
Abstract
Accurate activity recognition plays a major role in smart homes to provide assistance and support for users, especially elderly and cognitively impaired people. To realize this task, knowledge-driven approaches are one of the emerging research areas that have shown interesting advantages and features. However, several limitations have been associated with these approaches. The produced models are usually incomplete to capture all types of human activities. This resulted in the limited ability to accurately infer users’ activities. This paper presents an alternative approach by combining knowledge-driven with data-driven reasoning to allow activity models to evolve and adapt automatically based on users’ particularities. Firstly, a knowledge-driven reasoning is presented for inferring an initial activity model. The model is then trained using data-driven techniques to produce a dynamic activity model that learns users’ varying action. This approach has been evaluated using a publicly available dataset and the experimental results show the learned activity model yields significantly higher recognition rates compared to the initial activity model.
Keywords
Introduction
Activity recognition is considered an important area of research, particularly in the field of healthcare services [1]. The significance of this area is mainly due to the provision of support and assistance for elderly, disabled and cognitively impaired people [2]. Furthermore, activity recognition has become a primary indicator to measure physical and mental health of elderly individuals based on their ability to perform basic activities such as bathing, eating and cooking [3].
Smart homes have been used to provide monitoring technologies that can identify activities and patterns of daily routines [3]. They can also be used to monitor environmental changes using sensors installed in different locations and deployed on various objects [4]. Recent advancement in sensing and networking technologies have allowed smart homes to be integrated with other applications such as activity recognition [5], predicting human behaviour [6] and detecting early diseases [7, 8].
However, several issues have been associated with activity recognition. Firstly, there are different types of activities. Existing scales to evaluate individuals’ functional ability show that activities can be broken down into multiple levels of actions [9, 10]. For example, Preparing Food can be composed of different actions such as turning on the cooker, opening the refrigerator and finding a plate [11]. These actions result in the varying levels of granularities and they can contribute to the complexity of reasoning process. Secondly, there is no strict constraint on the sequence of actions to perform the activities. They are depending on the individuals’ preferences and particularities. Thirdly, the actions in which the activity is performed can be dynamically evolved, such as the change of activity duration and object used. As the patterns are different, it can lead to various types of activity models. Therefore, these issues have made activity recognition worthwhile and a well-researched problem [12]. In order for activity recognition to work, the inferred models should to be able to adapt to dynamic environments and different users’ behaviour.
With this respect, two main approaches have been used in activity recognition: data-driven and knowledge-driven reasoning [13]. The former is associated with machine learning techniques, where they are mainly used to extract patterns and generate activity models through training process. Meanwhile, the latter utilizes priori knowledge about the world to build activity models using knowledge representation techniques.
Both approaches their own disadvantages, resulting in the limited potential to recognize activities. For example, a widely recognized drawback for knowledge-driven approaches is that the inferred models are usually static, i.e., the models cannot be automatically adapted to users’ preferences [14]. As it is difficult to define complete activity models, this can become a problem to recognise every type of human activities in home settings. Thus, this can be properly dealt by integrating data-driven approaches with knowledge-driven models. The combination can produce activity models that are both complete and generic to capture all types of human activities. The models can also evolve continuously and learn to adapt to users’ varying behaviour.
This paper presents a hybrid approach by combining knowledge-driven with data-driven approaches. The aim is to build a learned activity model that can automatically adapt and evolve based on the action generated data. The proposed system is designed for identifying activities performed from the human-object interaction in a single-resident environment. This combinational approach helps knowledge-driven models to enrich their knowledge and produce a learned and specialized activity model.
The paper presents two contributions. The first is the architecture of the hybrid approach. The novelty of this architecture is that it integrates knowledge-driven reasoning with machine learning tools to compensate for insufficient information in the knowledge-based activity model. Secondly, a knowledge base that integrates common-sense and domain-specific information is introduced to represent knowledge of the environment and support activity modelling for the knowledge-driven approach.
The paper is structured as follows: Section 2 presents the related work in activity recognition approaches. Section 3 introduces the architecture of the proposed system and Section 4 discusses evaluation procedures to validate the proposed approach. Finally, Section 5 concludes the paper along with future work.
Related work
Activity recognition can be comprised of different tasks such as environmental sensing, activity modelling, data processing and pattern recognition [15]. Each of these tasks has their own purposes. For example, environmental sensing captures existing context in the environment. Context here refers to information such as users’ location, time and object used [16]. Meanwhile, activity modelling is merely a representation of computational activity models in a computer interpretable format [17]. Data processing usually involves data segmentation and feature extraction while pattern recognition builds activity models based on generated smart home data [18]. Generally speaking, there are three main approaches used in the activity recognition, known as data-driven, knowledge-driven and hybrid approaches.
Data-driven approaches use machine learning and data mining techniques to produce activity models from existing datasets [19]. Often, the reasoning system is performed using probabilistic and statistical approaches [20]. Machine learning algorithms are usually provided with a large representative of dataset in order to generate activity models. The learning is performed by comparing data input from sensor observations to a set of template models in the training dataset. Then, testing is performed by closely matching the sensor dataset with the models produced by the algorithms. However, these approaches suffer from the cold-start problem as they require a significant number of sensor data for the training process [21]. Furthermore, they are also difficult to adapt in different environments as the models produced are only specific to the trained subject in the same environment [22].
The knowledge-driven approaches present knowledge representation tools to model activities and exploits logical reasoning for activity inference [23]. The reasoning process uses Artificial Intelligence (AI) techniques such as rule-based systems, case-based reasoning and ontological reasoning to produce activity models [24]. Knowledge-driven approaches can represent context of the environments at multiple levels of abstraction to create generalized and personalized activity modelling [21]. In particular, ontologies have been widely used to represent semantic concepts and their relationships in a structural manner [25]. Advantages of ontologies include the ability to express knowledge in a clearly organized and structured manner, machine-readable representation and the expressive power to support the reasoning process [26]. Their main disadvantage is that knowledge-driven approaches usually suffer from adaptation problems since representation tools are usually being perceived as being generic and in static condition [27]. Furthermore, it also suffers from scalability in which it is usually difficult to generate a complete model of the environment [13].
Finally, hybrid activity reasoning combines techniques from data-driven and knowledge-driven methods in order to tackle the limitations imposed by both approaches and deal with the challenges in real-world environments [28]. This benefits the reasoning system as it can provide mechanisms to handle uncertainty and at the same time, works in dynamic environments through this combination. Moreover, the hybrid approach can represent semantic knowledge of the environment using knowledge-driven tools and as a result, the knowledge can be shared and reused across many applications.
Several studies have used hybrid approaches and fuse them into a single approach [15, 29], [30]. More recently, Ihianle (2018) combines the use of data-driven approaches using Latent Dirichlet Allocation (LDA) and knowledge-driven approaches represented by ontology to identify activities that have human-object interaction [12]. Although it has successfully addressed the limitations from the data-driven and knowledge-driven approaches, the learning process is still limited as it is only based on users’ concrete order of actions. If the user changes the order, the system may have a problem to identify the activities.
This study, on the other hand, focusses on the users’ non-sequence actions monitored from a smart home. To date, there is limited published work on learning activity models based on users’ non-sequence actions.
In particular, the proposed approach incorporates a knowledge-based reasoning with a data-driven technique to accurately infer users’ activities. Ontology is used to represent context of the environment and description logic reasoning technique is used to query and infer the initial activity model. Then, data-driven techniques are used to enhance the produced model, where the performance of several machine learning algorithms are investigated and compared in training users’ action and classifying them accordingly.
Architecture of hybrid activity recognition
The architecture of the proposed system is shown in Fig. 1. It contains two main inference processes: knowledge-driven and data-driven reasoning.

Architecture of hybrid reasoning system.
Firstly, the user’s presence and interaction with objects in the home are monitored. This interaction and its duration are indicated using state-change sensors that are installed on objects in various locations around the home. It is then recorded in a time-stamped activity dataset, which contains labeled sensor activation data formatted in a Comma Separated Value (CSV) file.
Then, the activity data are processed for further analysis. This includes storing the collected data in sensor logs with annotation attributes such as start time, end time, sensor ID, and activity label. Furthermore, some important features are extracted from the raw annotated data for activity classification. These features are selected based on their supportive functions in the reasoning system to infer activities.
The dataset is then fed into the first process, which is the knowledge-driven reasoning. It infers activities by reasoning with the information contained in the context knowledge base. In this paper, the word ‘context knowledge base’ represents the collection of semantic concepts about context of the environment and their relationships with each other stored in a library database. It is represented using ontology and used to produce an initial activity model. However, the model contains incomplete number of activities and partially labelled activity types. In this stage, the produced model is incomplete as it only depends on the knowledge represented by the context knowledge base. Furthermore, the knowledge base only represents a minimum number of necessary information to perform the activity and cannot be regarded as a complete model of the environment.
The second process uses data-driven reasoning to improve the initial activity model. It trains the initial model and generates a learned activity model that can classify the remaining unlabelled sensor data in performing the user’s corresponding activity. This is important as activities can be executed in many ways and they may vary based on the person’s particularities. Therefore, the data-driven reasoning will help to learn users’ action and produce a dynamic and personalized activity modelling.
Data processing is an important step toward identifying users’ activities [31]. In this paper, sensor activation data are stored in the time-stamped activity dataset. It contains several attributes such as start times, end times, sensor ID, object used and activity label. The data are then pre-processed to be represented in an explicit format for further analysis. Furthermore, the excessive information such as multiple header lines is also removed from the activity dataset. Table 1 shows the representation of this converted data.
Sensor data representation
Sensor data representation
Then, useful features are extracted from the sensor data using a feature extraction module. Within the scope of this work, these features represent a few context attributes such as where the activity happens, when it is happened, using what type of objects and how long the activity is performed. Below is the list of features used to infer the activities: Location of the activated sensor Time when the sensor is activated Object used Duration from the start-time to the end-time
Knowledge-driven reasoning is used to infer an initial activity model through the use of several installed sensors in the home environment. This approach is based on the dense-sensing paradigm [28], where it focusses on inferring activities by monitoring human-object interactions. The knowledge driven reasoning process is divided into two sub-elements: context modelling and activity inference.
The former uses the context knowledge base represented by the ontology representation tool. It basically encodes information about smart home, type of activities, time of a day, object and its location as well as other associated context information. Specifically, the context knowledge base contains activity model that specifies semantic information about activities based on the user’s context of the environment. The ontology contains two upper classes and approximately 245 descendants of class instances. Figure 2 shows an excerpt of the ontology, where it is designed based on Web Ontology Language (OWL) and implemented using Protégè 4.0 [32].

An excerpt of context knowledge base.
A detailed representation is shown in Fig. 3. From the figure, it can be seen that the context knowledge base is comprised of two sub-components, namely the common-sense and domain-specific knowledge bases. The common-sense knowledge base contains a collection of semantic concepts and their relationships that are related to the basic understanding of the environment. This knowledge base specifies general concepts that are defined independently from specific domains or applications. In other words, it consists of simple facts and information that ordinary people normally possess in their daily lives. This includes concepts such as Object, Location, and Time. These concepts are represented in a hierarchical structure based on the structure from OpenCyc Knowledge Base [33]. In the figure, the solid lines represent a subclass relationship (e.g., Fridge is a Device or Kitchen is an Indoor Location) while the dashed lines represent an object property. An object property is regarded as the binary relations between two classes. For example, concepts of Object and Location are connected together using the object property isLocated, and vice-versa with the inverse property of hasObject. Both properties are used to show the general information about the location and objects contained within the location of the house.
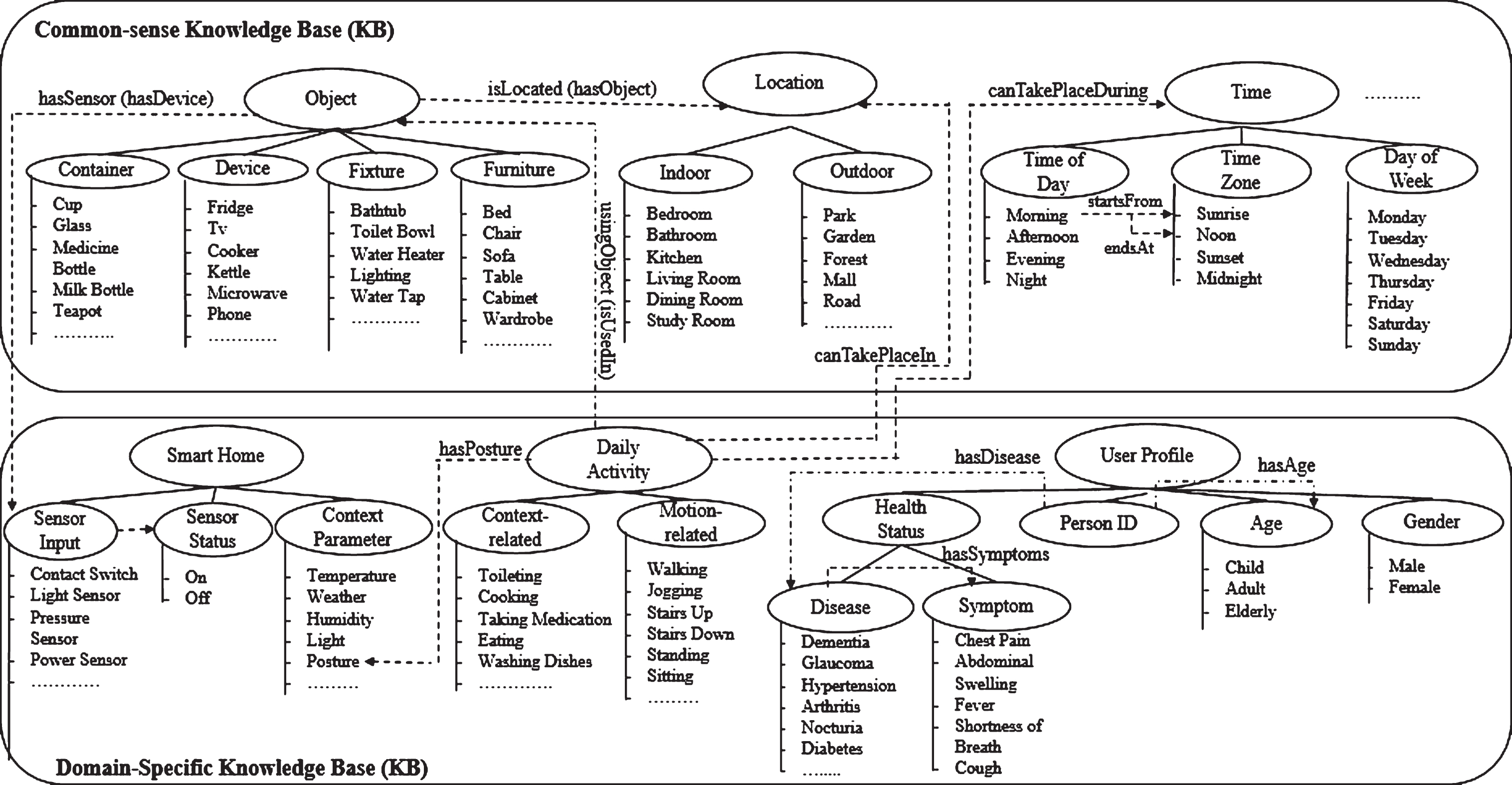
Detailed representation of the context knowledge base.
Secondly, the domain-specific knowledge base is used to represent concepts that are specifically described with respect to a certain domain in order to improve the principal understanding of the environment [34]. This knowledge base contains concepts which are based on the knowledge of experts in a particular domain. It provides a description of concepts that have been explicitly defined in a structured way to support the common-sense knowledge. Such concepts include Smart Home, Daily Activity and User Profile. Some of these concepts are based on the common-sense knowledge base, but they have been specifically defined in a more structured representation. For example, Smart Home is used to show the information about multiple sensors and the contexts that the sensors represent while Daily Activity contains types of activities divided into context-related and motion-related classes. Finally, User Profile contains the information about residents and their health historical status.
To make it more understandable, this knowledge base can also be described in the Description Logics (DL) language [35], which is considered as a first-order formalism that formally represents knowledge in a structured and reliable way. In the DL language, three types of entities are used, namely concepts, roles and individuals. These can be represented in the ontology as classes, relations and instances respectively. For example, in a scenario where the user is preparing a breakfast, he or she usually prepares the food in the kitchen, in the morning and interact with several objects such as a freezer, microwave and cooker. Figure 4 presents a snap-shot of the ontology created in the Protégé using the example of the scenario. The scenario can also be expressed in the DL language as follows:
CookingBreakfast ⊑ Cooking ⊓ ∃ hasperson..Elderly ⊓ ∃ canTakePlaceIn.Kitchen ⊓ ∃ canTakePlaceDuring.Morning ⊓ ∃ usingObject. (Fridge ⊔ Microwave ⊔ Cooker)
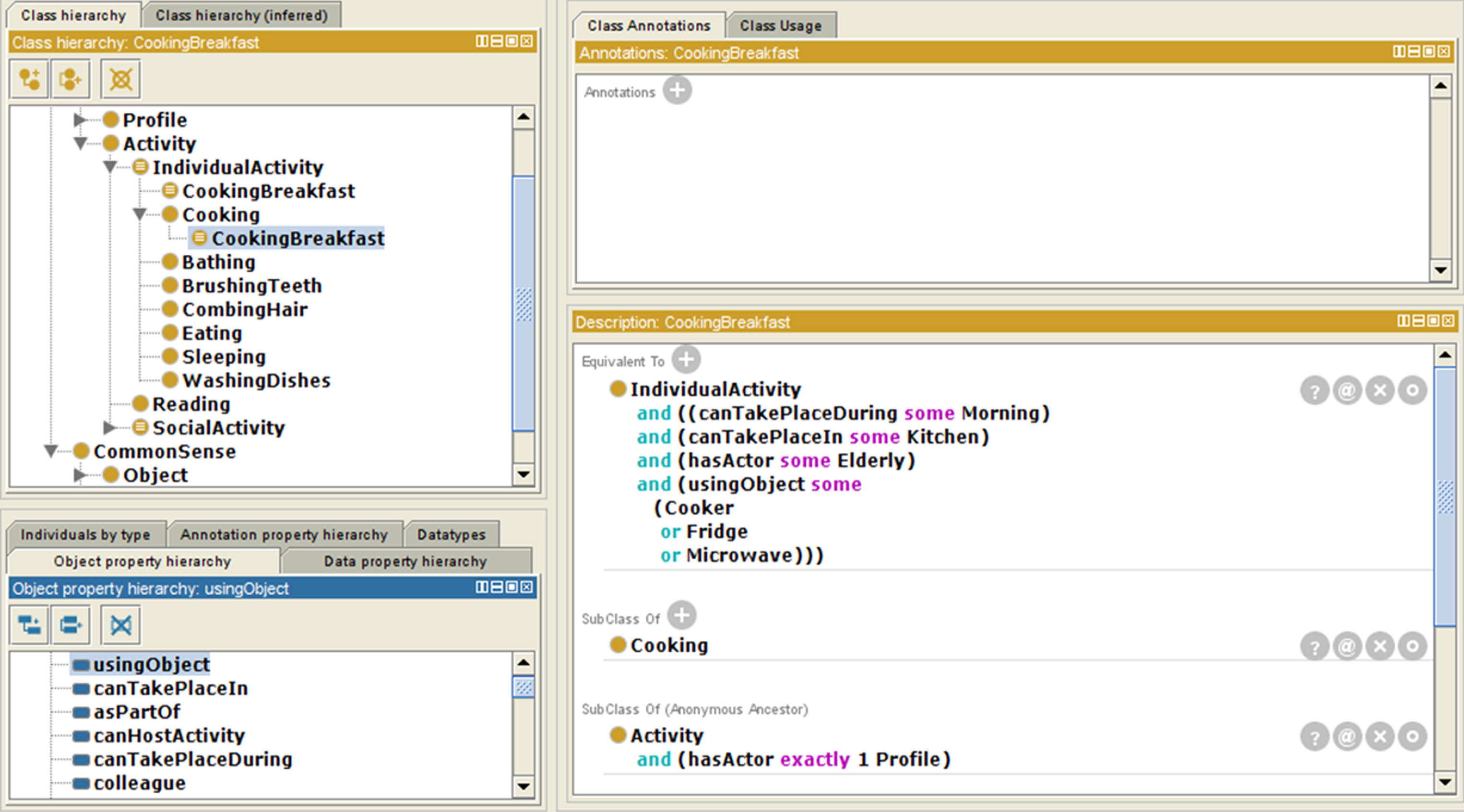
A snap-shot of CookingBreakfast in ontology.
The second step is to infer users’ activities through a description logic rule-based inference system. These rules are generated from the designer’s knowledge and they are used to classify activities based on the concepts represented by the ontology of the context knowledge base. The aim is to support the knowledge-driven decision-making process to infer the user’s activities. This provides higher-level context reasoning through the knowledge-driven approach. The rules can be expressed in the semantic web rule language (SWRL), which is based on the ABox and TBox concepts in the ontology. Specifically, 36 rules have been constructed to identify activities. Examples of these description logic rules can be expressed as follows:
Person(?p) ∧ Kitchen(?l) ∧ Morning(?t) ∧ Fridge(?o) ∧ Cooker(?o) ∧ Microwave(?o) ∧ canTakePlaceIn(?p,?l) ∧ canTakePlaceDuring(?p,?t) ∧ usingObject(?p,?o) → hasActivityPreparingBreakfast
Person(?p) ∧ Bathroom(?l) ∧ Morning(?t) ∧ Afternoon(?t) ∧ Evening(?t) ∧ Night(?t) ∧ ToiletFlush(?o) ∧ ToiletDoor(?o) ∧ canTakePlaceIn(?p,?l) ∧ canTakePlaceDuring(?p,?t) ∧ usingObject(?p,?o) → hasActivityToileting
where p, l, t, and o are the instances of person, location, time, and object respectively. This inference process is conducted using Protégè open-source software. Pellet reasoner is used to check the consistency of the ontology and SPARQL query is used to implement the rules in the query process of the testing stage. Among the information contained within a context are, person, location, time and object used. For example, in a situation in which an elderly person uses a microwave in the morning and the location is identified to be in the kitchen, the ontology reasoner can infer that the person is preparing breakfast. Figure 5 shows the example of SPARQL query codes for inferring the process given in the above scenario.

SPARQL query process.
The main problem in the knowledge-driven reasoning is that it is difficult to infer activities which are not specified in the context knowledge base. It is worth noting that the activity model produced by the knowledge-driven reasoning is difficult to be completed due to the various ways these activities are performed which may depend on the user’s specificities. Furthermore, the static nature of knowledge-driven models adds to the complexity as there are no mechanisms that can make the models evolve autonomously. Often, the activity models produced by the knowledge-driven reasoning need to be updated manually, and this can become a problem especially when smart home systems are expected to deliver their services autonomously. This issue can be properly addressed by feeding the output from the knowledge-driven reasoning, i.e., the incomplete activity model to the machine learning classifiers for further classification task.
Three well-established classifiers have been chosen for the data-driven classification process. These include naïve Bayes (NB), Support Vector Machine (SVM) and Multi-Layer Perceptron Neural Network (MLP). These are selected as they have been proven to have strong robustness in the activity recognition task. Although these methods differ fundamentally in their approach to classify data, in this study, all of them use the supervised training approach for the activity classification process.
Firstly, NB is regarded as a generative classification model, where it assumes that the features are independent and operates on a probabilistic model. It was chosen since NB is easy to implement and useful particularly for a large dataset. This classifier is based on the Bayes’ theorem. The conditional probability model is combined with a decision rule and used to infer the most probable hypothesis. Then, it assigns an activity class label by maximizing the posterior probability based on the given input vectors, i.e., sensor IDs and start time.
Meanwhile, SVM is a well-known and established way to classify data in a non-probabilistic manner. The advantages of SVM are that it is good at handling large feature spaces and employs overfitting protection which does not necessarily depend on the number of features. SVM has been widely used and considered as one of the fundamental non-probabilistic classifiers. SVM can be comprised of several kernel functions such as Polynomial, Gaussian and Radial Basis Function (RBF). In this study, RBF kernel is applied as it has better performance when dealing with multi-temporal features and it is the most frequently used kernel in remote sensing data applications [36].
Finally, MLP is one of the classifiers that is inspired by the architecture of the human brain. It is composed of inter-connected nodes called neurons and weighted links. In this study, MLP is chosen as it is commonly used for pattern recognition process. It consists of three layers of nodes known as input, hidden and output layers in a directed graph. Mappings between input and output features are represented in the composition of activation functions f at hidden and output layers. It maps the features values from the input layer and duplicates the value to multiple outputs without modifying the data. The nodes in the hidden and output layer are then used to modify the data for the training and classifying process. MLP is considered a suitable classifier since it has the capability to perform efficiently with a large volume of sensor dataset [22].
Evaluation and results
Experimental data
The experiments are performed based on a publicly available smart home dataset obtained from the study of activity recognition in a home setting by [37]. The dataset contains fourteen digital state-change sensors that monitor the user’s presence and interaction with objects. These sensors provide a change of binary state from 0 to 1. For example, when the person opens and closes the refrigerator door, the state of sensor changes from 0-1-0. This indicates a single interaction of the person with the object. Furthermore, these sensors are installed on objects at various locations such as doors, cupboard, and toilet flush. Data of the human-object interactions were collected for 28 days in a house of a 26-year-old man, who lives alone in a three-room apartment.
The smart home dataset also contains the activity labelling task by the author during data recording. This data annotation was performed using a Bluetooth headset combined with a speech recognition software. It is used to record the performed activities in the form of starting and end times. Overall, the smart home data contains 1217 sensor events and 245 activity instances. Seven types of activities are annotated in this dataset, which includes: Preparing Dinner, Preparing Beverage, Preparing Breakfast, Going Out, Showering, Toileting and Sleeping. Figure 6 presents the distribution of sensor events based on these activities in the dataset.
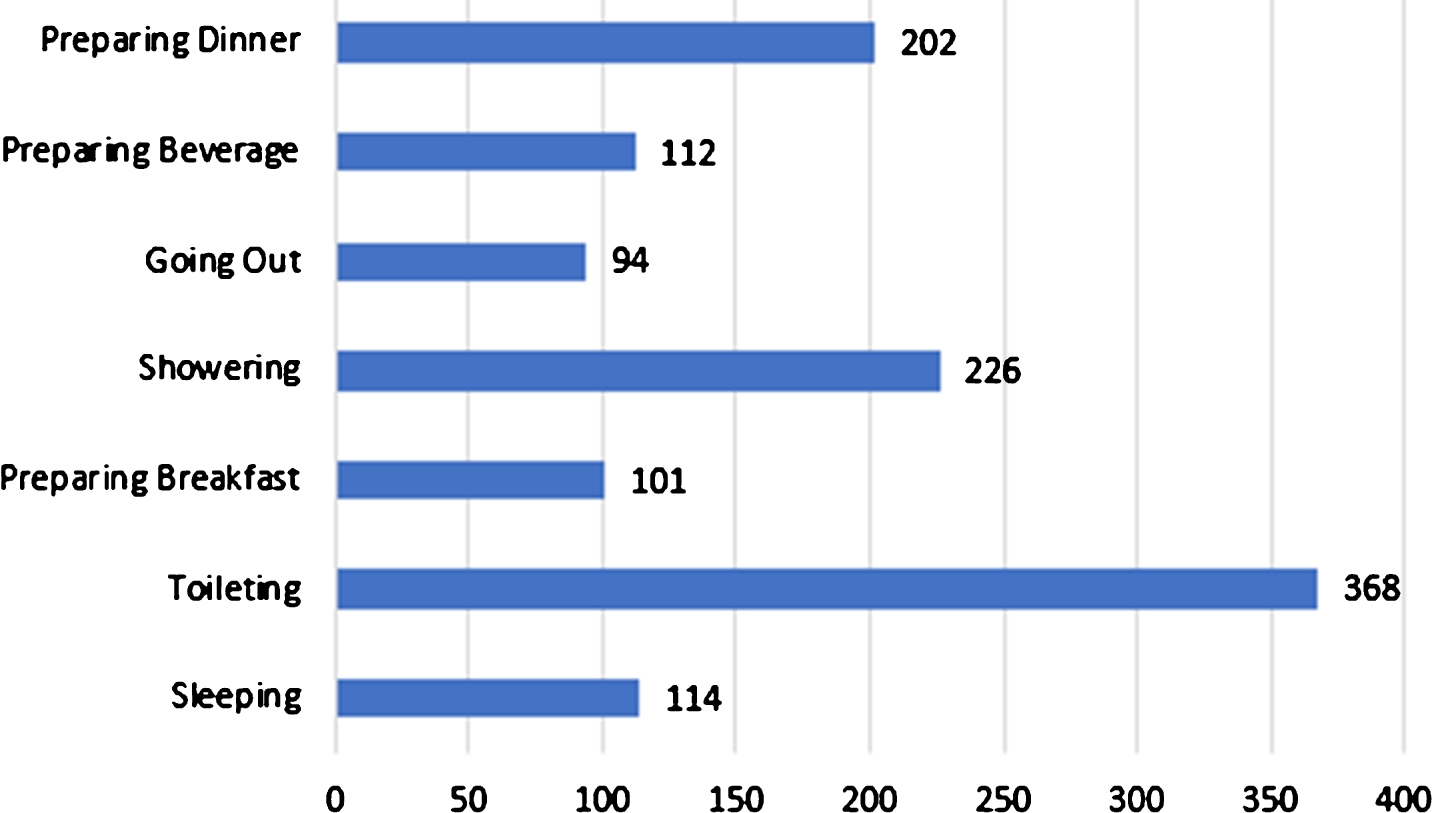
Distribution of sensor events.
The labelled activity class from the smart home dataset is served as the ground truth for comparison with the classifier’s output. The performance is measured by comparing the output from the learned activity model with the output from the initial activity model by means of true positive (TP), false positive (FP) and false negative (FN). TP shows values from correctly classified activities, FP is the values from wrongly classified activities and FN is the activity that cannot be classified at all. These values are then used to calculate performance metrics, which are composed of accuracy, precision, recall/sensitivity and F-measure [38]. The performance measurement is based on the class average accuracy, where it calculates the average percentage of correctly classified class [37].
The activity recognition performance is evaluated using 10-fold cross validation. It utilises leave-one-out cross validation on the ten datasets. During each step of cross-validation, the system is trained with nine datasets. Then, the remaining dataset (tenth) is used to cross-check the result and measure the performance with the ground truth.
Experimental results
Table 2 depicts the results generated by the first process, which is the knowledge-driven reasoning in producing the initial activity model. It is obtained based on the comparison between the output of the initial activity model and the ground truth provided by the smart home dataset. The initial activity model is represented by a partially annotated dataset, where it contains some incomplete labelled sensor data with their corresponding sensor IDs and the sensor’s activation and ending time. This comparison process uses TP, FP and FN values to calculate the percentage of true inferred activity (accuracy). From the table, it can be seen that only 663 out of 1217 activity instances can be detected as true positive while 413 and 141 activity instances are detected as false positive and false negative respectively.
Result from the initial activity model
Result from the initial activity model
The highest recognized activity class belongs to the Sleeping activity with the accuracy of 100% while Showering has the lowest rate of recognized activity (2.7%). This is because Sleeping contains inference rules that can detect the sensor’s activation of bedroom door without regard of the time when the sleeping activity is performed. This gives a direct classification to easily infer that the activity is Sleeping. Meanwhile, Showering is concurrently associated with Toileting activity and thus, it is difficult to recognize this activity as both of them trigger the same types of sensors.
Meanwhile, Table 3 shows the overall performance result indicating the accuracy, precision, recall and F-measure. From this table, it can be seen that the initial activity model only achieves 57.6% of accuracy. Meanwhile, the precision, recall and F-measure are calculated at 66.3%, 79.6% and 72.3% respectively.
Performance measure based on the initial activity model
Additionally, another experiment is performed to determine the system’s performance when the initial activity model is further learned to produce a specialized activity model using three different machine learning classifiers.
Table 4 presents the classification rates for each of the activity in the learned activity model. Similar to the first experiment, the result is obtained by comparing the output of the learned activity model from these three different classifiers with the ground truth provided by the smart home dataset. From the table, it can be seen that in some classifiers, the number of true positives has increased compared to the output of the initial activity model. For example, NB shows notable increase of true positives while SVM does not improve significantly. The highest performance belongs to the NB algorithm with 1093 activity instances detected as true positive while the lowest belongs to SVM, in which it only detects 972 activity instances as true positive. For NB classifier, it can also be observed that Sleeping has the highest true inferred activity rate while Preparing Beverage gives the lowest inferred rate. The low inferred rate of Preparing Beverage can be explained by the fact that it is performed concurrently with other activities in the kitchen such as Preparing Breakfast and Preparing Dinner, thus, making it difficult to distinguish from other activities. In this approach, it is worth to note that the false negative values have become zero as there are no activity instances that cannot be classified by the machine learning algorithms.
Result from the learned activity model based on three classifiers
Table 5 depicts the overall performance result of the learned activity model based on these three machine learning classifiers. The measurement is based on the average class accuracy. It can be seen that the performance of the learned model achieves higher accuracies with values range from 79% to 90% compared to the initial activity model. NB gives the highest accuracy results (90.0%) with 56.3% increase of accuracy rate from the initial activity model. SVM shows relatively the worst result (79.9%) compared with the two classifiers. However, the accuracy is still higher compared to the initial activity model with the increase of 38.7%.
Performance measure for the learned activity model based on average class accuracy
This also shows that the performance of the learned activity model has outperformed the results obtained by Kasteren (2008) in terms of average class accuracy, where the proposed approach achieves 90.0% compared to the existing ones, where it only achieves 79.4% [37]. Moreover, based on this results, the use of generative models such as Naïve Bayes and Hidden Markov Model (HMM) can outperform the discriminative classification model such as SVM, MLP and Conditional Random Field (CRF) for this smart home dataset.
Furthermore, NB also shows significantly higher rates in terms of precision, recall and F-measure. This can be explained as NB is highly scalable to be used with this dataset since it is considered as an efficient and reliable probabilistic classifier over multi-class dataset. Furthermore, the sensor sequences in the dataset are independent of each other and they are identically distributed along the day. Therefore, NB classifier is a good choice since it does not take into account any temporal relations between data points and thus, making it a high variance classifier.
Firstly, the performance of the initial activity model is evaluated. It can be seen that the result in Table 3 shows the initial activity model only achieves an overall accuracy of 57.6% due to the high false positive rates. Although activities such as Sleeping and Going Out achieve higher true positive rates, others obtain lower rates, in which Showering has only achieved 2.7% true positive rate. There are some activities that cannot be recognized in the initial activity model such as Preparing Beverage, with the highest false negative rate (43.8%). This low-performance results can be explained by two factors: (i) the information in the context knowledge base is not sufficient to represent all types of user’s activities and (ii) the description logic reasoner fails to infer some activities due to the insufficient DL rules introduced to the inference system.
Meanwhile, the obtained result in Table 5 shows that the performance has increased when the initial activity model is trained using machine learning classifiers. In particular, NB gives the highest classification results compared to SVM and MLP. In the data-driven reasoning, the number of inferred activities depend on the number of occurrence events in the dataset. The highest occurrence activity will provide more training data for the machine learning to learn and classify the data accurately. This can be seen in the inferring result of Toileting activity in Table 4, where the accuracy from the learned model has increased from 68.5% to 98.9%. In addition, the increase of precision and recall values show that the inferred activities are generally correct and that activities can be inferred although the information in the initial activity model is incomplete.
In any case, in this second step, the learning process allows the rise of true positive numbers and conversely, the false negative numbers become low. This achieves the goal of this study where human experts only need to supply minimal information and the rest will be trained using the machine learning algorithms to increase the recognition performance. For instance, if the initial activity model contains an activity A that has two different actions while the second activity B does not have any action that can be detected by the rules reasoner, the machine learning algorithms will learn these actions and classify the activity accordingly based on those two actions from the activity A.
Conclusions and future work
This paper proposes an approach to acquire a complete and specialized activity model through non-sequences actions based on the publicly available smart home dataset. The model is obtained by integrating the knowledge-driven activity model with data-driven reasoning techniques. This makes possible for incomplete activity models from the knowledge-driven reasoning to learn and further improve the activity model. Central to this approach is the knowledge representation method using context knowledge base, which is used as the initial source of information to infer the activities. It is comprised of two subcomponents: the common-sense and domain-specific knowledge base and these are represented using ontologies.
This approach has several advantages compared to the existing hybrid approaches. Firstly, it eliminates the cold-start problem, where large representative of sensor data can be avoided to model the activities. This is because the proposed approach first incorporates knowledge-driven technique to model the activities without the use of large dataset. Then, the model is passed to the data-driven reasoning for further activity learning.
Secondly, this approach has a higher scalability as it can be used in different environments without undergoing any specialized training process before beginning to work. It is applicable to any user as the knowledge models are built generically.
Thirdly, using the data-driven reasoning, the activity models are then trained to evolve according to the user’s specificities. Thus, this approach allows incomplete and general activity models to properly learn and adapt automatically based on minimal previous context knowledge.
However, the limitation of this approach is that it only investigates a consecutive and single activity. This may not work in real-world environments, where people usually perform their activities concurrently. For example, toileting can be performed while the user is preparing the food. The reasoning process is much more difficult as it needs a complex pattern recognition process. Moreover, this approach cannot differentiate the usage of real and meaningless object. This is important as some objects do not have any interactions with the user in regard to the activity and therefore, they can be eliminated to increase the system’s performance and reduce its computational time.
As for the future work, the activity models can be extended to include concurrent activity scenarios. A possible approach to deal with this problem could be to add a sensor-time mapping system, where time-start and time-end of sensor activation are mapped to the specific activity. This data will be used to train and build the activity models separately according to each of the activities. This implies that each activity has their own models in term of time mapping and applying the same machine learning algorithms might yield better results.
Furthermore, a feature selection method can also be applied to differentiate between real object usage and meaningless object interactions. Existing feature selection approaches such as Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA) can be used to select which important features that can contribute effectively to the pattern recognition process.