
Abstract
Object detection is a technologically challenging issue, which is useful for safety in outdoor environments, where this object, frequently, represents an obstacle that must be avoided. Although several object detection methods have been developed in recent years, they usually tend to produce poor results in outdoor environments, being mainly affected by sunlight, light intensity, shadows, and limited computational resources. This open problem is the main motivation for exploring the challenge of developing low-cost object detection solutions, with the characteristic of being easily adaptable and having low power requirements, such as the ones needed in on-board obstacle detection systems in automobiles. In this work, we present a trade-off analysis of several architectures using an FPGA-based design that implements ANNs (FPGA-ANN) for outdoor obstacle detection, focused in road safety. The analyzed FPGA-ANN architectures merge outdoor data gathered by a Kinect sensor, images and infrared data, to construct an outdoor environment model for object detection, which allows to detect if there is an obstacle in the near surroundings of a vehicle.
Keywords
Introduction
Survival of the fittest is the simplest explanation evolutionary scientists provide to explain the extinction of several species, while several others have been around for thousands or even millions of years.
A particularly determining factor in survival of the species in nature is how well the individual adapts to its environment, which can be translated as how well it manages to avoid environmental dangers, such as predators (without forgetting the relevance of covering its basic needs to feed, breed, etc.). This concept of survival, also applied to human beings, as individuals interacting with nature in a daily basis, just a few centuries ago.
One of the consequences of technological developments and urbanization is the fact that human beings interact less and less with nature, which, in consequence, reduces the possibility of being threatened by predators; nevertheless, this, by no means, represents there are no potential risks in these new civilized environments, and, although it is evident that life expectancy has considerably increased as a consequence of this development, these new conditions end up bringing new challenges in terms of human security.
Nowadays, the cost of cars is within easy reach for almost everyone, which has been reflected in the blatant increase in the number of motor vehicles (all around the world there is one motor vehicle for each 7 persons, which is approximately 142 of these vehicles for each 1,000 inhabitants; while in the USA, in 2012, there were 806 motor vehicles for each 1,000 inhabitants [1].
It is worth mentioning that, in most of the cases, car accidents involve events where at least one driver finds an unexpected obstacle in the car’s path (this obstacle might be another car, a pedestrian, a cyclist, a motorcyclist, an object left on the road, a road bump, etc.). Three things can happen as a consequence of this unexpected event: 1) the driver succeeds at avoiding the obstacle, preventing a potential accident from happening; 2) the driver is unable to avoid this obstacle and a collision or a run over occurs; or 3) the driver attempts to avoid this obstacle, but this maneuver provokes another accident, such as a collision or a run over.
The World Health Organization (WHO) provides with alarming statistics, asserting each year 1.25 million people die worldwide, due to car accidents, despite the ever evolving regulations in road safety and the technological advances in car design [2]. According to the same report, half the number of deaths in the event of car accidents are pedestrians, cyclists or motorcyclists, which turns out to be obvious, given their vulnerability.
The aforementioned facts reflect cars have become a real life-threatening element in modern societies; however, the human factor is extremely relevant when determining the reasons for these accidents, since drivers being distracted by, for example, their interaction with their cellphone, or under the influence of alcohol or other drugs, are common causes of these life-threatening events.
The WHO has defined a 50% reduction in the number of deaths and traumas caused by car accidents, by 2020, as one of the purposes of the Sustainable Development Goals. In this context, it seems clear that, those efforts aimed to reduce the number of car accidents, by providing human drivers, and even future self-driving cars, with adequate tools to accurately identify potential risks, should be a priority in road safety research.
When we mentioned evolution as a relevant aspect in the survival of a species, we did not implicitly include technological advances. However, in the case of human beings these advances represent a certain type of evolution, since they have the potential of providing with additional safety measures, particularly in the scope of this paper, in car driving. In this sense, assistance systems stand for one relevant technological evolution, since these automatic systems are designed to help human beings make decisions; and, in some cases, they even make decisions for them, when the reaction speed is a relevant factor, such as in security (e.g., when avoiding having an accident or when preventing an attack). Either in a self-driving car or in a car with a human driver, the availability of obstacle detection mechanisms, able to provide with warnings, might become life-saving elements in future cars.
Although several object detection methods have been developed in recent decades, based on cameras and other sensor types, these systems tend to fail in outdoor environments, which are precisely the ones where driver assistance systems are needed. The reason for the poor performance of these systems is, mainly, the fact that they find it difficult to deal with illumination changes and shadows; and since these systems tend to have limited resources, the possibility of applying sophisticated processing techniques is seriously limited.
And, while the last decade has given birth to the most outstanding advances in drive assistance systems(ADAS), the recent accidents reported in news, in which self-driving cars using these systems have been involved, make us think we might need to take one or two steps back, considering these systems have failed in really basic aspects, such as object detection.
In this sense, Intelligent Cyber-Physical Systems (iCPS) present a synergy to establish a cross-point between reality and a virtual world, where several factors can be evaluated to support decision making. The iCPS paradigm provides systems, whose elements are computational processes, storage, communication networks and human processes, where Artificial Intelligence can be applied to efficiently identify real-world objects and processes to carry out complex tasks, improving the operation modes in real-time for pervasive systems. This situation occurs in the case of road safety; and particularly, for outdoor object detection this implies the use of several data sources and the application of autonomous intelligent techniques. In this context, the main research problem is solving design challenges as security, high performance, low power consumption, new algorithms, and so on.
This situation is the inspiration for this paper, where an innovative object detection architecture is presented. This object, in particular, is expected to be a potential obstacle that must be avoided by a drive assistance system (see Fig. 1). The architecture is robust, especially, when used in outdoor environments, thanks to its use of merged images and infrared data, obtained by a Kinect sensor; these characteristics, as we mentioned, make this architecture applicable to these drive assistance systems, providing a reliable in-time detection of objects in the near perimeter of the car. The other important feature presented in this work is the fact that in it, several ANNs are thoroughly analyzed and compared, to determine the pros and cons in each implementation. The reason to choose implementing these ANNs in an FPGA is the fact that the on-board computer in a car has limited resources, which are reserved to be used by the car itself; and even if these resources were available to be used in an obstacle detection system, they are, as we mentioned, limited, making these processing and storage restrictions insufficient to implement a robust real-time obstacle detection system.

Example of the application of outdoor object recognition in a real-life situation.
In summary, the objectives in this work are: i) providing an obstacle detection mechanism with complementary information, particularly coming from a Kinect sensor; ii) using this information to overcome the difficulties in classic real-life outdoor obstacle detection systems, such as sunlight, light intensity, and shadows, employing an ANN; and iii) evaluating different FPGA implementations, aimed to improve performance, while overcoming the availability of limited hardware resources in a vehicle (these implementations are suitable to be used in an on-board obstacle detection system).
In the following sections, we describe the principles on which this work is based (Section 2); we also review the state of the art, in order to cover the most significant related works (Section 3); the proposed general method for outdoor obstacle detection is explained in detail (Section 4); also, the details on how the proposed method is implemented using the FPGA-ANN approach, is explained (Section 5); the hardware implementation, examining its benefits and weak points is a relevant part of this work (Section 6); finally, we discuss and present our most relevant conclusions of this work (Section 7).
This section contains the most relevant concepts with respect to this work. In this section, we describe:
i) the object recognition and classification tasks, as relevant processes undertaken in different contexts; ii) the particular case of outdoor obstacle detection and its intrinsic problems, since this poses critical conditions under which, several classical object detection techniques collapse; and iii) the explanation of the different metrics used to evaluate the implemented FPGA architectures, given the relevance of providing the reader with clear and fair metrics for comparison purposes.
Object recognition and classification
Object recognition and detection are relevant tasks in daily life and industrial processes, since their adequate execution are of great help in the subject interaction with their environment. The term object is widely used and, in this context, it can refer to a vehicle, a person, an animal or any other element in the surroundings, that needs to be identified. When referring to a vehicle, objects are potential obstacles, especially if they are located in the path the vehicle is traversing and, consequently, the appropriate maneuvers to avoid collisions with these obstacles, must be executed. Object recognition is, in most object detection methods, a fundamental element. This task has been widely approached in recent years, especially with the significant increment in computational resources and the availability of digital videos and images. In case the reader wants to check some related works in this topic, the authors of [3] make a thorough work, covering more than 270 related works in this matter.
Outdoor obstacle detection problems
Outdoor obstacle detection is, currently, a very popular task, given its very diverse applications in robotics and computer vision, just to mention a few examples. This complex process, can be described as the detection of an upcoming object, performed in order to avoid a collision with such an object, by some sort of signaling or maneuver [4].
Although, in controlled environments, detecting and identifying an object is relatively simple, the actual challenge appears in real-life situations, such as in outdoor conditions, where object color, illumination changes, shadows, and occlusions, are frequent; and, consequently, they tend to cause poor performance in terms of low detection rates. Several works such as [5, 11] use one data source. A very popular approach, intended to deal with these problems, is based on the idea that, by providing a detection system with complementary information, the system will be more robust to these changes. This instinctive approach has proven to be successful, as we will see further in our review of the state of the art; nevertheless, as simple as it sounds, integrating more sensors, can rarely be done in a direct way, since these multiple sensors, or more precisely, their outputs, need to be adequately integrated and fused, in order to actually provide with a more reliable obstacle detection than if just a single sensor were used. In this case, works such as [4, 13] describe different solutions. Particularly, in this work, we suggest fusing infrared images and depth maps provided by a Kinect sensor.
FPGA performance metrics
Two main performance metrics are used to determine how good an FPGA design is carried out: 1) Throughput performance, and 2) Efficiency.
Throughput performance
Throughput performance is measured in bits per second (bps) (see Equation 1). For this measure, the clock frequency is obtained from the system implementation in the FPGA technology.
Another metric is related to implementation efficiency, regarding hardware use, defined as the ratio between the throughput reached and the area (see Equation 2), where the area is measured by the number of Slices or LUTs the implementation consumes.
With the purpose of providing a general review of the state of the art, we present related works in obstacle detection, outdoor object detection and FPGA implementations.
Obstacle detection
Object recognition is an important task in the design of road safety systems. For instance, detecting objects considered as potential obstacles, such as garbage, tires, vehicle parts resulting from accidents, vehicles parked on the road shoulders, etc., is a major issue; since outdoor environmental conditions are unpredictable and roads are not always well defined and/or illuminated. Therefore, several works have been focused in segmenting objects by using edges and color features, while others look for a solution recognizing each object by employing fuzzy logic [7] or data fusion, taking into account information provided by LiDAR [4], infrared, or camera sensors [5]. In the following, some works related to the approach presented in this paper are described.
The use of Microsoft Kinect in Computer Vision and Robotics has been widely explored in recent research. One such example of the successful use of this sensor is [5], where the authors propose an obstacle detection algorithm for legged robots. The starting point for the route is computed using a spiral search strategy, while the elevation map for the traversal is built using depth information, and breadth-first algorithm is used to determine traversable areas in the map. Experimentation using a six-legged robot, shows that, thanks to the definition of a set of judging rules, this approach is effective for real-time applications for the legged robot to go over certain kinds of obstacles namely steps, ramps and grooves.
In our previous work, in [8], we presented an obstacle detection system based on video analysis. Images are filtered to eliminate noise; after which, the road is removed and the candidate obstacles are determined; finally, the extended Kalman filter is applied in order to determine the trajectory the potential obstacles follow. Robustness to real-world conditions is the most relevant contribution of this work, where several lighting and surface variations were tested.
Outdoor obstacle detection
For road safety, an accurate perception of the environment is a must. Particularly, designing road safety systems for outdoor complex environments, poses a great deal of challenges related to real-time obstacle detection; for instance, determining where an obstacle is located or how to distinguish between objects and shadows in an open road. In the following, several works related to obstacle detection, based on data gathered by a Kinect sensor, images or infrared data, are presented.
The authors of [9] present a real-time obstacle detection system using two Kinect sensors. This system is aimed to help visually impaired people, by allowing them to navigate outdoor environments. Thanks to their dual setting, the system is able to construct a disparity map by using a block-matching algorithm; this map provides 3D information, which is then used for background segmentation, employing the random sample consensus algorithm. The authors report their solutions is low cost and efficient under extreme illumination conditions.
Another solution using the Kinect sensor, is introduced in [10]. The system is built employing information fusion for obstacle detection in outdoor environments. The mean-shift algorithm is used in the depth map to segment areas to be detected from the background. Depth maps are enhanced by using gradient calculation. Both, depth and infrared information, provided by the Kinect sensor, are fused and employed along with a sequential application of edge detection, morphological processing and the marking of edge information, after which, inaccurately detected objects are removed and the distance to the remaining objects is calculated. The experiments presented indicate the method is robust to a number of outdoor illumination conditions, with the ability to detect even small objects.
In [11] an outdoor detection method, using data provided by the Kinect sensor, was proposed. The authors focus on describing a set of filtering techniques that allow to translate a depth image into definite obstacle projections inside a navigability map, displayed on board of a vehicle. As a result, the authors showed that using Kinect sensor data to detect obstacles is better than using stereo vision.
FPGA implementation for obstacle detection
Obstacle detection has been widely studied in recent research. Hence, developing effective, easily portable, low-cost, and low-power consumption solutions, is an open challenge that deserves further research. Regarding this, the following works have proposed FPGA implementations to detect obstacles in outdoor environments.
In [12] the authors presented an architecture to detect obstacles, which is mounted on a belt; it uses data provided by an array of ultrasonic sensors. An FPGA implementation carries out data processing; this allows to activate and send vibrations, by using mounted motors, to specify the direction of the nearby obstacle.
In [13], a real-time hardware architecture, using computer vision to detect obstacles on a flat ground, is presented. The authors carry out localization with the help of Inverse Perspective Mapping, the Otsu’s method, and Bresenham’s algorithm. Their main contribution is that detection is carried out in real-time without prior knowledge of the environment, and that the architecture presented shows a good cost-effectiveness trade off, along with a fast frame processing, presenting both, low power consumption and low latency.
Proprioceptive sensors are merged with computer vision to present, in [14], a hardware/software system to detect and locate obstacles. This task involves a reconstruction, in real-time, of a 2D occupancy map (software module). An FPGA architecture us used to carry out obstacle localization. The architecture presented shows low-cost, low-latency, high-throughput and low-power consumption.
A comparison of recent related works based on hardware approaches is presented in Table 1, summarizing their main features and the differences among them, such as, data sensor, algorithms, characteristics analyzed, and implementation results.
Comparison of related works
Comparison of related works
*sl-r: slice-register; BRAM: block RAM; sl: slice.
The proposed outdoor obstacle detection system, focused on road safety, is based on a Multi-layer Perceptron Network model. The set contains signatures that represent the main object features used to detect an obstacle in an outdoor environment. This set is used to recognize approaching objects, emulating the way a human being carries this task out. The backpropagation ANN model is implemented in an FPGA, exploiting parallel structures that allow to carry out a trade-off among several architectures, analyzing their throughput performance and efficiency, and improving their required processing time.
The design of the outdoor obstacle detection system has been divided into two processes: 1) a process to evaluate and select the FPGA-ANN architecture, and the on-board implementation of the architecture selected to carry out outdoor obstacle detection.
Evaluation-selection process for the FPGA-ANN architecture
The process to select and evaluate the FPGA-ANN architecture is divided into five stages (see Fig. 2): 1) an outdoor environment data extraction module by using a Kinect sensor; 2) the creation of a data set from depth images with several obstacles (e.g. balls, flat top traffic cones, plastic traffic barriers and a-frame traffic barricades); 3) an image pre-processing step, where several filtering algorithms were processed to transform a color image into a gray-scale one, removing noise, selecting a region of interest, and eliminating the ground, in order to find the centroid of the object; 4) an image fingerprint extraction module, to identify the main characteristics of a potential obstacle; and 5) the implementation of ANN architectures in an FPGA, which allows to configure the modules and evaluate the results, in order to select the most adequate architecture, considering throughput, hardware resources, and efficiency.
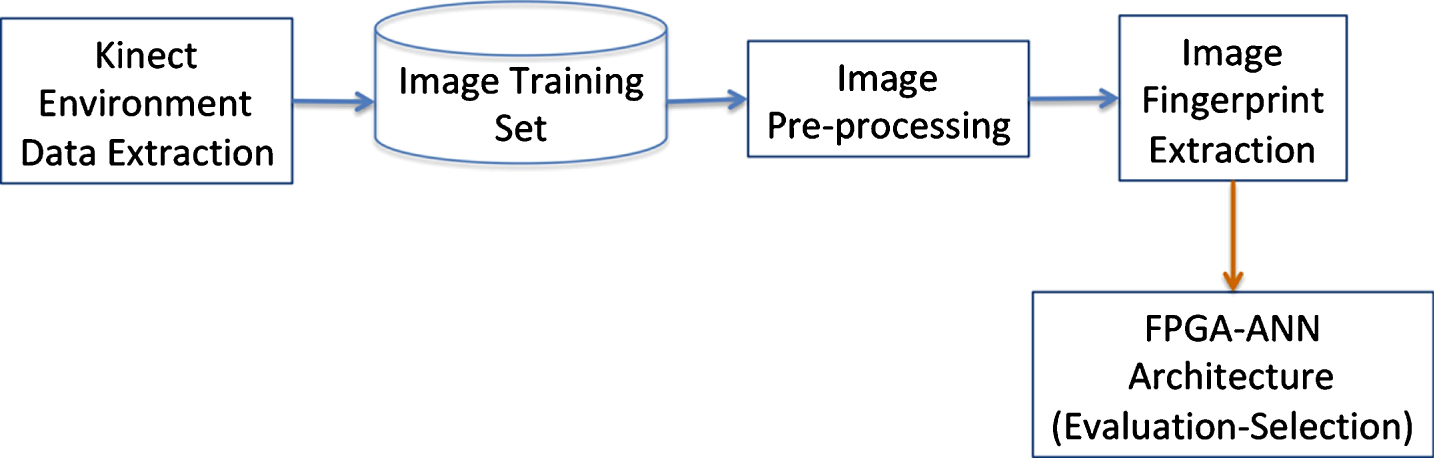
FPGA-ANN architecture selection for obstacle detection.
The FPGA-ANN architecture selected to detect and identify obstacles in outdoor environments is composed of five steps (see Fig. 3): 1) a module that senses the outdoor environment with a Kinect sensor; 2) an image acquisition step, which extracts an image, using the Kinect sensor, at a speed of 30 frames per second; 3) an image pre-processing module, where the color image is transformed into a gray-scale one, removing noise, selecting a region of interest, and eliminating the ground, in order to find the centroid of the object; 4) an image fingerprint extraction process, to identify the main characteristics of potential obstacles; and 5) obstacle detection, using the FPGA-ANN architecture, which processes the input image fingerprint.
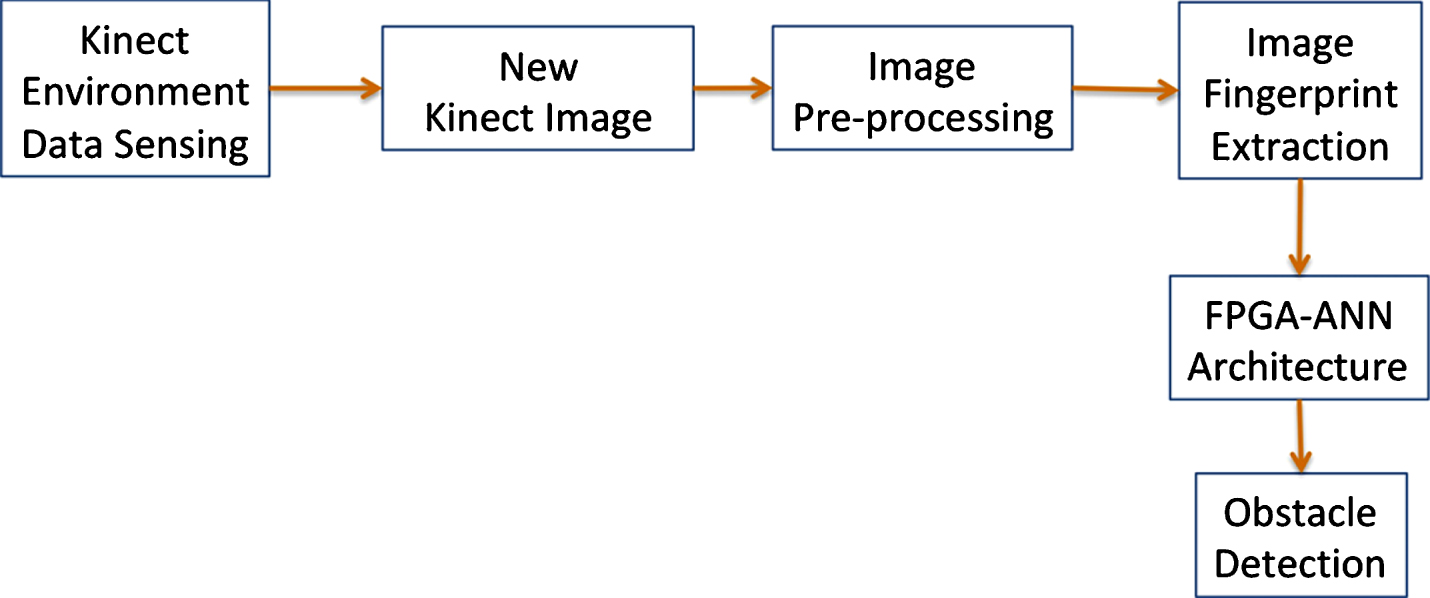
Implemented FPGA-ANN architecture for outdoor obstacle detection.
The used data set contains image fingerprints, which have different lengths: 16, 32 and 64 points (see Table 2); these fingerprints represent 4 types of objects: plates, balls, cups and glasses. This data set is divided into two sets: the test set and the training set. Each of the sets has image fingerprints of three different lengths, and contains 100 fingerprint samples for each type of object to be recognized; so there are 100 fingerprints for plates, 100 for balls, 100 for cups and 100 for glasses. In this way, each set is organized for each length (16, 32 and 64 points) and stores 1200 total signatures.
Examples of fingerprints in the data set
Examples of fingerprints in the data set
The ANN-based object recognition model uses fingerprints, which are distances between the object centroid and its external contour. These distances compose a fingerprint from a depth image and provide additional advantages such as: 1) adequate object scaling for discriminating among balls, bags, oranges, and similar forms; and 2) distinction between backgrounds and objects with similar colors or textures. Figure 4 shows examples for two objects, where centroid c, the x i points (where i∈ [1, n]) and length n = 16 are indicated.
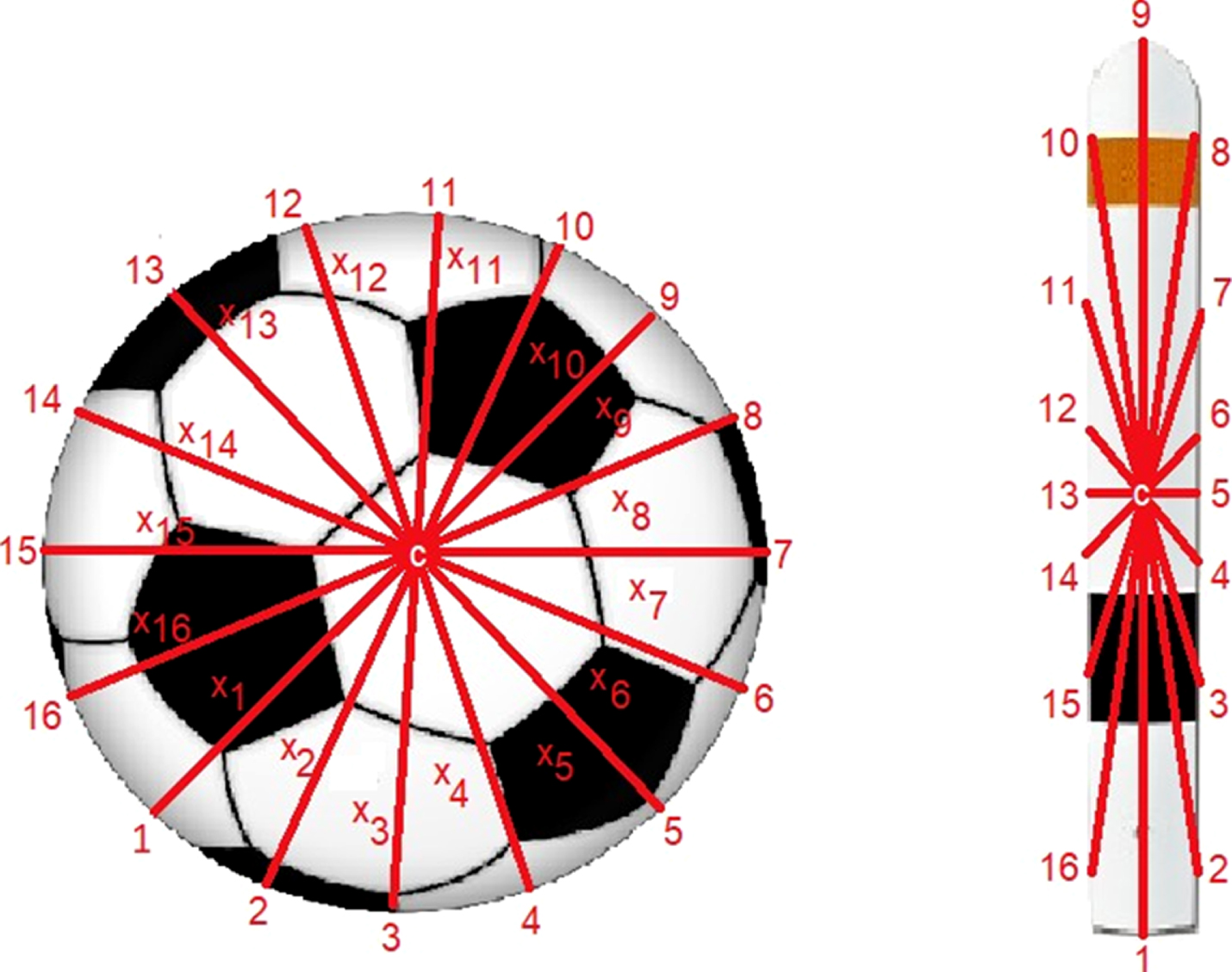
The dataset stores n distances x i , where i∈ [1, n]. In these examples, the fingerprint consists of 16 points for both, the ball and the traffic signal, so x1, x2, …, x16 are obtained.
The basic structure of the ANN configuration is shown in Fig. 5, which is an MLP (MultiLayer Perceptron) network, structured in three layers, called the input layer, the hidden layer and the output layer.
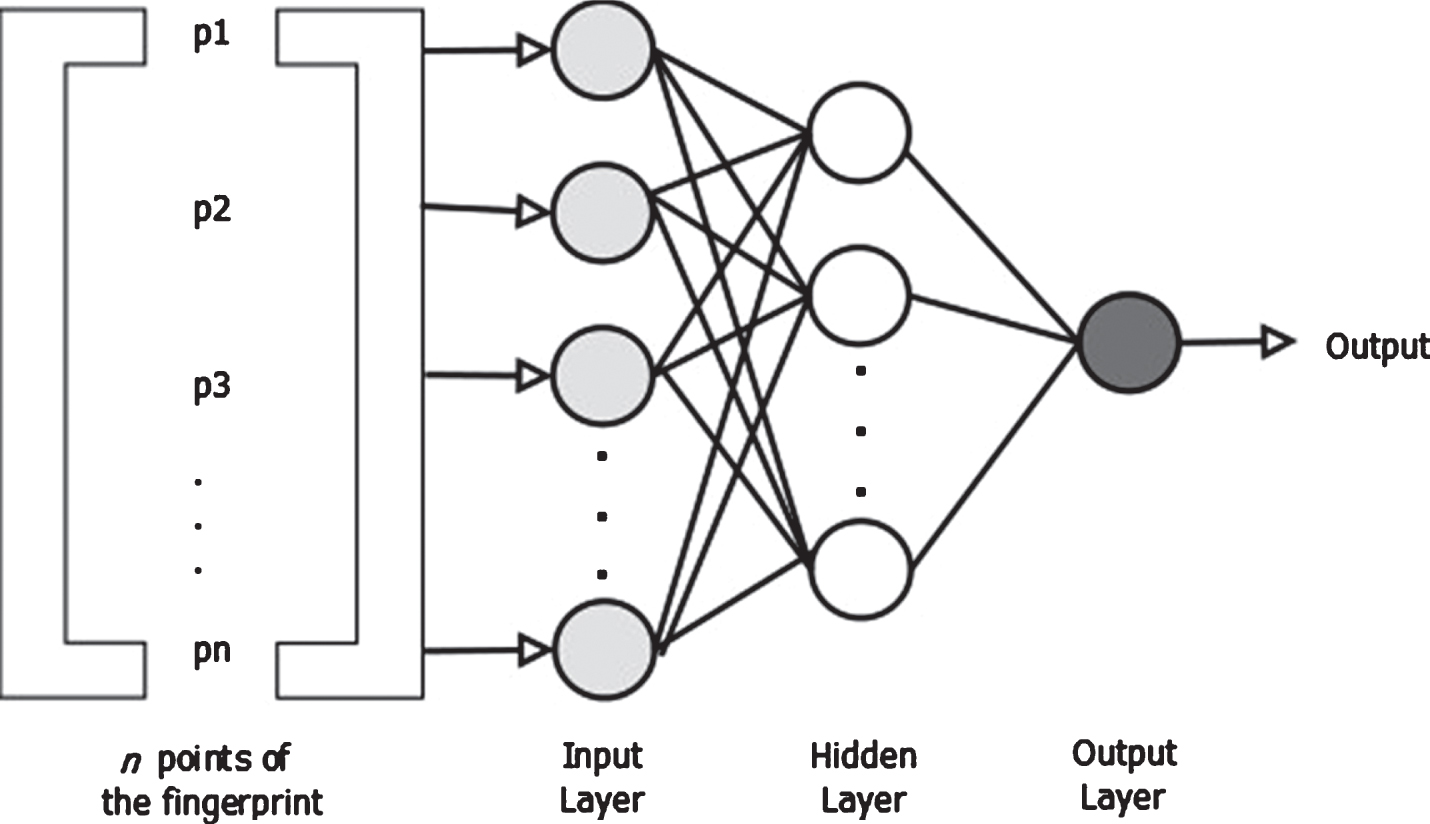
Configuration of a three-layer ANN.
In [15], 18 configurations were evaluated, resulting in the selection of the six with the lowest detection error. All these configurations are implemented by using blocks of Xilinx, and building the hardware architecture in Simulink for each configuration, also evaluating throughput and efficiency.
The six selected configurations are named 16×4×1, 32×6×1 and 32×2×1 for the logsig–logsig configuration, while for the tansig–logsig configuration they are 16×4×1, 64×3×1 and 16×1×1 (see Fig. 6). These names contain three numbers, representing the number of neurons in the input, hidden and output layers, respectively. From the training carried out for these configurations, the obtained weights and bias are stored in the architectures by implementing ROMs/RAMs. Also, the computed fingerprints are stored in these memories, which are used to classify the object according to the ANN-based recognition model.
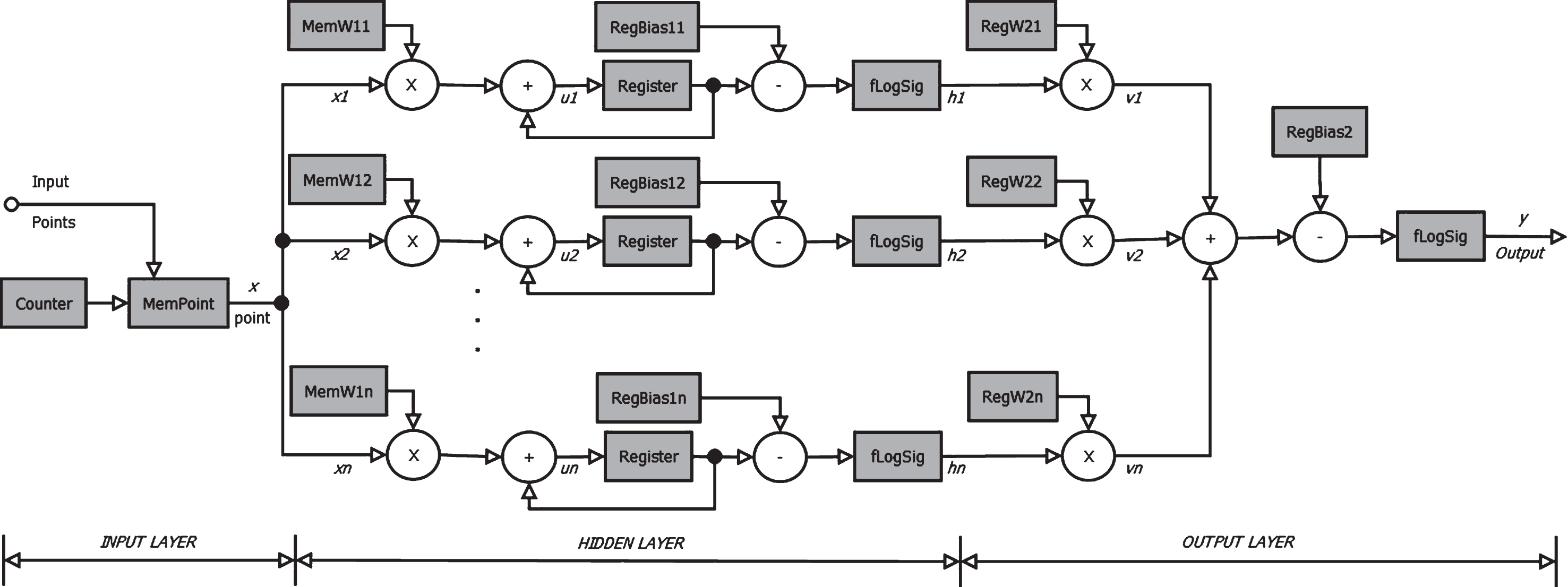
General hardware architecture for logsig–logsig and tansig–logsig configurations.
The first three hardware architectures belong to the logsig–logsig configuration while the last three proposals correspond to the tansig–logsig configuration. The difference among these architectures lies in the number of neurons and the activation functions that they require for object recognition. Each architecture needs a different latency, depending on the number of input points, that is, if the hardware architecture takes 16 points, then 17 clock cycles are needed: 16 clock cycles for processing the 16 points and the last cycle for determining the output. Similarly, the hardware architectures for 32 and 64 points require 33 and 65 clock cycles, respectively.
In general, the design for the six architectures is based on the structure of the ANN-based configuration, where they use the weights and bias obtained from the training process. In this hardware design, the training set is used and the multiplication of weights by the points is done iteratively; when the processing of all the points is completed, the remaining operations are carried out in parallel until the output is obtained.
The six architectures are evaluated to examine recognition performance, using the test set; the purpose is to use the metrics defined in Section 2.3, in order to compare the hardware architectures and select the best configuration, in terms of recognition rate, throughput and efficiency (see Table 3).
Recognition rates of the ANN-based hardware implementation
Table 3 shows the recognition rates for each hardware architecture, where the architectures with the best object recognition performance are: the 16×4×1 hardware architecture of the logsig–logsig configuration, and the 16×4×1 hardware architecture of the tansig–logsig configuration. In this manner, these two hardware architectures are analyzed for six FPGA devices and different metrics are evaluated.
For the analysis, the hardware implementations are performed using System Generator, selecting the Timing and Power Analysis process and generating the Place and Route Report and the Post-PAR Static Timing Report, where hardware resources, minimum period and maximum frequency are obtained. The evaluation of each architecture is carried out in different FPGA technologies: Virtex (V4, V5, V6 and V7) and Spartan (S3 and S6). See Tables 4 and 5 for the logsig–logsig and tansig–logsig configurations, respectively. Both implementations require a latency of 17 clock cycles.
Hardware results of the logsig–logsig configuration
*sl-r: slice-register; BRAM: block RAM; sl: slice; bps: bit per second; Hz: Hertz.
Hardware results of the tansig–logsig configuration
*sl-r: slice-register; BRAM: block RAM; sl: slice; bps: bit per second; Hz: Hertz.
It is well known that both, Virtex and Spartan technologies, have advantages and disadvantages, such as their cost or their physical characteristics. Thus, according to Tables 4 and 5, the logsig–logsig and tansig–logsig configurations implemented in the V5, V6 and V7 devices, report the best throughput and efficiency. These results are obtained using the 16×4×1 architectures for both configurations.
Analysis and results are important because they are necessary to determine the hardware architecture with the best recognition rate and the highest efficiency for object recognition. Moreover, the analysis of the ANN proposals in this work shows that, at least in our experiments, the fewer the number of points, the better the recognition rates provided by the ANN-based model. Additionally, a classifier system trained with an excessive number of object features can be too specific for those features [16], producing an overfitting phenomenon. The implementation results of the 16×4×1 hardware architectures from the logsig–logsig and tansig–logsig configuration are analyzed. For example, for the case of the first configuration and the amount of processed data by unit time, Fig. 7 (a) shows that the 16×4×1 device, reaching 3.4862 Gbps, unlike the V5 device These results are related to the used technology; since the V7 is more advanced, because it has a higher level of integration and density with more-specialized processing blocks and a greater number of input bits. Likewise, hardware architectures, in the case of the logsig–logsig configuration, show an independence of FPGA technologies for the V5 and the V6 (similar throughput), while the hardware architecture, in the case of tansig–logsig architectures, presents a more relevant dependency according to the FPGA technology (different throughput among V5, V6 and V7) (see Fig. 7 (b)).
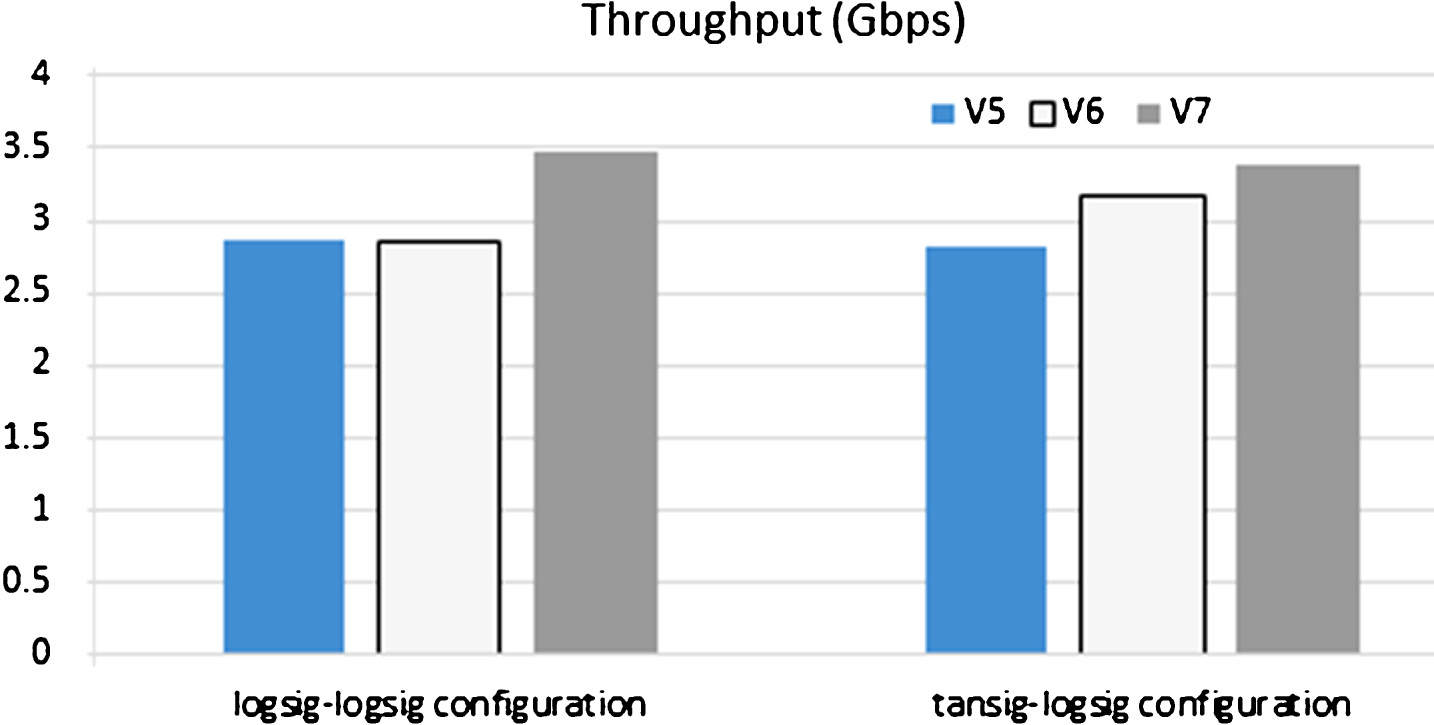
Throughput of the hardware implementations.
Other important analysis is to determine the hardware implementation with the best throughput but using the hardware resources in the best manner, which is named efficiency. In this work, two types of efficiency are presented, and for the first case, Fig. 8 shows the efficiency in terms of bps/slices (bits per second/slices of the FPGA), where the architectures implemented in the V7 technology show the highest efficiency. This conclusion allows to highlight that the structure of the V7 is adequate to the hardware architectures of the ANN-based model that is being proposed in this work, and this result is very different when the throughput is separately analyzed. In several cases, it is demonstrated that implementations on the V7 can reach better throughput, but lower efficiency, and vice versa.
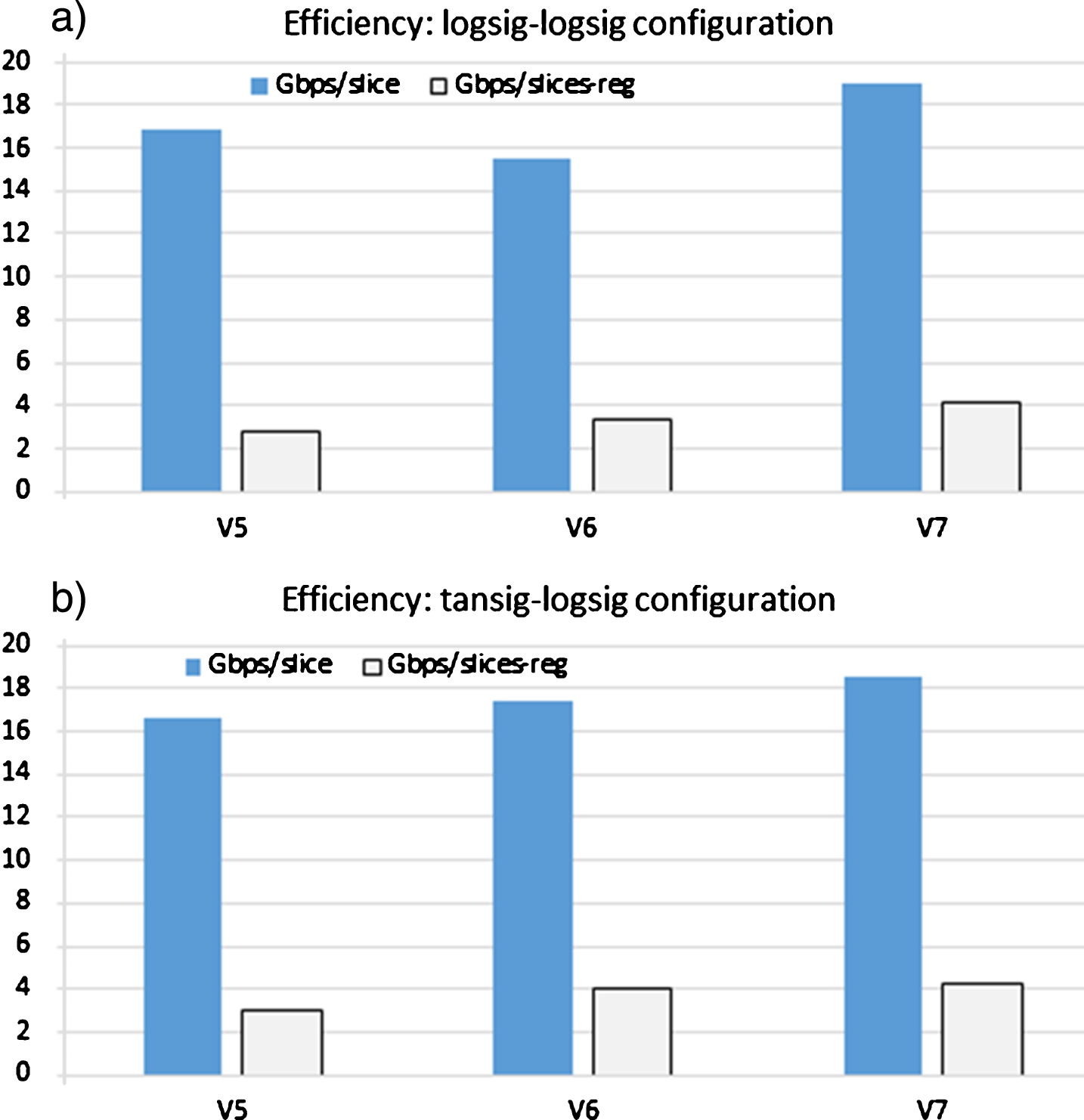
Efficiency comparisons (Gbps/slice) of the implementations.
The second case of efficiency is when the throughput is analyzed with technological independence, that is, the efficiency that considers throughput by the clock frequency (bits per second by Hertz). In Fig. 9, it is shown that the hardware implementations report higher efficiency on V5, for example, the efficiency has a value of 28.2353 Kbps/Hz for the logsig–logsig configuration, due to the number of neurons and the bits processed by each LUT in this technology.
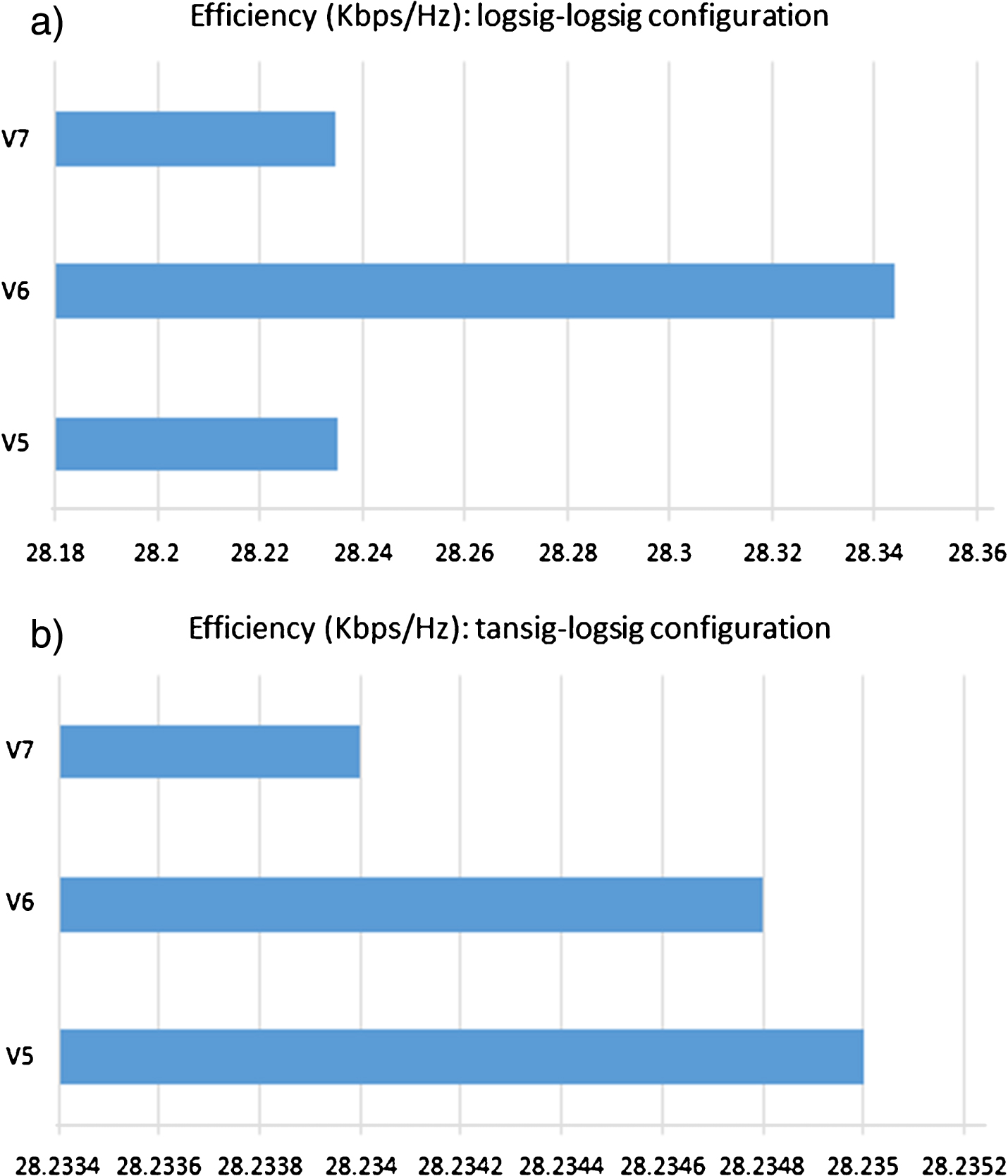
Efficiency comparisons (Gbps/Hz) of the implementations.
Considering previous results, the 16×4×1 architecture is ideally implemented in the V7 device since this technology positively impacts the throughput, while the V6 device is a second option. Conversely, the V7 technology is more expensive, since it is more advanced and has a higher level of integration and density, with more specialized processing blocks and a larger number of input bits; although, if the V5 technology is used, then better results are obtained in terms of efficiency, since there is a better throughput, regardless of the technology, that is, the efficiency computed in this point is based on the throughput and the clock frequency.
It is described that the comparisons with respect to the throughput are not fair because different FPGA technologies are used and there are large generational gaps, so efficiency is also used, where the relation throughput/clock cycles and the relation throughput/hardware resources are considered [17]. Analyzing and reporting the proposed hardware architectures, the V5 devices present better results on efficiency, the V6 devices have the most balanced characteristics and the V7 devices enable higher-throughput implementations.
Finally, a comparison among the implementation characteristics of both configurations is made to evaluate which of the two ANN-based hardware architectures must be used for object recognition on the V5, V6 and V7 technologies (see Fig. 10).
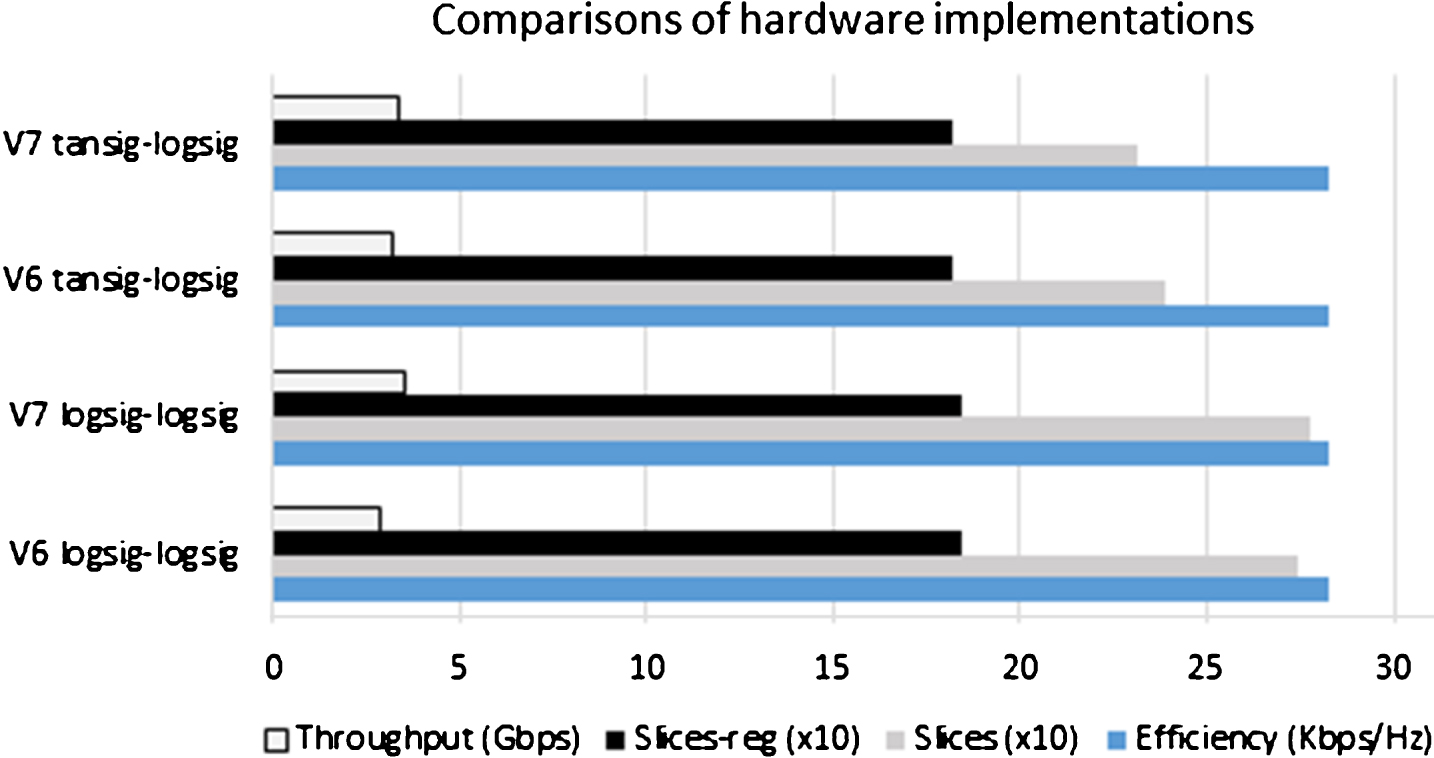
Comparisons of the two final implementations.
Additionally, the 16x4x1 architecture with activation functions logsig–logsig, implemented in the V7 device, is the best qualified, since this configuration has the highest recognition rate in hardware, and the best throughput at technology level, which reports values of 98% and 3.4862 Gbps, respectively.
On the one hand, in [15], the best-qualified final software implementation works at 10.788 Mbps, while in the present work, the best equivalent hardware implementation reports a throughput of 3.4862 Gbps; this is, the hardware implementation is 323.4 times better than the software one, in terms of throughput. On the other hand, the processing time in software to recognize a fingerprint is 95 ms, while the hardware implementation requires just 137.6 ns, providing 693.4 times of improvement.
Hardware complexity of the proposed architecture is listed in Table 6, in terms of N + 1 memories of size N, 2 N multipliers, 3 N adders/subtractors, 3 N+1 registers, N + 1 fLogSig and 1 counter. Time complexity of the proposed architecture is listed as well in Table 6 in terms of number of cycles. The architecture requires a latency equal to 4 + N clock cycles, where certain hardware blocks are combinational circuits and do not require clock cycles (N.A.); in addition, certain hardware blocks are sequential circuits, but they are executed in parallel, so they do not contribute to the latency (N.L.C). Moreover, the clock period is defined by the maximum clock frequency, and the critical path is located on the first line of f LogSig and the second line of f LogSig.
Hardware and time complexity of the proposed architecture
N=Number of inputs. N.A.=Not Applicable. N.C.L.=Not Contributing to Latency.
The design and a thorough analysis of a number of real time obstacle detection architectural variations, considering features such as, easy portability, low-cost, and effectiveness, is presented in this paper. In the context of road safety (which implies an outdoor environment), objects are considered obstacles when they are located over the road. Hence, an important issue is real-time obstacle detection, in order to assist on-board decision making for automotive applications, focused on avoiding traffic accidents by timely warning when an obstacle is located.
In this work, several trade-off analysis of FPGA-ANN hardware architectures are presented, which show advantages on hardware implementations such as high throughput, high efficiency and high object-recognition rates. This provides with important characteristics when an ANN-based model is used, because it presents parallel structures and benefits in the detection process. In the proposed architecture, several clock cycles are necessary to compute the result, considering points of the fingerprints are stored on the ROM; hence, future work will focus on double-port memories and multiple data inputs, requiring new hardware designs and analysis.