
Abstract
Deep Rectified System for High-speed Tracking in Images (DRSHTI) is a unified open-source web portal developed for object detection in images. It aims to be a platform for the end user, where he/she can perform object detection on images without going through the hassles of debugging countless lines of code or setting up the right environment to perform computer vision tasks. By making the platform open-source, this work targets beginners in computer vision to form a basic understanding of object detection as an artificial intelligence task. This is made possible by releasing source codes, tools and tutorials on its usage via GitHub. This open-source portal offers two detection pipelines based on Faster-RCNN – a model to detect ground vehicles in aerial images and a model to detect everyday objects in 37 different classes in normal images. The former model is trained on VEDAI dataset, which gave 98.6% accuracy during testing and is offered as proof-of-concept that showcases the models ability to perform small target detections, but the latter model is trained on the PASCAL VOC dataset. Making the project open-source also aims at bringing in more development and tweaking to the existing vehicle detection module. The web portal can be accessed via https://drshti.github.io, where user can upload images and get annotations on objects present in it. Tutorials and source codes can be found at https://github.com/vyzboy92/Object-Detection-Net.
Introduction
Artificial intelligence (AI) has recently gained interest in the industry as well as academia, where these concepts are used to solve complex computing tasks with high precision and less effort. Concepts of A.I. solves problems in the domain of computer vision, natural language processing, stock-market predictions, complex modelling etc. Primary use cases of AI in computer vision could be described as either a classification task or an object detection task. A classification task involves categorizing an entire image as belonging to a particular class, whereas object detection requires the identification and localization of a particular entity or subject within the frame. There could be multiple subjects that needs to be detected and a detector should be able to identify those objects and also give the spatial extent of the said objects in the image. The applications of such object detectors are diverse. They could be used for traffic monitoring in cities, military surveillance and reconnaissance, border patrol, security systems, home automation, self-driving cars, face recognition systems etc. A sliding window based search algorithm [12–15] and manual/shallow-learning-based features [17–19] was previously used by vehicle detection systems. Time-complexity of these windows are very high and it can generate too many redundant windows [16]. Previously these tasks were handled as image processing problems that used methods like, Histogram of Oriented Gradients (HOG) or background subtraction methods to extract prominent features from an image and localize their extent. HOG and singular value decomposition methods were used by authors of [8] for feature engineering along with a support vector machine (SVM) classifier to detect vehicles in aerial imagery. These methods although fast, could not deliver the accuracy that real world usage demanded [11] and could not be a scalable solution that could be deployed as a real-time system.
Then came cascade classifiers, like haar-cascades [4]. These machine learning classifiers were trained to detect any one particular object class and multiple haar-cascades were required to detect different objects in the image. Microsoft has a huge repository of such cascade classifiers that detects mostly humans, faces, torso etc., and these are trained on a very big and diverse dataset. While these classifiers offer a light weight and faster solution for object detection, they are often not diverse enough to offer solution for real-world systems. They are plagued by many issues like practicality, where any system deploying a cascade should have a classifier for each and every object class it encounters and this makes the system cumbersome and at times storage expensive. Other issues relate to scalability, where these systems often fails, when it encounters a slightly skewed variation of the subject it needs to track. For example, the face detections using haar-cascade requires the subject to be at a particular proximity to the capturing device and a face that is tilted may never be recognized by the classifier. Another scalability issue comes with the training of these classifiers for newer classes of objects and this is a highly labour intensive task. These machine learning classifiers require manual feature engineering on the training data and this limits their performance in a dynamic environment. Over the years, neural networks have out-performed machine learning classifiers and delivered state-of-the-art performance for different use cases. Convolutional neural nets or CNN, are a special type of neural nets that is widely used for computer vision tasks and have reportedly given leading edge results. Several object detection CNNs have been introduced over the years. Segnet [3] is one such attempt at designing a pixel-wise segmentation net that classifies objects via a deep encoder-decoder net followed by a pixel-wise classifier. It is capable of recognizing the pixel-wise distribution of each object in a scene and gives colour coded masks as overlay to distinguish various entities. Computational complexity limits the deployment or training of Segnets on most consumer grade machines as the encoder-decoder layers are memory expensive and resource intensive. A similar pipeline is discussed in [1], where the authors proposed a segment-before-detect approach, which uses a semantic segmentation of vehicles from ISPRS Potsdam and the NZAM/ONERA Christchurch datasets, by training a deep fully convolutional net and use the extracted semantic map to classify vehicles via a CNN trained on VEDAI dataset. Segment before detect pipeline although successful in detecting the vehicle instances in aerial image, do not provide any source code or a public portal to the end user. The pipeline also requires manually executing each blocks of the process rather than providing a unified solution for the end user.
This research uses the Faster-RCNN (F-RCNN) introduced in [5]. There are over 37 different classes of objects that could be recognised by the F-RCNN. This research intends to build a vehicle detection system that could identify vehicles from aerial imagery by training the F-RCNN on VEDAI dataset [9]. The possibilities of such systems are immense, ranging from military applications to civilian use cases. Such a detector could be used to monitor military convoy movements, tracking rogue vehicles, traffic monitoring, parking lot management etc. Existing solutions in the market are not quite user friendly and requires some level of domain knowledge to execute. For example, the Detect-Net offered by NVIDIA, requires the user to setup his/her local system and configure the environment to properly run the solution. This is the case with most object detection nets offered via public repositories. So, this work aims to build a free, open-source, online API for vehicle detection, christened DRSHTI (Deep Rectified System for High-speed Tracking in Images), that is freely accessible to the general public. The source codes are made openly available, with tutorials for anyone who wishes to build or modify the system described here. Vehicle detection in aerial images is introduced as a proof-of-concept and can be tweaked by any user to include more training data to improve upon the existing model. Additionally, DRSHTI also provides option to detect another 37 different classes of objects found in real world. The user just needs to upload an image to the public dashboard of DRSHTI and get annotated images as result. The source codes of this work are released openly via GitHub, which could be adapted to video feed by making slight modifications by the user after following some simple steps mentioned in the repository.
Background of proposed work
This section discusses in detail the Faster-RCNN network used for this pipeline, its various components and the reason to choose these parameters.
Faster-RCNN architecture
Introduced by Shaoqing Ren et.al, Faster RCNN [5] or Faster Region-based Convolutional Neural Net is a modified iteration of the Fast RCNN [6], where the conventional selective search of Fast RCNN is replaced with a Region Proposal Net (RPN). The authors reported better and more efficient performance for this RPN based pipeline both on CPU and and GPU. It is due to the fact that, time complexity in generating proposals via an RPN is very small compared to the selective search approach. The input to the RPN is the final convolutional feature map from a CNN (ResNet-50 in this work) and the resultant feature map with embedded region proposals from the RPN is fed into a two sibling fully connected layers – a box regressor layer and a box classifier. The RPN tells the model the locations to search so as to reduce the computational overhead. Scanning all the locations helps to determine whether further processing is required by the net. The F-RCNN pipeline is demonstrated in Fig. 1 An in depth read on F-RCNN and Region Proposal Nets can be found in [5].
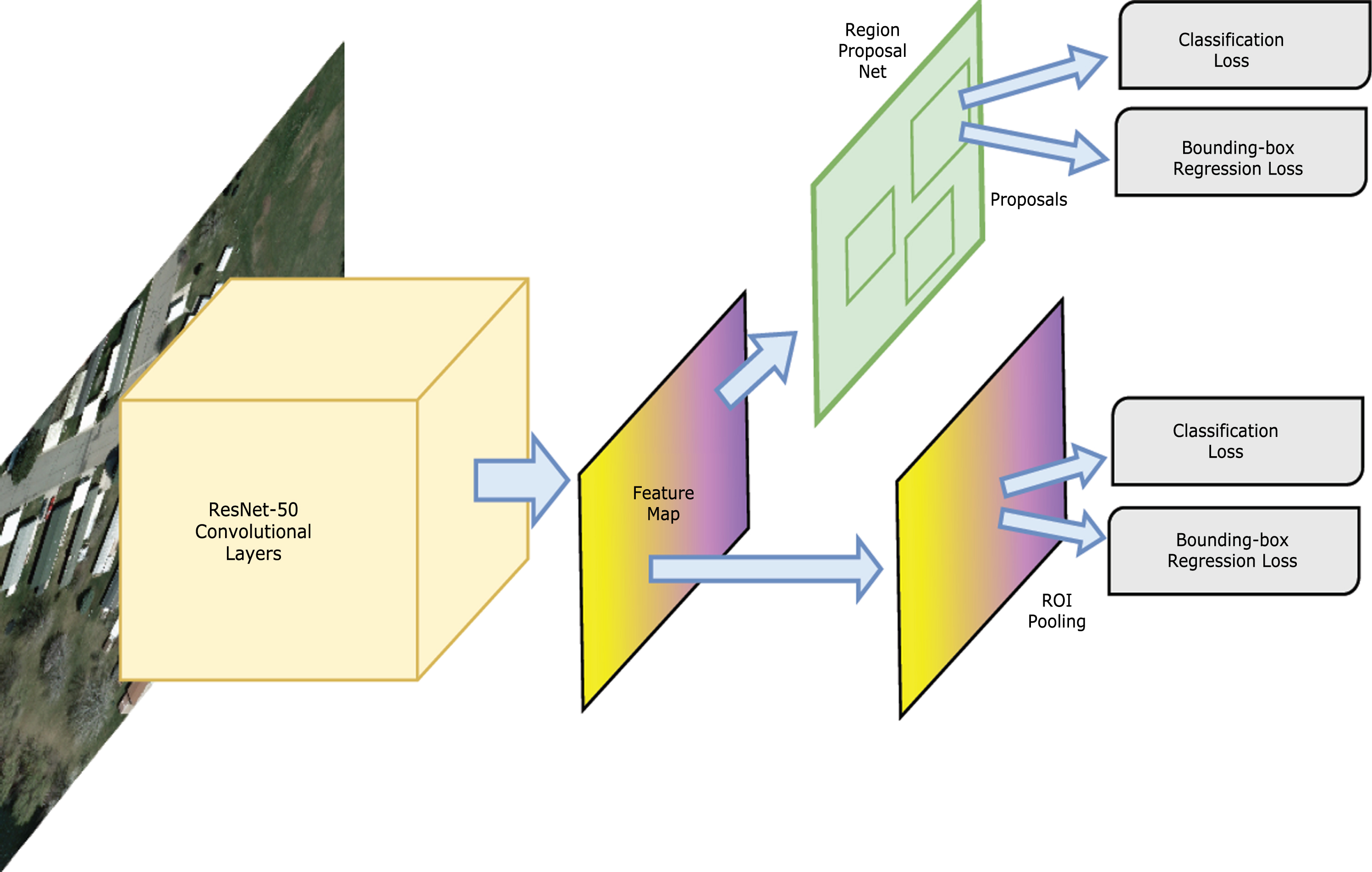
This image shows the Faster-RCNN Pipeline. Initial layers are convolutional layers of ResNet-50, which shares the final convolutional feature map with the RPN, which generates region proposals to be fed into the sibling classifiers and the Fast RCNN module. This RPN+ResNet combo replaces the selective search method of Fast-RCNN.
The CNN layers within the F-RCNN used here is a Residual Network or ResNet [2]. It is the winner of ILSVRC 2015 classification task and the authors claim that it is much less complex than VGG Nets, while being 8 times more deeper than the latter. They claim that ResNet overcomes the issue of degradation, which is the saturation of accuracy with subsequent stacking of deeper layers. As per the authors, residual connections in ResNet helps overcome this issue. It is achieved by adding shortcut connections between layers of a plain deep net. ResNet-50 is the fifty layer version discussed in the base paper. This work chose ResNet-50 over VGG16 [7], which was the original convolution layer used by authors of Faster-RCNN, mainly due to the fact that ResNet was able to produce better performance results and gave higher accuracy for object detection on the PASCAL VOC 2007 dataset. The final 1024 dimensional feature vector of ResNet-50, serves as input to the RPN. Detailed descriptions of the performance and experimental setups for ResNet can be found in [2]. Still the user can choose to train a VGG16 + RPN version of the Faster-RCNN pipeline. The source code has been designed with this functionality and details on the same is explained in the tutorial published in the GitHub repo. This would require the user to train the model from scratch because the model files provided in the repository is for ResNet-50 + RPN version of F-RCNN.
Dataset Description
VEDAI Dataset
VEDAI is a dataset introduced by Razakrivony et al. in [8], which is a collection of satellite images from Utah. It was mainly aimed at serve as a freely available dataset for small target detection in aerial images. VEDAI offers a varied mix of images having a dynamic background, from urban residential complex to barren rural landscape and contains vehicle samples from 9 different classes, namely, plane, camping car, tractor, car, truck, boat, van, pick-up and the other category. These vehicles are spread across various environmental setups with diverse colours, orientations and are sometimes occluded. In terms of diverse backgrounds, VEDAI offers vehicles on roads, city blocks, residential neighbourhoods, barren land, construction sites, parking lots, fields, woods, highways etc. In total, the dataset contains 1210 images in two resolutions namely, 512x512 and 1024x1024. This research uses the 1024x1024 images in RGB channel, although VEDAI offers a fourth IR channel. Along with the images, a text files with annotation of position, orientation, central pixel value, class label etc., are provided with the dataset. In total, 3322 vehicle instances are present in the dataset but, each class contains varied number of samples, which causes data biasing. In this work, the aforementioned bottleneck is overcome by treating all 3322 vehicles as belonging to a single class named ‘Vehicles’.
PASCAL VOC Dataset
PASCAL Visual Object Class dataset provides a baseline image dataset for the core purpose of object class recognition in images. PASCAL stands for Pattern Analysis, Statistical Modelling and Computational Learning. It brings with it a unique set of annotation style and accompanied tools to access this data. This dataset helps in evaluation and comparison of various object recognition models. According to the authors, PASCAL VOC challenge was designed to provide vision and machine learning communities a standard or benchmark dataset with standardized guidelines to perform object detection. The datset is updated every year and details of the same along with the download link can be found here 1 .
Methodology
This work aims at developing an end platform for the user to perform object detection tasks on images with state of the art results, without going through the hassles of setting up their system or debugging countless lines of code. It also demonstrates the capabilities of integrating computer vision systems to the internet and the benefits of offering the solution as an open source platform, to trigger future development via crowd-sourcing approach, where any developer or user has the full access to the source codes of the system, which enables them to commit or develop newer more advanced versions of the current model. The entire source code for this work, along with instructions on how to use it has been uploaded to GitHub and can be obtained at the link 2 This section discusses how the models for object detection for normal scenes as well as vehicle detection in satellite images were developed.
The DRSHTI web API offers the users access to two of the aforementioned models, out of which the object detection for normal scene model can be used for performing detection of everyday objects belonging to 37 different classes, like cars, buses, people, plants, dogs, horse, bike etc, to name a few. This model, takes as input, a regular image of any size and provides bounding box annotations for the detected classes of objects. The second model, which is the vehicle detection model for satellite images, helps track any ground vehicles, belonging to 9 different classes like plane, camping car, tractor, car, truck, boat, van, pick-up and others category. Both the models can be accessed via the following link. Two different models required two different training strategies as well as different dataset. The model for normal scene was trained on the PASCAL VOC [10] and the vehicle detection model for aerial images was trained on VEDAI dataset [9]. Both models were trained by employing transfer learning techniques, where pretrained weights were loaded prior to training. This made sure the models never overfit due to lack of training data. Training on PASCAL VOC dataset was primarily done to evaluate the models performance and its various dynamics. This step was crucial, as it helped in understanding the various parameters that governed the model and how to better prepare the VEDAI training data. The annotations had to be prepared in a unique way as stipulated by the PASCAL VOC annotation format. Each object in the image that needs to be included in the model has to be annotated by drawing bounding boxes around them and generating annotation files in text format. Each line in the annotation text file contains the following – filename of the ground truth image, the top-left and bottom right corner pixel values of the bounding box and a class label that defines the object within the bounding boxes. This unique annotation style demanded an in house solution and an OpenCV based annotation tool was developed. The annotations provided with VEDAI dataset could not be used for training the current F-RCNN pipeline. So, the annotation tool was used to produce new annotation for the entire 1210 images in the VEDAI dataset. Every vehicles, irrespective of what category (9 classes in VEDAI) they belonged to, were treated as class ‘Vehicles’. There were two main reasons to do so. One was due to the fact that VEDAI dataset contains different number of samples within its 9 categories, so this could cause class biasing while training and may cause the model to overfit. Another reason was to simplify the process of manually annotating 1210 images. This reduces fatigue as well as human errors and considerably reduces the data preparation time. Once the annotation text files for the VEDAI data was obtained, the model was trained and weights were saved.
The training was broken down to 3 main stages, through which both models were created and various dynamics and parameters of the said models were analyzed. The following are the 3 stages adopted to create the required models.
Stage 1: Train F-RCNN on PASCAL VOC Data. The PASCAL VOC Dataset was obtained from this link 3 . Annotations included within the dataset were used for training. Transfer learning techniques were made use for all three stages of model development. Weights pretrained on PASCAL dataset were loaded and new dataset was used to train the model for 20 epochs. This training was primarily done to check the model for parameters and metrics while training and hence limited to 20 epochs. It helped gain a better understanding of the pre-trained weights and the performance scores of the model. Trained model was tested on random images of varying size obtained from the web. Performance scores and other metrics related to the training are explained in the next section.
Stage 2: Train F-RCNN on VEDAI data with included annotations. VEDAI dataset comes with a proprietary annotation file with location and orientation information about vehicles inside each image. Behaviour of the model if trained on this annotation needed to be demonstrated to show why it is important to follow manual annotation in PASCAL VOC format. This also help to validate the performance of manually generated annotations for VEDAI data against standard annotations provided with the dataset. Included annotations had several erroneous points that had to be manually removed to clean it. The errors were mainly in the pixel value information. Once cleaned, the model was trained for 50, 100 and 150 epochs, to see how the model performance varied with number of epochs. Details of this is explained in the next section.
Stage 3: Train F-RCNN on VEDAI data with manually generated annotations. For this, an OpenCV based annotation tool was developed in-house because, readily available solutions were less tweakable to cater to the problem at hand. Every image in the VEDAI dataset with a resolution of 1024x1024 was annotated using the tool. The resultant text file along with the images were parsed to the model and subsequently trained for 50, 100 and 150 epochs, while creating checkpoints along the way. Train-test split was maintained at 90:10 ratio for both the models.
The Faster-RCNN paper discussed a model which used a VGG-16 in the initial layers. This work replaces the VGG-16 with a ResNet-50 and it is compared against similar solutions trained on VEDAI dataset to detect vehicles in aerial images. Details on model performance and its comparison with existing methods are discussed in next section.
Results and Discussions
The Faster-RCNN was used to develop two models as mentioned in previous section. The object detection model for normal scene was developed after training the net on PASCAL VOC dataset for just 20 epochs and the model showed very good performance wherein, the RPN classifier showed an accuracy of 97%. This was expected as the pre-trained weights loaded to the model is trained on an older version of the PASCAL VOC data and all that the retraining did was slightly diffuse the weights on more samples of same class type already seen by the model. This is also justification to the fact that the model gives good performance, even though trained only for 20 epochs. Anyway, this step of the process was done to verify the model performance and various data parsing techniques. It also helped in gaining insight into how to prepare the VEDAI dataset for training. This model can be used to detect objects belonging to 37 classes of objects, details of it can be found here 4
VEDAI dataset is used to develop the vehicle detection module for aerial images. The training of model was carried out under two case studies. One involved training the model using annotations provided/included in VEDAI dataset and another where annotations for the entire dataset was manually generated using a proprietary labelling tool developed in-house using OpenCV and Python. This tool was designed in such a way that the generated annotation /label files followed strict guidelines mentioned in the PASCAL VOC annotation scheme. The annotation tool loads images as batch from a folder and the user can click and drag with their mouse to create a bounding box around the object to be annotated (vehicles in this work). Class label of the desired object to be annotated can be inputted in specific part of the source code of the tool. Multiple objects can be annotated in a single image at a time, but the tool limits annotation of objects of only one class during a single execution, which means each class should be separately annotated in isolation, which is a potential drawback. More robust annotation tools are available, but the label files generated by these tools require a bit of manual cleanup and pre-processing before using it to train the model.
Initial case considered was to use images of resolution 1024x1024 along with VEDAI provided annotations. These annotation files are a bit tricky in how they store information about the objects/vehicles in the image. They hold info on the corner pixel values of the bounding box, central pixel location of vehicle, its orientation in degrees, its class label etc. Most of these values when tested using a sample ROI (Region-of-Interest) extraction program, returned erroneous results. Many pixel coordinates returned random patches from the image, although they were supposed to bound the vehicle instances within the image. This error was considered to be human error and was overcome by manually checking and clearing out false entries within the annotation file. Resultant annotation file was used to train the model. Training was done in three stages – for 50, 100 and 150 epochs. A standard train-test split of 90% -10%, which resulted in 1142 images for training and 127 images for testing. The total loss reduced from 0.647 at 50 epochs to 0.43 at 100 epochs, while it further saturated at 0.368 and stayed steady till 150 epochs. The training was limited at 150 epochs due to this and the final classifier accuracy for the bounding boxes from the RPN was reported as 94.4%. The total loss is sum total of all the losses from the sibling networks – the box classifier and the box regressor.

Images shows the real world performance of model trained on VEDAI provided annotation (images on the left with green bounding boxes) and model trained on annotations generated manually as per PASCAL VOC format (images on the right with blue bounding box). Notice that the images on the right do not contain mis-classifications like the ones on the left.
Next step, was to train the F-RCNN model on same images as before but, with proprietary annotation files generated in-house. This too was carried out under the same conditions and trials that were used to train the model with VEDAI provided annotations. Model was trained on newer annotation files for 50, 100 and 150 epochs. At 50 epochs, the total loss was 0.425 but decreased to 0.211 at 100 and saturated at 0.09 before 150 epochs. The classifier accuracy was reported at 98.6%. This shows a clear performance difference between both the vehicle detection models. The bump in performance maybe mainly attributed to the annoatation files. The former model used author provided annotations while the latter model was trained on newer annoatation files that were developed while following the PASCAL VOC annotation format. This new annotation was developed in-house and was manually generated using proprietary tools developed in OpenCV. The transfer learning technique initialized a pre-trained model weight that is trained on the PASCAL VOC dataset and the data parser in the model was pre-configured to accept PASCAL VOC style annotation file. Also the reason for lower performance score of model trained on VEDAI provided annotations could be attributed to false or erroneous label info in the files, which may have been left unnoticed or ignored during the cleanup stage. This performance difference is displayed in real-life performance, where the model trained on VEDAI annotation was giving more mis-classifications. It had higher tendency to loosely make detections on non-vehicle instances belonging to the background. Again, this could be attributed to false entries in the annotation file that may contain ROIs depicting background patches. These mis-classifications are clearly reduced in the model trained on in-house generated annotations. This model also has slight issues, which could again be traced back to the dataset used. This model has a tendency to classify building rooftops as vehicles, mainly in highly crowded scenes like residential areas, cities etc. It could be due to samples from one particular category within VEDAI named ‘trailers’, which share striking resemblance to rooftops, when viewed from above. This particular object also shares other key features with roofs of small buildings, like reflectance, shadow, geometry etc. Also, VEDAI has largest number of samples in ‘trailers’ class – nearly 350 instances. Removing this class in future training could improve these fairly rare mis-classification instances. Smaller size of the training dataset could also be the reason for these false classification, because the Faster-RCNN pipeline is a deep-net and require large and robust data for proper learning. Some comparisons of both models at testing is shown in Fig. 2. It is very evident that the first model (images with green bounding boxes on the left) makes more mistake compared to second model (images with blue bounding boxes). This better performing model was chosen to serve the vehicle detection pipeline for aerial images in the DRSHTI platform. Attributing to the fact that the model is still not perfect and needs more tweaking, the vehicle detector is offered as a proof-of-concept. The current model was also compared with existing solutions trained on VEDAI dataset. Since training on VEDAI dataset alone may not help the model to be more generalized, a benchmarking task mandated the use of models trained on same dataset. In 2017, a Cascaded CNN (VDN+VPN) [20] was introduced by Jiandan Zhong et al., which reported an accuracy of 78% in detecting vehicles. Wesam Sakla et al. trained a Faster-RCNN (VGG-16 + RPN) [21] with parameter changes to RPN on the VEDAI dataset and as per the authors, showed 93% accuracy. The model introduced for DRSHTI platform has significantly improved performance, where it gave detection accuracy of 98.6%.
This work aimed at creating a unified, open-source and easy to use web portal for users to perform object detection task on images. Deep Rectified System for High-speed Tracking in Images (DRSHTI), is made available to users and can be accessed via the link. It was designed to help beginner level users to perform object detection on images, thereby serving as a platform to learn more about this computer vision task. Keeping that in mind, all the source codes, model files, architecture and a detailed tutorial on its usage is made available through GitHub and can be accessed via link. Most of the existing solutions either require domain knowledge and programming skills to setup or in some cases it is not distributed freely. Here, the portal is freely accessible and source code is easily tweakable, which is aimed at encouraging development through crowd-sourcing from the online community.
Current platform offers two models, one for performing object detection on normal scenes, which includes everyday objects and another one which enables the detection of vehicles on the ground in aerial images. The former enables detection of nearaly 37 classes of objects while the latter is offered as a proof-of-concept, to demonstrate that the model is capable of performing small target detection in satellite images. The vehicle detection model is only trained on VEDAI dataset and would require more enhanced training on robust dataset to become a more generalized model and this is the reason to release the source code openly to the developer community, which could trigger more development with newer datasets. The vehicle detection model performed really well while training and gave a test accuracy of 98.6%, outperforming existing solutions trained on VEDAI dataset. Real-world performance justified these values but still required more development. The aim for the future is to train the vehicle detection pipeline on more data, to form a generalized model for vehicle detection and also incorporate a feature to perform class wise categorization of vehicles based on their type.