
Abstract
For the artificial intelligence (AI) to effectively mimic humans, understanding humans, more specifically, human emotion is important. Sentiment analysis aims to automatically uncover the underlying sentiment or emotions that humans hold towards an entity. There is high ambiguity of emotion in text data. In this paper, we consider the sentence-level sentiment classification task, and propose a novel type of convolutional neural network combined with fuzzy logic called the Fuzzy Convolutional Neural Network (FCNN) and its associated learning algorithm. The new model is an integration of modified Convolutional Neural Network (CNN) in the fuzzy logic domain. The proposed model benefits from the use of fuzzy membership degrees to produce more refined outputs, thereby reducing the ambiguities in emotional aspects of sentiment classification. Also it benefits from extracting high-level emotional features due to convolutional neural representation. We compare the performance of our proposed approach with conventional CNN for sentiment classification. The experimental results indicate that the proposed FCNN outperforms the conventional methods for sentiment classification task.
Introduction
Today in the Internet era, and with the influx of social media, it is necessary to dig into essential and meaningful information from the countless data available in it. They usually come in the form of text and explicitly state the viewer’s affection for content such as products, services, books, hotels, etc. Text is one good source for expressing your ideas, emotions and feelings. Languages are not only used for communication but also impart emotion associated with it. Sentiment analysis of such texts is pivotal to clearly grasp the opinions and emotions expressed within an online mention.
Sentiment extraction from texts has made a remarkable development in the past few years [11, 21]. Sentiment analysis analyses online texts using natural language processing (NLP), text analysis and computational linguistics to categorize a piece of text into positive versus negative emotional states. However sentiment polarity (positive and negative) and sarcasm in text can make sentiment classification a challenge to machine learning.
The Convolutional Neural Network (CNN) is a machine learning model that showed remarkable results in identifying and classifying problems, especially in the field of NLP [1, 6]. The deep CNN can extract high-level features from the input that improves the classification accuracy [8]. These classifiers treat the classification of sentiment in a “black-and-white” manner and do not deal with inherent ambiguities with linguistic labels. Also, the features extracted by the deep CNN are not something that humans can interpret.
Fuzzy logic has been in use for dealing with many practical problems of ambiguities with linguistic labels. Unlike deep CNN, fuzzy logic can extract the degree to which a document contains a specific sentiment. Fuzzy rules can be derived from a large amount of training data by automatically learning the fuzzy membership functions. Based on the predicted classes (e.g. positive and negative) and the corresponding fuzzy membership values, the system allows the inference of more refined categories (e.g. neutral) or intensities (e.g. somewhat positive, somewhat negative) of sentiment without the need to define more classes. Both neural network and fuzzy logic can represent data efficiently. Many successful fuzzy-neural models have been developed a few decades ago. In the fuzzy-neural network (FNN), input signals, weights and output signals are fuzzified and expressed in the fuzzy domain [7, 19]. The FNN is capable of handling linguistic ambiguities such as low, medium, and high or fuzzy values which enhances its sustainability and processes capabilities with ambiguous data [19].
In this paper, we propose a new Fuzzy Convolutional Neural Network (FCNN) model that is an integration of fuzzy logic in to a traditional CNN framework. The combination brings together the advantages of both fuzzy logic and CNN models by extracting high-level useful features from ambiguous text data. A preliminary version of this work has been presented as a conference paper [18]. The FCNN model was tested on sentiment analysis tasks that showed better performance as compared to the conventional CNN model. In the current version, we perform detailed experimental analysis using five varying data sets. We analyze the contribution of fuzzy operators in feature extraction with detailed feature set visualization at different layers. We also verify the robustness of the proposed FCNN by experiments with noisy data.
The rest of paper is organized as follows: in the next section, we present the related works. In Section 3, we explain our proposed FCNN model architecture. In Section 4, we present the results of our experiments. In the last section, we conclude our results and discuss our future plans.
Related works
Sentiment extraction from texts has made considerable progress in the past few years [11, 21]. For text sentiment analysis, lexicon-based dictionaries; bag-of-words; word embedding [16] in combination with classifiers such as SVM [23] or deep neural networks [5, 12] have been attempted.
The CNN for text based sentiment analysis has been applied to a broad set of applications including language modeling [16], sentiment analysis [11], syntactic parsing [13], and machine translation [15]. Deep learning networks carry out automatic feature extraction and doesn’t have the capacity to represent inherent uncertainties with linguistic labels. This makes deep learning unsuitable to address the problems of data uncertainty as well as ambiguity.
With the development of deep learning models, many studies have attempted to combine fuzzy logic with deep learning models that produce remarkable results such as fuzzy restricted Boltzmann machine (FRBM) [2] which replaced RBM’s parameters with fuzzy number, or parallely concatenate fuzzy inference system with multilayer neural network in fused fuzzy deep neural network (FDNN) [3]. Another attempt is using fuzzy logic correction module to improve performance of CNN in [22]. However, these models are just a combination of fuzzy logic and neural modules in a successive or parallel way, which do not really integrate the two models to take full advantage of them.
FCNN architecture
Figure 1 shows the architecture of proposed FCNN architecture for text sentiment analysis. Firstly, the input sentence is embedded by embedding layer to real value matrix. Then fuzzification layer transforms the input matrix in to fuzzy domain. Consequently, the fuzzy representation is convoluted in fuzzy convolutional layers which works as a filter to get high-level features from the data. After passing through the fuzzy convolutional stage, the extracted feature set is converted into crisp value by defuzzification layer. Finally, fully connected layer works as output classifier for FCNN.
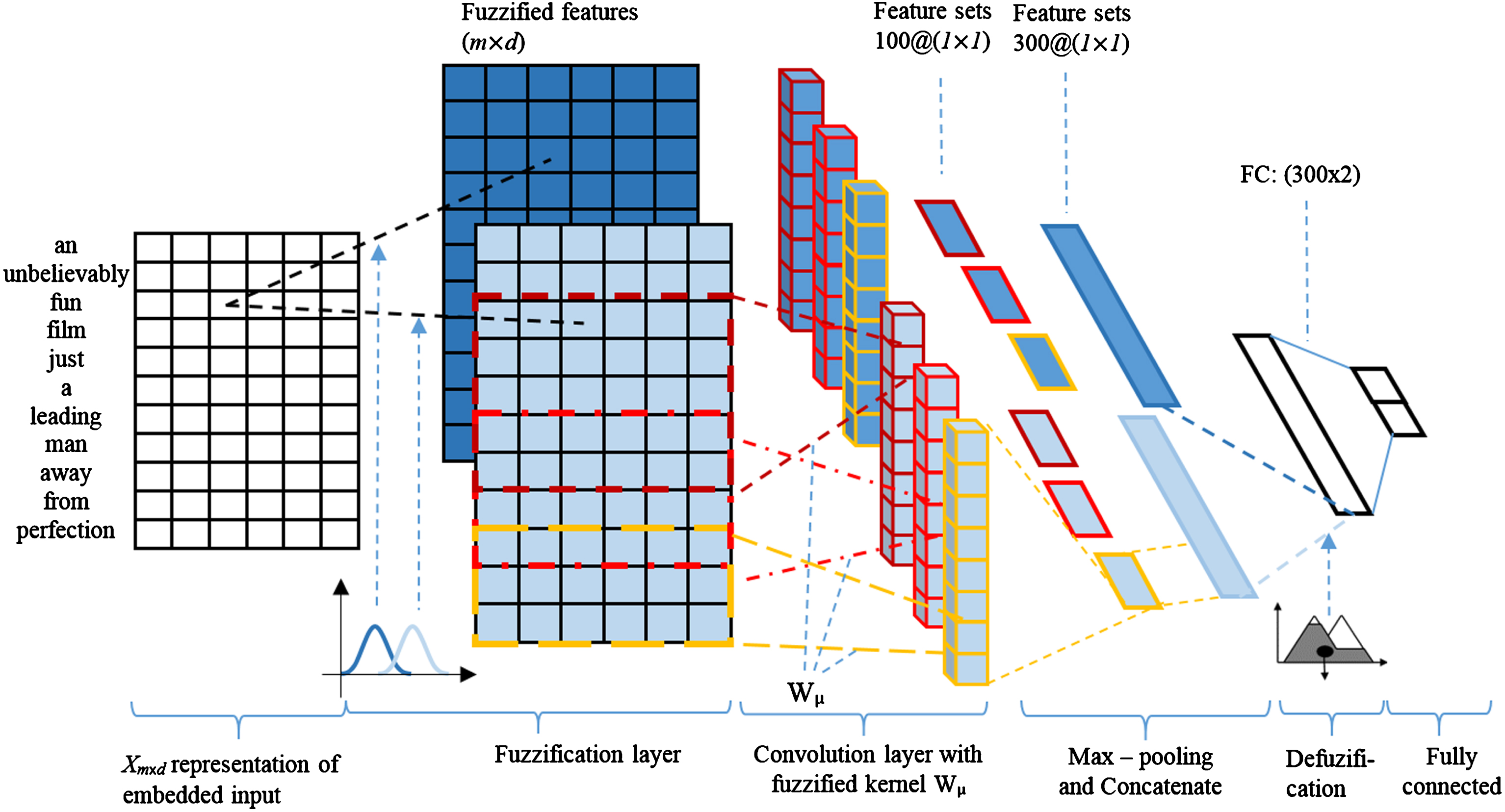
FCNN for text sentiment analysis.
For sentiment classification of a sentence, FCNN calculates a score value for each emotional label. To do this, the model first receives the input as a sequence of words and passes through the layers of the model. Through each layer, higher-level features are extracted and taken to the next layer. The model then extracts the features from the vector level of the word to the sentiment level of the sentence.
For proper computation using FCNN, the words in the sentence must be expressed as numerical values. Word-level embedding is the first step to map every word in a sentence to a d-dimensional vector so that each sentence will be transformed into a matrix of size m × d, where m is the length (number of words in the sentence) and d is the dimension of the embedded vector. Typically, the length of the sentences in the dataset are usually different. For convenience, we pad a special word at the end of each sentence to make their length same.
For each sentence consisting of M words (w1, w2, …, w m , …, w M ), the w m words in the sentence will be transformed into a vector u m = [u1, u2, …, u D ]. We use a fixed size V dictionary, so we have embedding matrix D ∈ R(d×|V|). We obtain the mapping of w m to the vector u by Equation 1.
After embedding each input to a matrix X, each element in the input matrix is assigned multiple linguistic labels based on membership functions. The fuzzy membership function calculates the grade that describes the membership of the input node to a particular fuzzy set. The fuzzy sets
Each fuzzy convolution layer includes three processing stages, namely fuzzy convolution stage, nonlinearity stages and pooling stage. The fuzzy convolutional stage is a process of applying fuzzy convolutional filters to original 2D data as in Equation (4) in which fuzzy convolutional filters W
μ
is calculated as Equation (5) where W is original convolution filter.
The following Equation (6) is a non-linear transformation of the output obtained from fuzzy convolution stage. The last stage is another operation called pooling (e.g., Max Pooling) which is a summary statistics of nearby results after feature extraction stage. This stage helps the representation to be invariant to translation of input, and meanwhile, the size of the input to next fuzzy convolutional layer might be reduced.
The fully connected layer of the FCNN is working as a classifier with input features being the crisp value z
i
obtained from the deffuzzification process with center of gravity method in Equation (7), where C
y
is the center of the defuzzification membership function.
Cross entropy is the loss function used to evaluate the output error, as shown in Equation (9), where y is target,
The parameters of the model are trained by conventional back-propagation learning algorithm with the cross-entropy loss function. The weight update as shown in Equation (10).
The centers C
y
(k) of defuzzification membership functions are updated as Equation (11), where a
C
y
denotes the learning rate of updating center, yk+1 and
Center value C
w
and variance σ of fuzzification membership function of convolution layer’s weight are calculated by Equations (12)–(15) with learning rate α
C
w
For updating the mean and variance of fuzzification layer’s membership function, we use Equations (16) and (17), where α
cx
is the learning rate of fuzzification layer.
The process of training the FCNN with back-propagation is summarized in Algorithm 1. For given training dataset with feature set X and target y, we apply mini-batch training procedure to obtain the best parameters for FCNN and CNN. The hyper-parameters such as learning rates, batch size, dropout rate, and training epoch are empirically chosen.
Experiments
Model configuration
The structure and the detailed settings of parameters for the FCNN model is illustrated in Table 1. Notice that we adopt ‘dropout’ in the last layer after fully connected layer to prevent over fitting. We use a variant of the proposed model with the same structure as regular FCNN with fuzzification and defuzzification stages, but replace the fuzzy convolution layers with conventional convolution layers for comparison. We name this model as FCNN w/o FuzzConv. We employ this model to analyze how fuzzy convolutional layer in the proposed model contributes to sentiment classification task.
CNN and FCNN Model Parameters for text sentiment analysis
CNN and FCNN Model Parameters for text sentiment analysis
The proposed FCNN model with the above parameters is tested on five different datasets with varied properties like number of classes, data size and length of the sentence. Table 2 gives the summary statistics of five datasets used.
Training procedure for FCNN
Training procedure for FCNN
Summary statistic of used datasets. c: Number of classes, l: average of sentences length, N: Number of samples in dataset, Test: Size of test set (CV: using 10-fold CV)
Movie reviews (MR) were first used in [20], which contains 10,662 reviews, including 5,331 positive and 5,331 negative snippets. Each sample in this dataset corresponds to a single review which usually contains one sentence. The length of each sentence is smaller than fifty six words. All the sentences are lower-cased. The samples are labeled as negative and positive. Some examples of sentences in this text dataset are shown in Table 3. Stanford Sentiment Tree bank (SST) which includes SST-1 and SST2 is an extended version of MR with standard separation of train/dev/test sets. SST-1 has 5 classes while SST-2 has 2 classes. Twitter sentiment dataset is a small dataset extracted from Twitter, which is a popular micro blogging service. Twitter’s user can create status messages, which are called tweets, with a maximum of 140 characters. The Twitter dataset used for our experiments has a total of 9,513 tweets. Each sentence has an associated emotional label as positive, neutral or negative. Twitter-2 is the same with Twitter-1 dataset, but the neutral class is eliminated.
Some samples of sentences in MR dataset
For the datasets that are not separated according to standard train/dev/test set, a 10-fold cross validation is performed, where the classifier is trained on 90 percent and tested on 10 percent of the dataset. This is repeated such that each sample from the dataset is used once for validation. Then the average accuracy is calculated. For comparison, we select a CNN which is derived from [5] with the similar structure and complexity as the baseline approaches. To make sure the performance of the proposed model and the baseline method is comparable, we apply the same training hyper-parameter as pooling probabilities, dropout rate, and learning rate for classification layer. For comparison, we empirically choose hyper-parameters of each model by trial and error.
Table 4 shows the comparison of 10-fold classification of CNN and FCNN for MR dataset. The results show that the average accuracies of the emotion recognition system are 74.03%, and 76.34% for the CNN and FCNN classifiers respectively.
Comparison of classification accuracy of CNN and FCNN for MR dataset using cross-validation
Comparison of classification accuracy of CNN and FCNN for MR dataset using cross-validation
Comparison of classification accuracy is summarized in Table 5. This table shows the classification accuracy of 3 models: CNN, FCNN and FCNN w/o FuzzConv with respect to 5 datasets. With MR, Twitter-1, and Twitter-2, which are tested with 10-fold cross validation, the standard deviation is also mentioned. It can be seen that the FCNN has the highest accuracy. Our proposed model outperforms the vanilla CNN by an average of almost 2% with lower standard deviation. The performance of CNFN w/o FConv is lower than both CNN and CNFN. This result allows us to emphasize the effectiveness of the fuzzy convolutional layer, combined with the fuzzification and defuzzification stages, in extracting higher features. The lower standard deviation of FCNN after 10-fold cross validation also indicates that the proposed FCNN is more stable than the conventional CNN model.
Summary of classification accuracy of CNN, FCNN and FCNN w/o FuzzConv for all tests
To verify the robustness of the proposed FCNN model, we test on a noisy dataset. This is done by replacing a number of random words of all the sentences in the dataset. Then we train and test with noise added to this dataset. From the results in Table 7, we conclude that, although both CNN and FCNN are affected with noise, FCNN shows a smaller ratio of reduction in accuracy.
In Table 6, the sentences replicate ambiguous sentiments, which are sometimes confusing even for humans. By using CNN, the sentiment of the sentences were misclassified. Whereas, FCNN could recognize the sentiments in the sentences properly. This can be explained by higher feature extraction of FCNN on ambiguous data.
Some samples of ambiguity sentences in MR dataset
Comparison performance reduced by adding noise to MR dataset
In order to analyze the contribution of fuzzy operators in feature extraction and classification, we visualize feature sets that are extracted by fuzzy convolutional layers and compare with those of CNN at the same level. Two trained CNN and FCNN models for text sentiment analysis are employed with the same test dataset. We use the visual analytic method in [24]. Firstly, we apply 1,066 samples of the test set to train both CNN and FCNN models, then we extract output feature sets of given layers. After extracting all the feature sets, we project each of those to 2D scatter plots as shown in Fig. 2.
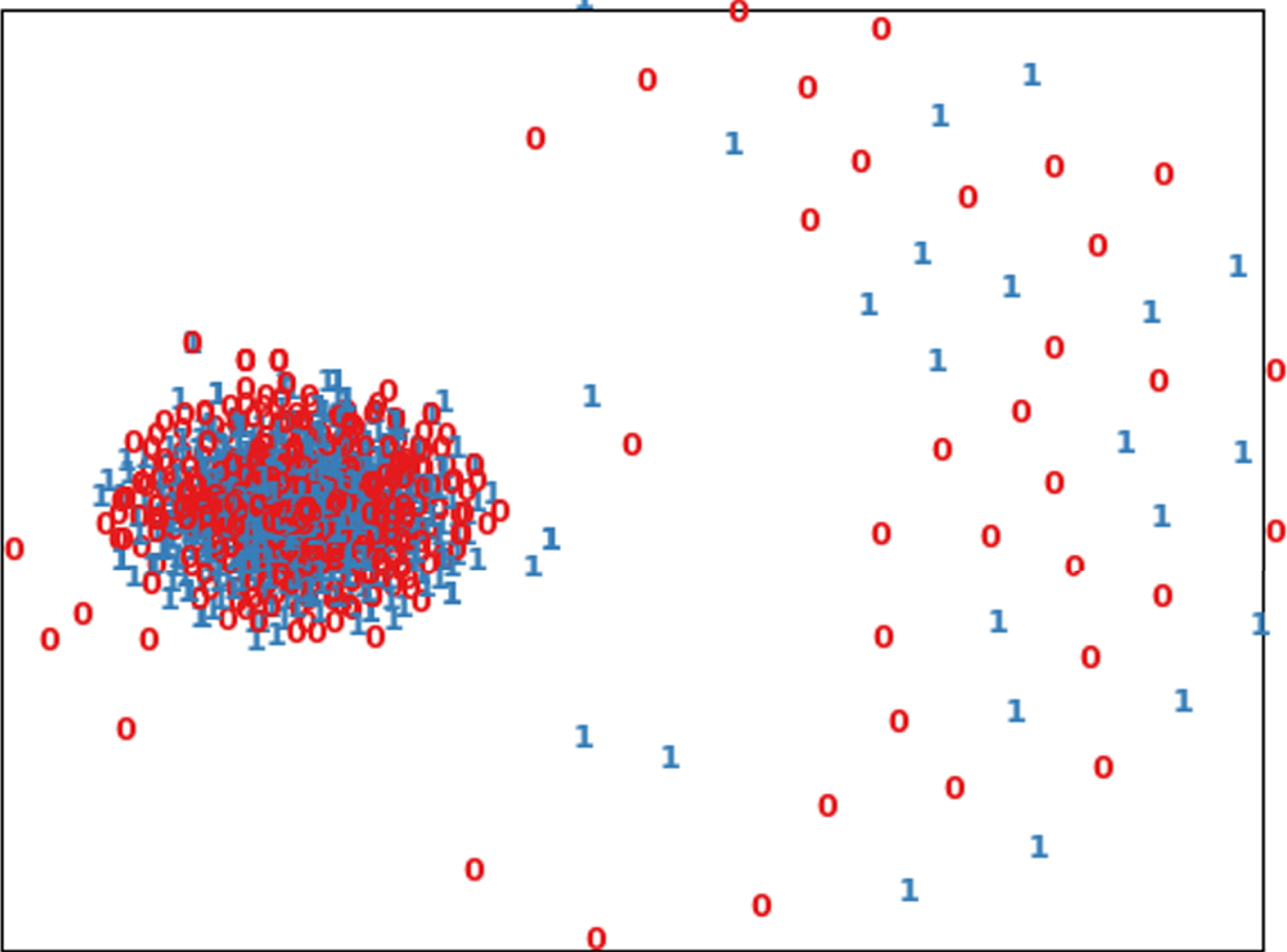
Projection of scatter plots of test input samples.
The projection uses t-distributed Stochastic Neighbor Embedding (t-SNE) [14] with same parameters. t-SNE is a popular method to visualize high-dimensional data. Each point on the plot is equal to one sample and labeled to the class it belongs to. The main reason of using t-SNE is to show how the proposed FCNN can better identify the hidden patterns in the data. The t-SNE represents the multi-dimensional data features in 2 or 3 dimensions.
t-SNE basically converts high dimensional distances between the data points into conditional probabilities. It shows the similarity between data points under Gaussian distribution. So if the points are close to each other based on the predefined variance, the probability of locating at the same Gaussian distribution would be higher. The t-SNE tries to minimize the sum of the difference of the conditional probabilities and this is performed through the minimization of the sum of the Kullback-Leibler divergences over the data by gradient descent.
By comparing the t-SNE distributions of CNN and FCNN in Fig. 3, it can be understood that both the local and global distribution of the data are retained better in case of the proposed approach. So in FCNN, the data points are less sparse than the CNN case and are clustered in a better probability distribution. Figure 3 also verifies that the data points in FCNN case are grouped in better neighboring distribution.
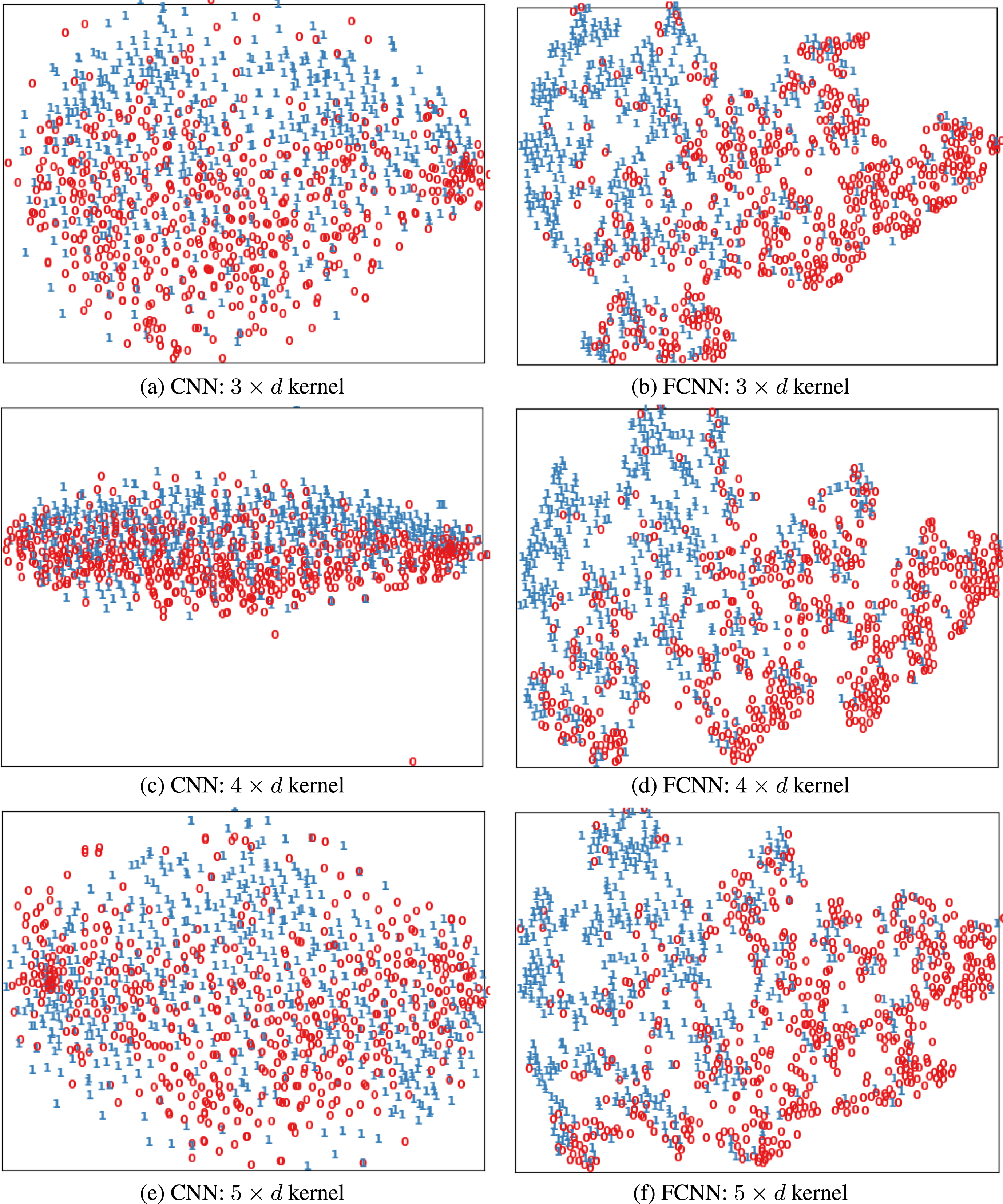
Projection scatter plots of output feature set extracted by convolutional layers in both CNN (first column) and FCNN (second column). Each model was tested using kernels of sizes 3 × d, 4 × d and 5 × d, where d is the dimension of the embedded vector.
Scatter plot of projection of input samples is shown in Fig. 2. By passing through the convolutional layers, higher feature sets can be extracted, so the distribution of feature set of each class is more separate as shown in Fig. 3. Figure 4 shows the plots of final features distribution of convolutional stage of two model. Those plots clearly show that fuzzy convolutional filter can extract more useful features for classification.
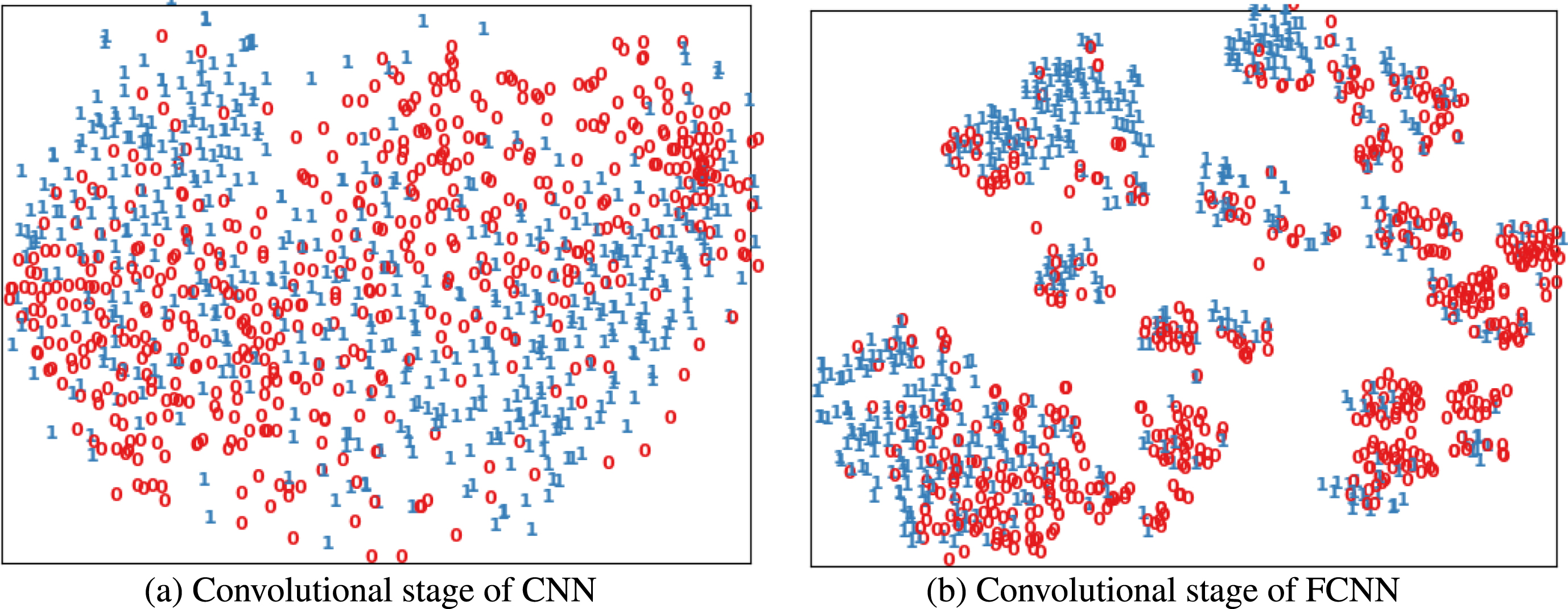
Projection scatter plots of feature set extracted by convolutional stage in both (a) CNN and (b) FCNN.
For quantitative analysis of separability of output feature set, we employed Silhouette analysis [25]. This analysis can be used to study the separation distance between the resulting clusters. The Silhouette plot displays a measure of how close each point in one cluster is to points in the neighboring clusters and thus provides a way to assess parameters like number of clusters visually. This measure has a range of [-1, 1]. Silhouette coefficients near +1 indicate that the sample is far away from the neighboring clusters. A value of 0 indicates that the sample is on or very close to the decision boundary between two neighboring clusters and negative values indicate that those samples might have been assigned to the wrong cluster. The comparison of Silhouette score for each layer of two models is shown in Table 8. Compared to CNN, the fuzzy convolutional filters of FCNN show higher ability to extract discriminative features, and then the output feature set gets more separable with the higher Silhouette score.
Comparison of Silhouette score
This paper takes advantages from deep learning, fuzzy modeling and neural networks and propose a hybrid deep learning based fuzzy-neural model, Fuzzy Convolutional Neural Network, which integrates fuzzy logic and CNN, for text sentiment classification. FCNN can generate more reasonable features that achieve better classification accuracies on emotional data as compared to conventional approaches such as CNN. The proposed model addresses the problems of data ambiguities with linguistic labels that have relevance for emotion identification in sentiment analysis tasks. In future, we intend to explore a more deeper architecture by adding fuzzy convolution layers to the proposed framework. We also intend to integrate features from multiple modalities such as text, video and audio and use the proposed FCNN model for emotion recognition and sentiment analysis. Also, we intend to develop an explainable AI which indicates the roles of hidden layers and neurons to produce an output. Furthermore, we are trying to develop other fuzzy operators in the deep fuzzy convolutional neural networks as well as a deep fuzzy recurrent neural network.
Footnotes
Acknowledgments
This work was partly supported by Institute for Information & communications Technology Promotion (IITP) grant funded by the Korea government(MSIT) (2016-0-00564, Development of Intelligent Interaction Technology Based on Context Awareness and Human Intention Understanding) (50%) and the National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIP) (No. NRF-2016R1A2A2A05921679) (50%).