
Abstract
We propose a fuzzy Reinforcement learning (FRL) framework for an efficient solution to the Economic thermal power dispatch (ETPD) considering multiple fuel options along with valve point loading effect concerning with thermal power generating units. The objective of ETPD is optimizing operating cost for specified power demand meet and to satisfy the generation capacity limits of each unit. In the presented work, We cast the ETPD as a multi agent FRL (MAFRL) problem wherein individual thermal generators act as players for minimizing operational cost and also satisfying the generation limits of each units to obtain a specified power demand. To prove supremacy and validity of proposed multi agent fuzzy reinforcement learning technique, two benchmark test systems involving 10 and 40 units integrated using numerous fuel systems with valve point loading effect have been simulated. Simulation results and comparison against several other existing solution approaches showcases the efficacy of MAFRL technique in solving the ETPD problem.
Keywords
Introduction
Economic thermal power dispatch (ETPD) refers to a constrained load optimization and energy management task for power scheduling operation and control. Main objective of solving ETPD have to find best possible arrangement for power generation among the units for minimizing total operating cost of fuels and thereby satisfying various constraints of equality and inequality; power balance, transmission loss and power demand constraints. ETPD problem shows highly non-linear characteristics because of modern power generating units are operated with multiple fuel systems. Therefore, ETPD is consider as non-continuous, non-convex and non-differentiable optimization task for finding the optimal powerdispatch trough each generating unit.
In the last two decade, researchers have implemented several conventional, meta heuristic and hybrid techniques for finding solution of ETPD incorporating valve point effect combining with numerous fuel options e.g., gradient technique [1], dynamic programming (DP) [2], linear programming [3], quadratic programming [4], Lagrange relaxation (LR)[5], hybrid GA (HGA) [6], real coded GA (RCGA) [7], advanced real coded GA (ARCGA) [8], evolutionary programming (EP) [9], ant colony optimization (ACO) [10], biogeography based optimization (BBO) [11], differential evolution (DE) [12], differential evolution integrated biogeography based optimizer (DEBBO) [13], bacteria foraging optimization (BFO) [14], modified BFO [15], group search optimization (GSO) [16], differential evolution based PSO (DEPSO) [8],craziness based PSO (CRPSO) [17], seeker based optimization (SOA) [18], Taguchi algorithm (TSA) [19], krill herd algorithm (KHA) [20], Grey wolf optimization algorithm (GWO) [21], cuckoo search algorithm (CSA) [22], one rank cuckoo search algorithm (ORCSA) [23], improved GA (IGA) [24], enhanced augmented Lagrange Hopefield network [25], crisscross optimization (CSO) [26], dynamic search space strategy (DSSS) [27], and social spider method (SSM) [28].
This work is an effort to enclose a multi agent adaptation of fuzzy reinforcement learning framework [29] for an competent solution to the ETPD problem. In our view, it is a foremost effort at ETPD problem via the FRL. Here every player (generating unit) attempts to optimize its output based on an RL signal emanated by the system while satisfying several system constraints. In other words, We solve a constrained optimization task using FRL. Reinforcement learning is a paradigm which aims to optimize behavior of a single or several agents operating in an Markov decision process (MDP) [30] environment. The agents/players seek to find the most optimal policy based on a reinforcement learning signal emitted by the environment. This RL signal is a heuristic signal signifying the profitability or otherwise of an action taken by an agent. Thus, RL concerns optimization of a sequential decision making problem.
In [30], FRL has been used to generate approximate optimal controllers for non-linear systems/plants. In this work, we extend FRL to a multi generator optimization scenario. Recently we have implemented FRL to solve complex constrained thermal unit commitment problem in [31]. Our attempt here is to look at ETPD as a sequential decision making problem in a self learning framework. Here different generators learn to output correct power level by a trial and error mechanism. The aim of each generator is to output power so that total cost of generation to meet a given load is minimized. In an RL framework, this is achieved by minimization of a cumulative cost function called the Q function for each generator. Reinforcement learning basically rewards actions that lead to reduction in generation cost while discouraging higher cost actions.
Rest of the manuscript is planned as follows: in Section 2, we describe the formulation of ETPD problem, in Section 3 fuzzy reinforcement learning approach is briefly described, Section 4 explains implementation details of MAFRL approach as applied to the ETPD problem, in Section 5 experimental consequences and evaluation with various contemporary approaches are specified and Section 6 concludes the paper.
Mathematical modeling of economic thermal power dispatch problem
Aim of ETPD solution is to minimize cost of fuel for each unit while meeting power balance constraints and total load demand.
Fuel cost function
The fuel cost function for solving ETPD is given in form of a quadratic expression as:
where a j , b j and c j represents fuel cost coefficients for j th generating. unit, F total represents summation of fuel cost, U p j is power meet due to j th generating. unit, F j (U p j ) represents function of fuel cost for j th unit, NG represents overall number of generating units.
Modern thermal power generating units have multiple fuel options (MFO) from several fuel sources. Each power generating unit may have different fuel cost with numerous fuel options. Here choice of fuel depends on load demand and power generation availability. Here objective is to search for an appropriate fuel option for each unit so that total operating cost will have minimum value while fulfilling equality constraints due to load balance and inequality constraints due to generating capacity. More realistic and accurate ETPD solutions can be obtained by incorporating MFO with VPE and mathematically represented as:
where aj,h,bj,h,cj,h,eg,h and fj,h are representing fuel cost coefficients of h th fuel system for j th generating units.
We formulate MFO in a manner different from earlier ones [32], where selection of fuel options are predefined at different power levels as:
where U1, U2, …,Uh-1 are several predefined levels of power for selecting fuel options, and Up
j
,max represents maximum power generation limit for j
th
sunit. We formulate MFO in a more practical manner so that selection of fuel options for generating units could be free from any predefined levels of power. For accurate results, we compare fuel cost of each unit for all fuel options available. For illustration, if power generated from unit 1 is U1 and available fuel options are of 3 types then F
total
is calculated as:
Unit capacity constraint
Each thermal power generating unit has to generate active power within boundary of its generating capacity. Mathematically:
Generating power from all units should be equivalent to sum of power demand plus the total transmission losses. Mathematically:
where P demand represent power demand P loss represents transmission loss given by Kron’s in [33] as:
where B p j g , Bp j 0, and B00 are the power loss coefficients.
Handling of power balance constraint is done by eliminating one variable like other equality constraint handling in optimization task. The eliminating variable is called as slack variable. Here total number of committed units is NG and out of which only NG - 1 variables/ committed units are controlled using MAFRL approach. The power of slack variable/generator is computed by rearranging the equality constraint as:
If the slack generator output U p NG violates its limit then external penalty is added in objective cost function to hold the violation as:
where ζ is penalty factor with large valve.
We look at ELD problem as a constrained optimization task in an RL setup. The RL procedure tries to get optimal power output of each generator while satisfying power balance and load demand constraints which minimizes the total fuel cost. First basic algorithm on which our research based is the Q learning.
Q learning
Q learning framework optimizes decision making in sequential assessment task modeled as Markov decision making process. Q learning involves repeated action generation at each stage and an evaluation of the action choice to figure out best possible action at each stage. We have implemented a multi agent adaptation of Q learning for solving ETPD.
In Q learning procedure each generating unit gives a particular power from within it constrains and the power generated by all generators must satisfy system constraints and total power demand. The power outputs of generators are represented by y k ∈ Y (k = 0, 1, 2…). The goal is to meet load demand while satisfying constraints. If the combined action of generators is satisfactory; all generators are rewarded or else they are penalized for making wrong choices. Thus, it is a learning problem to discover correct power outputs. We judge this using a Q value estimate Q (y k , a (y k )) where a (y k ) ∈ A (y k ) is the power output of the generators. These Q values are tuned incrementally in an online manner for identifying optimal power generation. Next, we digress briefly to describe the fuzzy Q learning approach.
Fuzzy Q Learning
Standard Q learning algorithm uses a look-up table for storing (state action) values or the Q (y k , a (y k )) values. However, as the state-space dimensionality increases, look up table based storing of values becomes computationally intractable. To overcome this hurdle; we can use function approximator to store Q values.
Function approximation could be carried out using neural networks or fuzzy inference systems. In this work, we have used fuzzy systems for implementing multi agent Q learning. At each instant, the state vector
where
The agent/generator has to select appropriate action corresponding to maximum q
g
value from amongst the m actions. Overall action or combined action of the generator is obtained as weighted average of generator actions under chosen each rule as:
u g being the optimal action in rule Rl g .
In RL, we need to explore for more profitable actions from the action set. This is achieved by following an exploration-exploitation policy (EEP) which selects random action from the set of available actions with a small probability. This EEP action is designated as ε - greedy and is obtained as
Next, we calculate state value as:
The generated action u (y
k
) is initial output of generating unit and corresponding signal “r” is generated. By using this signal we obtained a temporal difference (TD) and using TD updated output of each generating unit is calculated as per the following:
here 0 ≤ γ < 1 refers to discount factor; basically discount factor relates updated cost to present cost and η (learning-rate factor) is used to blend old estimates with new ones.
We attempt a multi agent FRL framework for solving ETPD problem. First point is to place fuzzy sets above each units power limits and partitioning within their operating range. We impose Gaussian membership functions through the universe of discourse. For example, if the power limit of a unit is [Up
j
,min, Up
j
,max], We fix 3 fuzzy sets having centers on
In MAFRL, we organized all rules Rl g : in the succeeding form:
If j1 is
where
Thus at each state g
k
, we obtain an optimal action vector
Takagi Sugano FIS rule aggregator is used to create simplified optimal power for each unit as:
Where
where
Optimal EEP power is specified by:
Global Q g p power equivalent to each unit g p is specified by:
Generating unit produces a power vector gk+1 for corresponding optimal action as per (18). Next, we calculate target value V g p (gk+1) (for stage k + 1), corresponding to each generator as:
Finally, overall global cost for generator outputs g k is calculated’ as:
where λ = Penalty factor(10000 $/MW, in our case).
Next, temporal difference (TD) is calculated for each unit as:
Finally updated q g for all unit’s is obtained as:
Therefore, we get updated q g for discovering optimal power of unit g k .
For evaluating the efficiency of proposed MAFRL, two standard test systems incorporating valve point effect along with multiple fuel systems have been solved. We simulate the MAFRL for ETPD problem solution using MATLAB 7.12.0 (R2011a) on 3.50 GHz INTEL Core-i5 processor. Comparison has been made with various other contemporary methods for the following test cases: 10-units generator system with multiple fuel system and valve point loading effect for a power demand of 2700 MW. 40-units generator system with multiple fuel system and valve point loading effect for a power demand of 10800 MW.
Flowchart for MAFRL technique for ETPD problem
Test case-1
In Test system 1, we consider a 10-unit generator system having multiple fuel selection options. Generator fuel coefficients have been taken from [34] and are provided in Table 1 and load demand is considered as 2700 MW. Table 2 shows type of fuel, optimal power scheduling and fuel cost by the proposed MAFRL technique and we find that our method is superior to other techniques. Proposed approach is able to satisfy all system constraints and provides feasible results. In Table 3, we show comparison of MAFRL with various optimization techniques listed in literature. The result obtained with MAFRL has least operational cost when compared to various techniques described in literature. A fuzzy set laid over the generating range of 10-generator system is shown in Fig. 2 and Convergence characteristics of MAFRL approach for a 10-generator system is presented in Fig. 3.
Fuel coefficients for 10-generator system with MFO and VPE
Fuel coefficients for 10-generator system with MFO and VPE
Best power generation for 10-generator system with power demand of 2700 MW
Comparison of numerical simulation using various techniques for 10-generator (power demand 2700 MW)
aActual generation cost calculated with given power.

MAFRL architecture for economic load dispatch problem.
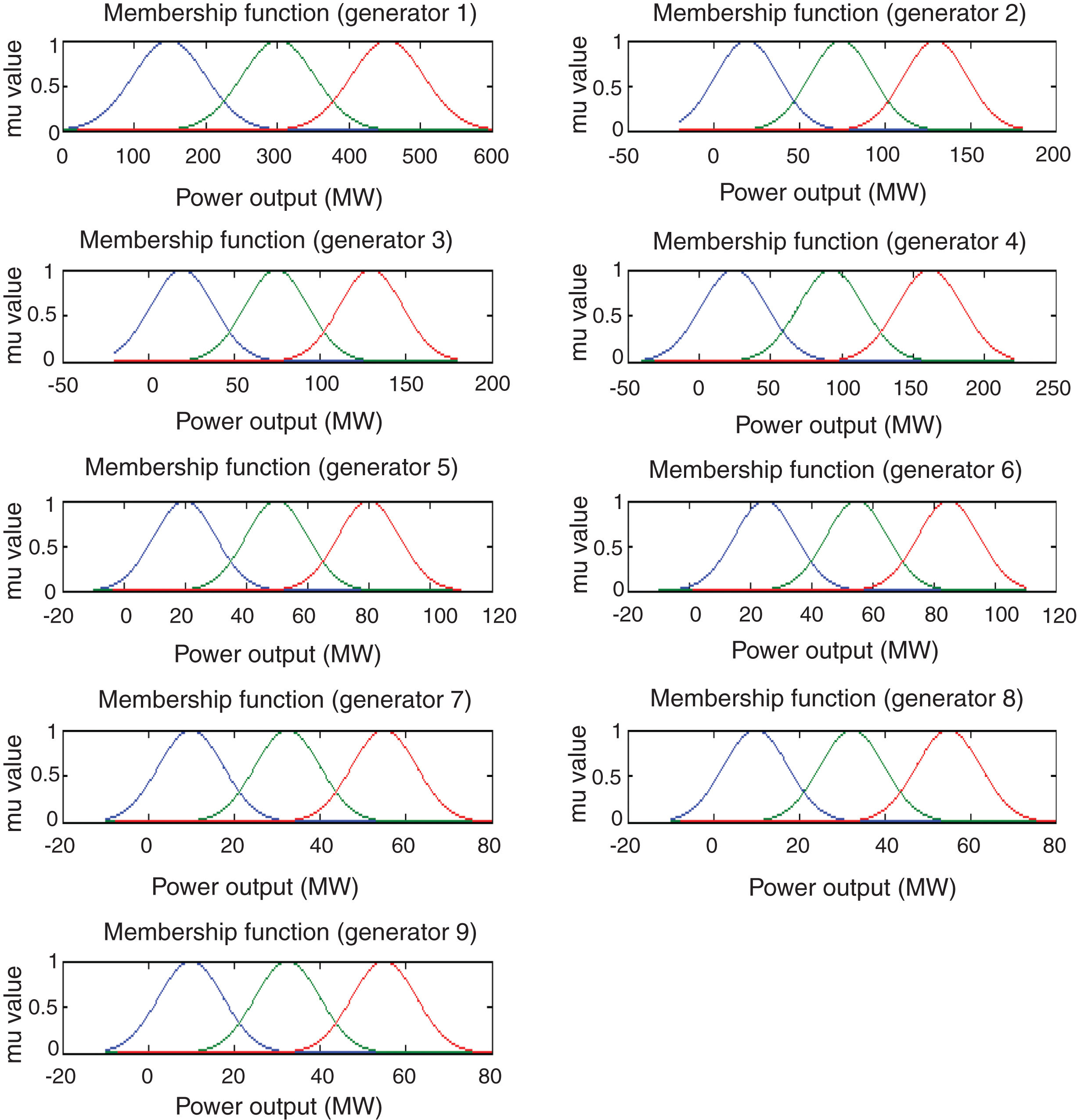
Fuzzy sets through power range of 10-generator system.

Convergence characteristics for 10-generator system.
In Test system 2, we consider a 40-unit generator having multiple fuel options. Load demand is taken as 10800 MW. Adding of number of units in the ETPD problem require powerful global search ability to discover optimal power output and to overcome problem of premature convergence. The best optimal power generation schedule, type of fuel and fuel cost calculated by the MAFRL technique is given in Table 4. Our proposed MAFRL has ability to fulfill equality and inequality constraints and provides feasible solution of this large power system of 40 units having multiple fuel systems. These results confirm that MAFRL is powerful in exploiting local optimum search. In Table 5 we compare MAFRL with various other techniques listed in literature wherein we see that MAFRL achieves least cost of production. A convergence characteristic of the MAFRL approach (40-generator system) is presented in Fig. 4.
Best power generation for 40-generator system with power demand of 10800 MW
Best power generation for 40-generator system with power demand of 10800 MW
Comparison of results of various methods for 40-generator system with power demand of 10800 MW
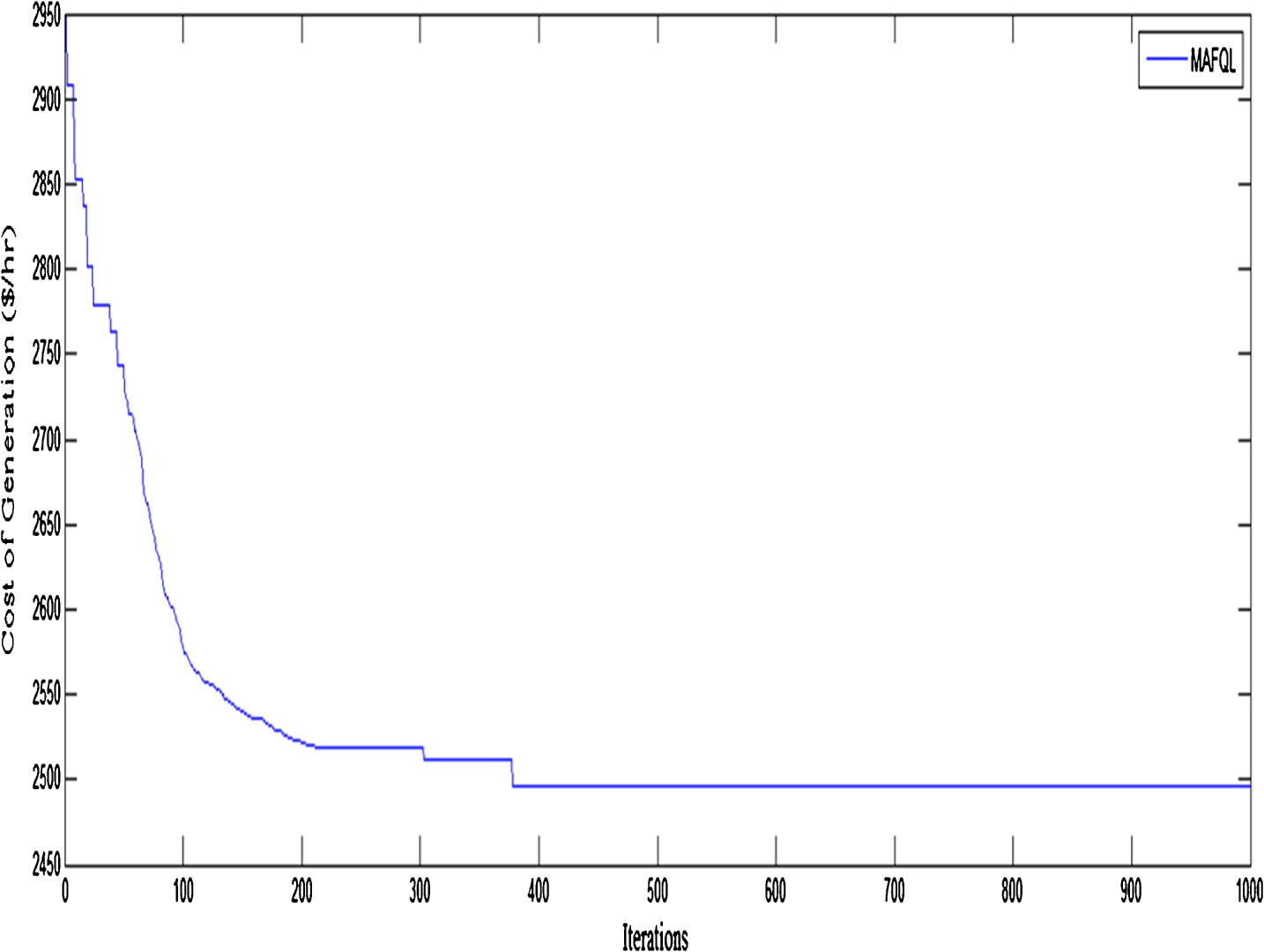
Convergence characteristics for 40-generator system with power demand of 10800 MW.
In this research, we applied a fuzzy reinforcement learning framework for solving economic thermal power dispatch. In this technique we analyze all thermal generating units as a participant in a reinforcement learning setup for optimizing optimal power task and to satisfy various operational constraints. To evaluate the efficiency of our Proposed MAFRL approach, we employed it on 10 and 40 generator test systems integrated with valve point effect and multiple fuel systems. Numerical simulations indicate accuracy of solution and mature convergence ability of the proposed MAFRL approach. Overall, MAFRL emerges as a superior and alternativesolution approach to solving economic thermal power dispatch problem.