
Abstract
Rapid web growth and associated applications have proven of colossal importance for recommender systems. In the current digital world, a recommender system aims to acquire high-level prediction-based accuracy. However, many studies have suggested diversity-based recommendations are required for high-level accuracy. Group recommendation systems (GRS) recommend lists of items to a group of users according to their social activities, such as planning for a holiday tour, watching movies, etc. Using GRS, preferences/choices shared by users affected all the available aggregation with GRS leads to information loss and negatively affects ‘diversity.’ To handle the problem of ‘information loss,’ which is caused by aggregation, this paper proposes fuzzy-based GRS and argues that communicating such hesitant information will prove beneficial to generating recommendations. To find the valuable suggestions, greater focus must be dedicated to avoiding lack of variety and interest in the complete list of recommendations. In this article, we propose a novel Parallel Computing Group Recommendation System, which quantifies different approaches, chooses the right approach for group recommendation, and quickly generates optimal results. This proposed approach is an ensemble model of parallel ranking and matrix factorization that facilitates a diversified group recommendation list. Experimental evaluation signals that our model achieves higher diversity positively packed with user satisfaction.
Keywords
Introduction
Recommender systems (RS) can be applied to produce personalized recommendations. Traditional evaluation strategies and metrics were developed to improve user-level satisfaction. The RS recommends items to users to optimize a utility composed of one or more objectives applied to filter out surplus or undesired and unwanted items (for example – TV programs, books, apps, movies, music, etc.) and overcome the ‘information overload’ problem. It produces hopped-up sound interest in optimizing RS algorithms to generate top N product/service recommendations [1]. Because of the wide availability of different varieties of services and products, consumers often face difficulty in locating exactly what they are interested. Discrepancies between desired and realized lists remain.
The main role of any recommendation system is to provide consumers’ unknown popular items via individualized recommendations of the top-N items through the assumption of the highest predicted rating values. To evaluating the recommender systems, various evaluation metrics such as accuracy, recall, precision are employed. Recommendation methods and approaches are proposed by focusing on recommendation accuracy [4]. Most RS design concentrates only on how to improve prediction accuracy [6]. However, recently many drawbacks have been highlighted and explored for recommendation systems focusing only on accuracy maximization [4, 5].
Several works have sought to surpass traditional accuracy evaluation metrics in the implementation of RS design and have resolved the diversification of recommendations problem [17] as one method of improving user serviceability [3]. Diversity is needed to achieve better customer satisfaction. We aim to generate recommendation systems that balance accuracy and diversity [3].
RS mainly concentrate on providing services or products to individuals. However, some items are interconnected with social behaviors and are in a personal way but in a group manner [26]. For example, some consumers may want to go on a holiday tour together with friends and family. In this situation, individualized recommendations may not satisfy the original demand. Tackling such situations require optimized group recommendations [2]. Without wasting so much of time for making decisions itself, we need to optimize the approach if group recommendation systems. To reduce elapsed time computation, we propose a parallel computing group recommendation System (PCGRS) that has been discussed and elaborated upon in the literature.
Existing GRS collect aggregated information from available users within a particular group. The aggregation introduces potential valid information loss, particularly via the distribution of data and diversity. This information loss may yield subsequent problems such as incorrect results or bias value. This information loss enables the introduction of information fusion tools to overcome this problem and as well as these tools mandatory for us to store maximum information set [2].
Hesitant fuzzy sets (HFS), which are an extension of fuzzy based sets combinations, were originally applied and researched by Torra [7] as a method for designing hesitation. HFS is available with a reference set of information provides not only one value, but it provides a set of values [8]. Hence, we can obtain inferences from HFS the model which gives a complete picture of different user preferences for one particular item [9].
The proposed work is comprised of a hesitant fuzzy set group recommender system (HFSGRM) based purely on collaborative filtering (CF) and HFS. This system enables us to generate group recommendations to n number of users while maintaining all information and eliminating problems associated with individualized recommender systems. This evaluation of our proposed system will be carried out through with traditional group-based recommender system. In this experimental evaluation, we considered commonly applied data sets for RS and elaborated upon the overall discussion of results to elucidate different perspectives such as accuracy and diversity. The proposed system displayed great improvements over the individualized RS.
This paper has formulated based on the following structure. In Section 2 we list out related works. In Section 3 we elaborated on the background details of PCGRS and HFS. In Section 4 we provide a detailed description of the proposed model of HFSGRM and ensemble model of MF and Parallel Ranking. In Section 5 we relay our experimental evaluation and discuss findings. Finally, in Section 6 we conclude the article by considering future directions for further research.
Related works
In today’s electronic business activities, recommendation systems are vital application systems for almost all web-based applications. They form maximization towards customer satisfaction. Recommender systems help overcome ‘information overload,’ ‘information overfitting’ and other associated problems. Users often feel overwhelmed by massive and messy information. Recommender systems can provide various alternate suggestions to customers [20]. Recommender systems can also provide personalization-based services and to screen useful information [1].
Recommendation algorithms consider only non-viewed items when making recommendations. A relevance score is computed across the active target user and items to predict recommendation output. The most relevant set of items is then filtered to constitute a top-n recommendations list, and recommendations are filtered to the users via a user interface [21]. Initially, user information, such as past ratings and online interactions, is analyzed. The outcome of this user information analysis is utilized to model the user profile, which is then employed in the recommendation generation process. Most RS use CF to create recommendations [12]. Recently, more focus has been attributed to diversity [18], which measures how dissimilar items suggested to the intended users. Diversity requirements improve customer satisfaction [19]. Our objective is to generate a recommendation system that adequately balances accuracy and diversity [11]. Content-based attributes measure diversity. Rating-based diversity positively generates novel diversity recommendations, and it positively correlates with novelty. By using a diversity-based recommendation system, a user group receives more accurate recommendations, even though user group received input data as sparse data. Today, the diversified recommendation is preferred, as it aids in avoiding monotonous recommendation lists. Rearranging the recommendation list in the final ranking to get a related form of diversity-based recommendations [13].
Typically, traditional Group Recommender Systems (GRS) are based on RS approaches, but GRS faces several issues that will not be reflected on recommendations to the targeted user. Several other authors present various sets of challenges to cope with GRS [17]. Matrix Factorization (MF) based recommendation system used to predict ranking based recommendations [23]. The concept of Matrix Factorization Collaborative Filtering has been implemented in various related areas, and many studies are available on this subject. Sarwar et al. proposed a Matrix Factorization-oriented dimensionality compression technique in Collaborative-Filtering [15] based with unique index ID, PR = {0, 1, 2, and 3 ... .N}. PCGRS works with user set, U = {u1, u2, u3 . . . . . . u p }, a set of items, I = {i1, i2, i3,. . . . i m }, and a set of ratings, R = {u1, u2, u3,. . . . u n } ⊂ U, n << p specifies the target set of people; excluding loss of general applicability, we assume Grp is the first n set of users.
RS to eradicate numerous drawbacks of neighborhood-based techniques [15] such as synonymy and scalability. Weng et al. suggested traditional matrix factorization generates closely compacted in substance form of user latent factor model (LFM) matrices and item LFM matrices [16]. It gives good collaborative-filtering recommendation system results. The idea which is encouraged even though user formulated a structural relationship concerning the latent factor model. The standard matrix factorization model produces closely compacted user and item information. Producing latent factors in a parallel manner is impossible. MF models are framed with the help of the interaction units of available ratings, a product of LFM user and item models.
Regular matrix factorization models produce both users latent factors and item latent factors in a dense format. But the item latent factor must remain in a sparse form. Latent factor model factorization produces high accuracy results and performs better regarding diversity and associated measures. Good quality results can be obtained more quickly using latent factor model-based matrix factorization. We can obtain high diversity results using generating a recommendation system regarding NNMF [17].
Preliminaries
In this section, we provide a detailed review of the PCGRS, and HFS approaches. Comprehension of these systems is mandatory for understanding our proposed work.
Parallel Computing Group Recommender Systems (PCGRS)
PCGRS is designed with Message Passing Interface (MPI) [22] and spawned parallel processors with a unique index identifier. Among processors, one processor can be treated as the ‘master’ processor. Other remaining processors are treated as ‘slave’ processors. PCGRS works with a set of processors.
HFS for group-based recommendations
An HFS (Hesitant Fuzzy Set) is originally made available by extending regular fuzzy sets [8, 9], which is function definition that returns a set of available membership degree values for every element in the domain.
Definition 1
Assume X is a reference list, an HFS on X is one kind of function [2] h that returns non-empty subset values in [0, 1]:
Definition 2
Assume that X is a reference set; an HFS available on X is a function h such that returns a nonempty form of subset available in values ranging from 0 to 1.
Definition 3
Assume that M = {μ1, μn} is a set of membership value associated functions. HFS is originally associated with M, while hM is defined as:
Xia and Xu [10] stated that the original meaning of HFS includes the notion of the hesitant fuzzy element (HFE) and is a specific subset of values in the range [0, 1] for a specific x belongs to X.
Gonzalez-Arteaga et al. [25] formulated an extension of PCC, to be a sign of ρ, to the Hesitant Pearson-Correlation-Coefficient (HPCC), ρHFS. Assuming that there are two values, X and Y, and there are three different items represented as i1, i2, and i3. The objective of HPCC is to calculate the correlation between both x and y values. Concerning hesitation information and might display a rating for each item rather than assigning one specific rating value, HFS is used to model each valuation. The similarity measure HPCC measures the correlation coefficient value between X and Y.
Definition: Assume X and Y are two HFS on S, the HPCC, and ρHFS, is defined as follows:
Where SSC (hX, hY) is the covariance of both the sets
To develop a novel ranking supported multi-phase optimized diversity-based recommendation system, we must follow various approaches. As in Fig. 1, the architecture comprises many stages. Once the input user-item matrix is extracted from the ml100k dataset, parallel computing [22] approach that generates a group recommendation system. To optimally select a group based recommendation, PCGRS is modeled via three approaches [14]. The appropriate approach must be selected for further development of the proposed system. If parallel processor = 1(slave1), then an individual user’s preferences, specified through individual rating values {rij}, are collected to attain a group’s choices.

Schematic representation of the overall architecture.
Once group preferences are received and given as input for the classical correlation coefficient called Hesitant Pearson Correlation Coefficient (HPCC), taking sole responsibility to generate recommendations through intermediate group predictions. If parallel processor = 2, then a similarity measure is applied to each user, ui, to attain individual user predictions. These predictions are then aggregated to produce group recommendation through intermediate group predictions. If parallel processor = 3, then a similarity measure is directly applied to formulate group predictions. Hence, group recommendations are directly generated without aggregation. The master processor extracts information from these slave processors. The role of the master processor is to select the best of these three approaches.
After analyzing results, the third approach proved most suitable and was selected by the master to develop an effective group-based recommendation, because there is no risk of aggregated information loss. In the other two approaches, loss of information is a major problem quickly identified using parallel computing methodology.
In the next stage, a Hesitant Fuzzy Set Group Recommender Model (HFSGRM) based on Collaborative Filtering and Hesitant Fuzzy Sets is introduced. HFSGRM uses CF GRS not only to consider individual user preferences but also monitor collective user preferences.
For considering user preferences, we need to follow a strategy to find n nearest neigh neighbors with similar tastes along with preferences. HFSGRM computes a similarity value among the target group and nearest neighbors via the use of an available group rating list. The proposed architecture of HFSGRM illustrated in Fig. 2 is segmented into 3 phases:
Phase 1: Similarity computation using correlation coefficient HPCC
Phase 2: Rating predictions for the group.
Phase 3: Recommend Best-N suggested items having the uppermost prediction value to the Group.
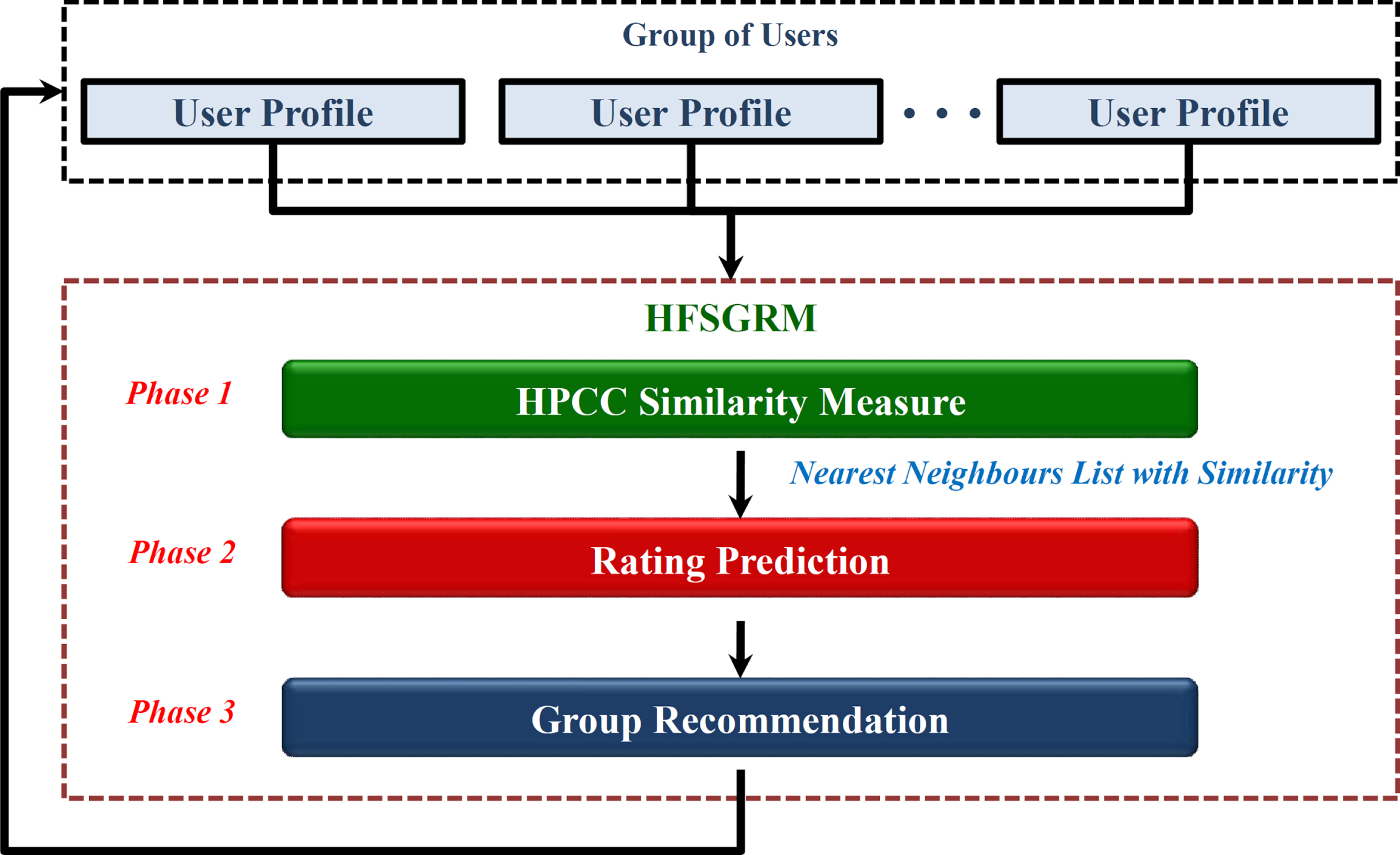
Work flow model of HFSGRM.
If a user has two or more similar item ratings, the system will choose one of the available ratings. Without the need for aggregation, the direct prediction is performed based on similarity values of the nearest neighborhood. Finally, the system recommends a top-N recommendation list to the set of group members.
From this top-N recommendation list, we must apply the ensemble model of Matrix factorization and parallel ranking algorithm to generate a diversified recommendation system. In the next stage, an ensemble model of parallel ranking and matrix factorization is implemented. Consider a list of group recommendations organized based on the linked list the summation value of the last i elements available on the list one≤i≤n. Sums are computed from the termination point. The way to identify list position is to count the total number of links traversed between the list element and the list’s termination point. The single pointer in linked list representation can be followed in an independent step, and n-1 pointers are required in between the list’s start and end points.
If we associate an independent processor with every specific list element and transfers the control concurrently using jump pointers, the distance measure to the final point of the entire list cut in half by using the instruction nextval[i]<- nextval[nextval[i]]. If one parallel processor adds to its traversal count, position[i], the current link – visiting count of the successors it encounters, the list operation correctly identified. This algorithm executes based on ‘concurrent read and exclusive write’ principle. This algorithm finds the position of the independent item with the help of a singly linked list.
We can perform item ranking within a list using the following algorithm. We propose the inclusion of diversity-oriented specifications in a collaborative filtering-based matrix factorization model.
Parallel Ranking Algorithm
One frequently applied technique for deriving latent factor model-based matrix factorization is user latent factor specification model. Factor vectors are learned by minimizing the RMSE.
Given each independent user in the group has initially rated popular items in the system; we must predict how users will likely rate items not yet rated. In doing so, we can generate various types of recommendations for the set of n users. In this kind of scenario, all available information collectively gathered about previous ratings can be represented in a matrix.
To identify different features of items, we must consider what number of features comprises of a small number of items. It is very difficult to understand the assumption based model made available concerning assigned item features for one particular user. With this context, it proves difficult for us to generate recommendations, because some items have been rated by other users but do not appear in the interesting item list for a single set of few users. Same kind of process applied regarding items also.
Non-negative matrix factorization (NNMF) is a team of procedural representations available within multi-variant analytics and linear shape of representation that includes algebra. In this form of factorization, a given input matrix V is originally factored towards two different matrices, W and H. Also, the property associated with matrix factorization is comprised of all three matrices without having a negative form of elements. The process of converting non-negativity constructs, the output matrices makes it very simpler to perform the analysis process. Furthermore, in various applications, such as muscular activity or audio spectrogram processing, the concept of non-negativity is intrinsic to deliberated available data. While the original task is not generally accurately solvable, it is generated as a common approximation solution and solved numerically.
Four steps are executed to recommend items via non-negative matrix factorization. They are as follows: Generate a list of recommendations by applying the MF and kNN or mean rating approaches. Follow this approach regularly if the user has already selected from an item list or appraised any items on the recommendation list. Formulate a fresh recommendation list set using modified information (fresh rating values supplied by the user). Measure the diversity of the fresh recommendation list via comparison to existing iteration (the original recommendation list generated for the user concerning time and the user’s previous communication with the real system).
Description of the experiment
In this section, we document our experimental evaluation of the performance of our proposed work with traditional methodologies namely PPMF and BCD-NMF. The MovieLens 1M Dataset has been employed for this experimental evaluation. This dataset comprises 1,000,209 obscure ratings of roughly 3,900 movies by 6,040 users. The complete dataset is divided into two categories training and testing with a respective contribution ratio of 80:20. The experiments were organized on an Intel Core 2 Duo processor with 1.86 GHz 120 GB HDD and 8 GB RAM supported desktop system. The algorithm was implemented via Python 3.6.5; the Windows 2010 operating system was used. To handle the experiment’s large volume of data, we employed a parallel computation and distributed computing environment. For parallel and distributed computing implementation, the high-performance cluster is applied to run modules using the CUDA Application program toolkit and MPI programming interface. The attained results of our HFSGRM group recommendation model were then compared using the traditional group recommendation models.
Performance evaluation metrics
The objective of this experiment was to evaluate the traditional model with the proposed HFSGRM to optimize group-based recommendations.
We evaluated five metrics: precision, F-measure, recall, NRSMSE, and NDCG.
Precision
Precision is a popular quantitative evaluation metric used to calculate prediction value. The precision metric is expressed as the actual percent of relevant recommendations identified in a retrieved recommendation set. Precision illustrates the fraction of relevant items in the top-N list of recommendations and is evaluated via the following formula:
Recall
The recall is the percent of relevant recommended items and Top-N Recommended items. It indicates the fraction of relevant items within a test set and quantifies the chance of selecting an appropriate item to generate the final recommendations list. Recall, also termed sensitivity, is evaluated using this formula:
Both the precision and recall evaluation metrics have been applied to identify the proposed system’s performance accuracy centric measures.
NRMSE (Normalized Root Mean Square Error)
As stated earlier, this evaluation is executed with five cross-fold validation and the NRMSE formula:
Where
NDCG (Normalized Discounted Cumulative Gain)
NDCG generates the quantity value of the proposed system’s original performance based on a graded relevance score. This value ranges from 0.0 to 1.0.
Where IDCG is the peak possible DCG value, the actual relevance of a recommended item is predicted using
The HFSGRM model was executed for the datasets mentioned above. In the following section, we outline our observations and inferred results. Since this dataset does not include information about groups such as random groups, similar and dissimilar groups, information can be selected from any of these group formations. The list of suggested items is provided by seeking the group most similar to the intended customer.
Comparative analysis of proposed work with traditional methods performed for the set of groups. Groups with similar attitudes and interests, suggesting items to group members is easy. But, in contrast, the satisfaction of a group of members with dissimilar interests can prove tedious. Consequently, results attained from diversified groups are inferior to similar groups.The results attained from the proposed model were tested with evaluation metrics to gauge model performance. Analytical information about accuracy centric measure and diversity were extracted.
The results can be grouped within three categories: small groups SG (3 Users), medium groups MG (5 users), and large groups LG (8 Users).
HFSGRM model results were also compared with two traditional methods: PPMF (parametric probabilistic matrix factorization) [17] and BCD-NMF (block co-ordinate descent-based non-negative matrix factorization) [23] about the recall and precision accuracy centric based RS models of MovieLens 100K dataset and MovieLens 1M dataset. Tables 1 and 2 compare these values by taking group size 3, 5, 8. To initially evaluate the precision and recall measures, we adopted a threshold rating value of 4. Ratings greater than or equal to the threshold value were treated as positive, while ratings lower than this threshold value were treated as negative [24]. The precision and recall measures we observed are illustrated in Table 1 for MovieLens 100k dataset and 1M dataset.
Accuracy centric comparison with RS models for 100 K dataset
Accuracy centric comparison with RS models for 100 K dataset
Accuracy centric comparison with RS models for 1 M dataset
As seen in the above Tables 1 and 2, the high precision value indicates our model correctly predicted all positive ratings. This desirable outcome means our model is working properly. However, recall levels were observed as very low, likely because the dataset is comprised of sparse data.
Tables 2 and 3 compare this paper’s proposed method with traditional methods such as PPMF and BCD-NMF. Precision and recall values were computed for 20 recommendations, and the ML 100K and ML 1M datasets were applied. The proposed method elicited substantially increased accuracy compared to traditional methods. The quality of group suggested items shows a 15% to 20% increase in the ‘LG’ category, a 10% to 15% increase in the ‘MG’ category, and a 5% to 10% increase in the ‘SG’ category. Though the F-measure produced by the proposed method is higher than traditional methods, it shows betterment results. Time complexity plays a key role in the evaluation of the proposed method with two different datasets. For the ML 1M dataset, more computation time is required.These results confirm the original hypothesis: by retaining all information pertaining to group members, considering vague properties, and eliminating agglomeration processes, the HFSGRM model produces better results in less time. The results also show a clear tendency for bigger group sizes to produce better diversity. The designed representations do not have negative persuade specification in the accuracy value of the system.
Comparison of Error rates with RS models for 100 K dataset
The NRMSE and NDCG evaluation metric results are shown in Tables 3 and 4. Both these metrics evaluate the proposed method’s error rate performance. NRMSE values are much less for both the ML 100k and ML 1 M datasets.
Comparison of Error rates with RS models for 1 M dataset
By observing the above Tables 3 and 4, we can see the proposed method slightly outperforms traditional methods. This proves our method delivers a comparatively lower error rate and, as a result, is the best method for the group-based movie recommendation. Our proposed method received a lesser error by obtaining more accurate ratings via predictions with hesitant fuzzy sets rather than aggregated values.
NDCG and NRMSE values were evaluated and compared to the proposed method with two different traditional approaches. Tables 3 and 4 compare the error rates of these methods. Data sparsity is the key challenge in handling such datasets. The positive effect elicited by including group correlations using HFS reduces this data sparseness. NRMSE results show the proposed system yielded a lower error rate than the other methods. These results demonstrate the proposed system can ease the handling of data sparsity by using the group preferences among diversified groups. When group size increases, the error rate is drastically reduced compared to other traditional methods. Optimal performance is obtained in all groups with sizes equal to 2, 5 and 8. When applying both datasets, the proposed system significantly improves recommendation performance, accuracy, and efficiency. With traditional approaches, total computational time increases with group size. But, the proposed parallel computation ensemble model drastically reduces the total elapsed time. By attaining similar comparative analysis performed using proposed it is easier to generate a diversified recommendation list via hesitant fuzzy sets.
Proposed group recommendation system and traditional group recommendation system comparison results in terms of evaluation metrics depicted in Fig. 3(a)–(e).

(a) Comparison of Precision (b) Comparison of Recall (c) Comparison of F-measure (d) Comparison of NRMSE (e) Comparison of NDCG.
The novel approach of generating group recommendation with parallel computing is performing in an optimal way of solving the problem associated with a recommender system. By using HFS to generate group recommendations, we eliminated the requirement for an aggregation process. By using this approach, the potential for bias values missed crucial information was completely resolved. Diversity is today’s most desired property in recommendation generation. Our approach employed an ensemble model of parallel ranking and matrix factorization and generated a diversified recommendation list. The outcome includes group members with conflicting or different interests. Therefore, diversity provides satisfaction to the user with any of the desired items and increases satisfaction for groups of users. Experimental results show the proposed model HFSGRM enhances diversity as group size increases. Also, combined diversity and accuracy evaluation metrics generated remarkable improvements. Hence, our proposed model not only produces accurate recommendation lists but also with diversity feature—it satisfies all levels of group users. This proposed model is suitable for collaborative filtering recommendation systems. In the future, this model could inspire more advanced research towards content-based and hybrid-filtering based recommendation systems.
Footnotes
Acknowledgment
The authors are grateful to Science and Engineering Research Board (SERB), Department of Science & Technology, New Delhi, for the financial support (No. YSS/2014/000718/ES). Authors express their gratitude to SASTRA Deemed University, Thanjavur, for providing the infrastructural facilities to carry out this research work.