
Abstract
The current e-business information retrieval system ignores the threat of distributed denial of service attack from computer network, which results in low retrieval recall, accuracy, and efficiency. For this problem, a design method of fuzzy retrieval system for e-business information based on block chain technology is proposed in this paper. A fuzzy retrieval system of e-business information is designed, which includes three layers of client, application server and data server. The construction rules of the rule library used by the system are researched. The keyword expansion method of association word list, compound word list and synonymous word list is given. The dynamic knowledge base of the system is built and updated in real-time. Security control of e-business information documents in the system is implemented by using anti-attack performance of block chain technology. Experimental results show that the proposed method improves the recall, accuracy and average accuracy of the system and the retrieval efficiency is high.
Introduction
According to statistics, the number of information on the World Wide Web will increase two times every few months. The proportion of the Internet in people’s work, study, daily life and leisure activities is bigger and bigger. At present, the Internet commercialization has been rapidly improved, and the growth of e-business applications is far more than the other types of network applications. How to effectively find the required information for users from the massive information is crucial for the effective use of network information technology [1].
Internet network information has its own characteristics of openness, distribution and isomerism. This not only leads to the rapid expansion of Internet information resources, but also makes the information on the network without regular indexing mechanism and hierarchical directory structure. Different Web information is stored randomly on different Web servers, thus lacking a unified management and organization. It is hard to find the information in such a huge network of network data. In order to help users to search, reduce the search time, and improve the accuracy of the data, a large number of search engine systems are introduced [2].
However, search engine technology is facing great challenges, such as poor understanding, useless information in the search results, and low search accuracy, which introduces great obstacle to the obtainment of network information. Therefore, it is of great academic significance and wide application background to research the new generation of intelligent information retrieval system by using the traditional information retrieval technology in combination with computer networks and data mining [3].
In the literature [4], a design method of fuzzy retrieval system for e-business information based on matrix decomposition is proposed. Based on the OpenRDF Sesame framework, distributed hierarchical storage architecture is used to implement the storage structure of the attribute table for the storage of semantic data. On this basis, for the problem that the Boolean matrix decomposition algorithm is slow to construct the attribute table for large scale semantic data, based on Spark distributed computing framework, a parallel frequent itemset mining algorithm is proposed to solve large-scale matrix decomposition and accelerate the construction process of attribute table. Furthermore, the retrieval optimization based on Hash conversion is added to the retrieval layer. In the literature [5], a vertical retrieval system for e-business information is designed and developed based on the Website simple ontology library. According to the navigation directory of the Website, the ontology library of the e-business information network is built. Based on the Lucene engine, a technical framework is constructed to segment the objects and the content of the Web pages in the ontology library. The ontology object index library and Web index library are built. The front end is extended in the ontology object index library after segmentation of the content retrieval. The correlation of the extended results is calculated by TF-IDF correlation algorithm, and then sorted. This value is taken as the weight of the extended ontology objects and the weights are assigned to the objects extended with the Jena second semantic analysis technology. Finally, all the key words with the weight are retrieved in the Web index library. The correlation is calculated and sorted. In the literature [6], a design method of e-business information retrieval system based on improved chaotic particle swarm optimization algorithm. The failure mode of e-business information system is divided into single limit state and multi-limit state. The failure probability of e-business information system under two states is calculated. Combining chaos optimization with particle swarm optimization, the obtained robust function is obtained to dynamically search the robustness of e-business information system. Global optimal solution of robust optimization design for e-business information system is obtained. In the literature [7], an open source based e-business information search system is designed. Combining the field of e-business and its characteristics, the index and search method modules of the original search engine framework are modified. E-business information is segmented by designing a dictionary based two-way maximum matching model and integrated into the participle module of the Nutch search engine framework. Then a vertical search system for e-business information is constructed. In the literature [8], an electronic commerce information retrieval system based on reordering fusion is proposed. The pseudo correlation feedback technology is used to extend the content of user retrieval, and the retrieval result is taken as the first ordered result. The initial ordered result is reordered by using the user’s generated social information features. The reordered results are fused by using the sequential learning method.
With the development of network information, the information of electronic documents presents an explosive growth trend. The security problem of secret electronic documents has become an increasingly prominent problem. The secret electronic documents may involve the secrecy of the state, the army and the institutions and the business secrets of the enterprise. In order to cope with various security threats, various security networks have been constructed by the party, government, military and enterprise departments to prevent document leaks. Defense means include firewall, VPN, anti-virus, human intrusion detection, waterproofing wall, intranet control, and trusted computing. It can effectively control the security of secret electronic documents to a certain extent. However, these existing technologies have apparent changes in facing unknown threats. The above method does not guarantee the security of confidential documents. In the high level security network environment of physical isolation, the encrypted e-business information document also has the risk of being stolen. To address this problem, a design method of fuzzy retrieval system for e-business information based on block chain technology is proposed in this paper. The research structure of this paper is as follows.
A fuzzy retrieval system of e-business information is designed, which includes three layers of client, application server, and data server.
An extension method of e-business information keywords of association word, compound word, and synonymous word is given.
The superiority of the proposed method is proved by the experimental test and the analysis of the results.
Conclusions and the further research in the future.
Material and Methods
The overall design of the fuzzy retrieval system for electronic commerce information
In the intelligent fuzzy extension search system, fuzzy retrieval is achieved based on keyword expansion. The system uses the three layer structure: client, application server and data server. Client is responsible for the interaction between the user and the system. Application server mainly consists of four modules of retrieval extension, searcher, result processor and document processor, which implements retrieval expansion, information retrieval, retrieval result processing, and information processing, respectively. Data server includes two parts of the knowledge base and the document collection, which store the dynamic knowledge base and the retrievable document information set, respectively.
The framework structure of the proposed system is shown in Fig. 1. It includes three modules of retrieval statement processing module, information retrieval processing module, and post processing module.
Framework structure of fuzzy retrieval system for e-business information.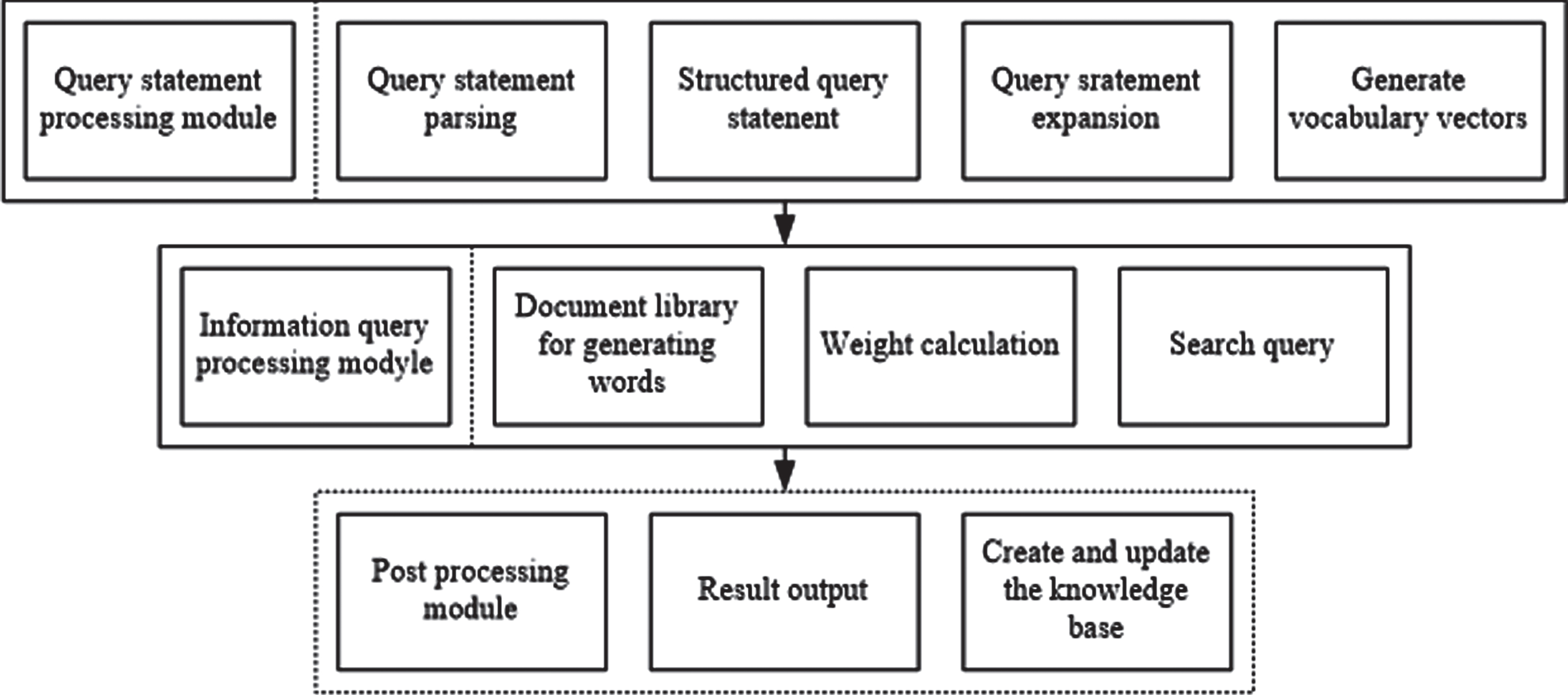
As the system is retrieved according to the keyword extension fuzzy algorithm, the retrieval conditions for the user input should be processed. First, the retrieval sentence is analyzed, and then the retrieval sentence structure is structured after analyzing the result. The retrieval sentence is extended and the keywords are recombined to form the new keyword group, and finally the corresponding word vector is generated. The steps of retrieval statement processing are as follows.
In our language, word is the smallest meaningful unit of language that can be a single sentence. It is also the most basic operating unit and information carrier in the retrieval system. Chinese word segmentation refers to the process of dividing a sequence of Chinese characters into one or more sequences of words automatically identified by a computer. In English, the distinction between words uses a space as a separator. In Chinese, there are obvious delimiters to delimit words, sentences and segments, but there is no clear demarcation for words. The key to the understanding of the natural language is to determine the words in Chinese. The current word segmentation methods mainly include statistical-based segmentation, understanding-based participle, and string matching based participle method. It is also divided into two methods of only segmentation and combination of segmentation and labeling. Because the current method is mainly for the basic method of open knowledge domain, while recognizing general knowledge, it also needs that the retrieval sentence processing module can recognize knowledge words in professional field.
Retrieval statement structuration
In the difference of retrieval statement, there is a difference in the influence of each word obtained with the segmentation of a sentence. Not all words can understand the meaning of the retrieval sentence. Retrieval statement structuration can not only eliminate the unimportant words that produce noise in natural language processing to improve the accuracy of retrieval results, but also reduce the complexity of operation and improve the efficiency of system retrieval.
Retrieval statement extension
Retrieval statement extension includes the two problems of selecting additional search phrase and correcting search statement and weight. The similarity between phrases in a fuzzy thesaurus is a measure of the choice of additional search phrase. The extended phrase vector is added to the retrieval vector, which can be well processing for the correction of the retrieval sentence and theweight.
After the three above steps of operation on the input retrieval conditions, all the keywords for computing are obtained. These keywords are called as keyword group. The vector of keyword group is expressedas
Assume tf ie (1 ≤ i ≤ l) is the number of appearance of e-business information vocabulary d i in the retrieval condition. If a i is equal to tf ie , it indicates that the retrieval condition contains d i .
Information retrieval processing module contains two processes of file information and retrieval information. The working flow is as follows. First, retrieval conditions are input by the user, and then the retrieval extender search the keywords from the knowledge base to obtain the terms in accordance with the conditions. The results are returned to the user for selection. After receiving the filtered results, the knowledge base retriever retrieves the information from the document set and returns the information to the user. Finally, the knowledge base is optimized according to the results.
Generating the document matrix of the word
Considering that the retrieval conditions of user input are less and the key words are less, it will inevitably reduce the accuracy of semantic computing. To address this problem, all documents are divided into two categories: document with no keywords and document with keywords. The calculation is given by
Equations (2 and 3) are the high order matrix. Considering the large number of retrieved documents and more words in the text, each text does not necessarily contain the same m words and each word does not appear in all texts at the same time. So A TAD and ATAD(K) must be sparse matrices. As the presence of the noise, the correlation processing of A TAD and ATAD(K) is implemented.
As the presence of interference information in the documents, the singular value decomposition method is used to reduce the dimension of the matrix. In this way, the dimension of the word and text space is reduced, the semantic structure space is simplified, and the interference of the semantic noise is suppressed.
For the fuzzy retrieval system of electronic commerce information, the following retrieval method is planned to be realized.
Exact retrieval of non-content field
A non-content field refers to other fields other than the content of the file, such as file name, author, and release time. When the user is able to know exactly the content to be retrieved, such as searching the file of summary record of e-commerce information in 2016, the search field filename and the keyword 2016 summary record can be filled in in the search interface, and the item of exact retrieval can be selected to improve retrieval efficiency and accuracy of retrieval results.
Fuzzy retrieval of non-content field
When the user cannot determine the non-content field of the file to be retrieved, fuzzy retrieval can be used. For example, only the word “record” in the file name is remembered, then you can fill in the search field in the retrieval interface for the file name, search keyword “record”, and choose “fuzzy retrieval”, then the files with the name containing the word “record” are searched. The user selects the required file from the retrieval results. This retrieval is suitable for failing to remember exactly the value of certain attribute of a document, and may find some useless results, but it can improve the retrieval probability compared with the exact retrieval.
Fuzzy retrieval of content field
In some cases, the user does not know the name, the release time, the author, and of the file to be retrieved, just hoping to find a document related to certain content. For this case, fuzzy retrieval of the content fields of the file is carried out. The storage type of the content field in the database is text, and the file retrieval is based on the full-text retrieval technology. The full-text index will be set up in the file information table. The primary keyword ID of the table will be used as the unique index key of the table, and the column of file content (text type) will be selected as the column of full-text index, so as to achieve fuzzy retrieval of file content [9].
Because in the retrieval system, all knowledge documents already exists, before the initialization of system, the correlations between all documents are calculated and saved in the data table of knowledge base, users only need to read the relevant data in the database, and not re-calculate every time.
The segmentation of all documents after weight calculation is denoted as the matrix A
TAD
. Assume there are m′ documents, n′ words, then the size of A
TAD
is m′ × n′. After singular value decomposition, the new m′ × n′ matrix is obtained as ALL
TAD
. The correlation between documents is expressed as
The correlation of the document i and the document j is the value of the i th row and the j th column. The retrieval system only needs to feed back to the document that the document distance is greater than the threshold value according to the defined threshold and the calculation result of ALL TAD × ALL TAD is saved in the knowledge datasheet. The data of the data table will be updated with the update of the knowledge base, so when the user retrieves, the system does not need to recalculate, which greatly improves the speed of retrieval.
The retrieval module first retrieves all the text satisfied the conditions. Through the union and sorting operations, the final result of the text is obtained. Secondly, the summary of the text is written in the feedbacked web page. Finally, after all the retrieval keywords are traversed through the index library, the pages are sorted according to the correlation. Each page is based on the importance of a keyword to the content of a web page and a weight is set for it.
The correlation between the users’ retrieval string and web page is obtained by adding the weights of the retrieval string contained in the web page. The greater the value, the better the order of the web.
After the retrieval sentence and the information retrieval processing module, the word vector is used to express the user input information. The document matrices A TAD and ATAD(K) are obtained. The method of keyword expansion is used to calculate the similarity between documents, document and word, and words. According to the similarity, not only the information documents related to the user’s needs is found out, but also the knowledge base is dynamically built and updated. So the function of intelligent fuzzy retrieval is achieved.
Construction of dynamic knowledge base
The knowledge base is mainly composed of three parts: dictionary, rule base, and corpus. In the proposed system, the dictionary part uses existing Chinese word segmentation dictionary. The conclusion tables constructed by the rule base are the associated thesaurus, the compound thesaurus, and the synonymousthesaurus in the database, respectively. Corpus is a corpus based on large-scale real text. With the use of search system, people constantly increase search keywords and update them to corpus. After a certain time, the sentences in corpus are re-analyzed according to the construction rule of rule base, and the results are added to the above three tables.
The knowledge base contains the relationship information between knowledge. The construction of the dynamic knowledge base mainly includes two parts: the extraction of the retrieval extension words and the determination of the correlation between the extension words.
Update of dynamic knowledge base
Update of dynamic knowledge base is achieved by using the dynamic optimization of users’ feedback information. No experts often have to participate in manual update during the dynamic optimization of the knowledge base. In the retrieval process, when the user submits the search term, the search word will be extended through the retrieval expander, and dynamic knowledge base is updated and adjusted according to the feedback of extended information operation. After long term use, the system can learn and accumulate a certain amount of user knowledge and experience, so that the organization and content of dynamic knowledge base will be optimized continuously [10].
E-business information fuzzy retrieval system based on extensible key word
The working principle of e-business information fuzzy retrieval system based on extensible key word is as follows.
Receive the user’s request in a natural language, and then effectively understand the user’s request through the technologies of Chinese word segmentation and syntactic analysis.
According to the key word string obtained by segmentation, the key words are extended with the keyword list, associated thesaurus list, compound thesaurus list, and synonymous thesaurus list in the knowledge base to generate new keyword group, which is feedbacked to the user. The user selects the appropriate key words to extend the initial retrieval. Then the extended information selected by the user is sent to the system, and the system optimizes the knowledge base according to the information of the user’s feedback.
On the one hand, the system retrieves according to the revised retrieval and returns the results to users. On the other hand, it continues to process the retrieval results, and extracts relevant concepts to supplement and update the related knowledge tables of the knowledge base. The knowledge tables constructed by the rule base of the knowledge base are the relevance thesaurus, the compound thesaurus, and the synonymous thesaurus.
The retrieval system sorts the results returned by the index library, and then presented the final result to the user [11]. The workflow is shown in Fig. 2.
Workflow of e-business information fuzzy retrieval system based on extensible key word.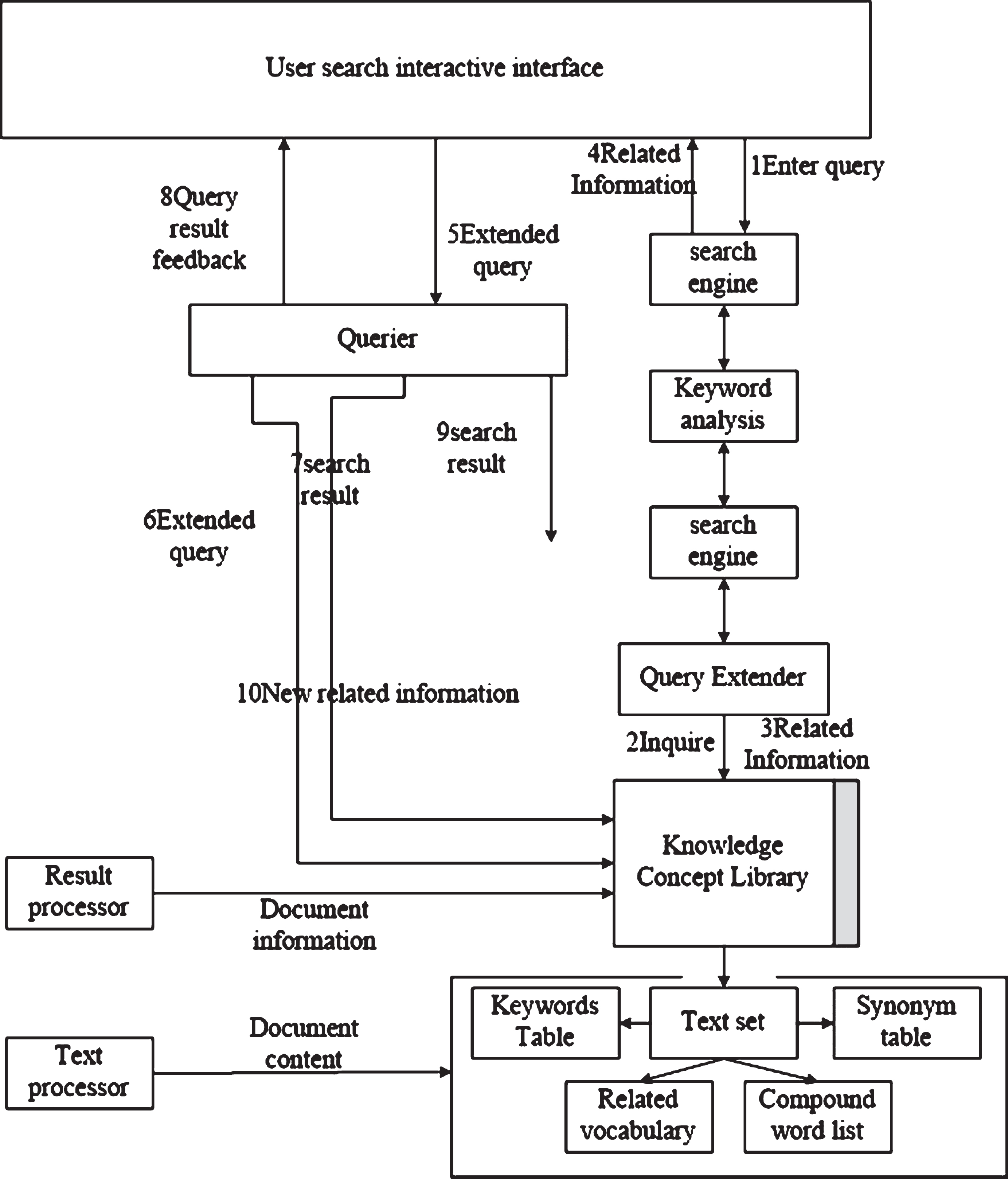
Retrieval expansion method has long been applied to text information retrieval system. Its main purpose is to solve the problem that users cannot accurately express key words in retrieval. There is no literature related to the extension methods of relevance, compound and synonymous keywords. Therefore, based on the retrieval sentence, the following three ways is researched to solve the above keywords[12, 13].
In this system, e-business information is divided into multiple classes, each of which contains different subclasses, and each subclass contains different subclasses. The semantic similarity of the semantic coding C1 and C2 of e-business information is calculated by using
For the analysis of compound key word, the calculation of the coupling probability between the compound words is realized by using the EM algorithm. Assume compound word lexicon is composed of the word strings of b
i
and d
i
, that is, κ ={ (b
i
, d
i
), (b2, d2), ⋯, (b
t
, d
t
)}. The coupling probability of the combination of W
b
and W
d
is expressed as
According to the above calculation results, the compound words with coupling probability higher than the preset threshold are extracted, and the extracted compound words are added to the compound word list. The retrieval efficiency of the high search engine can reduce the granularity of the search term, and greatly improve the search efficiency of the search engine.
First, the weight value of e-business information standardization is sorted. Then, the expansion threshold is set according to the information input by users and the weight value is filtered. Finally, the index item of the extended phrase in the retrieval vector is finally determined.
Design of deployment and technical architecture of e-business information fuzzy retrieval system based on block chain technology
The secret document protection scheme based on block chain technology is generally constructed with private chain technology. A private chain is a block chain that has a certain centralization control. Private chains can create more stringent systems for permissions control. Modification even read permission can be limited to a small number of users in the internal network. A control node can be CA center, key center, privilege management, and approval node. It is the special control of the document permissions at the cost of sacrificing part of the centralization. Therefore, it is possible to adopt simpler, more efficient, flexible and low-cost consensus mechanism than the public chain. Because the limited decentralization is easier to reach consensus, it is only in the special case that documents need to be identified, arbitrated, and degenerated.
The system deployment is shown in Fig. 3. The server includes the CA center, the key center, the authority management, the approval node, and document server and document database. The client installs the document client to realize the creation, encryption and decryption of the e-business information document, and the authority management. Deployment is flexible and can be combined with OA to deploy to the cloud or Intranet [14].
System deployment structure.
The technical architecture of e-business information fuzzy retrieval system with anti-attack performance is shown in Fig. 4. It is divided into the system support layer, the document service layer, and the application layer. The system support layer includes block chain technology (chain document, intelligent contract, and consensus mechanism), OFD technology, cryptographic service infrastructure (cryptographic hardware, PKI system, key management, etc.). The document service layer includes electronic document creation, electronic document browsing, electronic document encryption and decryption, electronic document retrieval, electronic document conversion, and electronic document transmission. Application layer include electronic document management, unified user management, and unified authority management.
Technical architecture of e-business information fuzzy retrieval system.
The secret electronic document system optimizes the process and improves efficiency through consensus technology. Rationality, compliance, and classification of the documents are automatically recognized and automatic identification and filtering of document access instructions are implemented through intelligent contract technology. The related data of the document is shared by account book sharing technology among the participants of document owner, the administrator, the reader, and the regulatory audit institution. Document confidentiality protection and access control are achieved by encryption and identity authentication. Finally the cooperation automation of electronic documents and the full protection of the confidential electronic documents with different business strategies are realized [14–17].
Test environment
Software and hardware configuration of test environment
Software and hardware configuration of test environment
Creation of e-business information metadata.
Required storage space and time average for the creation of e-business information metadata
Required storage space and time average for the creation of e-business information metadata
Creation of index and e-business information semantic relation library.
The creation of the index needs to scan the entire metadata set to extract the keyword set and create an inverted index with the correlation value. Figure 5 shows that the time cost of index creation is basically linear with the size of the metadata set.
Relationship of time cost of index creation and metadata set size.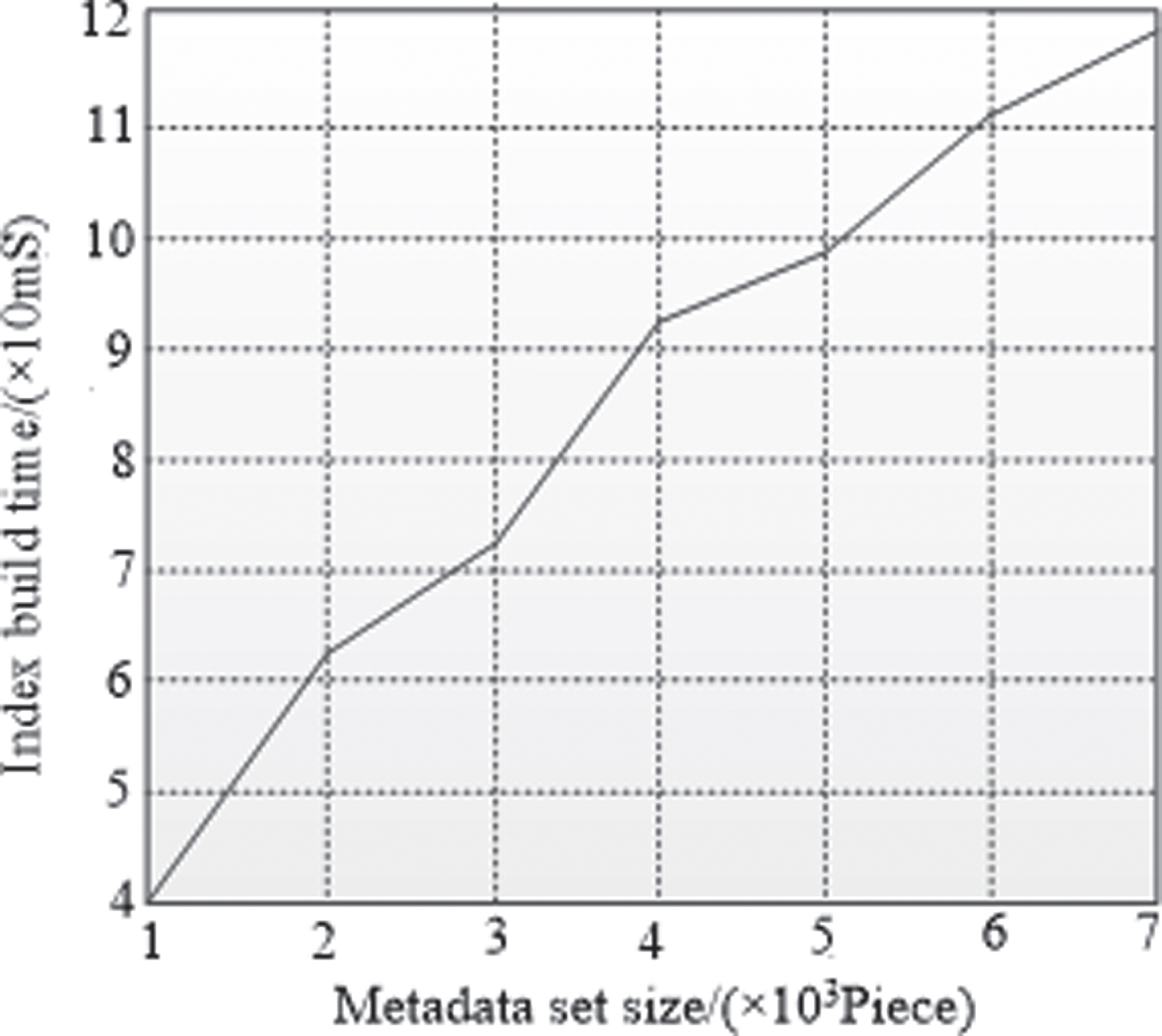
Figure 6 shows that the time cost of index creation is basically proportional to the number of documents in the e-business information document set.
Relationship of time cost of index creation and number of documents.
The retrieval process mainly includes retrieval extension, index retrieval, calculation of comprehensive correlation values, and return to the previous L result document. Compared with the previous sort retrieval, the keyword extension and the time cost of calculating the comprehensive correlation according to the retrieval result of the keyword set are introduced. Therefore, the number of extended keywords is one of the factors of retrieval efficiency. The test result of the 1000 document is shown in Fig. 6. It can be seen that the retrieval time is basically proportional to the number of extended keywords, and the retrieval time increases with the increase of the scale of the extended keyword set.
To evaluate the system retrieval performance, statistics of average retrieval time on 1000 to 7000 document sets is carried out. The test result is shown in Fig. 7. The retrieval time is proportional to the size of the document.
System retrieval performance.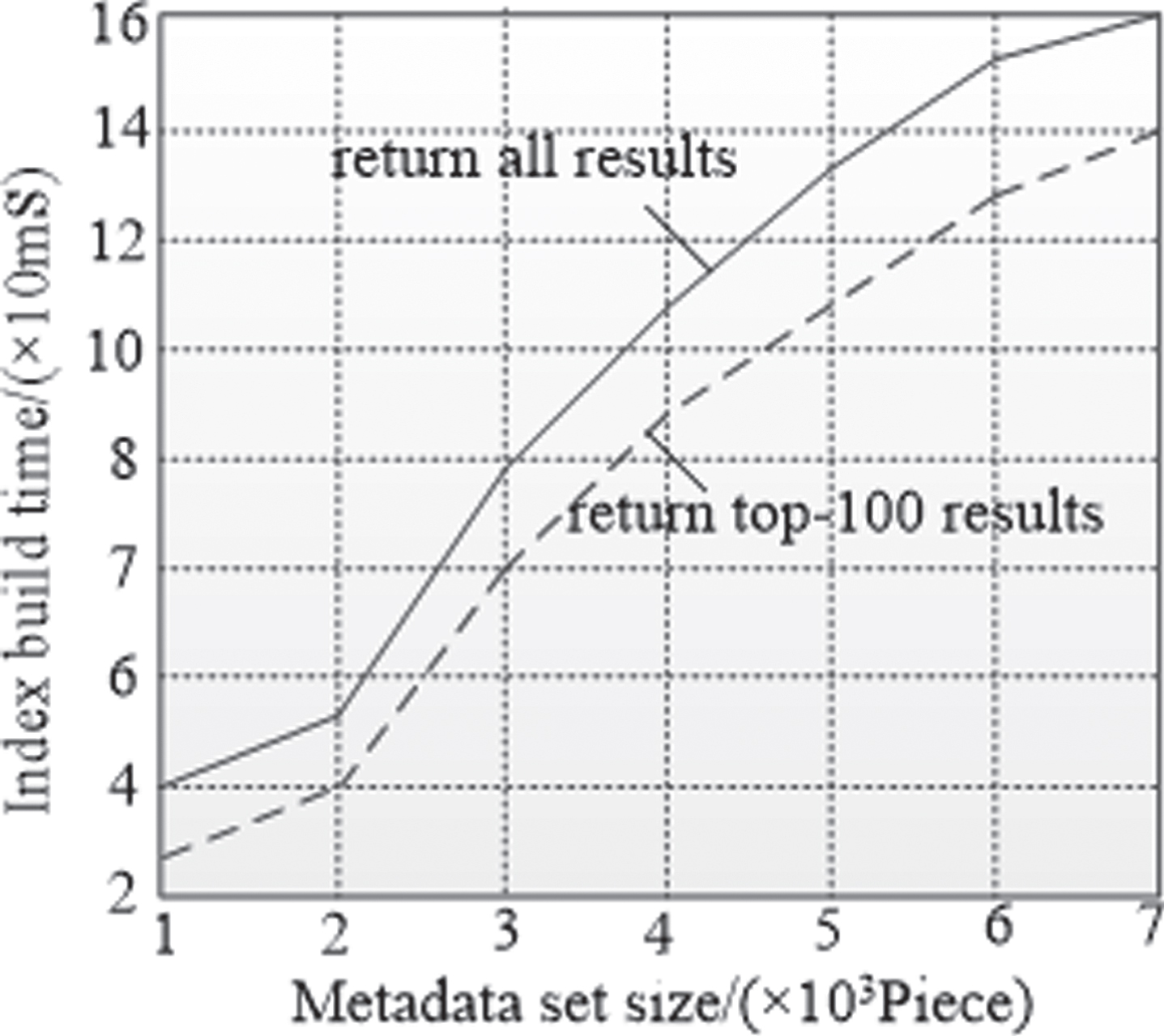
From the analysis of the results, the retrieval efficiency can be effectively improved by sorting and returning the number of documents required by the user.
System anti-attack performance test.
The effectiveness and practical application value of the method is generally measured by the recall ratio and the precision ratio. The recall ratio is mainly a measure of the number of documents correctly classified in a specific document category, and the ratio of the number of documents that belong to the category in all document libraries. The precision ratio is the ratio between the number of documents correctly classified in a text category and the total number of documents in this category (automatic classification). If the recall ratio is higher, the precision ratio will be affected. If the precision ratio is higher, the recall ratio will decrease, especially when the retrieval system is attacked. For a particular classification algorithm, the recall ratio and the precision ratio should be trade-off.
The recall ratio R is given by
The precision ratio P is given by
Comparison of test results
From Table 3, it can be seen that, the recall ratio and the precision ratio of the proposed method is highest. The literature [4] method and the literature [6] method are the second, and the literature [5] method is lowest. But it can also reach an average of more than 80%. The result of this experiment is more accurate than the classification results in the literature. The main reason is that the feature extraction method is not the same. The test results are not very good for 6000 and 7000 documents. The false detection ratio is also higher with the literature [4] method and the literature [5] method. The main reason is that these two kinds of e-business information feature words have high repetition rate, and there is little difference between the categories. It can be seen that the accuracy of the retrieval is not only influenced by the retrieval method, but also has a great relationship with the document characteristics of the corpus. The proposed method can effectively classify electronic commerce information documents, and the recall ratio and the precision ratio are very high.
Average precision ratio test.
The average precision ratio is introduced to measure the effective performance of different methods. The average precision ratio is denoted as average and given by
From Fig. 8, it can be seen that, the proposed method can effectively retrieve e-business information and has strong anti-attack performance. Compared with the literature [7] method, the average precision ratio of the proposed method is higher. This is due to the characteristics of chain structure, tamper-resistance, intelligent contract, consensus mechanism, asymmetric encryption, and data security storage of block chain technology, which realizes the security control and retrieval ofconfidential e-business information documents under the private chain.
Average precision ratio of the retrieval results with DDoS attack of two methods.
The emergence of block chain technology improves the possibility of protecting digital assets and the security of access to confidential electronic documents. The characteristics of block chain, such as tampering, centralization, distributed, open and transparent, are applied to the field of e-business information document protection, which will greatly reduce the occurrence of the leakage of e-business information documents. On the basis of the existing search engine retrieval technology, a design method of fuzzy retrieval system for e-business information based on block chain technology is proposed in this paper. The three stages of the process and the working principle of e-business information processing are given. Through the research on the keyword extended fuzzy query, the method of keyword expansion is proposed. This method extends relevance keyword, compound keyword, synonyms keyword, respectively. The system has strong anti-attack performance by using block chain technology.
The proposed method achieves the expected design requirements, which can meet the basic needs of file management and retrieval, but there is still further improvement.
The user experience can be further improved. For example, while the system display the data from historical retrieval to the user, the retrieval operation in all the data can be carried out directly in the background. After the retrieval, the AJAX technology can be used to display the new retrieval results to the user in a local update way with no user manual operation.
For a file retrieval system, efficiency is one of the most important indexes. As time goes on, there will be more and more files in the library. The amount of access will be increased and the performance of the database system will be reduced. It must be constantly adjusted and optimized to make it better for the actual work.
Footnotes
Acknowledgments
2017 Ktion plan of Tibet Autonomous Region.
Key technology research and design of e-commerce application platform based on block chain(XZ201703-GC-09).