
Abstract
Reusing knowledge obtained in other related but different tasks to accelerate the learning procedure of reinforcement learning (RL) has attracted more and more attention and expert knowledge transfer is the root cause of positive effect. Nevertheless, compared with acquiring knowledge by RL training in source tasks, this paper proposes to transfer knowledge contained in human-demonstrations of source tasks. Based on this, three specific forms of knowledge in total are mined from demonstration trajectories to be reused in the target task to shape RL and all of them are closely associated with the similarity between states of different tasks which can be measured by Euclidean distance via human-supplied inter-task mappings. In more detail, the similarity between the target state and the most similar state in source samples, the proportion of different actions among the k-NN of the target state in source samples and the proportion of different actions under a constant similarity with the target state in source samples are respectively selected to initialize the value of state-action function. Simulation experiments of mountain car problems with different difficulties and different dimensions suggest that all the three shaping methods could obviously speed up RL. In comparison, it can also be found that the two latter methods are more robust and efficient to the quality of human demonstrations as it takes more source samples’ information into consideration.
Introduction
As time goes on, endowing the learning agent with the ability to solve unknown tasks by autonomously interacting with the environment other than completely relying on hand-coded programs has been the research hot [1]. Reinforcement Learning (RL) is a feasible technical route and it has attracted an increasing number of studies in machine learning, operation research and automatic control during the past few decades [2]. Nowadays, RL has shown a very strong human-level control, for example AlphaGo defeats one most excellent chess player in first half of 2016 [3]. Nevertheless, tabula rasa learning (starting learning without knowing anything about the task) which is the most distinctive feature of RL prevents its widespread use in practical control as it would result in time-consuming random exploration and research in RL domains at present are mainly with the objective of expediting the learning process.
From the perspective of improving interactive data efficiency, many techniques such as options [4], hierarchical learning [5], Actor-Critic (AC) [6], experience replay (ER) [7], and so on are proposed to integrate with RL and the effect is obvious.
From another kind of view, providing the agent with some expert knowledge about the task is a new direction though it seems to be conflicted with RL’s tabula rasa learning. In fact, expert knowledge can be of various forms, for example, symmetry in state-action space of task [8] and shaping rewards [9] and it is not contradictory. If expert knowledge is acquired in a different task, the reusing process can be called transfer learning (TL). Despite that TL has been combined with many machine learning algorithms since 1990 [10], it is not until recent years that the combination with RL has achieved tons of attention [11–14].
Three aspects must be taken into consideration when using transfer [12, 15]: 1) selection of the source task; 2) forms of transferred knowledge; 3) methods of reutilizing gained knowledge. However, no transfer method can complete these three aspects autonomously up to now [12]. Now, gaining expert knowledge with RL in the source task covers most of the research [13]. But RL has superiority in solving complex tasks and making using of RL to acquire knowledge in a simple task is not a wise choice. What’s more, designing related reward function in two tasks is also a great challenge for expert [13].
Now, there is some research that combines learning from demonstration (LfD) and RL where rather than transfer of value function, such as state value function [12], optimal policy [16], skill [14] and so on when using RL to train source tasks, knowledge is wholly contained in demonstrations. The agent should mine an appropriate form of knowledge from demonstrations to accelerate RL, for example, García et al. [17] took advantage of demonstrations to avoid unsafe exploration in RL which is called safe reinforcement learning (SRL), Theodorou et al. [18] utilized demonstrations as an initial control solution for path integral control (PIC), Taylor et al. [19] extracted rules from demonstrations to assist RL which is called human-agent transfer (HAT) and Brys et al. [15] used demonstration trajectories to shape RL.
However, knowledge transfer should come about across different tasks in conventional sense, but now, research of combining LfD and RL confines transfer in the same task. As a result, this paper proposes that RL can reuse knowledge derived from demonstrations of source tasks in target task and it would be easier to achieve strong transfer [12, 20]. Effect of constructing an extra reward function or guiding the agent to explore by demonstrations has been discussed [21], in this paper, three other forms of derived knowledge which are closely related to the similarity between state of the target task (target state in brief) and source samples are used to shape the initial state action value for RL.
The rest is organized as follows: Section 2 gives the definition of RL, reward shaping and LfD. Section 3 introduces the three proposed approaches of deriving knowledge from demonstrations of a simple task to initialize RL. Section 4 utilizes a benchmark simulation experiment to evaluate different shaping methods and performances are compared. The last section comes a conclusion and the future work.
Background
Reinforcement Learning (RL)
Reinforcement Learning is suitable for solving sequential decision problems described by Markov Decision Process (MDP). A MDP is determined by 5 tuples 〈S, A, P, T, γ〉, where S is state space agent can reach, A is action space agent can execute,
State action value function along the interaction with environment can be calculated by:
As Actor-Critic methods shown by Fig. 1 combine Critic-Only methods’ low variance estimate of policy gradient with Actor-Only methods’ good convergence, they are among the most popular algorithms of RL.
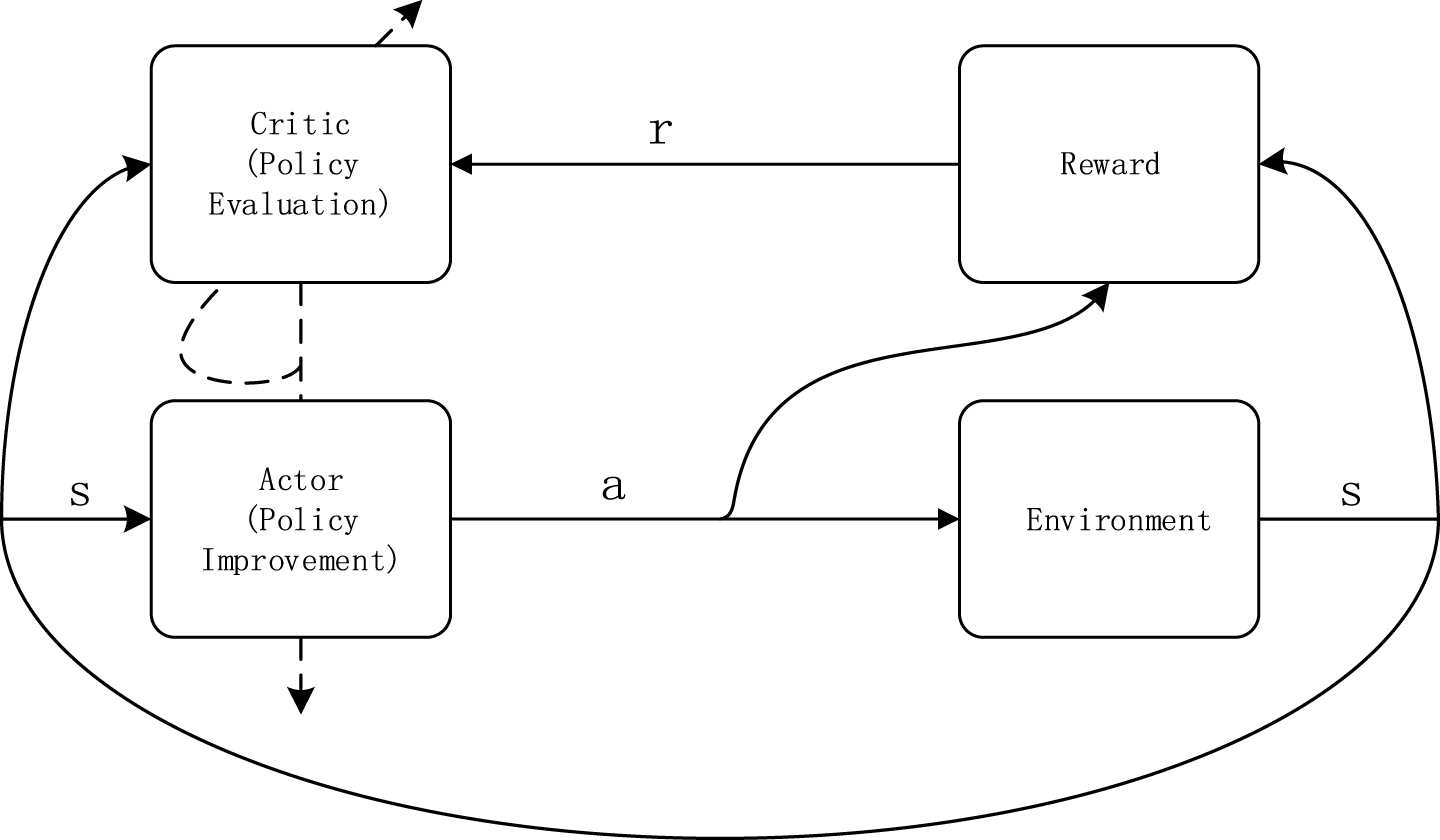
The Actor-Critic framework.
In 2008, Peters et al. [22] proposed NAC to incorporate natural gradient into Actor-Critic methods and it further raised sample’s utilization efficiency by overcoming the large plateaus in expected return and pointing directly to the optimal solution. This paper takes NAC as an example of RL to illustrate the proposed transfer methods’ positive effect. For further details of NAC, readers can refer to Peters’ work [22].
In RL, the target of learning is included in the design of reward function. Restricted by the level of expert knowledge, reward function may be very simple. For example, only when completing a task can the agent get a non-zero reward, and in other cases, reward is zero. It is an intuition that informative reward can shorten the learning process.
Inspired by this, shaping [13, 23] refers to construct a heuristic reward to contain ‘hints’ and it can accelerate the learning speed by altering the temporal difference value i.e., the amount of each update in the brackets of Equation (2) when evaluating policy:
Among all the shaping methods, potential function proposed by Ng et al. [23] is an efficient one as Equation (3) shows:
The object of LfD is to develop a policy of exact representation from demonstration trajectories [25] and LfD can play an important role in situations where defining the control objective with a simple reward function is very difficult, for instance, what is ‘flying well’ of an unmanned aerial vehicle [26]. Another advantage of LfD is that expert could demonstrate the task without many failures even though demonstrations are not perfect.
In LfD, supervised learning techniques such as classification and regression can be used to derive a control policy from the demonstrated state-action samples and the function of policy is to generalize actions from demonstrated samples to unvisited states. Nevertheless, when demonstrations are used as a knowledge pool, a suitable knowledge form should be derived as prior information other than an exact policy. In addition, it must be noted that derived knowledge should be robust to avoid the bad influence of some poor demonstrated samples since demonstrations may be of poor quality.
Shaping by human-demonstrations of a simple similar task
The agent of RL can benefit from different forms of source knowledge and they can be unified in a framework as Fig. 2. It shows that knowledge can be gained by RL training, demonstrations or supplied by expert directly.
Based on this, the paper supposes that various forms of knowledge which should be transferred to the target task can still play a positive effect when the target task is different from the source task. To enhance persuasion, three methods are introduced to derive robust knowledge from the demonstration samples with either good or poor quality to shape RL in a different task.

The unified transfer framework for RL.
In this section, function f is defined to initialize state-action value Q (s, a) for the target task with the demonstrated samples as Equation (4):
When the state-action value is approximated by linear function as Equation (5) shows,
Proposed three specific methods below all focus on how to initialize the weight parameters of Radical Basis Functions (RBFs) as an example and it can be extended to discrete state space or other function approximators all the same. What’s more, it should be noted that in the three methods, Euclidean distance (dis) is regarded as similarity measure in to associate different states in different tasks when their state space keeps consistent or inter-task mappings are given (both state and action mappings) [12].
Preference for different actions in some state can be reflected in state-action value. For a target state, if the most similar demonstrated sample takes action A, the value of A’ corresponding action in the target task should be relative high to guide the agent to take it with greater probability.
As value of RBF decreases with the growing of state’s distance to the center, the RBF whose center point is most similar to the state among all the RBFs plays a decisive role in determining the size of state-action value. Inspired by this, method 1 initializes parameters θ for different actions according to centers’ distance to the most similar demonstrated sample as Equation (6) shows:
Above all, method 1 can be realized by three steps: classify demonstrated samples according to the different actions as states with different actions are deemed to have no relation at all; for each class, calculate the similarity between the center of the basis function and the samples to select the most similar sample; determine the initial weights for corresponding action according to Equation (6).
Nevertheless, in method 1, only center’s most similar state plays a role in the process of initialization and information of all the other samples are deserted. It is a waste of information. In addition, the quality of demonstration trajectories would not be guaranteed as expert cannot give an exact optimal policy, especially if expert takes a suboptimal action or even bad action in state that is most similar to RBF centers, it would mislead the selection of actions in the target task and the performance is limited. In a word, the performance of shaping by very few samples may be sensitive to the quantity of demonstrations.
In order to reuse information contained in more samples and design a robust shaping method, k most similar samples of the center among the demonstrated samples are selected.
k-NN is a famous supervised learning algorithm and it takes use of k samples’ labels to vote for new sample’s best label. Similar but different with k-NN, method 2 initializes the weights of RBF for different actions by the proportion of different actions in the k most similar samples of the center as Equation (7) shows:
Method 2 can also be realized by three steps: measure the similarity between source samples’ state and the center of RBF; sort samples according to the size of similarity and select k most similar samples; count the numbers of different actions in the k samples and make use of the adjusted proportion of different actions as the relative value for different actions as Equation (7).
Method 2 is based on the truth that agent selects action according to a probability constructed by state-action value in RL and when samples near the target state take some action more frequently, the initial weights of the target task should encourage the agent to select the corresponding action with greater probability.
In this subsection, method 3 only concerns the demonstrated samples under a certain similarity with the center of RBF and samples that are far away from the center are of no reference value for action selection in the state of the target task where this basis function plays a decisive role for the value. The underlying reason is that agent should select similar action in similar states, and the farther away the new state is from a state, the less influence can it have on the selection of action.
Above all, method 3 can be realized by three steps: measure the center’s similarity with all the source samples; select the samples that similarity is under a predetermined constant; take advantage of different actions’ proportion as the relative value for different actions in the target task as Equation (8):
where definitions of cons and function I are consistent with Section 3.2 and sum (dis < rim) calculates the number of samples under distance value rim. The idea is similar to method 2.
Experimental setup
Mountain car tasks [27] with different dynamic models and dimensions as Figs. 3 and 4 are used to evaluate the proposed methods.

Mountain car problem.
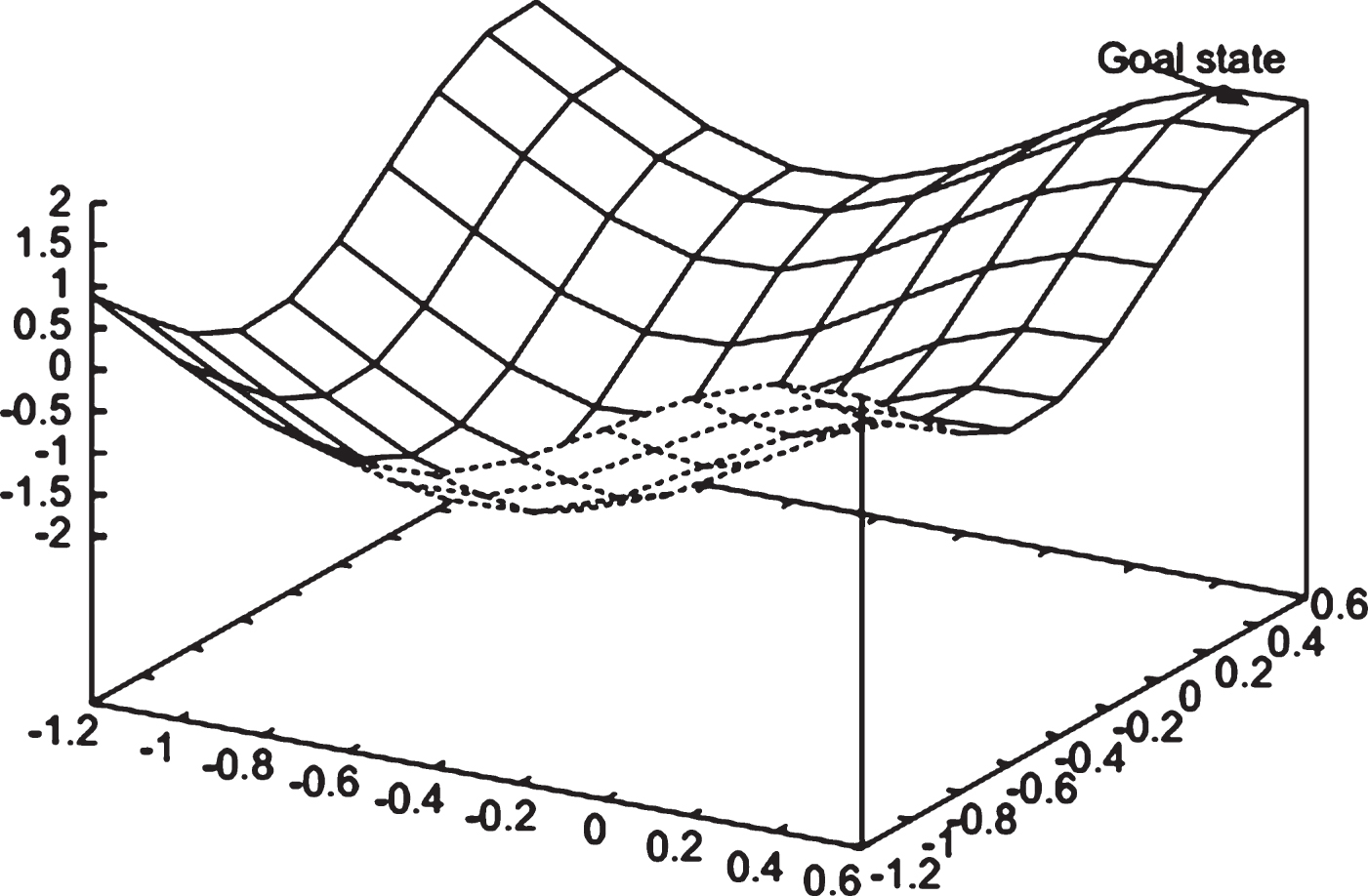
3D mountain car problem.
In mountain car problem, the goal of the agent is to drive an underpowered car up a steep mountain described by sin(3x) or sin(3y) as quickly as possible. The difficulty is that gravity is stronger than car’s engine in some states and it is impossible for the car to accelerate up the slope directly. The car needs to move up the opposite slope firstly to store enough inertia.
In 2D tasks, state space consists of car’s horizontal position x and velocity
In source task, value of actions is large, i.e. –0.2, 0, +0.2. It can be demonstrated easily and then expert knowledge is encoded into the demonstration trajectories. In order to enhance the persuasion, there are two new target tasks, one is with lower power in 2D, i.e. –2/15, 0, +2/15 and the other is with 3D dimension which is related by inter task mappings as Table 1 shows.
The inter-task mappings of state space and action space
In target tasks, reward is +1 only when the goal position is reached, and otherwise it is –0.01.
RBF as Equation (10) is used to approximate the state-action value,
Parameters of NAC keep consistent in all tasks and though they are probably not optimal, the contrast is effective.
The expert demonstrates the source task for three times with both good and poor quality and then expert knowledge is encoded in demonstration trajectories. Trajectories of good quality is composed by 139 state-action-state samples and 208 state-action-state samples compose trajectories of poor quality. The number of interaction is relative small compared with using NAC to obtain a near optimal policy in the source task and it can be found in following tables.
When the car reaches the goal or the number of steps is greater than 800 in 2D tasks or 2000 in 3D task, a training episode ends and the performance of RL is evaluated according to the steps for the car to reach goal position after each training episode ends. In order to reduce random errors, the learning process is repeated from the same initial state with a random disturbance for 5 times.
Comparisons in the same task
Figures 5, 6 and Table 2 give the simulation results of various shaping methods in the same task so as to compare with previous research whose tasks keep the same.
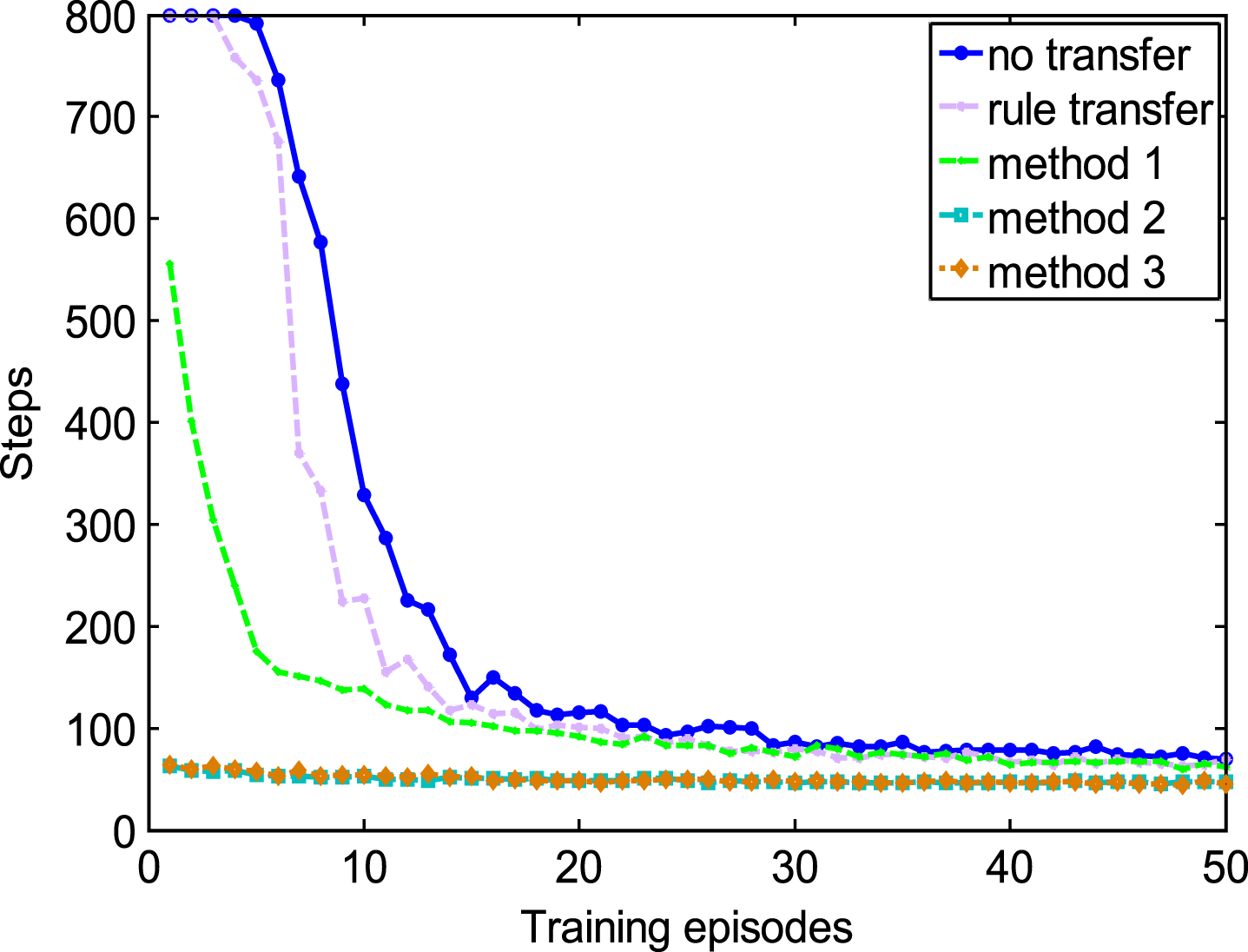
Comparisons in the source task with demonstration of good quality.
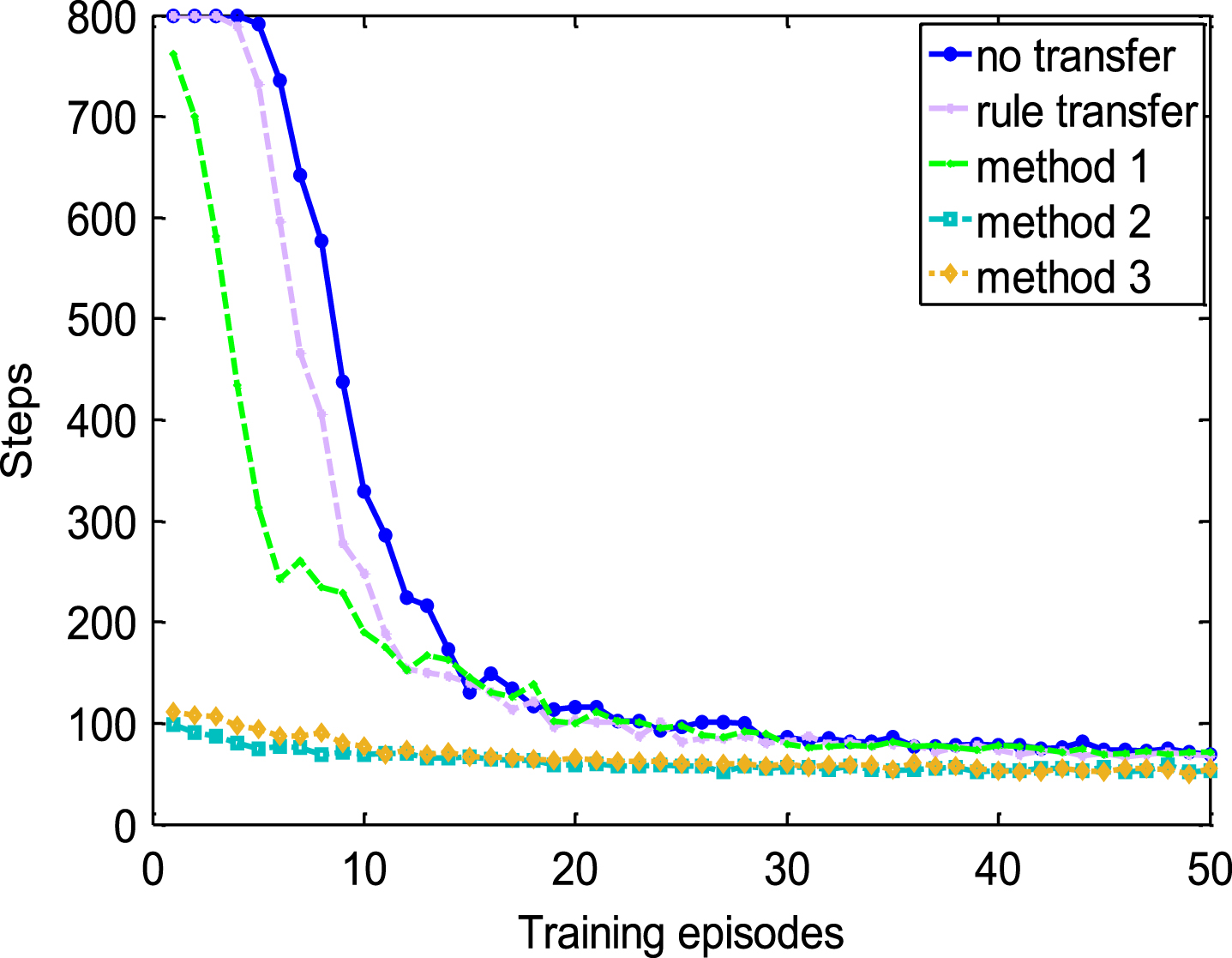
Comparisons in the source task with demonstration of poor quality.
Performance in the same task
Rule transfer introduced by Taylor et al. [12] is selected as a comparison and rules are derived from demonstrated samples by Weka’s M5Rules.
Figures 5 and 6 show that both the four transfer methods can accelerate the learning speed in view of the training episodes though the benefit is related to the quality of demonstrations. The improvement can be easily found from the view of jumpstart and asymptotic performance, especially the jumpstart of method 2 and method 3. By comparing the two figures, it can also be found that when the quality of demonstrations becomes poor, jumpstart of method 1 decreases from 240 steps to 40 steps while that of method 2 and method 3 keeps a high level at around 700 steps. In other words, the effect of method 2 and method 3 is more robust to the quality of demonstrations than method 1 though they are all more efficient in view of training episodes than rule transfer.
Data in Table 2 shows that in view of training samples, the performance of shaping by method 1 and assisted by rules derived from demonstrations of poor quality is even worse compared with regular RL because shaping function may guide the agent to explore more times in each training episode. It is also obvious that the reduction in the number of training samples with our shaping methods is greatly large compared with the number of demonstrated samples and it can be considered as strong transfer.
Figures 7, 8 and Table 3 compare performances of different methods in a relative hard 2D task. It is clear that reusing knowledge of various quality has a positive effect in accelerating speed of RL though the task changes.
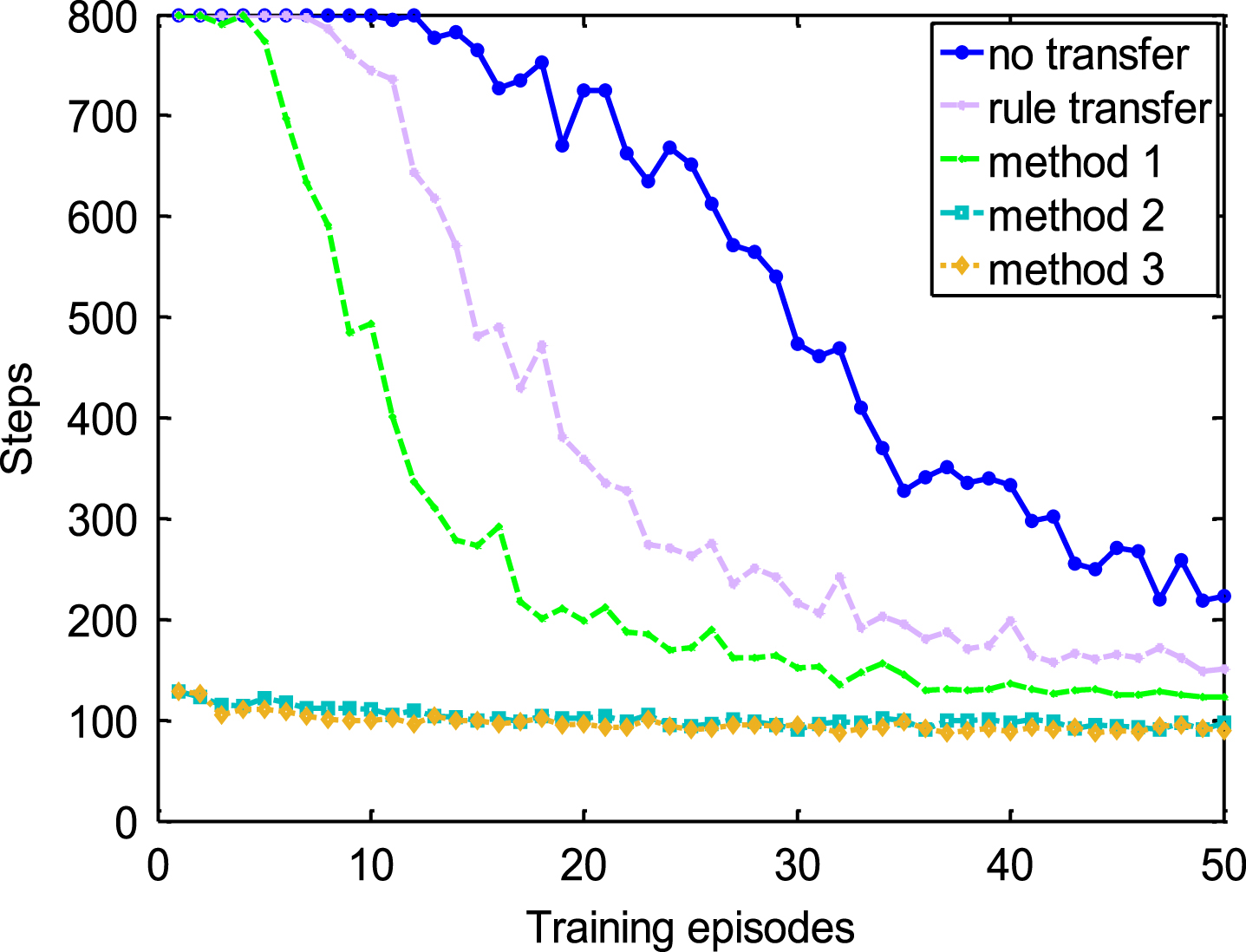
Comparisons in a relative hard 2D task with demonstration of good quality.
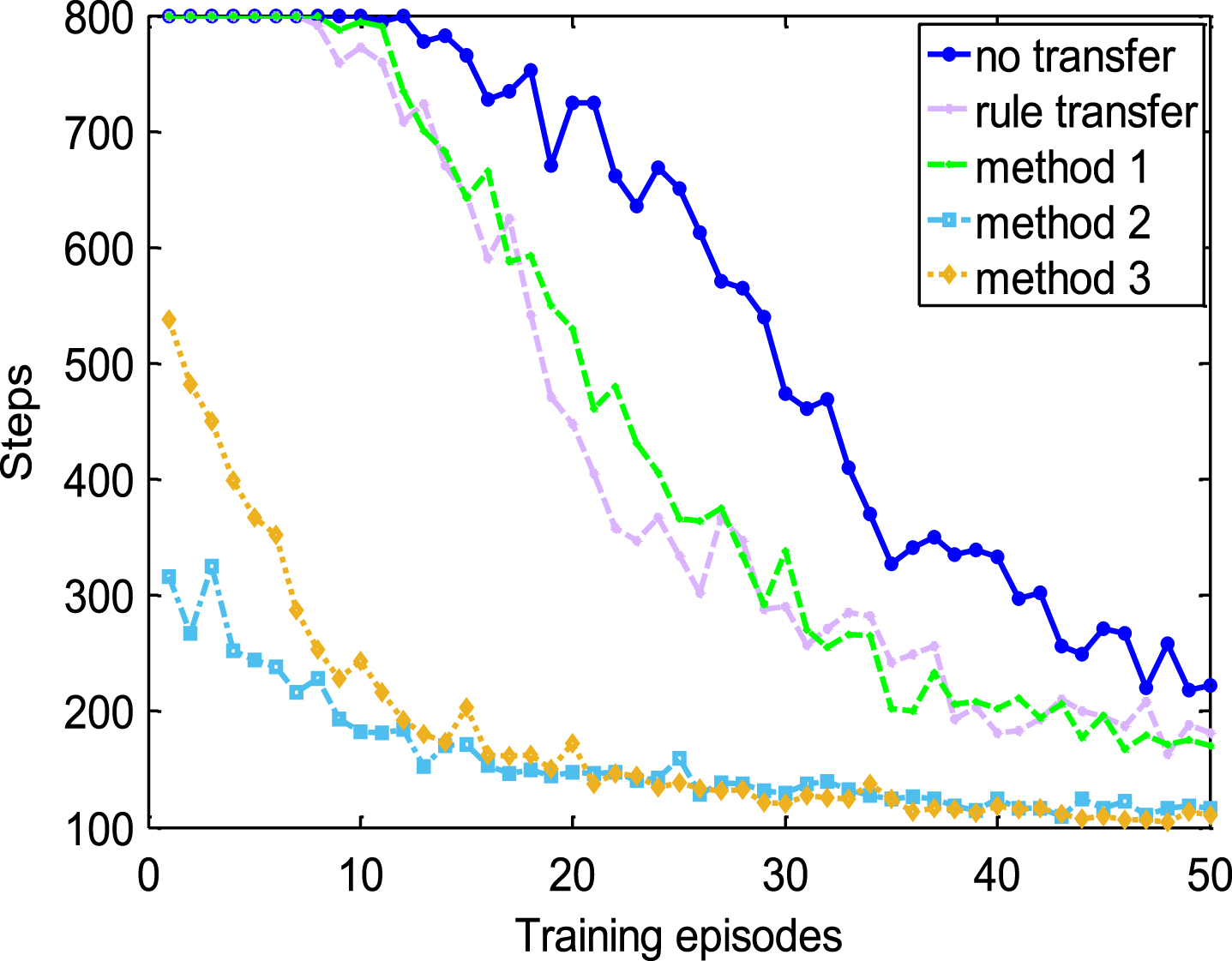
Comparisons in a relative hard 2D task with demonstration of poor quality.
Performance in a hard 2D task
It can be found that when demonstrations are of good quality, performances of the proposed three methods is better than rule transfer in view of both training episodes and training samples, especially the jumpstart of method 2 and method 3. When the quality of demonstrations becomes poor, the jumpstart decreases from 680 steps to 260 steps for method 3 and to 480 for method 2, nevertheless, the performance of method 1 has even no advantage over rule transfer any more from two views. In the meantime, training samples of RL with method 2 and method 3 is much less than shaping by method 1, rule transfer or without transfer. All in all, there is a conclusion that method 2 and method 3 are more effective and robust compared with method 1 and rule transfer when the task changes.
Figures 9, 10 and Table 4 show us the results of transferring knowledge contained in various quality of demonstrations to 3D mountain car.
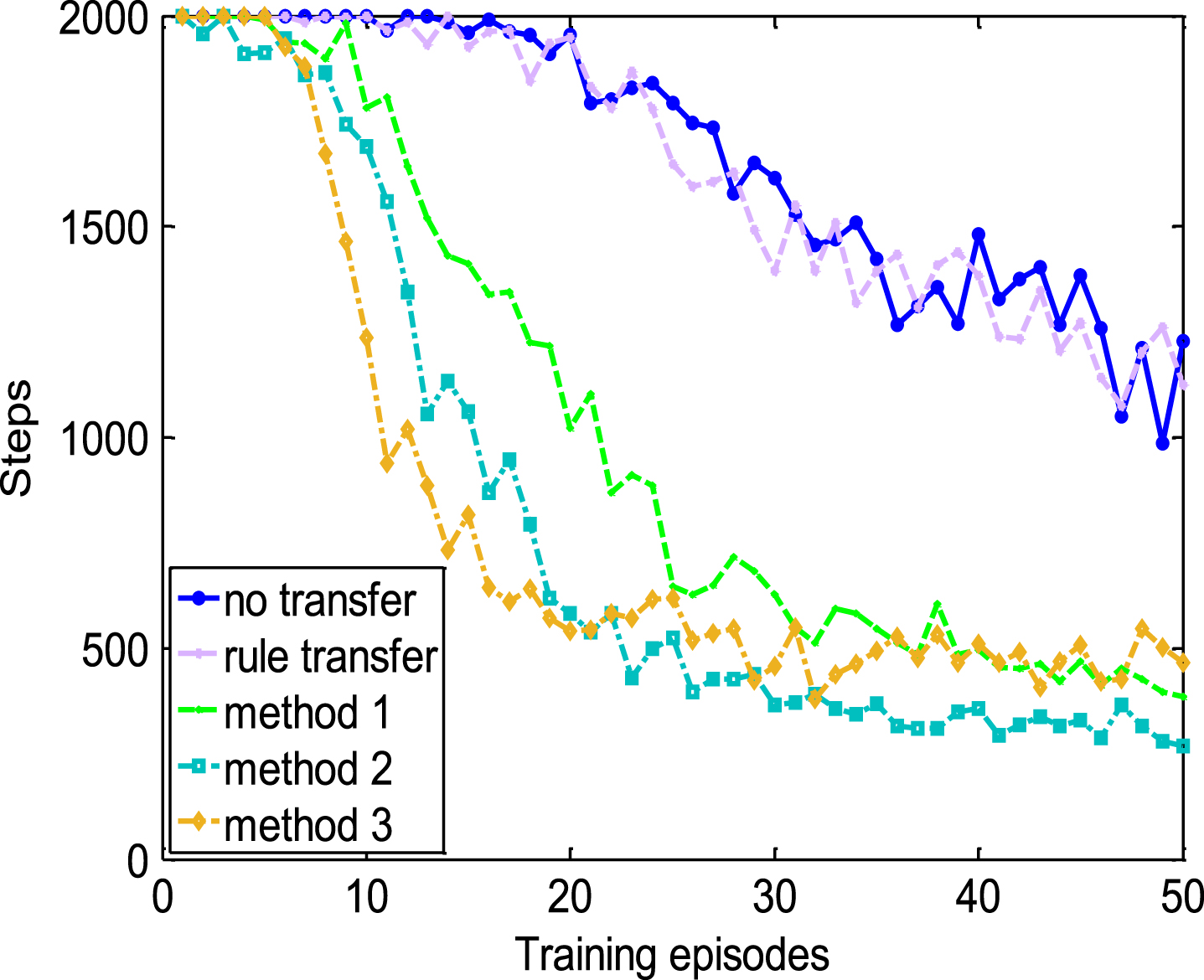
Comparisons in 3D task with demonstration of good quality.
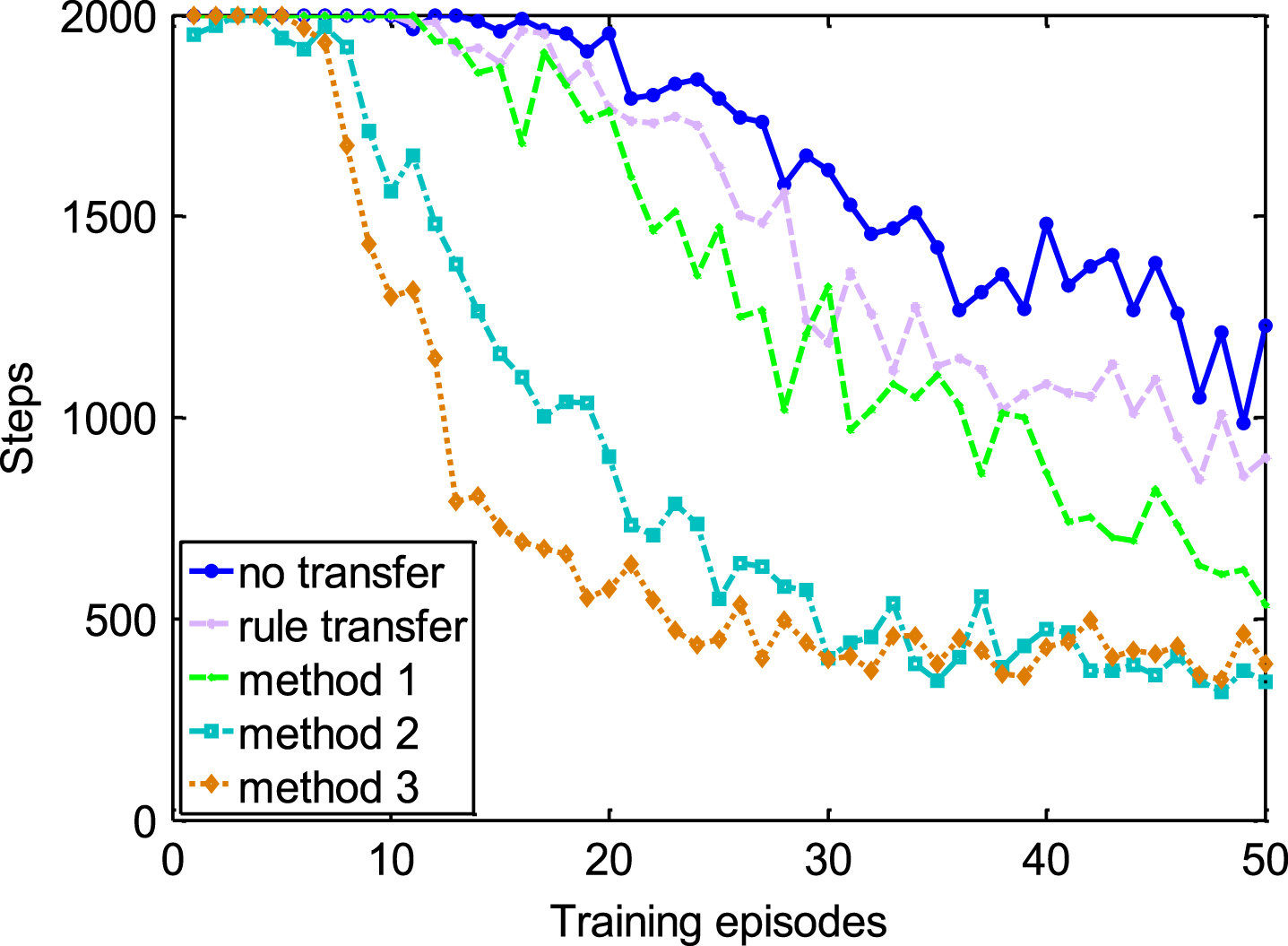
Comparisons in 3D task with demonstration of poor quality Conclusions and future work.
Performance in 3D task
In this target task, with the increasing of dimensions, performances of rule transfer degenerate obviously, especially when the rules are derived from demonstrations of good quality as Fig. 9 shows. It may be caused by over-fitting or the extension to 3D task by inter-task mappings.
There is no obvious difference with tabula rasa learning in view of training episodes though Table 4 shows that the training samples can still be reduced. Nevertheless, the proposed shaping methods still work well with various quality of demonstrations. Among them, mean training steps of method 2 and method 3 with various quality demonstrations are just a little more than 4000 steps while that of RL without transfer is more than 80000. There comes a conclusion that when the dimension of task has changed, method 2 and method 3 can still accelerate the learning speed evidently compared with the other two methods and the performance is more robust to the quality of demonstrations.
In this paper, in order to reuse the knowledge contained in demonstrations of a simple similar task, three specific methods are proposed to shape the initial value of state-action value function. After that, agent can solve a relative more complex target task with fewer training samples and it could improve the applicability of RL. All the three methods, especially shaping by the proportion of different actions among the k-NN of the target state in the source samples and the proportion of different actions under a constant similarity with the target state in the source samples, can make use of the knowledge contained in demonstrations with good or poor quality more effectively and robustly. And simulation results of mountain car problems with different dynamic models and dimensions have illustrated the efficiency of our shaping methods obviously.
However, the shaping approaches are only suitable for RL with Actor-Critic and Critic-Only structures as the effect is realized by initializing the state-action value. How to extend the proposed knowledge reusing methods to Actor-only structure is the future work. What’s more, a more robust and applicable means to reuse expert knowledge contained in demonstrations for RL needs to be explored, for example, new methods to define the relationship between different tasks, new forms of derived knowledge and new ways of reusing knowledge.
Footnotes
Acknowledgments
This work was supported by National Natural Science Foundation of China (61004066) and Zhejiang Provincial Natural Science Foundation (LY15F030005).