
Abstract
Taking the dynamic risk identification as the research object, propose a risk identification model of dynamic memory and variable fuzzy identify based on the immune mechanism extension, DRIBIEM. According to the dynamic risk characteristics which is complex and uncertain, DRIBIEM dynamically maps the intensity and frequency of risk to the concentration of antigen, based on the cell death pattern, stimulates immune memory, guides the evolution of antibodies and controls life cycle of identifier by antigen concentration which solves the problem that the traditional immune identification algorithm takes too long time, realizes the distributed automatic updating of identifiers and improves the dynamic risk identification ability. Simulation results show that DRIBIEM fully reflects the dynamic characteristics of immune memory and can effectively identify the complex dynamic risks. Its feasibility can be verified in the practical application of dynamic risk identification.
Introduction
Artificial immune system has become one of the research topics in the field of emerging information science. As one of the main ways of immune response, immune memory plays an important role in the artificial immune system and is widely used in risk identification, emergencies, network intrusion detection and anomaly detection [1–3]. The memory cell theory is an idea that is widely adopted, and it is even more successful in handling optimization problems [4–7]. In general, the local optimal solution is stored in the form of memory cells, and then taking the affinity or matching degree between antibody and antigen as a measure, continuously compare the local optimal solutions in the calculation process to obtain the global optimal solution. This method is suitable for solving the characteristics of optimizationproblems.
Especially the emergencies in small probability, as a special case of dynamic risk, it not only has the dynamic risk’s characteristics which change over time and are complex uncertainty, but also has the characteristics of irregularity, which manifests mutation and abnormality in time and makes the identification of such events more difficult. However, the small-probability emergencies widely exist in the fields of engineering, climate, outbreak of infectious diseases and so on. How to effectively identify the mutations and abnormalities of small probability emergencies is the hot spot in the research of dynamic risk identification.
For example, some scholars used Fisher’s information to detect and identify mutations in the structure of system dynamics, from the perspective of dynamics structure [8]. However, from a dynamics point of view, the mutation is a system from one stable state to another stable state [9]. Therefore, from a dynamics point of view, it is likely that the risk of instability during the mutation will not be identified.
The biological immune system is a dynamic and complex system, various immune effector molecules maintain the dynamic balance of the system in mutual inhibition and motivation, and then maintain the stability and safety of the system in a constantly changing environment. These characteristics of biological immune system provide a new method for dynamic risk identification. At the same time, the biological immune system in a case that the environment faced is entirely uncertain, time-varying and the type of external invaders (antigens) is almost unlimited, can provide excellent defense against both known and unknown antigens. This feature makes the artificial immune system, which mimics the operating mechanism of the biological immune system, has a natural advantage in identifying the risk of small-probability emergencies. However, there is not much research and application on artificial immune system in the field of small-probability emergencies. For the conventional immune memory method based on the theory of memory cells, if the risk identifier successfully identifies a certain pattern, the identifier is stored and saved as a memory cell so as to identify the same pattern again [10, 11]. Immune memory is maintained by memory cells. This identification mechanism leads to memory being static, while the feature’s changes of small probability emergencies cannot be correctly captured and identified. Therefore, immune memory is not fully adapted to the dynamic risk identification of small probability emergencies.
Wilson proposed the artificial immune system to adopt the residual antigen theory to simplify the memory model for the first time in 2004, which break the traditional method of using memory cell theory to establish memory model, and no longer distinguished between memory cells and ordinary cells. Wilson uses a life-cycle control algorithm based on the process of cell mitosis, the principle is: There is a short segment of DNA in the cell called telomere, which decreases in length each time the cell cleaves, and when its length decreases to zero, the cell would die because of cannot cleave [12]. In this way, the memory will be greatly prolonged, but eventually disappear. If used in the dynamic risk identification of small probability emergencies, it will not be able to fully adapt to the characteristics of irregularity and mutation of small probability emergencies.
The biological immune system’s functions that identify external invasion and resist internal abnormal is mainly realized by cellular immune response. The mode of cell death is related to the response way of immune response, the nature of antigen determines the response way of immune response, while the way of cell death determines the nature of antigen [13].
This paper proposes a dynamic risk identification model based on immune mechanism extension (DRIBIEM, Dynamic Risk Identification Biological Immune Extension Model). Unlike to Wilson’s, DRIBIEM directly and dynamically maps the intensity and frequency of the dynamic risk of small-probability emergencies to the antigen concentration, and uses the cell death way as the basis of antigen identification, stimulate the immune memory through the antigen. Thus, the antigenic form the system memorizes is the most valuable, and the utilization of resources will be improved.
Dynamic risk identification extension of biological immune mechanism
Immune cells in the biological immune system are mainly divided into B cells and T cells. B cells mature in the bone marrow, its role is to produce antibodies, eliminate antigen. T cells are produced in the bone marrow and then enter the thymus, most of the T cells that threaten their own proteins are eliminated, and a few of them that are harmless to themselves develop into maturity. Mature T cells have a receptor for antigen detection, and once a non-self-antigen has been found, B cells are activated immediately to make an immune response toeliminate the antigen. The level of stimulation of B cells depends not only on the concentration of antigen and the degree to which B cell antibodies bind to the antigen, but also on the degree of T cell’s coordination. If the B cells’ stimulus level exceeds a certain threshold, B cells would begin to cleave, replicate and mutate, while B cell antibodies with a high degree of binding are retained. On the contrary, if the stimulus level drops to a certain threshold, B cells would no longer replicate and die at the scheduled time. B cells and T cells cooperate with each other to identify antigens through their surface antigen receptors.
The main way to identify antigens is negative selection [14]. The core of negative selection lies in coding according to the characteristics of the identification object, defining a “self-set” and randomly generating identifiers to identify the change of “self-set”.Negative selection mechanism has been widely used in image recognition, intrusion detection and anomaly detection. But the generation of negative selection identifier only relies on the samples data of normal pattern and does not make full use of historical experience data, therefore, it is inefficient to dynamic risk identification. In addition, the negative selection identifier detects non-self through simple binary string matching, so it lacks flexibility and robustness when use the traditional negative selection identifier to identify the dynamic risk, resulting in relatively poor identification performance.
Dangerous theory, put forward by Polly Matzinger in a paper published in Science, is a major advance in risk management and immunology research. Immune dangerous theory puts forward that the factors that trigger the immune system to initiate immune response are not non-self-pathogens invaded but the dangerous signal sent by the body, which do not completely follow the “self-non-self” mode. When the “danger” of an organization be invaded accumulates to a certain extent, sends a dangerous signal, which means that the immune system identifies dangerous antigens [19, 20]. According to the dangerous theory, the stimulation of low concentration of risk antigen doesn’t trigger the body’s immune response, only when this dynamic risk factors accumulated to a certain degree, a dangerous signal would be sent and then the body initiate the immune response proactively [21–23].
In the biological immune system, the identification rate of autologous/allogeneic is very important to the performance and health of the system. The higher the identification rate, the stronger immunity of the system. The traditional risk identification model generally detects the risk through the known risk characteristic items matched by the knowledge database in the risk identification system [14]. Due to the unpredictability and dynamic evolution of small probability emergencies’ risk, traditional identifiers have a low identification rate of dynamic risk. At the same time, the traditional dynamic risk identification model may also identify the beneficial information factors as danger signals, which leads to self-harm and misidentification. Therefore, it is very necessary to study the dynamic risk identifier model for the complex uncertain characteristics of dynamic risks, so as to improve the identification rate of dynamic risks and reduce the false identification rate [24–26].
To this end, this paper proposes a dynamic memory risk identifier model based on immune extension, DRIBIEM. The construction of this model includes two steps:
The established automatic identifier includes two types: dynamic memory automatic identifier and variable fuzzy automatic identifier.
The dynamic memory automatic identifier mainly identifies some basic anomaly in enterprise activities. It consists of historical experience and some simple dynamic risk identification rules, and outputs the “normal” or “abnormal” state, as shown in Fig. 1. Among them, the historical experience database includes the feature database established by quantitative analysis of various dynamic risk sources’ features, while the risk identification rules are some simple rules formulated by the domain experts based on experience.
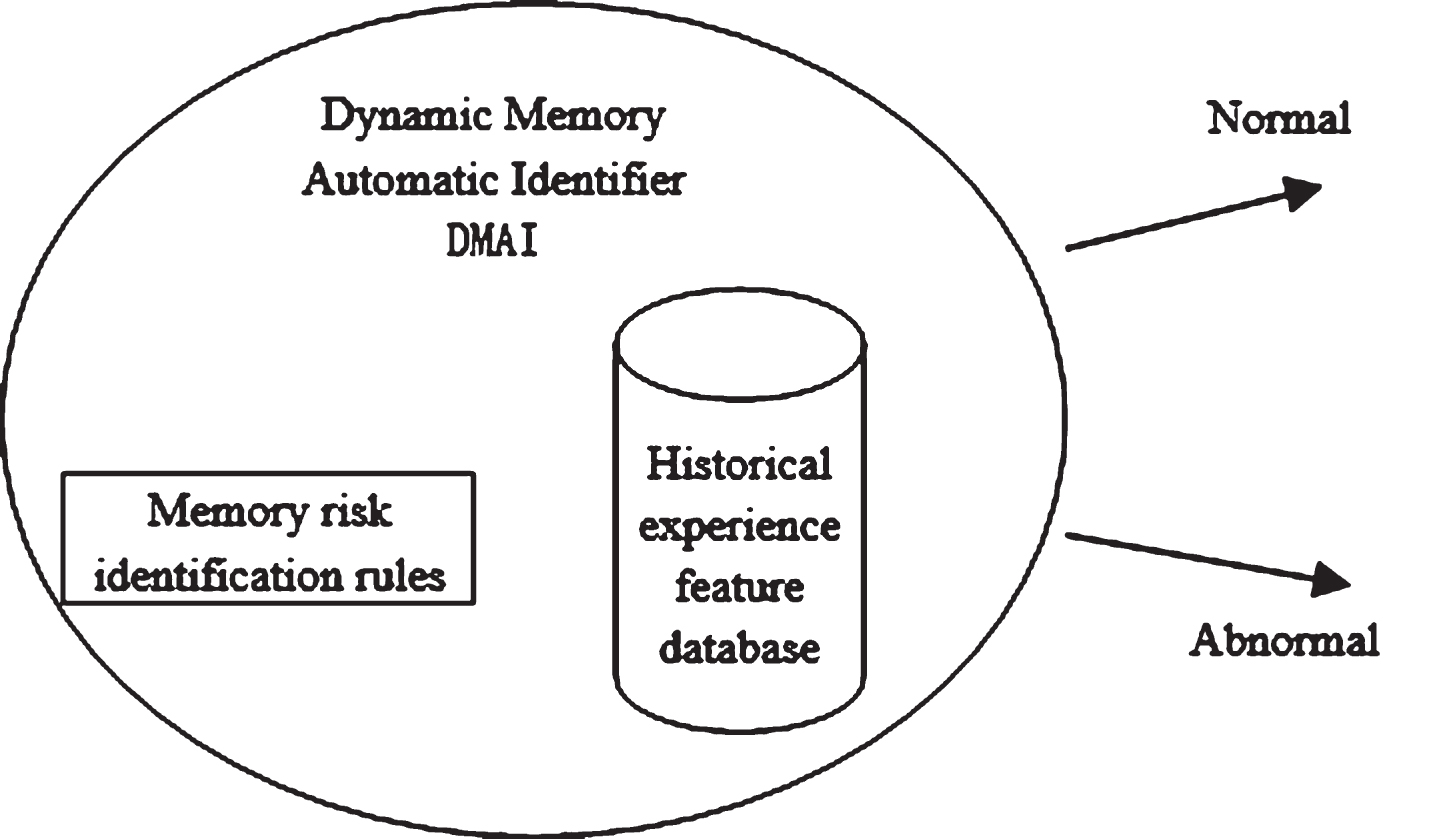
Dynamic Memory Automatic Identifier.
The variable fuzzy automatic identifier mainly identifies the risks that more complex and variable. It is a set of fuzzy reasoning system composed of dynamic risk feature database and fuzzy variable risk identification rules obtained in dynamic learning process, and it has three states that is “normal”, “doubt” and “abnormal”. The risk identified as “doubt” would enter the stage of risk monitoring to re-identify, as shown in Fig. 2. During the study period, the functions and parameters of the fuzzy reasoning system will be determined according to the historical experience feature obtained in the dynamic and proactive learning process, while according to the extracted dynamic risk feature in accordance with the fuzzy variable risk identification rules for reasoning to determine the state of risk at the time of identification. The reason for the construction of fuzzy variable identification rules is that the boundary itself between normal and abnormal is fuzzy, so fuzzy rules are more in line with the essential characteristics of risk evolution [15].
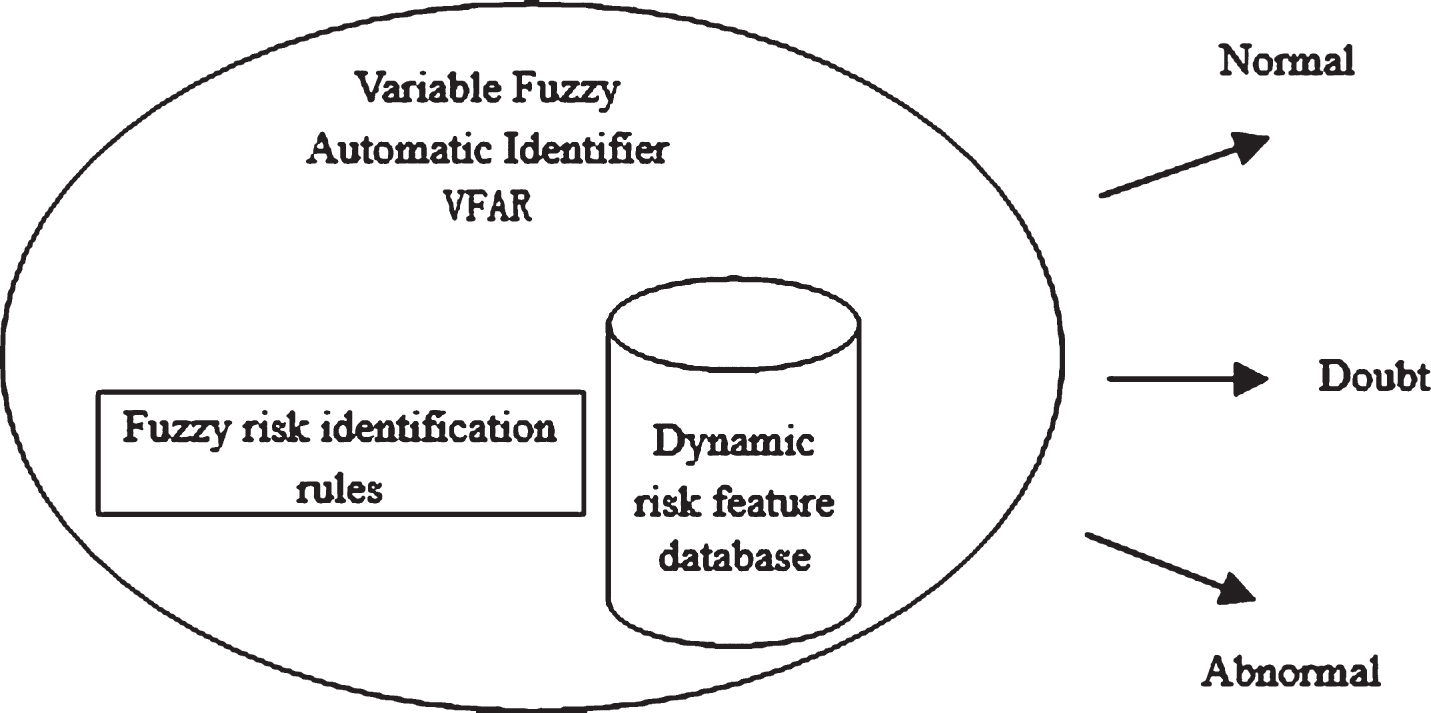
Variable Fuzzy Automatic Identifier.
This paper proposes an immune extension algorithm based on dynamic memory. Compared with the traditional artificial immune risk identification algorithm, this algorithm is extended in the following two aspects: On the one hand, the dynamic risk identifier can be generated directly by using the dynamic risks memory database and the dynamic feature database obtained during the dynamic learning process, which avoids the shortcoming that the immune negative selection algorithm would take too long to generate a suitable identifier, improve the dynamic risk identification efficiency. On the other hand, there is an extension in the “self-not-self” mode. This algorithm proposes dynamic memory automatic identifier and variable fuzzy automatic identifier, which has a good identification effect on the dynamic risk of complex and variable, especially the dynamic risk of small probability emergencies.
It is assumed that antigen agent represents the dynamic risk, which is the identified object of dynamic risk automatic identifier; the automatic identifieragent is generated to deal with the specific dynamic risk, and eliminate the identifier of the poor identification performance, retain the identifier of the good identification performance through the corresponding proactive learning model and the preferred method, then maintain the optimal risk identifier in the process of dynamic identification. To this, the paper will establish the one-to-one corresponding relationship between the basic elements of biological immune system such as pathogens, antigens, antibodies and other factors and factors of the dynamic risk identification, then obtain the corresponding relationship between the biological immune system and the dynamic risk identification system, as shown in Table 1.
The corresponding relationship between biological immune system and dynamic risk identification system
The corresponding relationship between biological immune system and dynamic risk identification system
The dynamic risk identification problem is essentially a fuzzy clustering problem, rather than a structured problem which is 1 if not 0. It is difficult to guarantee the accuracy of dynamic risk identification by using only the idea of combining clonal selection and negative selection in traditional biological immunity and using structured methods to solve the problem of fuzzy clustering in calculating antibody and antigen matching. DRIBIEM simulates the function of the biological immune system to quickly and accurately identify the harmful antigens, and extend on the definition and identification algorithm of antigens, to achieve the dynamic risk automatic identification function of DRIBIEM.
DRIBIEM is an automatic identification system formed by its own continuous learning and evolution, which mainly divided into two stages: dynamic memory automatic identification and variable fuzzy automatic identification.
Dynamic memory automatic identification based on the existing antibody set and antigen set of organization, automatically identify the external pathogens through the historical experience database gained from the continuous learning of auto antibody sets and the immune memory that formed via antigen with low concentration stimulating the immune system continuously. Historical experience database is composed of identifiers that can automatically identify a specific class of antigens through a dynamic memory immune algorithm. The stimulation of antigen with low concentrations in the body doesn’t trigger an immune response, only leaving the tissue immune system always in a state of preparation for possible hazards, and the level of antigenic stimulus at this concentration is expressed as a safe antigen concentration.
If confronted with the hazard (or similar pathogens) over safe concentrations again, the immune system would automatically identifies such antigens. The antigenic stimulation in the safe concentration range produce immune memory, expressed as the life cycle of the dynamic memory automatic identifier. The frequency and intensity of dynamic risk are intuitively mapped to internal antigen concentrations by antigen proliferation and attenuation mechanisms, which in turn guide the evolution of the identifier. If the identifier identifies the antigen, the corresponding antigen concentration increases, then the antigen information is output, the corresponding antibody are preferred for cleavage mutations, finally update the dynamic memory automatic identifier after training constantly; If the identifier does not identify the antigen, the corresponding antigen concentration decreases until the antigen concentration corresponding to the identifier decays to zero, then the identifier is dead, that is to complete a complete life cycle.
Variable fuzzy automatic identifier model description
The variable fuzzy automatic identifier mainly aims at the identification of antigens that cannot be identified by the dynamic memory identifieror the more complicated and changeable one, such as the risk identification of small probability emergencies. It is composed of dynamic risk feature database continuously learned in the process of artificial immune identification and the variable fuzzy immune algorithm.
The dynamic risk feature database can automatically identify a certain specific antigen by variable fuzzy immune algorithm, the variable fuzzy immune algorithm is mainly based on the cell death identification theory, and use the idea of fuzzy matching and the method of threshold value matching to extend the scope of the identification, thus greatly reduce the number of misidentified and leaked identification, improve the identification accuracy.
The cell death identification theory uses the method of cell death as the basis of antigen identification [15], then divide immune cells into healthy cells, apoptotic cells and necrotic cells. The healthy cells are normal cells that maintain the body’s stability. The apoptotic cells are cells that are actively die for better adapting to living environment, are generally non-pathological and do not trigger an immune response. While the necrotic cells would produce harmful substances that can cause inflammation of the body, then trigger an immune response.
If the identifier identifies healthy cells, ignores directly; if the identifier identifies necrotic cells, initiates the immune response to remove the necrotic cells; if the identifier cannot determine whether it is a healthy cell or a necrotic cell, then enter the monitoring phase; In the monitoring phase if the detected cells innocuous apoptotic cell, ignores directly, if the detected is harmful necrotic cells, then initiates the immune response to remove necrotic cells.
Based on the cell death pattern, the dynamic risk problem can be mapped with the immune cells one to one. The event source running normally corresponds to the healthy cells, the external events source that do not trigger risk corresponds to the apoptotic cells, and the external event source that causes or may cause the risk corresponds to necrotic cells. If the identifier identifies a harmful external event source, outputs the risk information, then evolves and optimizes the corresponding identifier, continuously updates the variable fuzzy automatic identifier through the proactive learning; if the identifier identifies a safe event or an innocuous external event source, ignores directly; and when identifies the suspected event, enters the immune monitoring phase. If during the immune monitoring phase the identifier detects a harmful external event source, outputs the risk information, and evolves and optimizes the corresponding identifier, continuously updates the variable fuzzy automatic recognizer through the proactive learning, otherwise, ignores directly. The overall framework of DRIBIEM shows as Fig. 3.
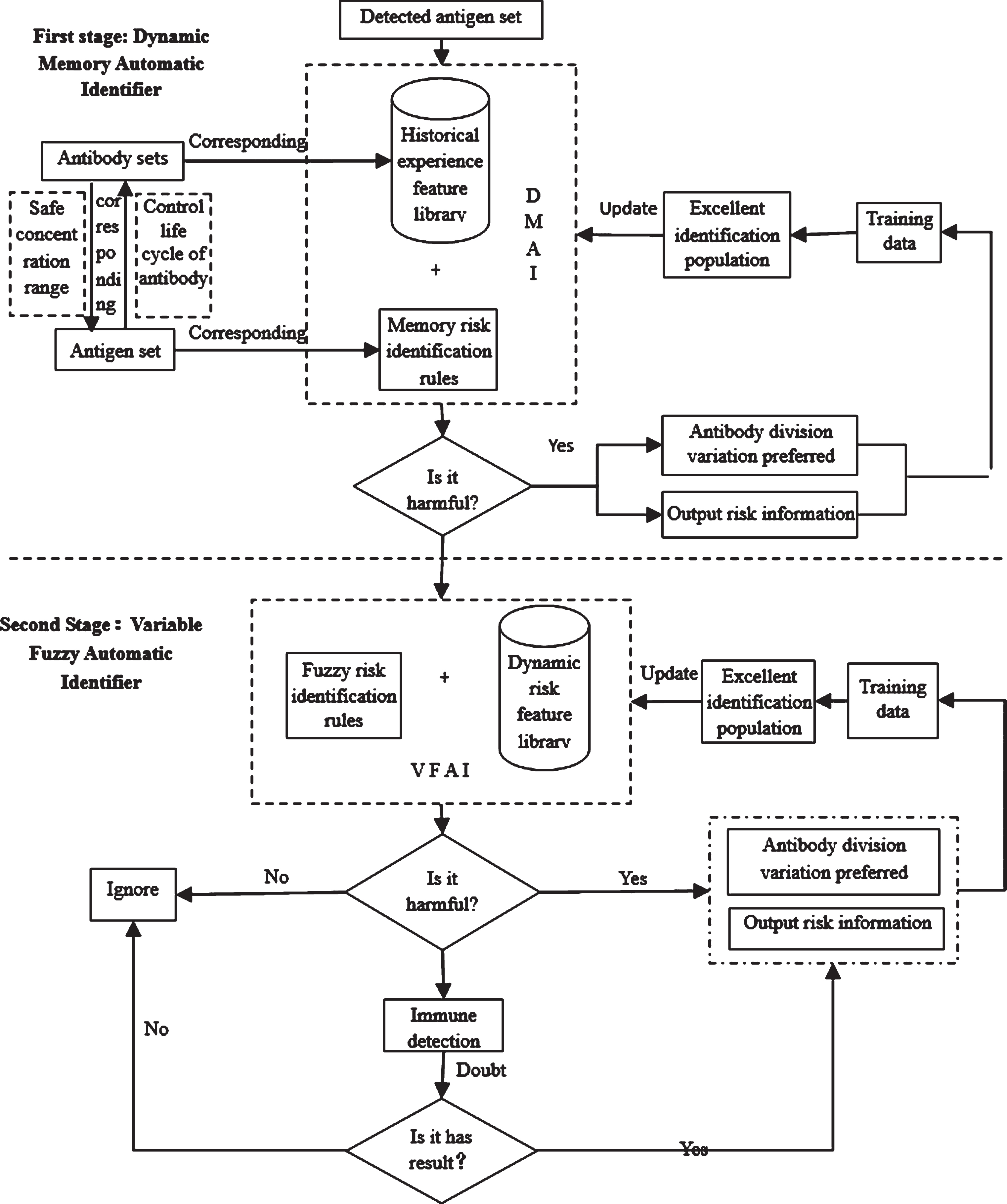
DRIBIEM framework.
According to the basic idea of the biological immune extension model of dynamic risk identification, the basic flow of DRIBIEM algorithm is determined as shown in Fig. 4.
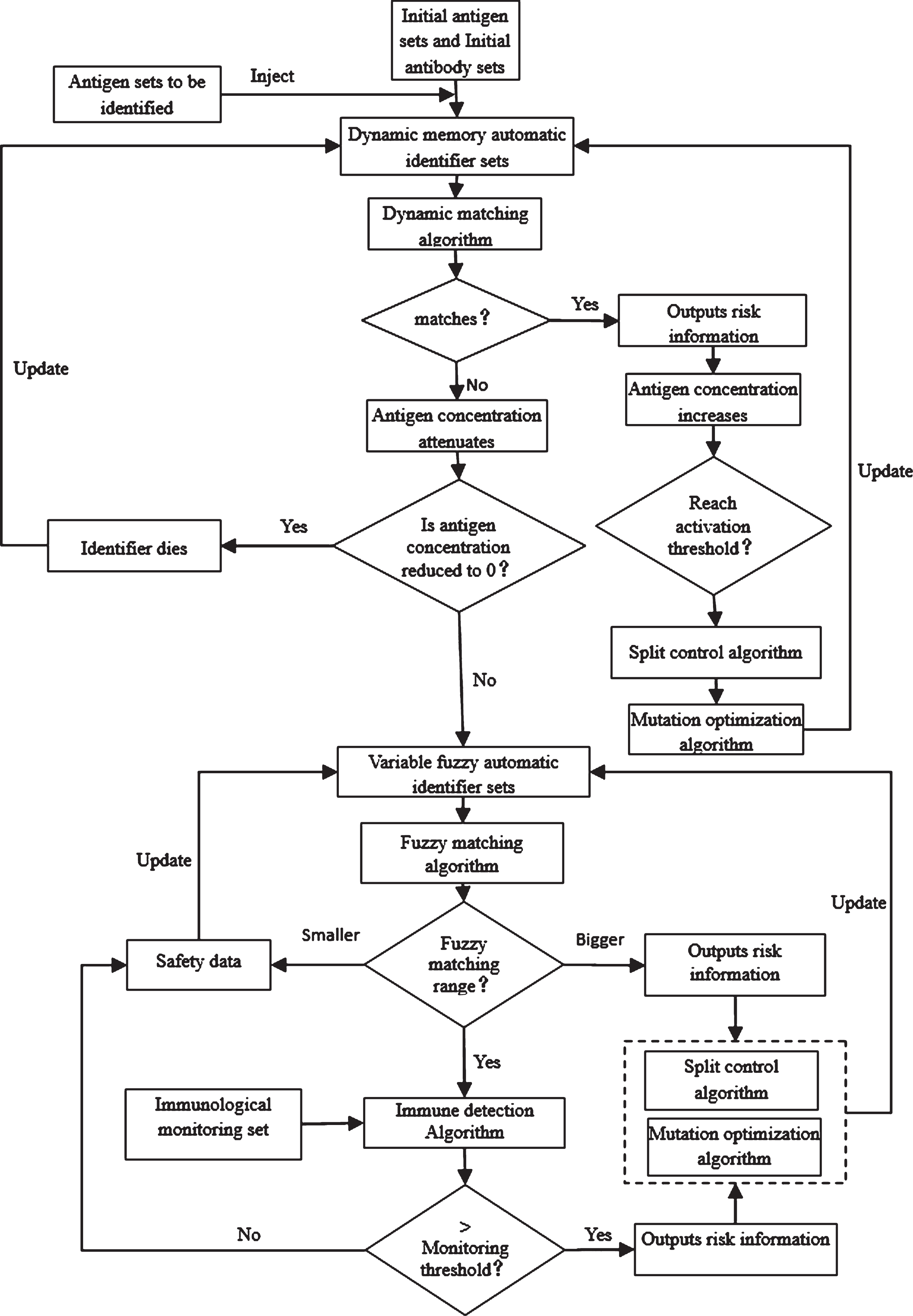
DRIBIEM algorithm flow.
The algorithm is described as follows:
The key immune algorithm rules in DRIBIEM algorithm mainly relate to the dynamic matching algorithm rules, the antigen concentration attenuation and increase algorithm rules, the variable fuzzy matching algorithm rules, the immune monitoring algorithm rules and the automatic identifier update algorithm rules.
In the biological immune system, most of the antigens are eliminated, and only a small amount of antigen remains in a safe concentration scope to continuously stimulate the immune system, which make the immune system always in a predict state to the possible dangerous. The biological immune system adjusts the immune system’s memory against the antigen based on the number of exogenous pathogens and the degree of tissue infection. Therefore, the immune memory is mainly determined by the level of antigen stimulation in the body and the affinity between antigen and antibody. The level of antigen stimulation in the body is expressed as the antigen concentration, according to the concentration of antigen, this paper establishes the antigen concentration increase and attenuation algorithm rules to simulate the changes of frequency and intensity of pathogens stimulating immune system.
The alleged matching means that affinity between the antigen to be identified and the antibody is greater than a given threshold, and the concentration of antigen to be identified exceeds the safe antigen concentration. Assuming that the antigen (Ag) and the antibody (Ab) are structurally similar, they are a combination of decimal bit strings whose length is n. The affinity of the antigen and the antibody is related to the distance between them. Thus, the affinity of antigen Ag and antibody Ab is calculated by the Euclidean distance. The calculation formula of affinity Aff(Ag/Ab) between Ag and Ab is as follows:
The antigen concentration (C) of any antigen Agi in the body antigen group G is calculated as follows:
Among them, 0 < α < 1, d (g, Agi) is the Euclidean distance between g and Agi.
The antigen concentration attenuation and increase algorithm rules
The concentration of antigen in the body reflects the situation of pathogens invasion that the immune system faced currently, and the antigen and antibody (identifier) adjust and influence each other in the quantity and concentration through the number’s increase and attenuation of antigens in the body. When the antigen to be identified enter the immune system, if the identifier identifies the risk, the corresponding antigen concentration increases, if the identifier fails to identify the risk, the corresponding antigen concentration decreases. The formula for the increase and decrease of antigen is as follows:
Among them, C (t) is the antigen concentration in the body at time t, C0 is the initial antigen concentration in the system, r is the added-value coefficient of the antigen (0 < r < 1);
The variable fuzzy matching algorithm rules
According to the initial set of affinity between antigen and antibody, set the initial minimum matching value and maximum matching value. When inject the antigen to be identified, the minimum matching value and the maximum matching value are recalculated, the affinity of the antigen to be identified is calculated as well, then determine the fuzzy matching interval scope according to the minimum matching value and the maximum matching value. If the affinity of antigen to be identified is less than the minimum matching value, it would be ignored. If the affinity of antigen to be identified is greater than the maximum matching value, that is, exceed the fuzzy matching interval scope, outputs the risk information; otherwise, enter the immune monitoring phase. Assuming the maximum match value is Affmax, the minimum match value is Affmin, the fuzzy matching scope is obtained:
MR = falgorithm (Affmin, Affmax). The fuzzy matching formula is as follows:
Among them, Aff (Agi, Abi) is the affinity between the antigen to be identify Agi and the antibody(the identifier) Abi, which is also calculated from Euclidean distance. When Aff (Agi, Abi)<MR, it means that Agi isn’t a “risk” antigen, which does not harm to the body; When Aff (Agi, Abi)>MR, it means that Agi is a “risk” antigen; When Aff (Agi, Abi)= MR, it means whether Agi is a “risk” antigen is not sure, and it needs a further monitoring.
The immune monitoring algorithm rules
When the body first comes into contact with the antigen, only a small amount of antibodies would be produced in a certain period of time, since the antigen has a latency period. It is difficult for the immune system to completely eliminate antigens in the body, and the antigen not only has a latency period, but also has an outbreak period, when the antigen reaches a certain amount, it may cause re-damage to the body. According to the characteristics that antigen has latency period and outbreak period, establishes the immune monitoring mechanism to detect latency antigens. The immune monitoring algorithm rules are as follows:
Among them, k (Agi, T) is the risk coefficient, which calculates the risk coefficient of Agi at time T, Kthreshold is the risk monitoring threshold.
When ID (Agi)= 1, it means that Agi is a “risk” antigen; When ID Agi= 0, it means that Agi isn’t a “risk” antigen, then would be “ignored”.
Among them, Match (Agi, { Ab }) is the matching degree between the antigen (Agi) and the antibody ({Ab}), φt is the risk coefficient attenuation factor, which make a balance between the antigen concentration and time t.
Among them, γ controls the speed of attenuation, and φt varying over the time t. When t = 1, k (Agi, 1)=Match (Agi, { Ab }), that is the matching degree of the antigen Agi when it is identified by the antibody identifier for the first time; When t > 1, 0 < φ (t < 1), it is concluded that only when the matching degree in the subsequent loop matching is greater than the first matching degree, Agi can be judged as a “risk” antigen.
The automatic identifier update algorithm rules
Among them, R (t - 1) is the antibody identifiers which are still present in the organization at time t-1, Rdead (t) is the antibody identifiers that had dead in the organization at time t, Rchoice (t) is the identifiers that are generated by cleavage and mutation in the organization at time t, and Nnew (t) are the antibody identifiers that are added into the immune system at time t. The cleavage and mutation rules of RchoiceAgi is as follows.
When the degree of antibody activation reaches the threshold, the antibody begins to cleavage and multiply, and the specific cleavage rules are as follows: If the degree of antibody activation Ad is greater than or equal to the activation threshold, the antibody would be cleaved into two offspring antibodies; Perform mutation operation on the offspring antibodies. The activation formula of the antibody is defined as:
Among them, Aff (Agi, Abi) is the affinity between antigen and antibody, C (Agi) is the antigen concentration, and ɛ is the adjustment factor. It can be seen from the above formula that the degree of the antibody activation is determined by the antibody concentration and the affinity between antibody and antigen. The greater frequency and intensity of a type of antigen is, the greater the activation degree of the antibody is, and the better ability the antibody to identify such antigenowns.
The accuracy of immune identification is determined by the principle that the affinity of offspring mutation antibody is greater than the affinity of parent antibody. If affinity of the two offspring antibodies after mutation are both lower than the affinity of parent antibody, the two offspring antibodies would be deleted and the parent antibody be retained; If affinity of the two offspring antibodies after mutation are both higher than the affinity of parent antibody, the parent antibody would be deleted and the offspring antibodies be retained, and give the antigen concentration corresponding to the offspring antibodies according to the formula; If there is only one offspring antibody affinity after the mutation higher than the parent antibody affinity, the parent antibody and the offspring antibody are retained, and set the initial antigen concentration corresponding to the offspring antibody be equal to the antigen concentration corresponding to the parent antibody.
Among them, Aff (Abchildren, Abparenti) is the similarity between the offspring antibody and the parent antibody, which is calculated by the Euclidean distance formula.
Simulation experiments and results analysis
System simulation based on Multi-Agent Modeling is an effective method to solve the complex social system, and it is very suitable for solving the simulation experiment of dynamic risk identification model. Learn from the idea of artificial immune, computational experiment and parallel execution, use the Multi-Agents structure, each agents run synchronously, and move freely between the nodes to detect abnormalities in the virtual environment. The identifier Agent identifies the antigen Agent’s behavior and generates a specific immunity response, and then conduct memory learning and dynamic change according to the changes of environmental [16–18].
Select the multi-agent global modeling and simulation software, Netlogo, as a simulation platform of DRIBIEM to simulate the execution system of immune identification system, based on the dynamic memory and fuzzy dynamic risk automatic identification algorithm, fully consider the characteristics of dynamic risk identification mechanism, dynamically update the identifiers to satisfy the requirement of proactive learning and memory of dynamic risk identifier, simulate and realize the practical application of immune extension mechanism in the dynamic risk identification.
Through simulating the constructed DRIBIEM dynamic risk identifier model, verify the scientific and feasibility of the model from the aspects of DRIBIEM’s risk identification performance and dynamics and so on.
DRIBIEM’s accuracy verification
In order to verify the identification performance of DRIBIEM, we will compare the result with the known “Self – non – Self” model, Dendritic Cell Model and Clonal Selection Model to prove the effectiveness of this method. In the process of immune identification, the identification rate is generally used as an indicator to measure the design effect of the identifier. The IPR (Identify Positive Rate) indicates the proportion that the identifier can correctly identify the risk antigen, which can be calculated using the following formula.
Among them, TP (True Positive) indicates the number of risk antigens that identified by the identifier, and FP (False Positive) indicates the number of risk antigens that failed to be identified.
The INR (Identify Negative Rate) indicates the proportion that the identifier can correctly identify the non-risk antigen, which can be calculated using the following formula.
Among them, TN (True Negative) indicates the number of non-risk antigens that identified by the identifier, and FN (False Negative) indicates the number of non-risk antigens that failed to be identified.
Finally, obtain the formula for calculating the identification rate, as follows:
This article selects the Heart – diseases data set as the experimental data. The 14 attributes of the Heart-Disease data set contain 13 fixed attributes and one prediction attribute, and the prediction attributes are divided into two states which respectively is health status and disease state. According to the predicted attributes, the health data is called normal data, and the disease data is called risk data. According to the DRIBIEM and risk identification rate formula, simulate and analyze the accuracy and efficiency of the DRIBIEM automatic identifier which combine the dynamic memory and variable fuzzy.
In this paper, the DRIBIEM simulation results are compared and analyzed with the traditional “Self-Non-Self” Algorithm (SNSA), the Dendritic Cell Algorithm (DCA) and the Clonal Selection Algorithm (CSA), the comparison results are shown in Table 2.
Comparison of identification rates of each immune algorithms
Comparison of identification rates of each immune algorithms
From the identification rate of each immune algorithm, we can see thatthe average accuracy of antigen identification rate of DRIBIEM and CSA is up to 90%, among them: The average accuracy of DRIBIEM antigen identification is 96.21%, and the average accuracy of IPR and INR of DRIBIEM is 95.82% and 96.01%, respectively, which are both higher than those of SNSA, CSA and DCA. It is visible that the effect of DRIBIEM antigen identification is excellent.
To verify the dynamics of DRIBIEM identification, this paper continues to use the Heart-Disease dataset as the experimental data. Select some data from the experimental data as the initial set of antigens and antibodies, and the parameters in the model are set as follows, which is shown as Table 3.
DRIBIEM parameter setting
DRIBIEM parameter setting
According to the parameter setting in Table 3, the simulation results are shown in Fig. 5. The red icon in the left image represents the antibody (identifier) Agent, and the blue icon represents the injected antigen (risk) Agent. The figure on the right shows the trend phrase of the antibody changes with antigen injection, where the abscissa represents the number of antigen injections and the ordinate represents the changeable number of the antibody (identifier).
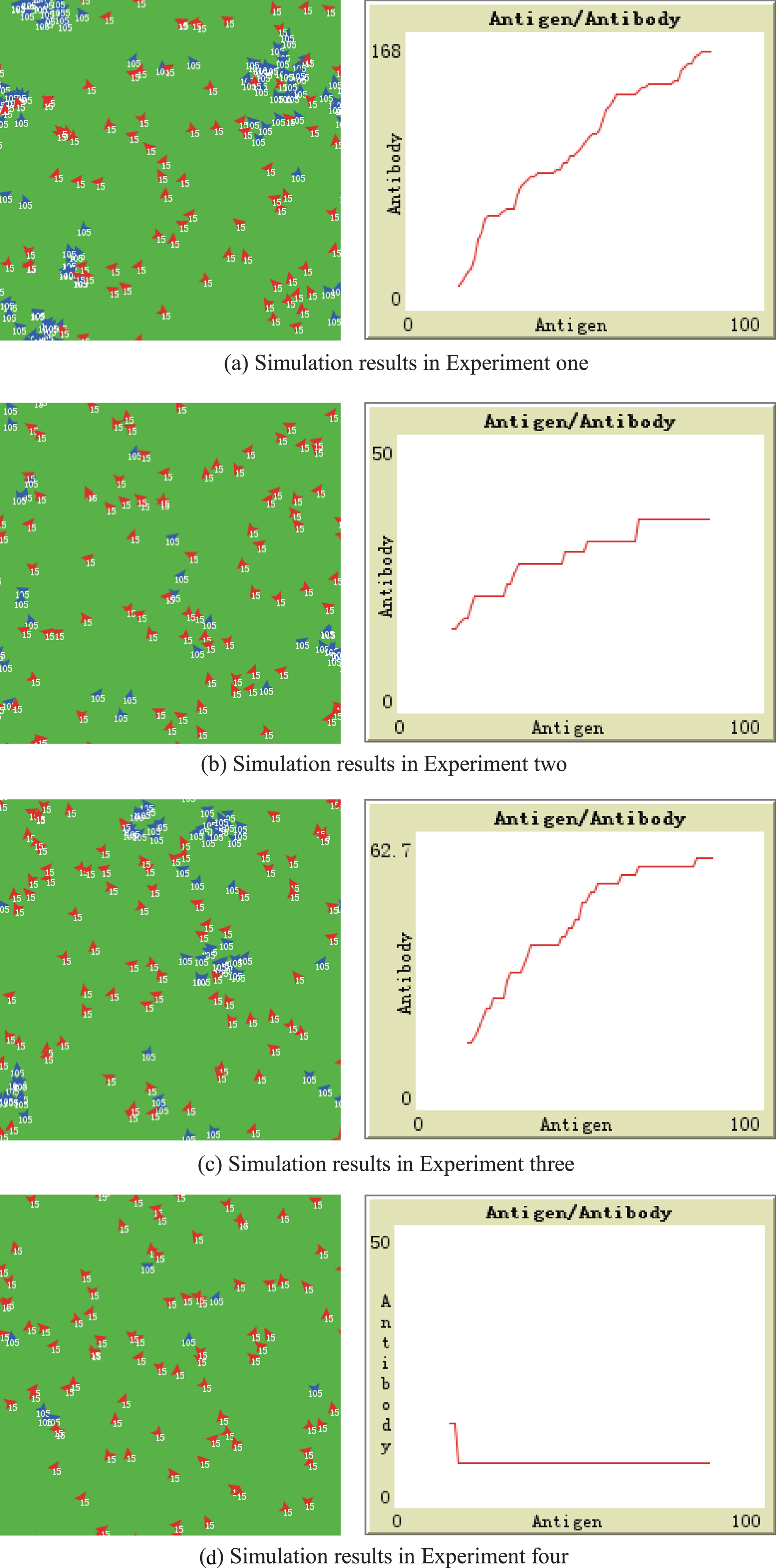
DRIBIEM model simulation results.
From the simulation results in Fig. 4.1, we can see that the antibody (identifier) changes dynamically with the number of antigen injection. The specific changes are related to the initial parameters of each experiment. The experimental results are analyzed following.
Comparing the experimental results of Experiment one and Experiment two, it can be concluded that in Experiment one the antibody (identifier) grows faster and the total number is bigger. In the situation that the matching threshold, the activation threshold and the increase or decrease coefficient of antigen and antibody are constant, the higher the concentration of the safety antigen, the more difficult for the corresponding antigen concentration to the antibody (identifier) decayed to 0, and the antibody (identifier) is more difficult to die. Comparing the simulation results of Experiment two and Experiment three, it can be concluded that in Experiment three the antibody (identifier) grows faster and the total number is bigger. In the situation that the matching threshold, the increase or decrease coefficient of antigen and antibody are constant, the higher the concentration of safe antigen is and the greater the activation threshold is, the faster the antibody (identifier) would grow. The higher the concentration of the safety antigen is, the more difficult for the corresponding antigen concentration to the antibody (identifier) decayed to 0, and the antibody (identifier) is more difficult to die. While the higher the activation threshold is, the more difficult for the antibody (identifier) to cleave, and the growth rate of the antibody (identifier) would be inhibited to some extent, which leads to a slower growth rate of Experiment two compared to Experiment one. Comparing the simulation results of Experiment four and Experiment three, it can be concluded that antibodies (identifier) of the Experiment four are basically dead. It indicates that the overlarge attenuation coefficient of antigen will lead to antigen fell sharply, the corresponding antigen concentration to the antibody (identifier) is easier to decay to 0, which lead to the identifier to die be before a large number of split.
The above simulation results show that, in the case where the initial parameters of DRIBIEM is set reasonable, the antibody (identifier) changes dynamically with the level of antigen stimulation, which verifies the dynamic validity of DRIBIEM identification.
As a method of application modeling and simulation, this paper aims to construct a systematic study of the dynamic risk identification’s application from the perspective of immunology. Firstly, this paper analyzes the mechanism of biological immune extension, then constructs the application model of biological immune extension, DRIBIEM. We use the multi – agent global modeling method to simulate the DRIBIEM on the Netlogo simulation platform to verify the validity and feasibility of model. The extended research on dynamic risk identification from the perspective of artificial immune system is an effective complement to existing research on dynamic risk, at the same time can be adapted to the application requirement of dynamic risk identification methods in the fields of organization, society and engineering.
The theoretical contribution of this paper is mainly reflected in the following two aspects:
Compared with the existing theory of dynamic risk identification, attempts to study the dynamic risk identification method from the perspective of biological immune mechanism are the study perspective’s innovations of this paper. Dynamic risk identification gradually turned to the perspective of extension on artificial immune, however, there is no in-depth and effective exploration on the specific supporting method in academia. The traditional immune method model is difficult to solve the complex and variable dynamic risk problem. This paper constructs the dynamic memory automatic identification model and the variable fuzzy automatic identification model, which gives a new idea to solve the dynamic risk identification in theory. The academic exploration of the immunological perspective plays an important role in promoting the practice of dynamic risk identification, and the current dynamic risk alert system has less application of this model and supporting method. The reason mainly lies in the operability of the method and the lack of specific experimental guidance. In order to remedy this defect, this paper not only describes the mechanism and supporting methods of the biological immune extension model on dynamic risk identification in detail, but also uses the simulation platform to calculate and study the method.
This paper also has some enlightenment on the dynamic risk management of enterprises through the introduction of theoretical method and simulation analysis. In the context of new format, “Internet +”, organizations have high requirements on investment and technology demand, and are constrained by such factors as technology maturity, financing capability, network marketing capability, customer demand, Internet policy and technological development. There are great uncertainties in the future development and benefits of the enterprise, and the risks the enterprise faced are complex and changeable in the process of growth. And how to deal with the uncertain risks timely and effectively is becoming more and more important to the management of organization. While the traditional single risk identification method is difficult to meet the demands of organizational decision layer. The dynamic risk identification extension model based on artificial immune system is an innovation of the risk management method, which is necessary for the decision maker to promote and apply the method together with the theoretical researcher. On the one hand, decision makers should actively apply the method in the organization to effectively avoid the internal and external risks of organization. On the other hand, in the process of practicing the dynamic risk identification extension method on biological immunity, the organization need to actively participate in practical effect feedback, which is facilitate for the theoretical researchers to improve the model and algorithm.
The application of dynamic risk identification method on biological immune extension mechanism needs a further study and improvement, which mainly involves the effective docking of DRIBIEM with risk identification in organization, enterprise and engineering. The challenge faced in the application of DRI method in the biological immune perspective lie in the extraction, quantification, retrieval and optimization of risk characteristics, the construction of risk knowledge database, and the applicability of the DRIBIEM method in various fields. On the future we can do in-depth exploration from the following two aspects:
Systematically analyze the formation and evolution mechanism of the internal and external risks in the application field, construct the relevant risk index system and risk knowledge database, use DRIBIEM to establish a dynamic identification supporting system, and then empirical test the validity of DRIBIEM. Explore the process of different fields of risk identification, so as to further deepen and extend the algorithm research of DRIBIEM and further enhance the applicability of the model.
Footnotes
Acknowledgments
This work was financially supported by the National Natural Science Foundation project (71640022, 71561010), the Jiangxi Province Social Science “Twelfth Five Year Plan” project(15TQ04).