
Abstract
Semi-supervised learning is an emerging subfield of machine learning, with a view to building efficient classifiers exploiting a limited pool of labeled data together with a large pool of unlabeled ones. Most of the studies regarding semi-supervised learning deal with classification problems, whose goal is to learn a function that maps an unlabeled instance into a finite number of classes. In this paper, a new semi-supervised classification algorithm, which is based on a voting methodology, is proposed. The term attributed to this ensemble method is called CST-Voting. Ensemble methods have been effectively applied in various scientific fields and often perform better than the individual classifiers from which they are originated. The efficiency of the proposed algorithm is compared to three familiar semi-supervised learning methods on a plethora of benchmark datasets using three representative supervised classifiers as base learners. Experimental results demonstrate the predominance of the proposed method, outperforming classical semi-supervised classification algorithms as illustrated from the accuracy measurements and confirmed by the Friedman Aligned Ranks nonparametric test.
Introduction
Learning from examples is a method that has been extensively analyzed in machine learning, a fast growing subfield of computer science. Over recent years, different machine learning approaches have been applied in several scientific fields, such as supervised, unsupervised and semi-supervised learning. Supervised learning deals with problems in which the output classes of the instances in the training set are known, while in unsupervised learning there is no knowledge regarding the output classes [34].
Semi-supervised learning (SSL) is a combination of supervised and unsupervised learning aiming to obtain better results from each one of these methods exploiting a small pool of l labeled examples L d = {(x1, y1) , (x2, y2) , …, (x1, y1)} with x i ∈ R n , i = 1, 2, …, l, together with a large pool of k unlabeled examples U d = {x1, x2, …, x k } with x i ∈ R n , i = 1, 2, …, k. Since it is difficult and expensive to obtain a fully labeled dataset in many real world problems, SSL has turned to a powerful and effective machine learning tool for learning from both labeled and unlabeled data [42].
Depending on the nature of the output class, SSL is divided into two main tasks: semi-supervised classification (SSC) for discrete output class and semi-supervised regression (SSR) for real-valued. Most of the studies about SSL deal with classification problems, with a view to predicting a label from a finite set of class labels. The most frequently studied classification problem is considered to be the binary classification, where the output variable y ∈ {0, 1}, while in multi-class classification y ∈ {0, 1, 2, …, n}. SSC can be either inductive or transductive [42]. Inductive SSC aims to learn a classifier for future unknown data, while transductive SSC classifies instances from the unlabeled dataset.
Several ensemble methods have also emerged recently, combining different classifiers for the improvement of the classification accuracy [21]. Ensemble learning or committee-based learning or learning with multiple classifier systems, concerns the formulation and training of a set of classifiers [40] for classifying new instances, usually through an iterative voting procedure, that is based on classifiers’ individual predictions. There is a growing apprehension that ensemble methods outperform each one of the single classifiers within the ensemble, especially when these component classifiers are as accurate and diverse as possible [9]. Accordingly, ensemble learning has become an increasingly widespread methodology for building powerful and accurate predictive models.
In view of the above, SSL methods and ensemble methods constitute two significant machine learning paradigms. The former attempts to achieve strong generalization by exploiting the hidden information on unlabeled data while the latter attempts to achieve strong generalization by using multiple classifiers [40]. Although both methodologies have been applied effectively in a variety of scientific fields during the past decade, they were almost developed separately. Zhou [40] showed that SSL and ensemble learning may be beneficial to each other, since unlabeled data are in abundance and can be exploited to the full by a combination of diverse classifiers.
Following up the results of this study, in the present paper an attempt is made to put forward an ensemble of SSC algorithms. Therefore, a new semi-supervised ensemble algorithm, called CST-Voting, is proposed. CST-Voting combines three representative SSL algorithms, and in particular Co-training [4], Self-training [37] and Tri-training [41], and is based on a voting methodology. The efficiency of the proposed algorithm is evaluated with a number of benchmark datasets in terms of classification accuracy using three familiar supervised classifiers as base learners, while several experiments are carried out showing its efficacy.
The rest of this paper is organized as follows: Section 2 refers to familiar SSL algorithms. The proposed ensemble method is described in detail in Section 3. The experiments’ procedure and their results are presented and analyzed in Section 4, while comparing the proposed method to its component SSL algorithms. Finally, Section 5 concludes considering some further research topics for future work.
Semi-supervised techniques
In recent years, a number of familiar SSC algorithms have been implemented with remarkable results in many application areas. Self-training, Co-training and Tri-training constitute representative SSL methods trying to effectively exploit the unlabeled data as far as possible, since the utilization of unlabeled data is essential for their efficiency [14].
Self-training or self-teaching is considered to be a simple and effective SSL method. The self-training idea first appeared in Yarowsky’s study concerning the implementation of an unsupervised algorithm for word sense disambiguation [37]. In accordance to Ng and Cardie [27], self-training is a “single-view weakly supervised algorithm” which is based on its own predictions on unlabeled data to teach itself. At first, a classifier is trained from a small amount of labeled data constituting the training set, which is then used for classifying a predefined number of unlabeled data [42]. The most confident predictions, i.e. the unlabeled examples that have a high probability of been assigned with the correct label, are added to the labeled training set and the classifier is retrained. The previous learning process is repeated until all unlabeled data are finally labeled. Self-training is considered to be an iterative bootstrapping method since it is based on its own predictions to teach itself. However, false predictions of the classifier on the initial steps frequently result to a large number of erroneous predictions [37]. Therefore, several techniques and filters have been applied to reduce the impact of misclassified instances during the initial stages of the learning process [42]. In [26], a soft-labeling approach is adopted to minimize the expected loss of a classifier, while in [10] a new SSC method is proposed to overcome false labeling during the learning process and improve the classification performance. According to this method, unlabeled data are only used to generate new synthetic data extending the amount of labeled data and the final classifier is learned in the extended feature space. Very recently, a new method called SSL Sparse Representation based Classification was introduced addressing the problem of a small number of noisy labeled examples [12].
Co-training [4] is a widely used method in SSL setting that was originally proposed by Blum and Mitchell and is principally based on the assumption that each example in the dataset can be partitioned into two distinct views. Moreover, each view is assumed to be sufficient to make correct classifications and the two views are considered to be conditionally independent given the class label. Two learning algorithms are trained separately for each view using the initial labeled dataset and the most confident predictions of each algorithm on unlabeled data are used to augment the training set of the other algorithm through an iterative learning process until some stopping criterion is met, i.e. for a predefined number of iterations. In essence, Co-training is a “two-view weakly supervised algorithm” [27] since it uses the Self-training approach on each view. The efficacy of the method is influenced mainly by the appropriate selection of the two algorithms, as well as the existence of two different views and the above-mentioned assumptions. Nigam and Gani [28] showed that Co-training outperforms other SSL algorithms when there is a natural existence of two distinct and independent views. However, the existence of two independent views on a dataset can hardly be met in practice. Several variants of Co-training algorithm have been developed to overcome this hurdle, such as Democratic Co-training [39] and Tri-training [41]. A very recent approach employs an improved variant of Co-training algorithm for software defect prediction using random under-sampling technique [24].
Tri-Training is an improved single-view extension of the Co-training algorithm exploiting unlabeled data without relying on the existence of two views of instances [41]. Tri-training is a bagging ensemble of three classifiers [15], since they are initially constructed by Bagging [5] and trained on data subsets generated through bootstrap sampling from the original labeled training set. If two of the classifiers agree on the labeling of an unlabeled example, then this example is used to teach the third classifier. In contrast to other variants of the Co-learning approach, Tri-training does not require different supervised algorithms, leading to greater applicability and implementation of the algorithm in many real world datasets.
Several notable ensemble methods have also applied in the SSL setting mainly based on the Co-training paradigm, such Co-Forest [22] and CoBC [15]. In Co-Forest, an initial ensemble of random trees is trained on bootstrap sub-samples generated from the original labeled dataset, while in CoBC, a committee of diverse classifiers is used instead of redundant and independent views. In [36], a prediction model based on semi-supervised twin support vector machine is introduced for medical prognosis of patients. In a very recent study [38], a progressive SSL ensemble approach is introduced that handles high dimensional datasets through random subspaces, as well as datasets with a limited amount of labeled instances enlarging the training set by a progressive generation process and a self-sample selection process. Following up the results of these studies, a new semi-supervised ensemble method is proposed and described in the next section.
Proposed method
In general, the generation of an ensemble of classifiers considers mainly two steps: Selection and Combination.
The selection of the appropriate component classifiers is considered to be an essential step towards obtaining highly accurate classifier systems [40]. The key point for the effectiveness of the method is the component classifiers to be as accurate and diverse as possible. A commonly used approach is to generate classifiers by applying different learning algorithms (with heterogeneous model representations) to a single dataset (see [25, 32]). On this basis, the learning algorithms which constitute the proposed ensemble are: Co-training, Self-training and Tri-training. What all these methods have in common is that they are self-labeled methods operating in different ways, trying to take full advantage of the hidden information in unlabeled data. The crucial difference between them is the mechanism used to label unlabeled data. Co-training is a multi-view method, while Self-training and Tri-training are single-view methods. Moreover, Co-training and Tri-training are indeed ensemble methods, since they make use of multiple classifiers.
The combination of the component learning algorithms takes place through several methodologies. The proposed ensemble incorporates a majority voting methodology, since it is a simple and easy to implement method for combining the individual predictions of component classifiers in an ensemble. According to this approach, the ensemble output is the one made by more than half of them.
The pseudo-code of the proposed ensemble method is shown in Algorithm 1. Initially, Self-training, Co-training and Tri-training algorithms are trained on the labeled dataset L and then applied on unlabeled dataset U. L is augmented incrementally and the process is repeated until some stopping criterion is met or U is empty. The final hypothesis of an unlabeled example of the test set, i.e. the ensemble output, is produced via majority voting.
CST-Voting
CST-Voting
The experiments were based on 40 benchmark datasets from UCI Machine Learning Repository [23] and KEEL repository [2]. A brief description of datasets structure (number of instances, number of attributes and output classes) is presented in Table 2. These datasets have been partitioned using the 10-fold cross-validation procedure so that each fold had the same distribution as the entire dataset. For each dataset, 90% was used as training set, while the remaining 10% was used as testing set to evaluate the performance of the learning algorithms. The training partition of each fold was divided into labeled and unlabeled subsets according to a selected ratio value. In order to study the influence of the amount of labeled data, three different ratios were used: 10%, 20%, and 30%.
Brief description of datasets
Brief description of datasets
The performance of the proposed ensemble algorithm was compared to its component SSC algorithms, and in particular Self-training, Co-training and Tri-training in terms of classification accuracy. Accuracy is one of the most frequently used measures for assessing the overall effectiveness of a classification algorithm [31] and is defined as the percentage of correctly classified instances. Furthermore, the implementation code was written in Java, using Weka Machine Learning Toolkit [16]. A plethora of experiments were carried out on each dataset deploying three well-known supervised classifiers as base learners in each SSL method thus creating a total of 120 datasets (3 labeled ratios for 40 datasets). A brief description of the three supervised classifiers is given below: J48 is a very effective classification algorithm for building decision trees. It is a Weka implementation of the C4.5 Decision Tree algorithm [30], a widely used classification algorithm categorizing instances to a predefined set of classes according to their attribute values from the root of a tree down to a leaf. The accuracy of a leaf corresponds to the percentage of correctly classified instances of the training set. JRip, a well-known inference and rule-based algorithm which was originally introduced by Cohen [8]. It is a java optimized version of the RIPPER (Repeated Incremental Pruning to Produce Error Reduction) algorithm, implemented in Weka. JRip is considered to be a very effective algorithm, especially on large samples with noisy data. Moreover, RIPPER produces error rates competitive with C4.5 and better running times. kNN is a representative instance-structured learning algorithm [1] based on the assumption that similar examples are close to each other. More specifically, a distance function is used to predict the output class of an instance through identifying the most frequently found class among the k nearest neighbors of it. The function should minimize the distance between two equally classified examples.
Studies have shown that the above classifiers constitute some of the most effective and widely used data mining algorithms [35] for classification problems. Moreover, Co-training, Self-training and Tri-training algorithms often achieve impressive results when C4.5 is used as base learner, while Tri-training also performs well with kNN as base learner [33]. The configuration parameters of all the SSL methods and base learners used in the experiments is presented in Table 1. Regarding the base learners, the default parameter settings included in the Weka software were applied.
Parameters configuration for all SSL methods and base learners
The experimental results using 10%, 20% and 30% labeled ratio are presented in Tables 3– 5 respectively.
Classification accuracy (labeled ratio 10%)
Classification accuracy (labeled ratio 20%)
Classification accuracy (labeled ratio 30%)
The number of wins of each one of the tested methods according to the supervised classifier used as base learner and the ratio of labeled data in the training set is presented in Table 6, while the best scores are highlighted in bold. It should be mentioned that draw cases between algorithms have not been encountered. The above aggregated results show that CST-Voting is by far the most effective method in all cases except the one using 3NN as base learner with a labeled ratio of 10%. In this case, Tri-training performs better in 13 datasets, followed by CST-Voting (12 wins), Co-training (5 wins) and Self-training (2 wins). In more detail:
Total wins of each algorithm
Depending upon the base classifier, CST-Voting (JRip) scores the best accuracy value in 19, 13 and 19 datasets (a total of 51 out of 99 datasets), using a labeled ratio of 10%, 20% and 30% respectively. CST-Voting (J48) performs better in 17, 16 and 19 datasets (a total of 52 out of 101 datasets), while CST-Voting (3NN) prevails in 12, 11 and 13 datasets (a total of 36 out of 98 datasets) respectively. So, CST-Voting performs better using JRip or J48 as base learners.
Regarding the ratio of labeled instances in the training set, CST-Voting performs better in 48 out of 98 datasets for 10% labeled ratio, in 40 out of 99 datasets for 20% labeled ratio and in 51 out of 101 datasets for 30% labeled ratio. It is clear that CST-Voting achieves better results for 10% and 30% labeled ratio.
Additionally, a more representative visualization of the classification performance of the compared SSC methods is presented in Figs. 1– 3. Each figure displays a radar chart illustrating the accuracy measure of each tested algorithm according to the supervised classifier used as base learner and the labeled ratio.
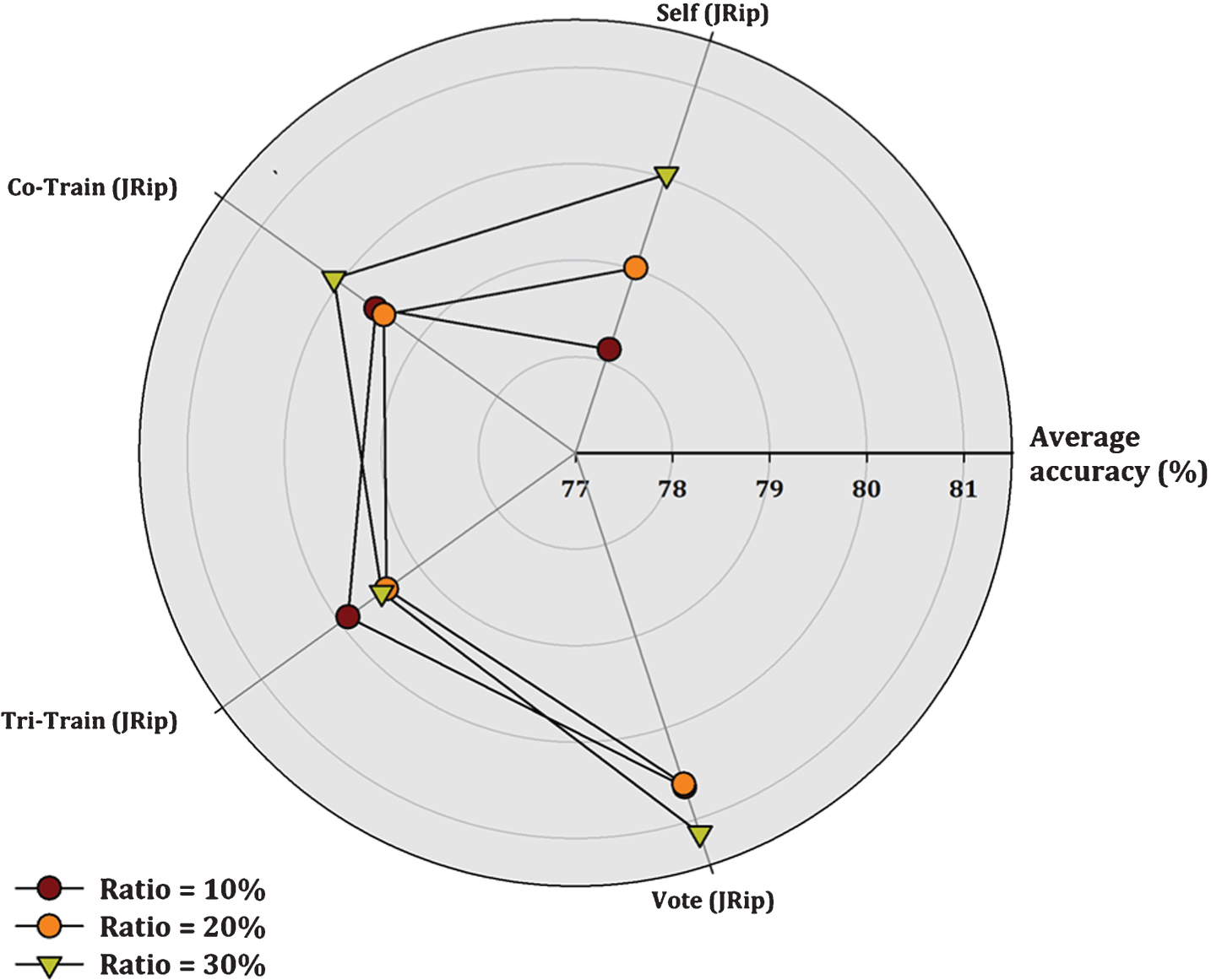
Comparison of SSL algorithms (JRip base classifier).
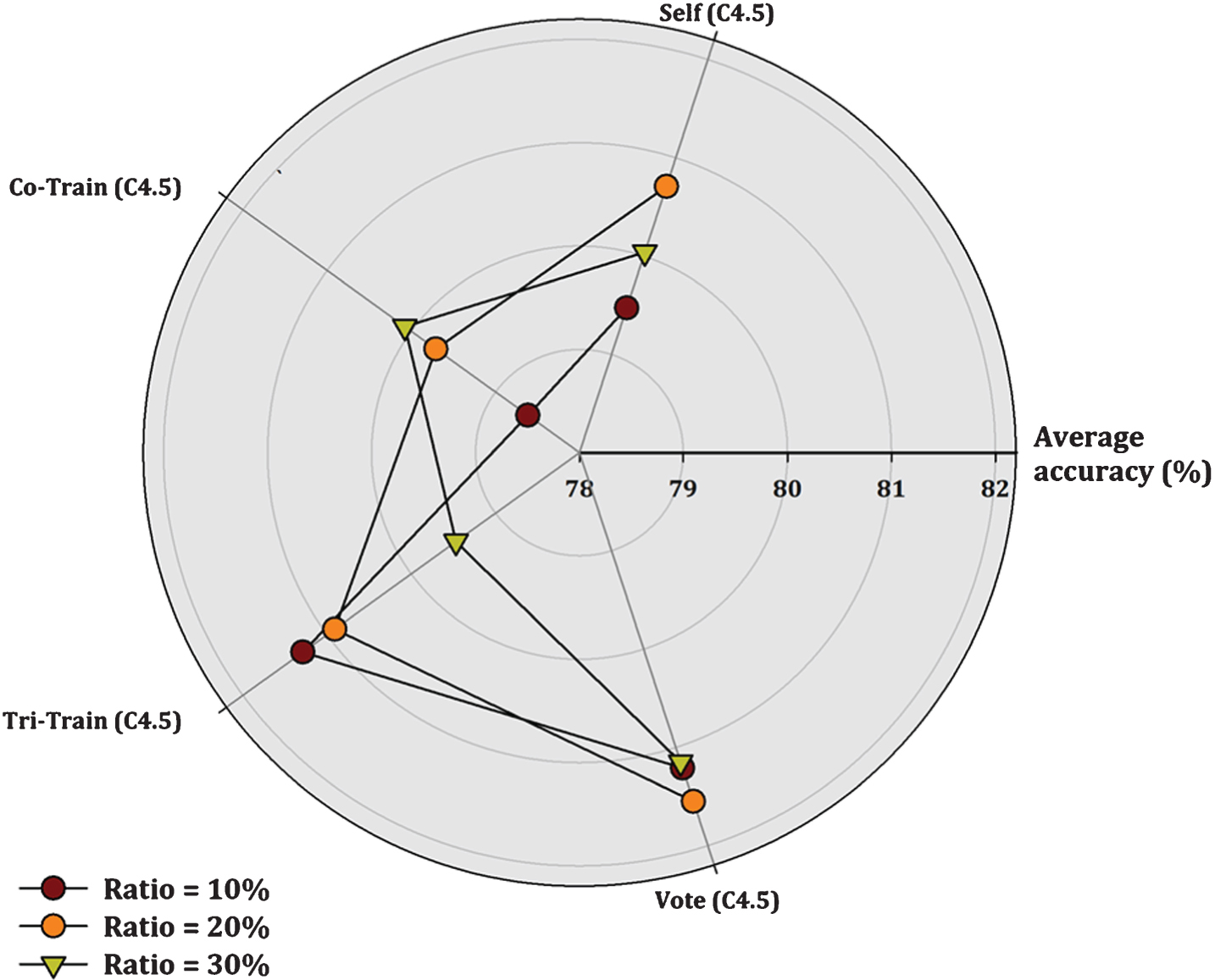
Comparison of SSL algorithms (J48 base classifier).
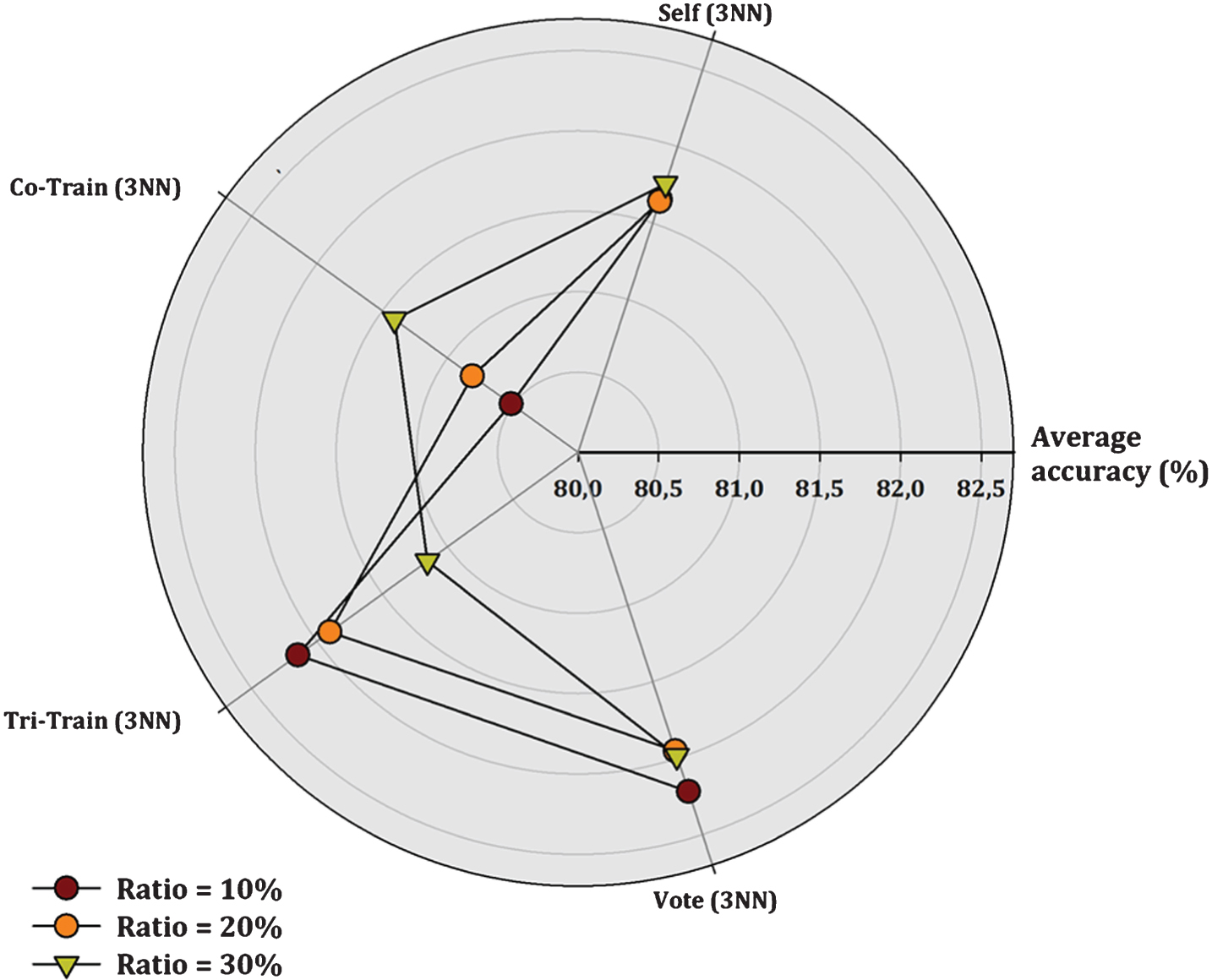
Comparison of SSL algorithms (3NN base classifier).
To evaluate the performance of the tested algorithms, we performed multiple comparisons of the accuracy results between the proposed method and the set of SSC algorithms used in our study. Therefore, the Friedman Aligned Ranks nonparametric test [19] was applied first and after the Finner post hoc test [11] with a significance level α= 0.05. Friedman Aligned Ranks test is considered to be one of the most well-known tools for multiple statistical comparison tests when comparing more than two methods [13]. According to the computed Friedman test results (Tables 7– 9) the algorithms are ordered from the best performer (lowest ranking value) to the lowest one (highest ranking value). It is observed that CST-Voting prevails in all 9 cases (3 different classifiers and 3 different labeled ratios) indicating its efficiency.
Friedman Aligned Ranks test-Finner post hoc test (a = 0.05)
Friedman Aligned Ranks test-Finner post hoc test (a = 0.05)
Friedman Aligned Ranks test-Finner post hoc test (a = 0.05)
Since the null hypothesis of equivalence of medians of algorithms is rejected, the Finner post hoc statistical procedure is applied to detect the specific differences among the algorithms. Finner test is easy to comprehend and usually offers better results than other tests, such as Holm test [20] or Hochberg test [18], especially when the number of algorithms to be compared is low [13]. The complete post hoc results are also presented in Tables 7– 9 using CST-Voting as control method. The proposed ensemble method takes precedence over the rest SSL algorithms, since it gives statistically better results in all cases except the one using 3NN as base learner with a labeled ratio of 10%, confirming that the proposed ensemble method obtains higher classification accuracy than its constituent parts.
In the present study, a new SSL ensemble algorithm, called CST-Voting, is proposed. Semi-super-vised learning is an emerging subfield of machine learning, with a view to building efficient classifiers exploiting a limited pool of labeled data together with a large pool of unlabeled ones. CST-Voting combines three familiar SSL algorithms: Co-training, Self-training and Tri-training. The efficiency of the proposed algorithm was evaluated on a number of benchmark datasets in terms of classification accuracy using JRip, C4.5 and 3NN supervised classifiers as base learners and different ratio of labeled data. A plethora of experiments were carried out indicating the effectiveness of the ensemble, as confirmed statistically by the Friedman Aligned Ranks nonparametric test and the Finner post hoc test.
CST-Voting outperforms its component algori-thms, which use the same base classifiers, confirming the effectiveness of ensemble methods. Co-training, Self-training and Tri-training exploit unlabeled examples through different mechanisms and thereby ensure the ensemble diversity. Therefore, combining the ensemble methodology and SSC algorithms seems to lead to more efficient, stable and robust predictive models. Since the experiments results are quite encouraging, a next step should be the usage of other supervised classifiers as base learners, such as support vector machines [6, 29] and neural networks [3, 17]. Moreover, an interesting aspect is the implementation of the method in specific scientific fields applying real world datasets, such as the educational field.
Another interesting aspect for future work is a parallel implementation of the CST-Voting method. Recently, a distributed SSL method with kernel ridge regression has been effectively applied to data subsets that are distributive stored on multiple servers [7]. Implementing each one of the components SSL algorithms in parallel machines is a very important aspect to be studied, as huge amount of data can be processed in significantly less time.
Footnotes
Appendix
A java software tool implementing the proposed ensemble method can be found http://www.math.upatras.gr/ livieris/Software/CST_Voting.zip.