
Abstract
Recently, sentiment analysis has become a focus domain in artificial intelligence owing to the massive text reviews of modern networks. The fast increase of the domain has led to the spring up of assorted sub-areas, researchers are also focusing on subareas at various levels. This paper focuses on the key subtask in sentiment analysis: aspect-based sentiment analysis. Unlike feature-based traditional approaches and long short-term memory network based models, our work combines the strengths of linguistic resources and gating mechanism to propose an effective convolutional neural network based model for aspect-based sentiment analysis. First, the proposed regularizers from the real world linguistic resources can be of benefit to identify the aspect sentiment polarity. Second, under the guidance of the given aspect, the gating mechanism can better control the sentiment features. Last, the basic structure of model is convolutional neural network, which can perform parallel operations well in the training process. Experimental results on SemEval 2014 Restaurant Datasets demonstrate our approach can achieve excellent results on aspect-based sentiment analysis.
Keywords
Introduction
Sentiment analysis [25, 35] is indispensable in modern social networks [1] with the rapid growth of text reviews. It provides a cornerstone for many downstream applications such as smart environments [23, 47], customer-analyzing system [54] and text data security protection [52]. In this paper, we focus on aspect-based sentiment analysis (ABSA) [22], which is an essential and challenging subtask in sentiment analysis. Instead of predicting the overall sentiment polarity of a sentence, the aim of ABSA is to infer the sentiment polarity (i.e., positive, negative, or neutral) on a specific opinion aspect expressed in a sentence. For instance, consider the sentence: “The environment is very beautiful, but the food is dreadful!”, two opinion aspects are mentioned: “environment, food”. The sentiment polarity of aspect “ambience (environment)” is positive but negative when considering the aspect “food”.
Traditional approaches for ABSA mainly focus on designing a number of features, such as using the sentiment lexicons [15, 41], combining n-grams and sentiment lexicon features [48]. Nevertheless, feature engineering is labor intensive and almost reaches its performance bottleneck.
As machine learning [10, 51] advances, especially deep learning [6, 46] and [57], some researchers have designed effective neural networks and have obtained promising results on the ABSA task. Such as Recursive Neural Network [9, 33] and Recurrent Neural Network [45, 49]. Despite the effectiveness of these approaches, they still have some drawbacks. First, neural networks are largely depended on a great deal of data; and the purely data-driven learning will result in uninterpretable results [32]. Second, from the viewpoint of human beings, we can conclude that people learn not only from specific examples (as DNNs do) but also from knowledge and experience [20, 30]. However, the previous studies almost neglected the role of human knowledge. Last, the models’ results sometimes are easily affected by bias in data. Unfortunately, Nakov et al. [31] pointed out that class imbalance is still a problem awaiting solution in sentiment analysis.
The purpose of our work is to improve models’ interpretability but also to fully employ linguistic resources in real life (human knowledge) to benefit ABSA. Through the sampling analysis of the dataset, we find that some sentences have obvious linguistic rules that can be employed. For instance, “Decor is nice though service can be spotty.”. There exists an adversative conjunction (AC) “though”. As we all know, an AC expresses opposition or contrast between two statements, then the conjunction “though” plays an important role in a sentence, thus sentiment polarities of two aspects before and after “though” should be opposite. Besides ACs, we also found that coordinating conjunctions (CCs) have a similar effect. “Best of all is the warm vibe, the owner is super friendly and service is fast.”. In this example, the CC “and” shows that the sentiment polarity of each aspect is positive. Table 1 is the data statistics for the SemEval 2014 restaurant dataset, we give the number of ACs and CCs in which. As shown in the Table 1, the linguistic rules which we found are widely used in dataset. This phenomenon intuitively demonstrates the great potential of linguistic resources in the ABSA.
The data statistics for the SemEval 2014 restaurant dataset
The data statistics for the SemEval 2014 restaurant dataset
Based on the analyzed above, we combine the strengths of linguistic resources and gating mechanism to propose an effective convolutional neural network based model called GLRC to address the problems in ABSA. Specifically, GLRC using convolutional neural network (CNN) [18] as the basement firstly. Convolutional layers with multiple filters can efficiently extract n-gram features at many granularities on each receptive field. After that, following [53], we used the gating mechanism. The gating units have two nonlinear gates, each of which is connected to one convolutional layer.
With the given aspect information, they can selectively extract aspect-specific sentiment information for sentiment prediction. Finally, we apply the proposed linguistic regularizers on the model to help predict the sentiment on the aspect. In a word, the advantages of our paper are listed as follow: We model two linguistic regularizers according to the linguistic resources in real life. The coordinating conjunctions regularizer and adversative conjunction regularizer (CCR&ACR) improve the model’s interpretability. GLRC performs well on the SemEval 2014 restaurant dataset, and further cases demonstrate the linguistic regularizers works well for ABSA. GLRC is the first attempt to study linguistic r sources in ABSA task.
GLRC
Figure 1 gives the framework used in ABSA. GLRC includes Word Embedding, Convolutions & Gating Mechanisms, Max Pooling and FC-Layer with Linguistic Regularizers. We describe these parts in detail below.
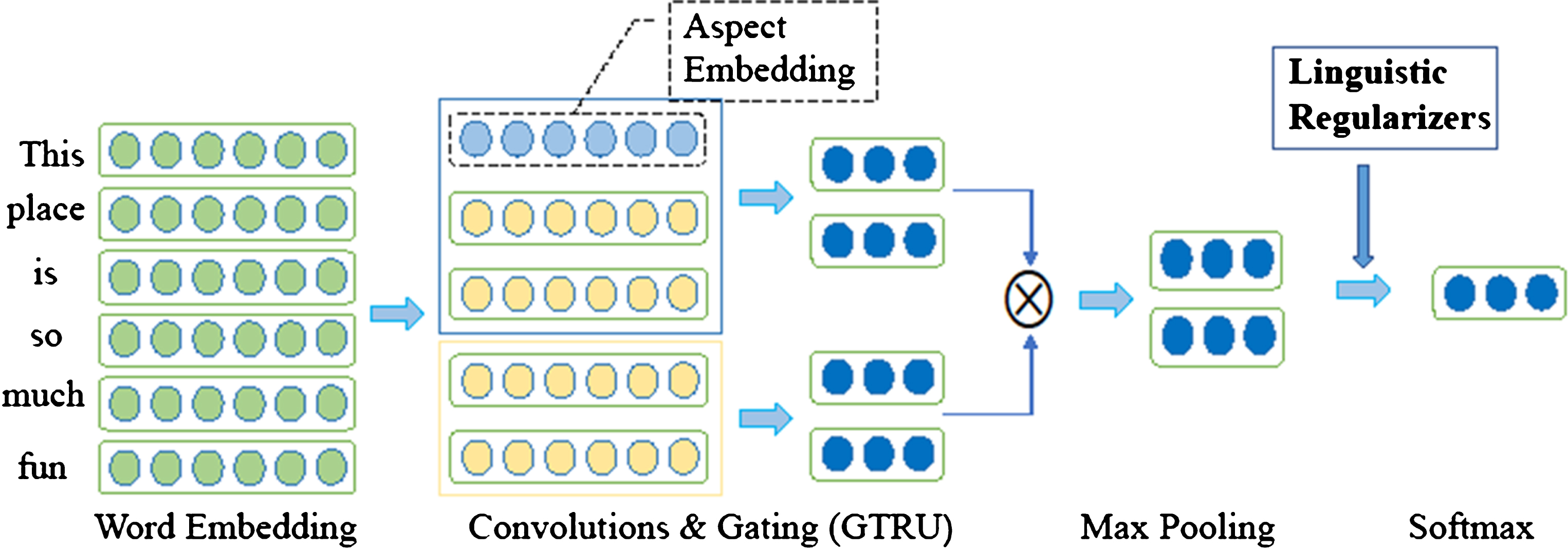
Illustration of our model GLRC for ABSA.
The input of model is a continuous sentence whose length is n (padded where necessary). Word embeddings model the context and the relationship between context and target words through neural networks. Because of the flexibility of neural networks, the biggest advantage of word embeddings is that they can represent complex contexts. With the help of word embeddings, the performance of various natural language processing (NLP) tasks [13, 37] has been greatly improved. There are so many works about how to get high quality word embeddings [2, 26]. We employ the method proposed by [29] to train word embeddings.
Convolutions & gating mechanisms
The convolution operation can be seen as a calculation between a vector w and a sequence x. The weights matrix w is regarded as the filter for the convolution. For example, if the length of the input sentence is n, it will be represented as X = [x1, x2, …, x
n
] where x
i
is the i-th word. The convolution operation uses a filter w to perform a dot product operation with the sequence x to obtain a new sequence. Specifically, a feature c
i
is generated from a window of words xi:i+h by
As the Fig. 1 shows, we used the GTRU with aspect embedding connect to two convolutional neurons at each position t. Through the GTRU, the c
i
will become:
Here V a is the aspect embedding, the convolutional features a i receive additional aspect information V a with ReLU activation function. Specifically, s i and a i are responsible for generating sentiment features and aspect features respectively. In ABSA, sentiment polarities of different aspects maybe different in the same sentence. For positive, the ReLU gate is no upper limit but strictly 0 for others. Therefore, it can output a similarity score according to the relevance between the given aspect information V a and the aspect feature a i at position t. If the score is 0, the s i will block; otherwise, its magnitude would be amplified accordingly.
The pooling function replaces the output of the network at a certain location with the overall statistic of the adjacent outputs. Recently, many pooling functions have been proposed: max-pooling [59], global average pooling [21], k-max pooling [17] and dynamic pooling [42]. In GLRC, max-pooling is used. Max pooling is taking the maximum value of a dimension. The purpose of max-pooling is to obtain the most significant information in the entire window. Ideally, each dimension will “specialize” a specific kind of predictor, and the max-pooling will select the most important predictor for each class. In addition, Zhang et al. [58] observed that 1-max pooling uniformly outperforms other pooling strategies in sentence analysis.
FC-layer with linguistic regularizers
FC-Layer represents fully-connected layer. In this layer, we employ dropout to prevent over fitting. Then add a constraint to the loss function as the regularization term, which is the linguistic regularizer (there will be a detailed introduction in section 2.2). Finally, we use a softmax to produce the output.
Linguistic resources
As mentioned in Section 1, when checking the training data, we found many sentences contain obvious linguistic rules. For example, considering a sentence “The restaurant was expensive, but the menu was great.”, “but” is a turning point obviously: before “but”, sentiment polarity of aspect “price” is negative; after “but”, sentiment polarity of aspect “food” is positive. We summarize and model two linguistic rules that are widely used in real life.
Considering such a sentence “Very good service and very good prices.”. Two aspects “service” and “price” are appeared in this sentence, their sentiment polarities all are positive. CCs like “and” play such a role: the sentiment distributions of aspects which before and after “and” should not vary much. We model this phenomenon as follows:
Where P E , P F are sentiment distributions of two aspects E and F. M is a hyperparameter for margin, and D KL (P, Q) is a symmetric KL divergence:
The ACR shows how ACs change the sentiment distribution of its context. When a sentence contains an AC, sentiment distributions of two aspects should be changed corresponding. Just like “The appetizers are ok, but the service is slow.”, sentiment polarity of aspect “taste(appetizers)” that before “but” is positive, while on aspect “service” that after “but” is negative. We collect the ACs that appeared in the dataset manually since the number is small, they can be seen in Table 2.
List of the CCs & ACs from the SemEval 2014 restaurant dataset
However, there exists another situation: the ACs maybe change the polarity from negative to positive or neutral. To respect such complex effects, we propose a transformation matrix T for ACs, and the matrix T will be trained by the model. ACR assumes that a sentence contains an AC, the first aspect’s sentiment distribution should be changed to close to the second aspect by the transformation matrix T.
where
To employ the context words and the two linguistic regularizers fully, we propose a new loss function as follows to incorporate the regularizers:
We perform the experiments to give evidence that supports the following hypothesis: GLRC can lead to an increase in performance.
Dataset and evaluation metrics
We evaluate our method on a widely used restaurant dataset 1 that from SemEval2014 Task4 [39] and has been used by [4, 49]. Each data contains comments, the aspects in the comments and the corresponding polarities. The set of aspects are (food, price, service, ambience, anecdotes/miscellaneous). For aspect miscellaneous, it refers to the case where there are no aspects explicitly mentioned in a sentence. For example, given a sentence, “This is as good as neighborhood restaurants come.”, there are no obvious aspects like “food”, so the aspect of this sentence is “miscellaneous”. It is worth noting that there exists a fourth polarity - conflict in the dataset aside from the general three polarities of positive, negative and neutral. Conflict means that for an aspect in a sentence, there will have two polarities, both positive and negative. And the number of conflict instances are 195, which is very tiny. It will lead to the class imbalance problem just as mentioned in Section 1. So we removed conflict category. Statistics of the restaurant dataset are given in Table 3 2 .
Aspect categories distribution for each sentiment class of restaurant
Aspect categories distribution for each sentiment class of restaurant
Following previous work [49], we use the Accur cy metric to evaluate our model, which is defined as:
Just as mentioned in Section 2.1.1, we use word embeddings from the C-BOW model of word2vec 3 [29] and fine-tuned by training. We use 300 as the dimension of word embeddings. For the neural parameters, we use SGD with the Adadelta [56] update rule, and train our model with a batch size of 50 examples. We implemented our works using Theano 4 [3].
Comparison of methods
We compare our model with several baselines, experiment results are shown in Table 4, and the baselines are listed as follows
The accuracy of all methods on restaurants dataset. ’*’ means the result with SVM are retrieved from NRC-Can
The accuracy of all methods on restaurants dataset. ’*’ means the result with SVM are retrieved from NRC-Can
NRC-Can NRC-Can [19] is the best system on the task of ABSA (Subtask 4 of SemEval2014 Task 4). It combines surface features, lexicon features and parsing features based on SVM
CNN Convolutional Neural Network [18] generates sentence representation by convolution and pooling operations
LSTM LSTM [11] is a common network structure in sentiment analysis, which has no ability to capture any aspect information in a sentence
TD-LSTM TD-LSTM [43] is an extension of LSTM, which treats aspect as a target, uses a forward LSTM and a backward LSTM to abstract the information before and after the target.
TC-LSTM TC-LSTM [44], an extension of TDLSTM, incorporates a target into the representation of a sentence.
ATAE-LSTM On one hand, ATAE-LSTM [49] embeds aspects into another vector space. On the other, ATAE-LSTM imposed the attention mechanism to LSTM.
IAN The main idea of interactive attention networks [27] is to use two attention networks to model the target and context interactively.
RAM Recurrent Attention on Memory [4] first runs through the input to generate a memory. And then, the model pays multiple attentions on the memory to pick up important information.
GCAE GCAE has two separate convolutional layers on the top of the embedding layer, whose outputs are combined by GTRU.
GCN GCN is same with GCAE besides GTRU does not have the aspect embedding as an additional input.
LR-Bi-LSTM Linguistically regularized LSTM [40] is proposed for sentence-level sentiment analysis. The models address the sentiment shifting effect of sentiment, negation, and intensity words to produce linguistically coherent representations.
Firstly, compared with traditional methods (SVM), our model shows a significant improvement. As we described in Section 1, traditional approaches rely heavily on hand-craft features, but it’s hard to set good features in general. But when the SVM combine with multiple sentiment lexicons, the performance is increased by 7.6%. This just proves that these linguistic resources in real life are very useful. It is very promising to combine linguistic resources with DNNs. Secondly, we conduct experiments to compare with neural network models (CNN, ATAE -LSTM, RAM, etc.), the experiment results are shown in Table 4 also. We get some results as follows: For the two basic networks, CNN performs significantly better than LSTM. ABSA is to extract the sentiment information closely related to the given aspect. On one hand, CNN has advantages in feature extraction. On the other hand, LSTM cannot capture any aspect information. TD-LSTM and LSTM, as extended models of LSTM, performed better than LSTM, but still worse than CNN. It further proves CNN’s inherent advantages in ABSA. The performance of ATAE-LSTM, IAN and RAM are worth emphasizing. They introduce various attention mechanisms on the LSTM architecture and have made some progress. This inspires us to work on introducing attention mechanisms in CNNs in the future. GCN and GCAE showed remarkable performance, indicating the advantage of CNN and the effectiveness of gating mechanism. Compared with LSTM, LR-Bi-LSTM which introduced linguistic rules, has made great progress, indicating that linguistic rules are very useful in ABSA.
As far as we know, our work is the first attempt to combine CNN with linguistic resources for ABSA. The results show that the model is valid. In general, in the sentiment analysis, words with significant sentiment polarity will have a crucial impact on the results, and CNN is mainly doing the extraction of features. Yin et al. [55] found that GRU and CNN are comparable when lengths are small in sentiment analysis. In addition, our main purpose is trying to harness the abundance of linguistic resources in reality, and to develop a simple model to integrate these linguistic resources. Thus we try to combine the linguistic rules with CNN and get promising results. Our performance is comparable to these state-of-art methods, but our network structure is obviously much simpler. At the same time, we found that the mechanism of gating is indeed very effective, it greatly improves the efficiency of model.
In this paper, we develop a model named GLRC, two linguistic regularizers are integrated in which. To demonstrate the effects of linguistic regularizers, we empirically study the performance of systems in which these techniques are not implemented through accuracy (Table 5).
Effect of linguistic regularizers
Effect of linguistic regularizers
Table 5 shows that when linguistic rules is used ((GLRC) vs. GCAE), a significant improvement is produced. The result demonstrates that the proposed linguistic rules technique is beneficial for ABSA. To further reveal which linguistic rule plays a more important role, we compared the model performance when removing different rules.
The results of remove linguistic rules are listed in Table 5. The comparison of the two numbers (80.61 vs. 80.44) tells us the result directly: CCR is more important for ABSA when the dataset is SemEval 2014 restaurant.
In this section, we compare CNN, GCN, and GCAE. Table 6 shows the results. Different from CNN, GCN added GTRU. And GCAE has the aspect embedding as an additional input compared to GCN. The experimental results show the validity of Gating mechanism intuitively.
Effect of gating mechanism
Effect of gating mechanism
In this section, we select three typical examples from the testing data to show the advantages and weaknesses of our model. As can be seen from Table 7: ID 1&2 are examples that contain the linguistic rules, ID 3 is for error analysis. First, for the linguistic rules (CCR& ACR) we proposed in paper, sentence 1&2 demonstrate the advantages of them perfectly. In sentence 1, due to the influence of CCR, our model correctly predicted two polarities of different aspects. Similarly, sentence 2 also proves the validity of ACR. Unfortunately, there exist a mistake in sentence 3 that cannot be ignored: although there is a “but” in sentence 3, we all know this “but” will not affect to sentiment polarities on different aspects. But our model will make an error prediction because of the effect of ACR.We will improve our model for this situation in future.
Case study: Some examples from the testing data
Case study: Some examples from the testing data
Aspect-based sentiment analysis
ABSA is a sub task of sentiment analysis. Ther fore, some general approaches for sentiment analysis can also apply for aspect-level. Traditional solutions are to manually design a series of features, such as using a combination of n-grams and sentiment lexicon features [48]. These methods are very effective but as mentioned in the Section 1, traditional methods cost a lot. In recent years, there are many neural networks proposed for sentiment analysis. For example, Dong et al. [9] proposed Adaptive Recursive Neural Network and some variations of the LSTM were also proposed for ABSA, for instance, TD-LSTM [43] and TC-LSTM [44], ATAE-LSTM [49], Recurrent Attention Network on Memory [4], and Interactive Attention networks [27]. Neural networks have many advantages, but there are also some shortcomings. They will lead to uninterpretable models, which are like black boxes. In addition, there exist,many resources that are not fully employed in real life, which can be used for sentiment analysis.
Applying linguistic rules for sentiment analysis
As mentioned above, linguistic knowledge and grammatical resources are very useful for sentiment analysis such as sentiment lexicons, negation words, and intensity words. For sentiment lexicon, Hu and Liu Lexicon [12] and MPQA lexicon [50], are widely used for sentiment analysis. For linguistic resources there are many applications, for example, Qian et al. [14, 40] proposed linguistically regularized LSTMs for sentence-level sentiment analysis. Their models addressed the sentiment shifting effect of sentiment, negation, and intensity words to produce linguistically coherent representations. Dhingra et al. [8] proposed to use external linguistic knowledge as an explicit signal to inform the model which memories it should utilize.
Gating mechanism
The gating units in LSTM can selectively determine whether the information passes or not, which can solve the problem of model collapse [11]. Specifically, LSTMs can memory part features selectively via three gating mechanism (input, forget, output). To some degree or other, LSTMs can solve the problem of vanishing gradient. Fortunately, CNN will hardly encounter vanishing gradient and CNN do not require forget gates. Oord et al. [34] have shown the effectiveness of GTU. Later, Kalchbrenner et al. [16] extended this mechanism with additional gates. In order to conquer the gradient vanishing of GTU, GLU was proposed [7]. In ABSA, Xue et al. [53] proposed Gated Tanh-Relu Units (GTRU) to control the path through which the sentiment information flows towards the pooling layer.
Conclusions
To address the problems in ABSA, we proposed a model named GLRC. As far as we know, GLRC is the first model to combine CNN with linguistic resources in ABSA. Experiments on the dataset verify GLRC can combine linguistic knowledge with CNN and get nice performance. On one hand, there are still abundant and unemployed linguistic rules in real life, we will attempt to impose more rules to neural networks. On the other, from the experiments, we observed that attention mechanism is also useful for the task. How to leverage attention mechanism in CNN would be our future work.
Footnotes
Acknowledgments
This research work is supported by the National Natural Science Foundation of China (NO. 61602059, 61772454, 61811530332). Hunan Provincial Natural Science Foundation of China (No. 2017JJ3334), the Research Foundation of Education Bureau of Hunan Province, China (No. 16C0045), and the Open Project Program of the National Laboratory of Pattern Recognition (NLPR). Professor Jin Wang is the corresponding author.
(Fo., Pr., Se., Am., An.) refer to (food, price, service, ambience, anecdotes/miscellaneous). “Asp.” refers to aspects