
Abstract
Construction of robust regression learning models to fit training data corrupted by noise is an important and challenging research problem in machine learning. It is well-known that loss functions play an important role in reducing the effect of noise present in the input data. With the objective of obtaining a robust regression model, motivated by the link between the pinball loss and quantile regression, a novel squared pinball loss twin support vector machine for regression (SPTSVR) is proposed in this work. Further with the introduction of a regularization term, our proposed model solves a pair of strongly convex minimization problems having unique solutions by simple functional iterative method. Experiments were performed on synthetic datasets with different noise models and on real world datasets and those results were compared with support vector regression (SVR), least squares support vector regression (LS-SVR) and twin support vector regression (TSVR) methods. The comparative results clearly show that our proposed SPTSVR is an effective and a useful addition in the machine learning literature.
Introduction
Over the last years, support vector machines (SVMs) introduced by Vapnik [20] have emerged as one of the most powerful methods for solving classification and regression problems. They have been widely studied and successfully applied in various pattern recognition areas of research, such as image processing, bioinformatics, economics [2, 6]. Although SVMs are shown to be powerful machine learning tools, the training of SVMs lead to solving time consuming quadratic programming problems (QPPs). In fact, the training time complexity of SVM is O (m3) which makes SVM intractable once m becomes large where m is the size of the training set.
With the aim of reducing training cost, following the work on nonparallel SVM called Proximal SVM via Generalized Eigenvalues (GEPSVM) introduced in [10], twin SVM (TWSVM) for binary classification was proposed recently by Jayadeva et al. [4].
TWSVM seeks two nonparallel hyperplanes with the property that each one of them is as close as possible to inputs of one of the two classes and at the same time at least one unit distance away from the inputs of the other class. This method has attracted lot of interest in recent years and the interested reader is referred to [8, 17].
Prediction by regression is an important field of study in machine learning. With the introduction of ε- insensitive error loss function by Vapnik [20], SVM has been successfully extended to regression. Like SVM for classification, the training of support vector regression (SVR) solves a QPP with linear inequality constraints. In the sprit of TWSVM, Peng [15] developed twin support vector regression (TSVR) for function approximation and regression. TSVR generates a pair of ε- insensitive down-bound and up-bound functions such that (i) both the functions lie as close as possible to the training data; (ii) all the training data is required to lie above the down-bound function but below the up-bound function; (iii) for each training data, its distance from the down-bound function and similarly from the up-bound function should be at least ε. This strategy results in solving two smaller sized QPPs rather than solving a single QPP of large size as in the case of SVR [9, 20]. The advantage of this methodology is that the time complexity of TSVR becomes significantly smaller than SVR [15].
In many real world applications, observed data are very often subject to unknown noise distributions. It is well known that loss functions play a crucial role in reducing the effect of noise present in the training data. In fact, the generalization ability of a learning method is largely dependent on choosing the proper loss function that represents the characteristics of the noise present in the training data. The popularly used loss functions for regression are: quadratic, 1-norm and ε- insensitive functions, defined by: for x ∈ R, (i) L (x) = x2; (ii) L (x) = |x| and (iii) L (x) = max {|x| - ε, 0} respectively [9, 20]. Among them, the quadratic loss function is smooth and hence attractive but is less robust because it is sensitive to large errors. Unlike quadratic loss function, both the 1-norm and ε- insensitive loss functions reduce the sensitivity to noise and hence they are more robust for learning. However, they are not smooth which precludes the application of the well known numerical minimization methods.
Recently, with the aim of reducing the sensitivity to noise and further improving the stability to re-sampling, asymmetric pinball SVM classifier based on pinball loss has been proposed in [13]. As its extension to the squared pin ball loss SVM for classification, an asymmetric least squares SVM is studied in [14]. In this work, it is proposed to use asymmetric squared pinball loss for TSVR and study its effectiveness and applicability on few synthetic noisy datasets and also on few well known bench mark datasets. For recent work on pinball loss SVM, we refer the reader to [12, 19].
In this study, all vectors will be column vectors. For any vector
The rest of the paper is organized as follows. In the next section, the formulations of the standard SVR, LS-SVR and TSVR are briefed. In Section 3, we formulate our novel robust squared pinball loss TSVR in primal (SPTSVR) and solve by functional iterative method. Numerical experiments have been performed on synthetic datasets having different types of noise and on real world datasets whose results are compared with SVR, LS-SVR and TSVR in Section 4. The conclusion is drawn in Section 5.
Related work
In this section, we brief the formulations of support vector regression (SVR), least squares support vector regression (LS-SVR) and a popular variant of SVR known as twin support vector regression (TSVR) proposed by Peng [15].
Let a set {(
Support vector regression
For a training set given and correspondingly to obtaining a nonlinear regression function, it is desired that the training data will be mapped into a higher dimensional feature space via a nonlinear mapping φ (.) [9, 20] and a linear regressor will be constructed in the feature space in which the resulting regression function will made as flat as possible.
The standard SVR learning method determines the regression function f (.) by solving the following QPP [9, 20]
The solution of (2.1) can be obtained by solving its dual of the form
For the set of training examples given, the least squares support vector regression (LS-SVR) method solves a QPP based on quadratic loss function subject to equality constraints defined as
The dual of the above problem can be obtained leading to solving the following matrix equation
Using the solution of the above matrix equation, the nonlinear prediction functionf (.) is obtained
Twin support vector regression
Motivated by the study of twin support vector machines (TWSVM) for classification proposed by Jayadeva et al. [4], a new learning method for regression called twin support vector regression (TSVR) was developed by Peng in [15]. TSVR determines two nonparallel functions f1 (
In this section, we briefly state the TSVR problem formulation. For a detailed discussion on the problem formulation, the method of solving and its advantages, see [15].
Assume that the kernel generated ε-insensitive down- and up- bound regression functions are
Since the pair of constrained optimization problems (2.3) and (2.4) is equivalent to the following pair of unconstrained optimization problems
For a new test sample, its prediction value using TSVR will be obtained as the mean of its down- and up-bound regressors, i.e.
In this section, we propose a novel twin support vector regression algorithm using squared pinball loss function (SPTSVR) as an extension of pinball SVM for classification proposed in [13] with the purpose of reducing sensitivity to noise present in the training data. Our formulation leads to solving a pair of unconstrained minimization problems which we will solve by functional iterative method.
Consider the squared pinball loss function defined as: For the input parameter 0 ≤ p ≤ 1,
Clearly, L
p
(t) = p max {0, t } 2 + (1 - p) max {0, - t } 2 or equivalently
The graphical representation of squared pinball loss function for various values of p is shown in Fig. 1. It is clear from Fig. 1 that squared pinball loss function is an asymmetric function. Note that this function is more suitable for dealing with asymmetric noise [13]. Again, one can observe that (3.1) will become the symmetric quadratic loss function when p = 1/2. Illustration of squared pinball loss functions for different values of p.
Now we describe our proposed squared pinball TSVR (SPTSVR) learning method. Like TSVR, our SPTSVR method constructs a pair of nonparallel regressors of the form (2.2) by solving the pair of unconstrained minimizationproblems
Now, by taking the vectors
In this work, it is proposed to find the solutions of the problems (3.4) and (3.5) by obtaining their critical points using functional iterative method.
Consider the problem (3.4). Its critical point can be obtained by taking its gradient vector to zero. Let ∇L1 (
from which we get
Similarly, the critical point for the problem (3.5) will be determined by
Finally, like in TSVR, the predicted value for a test sample will be computed using (2.7) or more precisely
Remark. For simplicity, numerical experiments in the following section were performed by taking C1 = D1 and C2 = D2.
Now, we demonstrate the performance of SPTSVR in comparison with SVR, LS-SVR and TSVR. We implemented the algorithms in MATLAB R2008b running on a Microsoft Windows7 PC with Intel(R) Core (TM) i7-4790 CPU@(3.60 GHz) processor having 4GB of memory. SVR and TSVR were implemented using the MOSEK (http://www.mosek.com) optimization toolbox for MATLAB. But, no external optimizer is used for LS-SVR and SPTSVR. The Gaussian kernel of the form K (
To avoid model complexity, we assumed ε1 = ε2 for TSVR and, however, for SPTSVR we set ε1 = ε2 = 0.01. The optimal values for the kernel parameter μ, regularization parameter C1 = C2 = C, the parameters ε and p are selected using ten-fold cross validation methodology by searching from the sets {2−5, 2−4, …, 24, 25} , {10−5, 10−4, …, 104, 105}, {10−1, 10−2, 10−3} and {0.1, 0.2, 0.4, 0.7, 0.9, 1} respectively.
Synthetic datasets
In this subsection, it is proposed to examine the robustness of our SPTSVR in comparison with SVR, LS-SVR and TSVR. For this purpose, the observed values of the training examples, generated as function values, will be purposefully corrupted by uniform or Gaussian additive noise having heteroscedastic error structure. In our study, we considered three functions and their training samples are constructed as follows
Function 1.
Accuracy comparison of SPTSVR with SVR, LS-SVR and TSVR on synthetic datasets with noise Type A and Type B. Test accuracy is reported in terms of RMSE. Gaussian kernel was used
Accuracy comparison of SPTSVR with SVR, LS-SVR and TSVR on synthetic datasets with noise Type A and Type B. Test accuracy is reported in terms of RMSE. Gaussian kernel was used
Function 2. f2 (x) =0.2 sin(2πx) +0.2x2 + 0.3
such that
x i = 0.01 (i - 1) , i = 1, 2, …, 200;
Function 3. f3 (x) = x + 2 exp(-16x2) such that
where U (a, b) denotes the uniform probability distribution in (a, b) and the noise ζ is drawn from the distributions:
Type A: ζ ∈ U (-1, 1), Type B: ζ ∈ N (0, 0.52).
Here, N (0, 0.52) denotes the Gaussian distribution with mean value zero and standard deviation equals to 0.5.
For testing, 500 samples free of noise were randomly selected. To avoid biasness due to the selection of random samples, we performed the experiments ten times and their averaged accuracy is reported. The test accuracies by the proposed SPTSVR along with SVR, LS-SVR and TSVR for Gaussian kernel are summarized in Table 1. From the table, one can observe that all the methods show comparable generalization performance. Always SPTSVR shows the best performance for both types of noise, except for Function1 and Function3 for the case of uniform noise. To further illustrate the advantage of SPTSVR, the accuracy plots and the prediction error plots for one sample trial for Function1 by all the methods for both type of noise considered are shown in Figs. 2–5. From the error plots we can clearly see that SPTSVR has a better performance than the other methods considered. In summary, we conclude that SPTSVR is a robust, efficient method for noisydataset. Prediction plot of SVR, LS-SVR, TSVR and SPTSVR on Function1 with uniform noise. Prediction error plot of SVR, LS-SVR, TSVR and SPTSVR on Function1 with uniform noise. Prediction plot of SVR, LS-SVR, TSVR and SPTSVR on Function1 with Gaussian noise. Prediction error plot of SVR, LS-SVR, TSVR and SPTSVR on Function1 with Gaussian noise.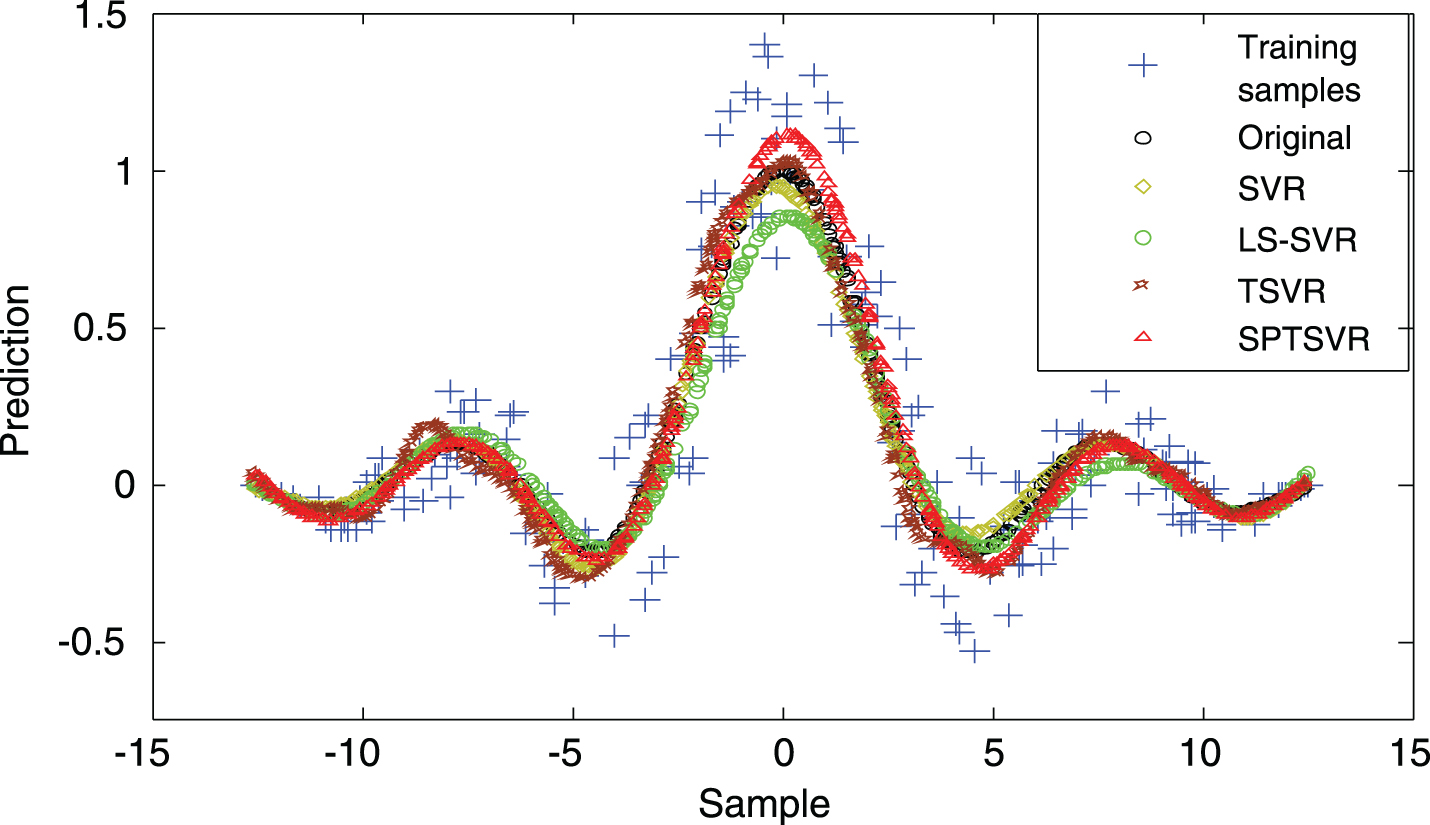



Accuracy comparison of SPTSVR with SVR, LS-SVR and TSVR on real world datasets. Test accuracy is reported in terms of RMSE. Gaussian kernel was used
Accuracy comparison of SPTSVR with SVR, LS-SVR and TSVR on real world datasets. Test accuracy is reported in terms of RMSE. Gaussian kernel was used
Hydraulic actuator dataset contains 1024 pair of samples with u(t) being the input gas flow rate and its output y (t) being the oil pressure. In our experimental study, we predict y (t) by assuming
Average rank for SVR, LS-SVR, TSVR and SPTSVR with Gaussian kernel for real world datasets.
From [5], the critical value at p = 0.10 is 2.291 and its corresponding critical difference (CD) is: Since the difference between the best and the worst of SVR, TSVR and SPTSVR is: 2.8 - 1.7667 = 1.0333 < 1.08, the post-hoc test becomes unsuccessful to find any difference among them; However, the difference between the ranks of LS-SVR and SPTSVR is: 2.9667 - 1.7667 = 1.2>1.08, we conclude that SPTSVR performs superior to LS-SVR; Similarly, the difference between the best and the worst of SVR, LS-SVR and TSVR is: 2.9667 - 2.4667 = 0.5<1.08, the post-hoc test is unsuccessful.
In conclusion, SPTSVR has improved generalization performance than the popular SVR, LS-SVR and TSVR methods on either the input samples were subject to noise, as in the case of synthetic datasets, or may be free of noise which clearly shows the usefulness and the applicability of SPTSVR.
In this work, a novel formulation of TSVR with asymmetric pinball loss function in primal (SPTSVR), whose solution was obtained using a functional iterative algorithm, was proposed. Numerical experiments were conducted on synthetic and real world bench mark datasets. Empirical results obtained for datasets which were corrupted by adding noise having heteroscedastic error structure show that SPTSVR was both robust and efficient. In addition, better performance by SPTSVR on majority of the fifteen bench mark datasets considered further clearly shows the effectiveness and usefulness of SPTSVR. As our method can be extended to classification, our future work will be on the study of its effectiveness for classification, more specifically when the input samples are corrupted by noise.
Footnotes
Acknowledgments
The authors are extremely thankful to the referees for their valuable comments.