
Abstract
Air is regarded as one of a fundamental element for the survival of human and other living creatures. Daily PM10 concentration forecasting is a useful measure that is applied to the prevention and control of work in advance. This paper proposes a multiscale fusion support vector regression (MFSVR) method for forecasting daily PM10 concentration. The method uses stationary wavelet transform (SWT) to decompose original time series of daily PM10 concentration into different scales, of which the information represents wavelet coefficients of PM10 concentration. At each scale, wavelet coefficients are used for training a support vector regression (SVR) model. The estimated coefficients of the SVR outputs for all of the scales applied to the reconstruction of the prediction result by the inverse SWT. To enhance forecasting of the MFSVR, a feature fusion approach that bases on partial least squares is adopted to extract the original features and reduce dimensions for input variables of the SVR model. The experimental confirmation of the proposed method is tested by applying the data of four monitoring stations between 1/1/2015 and 26/12/2015 in Lanzhou, China. The results indicate that the MFSVR approach can precisely forecast daily PM10 concentration on the basis of mean absolute error, mean absolute percentage error, root mean square error and correlation coefficient criteria. This method shows a potential prospect that can be implemented in air quality prediction systems in other areas.
Introduction
Poor air quality has triggered a widespread public concern, especially in densely populated urban areas, since air pollution is closely associated with the health of residents. The dominant pollutant is the particulate matter with aerodynamic diameter less than 10μm (PM10) in dust-haze pollution. The primary sources of PM10 are industrial emission, traffic, infrastructure construction, and other similar sources [1, 2]. These particles are particularly detrimental as they reduce not only atmospheric visibility but also cause grave human health problems through inhalation [3, 4]. In reality, several regulations have been put in place to set limits on the emissions of PM10 with the aim of improving and maintaining ambient air quality standards. It is great of importance for a reliable and precise approach for forecasting PM10 concentration to obey these limits because it can provide advanced PM10 pollution information at least one day in advance so that people can take timely and effective emission reduction actions.
An enormous amount of the air quality numerical methods, which aim to simulate the dynamics of environmental processes on air, have been applied to forecast daily PM10 concentration [5–7]. However, these models are unsuitable in most cities because they require adequate data from diverse pollution sources, the real emission components, the detailed account of physical processes in the planetary boundary layer, as well as the main chemical reactions from exhaust gases. Owing to these external challenges, statistical methods have been universally employed as an alternative to forecasting daily PM10 concentration. For instance, many linear or nonlinear regression approaches for PM10 prediction have also been published [8–10]. Nonetheless, the forecasting precision of these traditional models remains low when data are less and fluctuation.
After taking the nonlinear features of the real PM10 concentration into consideration, certain approaches with nonlinear mapping function have been established. One of such, artificial neural network (ANN) has been developed and successfully used for predicting PM10 concentration [11, 12]. The studies [13, 14] showed that the ANN models display better performance than the traditional statistical methods. As of late, various network structures have been designed for the ANN models [15]. In addition to, machine learning approaches have been quite excellent, and hence extensively implemented in PM10 concentration forecasting. Muñoz et al. [16] conducted a contrastive work between support vector machine (SVM) and ANN to forecast PM10 concentration. The SVM model exhibits better fitting capability. Wang et al. [17] predicted the daily PM10 using the SVM model. Hove et al. [18] used the successive over relaxation SVM (SOR-SVM) to forecast hourly PM10 concentration in urban areas. Arampongsanuwat and Meesad [19] adopted SVM optimized by particle swarm optimization algorithm for predicting PM10 time series. García et al. [20] forecasted the peaks of PM10 concentration by employing a k-nearest-neighbour, back propagation multilayer neural network, Bayesian classifier, and the support vector regression (SVR) machine, respectively. The comparison results thus showed that the SVR model has the best prediction performance in these approaches.
Lanzhou (102°35′58′′-104°34′29′′E, 35°34′20′′-37°07′07′′N), located in the semi-arid area of northwest China, is the capital of Gansu Province. Lanzhou urban district is a typical valley basin topography, resulting in a weak atmospheric dispersion capability [21, 22]. Various types of heavy industries (e.g., petroleum, chemistry, machinery, and metallurgy) were scattered throughout in this region [23]. These factors made it a prime zone for massive air pollution, and a top PM10 polluted city in China [24]. In fact, the real PM10 time series is a nonlinear dynamic system [25] and makes forecasting the PM10 concentration a difficult task. A considerable amount of historical data, including PM10 concentration and meteorological parameters, played important roles and helped make up for this defect. However, superior prediction abilities of the models rely on data representation, because different representations can entangle and conceal the different explanatory factors of variation behind the data [26]. Also, the multicollinearity between the independent variables can make it difficult to determine exactly the most important contributor to a physical process [27]. Consequently, feature extraction, fusion, learning, and analysis of historical data are crucial to ensure prediction precision.
This paper aims to examine the feasibility of using multiscale fusion support vector regress (MFSVR) to forecast daily PM10 concentration in Lanzhou. The nonlinear mapping capability of the least squares SVR (LSSVR), the multi-resolution characteristics of wavelet transform (WT), and the multicollinearity feature fusion of partial least squares (PLS) combined to obtain higher precision. First, the daily PM10 concentration was decomposed into different scales with stationary wavelet transform (SWT). Second, a PM10 prediction model of wavelet coefficients was constructed with LSSVR at each scale. As the final forecast, the consequences wavelet coefficients at each sequence were reconstructed based on the inverse stationary wavelet transform (ISWT). Lastly, to support the aforesaid forecasting procedure, the original features of the daily PM10 time series and the meteorological factors were analyzed to ascertain the input variables of LSSVR using PLS. Thus, the precision of the enhanced method were more suitable for practical applications.
Materials and methods
PM10 concentration and meteorological data
Four air quality automatic monitoring stations (marked by A, B, C, D in Fig. 1) have been built in Lanzhou by the Ministry of Environmental Protection of the People’s Republic of China. The stations are part of a national network that implements regular measurements of criteria air pollutants and radiates the entire urban area of Lanzhou. The daily mean concentration data of PM10 (360 samples each, totaling 4×360 samples) from four stations during 1/1/2015 to 26/12/2015 were collected from the Information Sharing Platform of Environmental Monitoring of China. Also, the meteorological data, comprising mean temperature (°C), mean atmospheric pressure (kPa), vapor pressure (hPa), relative humidity (%), precipitation (mm), wind speed (m/s), and sunshine duration (h), were obtained from the China Meteorological Data Sharing Service System.

Locations of air quality automatic monitoring stations in Lanzhou urban area.
LSSVR, a classic regression algorithm in machine learning field, is an improved version of support vector regression [28]. With the switching of inequality constraints to equality constraints in SVR, the least squares linear system takes the place of the original quadratic programming problem.
Suppose S is a training set for the daily PM10 concentration forecasting, as described below
The solutions of
Here, just two LSSVR model parameters (γ and σ2) are required to be determined. At the moment, a ten-fold cross-validation (10-CV) [31] has been used to test the precision of the model and to gain a stable model structure. Consequently, this paper selects the 10-CV to obtain the optimal γ and σ2 of the LSSVR model for the PM10 concentration forecasts.
As a result of the complex changes of the nonstationary and nonlinear series, it is hard to forecast with a single scale model [32]. Multiscale analysis is an excellent tool used to extract a local information of different resolutions, thereby, providing the possibility of revealing more fully the properties of the time series [33]. In this subsection, SWT is used for decomposing the daily PM10 concentration into different scales and employ the SVR model to forecast the PM10 at each sequence. The multiscale SVR outputs are applied to reconstruction the final forecasting result via ISWT.
In contrast to the classical wavelet transform, e.g., discrete wavelet transform (DWT), SWT has translation invariance [34]. Using the SWT approach, the daily PM10 concentration series
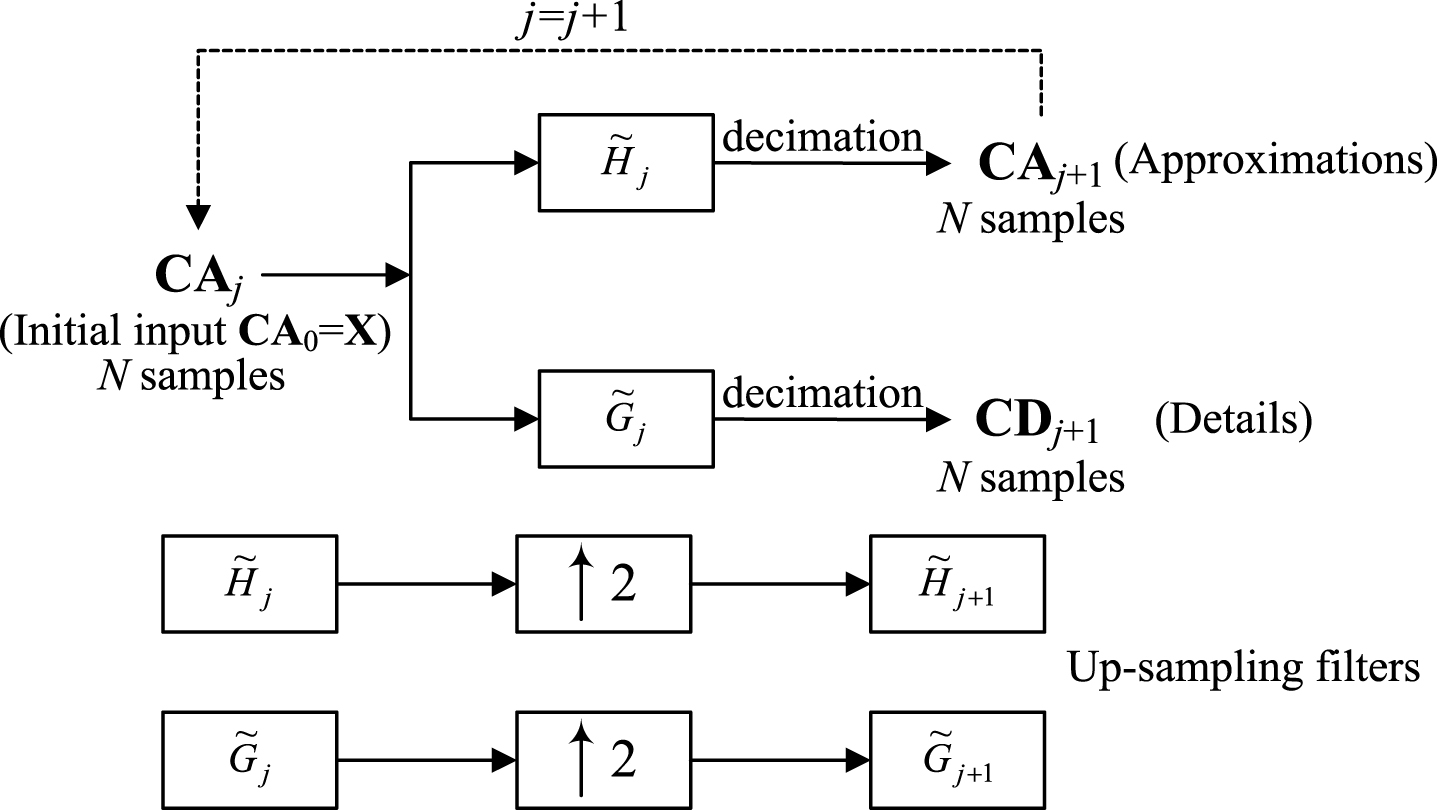
Sketch diagram of SWT decomposition and reconstruction.
As illustrated above, the original signal
As
The multiscale SVR model for daily PM10 concentration forecasting has been established. Nevertheless, what should be focused on is to simplify the computation in a practical application by fusion the original features and selecting the optimal factor. Accordingly, the feature variables of the model should be extracted in the first place. In the subsequent subsection, the PLS approach as a term refers to the connection between the dependent variables and predictor variables, used to define the input structure of the multiscale SVR model.
In the 1980s, Word et al. proposed PLS [36]. PLS constructs a linear model to explain the connection between dependent variables Y and predictor variables X. This linear technique attempts to seek out the multidimensional direction in the X space which explains the maximum multidimensional covariance direction in the Y space. As a supervised feature fusion approach, PLS can rapidly and efficiently discover a low-dimensional subspace. It also has a better dimensionality reduction performance than the traditional unsupervised methods (e.g., principal component analysis).
As stated by the principle of feature fusion, the matrix X (l × n) and Y (l × 1) can be regarded as an n-dimensional predictor variable and single dependent one, respectively. Thus, the PLS model tries to search for a linear decomposition of X and Y such that
The extracted X-scores is a linear combination of X, like the first extracted t of X is of the form t = Xw and the initial extracted u of Y is of the form u = Yc. The extracted t and u components possess the strongest explanatory power on the variable and can carry a lot of information as feasible. Remember that w and c are the corresponding eigenvectors to the largest eigenvalue of XTYYTX and YTXXTY, respectively. In case the first component has been extracted, the original values of X and Y would be deflated as
Similarly, the second component can be extracted by a new cycle. This method persists till every possible latent components t and u have been extracted. Lastly, the number of primary components needs to be determined accurately in the PLS approach. In this paper, the 10-CV was adopted to get the optimal principal components.
Based on the aforementioned explanations, Fig. 3 illustrates the flowchart for the MFSVR method used for forecasting daily PM10 concentration, which is also summarized below.
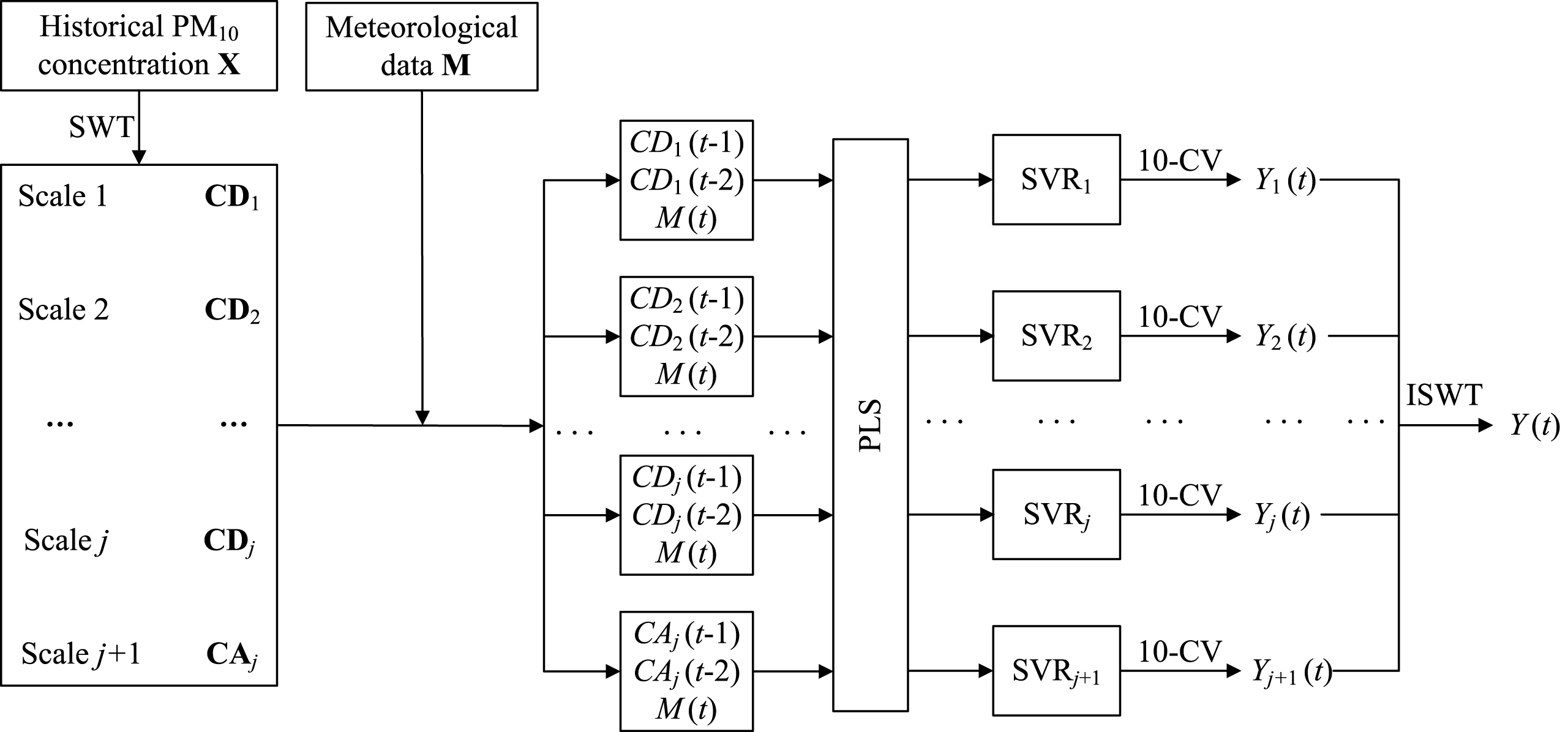
Structure of MFSVR for forecasting PM10 concentration.
Multiple performance measurements can be used to assess the ability of the model in the forecasting process [37, 38]. In this study, the prediction performance and precision for PM10 forecasting model are evaluated using the following criteria.
The mean absolute error (MAE)
The mean absolute percentage error (MAPE)
The root mean square error (RMSE)
The correlation coefficient (R2)
The comparisons were made on different data sets from the four monitoring stations to examine the effectiveness of the MFSVR system and to know whether the proposed MFSVR method is superior in the elementary SVR approaches. Amongst the 360-day patterns, the first 300 daily data (1/1/2015-27/10/2015) were applied as the training set, and the rest data (28/10/2015-26/12/2015) were utilized for the test. These models were designed and ran with software Matlab 7.1.
Data description
The Fig. 4 presents the daily average PM10 time series for one chosen monitoring station in Lanzhou city. There is quite an important variety of PM10 concentration on a daily basis. In the mean value of 122.16μg/m3, the standard deviation of the recorded values was equivalent to 57.85μg/m3. The high values of the standard deviation affirmed the complexity of the forecasting problem. Moreover, in terms of China’s national ambient air quality secondary standards (PM10 is 150μg/m3), the average daily limit of the PM10 concentration is frequently exceeded, the number of days (80) exceeding the value, and the results maximum, 450μg/m3, which is particularly shocking. The results clearly illustrate that the PM10 concentration maintains a high level in Lanzhou urban area all through the year. In addition, the correlation analysis approach, a term refers to the significance of a relationship between two or more variables, is used to verify the relationship between PM10 concentration and weather conditions. Correlation analysis outcomes (Table 1) demonstrate that the PM10 of four stations and all of the meteorological factors have a high mutual correlation (absolute value >0.1). According to the analyses above, the focus of atmospheric control work is the prevention of PM10 pollution.
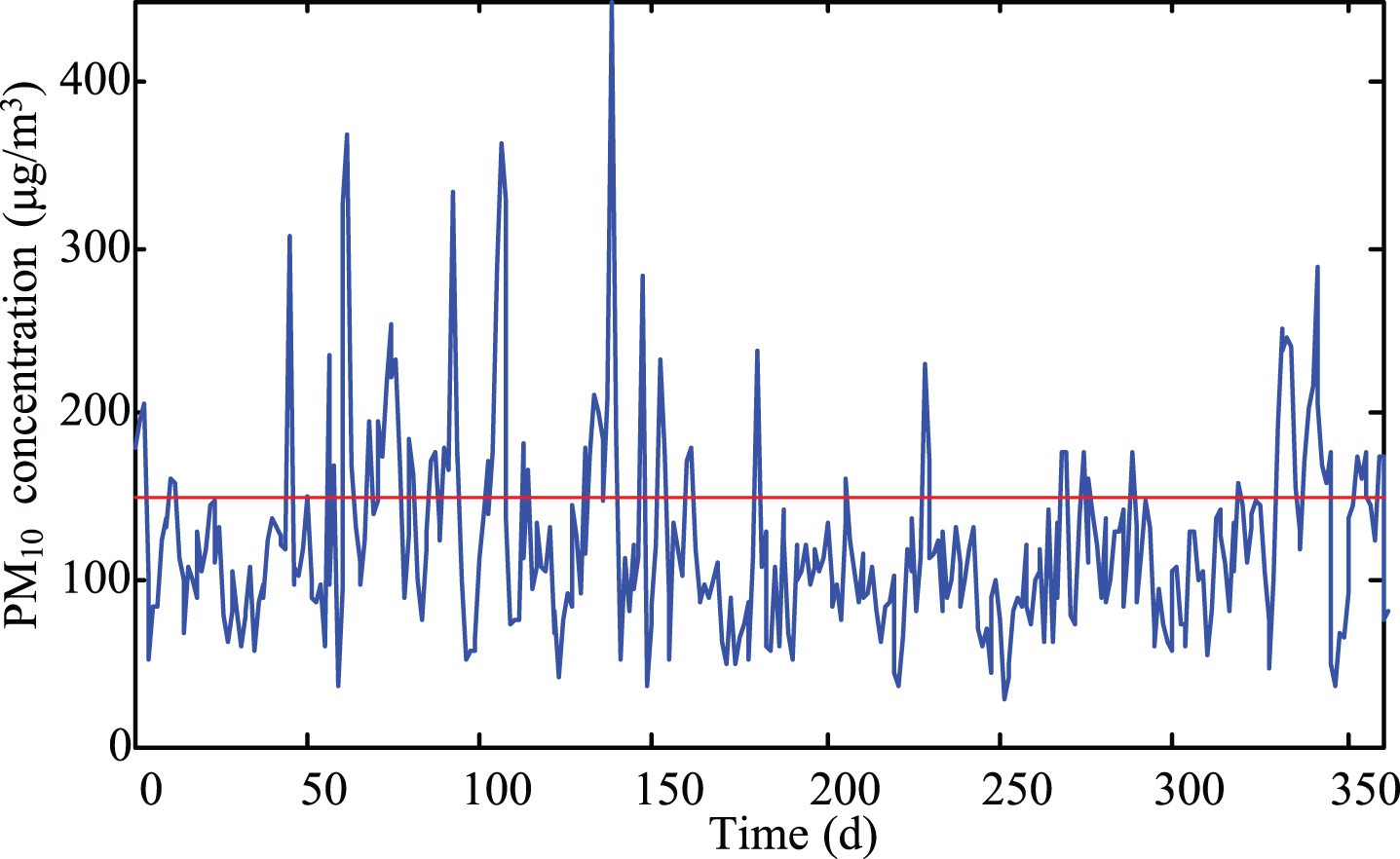
The daily averaged values of PM10 concentration for the period 1/1/2015-26/12/2015 at station B in Lanzhou, China.
Correlation analysis of daily meteorological factors and PM10 concentration for Lanzhou
Note: T represents mean temperature, AP represents mean atmospheric pressure, VP represents mean vapor pressure, RH represents relative humidity, P represents precipitation, WS represents mean wind speed, I represents illumination and PM10 represents PM10 concentration of four monitoring stations respectively. The correlation coefficients of meteorological factors and PM10 are separated by the slash (/).
For SVR inputs, the original PM10 time series and the weather conditions are analyzed using multiscale feature fusion with the hybrid model.
Choosing a logical wavelet function in the wavelet analysis is the first thing to consider. Normally, it is essential to select the mother wavelet function with compact support of time-frequency domain and orthogonality conditions [39]. Furthermore, the optimal decomposition scale of the PM10 time series in SWT performs a crucial role in reducing the distortion and preserving the information in the data sets [40]. The number of decomposition scales controls PM10 approximation in the data. In this case, the Daubechies wavelets db1 [41] is chosen as the mother wavelet in the decomposition.
Figure 5 shows the results of the 3-level wavelet decompositions of PM10 at each station. All signals, from the first (CD1) to the third (CD3) levels and the coarse approximation CA3 are illustrated in the original resolution. While observing the signals on different levels, one can perceive the marked difference in variability in which CA3 is the low-frequency coefficient that maintains the shape of the original time series, and also reflects the long-term trend of PM10 concentration. CD1, CD2, and CD3, instead, are the high-frequency coefficient that hides the details of the original time series, and reflects the random fluctuation characteristics of the diverse focal length of PM10 concentration. With this, this work can substitute the prediction task of the original series of high variability in forecasting its lower variability wavelet coefficients on different levels and utilizing Equation (10) to finalize PM10 forecast at any time point. Owing to most of the wavelet coefficients are of lower variability, the increase in the whole prediction precision will be expected.
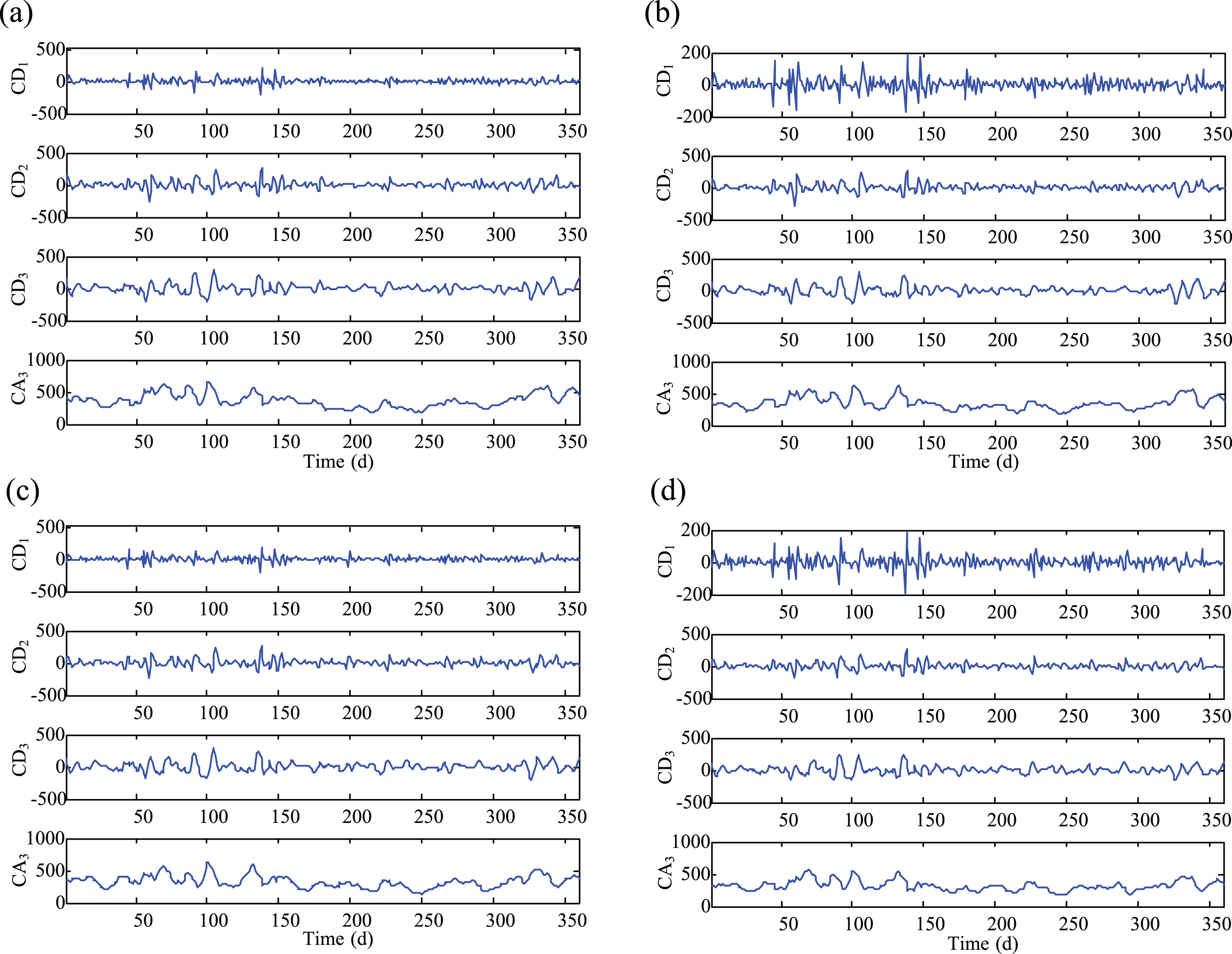
The wavelet decomposition of the recorded time series
The PLS method is used to overcome the multicollinearity problem in this study. There was a fuse of main information including nine predictor variables that are the wavelet coefficients in the previous two days and the total meteorological factors of the day. As stated in Section 2.4, the optimum amount of principal components are found by 10-CV. Looking at the studies above, Table 2 gives the PLS process results at diffident scales. It can be seen that PLS is performed to fuse the first few principal components and their cumulative variance explained in X are more than 98% of the factors. Subsequently, a few principal components are utilized to replace the forecaster variables X as the input data of the SVR model at each sale. However, it is to be noted that the cumulative variance explained in Y convey significant variances on different levels. It can prove that the weather conditions and historical PM10 data have a complex effects on the current PM10 pollution in multiple scales. Thus, it is a successful procedure to expose intrinsic regularity of the PM10 concentration.
PLS analysis of the factors for the MFSVR model
Note: PC represents the number principal components, CVE X represents cumulative variance explained in X, and CVE Y represents cumulative variance explained in Y.
As mentioned above, the optimum model inputs on each level of the MFSVR model consisting of four monitoring stations are concluded in Table 2. Moreover, the optimal structure parameters γ and σ2 of MFSVR are gained by 10-CV. Based on Table 2, the wavelet coefficients of each scale can be forecasted, and then the final result is reconstructed using ISWT. To evaluate the dominance of the proposed method, SVR and fusion support vector regression (FSVR) are also applied to forecast the daily PM10 concentration. This FSVR is a term that is a hybrid model using combination of SVR as predictor and PLS as a data fusion tool.
Figure 6 presents the prediction results for these three models of four monitoring stations, respectively. To measure the dispersal between the recorded value and the forecast results, the box plots of absolute errors were also shown in Fig. 6, explaining the lower error between the two data sets.
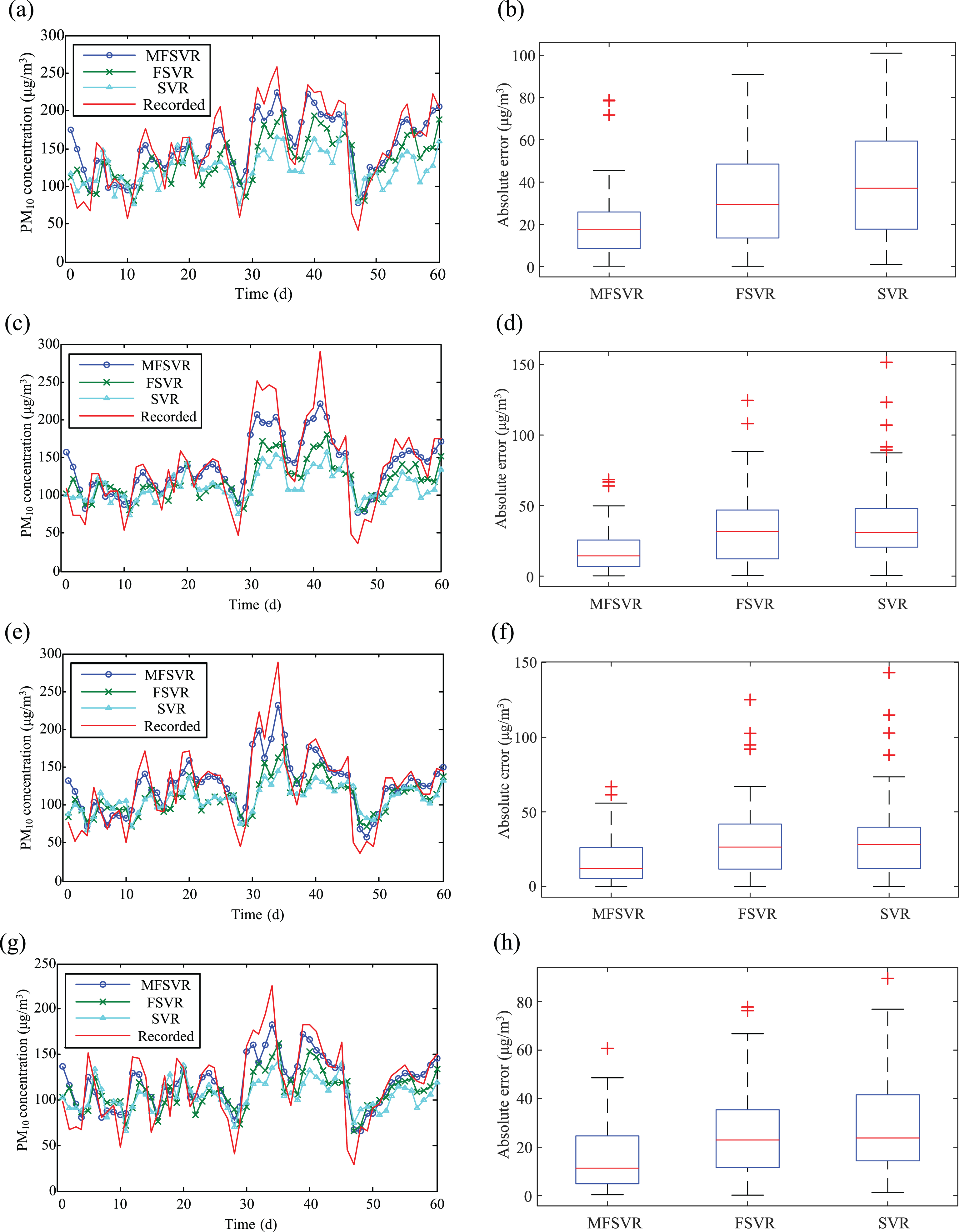
Forecasting results (left) and box plots of absolute errors (right) using different models at (a and b) Station A, (c and d) Station B, (e and f) Station C, and (g and h) Station D.
As seen in Fig. 6, the forecasting results of the proposed model are nearer to the recorded values compared to the values generated by SVR and FSVR in four monitoring stations. Apart from a few extreme points, it is able to follow the changes in the testing data accurately, and the forecasted values are consistent with the recorded ones. The box plots show that the distributions of the absolute error for the MFSVR model are the most concentrated, followed by FSVR and SVR. Furthermore, the position of the entity for the proposed model is lower compared to the two other models. Most errors of the proposed approach is thus within a lower range. Hence, when using SVR only, it is clear that the prediction performance of the testing data is inadequate indicating that it is hard to get a good result in a single model.
Based on illustrations discussed above, the proposed MFSVR approach shows obvious superiority in the PM10 concentration prediction. Moreover, the Friedman test [42], a classical nonparametric test method, is applied to further analyse if there is a statistically significant difference between MFSVR, FSVR and SVR for each one of the four monitoring stations. In this work, under the null hypothesis (H0): the independent, prediction model, is assumed to have no effect on the dependent, the value of absolute error; the three models have the same prediction error.
The formula of the Friedman test is
Take station B, for example, each model’s absolute errors are ranked and the ranked errors in each column are summed (R I ). Values of absolute error from Fig. 6(d) are substituted into Equation (17) to calculate the Q equals 17.5, and the critical value of normal distribution with two degrees of freedom for P is equivalent to 0.000 (P≤0.05). Thus, one reject H0: and conclude that the absolute errors were significantly different in the three models. In addition to, Friedman test are performed with the three other monitoring stations, and the P values are equal to zero. The results show that there is significant difference between the three models at each monitoring station, as reflected in the size of the absolute error. The test results in Table 3 (e.g., R I of station B for MFSVR, FSVR, and SVR are 94.8, 124.8, and 139.8, respectively) also prove that the most suitable performance is the MFSVR model for forecasting PM10 concentration, the second is FSVR, SVR is the worst.
Friedman test results of absolute error valuables using different models at each monitoring station
The wavelet analysis, which has excellent time-frequency characteristics and multi-resolution capability, is proficient in extracting the internal regularity of the PM10 series by transforming it into different scales. Likewise, the dimension from the unqualified variables and noises feature fusion can be reduced by feature fusion of the input data. Thus, the proposed MFSVR method can elevate the appropriate degree of complex features in multiscale and finally achieve an improved forecasting performance.
Besides, a quantitative assessment is implemented. Table 4 presents the prediction performances applying the MFSVR, the FSVR and the SVR model, respectively. It shows that the forecasting effect of the developed method is far enhanced than that of the corresponding FSVR and SVR in all four criteria.
Comparison of the forecasting performances of different models
According to Table 4, take station B for example, when compared with SVR, MAE, MAPE and RMSE of FSVR are lower than 5.01μg/m3, 1.61%, and 6.16μg/m3, respectively, while R2 is higher than 0.03. This is due to the PLS approach can use features information to eliminate the multicollinearity in the SVR model. Moreover, the hybrid FSVR model improves training speed and grid search. It can be seen that the whole computation time that is marked is saved. Also, it was seen that MAE, MAPE, and RMSE of MFSVR decreased by 42.23%, 29.36%, 40.29% respectively while R2 of MFSVR rose by 21.05% when contrasted with those of FSVR. The mono-SVR method has a good forecasting precision in the stationary phase of the time series. Nevertheless, it becomes swiftly lower during fluctuation period. This result shows that the partial sample contains a small amount of information. In other words, the multiscale characterization can explain the sophisticated internal features. Furthermore, one noticed that another three monitoring stations attain the same outcomes as the station B. This similarity also shows that the MFSVR approach has a great generalization ability in the field about air quality prediction.
Regarding the comparisons mentioned above, all the results sufficiently show that the developed method, which is combining the SVR and the multiscale fusion, demonstrates the best forecasting effect compared to the other methods.
The forecasting approach to the daily PM10 concentration is presented in the paper by applying multiscale fusion support vector regression. The decomposition of mixed features time series into several different subsequences with multiple simple features and by employing the use of prediction strategy for each of them at several scales is one extraordinary innovation of this approach. The application of this approach has divided the forecasting issue into a few more uncomplicated tasks to enhance the prediction precision. Another innovation of this method is using feature fusion as a new input at each scale based on PLS. This input extracted from the wavelet coefficients of PM10 concentration, and meteorological factors can replace the first collection of data. The hybrid model performs better than the single model and to some extent; it resolves oversized input dimension problems. The planned model has been tested using the data of four monitoring stations in Lanzhou, China. Also, the present method is compared with SVR and FSVR. The results indicated by executing the multiscale fusion, the MFSVR approach outperforms the two other models looking at the four criteria, hence creating the way for the optimal forecasting of air pollution system.
Footnotes
Acknowledgments
This work was supported by the Ministry of Environmental Protection of the People’s Republic of China (2111101). In addition, the authors are indebted to the editors/reviewers for their insightful comments and suggestions to help improve the quality of this paper.