
Abstract
In a Personal Area Network (PAN) populated with wearable devices, the security of stored files is an important concern. Secret sharing has received considerable attention as an effective approach for handling security as it guarantees confidentiality and integrity. A high level of data privacy is still assured when devices are compromised, lost, or stolen, and even in cases where the total count of these devices is less than the minimum threshold. However, because traditional secret sharing requires tremendous computational overhead and consumes large storage space, it is suboptimal for battery-powered wearable devices. To overcome these limitations, combinatorial-based file sharing is proposed. However, this approach is also hindered by an efficiency problem, because the preparation of file storage and retrieval involves computational costs. Additionally, this file sharing scheme was designed without taking into consideration an environment with heterogeneous wearable devices. To address the aforementioned problems, we first propose a new fog network model that delegates the calculation for the preparation of file storage and retrieval to a fog node, such as a smartphone or tablet PC. A fog node has comparatively higher computational speed, and a larger battery capacity; hence, the resources of the devices in the PAN can be managed efficiently. Additionally, we propose a new algorithm that facilitates file shares by considering the heterogeneous characteristics of wearable devices. In particular, we consider the factors of storage capacity and network speed to determine the size of the file shares. We use mathematical analysis and simulations to demonstrate that our proposed model efficiently manages stored files.
Introduction
As the usage of wearable devices continues to rapidly increase, it is expected that the personal area network (PAN) will become an important aspect of daily life. In such a network, the devices collect the necessary information from each user, transmit useful information between the devices or with the internet, and provide feedback to promote a higher standard of personal care [1]. Figure 1 shows the Personal Area Network. There is almost certainly privacy-sensitive information in the transmitted data. In a PAN that includes wearable devices, information is transferred as a form of raw data, which may cause privacy-related problems [2].

Personal area network.
When a wearable device is compromised, stolen, or lost, the data stored in the device can be recovered, which may infringe upon the user’s privacy. Furthermore, such portable devices are very small and lightweight, which increases the likelihood of loss or theft [3]. To guarantee the confidentiality of the stored data in wearable devices, encryption schemes can be employed.
In addition to the confidentiality of the data, integrity is also an important concern. When at least one of the wearable devices is compromised, and the data in the device are illegally changed, the integrity of data may be compromised. Moreover, owing to the aforementioned characteristics, when devices are lost or stolen, the data are usually permanently lost [4, 5].
To address these problems, researchers have attempted to apply secret sharing schemes that encrypt an original secret to create n file shares and distribute them to storages. In this scheme, n is the number of a device. For a pre-determined positive integer k, the n share satisfies the condition that any k among them can recover the original secret, but any k - 1 among them cannot. Using this secret sharing scheme, confidentiality is guaranteed until k - 1 devices are compromised, lost, or stolen. Moreover, the original data can be recovered until n - k devices are attacked, lost, or stolen.
Since secret sharing was firstly proposed by A. Shamir [6], many advanced versions have been developed. [7–11]. However, most of them are polynomial-based approaches involving a heavy operational cost. Therefore, the existing secret sharing schemes are not ideal for battery-powered wearable devices. To address this cost problem, Park et al. proposed a combinatorial-based (k, n)-file sharing scheme [12]. This approach significantly reduces the operational costs for sharing and retrieving files. Thus, this method can be adopted for wearable devices.
To adopt the combinatorial-based (k, n)-file sharing scheme to wearable devices in the PAN, the following issues must be considered.
Before sharing and recovering files in the original combinatorial-based file sharing scheme, the network should schedule how to generate file shares and how to retrieve the original file. These scheduling processes are complex operations. However, most of the devices connected to the PAN are wearable devices with limited resources. If these operations are performed by the wearable devices, then the operation speed will be slow owing to their low-performance rating of their processors, and their batteries will drain battery rapidly owing to the considerable calculation overhead. In the file sharing process, the existing file sharing scheme ignores the storage size and network speeds of participatory devices. In this case, however, a file share with a very large size is allocated to devices with a small storage capacity or slow network speed. This may significantly reduce the overall efficiency owing to operational delays.
Contribution and paper organization
In this paper, we propose a file share generation method with fog computing to enhance the efficiency of combinatorial-based file sharing for file management of devices participating in a PAN. The details of this scheme can be summarized as follows:
First, it incorporates fog computing into a PAN using the combinatorial file sharing scheme. As previously mentioned, performing the original combinatorial-based file sharing scheme on a device with limited resources may be a heavy computational burden, and the operational speed may also be slow owing to limited processing power. When considering the devices connected to a PAN, such as smartphones and tablet PCs, some of these devices have relatively good processors and large battery capacities. Therefore, if all the operations used in the technique are performed in the fog node by designating such a device as a fog node, wearable devices only need to consider the communication cost so that the limited resources can be efficiently used, and the calculation efficiency can be enhanced. We propose a method to determine the size of file shares by considering the characteristics of the devices in a PAN. To do this, it is necessary to calculate the best file share size by considering the capacity and the network bandwidth of the connected devices and to determine the size of the segments which constitute the file share to generate optimum file shares. If such a method is implemented, the file sharing scheme would be a more efficient technique in terms of capacity and communication.
The composition of this paper is as follows. Section 2 discusses work related to this study. Section 3 explains fog computing and the PAN in more detail and proposes and explains a system model incorporating fog computing into the PAN. Section 4 presents the file sharing and recovery algorithms to be used in the proposed system, and a file segment size determination algorithm to create a file share for each device. The simulation results for the proposed scheme are shown in Section 5. In addition, the results are described in detail, and the efficiency of the algorithm is demonstrated. Finally, a summary of the content and a conclusion are presented in Section 6.
This study focuses on realizing a combinatorial-based (k, n)-file sharing scheme with fog networks for a PAN and demonstrates that the approach guarantees both security and efficiency based on simulations results. This work is the extended version of a short conference paper [13].
Related work
MK Alam [15] has identified several security issues in the cloud and proposed possible solutions and methods for single cloud and multiple cloud security, using Shamir’s secret sharing algorithm. He described the secret sharing algorithm and applied it to the cloud to achieve data security and to reduce security risks.
C.N. Yang et al. [16] addressed cloud security services, including key contracts and certifications, while addressing key security issues in cloud computing. A Secure Cloud Computing (SCC) architecture was designed using Elliptic Curve Diffie-Hellman (ECDH) and a symmetric binary polynomial-based secret sharing scheme. This scheme was extended to multi-server SCC (MSCC) to enhance cloud security and operational efficiency.
T. Ermakova et al. [17] noted that the most important issue in the healthcare field is the simplification of sharing information between organizations, but the migration of sensitive health records to the cloud has serious associated security and privacy risks. They applied Shamir’s secret sharing scheme and Rabin’s information distribution algorithm for the security of multi-cloud architecture and concluded that Rabin algorithm is more efficient when comparing the two techniques.
These previous studies applied the secret sharing scheme for cloud security. They all demonstrate the strong security of secret sharing. However, the schemes used in the previous studies are not suitable for use in the cloud for small devices. Therefore, in this paper, we introduce a file sharing scheme that improves efficiency for use in environments with limited computing power.
N.B. Truong et al. [18] proposed a new VANET architecture, FSDN, which combines SDN and fog computing to solve the current architectural problems of VANETs such as poor connectivity, low scalability, limited flexibility, and less intelligence. In this study, fog computing was adopted to provide delay-sensitivity and location-awareness services to meet the requirements of future VANET scenarios.
P. Hu et al. [19] noted that facial identification and resolution technology are important tools for assisting in the identification of individuals in both physical space and cyberspace. In the IoT and big data situations, face identification and resolution are critical aspects of the demand for computation, communication, and storage improvement. In order to improve the processing capacity and save bandwidth, fog computing has been adopted, and we propose a fog computing-based facial identification and resolution framework.
I. Stojmenovic [20] argued that cloud services for smart services have latency and intermittent connectivity problems. To address this issue, we place a fog device between the cloud and the smart device to ensure that the cloud and the user are physically closer. Real-time applications, location-based services, and mobility support are available. He extended this concept to smart building controls and discussed SDN-based vehicle networks and demand response management in the smart grids by relating them to SDN scenarios.
H. Dubey et al. [21] noted that intelligent data reduction, data mining, and analysis are needed in a fog device because the size of the multi-modal, heterogeneous data collected through sensors is increasingly significant. To accomplish this objective, they proposed a fog data architecture and a low-power embedded computer that performs data mining and analysis on raw data collected from various sensors. Thus, the overall efficiency of the system is greatly improved.
M. Aazam et al. [22] suggested Emergency Help Alert Mobile Cloud (E-HAMC), an emergency alert service architecture using fog computing, because it is suitable for latency-sensitive services as it places cloud resources close to devices and the IoT. Using fog computing in real time, they provided a way to quickly inform an emergency department, and the possibility of emergency analysis and service improvement through automatic synchronization from fog to cloud.
In [18–22], fog computing was adopted as a method to increase the real-time throughput of large capacity data. [23–27] also mentioned fog computing as a method for processing big data, and it was introduced as a method to improve real-time data by lowering data latency. These various papers indicate that the adoption of fog computing can increase the efficiency of data processing. Therefore, in this paper, we apply fog computing to improve the efficiency of the scheme used for security in a PAN.
System model
Fog computing
Cloud computing is a centralized computing architecture in which all data are gathered and processed in a cloud data center. Most wireless devices are connected to the cloud, and the process of sending and receiving data is centralized in the cloud. This increases the response time for data transmission, processing, and result reception. To address these problems, cloud computing and services have been extended to the edge of the network so that more powerful computing resources can be placed closer to the devices connected to the cloud to exist as fog, and to reduce the burden on the central data center. This is called fog computing.
The fog is a service infrastructure that accesses the operations and storage resources of network devices. It provides the same services as the previous cloud, but does not involve the central server. As a result, it is possible to provide a more flexible and faster service, and the efficiency in terms of data transmission cost, and latency time can be greatly increased.
Combinatorial-based (k, n)-file sharing scheme
A (k, n)-file sharing scheme is a technique that converts a file to be stored into secret values, distributes these to n devices, and restores the original file when k devices out of n are collected. This scheme was originally proposed by Shamir, Blakley. Since then, the scheme has been advanced by several investigators. Most of the proposed schemes are polynomial-based, but in [12], a combinatorial-based (k, n)-file sharing scheme was proposed and this scheme was advanced in [28] and [14]. A combinatorial-based (k, n)-file sharing scheme uses a combination of n and k to convert to n secret values. Figure 2 shows the overall combinatorial-based (k, n)-file sharing scheme. When n devices are connected and a file is shared, the creator divides the original file into
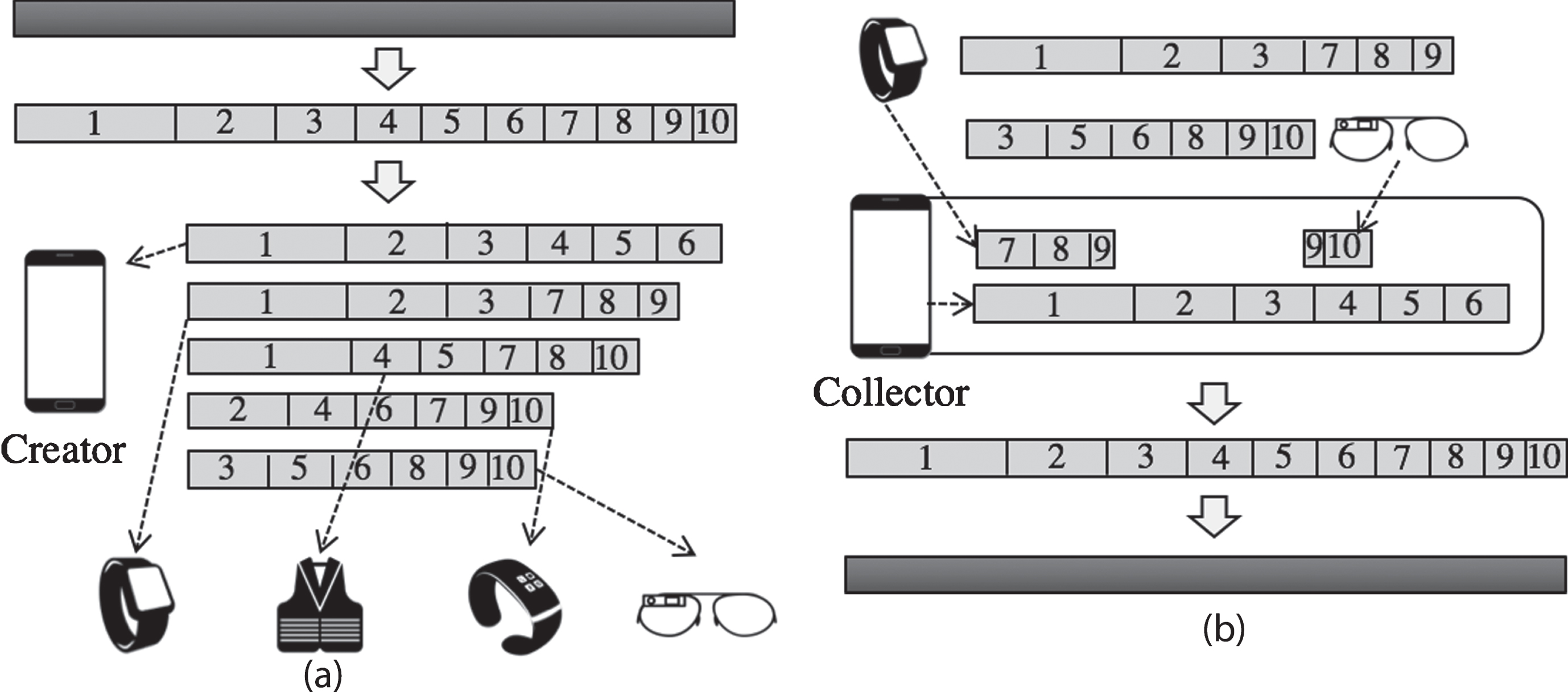
Combinatorial-based file sharing scheme process. (a) File storage (b) File retrieval.
When creating a file share, the creator uses the remaining capacity and the current network speed from all devices to create file shares that match the characteristics of the device. Because file shares are set of segments, the creator divides the original file into segments that reflect the characteristics of the devices. The details of this process are described in Section 4.
When one of the n devices requests recovery of the original file, the collector requests to send a part of the file share from k - 1 devices. The collector requests the remaining segments that are not in the collector’s file share on the k - 1 devices requested devices. The details of this process are also given in Section 4. This recovery process is shown in Fig. 2-(b). Because the collector smartphone has segment numbers 1, 2, 3, 4, 5, and 6, the remaining 4 segments must be received from k - 1 to recover the original file. Therefore, if the collector receives a portion of segment number 7, 8, and 9 from the smartwatch, and the collector also receives a portion of segment 9 and 10 from smart glasses, all 10 segments are collected and the original file can be restored.
Suppose now that we combine fog computing and the combinatorial-based (k, n)-file sharing scheme previously described and use this scheme in a Personal Area Network. In this case, the fog node must exist because fog computing is combined. This combination is performed to provide flexible and fast services and to increase the efficiency of data transmission costs and delays. Therefore, the fog node is responsible for the operation. Thus, among the many devices participating in the PAN, the smartphone with the greatest computing power operates as a fog node. Figure 3 shows the overall system model in which the smartphone connected to various wearable devices performs a file sharing scheme as a fog node.
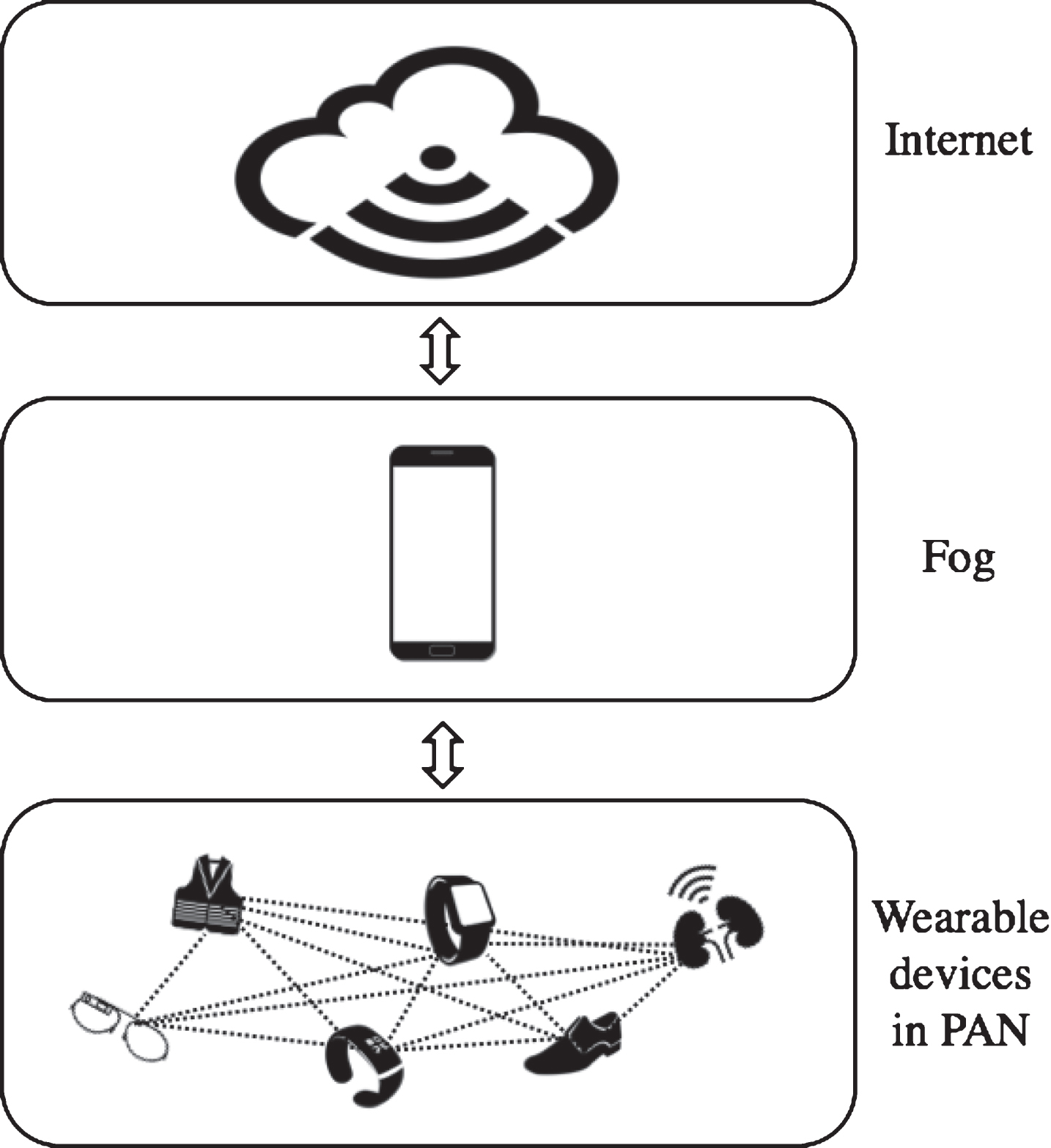
Personal area network combined fog computing.
During the sharing process, the smartphone plays the creator role, and creates the optimal file share and distributes it to itself and the other devices connected to the PAN. In addition, in the recovery process, the smartphone assumes the collector role. As the fog node can determine the network speed of all the devices and the segment composition of the file shares, it selects the most suitable k - 1 devices and request segments from them, prior to restoring the original file. Then, the restored file is transferred to the device that requested the original file recovery.
The devices connected to a PAN are all heavily burdened to operate this scheme given their low computing power and overall resources. By combining fog computing in the proposed manner, it is possible to conserve limited resources because only communication cost is considered. In addition, because fog is applied, the data delay problem can also be addressed.
This section details the algorithms and the sharing and recovery process for the proposed file sharing scheme. We explain the scheme for determining the size of the segments of the file and creating file shares using the proposed algorithm in a fog node. Then, the process of recovering from the original file from the fog node is described in detail.
Notations and symbols
The notations and symbols used in this paper are
listed in Table 1. n is the total number of wearable devices connected to the PAN, and k is the minimum number of devices that must exist to recover the original file. Then, k file shares are gathered so that the original file can be recovered. When creating file shares, the original file is divided into
During the file sharing process, the original file is first divided into σ file segments, s1, s2, ⋯, and s
σ
. The size of j segment s
j
is expressed as x
j
. At the end of the file sharing process, n file shares,
The possession table PT and the scheduling table ST are both n × σ matrixes. Let PT(i, j) and ST(i, j) be the element in i-th row and j-th column of PT and ST, respectively. The value of PT(i, j) is x
j
of D
i
if element j exists in I
i
, or 0. In the file sharing process, PT and ST are determined by the fog node. In the case of Fig. 2, PT is determined as follows:
ST is a table created and used by the file recovery process to determine the number of segments to retrieve from each device. If PT(i, j) is zero, ST(i, j) is unconditionally zero since there is no s j in D i .
I
i
represents the index set of segments which consist of
Notations
We first propose a file sharing process. The ultimate goal of this process is to create file shares that can recover the original files once k devices have gathered. To do this, the fog node determines the size of σ segments and the size of n file shares. First, the fog node computes the most optimal size of the file shares, and determines the segment size in order to ensure that the calculated optimal file share is a maximum.
As previously mentioned, the optimal size of the file shares is determined by considering the heterogeneous characteristics of the devices connected to the PAN: f1, f2, ⋯, f
n
. We aim to generate file shares that satisfy the following ratios as much as possible using r
i
p
i
, which is the product of the remaining capacity r
i
and the average network speed p
i
of the connected devices.
Therefore, the optimum size of each file share v1, v2, ⋯, v
n
is determined as follows:
The coefficient of F is (n - k + 1) because each segment is included in (n - k + 1) file shares, and hence the following equation is established:
Next, we need to determine the size of the segments that allows the optimum file share size to be a maximum. As there are n equations and the unknown number is σ, we cannot obtain the segments size from the solution of a set of simultaneous equations. Therefore, a positive solution may not exist, and negative solutions should be controlled so that the segments sizes are all positive.
Therefore, it is necessary to determine the optimal segment size in consideration of this problem. Considering this, we propose the implementation of a segment size algorithm which is shown in Algorithm 1.
Calculation of file segment sizes
Calculation of file segment sizes
We now offer an explanation of Algorithm 1. The optimum file share sizes calculated using this algorithm v1, v2, ⋯, v n are input values. Firstly, T is initialized with a set containing values from 1 to n. Lines 2– 13 is repeated n times repeated to determine the sizes of the segments. If T is not empty, assign i of the smallest v i to m. The algorithm then adds all the sizes of the segments that make up the m-th file share and stores them in sum. Increase cnt by a number of segments with zero size. In the first loop, the size of the initial segment is zero, so the sum is 0 and cnt is σ. v m - sum is saved to rest and change in the size of the segments that make up the m-th file share on lines 7– 11 is saved to rest/ cnt. Subsequently, T removes the m used in the loop and repeats the loop until T becomes empty.
For example, when F = 120, n = 5, k = 3 and v1 = 30, v2 = 95, v3 = 80, v4 = 45, v5 = 60, T = {1, 2, 3, 4, 5} and m = 1 because the index with the minimum value v
i
is 1. Since it is the first loop, sum = 0, cnt = 0, and rest = 40. On lines 7– 11, x1 = x2 = x3 = x4 = x5 = x6 = 5 because of I1 = {1, 2, 3, 4, 5, 6}. So, the result
Because m = 1 is used, 1 is removed from T, resulting in T = {2, 3, 4, 5}. The next smallest value is v4, so m = 4. sum = 18, cnt = 3, and rest = 32 because I4 = {2, 4, 6, 7, 9, 10} and x2, x4, and x6 are nonzero. By lines 7– 13, x7 = x9 = x10 = 10 and the file segments size is changed as follows:
By repeating the process in this way, it is possible to determine the size of all segments first. Once the size of the segment is determined in segments 2– 13, the value will not change in the later 2– 13 loop. Therefore, there may still be values left to be assigned. The remaining values are divided by the total number of segments σ to evenly distribute the segments. Because the objective is to fit the optimal size of the file shares from lines 2– 13, all segments are assigned the same value to avoid changing the decision ratio as much as possible. Therefore, when the loop in lines 2– 13 ends, the sizes of the segments are determined as follows:
Then, after lines 14– 16, the following final segments sizes are determined, and the algorithm ends.
Once the sizes of all the segments are determined by Algorithm 1, we can now create file shares using the PT calculated from the fog node and I1, I2, ⋯, I
n
. If PT(i, j) is nonzero for i = 0, 1, ⋯, n, the j segment exists in the i-th device. Therefore, the following five file shares are finally created:
When one of the devices connected to the PAN requests to recover an original file, the fog node must receive the file shares from k - 1 devices. The fog node chooses these devices devices considering the network speed between itself and the other devices.
Let D fog be the fog device. To retrieve a file, the fog node must first complete the scheduling table (ST) by scheduling how many of the segments should be received from the k - 1 device, excluding the current segments. If D fog has completed the ST generation, k - 1 devices must send the scheduled segments to D fog according to the result of the ST. If D fog has finished receiving the segments, the original file can be recovered. Algorithm 2 is used to compute ST and retrieves the original file.
Let D
q
1
, D
q
2
, ⋯, D
q
k-1
be the devices for which the fog node request the file share, where 1 ≤ q1 < q2 < ⋯ < qk-1 ≤ n and fog ∉ { q1, q2, ⋯, qk-1}. Let e
q
1
: e
q
2
: ⋯ : e
q
k-1
be the ratio of the communication speed between D
fog
and D
q
1
, D
q
2
, ⋯, D
q
k-1
. The ratio ST
q
i
: ST
q
2
: ⋯ : ST
q
k-1
should be similar to e
q
1
: e
q
2
: ⋯ : e
q
k-1
at best, where
We will now briefly describe Algorithm 2. Lines 1– 10 describe the procedure for initializing ST first. D fog arranges k - 1 devices selected first in the network speed order and initializes ST through PT in this order. Lines 11– 24 show the procedure for adjusting ST for optimal segments scheduling. In line 12, D u 1 and D u k-1 are the most allocated and least allocated devices, respectively. Therefore, the amount allocated on lines 11– 24 will move from D u 1 to the unassigned device. This results in ST with the best solution.
Download Scheduling Algorithm
Require: eq1, eq2, …, eqk_1
Download Scheduling Algorithm
These parts move from D u 1 to D u ℓ until ST u 1 = z u 1 or ST u ℓ = z u ℓ , in order of s π 1 , s π 2 , ⋯, s π μ . The iteration in lines 11– 24 proceeds until ST u 1 and z u 1 are the same or ST u 1 remains constant during one round of iteration. The scheduling algorithm is almost same as that proposed in the previous research [14], except that the ST is computed at the fog node.
In order to verify the efficiency of the proposed scheme, we compared its execution time with that of Shamir’s secret sharing, which is one of the most popular file-sharing schemes. Each scheme was executed 50 times for each file size and the results in Fig. 4 show the average times.

The file storage and recovery time of (2,4)-file sharing scheme and (3,5)-file sharing scheme.
In this section, we demonstrate the performance of the proposed file sharing scheme via two main experiments.
Firstly, the performance difference according to the change of and are graphically compared with Shamir’s secret sharing scheme, which is a typical file sharing scheme. Secondly, we examine whether the file shares generated by the segment generation algorithm are generated according to the characteristics of each device.
These simulations were performed on Macintosh OS, 8 GB RAM, and 2.8 GHz Intel Core i5 environment.
Figures 4-(a) and 4-(b) show the average time taken to share and retrieve Shamir’s secret sharing and the proposed file sharing schemes for k = 2 and n = 4;
Figures 4-(c) and 4-(d) are graphs showing the average time in an environment where k = 3 and n = 5.
In Fig. 4, the dotted line and the solid line represent the results of the previous file sharing and the combinatorial-based scheme, respectively. As shown in (a) and (c) of the storage results, the time required for file storage increases proportionally as the file size increases, both in the previous and in the combination-based scheme. When k = 2 and n = 4, the time required to store a 10 MB file is 1.833 s on average for the previous method and 0.412 s for the combination-based method. The file storage time for a 50 MB file is 5.109 s on average for the previous method and 4.247 s on average for the combinatorial-based method. It is noted that the execution time of both techniques does not differ greatly and neither technique requires much time for storage. However, in the case of Fig. 4-(c), where k = 3 and n = 5, the degree of the polynomials increases by one and the computation time is greatly increased. Therefore, the time difference between the previous and the combinatorial-based scheme is noticeable. The previous scheme requires 2.020 s for the file storage for a 10 MB file, whereas, the combinatorial-based scheme requires 0.342 s. The previous scheme requires 9.156 s for a larger file, with a file size 50 MB, whereas, the combinatorial-based scheme requires 3.207 s. The difference in the time taken by the two schemes is greater for the case where k = 2 and n = 4. Therefore, as k increases, the computation time increases greatly in the case of the previous scheme. However, as the combination-based scheme is not based on polynomials, it is seen that there is not much difference in the computation time even if k is large.
We now consider (b) and (d), which are the results of recovery. In contrast to the results of storage, it can be seen that the computation time increases rapidly as the file size increases in the case of the previous scheme. However, in the case of the combinatorial-based scheme, the computation time is almost the same regardless of the file size. For example, when k = 2 and n = 4, the recovery time for a 10 MB file is only 1.56 s for the combinatorial-based scheme, compared to approximately 36.930 s for the previous scheme. The recovery of a 50 MB file takes 1.221 s for the combinatorial-based scheme, and 182.520 s for the previous scheme. There is a difference of a factor of 180 between the two schemes. As the file size increases, the difference becomes more pronounced. The result for the computation time as gets larger, indicates a greater time difference between the schemes. Figure 4-(d) shows the recovery results when k = 3 and n = 5. The recovery time for a 10 MB file is 1.264 s for the combination-based scheme and 54.509 s for the previous scheme. This is a considerable difference of 50 times. In the combinatorial-based scheme, the time for recovery for a 50 MB file is 1.166 s. There is no difference in the time required for k = 2, k = 3 for small and large file sizes. However, the previous scheme required 288.285 s. This approach requires 280 times the amount of time compared to the combinatorial-based scheme. Therefore, it is not suitable for operation in wearable devices because of the significant computational burden required for recovery when using the existing scheme. However, when the combinatorial-based scheme is used, the difference in the computation for recovery does not increase. Figure 4 demonstrates that this is a suitable scheme for a PAN architecture.
Efficiency of the proposed algorithm
We next examine the efficiency of the segment size determination algorithm proposed in Section 4. The proof of efficiency for this algorithm is demonstrated numerically through the Cauchy-Schwarz inequality.
The size of the file shares is determined by the size of the segments. Therefore, if a segment size calculation algorithm is a suitable algorithm, file shares will be created that match the characteristics of the devices.
Therefore, the more efficient the file shares are, the closer they are to the ideal file shares that can be obtained by reflecting the characteristics of the device.
In this simulation, when the Cauchy-Schwarz equation is used, it is 1 if the size of the actual file share is exactly equal to the size of the ideal file share. Therefore, the closer the ideal size to the actual size, the closer the value to 1, and the less similar, the closer the value to 0.
Figure 5 shows the simulation results for n = 4, 5, 6, 7, 8 for k = 3, 4. The average result after 300 runs for each case is shown. The targets of this algorithm are wearable devices connected to a PAN. Therefore, the aforementioned random numbers are generated, applied, and tested.

The Cauchy-Schwarz inequality results.
Overall, we can see that the result of the Cauchy-Schwarz equation is close to 1, with a value of about 0.9. In general, the larger the number n (7 or more), the lower the accuracy. However, since the number of devices connected to the PAN does not increase infinitely, and the number of devices to be worn is limited, the results of the subsequent graphs not shown in Fig. 5 are negligible.
As such, a result of about 0.9 generally demonstrates that file shares are being considered that are well characterized by the devices connected to the PAN.
In this paper, we proposed an efficient file sharing scheme which incorporates fog computing in a personal area network (PAN). The devices connected to the PAN are small and light; hence, there exist inherent security vulnerabilities owing to the lack of strong security solutions as a direct result of the limited resources of these devices. This is partly owing to the fact that they are battery-powered as well as the possibility of data leakage owing to loss.
In order to address this problem, a file sharing scheme that can be used in a PAN is developed based on the characteristics of the devices, such that this scheme is much more efficient than previous schemes.
In addition, by combining with fog computing, it is possible to conserve the resources of the devices connected to the PAN and to reduce latency by taking charge of the entire operation in the fog node. If the proposed method is applied to a PAN, it saves files safely and improves efficiency considerably.
Footnotes
Acknowledgments
This research was partly supported by the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIP) (No. NRF-2017R1C1B5018116), and the Sookmyung Women's University Research Grants (1-1603-2018).