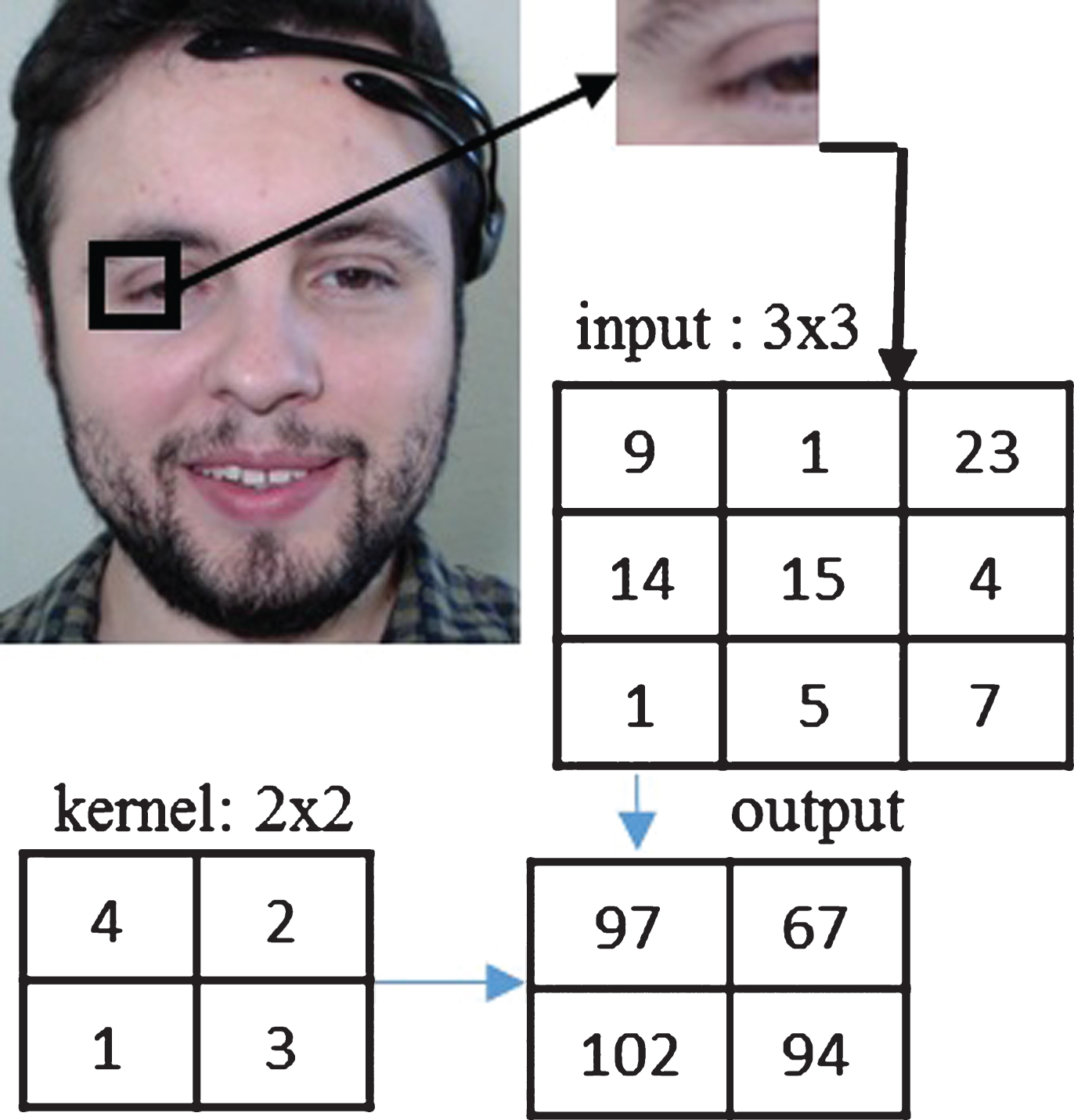
Example of the convolutional process of part of the face.
A typical convolutional neural network architecture consists of three stages for feature extraction. In the first stage, one or more convolutional layers perform in parallel a series of linear activations. In the second step, each convolutional layer executes a linear activation function called ReLu. These first two stages are sometimes called the detection stage (similar to the feature extraction process from other methods). In the third stage, we used a pooling function to modify the result obtained from previous steps. Pooling is a grouping function to replace the obtained values from the convolutional layers. Max-pooling is the most used grouping function, which holds the maximum values as output. Other common pooling functions include the average of a rectangular neighborhood, the L2 norm of a rectangular neighborhood, or a weighted average based on the distance from the central pixel. A pooling layer has the utility of reducing the spatial dimension of a convolutional layer before sending the data to the next convolutional layer (or any other type of layer). The operation performed by this layer leads to loss information and is referred to as “sample-down”. The operation used in the designed architecture is max-pooling with a window of size 2×2. The max-pooling process selects the max value of a selected area (Window). Figure 5 shows an example of application of max-pooling on a data entry. Numbers shown in figure are a simplified example.

Max-pooling process on an input data.
The architecture has three fully connected neural network layers. A fully connected layer takes all units in the previous layer (no matter what type of layer is). Fully connected layers are not spatially located anymore, so it is no possible having convolutional layers after a fully connected layer. The first two layers use ReLU as activation in their outputs, but the third layer (classification layer), uses Softmax as activation function. Another feature of the first layers in the CNN architecture is that they have a Dropout connection. The intention is to reduce the saturation of data between the layers of the neural network thus avoid bias in the data that affects the classification process. The Dropout connection selects randomly a part of the data input and places the values of that part at zero. This connection performs the dropout task in each training stage iteration. The fraction of the selected data is 50%.
Configuration of the CNN architecture
Table 2 shows the configuration of the CNN architecture. It includes data about the name of the layer, the type of layer, and the sizes of input and output dimension for each layer. Conv2D means a convolutional layer of two dimensions; MaxPooling2D represents a max-pooling layer of two dimensions; Flatten indicates a layer that transforms a matrix into a one-dimension vector; Dense specifies a densely connected neural network; and Dropout denotes a layer that performs a dropout operation. Convolutional layers have different dimensions because a kernel of 3×3 is overlapped in layers; this generates a reducing of data in each layer. Max-pooling uses a strider of 2×2 causing a reduction of up to almost half of the data in each layer. To improve the classification, we decided to flatten data before giving it as input to a first dense layer. Dense layers do not suffer modification in data dimension, except the final dense layer that reduces data to 15 units.
Description of the CNN architecture
Description of the CNN architecture
An essential part for any recognition system is the database for training (Fig. 6). Databases contain relevant information for any recognition system be able to discriminate important data to classify. We proposed a new method to build face expression databases using two EEG-based Brain-Computer Interface (BCI) systems: Emotiv Epoc and Emotiv Insight. They are interface systems that capture the brain activity and give information about the emotion that student is feeling. Next, we describe the used devices and methods.
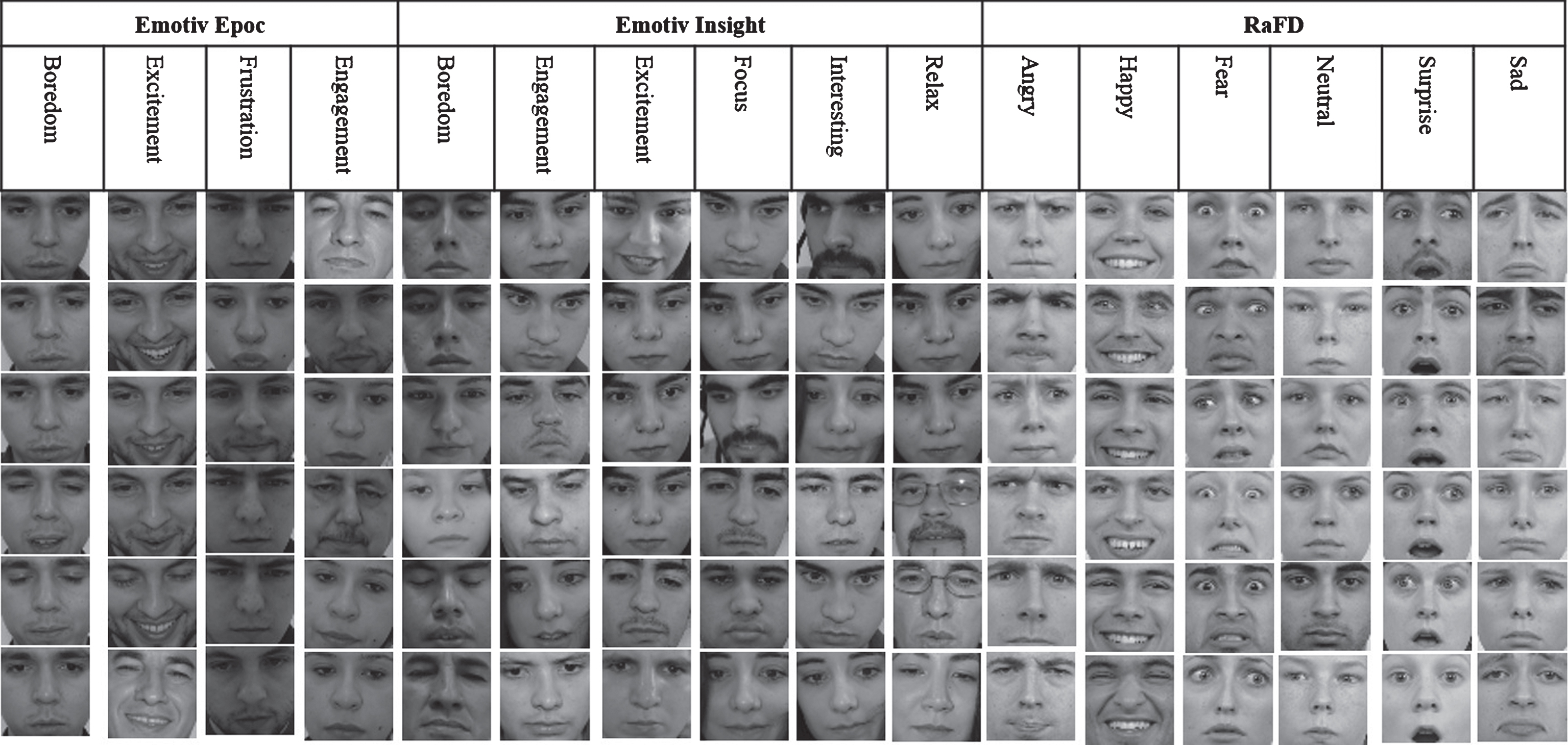
Photos of a part of three databases.
EEG is a technique for monitoring the brain’s encephalographic signals. It is a non-invasive technique where electrodes are placed on the scalp. Emotiv EPOC is a device built by the bio-informatic and technology company EMOTIV inc [27]. The set of tools of Emotiv is a wireless neuroheadset which works with bluetooth signals, a SDK to develop applications to gather and analyze data, a suite of desktop applications for the Emotiv EPOC, and a suite of mobile applications for the Emotiv Insight.
Protocol for building and filtering the facial expression database
We looked for a method to capture expressions during an educational context. In addition, we looked for an activity related to the domain of the intelligent tutoring system that uses the facial recognition system. The protocol followed for the creation of the database was as follows: The data was captured with 38 students from the Instituto Tecnológico de Culiacán with 28 men and 10 women. The participants were between 18 and 47 years old. The students wrote, compiled and executed programs in Java with the Emotiv diadem obtaining their emotional state during the coding of the program. In most of the works for building facial expression databases, experts in judging emotions participate in the annotation process to tag the captured images of students or users. In our work, the labeling is carried out automatically by an application and with the help of Emotiv. Figure 7 shows the used method and it is explained as follows: The student codes a Java program; meanwhile, the Emotiv device captures brain activity and the webcam takes a photograph every 5 seconds. Every photograph is labeled by system with the user emotion obtained at that moment from the Emotiv device. The annotation is made by an application that takes emotion from the Emotiv device and labels the photograph with that emotion. The photo previously labeled is saved into the facial expression Database. Finishing the previous steps, a group of experts evaluates if there is a match between the emotional label and the expression in the photo. If so, the photo is saved; otherwise it is discarded.
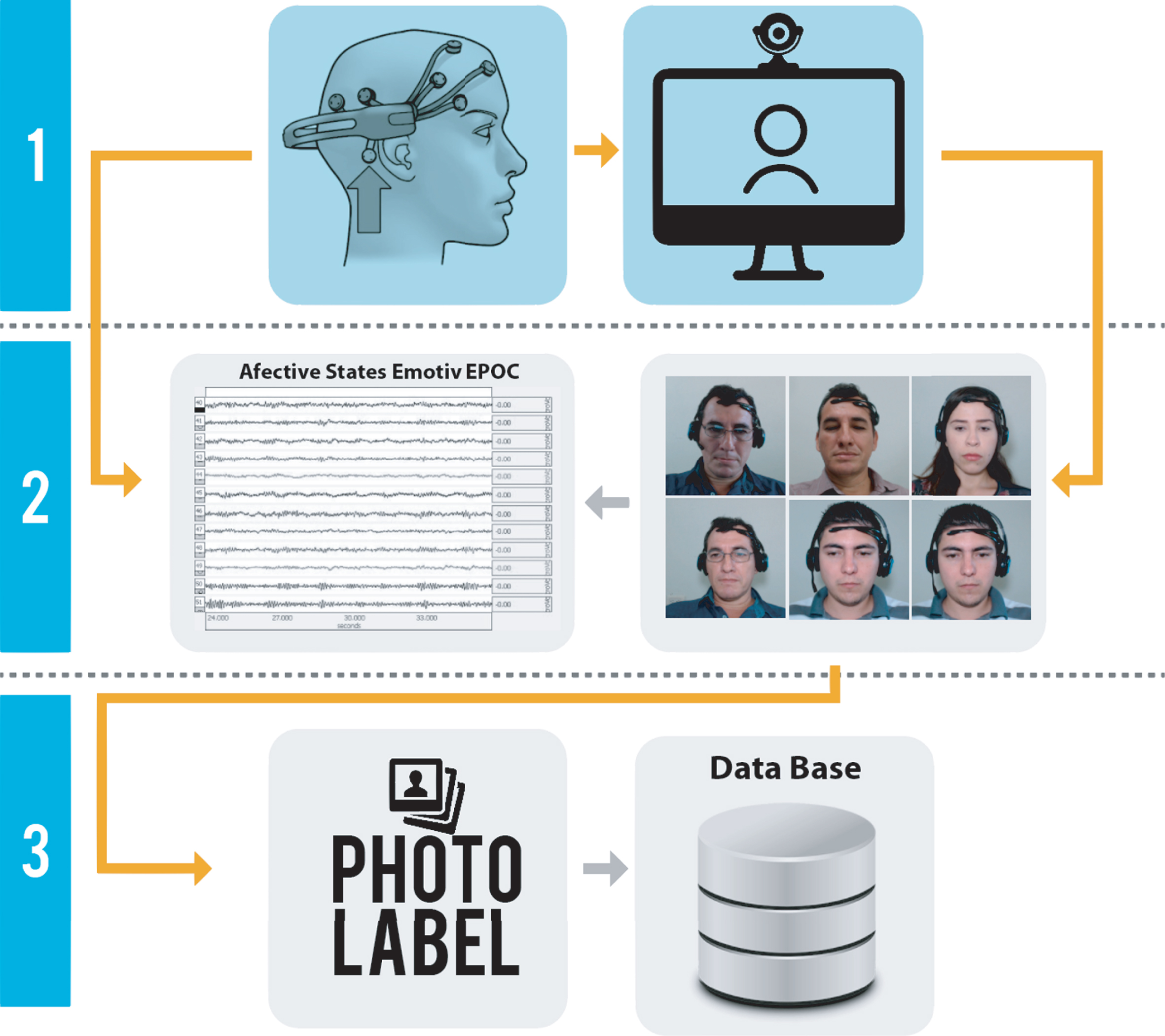
Method to take photographs for face expression database.
We obtained two databases, one by each Emotiv device. The Emotiv epoc database stored a total of 7,019 photographs. However, several photos had not a proper matching with their labeled emotion. We proceeded to filter the database eliminating incorrectly labeled photos obtaining a database of 730 photographs. This debugging process helped us to have a database with a validation also from human judges to have a database with properly labeled facial expressions.The Emotiv insight database obtained a total of 5560 labeled images; this database has not received a filtering process so it keeps its original size. Figure 6 shows parts of both facial expressions databases.
We show and explain the tests performed to the recognizers that were trained and tested with different databases. The tests consisted of measuring the accuracy of the recognizers using the RaFD database and the two databases built with Emotiv Epoc (dbE) and Insight (dbI). In the case of RaFD we decided to use 6 of the 8 basic emotions because they are the most common emotions in other research work, so we could make comparisons of our results to better validate our emotion recognition. Table 3 describes the contents of the three databases.
Description of databases
Description of databases
The RaFD database [10] contains a total of 1146 photos; 191 photographs for each basic emotional class. The Emotiv Epoc and Emotiv Insight databases contain images of learning-oriented facial expressions and have three emotional labels in common. The distribution of classes of the databases built with Emotiv are shown in Table 4.
Class distribution for databases built with Emotiv Epoc and Insight
The test consists of a cross validation of k = 10. This means that the recognizers will be trained and tested 10 times using a different segment of the input data in each training step. Data were divided into 90% for training and 10% for precision testing at each iteration. The data selection was random for both the training data part and the testing part. The division of the data did not take into account if a person existed in both parts of the data since the objective is the general recognition of an emotion in people and not in a particular individual. The features obtained from the LBP and Geometric-based techniques were used to train three classification algorithms: Support Vector Machine (SVM), Artificial Neural Network (ANN) and K-Nearest Neighbors (KNN). In addition, a test was added where the convolutional filters (CF) are applied to the images. The results of these filters were used as input features for the three classifiers mentioned above. The accuracy obtained in the three databases in combination with the classifiers and extraction techniques is shown below.
With the RaFD database, most of the methods did not obtain significant results. Only two combinations obtained results over 85% of accuracy. SVM and the Geometric-based method obtained a good result but the CNN obtained a value close to 100%. Table 5 shows the results for the tests with the RaFD database.
Accuracy obtained with database RaFD
With the dbE database, most methods obtained an accuracy between 80% and 85%. Accuracy values show how a filtered database can help classifiers to get a better accuracy. Table 6 shows the test data for the database dbE.
Precision obtained with the database dbE
With the dbI database, we obtained lower results than the other two databases (RaFD and dbE). One reason of the lower results is that this database contains an amount of photos five times greater than RaFD or dbE and they have not received a filtering process. The CNN obtained an average accuracy of 74% which we consider is a good result that should improve a lot once the dbI database goes through a filtering process. Table 7 shows the results for the database dbI.
Precision obtained with the database dbI
In the case of the RaFD database and using the CNN architecture we obtained a precision of 95%. Only the combination of geometric-based method with SVM came close to what was obtained with this architecture. This clarifies that in the case of a database of basic emotions with discrete and acted emotions the architecture has no problem. In addition, if we contrast this result against other works that have been tested with different databases of basic emotions, we can find that we obtained satisfactory results. For example, in Ilbeigy’s work [28], they used a technique that combines traditional feature extraction with fuzzy sets where they obtained 93.95% accuracy and Recio [29] averaged less than 90% in all experiments. RafD has not yet been tested with convolutional neural networks. However, we can compare our work with [25], which uses convolutional neural networks that were tested with two databases of basic emotions (CK [9] and Geneva [13]) obtaining a maximum value of 98% accuracy.
In the case of dbE the obtained precision had a value of 88% using the CNN architecture, which is superior to the other combinations of proven recognition techniques. In previous work [4, 5], in the tests with this database we reached a maximum value of 86% accuracy, clarifying that there were some notable differences between both tests. In these reported works the database was reduced because the recognizer could not identify all the parts of the face in several photos, which is fundamental for the feature extractor, reason why only 20% of the faces were detected. Comparing this work with other research is complicated. To the best of our knowledge, the problem of recognizing non-basic emotions using convolutional neural networks has not been addressed. In [30], we found an emotion recognition work using database Acted Facial Expressions in Wild, a database that collects images of movies to catch more realistic expressions. This work obtained an average below 70%, where six of the seven emotions analyzed obtained a percentage below 70%. With this, we can conclude that our recognizer has high accuracy since it identifies non-basic emotions obtained from a real programming context. There have also been work that have made a comparison with non-basic emotions but without using convolutional networks. The work of Bosch [31] is an example of this, where they obtained a precision less than 70%.
In the case of dbI, lower percentages were obtained compared to the previous databases. By joining the LBP and ANN methods, we obtained similar precisions to the CNN architecture. This helps us to understand that the database still requires work similar to dbE. A filter job has not yet been performed on this database and has an unbalanced class problem. Even so, we consider our results as satisfactory, because the previous comparisons with [31] and [30] give a clear idea of how complex it is to work with a database with spontaneous expressions.
This work presents an architecture of a convolutional neural network for the recognition of learning-centered emotions. The proposed architecture consists of 3 convolutional layers each followed by a max-pooling layer, and finally 3 layers of fully-connected neural networks. The CNN was tested with 3 facial expressions databases: one database contains posed or acted basic emotions and two databases contains spontaneous learning-centered emotions. The evaluation suggests that the architecture can perfectly detect facial expressions of acted basic emotions by having similar and superior results than other popular methods when detecting similar emotions. Evidence also shows that learning-centered emotions can be successfully recognized in the event that the database is validated and filtered. Our architecture is the first one to prove itself with this type of emotions and expressions. Many of the tests with this type of architectures have been done with databases for acted expressions or for spontaneous expressions that have no relation with the learning process. In addition, we validate the importance of two new databases built by us and their importance and effectiveness in the training of different types of classifiers. As a future work we have to perform tasks such as increasing some classes (emotions) that are unbalanced in the database dbI, trying new architectures with other layers of pooling, and performing different filtering and pre-processing methods on our databases dbE and dbI.