
Abstract
Accurate detection and localization of eye features under spectacles - is quite a relevant but challenging problem in the application field of Human-Computer Interactive (HCI) systems. The ill-effects caused by the usage of spectacles like occlusion, glare and secondary reflection formation are termed as “The Spectacle Problem.” In this paper, the authors alleviate the spectacle problem by employing a two-image based data fusion approach. Detail-preserving filters like Joint Bilateral Filter (JBF) and Guided Image Filter (GIF) are compared individually, to find out the suitability and consistency of the filters in the proposed data fusion approach. Experimentation on CASIA NIR-VIS 2.0 and self-generated facial database demonstrate that GIF based filtering approach has higher local and global eye feature preservation capability while mitigating the spectacle problem.
Introduction
Human eyes constitute various prominent features like eyebrows, eye corners, eyelids, iris, pupil, and sclera. Detection of one or more eye features plays an important role in face detection, recognition, and Human-computer interaction (HCI) systems. Literature [1–5] suggests that eye feature detection accuracy decreases drastically when the user wears spectacles.
The authors term the problems pertaining to the spectacle usage as “The spectacle problem.”
The spectacle problem
Spectacles are one of the most commonly used face accessories throughout the world. Though the spectacles occupy less area (in terms of number of pixels) in a human facial image, the impact of spectacles on eye/face feature detection and recognition is substantial.
The main problems due to spectacle usage are (see Fig. 1): Occlusion [3–6]: Depending on the age, comfort, and the nature of how the user wears - spectacles can occlude some/most of the eye features like eyelids, eyebrows, and iris. Illumination changes [4]: Depending on the nature of the illumination type, intensity, and concentration of illumination, there are two types of reflection problems. Glare: Glare corrupts most of the pixel information by replacing the feature pixel values with high saturated intensity values. This kind of corruption occurs in NIR illumination, and the corruption is concentrated within a few pixels. Secondary reflection: Secondary reflection might change the eye feature appearance by altering the pixel intensity values. This type of corruption occurs in VIS illumination, and the corruption is more distributed across the spectacle region.

Sample images illustrating the Spectacle problem. (a) First row: Occlusion by frame; (b) Second row: Glare; (c) Third row: Secondary reflection.
Both occlusion and illumination changes – have the capability to either block or alter eye feature information which results in performance inaccuracies.
In real-time scenarios wherein the control over illumination changes is less, the challenges provided by the spectacle problem are hard to be nullified. These inconsistencies in spectacle problem removal are yet to be thoroughly investigated and addressed.
In this paper, the authors present a method by exploiting the detail preserving filters as a bridge to achieve the purpose of mitigating the ill-effects of spectacle problem.
Though several studies on the topic of spectacle detection and removal have been reported, the study focusing on occlusion, secondary reflection and glare removal is very limited. The major hindrance in solving the spectacle problem is due to the ill-posed nature of the problem. This hindrance is due to the limitedness or non-availability of data in the regions affected by the spectacle problem. Of the limited available literature – based on the number of input images, the spectacle problem removal methods can be classified into two categories: Single image methods, Multiple image methods.
Single-image-based methods
Single image category methods mostly rely on the information provided by the neighborhood pixels/patches to repair the corrupted image areas. These patches might be extracted either locally or globally. Several inpainting techniques have been applied to fill-in the corrupted regions by propagating information from the extracted similar patches. Though the inpainting methods are easy to be implemented, it has been observed that the output images may still contain ambiguous corrupted local information [3]. Better results were reported in [7], wherein a user has to select the pixels related to the spectacle problem painstakingly. However, this user intervention approach is highly time-consuming.
As glare and occlusion corrupt the underlying eye feature information, it is difficult to reconstruct a seamless reflectionless image from a single input facial image.
Multiple-image-based methods
Multiple image category methods utilize multiple input images for eliminating the spectacle problem. The input images can be either a sequence of images of the same person taken under varying illumination conditions or at different time and location. A significant advantage of these approaches is that because of the availability of redundant data; it is relatively more straightforward to repair the corrupted pixels from the corresponding uncorrupted pixels.
To the best of our knowledge, the following three are the most sophisticated solutions mentioned in the literature: Sample-based learning [2]; PCA based approach [1]; Low-rank based approach [4].
[2] is a sample-based approach that learns from the statistical mapping between face images with and without spectacles. Based on this analysis, a seamless facial image without spectacle problem is reconstructed for a given input facial image with spectacle problem. [1] tries to generate a seamless facial image without spectacles by recursive error compensation using PCA reconstruction. Both these methods rely on the exhaustiveness of the availability of facial images with and without spectacles in the training set. [4] is based on the assumption that facial images subjected to various illumination conditions tend to lie on a low-dimensional Lambertian space. Therefore, any given sequence of multiple images is decomposed into the Low-rank and Sparse component. The low-rank part retains most of the uncorrupted facial features while the sparse component part retains the pixels related to the spectacle problem. Unlike [1, 2], this method does not need prior training. Another added advantage of this method is that it requires few tuning parameters.
Even though multiple image methods provide better results as compared to the single image methods, they have the following limitations: Requires a large training set or a sequence of images as input to achieve satisfactory results. Because of the usage of a large number of input images: resource, computational and time complexity of these methods are quite large.
To sum up, both single and multiple image methods have several constraints that limit their usability in real-time applications. Therefore, two-image based approaches were developed to address these issues.
Two-image-based methods
Generally, the two-image based approaches rely on learning a mapping function from a guidance (prior) image to adjust or enhance the details of the target (input) image. Eisemann and Durand [8], Pitie et al. [9] and Agarwal et al. [10] are the state of the art algorithms under this category. When applied to the spectacle problem removal application, these image quality enhancement algorithms do not provide a seamless high-quality output images (see Fig. 3 (B): 1(a-c), 2(a-c)). These inconsistencies are yet to be thoroughly investigated, and there is a scope of improvement.
So, in this paper, the authors formulate to solve the spectacle problem by using a data fusion approach which draws a good compromise between feasibility and quality of solution for the spectacle problem. The major improvement of the proposed approach as compared with the previous methods is - better results with a significant reduction in time complexity.
Spectacle problem removal: Problem formulation
Specularity problems occur when an illumination variation cause a disproportionate brightness of the object (here spectacles). These unwanted artifacts like glare and secondary reflections occlude or alter the eye feature information. To alleviate this problem, a two-image based data fusion approach is employed, wherein the details from both the images are used to fuse and synthesize a new image of higher feature quality.
Of the methods discussed in Section 2.2.1, in [9, 10] a transformation function is estimated based on the color information of the prior image. Therefore, the usability of these methods is limited to visible (color) illuminated images only. On the other hand, [8] can be applied on both visible and NIR (monochrome) illuminated images. So, our proposed approach draws inspiration from [8] and extend its idea to suit the spectacle problem removal application.
[8] transfers image details holistically at the expense of capturing finer details. This information loss generates severe artifacts in the output image results as illustrated in Fig. 3 (B): 1 (a) , 2 (a). In the proposed approach, the authors try to mitigate these artifacts by using detail preserving filters to extract the desired features like edges, texture, and small details of the prior image (P) and combine them with the large-scale component of the given input image (I). By fusing the two images, an output image (O) is rendered by redeeming the ill-effects of spectacle problems. A few sample images of prior and input images are shown in Fig. 2.

First & Second columns: Samples of prior images (without spectacle problems); Third & Fourth columns: Samples of input images (with spectacle problems).
In the literature, Joint Bilateral filter [11] and Guided image filter [12] are among the most successful detail preserving filters. In this paper, the authors use each of the filters individually and compare the performance and suitability of these filters regarding eye feature details preservation.
In this particular case of spectacle problem removal, the prior image P is assumed to be either a facial image without spectacles or a facial image with spectacles (but without any spectacle problems). Input image I is a facial image corrupted by spectacle problem. The prior image is used to replace the corrupted pixels of I and the filtered output image O (.) is obtained as:
Guided image filtering output O (.) is generated as a linear transformation function of the guidance image P in a local window w:
The x
j
and y
j
coefficients of the Equation (3) are determined by an energy function:
The main objective of this experimentation section is to validate the suitableness of the data fusion formulation in the spectacle problem removal application. We have considered the following state-of-the-art approaches for comparative analysis: Single image method [3]; Two image-based methods [8–10]; Multiple image-based method [4]. Four experiments were designed to evaluate the performance of the proposed algorithms - visually, qualitatively and quantitatively.
Database
To validate any spectacle problem removal algorithm, a database consisting of corresponding facial images with and without spectacles is required. An exhaustive literature survey on the availability of such databases, reveals the following facts: The availability of databases consisting of corresponding facial images with and without spectacles is very limited. Databases highlighting the spectacle problems like glare, occlusion and secondary reflection are even scarcer.
Among the limited available databases, the CASIA NIR-VIS 2.0 Face Database [13] meets a few of the algorithm validation requirements.
CASIA NIR-VIS 2.0 Face Database
CASIA NIR-VIS 2.0 Face Database is a heterogeneous database consisting of 169 pairs of facial images with and without spectacles. Of the 169 image pairs - 75 are taken in NIR illumination condition, and the remaining 94 are taken in visible light illumination. The main drawback of using this database alone for validating the proposed algorithm would be that it does not provide much emphasis on the spectacle problems like glare, occlusion and secondary reflection.
Self-captured database
To increase the credibility of the proposed algorithm, the authors have created a database of 144 facial images with more emphasis on the spectacle problems [14]. The dataset consists of facial images of 10 subjects with images taken under three categories, viz: without spectacles, with spectacles (without any spectacle problems) and with spectacle problems. A few samples of the facial images from our database can be seen in third and fourth columns of Fig. 1.
Experiment 1: Visual inspection
Figure 3 presents the sample output images of [3, 8–10] as well as the proposed spectacle problem removal algorithms. For a better and detailed visual comparison of the output rendered images, a portion of the image is zoomed and produced in Fig. 4.

Sample output images and their respective approaches - Results of (A) Single image approach [3]:: (B) Two image approaches: [8]: 1(a), 2(a); [9]: 1(b), 2(b); [10]: 1(c), 2(c); Proposed approach based on JBF filtering: 1(d), 2(d); Proposed approach based on GIF filtering: 1(e), 2(e):: (C) Multiple image approach: [4].

[3] fails to generate a seamless output image as it retains most of the ambiguous corrupted local information. In case of two image-based approaches, it is quite evident that on appending the proposed detail preserving filters to [8], the spectacle problem artifacts are less transferred onto the output image as compared to [9, 10]. On close observation, the JBF rendered outputs (see Fig. 3 (B):1 (d) , 2 (d)) are not as seamless as compared to the results produced by the GIF filtering approach (see Fig. 3 (B):1 (e) , 2 (e)). This limitation of seamlessness in JBF rendered outputs is due to the unwanted gradient reversal artifacts [12] which occur near the edges (here: spectacle frame boundaries). Due to the unaligned facial image inputs (especially in the custom database), the multiple based approach [4] fails to capitalize on the redundant information and produce unsubstantial outputs. Another observation worth mentioning is that the output results vary with respect to the type of spectacle frames used. The output results are comparable when the user wears rimless spectacles, and degrade when the user wears dark colored full-rim spectacles.
For qualitative measurement of the visual similarity between the prior image and the output rendered image, the authors considered three metrics, namely, Peak Signal to Noise Ratio (PSNR), Structural Similarity (SSIM) index, Edge Keeping Index (EKI). PSNR and SSIM are used to quantify the amount of visual and structural information retained in the output rendered image. On the other hand, edge preservation capability and discrepancy in edge location between output and the prior image is determined using EKI. The basic definitions and mathematical formulations of the metrics are as follows:
PSNR
Mean Square Error (MSE) represents the cumulative squared error between the reconstructed and the prior image, whereas PSNR (in dB) represents a measure of the peak error.
The Structural Similarity (SSIM) Index [15] is used to measure the structural correlation between the input image and the output rendered images. The index measurement is based on the multiplicative combination of structural term, contrast term and the luminance term.
SSIM index measure varies between 0 and 1, where 0 corresponds to structurally completely uncorrelated images, and 1 corresponds to similar images.
Most of the eye feature detection and recognition depends on the feature retaining capacity of the approaches. One of the most important features to be retained are edges. So, to assess the edge preservation capacity of the filters, EKI metric is used [16].
Performance indices values of few sample images is shown in Fig. 5, whereas the overall indices value distribution is presented in a boxplot shown in Fig. 6.

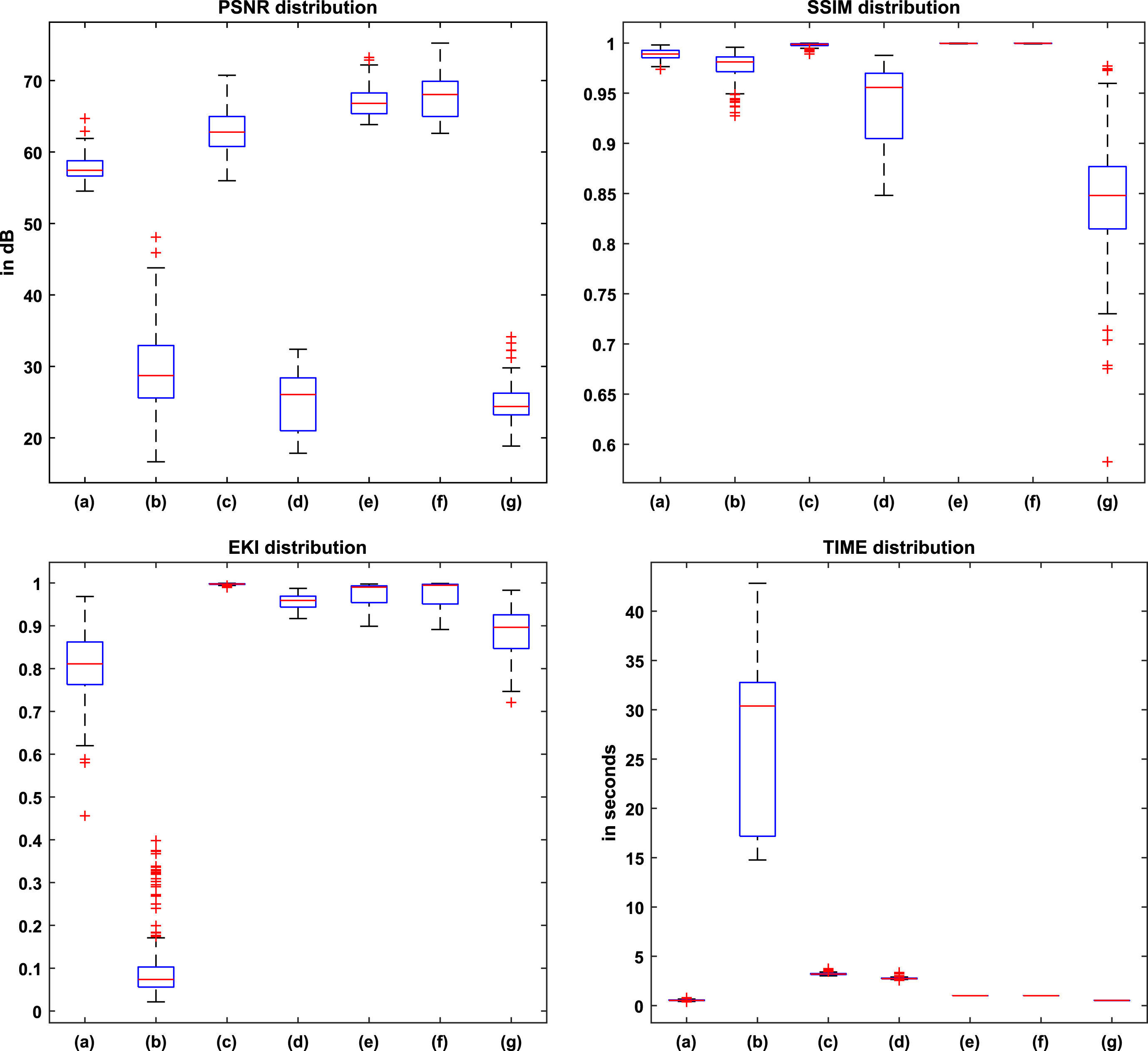
From the results displayed in Fig. 5, it is evident that the proposed filtering methods enhance the results of [8]. Visually, the proposed two filtering methods produce indistinguishable reconstructed images. But, the boxplot distribution in Fig. 6 indicates that the average similarity index values of the GIF filter are a tinge better than the JBF filtered based outputs. This is because of the better detail preserving capability of the GIF filter. Though minuscule, this difference in image similarity values is of great importance because it emphasizes higher image quality, better detection, and localization possibilities. The results (SSIM and EKI values) produced by [9] are equally good as the proposed approaches, but the usability of the method is limited to color images only.
Both visual inspection and similarity measurement experiments showcase the superiority and suitableness of the proposed approaches.
To validate the consistency of feature preservation capability among the output rendered images, the authors have conducted the following two experiments.
In this experiment, the global feature detection capability of the proposed algorithms is verified by detecting eye-pairs in both the prior image and the output rendered image. [17] is employed for detecting the eye-pairs and few of the output results are shown in Fig. 7.

Each sub-plot contains eye-pair detection output images of a given input image and it’s GIF filtering counterpart. Example results of (a,b) successful, (c,d) successful after filtering, (e,f) unsuccessful eye-pair detection.
The percentage of successful eye-pair detections before preprocessing the database images is 62.65. This emphasizes the ill-effects of the spectacle problem. After applying the respective algorithms, there is a significant increase in the number of successful eye-pair detections (see Fig. 8). The proposed GIF filtering based approach has the highest success rate of 87.65 followed by JBF filtering based approach at 83.86.

To validate the efficacy local feature preservation capability, an experiment on local feature matching (here corners) is conducted. The authors cross-verify whether the same features can be detected in both the prior image and the output rendered image. Local features were detected from both the images using Harris feature detector [18]. Later, the detected features were matched by the BRISK descriptors. Sample output images are shown in Fig. 9.

Percentage of Harris features retained after JBF filtering and GIF filtering.
The overall number of features retained is shown as a distribution in a boxplot Fig. 10.

From the experiment results, it is quite evident that the proposed approaches retain more local features than the rest of the spectacle problem removal algorithms.
All the experiments were conducted on a PC with Intel (R) core (TM) i3 CPU and 4.00 GB RAM. The algorithms were implemented in MATLAB R2017a without any GPU acceleration. All the images were resized to a resolution of 256X256. In case of color images, each red, green and blue channel were processed independently. All the parameters of the filters were tuned to attain the best possible image quality index values.
Discussion and Conclusion
Eye feature detection and localization under spectacles is an important and challenging problem. From the experiments conducted above,the authors conclude that the data fusion based detail preserving filters can be considered as a potential solution for mitigating the spectacle problems. Being a simple extension to the popular [8], our method enjoys the benefits of simplicity, speed. Both JBF and GIF based filtering techniques produce comparable results in terms of visual similarity, but GIF filtering based approach provides better local and global feature preserving capability. Another major advantage of GIF over JBF is that GIF is a faster filtering approach. The average time taken by JBF filtering based approach to run on a 256X256 image is 1.972841 seconds, while the GIF based approach can be executed in 0.040579 seconds. It reinforces our claim that the proposed approach can be used for real-time applications.
Future scope
The detail preserving filter algorithms works well for aligned facial images only. This weakness may be mitigated by considering a preprocessing step of face wrapping in case of unaligned input facial images. Even though most of the spectacle related problems are being removed by the data fusion approach, still the reminiscence of the reflection can be found in some of the rendered output images (see Fig. 4). Therefore, future work can be to minimize the reminiscence error and to increase the capability to retain the dynamics of the input image.