
Abstract
The proper expression of the potentially useful but hidden information in large-scale datasets via using proper structure is vital important in both theory and applications of advanced pattern mining. The fundamental challenges are how to alleviate the mining combinatorial explosion problem and ensure the efficiency of mining results. However, most of the existing algorithms have not been entirely capable of solving these issues due to the fact that enormous number of candidate patterns has been generated and the weight constraints of items were only considered in crisp values. In order to generate more practical patterns in the new proposed Fuzzy Supplement Frequent Pattern (FSFP), base-(second-order-effect) pattern structure is proposed and new pruning strategies including pattern-aware dynamic base pattern search strategy and FSFP-array technique are given. Thus, the proposed maximal FSFPs mining algorithm guarantees efficient mining performance by scanning the dataset only once, preventing overheads of pattern extraction based on the pruning strategies, and adopting fuzzy weight conditions to enhance the dependability of mining results. The extensive experimental results obtained from nine benchmark datasets indicate that our algorithm has outstanding performance in comparison to PADS and FPMax* algorithms.
Introduction
Mining potentially useful but hidden information from large-scale databases is one of the main goals of advanced pattern mining. The fundamental pattern mining methods, including Apriori [1] and FP-growth [2], and the properties of these two algorithms have been widely applied in other research works. In order to address the challenges of large data growth, more extensively studied algorithms have been proposed, including, but not limited to, sequential frequent patterns [3], top-k frequent patterns [4], weighted frequent patterns [5], and high-dimensional patterns [6]. The above mentioned frequent pattern mining methods are based on the downward closure property of frequent patterns that all of the sub-patterns are frequent for any frequent pattern. However, in accordance with the practical experience of medical field, the information and knowledge discovery for diverse patients tend to span several departments that generate a large number of relative frequent items and lower frequent items. In order to elaborate the complexity of diseases emergence, the combination of relative frequent items and relative lower frequent items should be analysed to perceive meaningful hidden patterns from large-scale medical datasets. Thus, this study aims to discover the diseases that are closely related with current diseases or those that would most likely be induced or pulled out diseases by common diseases instead of only discovering the association rules among common diseases.
In order to achieve the aim of reducing the collection number of frequent itemsets and meet the requirements of low runtime and low memory usage for large amount of data, research works have been proposed to mine maximal sequential patterns (MSP) [7] and closed sequential patterns(CSP) [8].
Although MSP and CSP can partly alleviate the mining expansion problem, MSP and CSP mining cannot fundamentally resolve the issue of low mining effectiveness [9]. For instance, for the given sample transaction database in Table 1 and the corresponding practical meaning for each item is shown in Table 2. It generated 181 association rules under the constraints of minimum support≥4, minimum confidence≥0.6, and a new added parameter that is used to guarantee positive association: lift⩾1. Based on the analysis of extracted MSP and CSP for Table 1, the longest frequent pattern is: <pgn>, and the association rules are occurred in patterns: <g,n,e>, <g,n,s>, <p,g,n>, <p,g,n,a>, <p,g,e,a>, <p,n,a,e>, <g,n,a,e>, and <p,n,a,e,g>. But according to practical meaning, more meaningful but second frequent patterns should be extracted. For instance, the meaningful pattern <b,c,m,h> (<Fatty Liver Disease,
Sample transaction database
Sample transaction database
The corresponding practical meaning of each item in Table 1
Based on above analysis, in the studied Medical dataset, the patients tend to have several main certain diseases (base items) and several induced diseases (second order effect items) during a defined period, and the changes of the structure of the base-(second-order-effect) patterns depend on the changes of the related fuzzy weight. Thus, in this paper, a novel structure called FSFP-Tree is proposed to extract the relations among different items based on the integrated fuzzy weights gained from different constraints. The new FSFP-tree conducts pattern analysis and pattern extraction more accurately by selecting core patterns due to pattern-aware dynamic base pattern search strategy. In order to reduce the traversing time and searching space, an advanced probing mechanism and FSFP-array technique is adopted to enhance the mining performance and efficiency. The clearly noticeable advantage is that the invalid subpatterns can be pruned sharply to reduce excessive combinations. The proposed algorithm significantly outperforms the efficient algorithms of PADS [10] and FPMax* [11] based on experimental analysis in Section 5.
This remainder of this paper is structured in the following way. In Section 2, the preliminary concepts and the problem statement of mining structure are given. In Section 3, the details of FSFP-Tree including structure, construction, and the corresponding pruning strategies that contain pattern-aware dynamic base pattern search strategy and FSFP-array technique are described. On the basis of Section 3, maximal FSFP mining algorithm is given in Section 4. In Section 5, extensive experimental results in terms of mined base pattern analysis, runtime analysis, and memory usage analysis are presented to demonstrate the performance of the proposed algorithm. The paper is concluded in Section 6.
This paper addresses the problem of mining appropriate and efficient maximal frequent patterns based on the characteristics analysis of medical transaction datasets. In previous works [9, 12], the weights are only defined by comparing with the differences among items, and the weight values are only assigned in crisp values. Being different from these works, the weighted support of each item is composed by four parts: item weight in itemset, itemset weight in database, item weight in transaction, and itemset weight in transaction. In order to resolve the uncertain and inaccurate problems embedded in medical items, we represent the weights by using fuzzy set to handle these uncertainness problems since fuzzy logic is a sophisticated approach to tackle uncertain issues [13, 14].
The transaction database is denoted as T, where T = {T1, T2,…, T
n
}, T
i
is a transaction, and T
i
= {i1,i2, …, i
m
} means one transaction composed by multiple items, where i
j
∈I, I = {i1,i2,…,i
k
} (m ≤ k), I is the set of all items. For each item i
i
in the itemset I, i
i
has a weight based on its hazard level. For a given I = {i1, i2,…, ii,… i
k
}, the fuzzy itemset weight for I is defined as
Based on the characteristics analysis of medical data, the expected mined itemsets are separated into two groups in terms of the items that belong to the base pattern and second order effect items. Given a base pattern, BP, it is the core part of any transaction T and consisted by the core elements in I. Given a pattern SOP, which is the second order effect item in I that pulled by the items in the base pattern.
The severity levels of pattern P are defined with assigning weights lie in [0, 10]. The sets of items are categorized into five levels (
Where, m is the number of items in one transaction.
The frequency of pattern P in transaction T i is calculated based on Equation (2.4), where |T i | means the length of T i . SUP(P) is a triangular fuzzy number that can be equivalently expressed by a triple of real numbers. The defuzzification method in this paper follows the fuzzy set operation shown in research work [15].
The useful pattern discovery in this paper focus on the combination items from the BP and SOP, which is called Fuzzy Supplement Frequent Pattern (FSFP). The FSFP is generated from two cases based on the functionalities of items: 1) All of the specific base items simultaneously appear together with partly second order effect items. The specific base items have very high severity level and ensure these items have the ability to attract the second order effect items with lower support counts. 2) Part of the specific base items simultaneously appear together with partly second order effect items. This means that only a part of the specific base items can be treated as core and able to pull the lower support items into a transaction. The association rules should also consider the influence from not occurred base items on full transaction since these base items may reduce or change the adsorption ability of core items and change the activeness of adsorbed items. The definition of FSFP is given in Definition 4.
Where, SUP(FSFP) is a triangular fuzzy element, SUP
L
(FSFP) is the lower number, SUP
M
(FSFP) is the middle number, SUP
U
(FSFP) is the upper number, and it has: SUP
L
(FSFP)≤SUP
M
(FSFP)≤SUP
U
(FSFP). If SUP
L
(FSFP)= SUP
M
(FSFP) = SUP
U
(FSFP), and then SUP(FSFP) is the traditional crisp number. Symbol ‘¬’ means not occurring together with other items, such as
Pattern-aware dynamic base pattern search strategy
Pattern-aware search conception is firstly proposed by Zeng et al. [10], which has improved the dynamical ordering strategy used in Mafia [16], GenMax [17], and FPMax * [11]. According to the conception of pattern-aware dynamic search, the subtree is firstly constructed with a method of searching the potential max-patterns that are scheduled into some branches, and then the previous found patterns can be pruned as they were the subsets of the max-patterns. However, base patterns mining is different from finding the maximum pattern mining, which requires considering the items’ fuzzy support value based on its severity level. Moreover, the proposed multiple-probing
process in pattern-aware dynamic search cannot ensure the newly obtained longer maximal frequency patterns to have a better pruning capability, meanwhile the expanding of the probing process would significantly increase the time complexity. Therefore, in order to discover the longest and optimal base pattern, a novel advanced probing mechanism is given to reduce traversing time and searching space.
In order to better explain the proposed probing mechanism, we first give some primary notations. Set I be an itemset, P node is the head of current search in the set enumeration tree. ∅ is an empty itemset. Since different ordering of the tail can affect the computation efficiency [10], we focus on utilizing the order of items in Tail to fully utilize the newly obtained base patterns and avoiding the cost of projecting database construction. Thus, we give the definitions of key search elements of Tail, untrimmed Tail, and the new generated tail as follows.
The proposed advanced dynamic base pattern search strategy has the following steps. 1) Searching the subtree rooted in an itemset I, if the I∪Tail(I) is not a subset of any base pattern and Tail(I)≠∅, and then we apply the advanced probing mechanism to find the longest base pattern BP1 in the current focused subtree. 2) Selecting one longer base pattern LBP1 as the key pattern from all of the found longer base patterns. 3) Reordering the items in Tail(I) in defined order, and constructing the I-projected nodes in FP-tree structure. All the children of itemset I in the FP-tree structure can be divided into two categories: a) the potential children, which may contain new base patterns in its descendant nodes; and b) the impossible potential children, which is impossible to contain new base patterns in its descendant nodes. For each item i∈ Tail(I)-LBP1, I∪{i} is a potential children for I. For each item i∈ Tail(I)∩LBP1, I∪{i} is an impossible potential children for I. We only recursively search the potential children to determine the final base pattern. We improved the probing process to reduce the traversing time and searching space by comparing with research work Zeng et al. [10].
The probing processes work as follows: 1) Determine the analyzed items and input into set UnTrim(o). For each item i in UnTrim(o), we need to check whether o∪{i} can satisfy the conditions of base pattern by the following steps. 2) Search the FP-tree structure and determine the paths that contain the current focused item o; 3) Start from the first item in the first path, if o∪{i} can satisfy the conditions of base pattern, and then input item i into set E; 4) If the length of E is greater than or equal to the current minimal length of all paths or the number of common items among paths is greater than or equal to the defined lower limit, we calculate the combination set and determine the basic base pattern, and then update the value of minimal length of all paths, the node link, and set E. 5) We repeat the steps from 2)–4) till all items in set UnTrim(o) have been examined.
We select the first five transactions in Table 1 as an example, and update fuzzy support value and the related count number of each item. Set the minimum support value θ = 0.2 and the minimum base frequency core_count_number=2. Then the potential base pattern is P1= {j,m,h,b,p,i,o}, which is sorted based on the corresponding fuzzy support value. Set the initial P=∅, the initial Tail(P) = P1. Set Q = {m} is the child of itemset P, then the untrimmed tail of item m in the set enumeration tree is UnTrim(Q) = {h,b,p,i,o}. For each item t∈ UnTrim(Q), if Q∪{t} satisfy the base pattern condition in Definition 5, then insert new item t into Tail(Q).
A Fuzzy Supplement Frequent Pattern Tree (FSFP-Tree) with the corresponding transaction database is a compressed tree that is used to mine FSFPs. FSFP-Tree structure is adopted to manage and maintain the information regarding continually added transactions and the related overall weights. All of the base items are not deleted, if the supports of base items are lower than a given minimum support threshold, then this base items with symbol ‘¬’ are inserted into FSFP-Tree. The reason is that the invalid base items still have influence on the current transaction due to the special functionalities of base items. Thus, all of the base items are contained in the head table of FSFP-Tree. The other items are determined based on the count number of appearing times and the corresponding severity level.
The key elements of constructing the structure of FSFP-Tree is given as follows: It has a root node labeled with “Root”; Each node in FSFP-Tree has seven attributes: A

FSFP-array technique for reducing traverse time and memory usage
In order to reduce the tree-traverse time, an array technique is proposed by FPMax * [11] and widely used in several research works [9, 10]. Based on the array technique, FP-tree structure is associated with an array. The array structure stores the frequency of every two pair itemsets for each FP-tree. For every two items i and j in the head table of FP-tree, the array technique is adopted to store the frequency (traditional support) of each pair {i, j} in the item-projected database. For each item i in the header table of the projected FP-tree, the examination of the existed frequent set with new added item i can be generated by reading the row of i in the array structure and collecting the item j such that the frequency of cell {i, j} is larger than the defined threshold, instead of by scanning the header table of the projectedFP-tree.
We focus on improving the version used by Zeng et al. [10] and Yun et al. [9] in order to improve the efficiency in reducing traverse time. Let BP be the base pattern set that is selected based on pattern-aware dynamic search strategy. Since the unique base pattern BP exists in each path of FSFP-Tree, the maximal FSFPs can be obtained by the base pattern and the associated items in each path, thus the array structure is changed into two dimensions that contain base patterns and the other items. Moreover, according to Definition 4, the potential maximal FSFPs are generated by base pattern and second order effect pattern. The items occurred in second order effect patterns have two categories, namely the items already exist in base patterns and the items do not exist in base patterns. Since the items already occurred in base patterns that currently belong to second order effect pattern are impossible to occur in the base pattern of the current focused path, thus, for any item i
j
in base pattern set BP appearing in path j, and the current base pattern bp
j
in path j, must satisfy the followingequation:
Consequently, the cell between i j and bp j in the array structure do not need to be generated. We give Example 1 to demonstrate the working mechanism for the new proposed array structure.

Pruned counting time based on new proposed array structure.
The mining procedure of maximal FSFPs is given in this section to show how the steps of maximal FSFPs mining are conducted and how the proposed pattern-aware dynamic base pattern search strategy and FSFP-array technique are applied in the mining procedure. The maximal FSFP mining algorithm is represented in Algorithm 2.

In Algorithm 2, The mining operations should firstly provide the values of fuzzy support value, base patterns, FSFP-tree, and FSFP-array. Thus, the fuzzy support value for each item is calculated by Definition 3, base pattern set BP is obtained based on pattern-aware dynamic base pattern search strategy, FSFP-tree is constructed based on Algorithm 1, and FSFP-array is built according to new proposed array structure. Note that in base pattern and FSFP-tree construction, the fuzzy severity level and frequency of items should be regarded as the pruning conditions. If the path is a single-path, a new pattern np i is generated by combining the current base pattern with checking of all of the items in the single path and calculating the new support value. If the new support value is greater than or equal to the minimum threshold and also has no superset for this pattern, then the pattern MFSFP should be regarded as valid maximal FSFPs and inserted into the set of maximal FSFPs. Otherwise, if the new MFSFP generated by the base pattern and the new itemset cannot satisfy the above maximal conditions, we only consider the base pattern with strong absorption abilities for the other items as the maximal FSFP in the current path. For the multiple paths, we generate the corresponding conditional database based on FSFP-array structure and sort the new set by using support value in descending order, and then recursively calls itself after assigning the new set of count number of the corresponding base pattern with each item in the header table until a single-path occurs.
Experiments and discussion
Experimental environment
Performances study including runtime and memory usage analysis is conducted to evaluate the effectiveness of proposed FSFP-tree mining algorithm, pattern-aware dynamic base pattern search strategy, FSFP-array structure, and MFSFP mining algorithm. The experimental results are represented on seven real datasets and two synthetic datasets. The real datasets including Chess, Mushroom, Pumsb, Connect, Accidents, Pumsb_star and two synthetic datasets including T10I4D100K and T40I10D100K have been extensively used in the previous studies as the benchmark datasets, where they can be gained at http://fimi.ua.ac.be/data/. We provide a new dataset called Medical that has a sparse feature and contains real patients suffering from different type diseases. This dataset can be downloaded at http://medical.witaction.com:808/medical/. Table 3 shows the features of the analyzed datasets.
The features of benchmark datasets
The features of benchmark datasets
All the experiments were evaluated in a PC computer by running in win7 system, with a 2.20 GHz Pentium i7-3632QM CPU, 8 GB RAM, and a 700 GB hard disk. The programs were written in C++ by using Microsoft Visual Studio 2010. Based on the above analysis, the existing algorithms still cannot efficiently obtain effective maximal frequent patterns, and runtime, memory usage, and combinatorial growth are still the bottleneck of frequent pattern mining. Therefore, these parameters will be the key monitoring objects.
The proposed dynamic base pattern search strategy is applied to extract the base patterns for eight datasets under the parameters of core_count_number, connect_count_number, θ , and σ . The initial fuzzy global and local weights are assigned with (1,1,1) for the other eight datasets except for Medical dataset. In this paper, we mainly study the sparse datasets and the mined base patterns are shown in Fig. 2.

Base patterns analysis for sparse dataset based on the proposed dynamic base pattern search strategy.
In Fig. 2, the lines with the same type marker are conducted under the same parameters and the dotted lines are the obtained base patterns. For Medical dataset, the larger the space between parameters of θ and σ is, the more significantly the obtained number of base patterns will be increased. Meanwhile, the number of the generated initial candidate base pattern peaked when θ = 0.6 and σ = 0.15, meaning that dynamic base pattern search strategy should avoid searching candidate base patterns to reduce running time and memory consumption since more “false” base patterns occurred when the value of θ is larger. What’s more, the number of the generated base pattern reached to the highest point when θ = 0.348 and σ = 0.05, indicating that this value is the optimum suitable point that can be selected to mine MSFPs. Similarly, we can get the boundary line of optimum candidate base patterns extraction and optimum suitable mining point for the other datasets.The distribution of sparse datasets is relatively discrete which caused the fact that multiple probes have to be conducted to determine the base pattern. Moreover, the mining of frequent items, MFP, and CSP for sparse datasets is facing more competitions because of the uncertain regularity and the discrete distribution. The dynamic base pattern search strategy can effectively determine the regular characteristics and be capable to efficiently locate the optimum point of generating candidate base patterns.
In these runtime experiments, the threshold of setting the minimum support of base items (
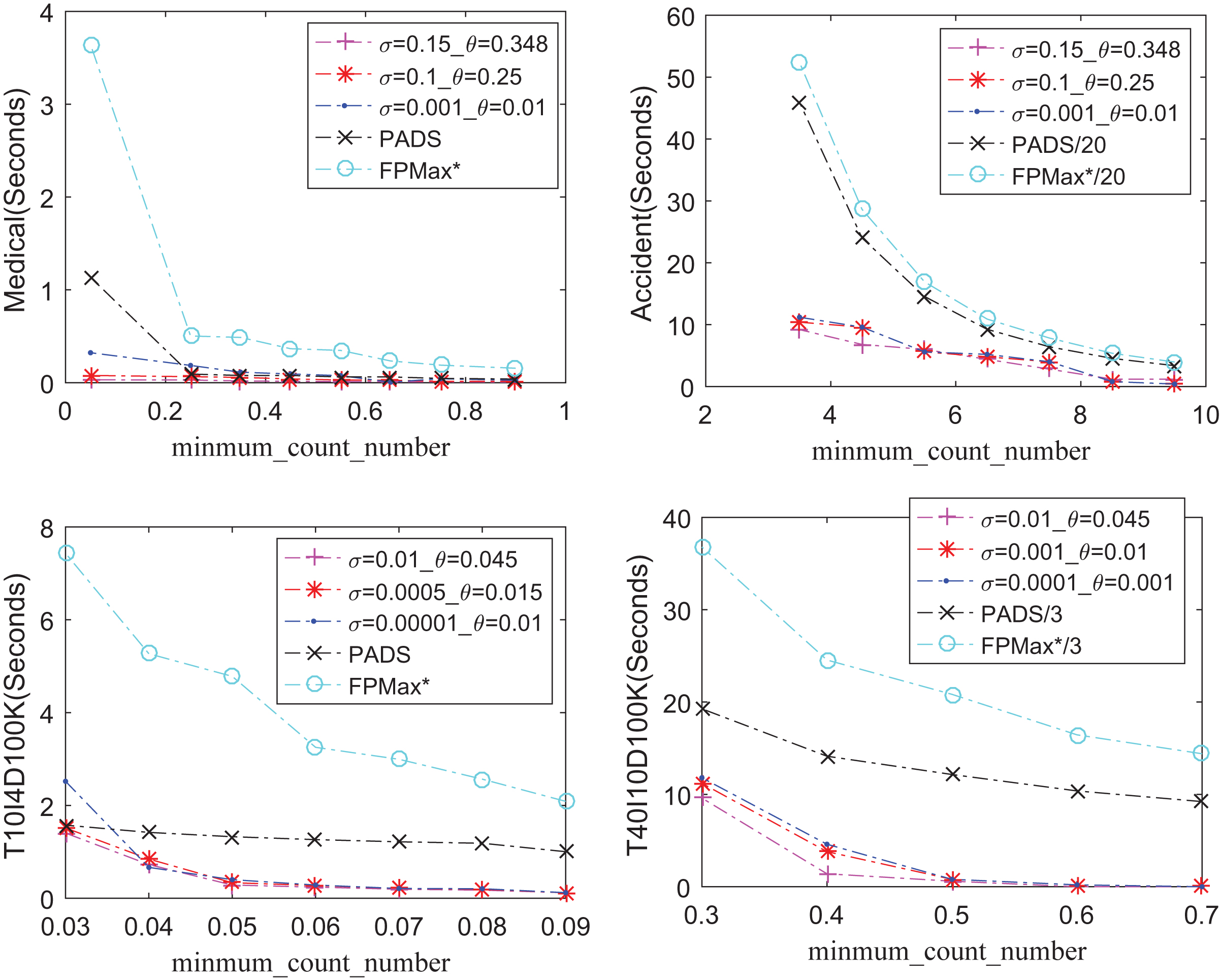
Runtime results (Sparse Datasets).
Generally, based on the experimental performance in Fig. 3, the MFSFP-Tree algorithm presents the fastest runtime performance under all parameters in all cases. Moreover, the proposed algorithm has the lowest runtime increments as the
We have selected four representative datasets to conduct the memory usage experiments, which is shown in Fig. 4. The proposed dynamic base pattern search strategy and array technique have made a great contribution to reduce memory usage. The proposed algorithm is the most outstanding in memory efficiency based on all of the datasets analysis. The memory usage of PADS and FPMax* are very similar since these two algorithms adopt FP-tree as the major structure. However, the memory usage has an enormous gap among the proposed algorithm, PADS, and FPMAX*, thus, we changed the scale by shrinking the results of PADS and FPMAX* in varying degree to allow the memory usage results emerge together and better represent the comparison results among all algorithms.
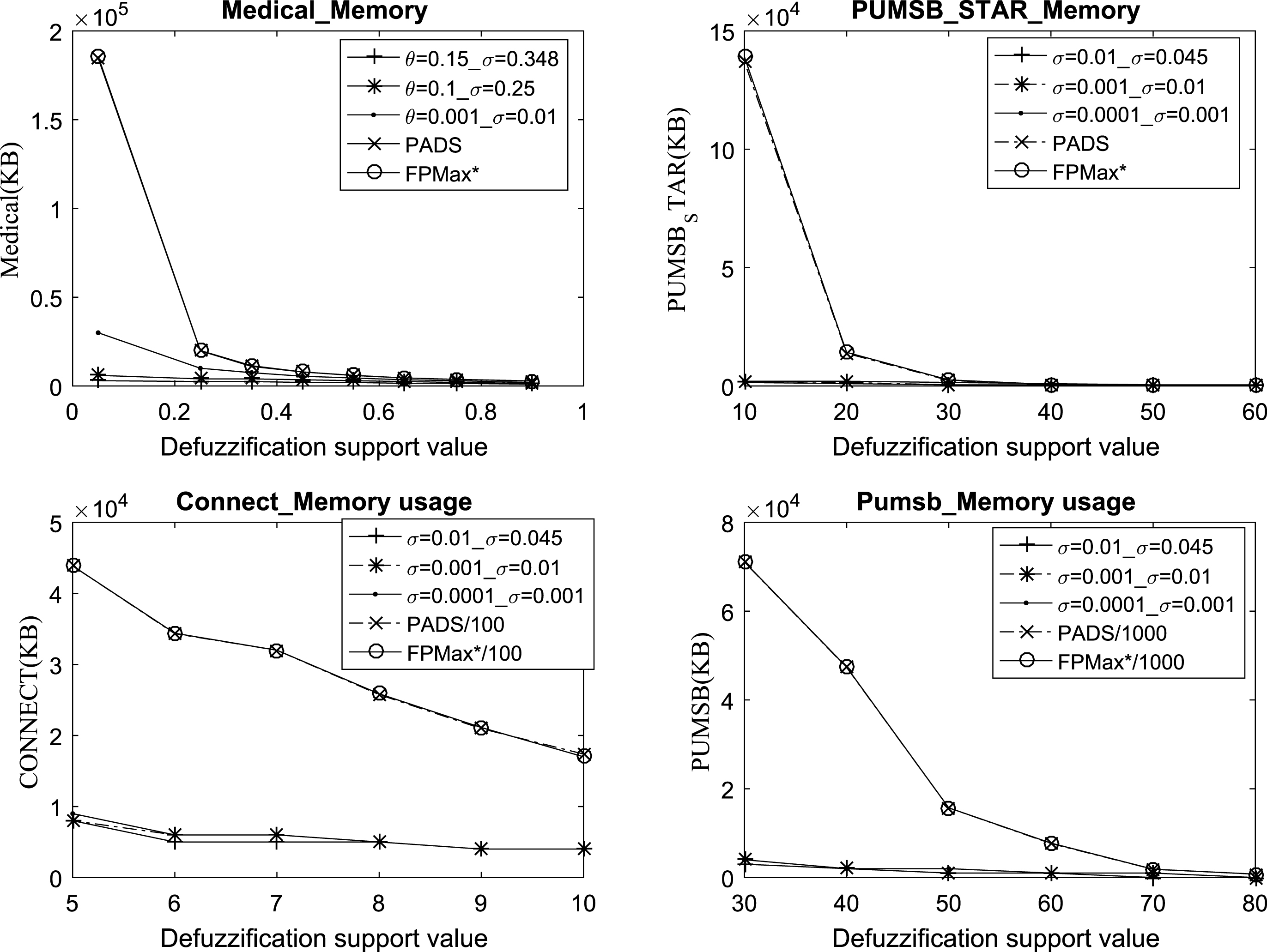
Memory usage results.
Similarly with runtime consumption, the proposed algorithm has the lowest memory usage increments as
Overall, the experimental results clearly show the power of dynamic base pattern search strategy and array technique pruning strategy in the proposed algorithm. The proposed algorithm conducts less subpattern checking by using the proposed pruning strategies in pruning subtrees to ensure better scheduling the candidate patterns.
Advanced pattern mining is vitally important in hidden information discovery and information proper representation from datasets. In this paper, we developed a new base-(second-order-effect) pattern structure, conducted FSFP-Tree, and proposed pruning strategies including pattern-aware dynamic base pattern search strategy and FSFP-array technique. The proposed pruning strategies and the new adopted fuzzy weight constraints and properties guarantee that the proposed maximal FSFPs mining algorithm mining is more efficient, which leads to conduct mining operations more quickly and effectively. In order to analyze the environmental performance of MFSFPs mining, we conduct extensive experiments in terms of obtained base patterns analysis, runtime analysis, and memory usage analysis, which clearly show that the proposed algorithm outperforms PADS and FPMax* algorithms. The obtained number and quality of MFSPs has shown that the proposed algorithm is more suitable to handle the combination of relative frequent items and relative lower frequent items.
In the future work, we will compare the discovered diseases extracted by MFSPs that have represented the relations of relative frequent diseases and relative lower frequent diseases with the clinical data to evaluate the effectiveness of the new proposed MFSFP pattern in medical perspective. In knowledge discovery perspective, it is very useful to explore how the proposed base-(second-order-effect) pattern structure and MFSFP mining can be extended to other advanced pattern mining tasks, and it is also interesting to study the inherent properties of the new structure.
Footnotes
Acknowledgments
This research is supported by the National Natural Science Foundation of China (NSFC) (No. 61602064, No. 61772091), Science and Technology Agency Project of Sichuan Province (No. 2017HH0088), and Scientific Research Foundation of CUIT (No. KYTZ201615). We would like to thank the editor and reviewers for their helpful remarks.