
Abstract
The number of features for fault diagnosis in rotating machinery can be large due to the different available signals containing useful information. From an extensive set of available features, some of them are more adequate than other ones, to classify properly certain fault modes. The classic approach for feature selection aims at ranking the set of original features; nevertheless, in feature selection, it has been recognized that a set of best individually features does not necessarily lead to good classification. This paper proposes a framework for feature engineering to identify the set of features which can yield proper clusters of data. First, the framework uses ANOVA combined with Tukey’s test for ranking the significant features individually; next, a further analysis based on inter-cluster and intra-cluster distances is accomplished to rank subsets of significant features previously identified. Our contribution aims at discovering the subset of features that discriminates better the clusters of data associated to several faulty conditions of the mechanical devices, to build more robust multi-fault classifiers. Fault severity classification in rolling bearings is studied to verify the proposed framework, with data collected from a test bed under real conditions of speed and load on the rotating device.
Introduction
There are constant increasing requirements for the continuous working of the transmission machines. This is why new approaches to build fault diagnostic systems with accuracy and reliability are highly valuable. Alternative computational approaches using Machine Learning (ML) for fault diagnosis have been developed by using Neural Networks [2, 25], Support Vectors Machines [39], Cluster Analysis [19] and Decision Trees [4]. These ML approaches have been very useful for implementing condition-based maintenance, as presented in [3, 15]. In case of ML-based fault diagnosis in mechanical rotating machinery, a sizable amount of features could be extracted from different signals which are processed to obtain condition parameters in time, frequency and time-frequency domain. There exist a wide set of alternatives to build robust classifiers, such as those based on decision trees and deep learning architectures, for which the number of input features does not decrease their performance [1, 16–18]. In the framework of the supervised feature selection, feature analysis is widely applied to select the most significant features improving the accuracy of machine learning based diagnostic models [2, 36], and more recently into a unsupervised manner [24].
Beyond the availability of complex robust ML models that can deal with a high dimensional feature space, the identification of the most significant features contributes to discover relevant knowledge about the application problem, at the same time that such features can lead to build more simple and also robust ML models, usually easier to interpret. Feature engineering arises as an essential topic in ML to identify features that are useful to build optimized models for explanation or for accuracy, from two perspectives of analysis, respectively: feature relevance and feature selection. Some works consider the analysis of the feature relevance as part of the feature selection process. Feature selection is a NP-hard problem, and several approximation algorithms have been proposed to find the near best feature subset over a reasonable time [5, 11]. Besides the most common metrics to measure the feature relevance, such as Gini Index, Information Gain, and Mutual Information (MI), statistic tests such as Chi-square and Analysis of Variance (ANOVA) can be used to measure relevant features regarding a set of class labels. They are very used for feature selection in text mining, emotion recognition, bioinformatics and medicine. However, its use in engineering applications to fault diagnosis is not widely reported.
This work is focused on both feature relevance and feature selection. Specifically, this paper proposes a supervised methodological framework for feature analysis using ANOVA and a cluster distance metric. In the first step, ANOVA is used to rank individually the statistical relevance of the features; in the second step, a cluster validity assessment index is used to rank the subsets of features that yield better cluster structures related to the failure modes, i.e. classes, under study. As result, a subset of features is identified, which reflects the discriminative information regarding the different classes. Previous works show ANOVA as powerful statistic test widely used to rank the feature relevance in supervised classification. Particularly, we are motivated in using ANOVA due to its ability to identify features discriminating set of data regarding the mean value, and this is considered a first step for selecting features that yield adequate cluster structures. ANOVA combined with other metrics to measure the ability of the relevant features to create proper clusters for classification is not studied, and this is our main contribution. A real dataset for fault diagnosis in bearings is evaluated to test our framework. Comparisons to the cluster structure obtained from the classic feature selection and reduction techniques are provided in order to show the performance of our algorithm. Finally, a K-Nearest-Neighbours (KNN) based supervised classifier is used to assess the performance of the selected features to give a proper fault diagnosis. Comparison to features selected by the Random Forest(RF) algorithm is also provided.
The following sections are organized as follows. Section 2 discusses some works related to feature selection preserving cluster structures, and related techniques to our proposal. Section 3 presents the theory used in this work. Section 4 introduces the proposed methodological framework for feature selection by using ANOVA and cluster validity assessment. Section 5 presents the results obtained with the proposed approach, and some analysis are developed. Finally Section 6 concludes the paper.
Related works
There are several works discussing the problem of feature selection for clustering from unsupervised or supervised manner. Compactness and separation measures are considered in [6], to quantify features that ensure the proper intra and inter cluster scatters. More recently, some works aim at preserving the cluster structure of the samples composing the dataset. In [34], an unsupervised feature selection method using a group sparse feature selection on local learning based clustering is proposed. In [7] a feature selection based on Mutual Information is developed to identify salient features, that are useful for maintaining the nearest and farthest neighbours from an instance, or sample. In [28], spectral clustering is introduced to discover the cluster structure and discriminative analysis between features is used to preserve the structure. In [21], the feature selection is based on the idea of minimizing the violation of the initial cluster structure and penalizing the use of features. Other approaches for feature selection are proposed into supervised environments, where MI is the main index used to rank features [20]. Recently, [32] proposes the use of a self-similarity factor as indicator to measure the feature importance into an affinity propagation based clustering process.
With regard to the use of ANOVA, it is reported for feature selection in classification of data related to gas chromatography [27, 31]. In [14], the performance of the selected features by using ANOVA is tested regarding their ability to yield proper clusters after applying feature reduction with Principal Component Analysis on data related to chromatographic features relevant to a given classification of jet fuels. ANOVA has been also reported as technique for feature relevance analysis in other types of industrial devices. In [9], ANOVA is performed over data obtained from the stator current of an induction motor, where different fault conditions are simulated by a progressively hole drilling into a rotor bar. In [10], multivariate ANOVA is applied for feature selection in internal combustion engine valve clearance fault classification; next, the Wilks statistic is used to determine the class separation ability of other feature combined with the previous selected ones. In [30], ANOVA is applied to determine the effect of each individual parameter of the stator winding fault model response, for running the induction motor with the best parameter values in its parameters range. The effect of different valve conditions on the Root Mean Square (RMS) value at its corresponding time-frequency segments, extracted from the acoustic emission signals, are analysed by using ANOVA in [29].
In the field of fault diagnosis of rotating machinery, the vibration signatures are analysed by one-way ANOVA method in [37] to conclude that a faulty state can be identified from the healthy one, but some faulty states cannot distinguish between them. In [12], two stage feature selection through ANOVA and a weighting technique is used to diagnose the gear crack development. In [38] ANOVA is applied to select the most relevant principal components to diagnose faults in a multi-shaft centrifugal compressor. In [22] ANOVA is used for analysing the main effects of the rotational speed and the radial load on the mean and standard deviation of the acoustic signal measured in dry and lubricated bearings. In [8] ANOVA was used to determine influence of the blade vibratory amplitude, the signal-to-noise ratio, the sampling time, and the sampling frequency on the side-band and noise amplitudes in the frequency domain of the vibration signal. ANOVA test was conducted in [35], in order to check the statistical significance of the gear fault separation by using RMS time synchronous average.
Background
Analysis of Variance (ANOVA) and Tukey’s test
ANOVA is a powerful statistical test to reject the null hypothesis H0 stated as H0 : μ1 = μ2 = … = μ
K
, where μ
i
, i = 1, …, K are the means of the K different data population, under assumption of the population independence, normality and homoscedasticity [23]. However, ANOVA can works well enough even under slight assumption violations. The alternative hypothesis H
a
states that H
a
: μ
i
≠ μ
j
for some i, j s.t. i ≠ j, j ≤ i. Each population, i.e. continuous values of the response variable Y, is characterized by one or more categorical factor, then ANOVA compares the means of the response variable into the different factors levels. One-way ANOVA only considers one factor with two or more levels (or groups). To accept H0 in one way ANOVA, the F-test is used by computing the F-statistics given by Equation (1):
The F-value is expected to be approximately 1 under H0, however to reject H0, a high F-value is needed. A single high F-value is hard to interpret on its own. Then, the reference value to reject H0 is based on the p-value, which is the probability of observing a F-value that is at least as high as the value that our study obtained, under the assumption that H0 is true. Commonly, H0 is rejected if p ≤ 0.05. Once the ANOVA test rejects the null hypothesis, multiple comparison by using the Tukey’s test is required to identify any difference between two means μ
i
- μ
j
, by calculating the ratio in Equation (2):
In some applications of supervised classification, the cluster structure of a dataset could be an interesting information to select the proper features addressing better classifiers. In this work, an overall clustering validity index, called Composing Density Between and With clusters (CDbw), is used to measure the cluster structure [13, 33]. This index puts emphasis on the geometric characteristics of clusters, such as compactness and separation. According to [13], a cluster i is composed by n
i
samples
Given a cluster partition, instead of using only distance information, intra-cluster and inter-cluster density information are also considering by the index CDbw, as stated in Equation (3):
On one hand, Sep (c) in (3) considers both the inter-cluster distances and the inter-cluster density, as proposed in Equation (4):
On the other hand, Intra _ D (c) in (3) is defined as the number of points belonging to the neighbourhood of representative points of the clusters, as proposed in Equation (7):
The intra-cluster density and separation will be significantly high for well-separated clusters, then we use this metric to evaluate the obtained cluster structure when a subset of significant features is selected. More details about this metric can be found in [33].
In feature selection, it has been recognized that the combination of individually good features does not necessarily lead to good classification [26]. In this sense, feature selection performed in a way of individually feature ranking instead of globally one, is not considered as the best way to choose the more significant features. By using the p-value in the ranking process through ANOVA, several features can have very close value, or even some subsets of the relevant features discriminate better the fault classes than other subsets with the same best p-value. Then, further analysis after applying ANOVA might be oriented to a new ranking according to the cluster structure associated with the relevant features.
Our feature analysis includes a further analysis of the relevant features ranked by ANOVA, by using the cluster distance metric described in Section 3.2, applied to the clusters that have been created from the relevant features. This is with the aim of identifying the features that better discriminate certain fault modes. In this sense, several subset of features can be selected as input to a classifier dedicated to particular failures modes. This is specially useful for designing multi classifiers in real time industrial applications where noise and disturbances make the classification a sensitive task that could not be easily to solve with one centralized classifier. Of course, an exhaustive search must be developed to find the final subset of features; then, the feature selection might be formalized as a combinational optimization problem finding a feature set to maximize the quality of the hypothesis learned from these features. However, our work is not focussed on the searching algorithm but in the features analysis.
Let F, P and S be the sets of features, fault classes, and dataset, respectively, such that F = {f
j
}, j = 1, . . . , n, P = {P
i
}, i = 1, . . . , c, S = {(x
k
, y
k
)}, k = 1, . . . , m,
where S
f
j
denotes the feature ranking index, and
In the second stage, a set of classes
Finally, the n-tuple of the most significant features f
best
creating an adequate cluster structure for the set
Algorithms 1 and 2 show the pseudo-code to execute our methodological framework for feature analysis.
ANOVA and Tukey’s test algorithms
Cluster validity assessment algorithm
Note that
Experimental text bed
This section presents the case study for fault severity classification in rolling bearing. This device is composed of an inner and outer race, inside which the rolling elements rotate; Fig. 1 shows the experimental set-up. Two bearings are coupled with a shaft as supporting device. A motor drives the shaft at different speeds, and flywheels can be disposed on the shaft in order to induce loads, when required. Vibration signals are collected through four accelerometers placed in different positions, for monitoring the machinery state. One accelerometer is placed in a radial position, and other one in an axial orientation in the first bearing (B1); two more accelerometers are placed in the same positions for the second bearing (B2). In this study, only the bearing B2 is considered under faulty condition, and the bearing B1 is in the healthy state; Table 1 describes the fault condition on B2. A data acquisition device collects the vibration signals and send them to a computer. Ten samples of vibration signals were collected for each condition. Additionally, the three loads are considered through a magnetic brake, i.e., with flywheel (L1), no load but with belt (L2), and 10 V (L3).

Experimental test bed to extract features from vibration signals for fault severity diagnosis in bearings.
Fault conditions in bearing B2
The feature extraction for this case study was performed under the same procedure described in [24], and a set of 663 features for each accelerometer were calculated from 120 samples of vibration signals collected for each fault condition. The resulting dataset has 2652 features and 1200 samples. Our analysis was conducted by considering three different set of fault: (i) P1 = {P1, P2, P3, P4}, (ii) P2 = {P1, P5, P6, P7}, (iii) P3 = {P1, P8, P9, P10}. Classical feature selection and reduction techniques were applied to show the performance of the selected features for building adequate clusters. Figures 2 and 3 show the cluster structure obtained from the best three features selected by supervised approaches such as Random Forest (RF) and Linear Discriminant Analysis (LDA), with data from all the four accelerometers in the case (i). Figure 4 shows the performance of the first three features by using the unsupervised technique Principal Components Analysis (PCA). These figures show the associated clusters are overlapped and scattered.

Clusters obtained with the best three dimensional vector of original features by using RF applied over data from four accelerometers in case (i).
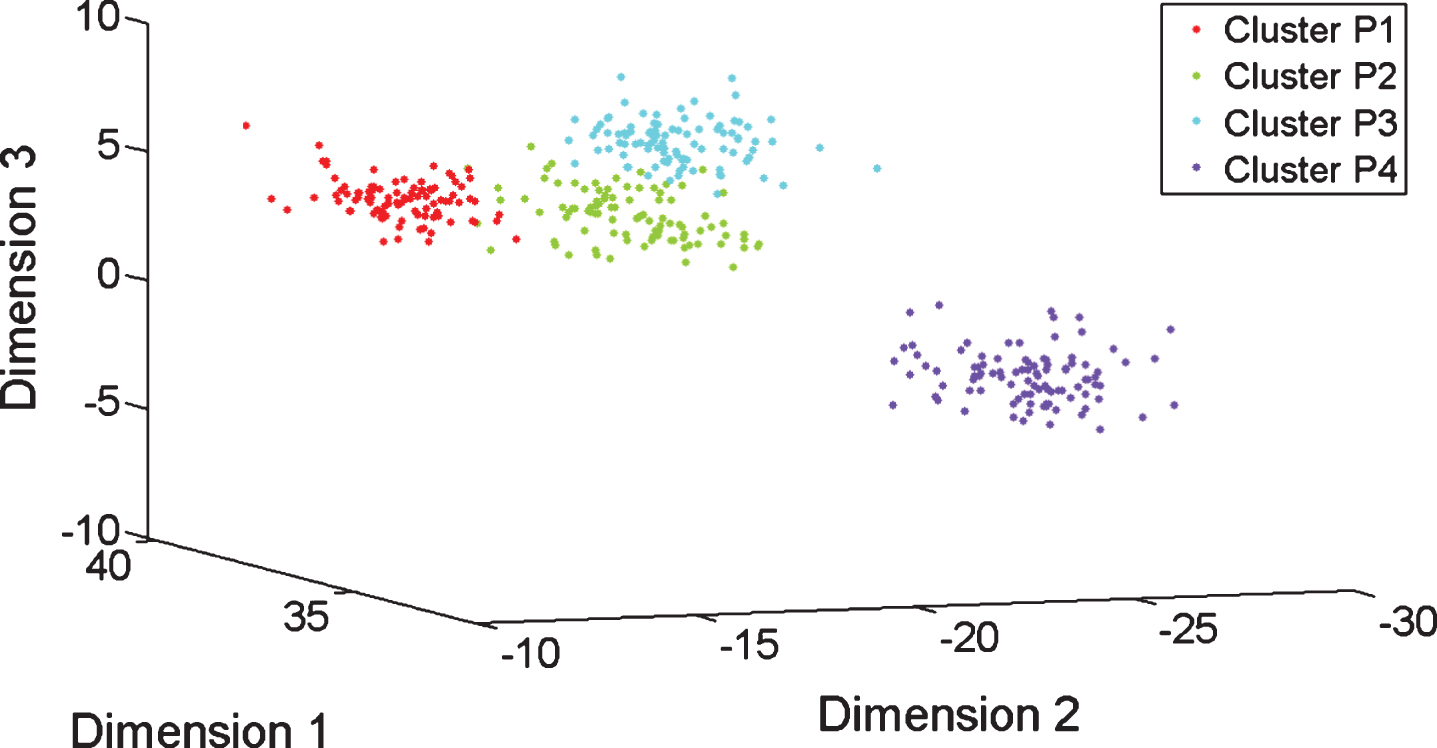
Clusters obtained with the best three dimensional vector of artificial features by using LDA applied over data from four accelerometers in case (i).

Clusters obtained with the best three dimensional vector of artificial features by using PCA applied over data from four accelerometers in case (i).
RF selects the best features from the original ones; the selected features are associated with the energy of the wavelet coefficients obtained from the Wavelet Packet Decomposition (WPD) using the wavelet family Daubechies 16. On the contrary, LDA and PCA propose artificial features obtained from the original ones. In this study, the best three artificial features, called Dimension 1, Dimension 2 and Dimension 3, are used as selected features. Next section shows that the proposed approach can select a three dimensional vector of features, from the set of the original features, better than the proposed vector by RF, LDA and PCA, regarding the cluster validity assessment.
Our proposed framework presented in Section 4 was used to select the best subset of three features, to build the best clusters oriented to fault severity classification in rolling bearing, for the experimental case described in the previous Section 5. According to some results, classical features for fault diagnosis, as the extracted ones in this work, can be considered close to normal distribution, then ANOVA can be applied [40]. The analysis is performed over the 80% of the available samples. The remaining 20% will be used to test the performance of the selected features in classification. As mentioned previously, the analysis was conducted by considering the three sets of faults P1, P2 and P3. Then, three analysis were performed by using the algorithms in Section 4. In the first step, the set P to apply the Algorithm 1 is composed by the classes in P i , and all the 2652 features were analysed in the following manner: (i) 1326 features from the accelerometers in the radial position, (ii) 1326 features from the accelerometers in the axial position, and (iii) all the 2652 features from all the four accelerometers.
In order to have statistical significance, the Algorithm 1 is applied for 30 repetitions, over a random selection of the 80% of the samples previously selected for analysis. After applying the algorithm with Th
s
= Th
PW
s
= 0.05, the result of the selected features is shown in Table 2 regarding the accelerometer placement (ACC), the number of features selected by one-way-ANOVA (NF (p < Th
s
)), the number of features selected by the pairwise comparison (NF (
Results of the Algorithm 1
Results of the Algorithm 1
In the second step, the Algorithm 2 was applied for each set F p obtained according to the set of study P i . Table 3 shows the results regarding each subset P i , the accelerometers placement, the value of the CDbwF z for the set f best , and the individual ranking of the selected features in F p according to the Equation (9). Table 3 shows that, in fact, the best individual features do not leads to the subset of features having the best value of the CDbwF z .
Results of the Algorithm 2
Figures 5, 6 and 7 illustrate the cluster structure obtained with the subset of three features having the maximum value of the CDbwF z . Axes labels describe the selected features; in most of cases, features related with the energy of the wavelet coefficient from the WPD using the mother wavelet Daubechies 16 were selected. It shows the importance of the time-frequency representation for feature extraction, in the field of fault diagnosis. Particularly, the features in Fig. 5 differs from those ones in Fig. 2 selected for the same case (i) by using RD; the cluster structure in Fig. 5 is better than the cluster structure in Fig. 2. Other selected features were the standard deviation on a certain frequency band, see Fig. 7. In case of P1, the best value of CDbwF z is the same with features from the accelerometers in radial position and all the accelerometers, as the same features are selected; then, the information provided by the two axial accelerometers is not useful. In the cases of P2 and P3, the best values of CDbwF z are obtained with features from all the accelerometers. The clusters have adequate overlapping and scattering. Particularly, Fig. 5 shows the selected features produce better cluster structure than that one produced with features selected from RF and PCA, as illustrated in Figs. 2 and 4, respectively. Regarding LDA in Fig. 3, the results of our framework in Fig. 3 makes that the cluster P3 is separated better from P2.
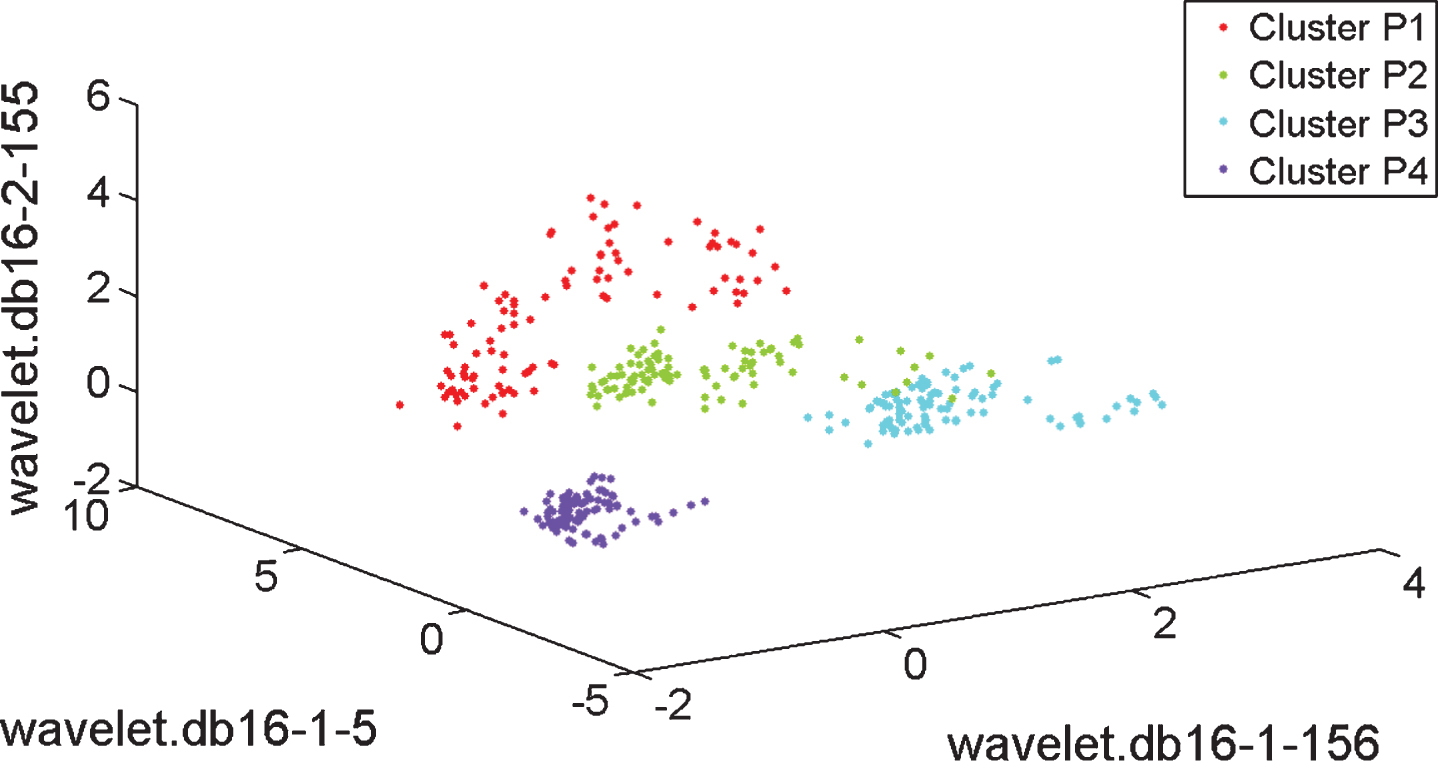
Clusters obtained with the best three dimensional vector of original features by using ANOVA and Clustering Validity Assessment, case (i), four accelerometers.
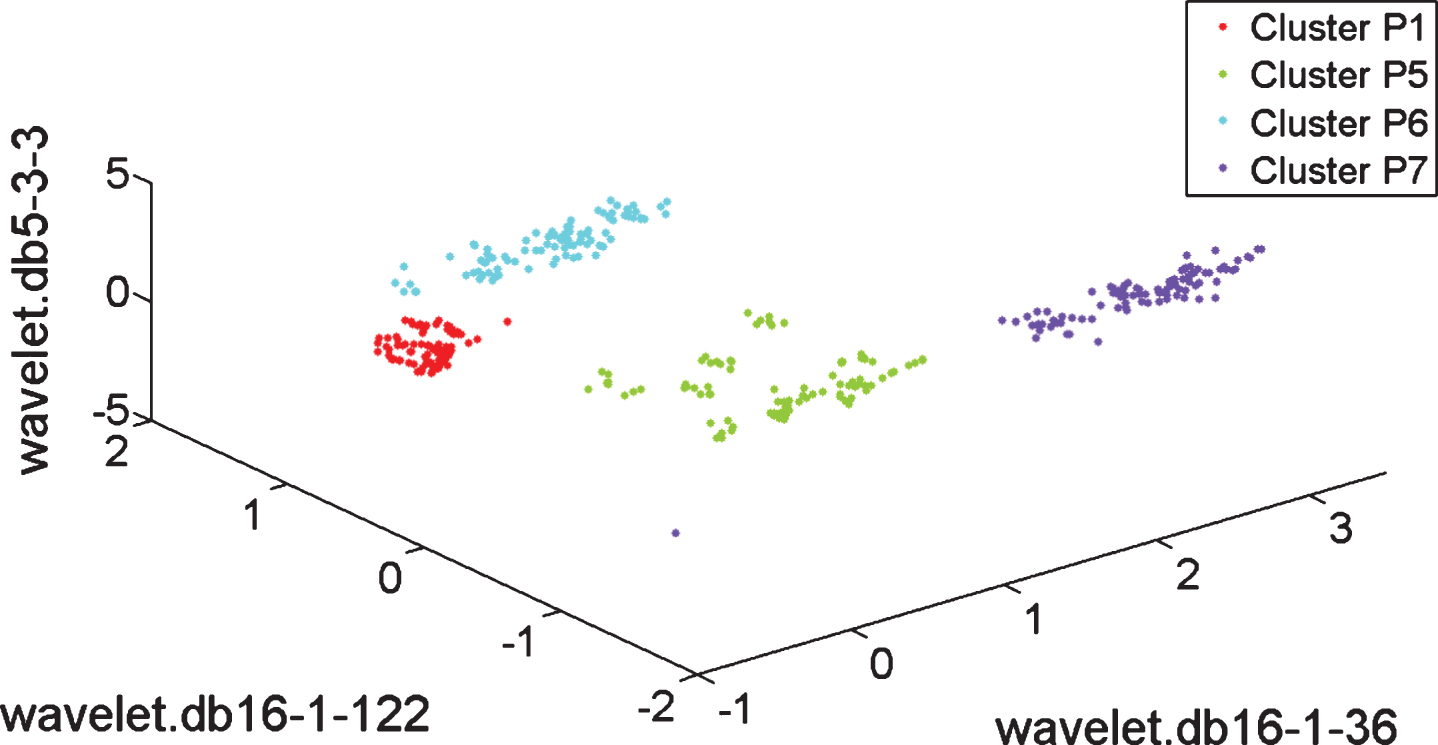
Clusters obtained with the best three dimensional vector of original features by using ANOVA and Clustering Validity Assessment, case (ii), four accelerometers.
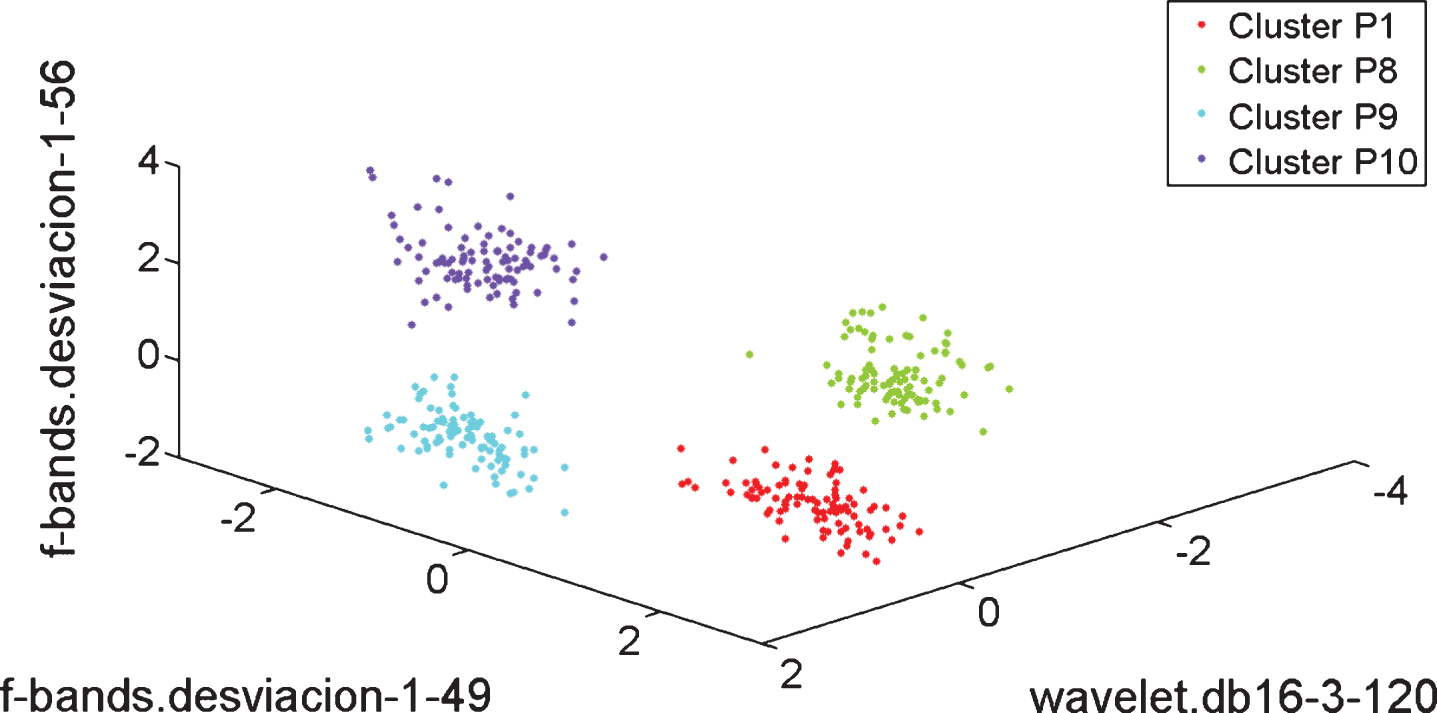
Clusters obtained with the best three dimensional vector of original features by using ANOVA and Clustering Validity Assessment, case (iii), four accelerometers.
KNN is a very simple ML algorithm which is widely used to test the performance of feature selection approaches for classification. Clearly, the success of the KNN depends on the cluster structure of the data instances. To test the proposed feature selection, three KNN-based diagnosers have been developed by using each subset of the selected features for the sets P1, P2 and P3. For each case, the performance of classification is measured according to the precision to classify the samples with labels belonging to the corresponding subset P i , based on the Euclidean Distance (ED) with regard to 20 neighbours.
Additionally, samples s
j
with P ∉ P
i
are also treated by each classifier in order to measure the ED regarding the closest samples in the class to which the KNN classifier is assigning this sample. Of course, this classification is wrong but the measured distance can be used as useful information to decide if the classification is good or not. Let s
j
be a sample with P ∉ P
i
that is assigned to a class P
i
∈ P
i
, and
The previous metrics are defined to have reference values which can be used to define some threshold to suggest if the sample assigned to a class P i with a specified KNN classifier could be not correct. The design of this threshold is not developed in this work, and the previous measures are only used for analysis purposes. The following classification results are obtained by using the feature selection with signals from all the four accelerometers.
Classification for the set P1
Table 4 shows the results of classification for the set P1 with samples having a label P i ∈ P1 and P i ∉ P1. The precision to classify the faults with labels P1, P2, P3 and P4 is quite good. The decrement of the precision to classify the class P2 is due to samples classified as class P3. In the following rows of the table, the minimum, maximum and average ED of the test samples correctly assigned to the classes, regarding the samples of the class, are stated.
Results of KNN based classification, set P1
Results of KNN based classification, set P1
In second part of the Table 4 the results by using samples with P i ∉ P1 is stated. In this case, 18, 100, 137 and 707 are the number of samples wrongly assigned to class P1, P2, P3 and P4, respectively. The minimum, maximum and average ED were also calculated. For example, the minimum ED obtained from samples wrongly assigned to P1 was 0, 5996, this value is up of the maximum ED, and quite up of the average ED, obtained for samples correctly classified. The average ED from of samples wrongly assigned to P1 was 1, 5281 and this value is quite up of the average ED obtained for the samples correctly assigned to P1. Then, this information can be used to define some metric or threshold to suggest the sample assigned to a class P1 with this KNN classifier could be not correct. A similar analysis can be concluded in case of P3. Then, based on the KNN classifier using the selected features for classes P i ∈ P1, the classification of samples in P3 and P4 are quite accepted.
In case of the samples with P i ∉ P1 wrongly assigned to P2, the minimum ED was 0, 1028 and this value is up of the minimum ED obtained for the correct samples in P2, but it is less than the maximum and average values for samples correctly assigned to P2. It could be not obvious to suggest if the classification is not correct for a sample having a ED into the ranges of the accepted ED for the classification in P2. However, the average value of the ED obtained for classes wrongly assigned to P2 are up to the average obtained in the correct assign; then, it is expected a low ratio of samples for which finally, the classification in P2 is accepted, under some metric. A similar analysis is addressed in case of samples assigned to P4. Additionally, note that most of the samples with P i ∉ P1 were assigned to the class P4; by comparing the ED min , ED max and ED ave value for this case, it is verified that all these values are lower than the ones in case of P1, P2 and P3.
Table 5 shows the results of classification for the set P2 with samples having a label P i ∈ P2 and P i ∉ P2. The precision to classify the faults with labels P1, P5, P6 and P7 reaches the 100%. In the following rows of the table, the minimum, maximum and average ED of the test samples correctly assigned to the classes, regarding the samples into the cluster, are stated. This values are compared to the obtained ones from samples with P i ∉ P2. In all cases, the metrics are quite up regarding the same metrics for the samples correctly assigned to the class P2. This result can serve to decide if the new sample belongs truly to a class in P2, according to how far the sample is from the most near neighbour in the known classes. As an example of the decision making, most of the samples with the label P i ∉ P2 were assigned to the class P1, i.e. a false negative can be obtained, however the metrics ED max and ED ave are quite different from the metrics in the correct assignment, then the final result can be that this samples is not in the healthy condition P1.
Results of KNN based classification, set P2
Results of KNN based classification, set P2
Table 6 shows the results of classification for the set P3 with samples having a label P i ∈ P3 and P i ∉ P3. The precision to classify correctly the faults with labels P1, P8, P9 and P10 reaches the 100%. The minimum, maximum and average ED of the test samples correctly assigned to the classes are calculated, and also these metrics are calculated for the samples that are wrongly assigned to those classes. In this case, the samples with labels P i ∉ P3 were distributed among the classes in P3, then, with these features, a sample can be assigned equally to any class. However, based on the metrics of the ED, an adequate conclusion regarding the correct diagnosis can be given, taken into account that ED max and ED ave are significantly large by comparing with the values in the correct diagnosis.
Results of KNN based classification, set P3
Results of KNN based classification, set P3
A RF based classifier was developed for each set of faults P1, P2 and P3, with data obtained from all the four accelerometers. The best three features ranked according to the entropy metric are shown in the last column of Table 7. Features extracted from the WPD using the wavelet family Daubechies 16 were always selected, and they differs from those ones selected by our approach, as shown in Figs. 5, 6 and 7. The precision for classification obtained by using the selected features is summarized in Table 7, by using KNN classification. The experimental conditions are the same as proposed in Section 5.3. Then, three different classifiers are considered to classify faults in the sets P1, P1 and P3. Regarding the precision reported in Tables 4, 5, and 6, the ability for classification of the proposed three best features by using ANOVA and cluster validity assessment is better than the ability of the three best features selected with RF, in case of P1 and P2; the same performance is obtained in case of P3. This result shows the improvement of the feature selection as contribution of the approach developed in this work, regarding the classical approach such as RF.
Precision in the classification by using features selected with RF
Precision in the classification by using features selected with RF
This paper proposes a two-stage methodological framework that combines ANOVA and cluster analysis to select the best set of features yielding an adequate feature structure for classification tasks in machine learning applications. The framework was applied on the problem of fault severity classification in rolling bearings, and the results were compared to classical feature selection techniques such as RF, LDA, and PCA. The main results of the feature analysis are: (i) The clusters obtained by our framework are better than those ones obtained by the mentioned classical techniques, in terms of the inter-cluster distance and intra-cluster density. This result is useful for the further development of fault classifiers where the cluster structure can determine its performance, (ii) The results also show that the same selection could be obtained from the proposed methodological framework by using accelerometers located in different places. This is an important result to implement fault classifiers in industrial cases where the placement of accelerometers in different locations is not available, (iii) KNN-based classifier was used to test the ability of the cluster structure to produce adequate diagnosis. Several metrics based on the Euclidean Distance of a new sample to the existing clusters were defined as reference values to asses whether a new sample is correctly assigned to the correct class. The results show that a decision-making system could be obtained by combining the metric values from the three classifiers, as the cluster structure for each set of fault is well defined. Future works aim at enhancing the definition of the index CDbwF z to weight properly the index CDbw associated to a pair of classes, in order to guide the selection of features that improve such specific cluster structure. On the other hand, the metrics defined from the Euclidean Distance could be used in a decision-making system at a third stage, then, several approaches also based on machine learning can be studied.
Acknowledgments
This work was funded by the research division DIUC of the Universidad de Cuenca, through the project “Análisis y definición de estrategias para el desarrollo de sistemas de mantenimiento industrial”, and by the Universidad Politécnica Salesiana under grant No. 002-002-2016-03-03.