
Abstract
One of the major issues of road accidents all over the world is drowsiness state of the driver. It is a complex phenomenon to measure a driver’s consciousness in a direct manner. This work proposes with three deep neural architecture for learning facial features which consists of 68 attributes from the RGB video input of a driver. The experimentation is conducted by three different CNN models such as ResNet50, VGG16 and InceptionV3. These three networks are combined for representation learning which then put together the features to form a feature fused architecture(FFA). The trained features as well as facial movements such as eye blinking, yawning and head swaying are again trained with a softmax classifier to classify the drowsiness state of driver. Out of the three networks and FFA, InceptionV3 shows 78% accuracy.
Introduction
The drowsy state of a driver is one of the major cause in road accidents. The mortality rate due to drowsiness is very high because the acknowledgement, observation and vehicle control abilities reduces sharply when a person falls asleep. Most often drowsiness happens suddenly so that driver loss his consciousness and control that he cannot make awareness to co-driver [12, 19]. On the report of National Highway Traffic Safety Administration(NHTSA) [25], which is an agency of Department of Transportation in United States, it is approximated that one lakh crashes occurs in United States due to driver drowsiness or fatigue. It has been reported by NHTSA that in 2013, 72,000 crashes happened due to driver drowsiness.It also reported 800 deaths and 44,000 injuries due to the drowsiness state of a driver [32]. So the need of a system that can monitor driver’s behavioral measures is very much essential in order to prevent such devastating accidents. Therefore a video based system is proposed by capturing the behavioral measures of the driver.
The widely used measures for monitoring drowsiness are a) Measures which are based on Vehicles - These type of measures can include deviations from the position of the lane, steering wheel movement, pressure on the acceleration pedal, etc., needs to be constantly monitored. Any changes in these measures show that the driver is sleepy [1, 23]. b) Behavioral measures - The driver’s behaviour which includes, head swaying, yawning, eye blinking etc., is observed using a camera and then make the driver observant if any of the symptoms of sleepiness are detected [33, 36]. c) Physiological measures - These measures include the physiological signals such as Electrocardiogram, Electroencephalogram, Electromyogram and Electrooculogram [3, 22]. Other types of measures such as subjective measures are also used to detect sleepiness in a driver. These measures are based on the input from the driver, in which drivers will be provided with a set of questions in order to rate their level of drowsiness. It is based on this rating that the intensity of sleepiness of a driver is ascertained [27, 35].
This paper proposes a detection system for driver drowsiness based on feature learning using three deep neural networks. The approaches done previously are generally based on the eye closure, eyebrows shape and blink rate. In order to capture various facial features and other complex features which are non-linear, the proposed algorithm makes use of the features which are learnt using convolutional networks so that to capture various facial features explicitly and the complex non-linear feature interactions. To classify whether the driver is drowsy or non-drowsy, a classifier called softmax is used. This system is hence used for warning by sound alert in case of drowsiness or in attention to prevent traffic accidents. To prevent accidents which are caused by sleepiness of driver, autonomous systems can play an important role in the future intelligent vehicles which is designed to detect driver drowsiness and to analyze driver exhaustion. The proposed deep networks learn appropriate features for the task and then predict whether the driver is sleepy or not.
The network consists of three deep neural networks: ResNet50 [14], VGG16 [18] and InceptionV3 [4]. Given frame sequences of video, all the three networks are independently fine tuned for feature learning, which are related to drowsiness. Then they are fused which in turns to form a feature fused architecture(FFA) in which it classifies into any of the four classes as: non-drowsiness, drowsiness with head swaying, drowsiness with eye blinking and drowsiness with yawning.
Related work
There are some notable studies previously about drowsy state detection and monitoring of fatigue. For real-time detection of driver sleep states [5], which is also non-intrusive, many schemes based on computer vision have been developed by observing various facial features and visual signs. To reflect the person’s attentiveness and fatigue, the pattern of head movements, movements of eyes and facial expression changes need to be observed. Examples of some drowsy features which are of high fatigue and can be observed are head swaying, jaw drop, eye blinks, eyebrow shape, eyelid movements etc. These visual signs can be made use of by mounting a remote camera on the dashboard of the vehicle. This position can help to analyse and learn driver’s physical conditions, drowsy features and classifies the driver’s state as drowsy or non drowsy. It can be said that the computer vision techniques are acceptable widely and also is non-intrusive [6].
K.Dwivedi, K. Biswaranjan, and A. Sethi [15] in their paper proposed an algorithm which is vision based for detection of driver drowsiness using representation learning. In order to uphold the claims which are made in this paper, both quantitative and qualitative results are provided for the system. Convolutional Neural Networks are used for feature learning in this system and then classifies using a softmax classifier and as a whole this network have only two layers. To detect the faces, the popular Viola and Jones algorithm was used in the system. It is based on the visual facial features, drowsiness is detected. But the system does not considers yawning of a person and head swaying. Hence there are chances for the system to fail for detecting drowsiness. K. Murata et al. [17] presents a non-invasive system for drowsy driver detection due to alcoholism and the system detects the individuals which are alcoholic by measuring biological signals. To differentiate between normal and alcoholic person, the frequency time series analysis is used. This is the supporting factor in finding alcoholic drivers. It uses a non-invasive method which uses backpack sensors for the detection of alcoholic driving. These sensors are attached to the driving seat. The paper mentions the system as a non-confining method too. An air-pack pulse wave(AP-PW) will be extracted from the signals which are obtains. From the various examinations of AP-PW, an algorithm for drowsy driver detection due to alcoholism is generated in this paper. System shows variation if the measurements based on AP-PW are taken for more than 20 minutes due to the ingestion of alcohol. A novel system for the drowsy detection has been invented in this paper for non invasively monitoring the drivers state.
Lee and Chung [21] proposed a tracking system for the protection of driver, a method which uses a different outlook of data fusion approach. It uses diverse discrete data types for the purpose of tracking. The approaches can be in-vehicle temperature, eye features, variation in biological signal and vehicle speed. This system needs no monetary expenditure and is mainly developed as an application for devices such as Android based smartphone. No extra equipments are required other than the smartphone. The paper says that its high flexibility and resolution are the added advantages of this system. Attributes such as temperature, techniques like photoplethysmography (PPG), electrocardiography (ECG), and an accelerometer with three axes units are gathered. The inference analysis framework takes input variables as attributes. Bluetooth is used here to transmit the sensory data to mobile devices and for the other communication purposes to the mobile device. The system is also done with realistic testing. Multiple features are manifested in the system testing. Feature blending also makes the system effective for the detection of drowsy driving. A. Mittal [2] in his paper, proposes a drowsiness detection system which is said to be automatic and can thus keep away from accidents. Sequences of driving is considered in the system which is a vehicle based measure. This makes this system distinct from the other systems proposed before. It is by considering the abnormalities in driving pattern that the drowsiness state of driver. is detected. For this purpose various kinds of measures such as behavioral, subjective, vehicular and physiological measures have been used. A comparative analysis of the techniques are done. The analysis shows that that the easy to acquire ones are the behavioral measures. Also this system does not interferes the driver’s driving as the system in non invasive. This system considers the task of head nodding as the powerful measure to detect drowsiness during driving. Head nodding is considered to be precise as well.
Krajweski et al. [9] proposed a drowsiness system which is based on association between micro adjustments. It achieved an accuracy of 86% for the system for drowsiness detection. Drowsiness detection based on the pattern of driving is another case and driving pattern recognition method is used for this. Any variation in the position of lane is used for detection. So the car’s position can be observed by analysing the lane and deviation [8]. The systems which are based on the sequences of driving method depends on the condition of road, the mastery of driving and the various attributes of driving. Another class of techniques taken the driver’s physiological data from the physiological sensors like ECG, EEG, EOG. Details on brains activity are included in EEG signals. There are three different signals used for Electroencephalogram(EEG) for measuring driver’s drowsiness. Variations happen in these signals such as signal values spikes up or come down. The spiking up of signal values are considered as the drowsy states of the driver. While in EEG, two of the signals seems to spike up very high and the other having only a slight increase. Hence the paper focuses mainly on the physiological measures.
Method
Proposed system has a deep architecture in detecting drowsiness state of a driver from video input. Proper features are learnt by the network for the task and predicts whether the driver’s state is drowsiness or non-drowsiness. The network comprises three deep networks: ResNet50 [14], VGG16 [18] and InceptionV3 [4]. All the three networks are trained using Keras. The VGG net consists of 16 layers of which 13 are convolution layers and the other three are the fully connected layers. VGG has a model size of 533MB for VGG16 as the network is too deep. ResNet50 has 50 weight layers and the model size is 102MB. ResNet has a smaller model size but is much deeper than VGG16 because ResNet uses global average pooling whereas VGG uses fully connected layers. The model size of ResNet50 has thus been diminished. InceptionV3 network is 22 layers deep which includes 20 convolution layers and 2 fully connected layers. Inception V3 has its weight 96 MB, which is very much slighter than the other two networks. Each three networks viz. ResNet50, VGG16 and InceptionV3 are individually fine tuned for classifying the drowsiness states into four types such as non-drowsy state, drowsy state with eye blinking, drowsy state with head nodding and drowsy state with yawning. The features from the output layers of the three networks are again trained using a softmax classifier. Thus the driver state can be classified in to non-drowsy, drowsy state with eye blinking, drowsy state with head nodding, drowsy state with yawning. VGG16 and ResNet50 accepts 224x224 input image frames whereas Inception V3 accepts 299x299 input image frames. The three networks are then integrated such that the features of the last layers are concatenated, input videos are classified using a softmax classifier into one of the four classes based on this concatenated feature. To evaluate this drowsiness detection, National Tsing Hua University(NTHU)Drowsy Driver Detection video dataset [2] and a pretrained model of ImageNet is used. The NTHU video dataset contains 36 subjects which includes different genders for different people with different ethnicities, which is in five situations such as bare face, bareface at night, wearing glasses, wearing glasses at night and wearing sunglasses. A subset of ImageNet database is used to train the pretrained model and is trained on more than a million images so that the images can be classified into 1000 object categories.
Representation feature learning
By the instigation of models such as Convolutional neural networks (CNN) [34], Deep Belief Networks(DBN) [11], Restricted Boltzmann Machine (RBM) [13, 30], Deep Boltzmann Machines(DBM) [29], Autoencoders [10], Recurrent Neural Networks (RNN) [7, 26], the area of feature learning has got many significant improvements. Feature representation learning is effective for getting more intelligent features from the unlabeled data input. This is the success of these kind of models. Multiple hidden layers are used by most of the models so as to learn high dimensional representations which are non linear and complex which are fed in to a classifier for the classification.
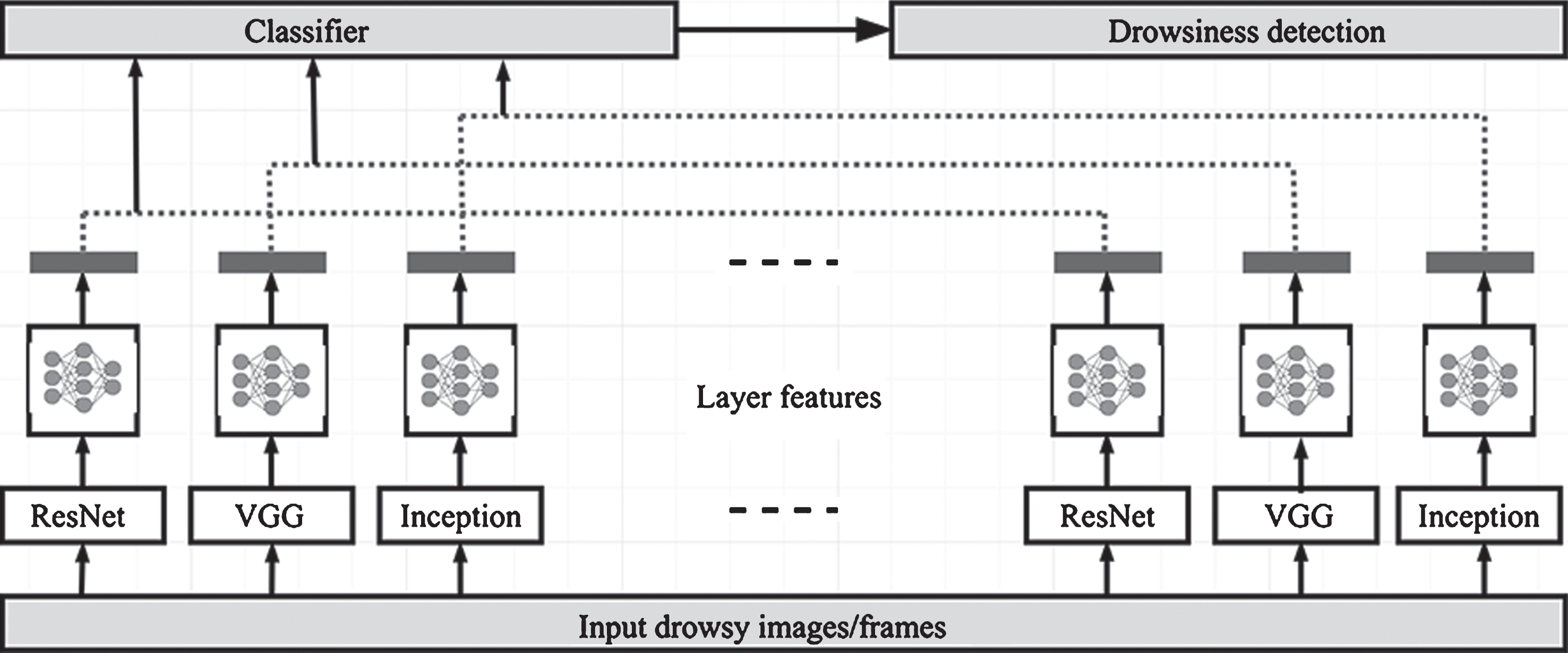
The framework of deep drowsiness detection neural network using Feature Fused Architecture.
Convolutional neural network or ConvNet or CNN is a kind of feed forward neural network with more number of hidden layers. Hence it is also called as a deep neural network. The CNN models used in the current system are ResNet which consists of 50 layers, VGG net of 16 layers and InceptionV3 of 22 layers. These three networks are then finally fused to form a feature fused architecture which is also a deep artificial neural network.
ResNet50
Deeper Convolution Networks are used to increase the accuracy level. Also it very difficult if the layers go very deep. Training errors can also happen on addition of more and more layers to deep networks [4, 16]. ResNets uses ’shortcuts’, also called as ’skip connections’ which allows skipping connections to the next layers which makes this neural networks too deep. Consider a residual architecture which is deeper provides a solution for adding additional layers to the network. Addition of each layer has an identity mapping. This addition of layers is done explicitly to fit residual mapping and thus reduce the training errors.
If M(x) denotes the desired mapping, the original mapping can be modified to M(x)+x, given the addition of layers fits to mapping of M(x)=F(x)-x. Thus it can be considered that the optimization of residual seems to be easier than the optimization of unreferenced mapping [14]. Suppose that the network have some activations in layer, a[L], then goes a[L+1]. Applying a linear operator and the ReLU non-linearity to a[L], to get a[L+1] is the main path of the network. This main path is not followed. Instead the particlulars from a[L] follows a shortcut path in order to go deeper into the neural networks. The Residual Nets are assessed on the ImageNet dataset with a depth of 50 layers. In residual learning, instead of trying to learn some features, the network learn some residual. Residual is known as its subtraction of features which are learned from input of that layer. By using shortcut connections, ResNet directly connects input of mth layer to some (m+x)th layer. ResNet50 implemented in the current system is trained using Keras library and it accepts 224x224 image inputs. The output of the last layer is then fed into softmax classifier for drowsiness classification.
ResNet is a form of architecture which is also called network-in-network architectures. Thus ResNet varies from other traditional neural network architectures such as OverFeat [28], and VGG [18]. ResNet relies on several modules called as ResNet modules. These modules are the building blocks for the construction of Residual Network.
VGG16
VGG architecture ranges its depth from 11 to 19 layers. The current system uses VGG16. The depth of VGG can be increased by adding convolutional layers. This can be made achievable by using extremely small convolution filters in all the layers. This is normally or fixed to 3x3 as this can be considered as the smallest size to capture the concepts of center, left-right and up-down. The input taken by VGG is a 224x224 fixed-size RGB image sequences. From each pixel, the mean RGB value is subtracted in the processing step and then evaluated on the training set. The image is passed through all the convolutional layers. The convolutional layers have filters with a very small receptive field: 3. A stack of two 3x3 convolutional layers without pooling in between has a receptive field of 5x5. The convolution stride can be fixed to 1 pixel. Spatial padding is done to preserve the spatial resolution after convolution in the convolutional layer. The five max-pooling layers does the pooling operation. The convolution layers are followed by max-pooling but not all convolution layers. VGG16 has three Fully Connected (FC) layers which follows the convolution layers. The first two FC layers have 4096 channels each, the third have 1000 channels as one for each class. Softmax is the final layer which is used for classification purpose. Hidden layer which lies between input and output layers have Rectified Linear Units, ReLU for non linearity. The VGG model is used in the Keras deep learning library.
Keras have two versions of VGG which are VGG16 and VGG19. By default, VGG takes an image size of 224 x 224 pixels as input and there are three channels for the color as well. VGG is comprised of 16 layers in the current system and hence is based on very deep Convolutional Neural Network architecture.
InceptionV3
Inception architecture organizes the convolutional layers into Inception blocks. These Inception blocks can be considered as the integrant constituents of an Inception network. Inception module has also got a property to perform as a multi level feature extractor. This is achieved by computing five(5x5), three(3x3) and one(1x1) convolutions in the very same module of the inception network. Computational complexity can be reduced by using these Inception blocks. These networks are made cheaper by limiting the number of input channels. Addition of an extra 1x1 convolutional layer before 3x3 and 5x5 convolutions can limit the number of input channels (Fig. 2). 1x1 convolutions are used as these are very cheaper than 3x3 and 5x5 convolutions. Along the dimensions of the channel, the concatenated outputs can then be stacked. This needs to be done before moving to the other network layers. The concept behind an Inception architecture is to find an approximation on ideal sparse structure in a convolutional network.
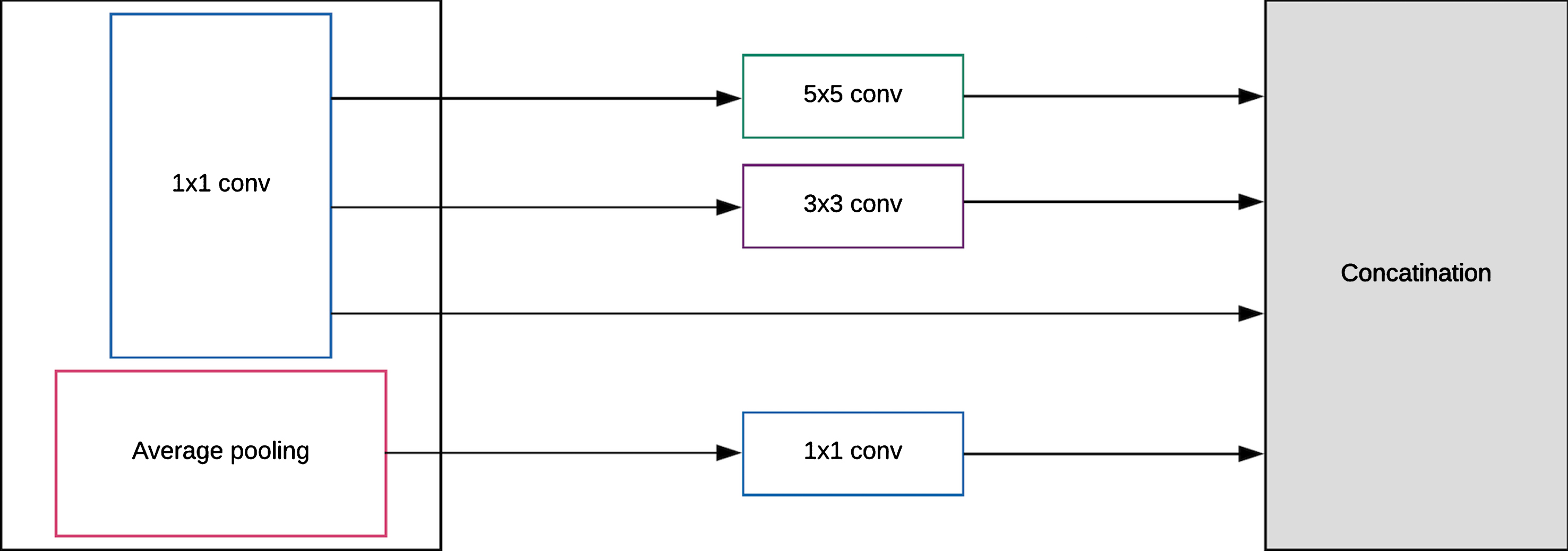
Inception module: Concatenation of the outputs.
The image input size of InceptionV3 is 224x224 which takes RGB color channels. This network is 22 layers deep while considering the layers with parameters. Else the Inception network has 27 layers including pooling layers. Rectified Linear Activation is used by the convolution layers. Inception Network takes average pooling rather than max pooling [24] which will be used before classifying an image.
Accuracy, specificity and sensitivity measurements of architectures
Accuracy, specificity and sensitivity measurements of architectures
The system is tested on a laptop equipped with MAC, Quad core Intel(R) Core(TM) i7 6MB L3 cache, 16GB RAM, and a RadeonPRO 555 with 2GB of GDDR5 memory (GPU acceleration not used). The experiment results are gathered using Keras > = 2.0. Irrespective of the situations being bareface, face with glasses, face with sunglasses, bareface during night and face with glasses during night, the drowsiness system classifies the drowsy state with an accuracy, same as that of a normal drowsy image. Even though the three networks viz. ResNet50, VGG16, InceptionV3 and the Feature fused architecture (FFA) classifies the drowsy state accurately, InceptionV3 network seems to outperform the other two and FFA with an average accuracy of 78.54% in various situations and 78.45% in different drowsy states of images of different persons (Table 1).
The graph (Fig. 3) shows the accuracy measurement of the three networks(ResNet50, VGG16, InceptionV3) and the feature fused architecture, FFA.
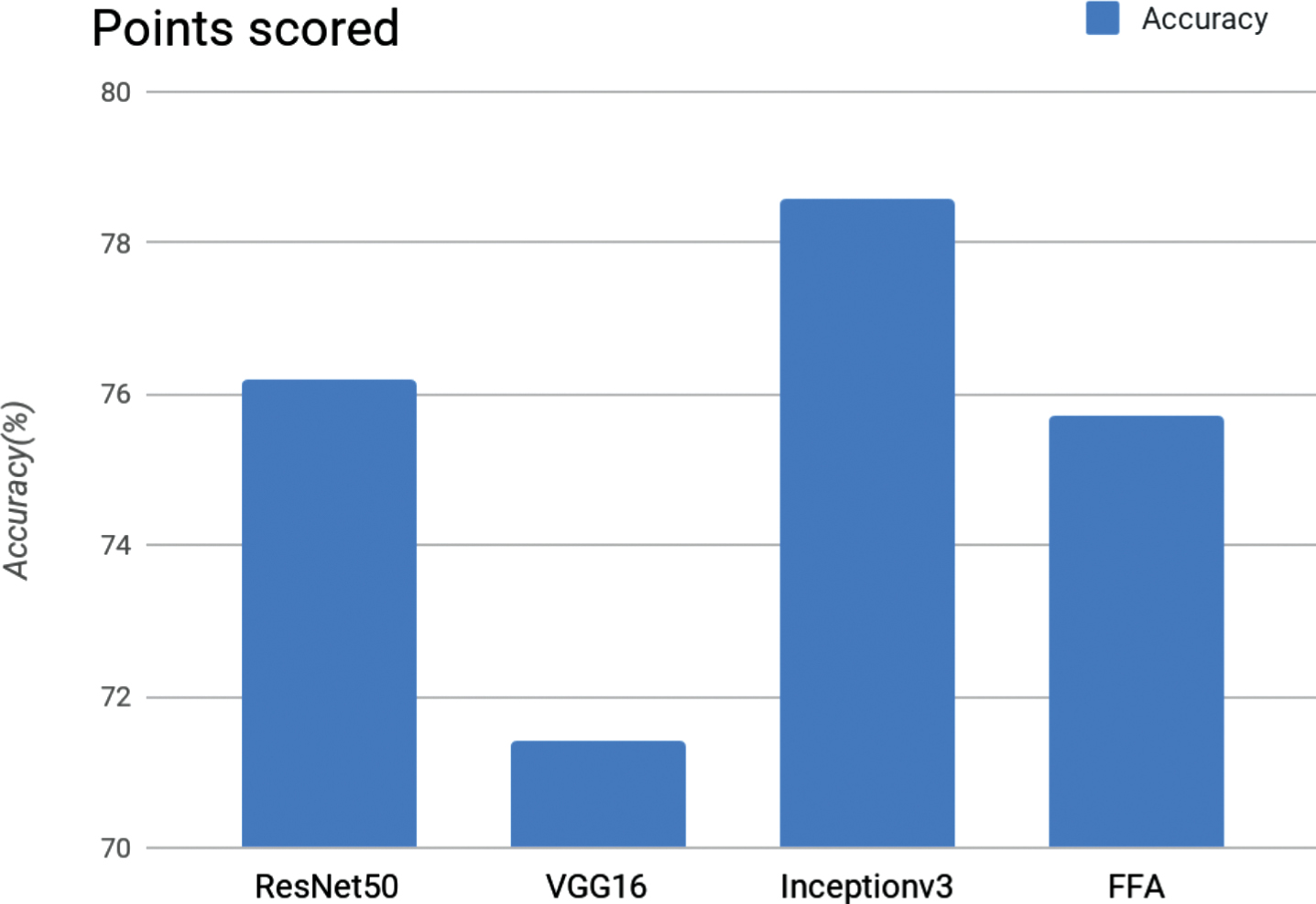
Accuracy measurement graph.
The system is tested by providing frame sequences of different people with different drowsy states which is shown on Table 2. The drowsy image/frameID mentioned in the table are the images/frames of different people.The test achieves an average accuracy of 71.25% for VGG16, 76.14% for ResNet50, 78.45% for InceptionV3 and 75.58% for FFA. From the analysis of various situations such as bare face, face with glasses, face with sunglasses, bareface during night and face with glasses during night, the accuracy rates are shown on Table 3 for the networks ResNet50, VGG16, InceptionV3 and FFA. The situation of drowsiness during night with glasses is illustrated in Fig. 4 and achieves an accuracy of 76.39% for ResNet, 71.12% for VGG16, 78.61% for InceptionV3 and 75.66% for FFA.
Drowsy system evaluation in different people
System evaluation based on various situations

Accuracy measurement of drowsiness with situation:Face with glasses during night.
This work presented a new approach to drowsiness detection based on representation learning using deep neural networks. The system being developed is a non-intrusive system to localize eyes, face and mouth and thus monitors driver fatigue. During monitoring, the system is able to decide whether the eyes are opened or closed, whether mouth is opened for yawning or not and whether head is swaying or not, in all the three networks namely ResNet50, VGG16, InceptionV3 and also in FFA, which is a fused architecture of ResNet50, VGG16 and InceptionV3. When any of the drowsiness signs are detected, a sound alert is issued. The proposed system was tested on driver images,frames and real time input videos of driver.
The future scope of the project lies in the task of enhancing the current single processing drowsiness detection system with multithreading, where the processes are shared and executes multiple processes or threads concurrently. Simultaneously running or executing tasks can enhance performance by decreased execution time. It also improvise GUI responsiveness. Further this system can be extended to monitor the reflect ray from eye using nano camera. The absence of reflect ray can be considered as the closure of eyes. These extensions can offer the drowsiness system with better enhancements.