
Abstract
The precision of price appraisal is directly linked to the sound development of a market-oriented economy and public benefit. Market comparison approach is a widely used price-appraisal algorithm. However, when the sample size is small, the computing precision of the market comparison approach is severely impaired. To realize precise, intelligent computing under the conditions of a small sample size and a low degree of proximity between samples and the object to be evaluated, this study adopted grey correlation and fuzzy mathematics to optimize the market comparison approach for price appraisal. The proposed algorithm used grey correlation analysis to quantify the weight of various attributes influencing price appraisal. The price correlation between samples and the object to be evaluated was confirmed. The fuzzy mathematical method was then used to obtain the relative weight of samples. The proposed intelligent price-appraisal algorithm was constructed to improve the market comparison approach. Finally, several residences in Hangzhou, Zhejiang province, China were chosen for an empirical analysis and for the verification of the feasibility of the improved price-appraisal algorithm. Results suggest that (1) The mean error of the algorithm is only 0.99%, indicating high computing precision; (2) When the number of objects to be evaluated is large, a computer system can be used to aid the intelligent computing and to efficiently perform intelligent computing. In conclusion, the proposed algorithm can maintain high computing precision under the conditions of a small sample size and a low degree of proximity, and the algorithm can be used as a theoretical basis to realize intelligent mass appraisal. Overall, the proposed algorithm is worthy of further development because it is highly operational.
Introduction
Price appraisal lays the foundation for commodity transaction, transfer, rent, and so on. The precision of price appraisal is directly linked to public benefit. Nowadays, commodity price is influenced by numerous factors, and these factors are associated with a large amount of data. Several commodities are in the imperfect market, such as the real estate market, which adds complexity to price appraisal. Widespread information asymmetry further complicates price appraisal [1]. Currently, despite the rapid development of computing and information technology, intelligent price appraisal is still performed using traditional algorithms that serve as the theoretical basis of improvement.
Market comparison approach is the most extensively used traditional price-appraisal algorithm. This approach compares the object to be evaluated with similar samples from recent transactions and then modifies the known price of similar samples to compute for the object’s price [2]. The algorithm applies to commodities in the highly developed market, which comprise residences, shops, and office buildings. However, as a traditional price-appraisal algorithm, the market comparison approach has several limitations in solving real-world problems. For example, this approach requires an adequate number of transaction samples and data; its computing process relies heavily on subjective knowledge and experience; the sample data cannot be repeatedly used to calculate different objects [3]. How the market comparison approach can be optimized, and how the theoretical basis for intelligent price appraisal can be improved have become issues of great concern. Previous scholars focused on embedding novel mathematical methods, such as fuzzy mathematics and neural network, into the market comparison approach to improve the objectivity and precision of computing. However, such improved market comparison approaches are still practically limited. For example, when the degree of proximity between samples and the object to be evaluated is low, the fuzzy mathematics would have poor computing precision [4]. For the neural network to train a highly precise price-appraisal model, a large number of samples is required, but finding a large number of similar samples will certainly increase the difficulty of applying the algorithm to solving real-world problems [5]. Generally, the current improved market comparison approach, under the conditions of a small sample size and a low degree of proximity, cannot effectively realize intelligent price appraisal. Therefore, computing precision, under the conditions of a small sample size and a low degree of proximity, should be theoretically and practically improved, and intelligent mass appraisal should be realized with the improved algorithm as the theoretical basis.
State of the art
To overcome the subjectivity of sample selection, Ferreira and Jalali selected similar samples using the fuzzy mathematical method [6]. Nonetheless, the fuzzy mathematical method is, in essence, an improvement of the market comparison approach. Its application has one prerequisite, that is, the use of similar samples. If the similarity of samples is low, then the computing results will be impaired. In terms of alleviating the influence of the subjective suggestions of appraisers on the objective appraisal outcomes, Mishlanova and Yur’evna set the initial value, persistently introduced new samples, and used adaptive estimation procedure (AEP) to continuously correct the model parameters and price estimates using new sample information, and they obtained satisfactory computing results [7]. However, the AEP focuses excessively on setting initial values. In particular, its lack of a standard algorithm has restricted its application. In terms of the price-appraisal model, Tabales et al. used artificial neural network (ANN) to train a large number of samples and obtain intelligent computing results [8]; by contrast, the ANN has poor explanatory capability due to it being a black-box operation. Liu et al. improved back propagation (BP) neural network and integrated such method with GIS to develop an intelligent price pre-estimation model [9]. Del Giudice et al. used samples to construct a hedonic price model (HPM) to realize intelligent price computing [10]. However, the establishment of the neural network and the HPM requires a large number of samples. In this way, the predictability of the model is determined by the training set consisting of similar samples, thereby making the selection of classical samples difficult. Thanasi used samples to simulate multiple regression analysis (MRA) for the price computing of specific commodities, and intelligent price appraisal was realized by using the MRA model [11]. However, the use of the MRA model requires successful simulation of equations and confirmation of hypotheses about zero mean, equal variance, sequence independence, normality, and nonexistence of multiple collinearity. Thus, the MRA model has high data requirement.
Several scholars have also explored how the market comparison algorithm can be replaced with the new appraisal algorithm. For example, Ahn et al. combined ridge regression with genetic algorithm (GA-ridge) to empirically study South Korea’s real estate market, and the empirical study results verified the validity of GA-ridge in intelligent price computing [12]. Arribas et al. proposed hierarchical linear model (HLM) to realize intelligent price computing, thereby overcoming the unrealistic hypothesis made by least square method about the individual independence of samples [13].
The abovementioned studies provide a favorable theoretical basis for intelligent price appraisal. However, they each have several limitations. For example, the GA relies on the selection of initial samples [14]. Similarly, the neural network and the HLM call for the support of a large sample size [15]. Owing to these limitations, the abovementioned algorithms cannot effectively guarantee their computing precision, especially when the available sample size is small or the proximity between samples and the object to be evaluated is low. Therefore, these limitations must be addressed. The current study quantified the attribute weights of the commodity price using the grey correlation analysis. The price correlation between the samples and the object to be evaluated was then identified. The fuzzy mathematical method was employed to modify the relative weight of samples. The improvement of the traditional market comparison approach was then finalized. The improved algorithm can effectively guarantee computing precision under the conditions of a small sample size and low degree of proximity. The improved algorithm can also serve as a theoretical basis for the realization of intelligent mass computing with the aid of computer technology.
This study is organized as follows: Section 3 expounds on the computing algorithm based on grey correlation and fuzzy mathematics. In Section 4, several residences in Hangzhou are chosen as study samples to verify the feasibility of the proposed algorithm. Analysis of the intelligent computing results suggests that the market comparison approach improved through grey correlation and fuzzy mathematics can achieve a high computing precision even under the conditions of a small sample size and low degree of proximity. Section 5 summarizes the main findings of this study on the basis of the analysis of the previous sections.
Methodology
Grey system theory reveals how an object with a small sample data and a small amount of known information changes by analyzing the characteristics of small-sample data and learning their behavioral performance. The theory is known for its high information utilization rate and precision, reasonable computing of the attribute weight, and simple data computing. The fuzzy mathematical method can solve for the proximity between different samples and objects to be evaluated. Even if the degree of proximity is low, the weight of samples can still be effectively determined. Thus, this study employed grey correlation analysis to determine the attribute weight influencing the commodity price, based on which the price correlations between different samples can be identified. The fuzzy mathematical method was then used to rectify the weight of different samples. Finally, the algorithm was adopted to solve for the price of objects to be evaluated to verify the validity and objectivity of the computing results.
Basic concepts
Grey correlation: Grey correlation is a measure of the correlation between two systems or two factors or between systems and factors. Ranging within the section of [0, 1], grey correlation describes the relative changes of factors during system development. If the relative changes of two factors almost coincide during the system development, then the correlation between the two factors is regarded as high. By contrast, the inter-factor correlation is low. The higher the correlation between influencing and influenced factors, the more likely is the influencing factor to be the main factor and to make significant contributions to the formation and change of the influenced factors. This condition also applies to price appraisal. When an attribute is correlated with the price, the attribute can play a key role in price formation.
Price index: Price index refers to the comprehensive scoring of different commodity properties obtained through a certain method.
Price correlation: Price correlation refers to the price correlation between two commodities identified using specific methods, at a certain point of time, and in a specific market. The price correlation can be measured by the price index of commodities. It is the ratio of the price index of objects to be evaluated to the price index of samples for case study.
Basic methods
Construction of the price correlation
(1) Measurement of attributes
Even at the same point of time, the price of different commodities varies. This condition is due to the fact that different commodities have different attributes, and the differences of attributes naturally lead to price differences. Therefore, before price appraisal, the attributes influencing the price must be extracted from the existing sample library. The extracted attributes are the prerequisite for price appraisal. In addition, to increase the efficiency of price appraisal, these attributes are divided into quantitative and qualitative attributes. Take the real estate industry, for example: the quantitative attributes include the floor, floor area, and so on; whereas the qualitative attributes include educational facilities and degree of decoration. The former is measured on the basis of its original values, whereas the latter should be transformed into quantitative attributes usually through the Dephi method.
The dimensionality of the abovementioned attributes is usually inconsistent. As a result, they influence the formation of the final commodity price to different degrees. This condition necessitates the normalization of attributes. After normalization, the attributes fall into two categories, namely, benefit-oriented attributes and cost-oriented attributes. In addition, take the real estate industry, for example: the benefit-oriented attributes, which refer to attributes having a positive and promoting effect on price formation, include decoration, traffic, community environment, and so on. The higher the value of benefit-oriented attributes is, the higher their price will be. By contrast, the value of cost-oriented attributes can curb price formation. In other words, the higher the attribute value is, the lower the price will be. In the real estate industry, cost-oriented attributes include the distance away from business districts, the age of houses, and so on. After the normalization of all these attribute values, they all fall within the range of [0, 1]. Overcoming the inconsistency of the dimensionality of different attributes contributes to comparability among different attributes.
Assume that X
i
is an attribute of the object to be evaluated; i (i = 1, 2, 3, …, n) refers to the number of attributes. The observational data of k samples can be written as x
i
(k), k = 1, 2, 3, …, m. The expression X
i
= (x
i
(1), x
i
(2), x
i
(3), …, x
i
(m)) is then regarded as the behavioral sequence of the attribute X
i
. Let the behavioral sequence of the price attribute be X0 = (x0 (1), x0 (2), x0 (3), …, x0 (m)). On the basis of the original behavioral sequence, the sequence operator is adopted to normalize the original behavioral sequence. The normalization result of x
i
(k) can be written as y
i
(k). The normalization method of the benefit-oriented attribute value can be expressed as follows:
The normalization method of the cost-oriented attribute value can be expressed as follows:
After the normalization of the original behavioral sequence, the following normalized sequence Y i can be obtained:
(2) Price correlation
The normalized sequence of the price attribute can be regarded as the mother sequence, and the difference sequence Δi (k) between the mother sequence and the sequence of other influencing factors can be written as follows:
The correlation coefficient γ
ik
can then be solved by Equation (5) as follows:
The degree of correlation γi can be written as follows:
Thus, the attribute weight ωi can be expressed as follows:
The weight matrix W can be written as follows:
The price index V
k
can be solved by Equation (9) as follows:
The price correlation δ refers to the ratio of the price index of an object a to be evaluated to the price index of any sample b:
(1) Proximity
Let the transaction sample of m commodities be A1, A2, …, A m ; their attribute set be T = (x1, x2, …, x n ); their eigenvector be {μA1 (x i ), μA2 (x i ), …, μA m (x i ) }, where μ A j (x i ) (j = 1, 2, …, m ; i = 1, 2, …, n) refers to the vector of the attribute value. The proximity σ between samples A p and A q can then be expressed by Equation (11).
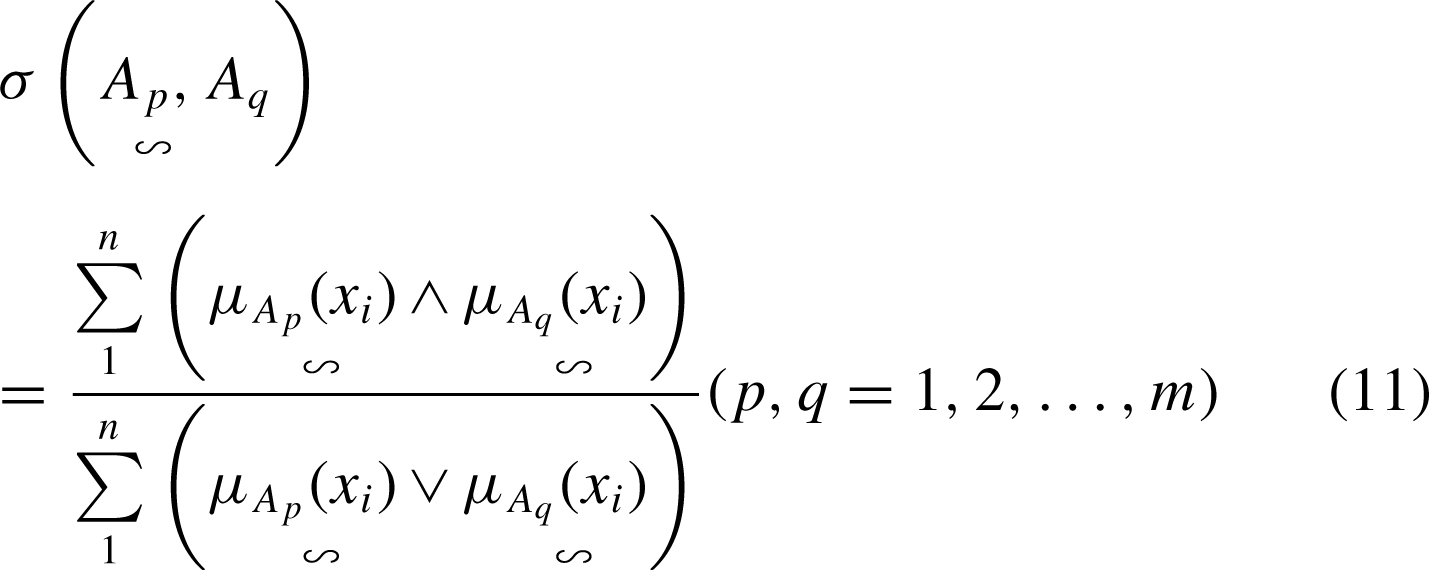
(2) Weight
As mentioned above, the influences of different commodity attributes on the price are different. Computation of the proximity between the sample and the object to be evaluated relies on decomposition and comprehensive analyses of the sample attributes. On the basis of Equation (7), suppose the object to be evaluated is B. The proximity between the transaction sample, A1, A2, …, A m , and B can be written as follows:
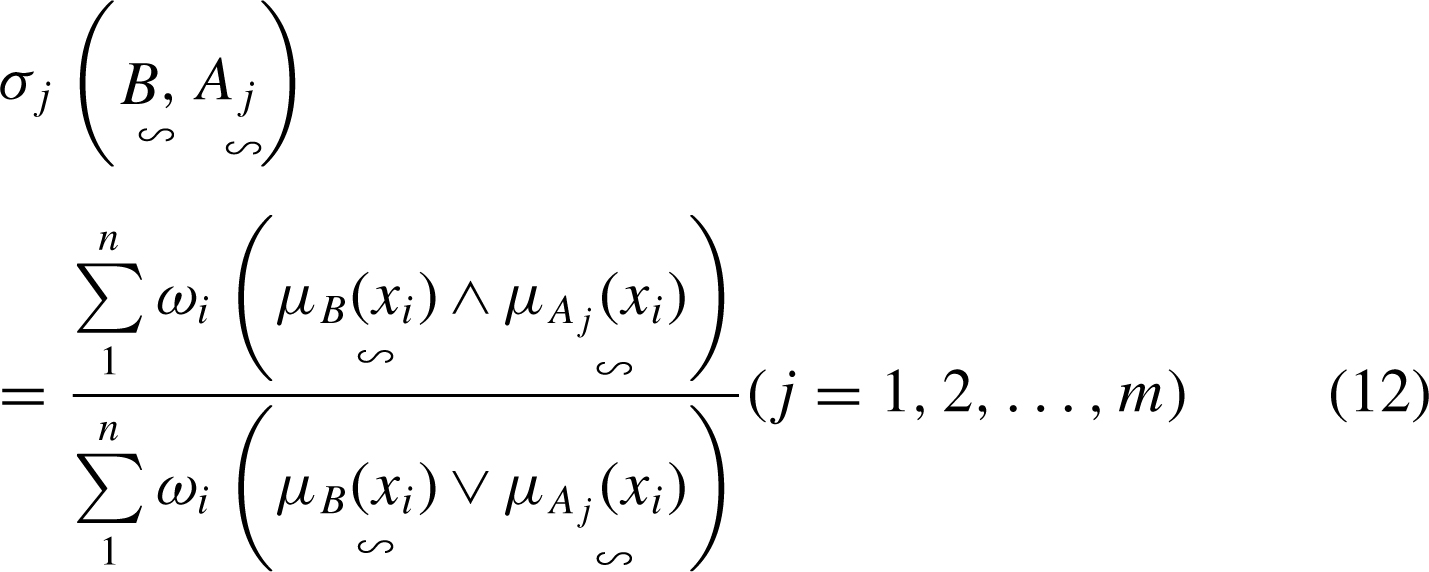
According to the proximity computing results and through normalization, the weight of samples α j can be written as follows:

Mass appraisal
Combining Equations (10) and (13), suppose the transaction price of the m samples is p1, p2, …, p
m
. The price P′ of the object to be evaluated can be written as follows:
Data sources
The study samples are from the Center for Real Estate Study, Zhejiang University. Several Hangzhou residences below the eighth floor and with a floor area below 100 square meters are chosen as study samples. These samples are used to verify the validity and reliability of the proposed price-appraisal algorithm based on grey correlation and fuzzy mathematics, and the intelligent price-appraisal system is hence built. Findings show that 11 main attributes can influence the residential unit price. They are X2 (the distance [kilometer] away from the central business district); X3 (the distance [kilometer] away from the West Lake); X4 (the number of bus routes nearby); X5 (the floor area [square meter]); X6 (the service years of the residence); X7 (the floor of the residence); X8 (the decoration degree of the residence); X9 (the community); X10 (the community property management level); X11 (the completeness of living facilities); X12 (the completeness of educational facilities). X1 is the unit price (yuan/square meter) of the sample. The residential unit price and attribute values are shown in Table 1.
Values of attributes influencing the residential unit price in Hangzhou
Values of attributes influencing the residential unit price in Hangzhou
Suppose that the price of the sixth sample is unknown. The first five samples form a library of sample cases; the price of the sixth sample can then be computed. Among the 11 attributes influencing the price, X2, X3, and X6 are cost-oriented attributes, and the rest are the benefit-oriented attributes.
The attribute values are normalized using Equations (1) and (2). According to the correlation coefficient of various attributes solved by Equation (5), the correlation degree of various attributes solved by Equation (6), and the weight of various attributes solved by Equation (7), the weight matrix W can be obtained as follows:
Combining Equations (9) and (10), the price correlation between various samples and the object to be evaluated can be obtained using Equation (15) as follows:
According to Equation (13), the weight of various samples can be obtained using the following equation:
According to Equation (14), the estimated price of the object can be solved, which is 4074.97 yuan, using the data in Table 1 and the results obtained by Equations (16) and (18). The relative error between the computing result obtained by the proposed algorithm and the actual price can be expressed as follows:
Error of the intelligent price-appraisal system based on grey correlation and fuzzy mathematics
As observed in Table 2, the intelligent computing system uses only five samples (Nos. 1 to 5). The sample volume is small, and the degree of proximity between the samples and the object to be evaluated is low. The small-sized sample is used to estimate the price of the object ranking No. 6 to No. 10. The minimum computing error is found with No. 9, and the minimum error is 0.01%. The highest computing error is found with No. 8, and the error reaches 2.7%. The mean error of the computing results by the five samples is only 0.99%. The overall precision is high, and this result suggests that the intelligent price-appraisal algorithm based on grey correlation and fuzzy mathematics can effectively estimate the price of the object with a small-sized sample and with a low degree of proximity with the samples.
Among the above computing results, the sixth sample is computed artificially, whereas the seventh, eighth, ninth and tenth samples are computed by a computer-aided system with the attribute values of the object to be evaluated as input. Efficient computation by the intelligent computing algorithm indicates that the algorithm can serve as a theoretical basis for intelligent price appraisal. In addition, the algorithm is suitable not only to the price appraisal of a single object but also to mass appraisal. The superiority of the algorithm will be more evident with the increase of objects to be evaluated.
Conclusions
Among traditional commodity price-appraisal algorithms, the market comparison approach has a poor computing precision when the sample size is small and the degree of proximity between the samples and object to be evaluated is low. To achieve intelligent computing, the market comparison approach should be further improved. In this study, an intelligent price-appraisal algorithm was developed on the basis of grey correlation and fuzzy mathematics. Through the construction of the price correlation among different samples and the confirmation of the sample weight, intelligent price computing was realized. Thus, the following conclusions can be drawn:
The intelligent price-appraisal algorithm based on grey correlation and fuzzy mathematics can maintain high computing precision even when the sample size is small and the degree of proximity between the samples and the object to be evaluated is low. The proposed intelligent price-appraisal algorithm can achieve mass appraisal of multiple objects to be evaluated using a computer-aided system. Thus, the algorithm is highly operational.
The proposed algorithm is an optimization of the market comparison approach. It can improve the computing precision under the conditions of a small sample size and low degree of proximity between samples and the object to be evaluated. Thus, the algorithm is worthy of further development. However, this study does not discuss how the uncertainty of attributes and the influence of a large sample size on the feasibility of the algorithm can be reduced. Therefore, these two issues should be addressed in future study.
Footnotes
Acknowledgments
This study was supported by the Fundamental Research Funds for the Central Universities (No. 2017CDJSK03XK02).