
Abstract
This paper presents a causation analysis model for traffic accident. Traffic accident is a result influenced by the interaction of various factors. Considering the characteristic of multi-dimensional and multi-layer in traffic accident data, a model which based on traffic accident historical data on the city of Guiyang in 2015 was built to find the main reasons and potential rules of traffic accidents. The model starts from the four main dimensions such as the drivers, the vehicles, the time-address and the environment, and uses a way which based on AHP and hybrid Apriori-Gentic algorithm to mine causes of accident. First of all, the analytic hierarchy process (AHP) is used to sort the importance of the influencing factors about accident. On the basis of objective analysis, the influencing factors are quantified and the main influencing factors are selected. Then the genetic algorithm combined with Apriori is used to analyze the main influencing factors and find the expected association rules out. The experimental result shows that the model can improve the accuracy of mining and find more expected association rules. Finally the hybrid algorithm is parallelized to reduce time complexity, which makes the model has a good application potential.
Introduction
In recent years, with the rapid growth on the number of automobile and driver in China, pressure on road traffic growths greatly and the trend of traffic accidents becomes more and more intensified [1]. At the same time, China is one of the largest countries in the world on the number of death caused by traffic accident. The latest official figures published by China’s ministry of public security shows that there were 187781 traffic accidents happened in 2015 on China [2, 3]. With the occurrence of traffic accident, the history data of accident is gradually accumulated. These data can be used for targeted statistical analysis and further research of mining. In order to explore the causes of traffic accidents, Data Mining is used to excavate the historical accident data hoping to find the potential and deep rules and data patterns in the traffic accident data so as to provide decision support for the prevention of traffic accidents. Due to many factors have influence on the occurrence of traffic accidents and there are many complicated fields and redundant information in the accident historical data, it is difficult to carry out the causation analysis. For this reason, the analytic hierarchy process (AHP) is introduced into the data preprocessing.
The main influencing factors about accident can be selected by the AHP. AHP [8, 9, 23, 24] is proposed by Saty, which is applicated to network system theory and multi-objective comprehensive evaluation. It is a systematic analysis method combining qualitative analysis and quantitative analysis. The method divides a complex problem into several layers. Each layer contains several factors. After through a depth analysis of the complex nature of things and the related influencing factors, a clear hierarchical structure chart can be drawn. And then the judgment matrix is established one by one between different factors. The weight of different factors is obtained by calculating the eigenvalues and eigenvectors of the judgment matrix. And the optimal scheme is selected according to the value of weight.
To improve the accuracy of mining, the Apriori algorithm and genetic algorithm are used together in association analysis. The Apriori algorithm is an original algorithm in mining frequent sets for the boolean association rules [10, 26]. Apriori uses an iterative method called layer-by-layer search, where the k itemsets are used to explore k+1 itemsets until it is impossible to find larger frequent sets. Through the frequent sets, the association rules in the form of A = >B can be got. And each rule is measured by two parameters which are called support and confidence.
The genetic algorithm searches the global optimal solution by simulating the idea of Darwin’s natural evolution. It’s initial population are composed of rules generated randomly [11, 12, 27, 28]. After each chromosome (rule) was encoded and the user gave the fitness function in the evolutionary process, rules are optimized by the generations according to the principle of survival of the fittest. Final group are composed of the most suitable rules in the current group and the descendants of these rules. Descendant is created by using genetic operations such as crossover and mutation.
This paper focus on the causes of urban traffic accidents. The historical data of traffic accident on city of Guiyang in 2015 is selected as the basis of analysis. The model combines AHP and hybrid Apriori-Genetic algorithm to analyze the data. Firstly, the weight of influencing factors are determined by AHP algorithm which can select the main influencing factor and remove the secondary influencing factors and simplify the operation. Then, the Apriori are used to associate the main influencing factor fields. Finally, the search results are optimized by genetic algorithm. The model can explore the comprehensive action rules and the details of traffic safety behind the main influencing factors. Such as the influences about the road conditions and other traffic environment on the accident. It also can improve the use value of data.
Related work
With the accumulation of traffic accident data, how to model the data and extract the useful information quickly from it has become the focus of the research. The Apriori algorithm can produce a large number of association rules, and has a good adaptability to explore the causes of traffic accidents [5–7]. The Apriori algorithm uses support to find frequent sets and discovers association rules based on confidence. However, if the Apriori algorithm is used directly, a lot of useless and repeated frequent items and association rules will be generated.
In order to find out the cause of the traffic accident accurately, it is necessary to improve and optimize the Apriori algorithm so that the algorithm can be applied to the research of traffic accident better. Many scholars have done research work in this respect. Jianfeng Xi, Zhonghao Zhao et al. Proposed a method of research on accident causes [13], which based on ahp-apriori algorithm. For the numerous and complex fields in the data of traffic accident, it is determined by the method of analytic hierarchy process which factors or attributes in accidents has a greater weight. Through the association analysis about the main influencing attributes in the data, the association rules are obtained. Then the driver’s psychological and behavior factors are introduced to analyze the association rules and verify the credibility of the rules. Although the use of analytic hierarchy process can screen out the main influencing factor fields of traffic accident, but the Apriori algorithm used directly still produce a lot of frequent sets and useless association rules. Moreover, only the support and the confidence as the measure will be biased in the algorithm.
S. Ghosh, S. Biswas et al. Proposed frequent pattern mining based on the genetic algorithm [14]. They introduced the genetic algorithm into association analysis to improve the mining process and reduce the time complexity in the global search. The method is simple and efficient, and has better performance in larger data set. Surendra Kumar Chadokar proposed a hybrid association rule and genetic algorithm for network communication [15]. He used the Apriori algorithm to process the network communication data and obtained the frequent sets. And then the frequent sets were through the genetic algorithm to get the lesser and better rules. By comparing the time complexity and the number of the frequent items and rules between the apriori algorithm and the hybrid algorithm, the result indicated that the hybrid algorithm can reduce the execution time in the calculation and is smaller in the number of frequent items and useful rules relative to the apriori algorithm.
With a simple genetic algorithm is difficult to meet the needs of data mining and it’s feature of randomness and error-prone, Haiyan Ren and Ke Luo [17] combined the genetic algorithm with theApriori algorithm and proposed a hybrid association rule mining algorithm which improves the accuracy of genetic algorithm in classification mining.
Sanat Jain and Swati Kabra [16] proposed an optimized association rule mining algorithm and introduced the mining of positive association rules [19, 20] and negative association rules [21, 22] in their paper. The Apriori algorithm which based on support and confidence is used to mine the valid positive association rules and the negative association rules, and the positive and negative rules are optimized by genetic algorithm. This method can reduce the search space and judge whether the association rule is appropriated for further mining by the correlation coefficient of each association rule.
Pankaj sharma and Sandeep Tiwari proposed an algorithm which used the mutated artificial bee populations algorithm to optimize association analysis [18]. This method is based on the foraging behavior of bees, which can produce high quality frequent sets in a large number of data set; At the same time, with the traditional association rule algorithm doesn’t consider the negative correlation attributes in a rule, it can be learned from the artificial bee colony algorithm which rules contain negative correlation attributes. The proposed algorithm is compared with the KNN algorithm and the standard artificial bee colony algorithm. It is concluded that the algorithm proposed by the authors has improved the accuracy of the classification, but the lifting effect is not ideal. There are also other research methods in the traffic accident analysis [29, 30] provide different solution mechanism.
Proposed methodology
Data presentation
There are accidenttime, accidentaddr, driver1fault, driver2fault, sex1, sex2, carcolor1, carcolor2, brith1, brith2, Driving experience and other a total of 21 fields and 11 fields about weather associated fields and traffic deduction for illegal activities in the original historical data (a total of 56651 accidents) of traffic accident on city of Guiyang in 2015 [4]. The data recorded the information about two sides of the driver. The field driver1fault and driver2fault recorded which driver as the main person in charge of the accident. The data of “driver 1 full responsible” accounted for 94.94% and the data of “driver 1 and driver 2 are equally responsible” accounted for 5.06%. The statistical analysis is shown in Fig. 1.
Therefore, the focus of the research is on the case of “driver 1 full responsibility” and the related data fields. The data of the latter case about “driver 1 and driver 2 are equally responsible” is less and involved more fields. What’s more, the relationship is more complex. So the latter case is not in the scope of the study currently, we will continue to research the latter case. In the accident data, not all attribute fields may be associated with the cause of the accident, such as license plate number, driver’s license number, accident number and so on. There is no doubt that the remaining attribute fields may be related to the accident influencing factor if the unrelated number fields are removed.
The proportion of accident type.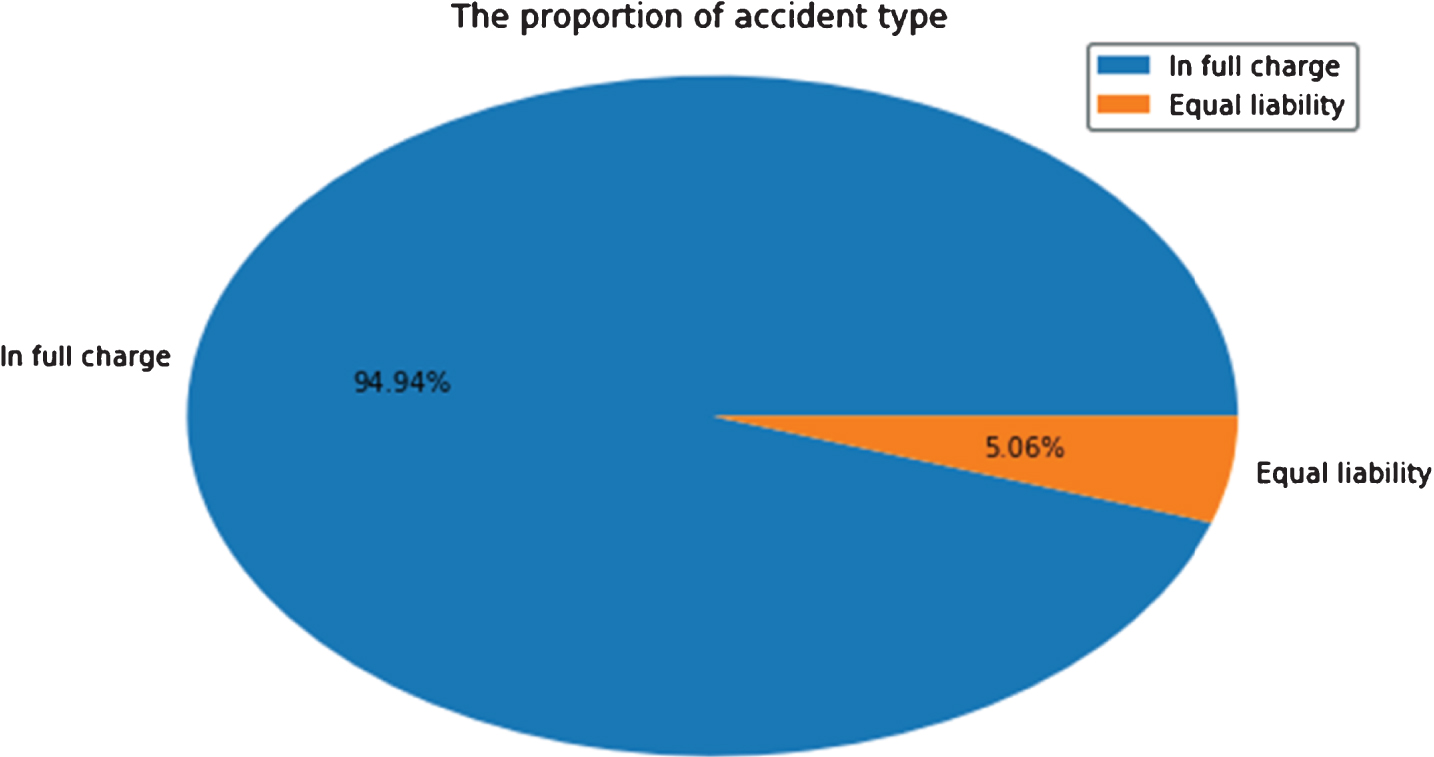
Because there are too many factors in the traffic accident data, if the association rules algorithm is used directly, a lot of useless and repeated frequent items and association rules will be generated. Therefore, the analytic hierarchy process is applied to select attributes.
AHP is clear. Not only can it make the mind become logic, mathematical and model, combine the qualitative analysis and the quantitative analysis while quickly and accurately find the key to the problem, but also it can sort the weight of the factors at all levels. AHP is suitable for decision analysis for complex problems with multi-criteria and multi-objective, especially for scheme evaluation and decision. In the traffic accident data, all the fields can be divided into four different dimensions: the driver class, the vehicle class, the time-place class and the environment class. The system hierarchy is shown in Fig. 2.
The system hierarchy.
With the analytic hierarchy process (AHP) combines with the expert knowledge, the judgment matrix of the upper and lower levels is constructed by referring to the nine factor ratio of AHP. Table 6 shows the nine factor ratio of AHP [23]. Then the matrix consistency test is carried out.
The judgment matrix of target layer and middle layer G-C
The judgment matrix of middle layer and scheme layer C1-S
The judgment matrix of middle layer and scheme layer C2-S
The judgment matrix of middle layer and scheme layer C3-S
The judgment matrix of middle layer and scheme layer C4-S
The nine factor ratio of AHP
Tables 1–5 show the judgment matrix of the upper level and lower level.
Then whether the above matrix can passed the consistency test is judged. The maximum eigenvalue of the matrix and its corresponding eigenvector(λ), and the corresponding CI and CR values are also calculated.
λmax1 = 4. 0211 λmax2 = 4. 1074
λmax3 = 4. 0458 λmax4 = 4. 0310
λmax5 = 3. 0385
The CI and CR are calculated as follows [8]:
The value of RI can be obtained by searching the mean randomness consistency index reference table. When the order of the matrix n is 3, RI takes 0.58. When the order of the matrix n is 4, RI takes 0.90 [23]. For each matrix, if the final calculated CR value is much less than 0.1, then the matrix passed the consistency test. The next step can be carried out.
For G-C matrix, CI = (4.0211-4) / (4-1) = 0.007 and CR = CI/0.9 = 0.0078< <0.1, so the consistency check for G-C matrix is passed. Table 7 lists the results and intermediate values which are calculated in our model. ω k represents the eigenvector corresponding to the maximum eigenvalue of the matrix. The weights of (C1, C2, C3, C4) in the G-C judgement matrix are (0.4773, 0.0809, 0.1539, 0.2880).
The result and intermediate values in calculation
Finally, the weight value of each attribute in the scheme layer relative to the goal layer will be got. By selecting the field which weight value is greater than a certain threshold as the main factor that affects the traffic accident (From Table 8, we can see that when the threshold is between 0.0376(0.1539*0.2772) and 0.04(0.4773*0.2483), we can make an appropriate partition. Some main factor fields can be selected easily in the condition. If the threshold is too large, the selected fields will be less, resulting in less association rules. On the contrary, if the threshold is little, the selected fields are too much. It is not good for the filtration of main factor fields).
The arrangement of the weight value about each field attribute related to the goal layer
Combining the advantages of genetic algorithm, this paper designed a hybrid genetic association rule mining algorithm. Apriori which is the classic algorithm in association rule mining was used to find the frequent itemsets in the traffic accident data. The frequent itemsets are translated into chromosomes in some form as the initial population of the genetic algorithm and then the fitness value for each chromosome was calculated according to the predefined fitness function (or evaluation function). A number of chromosomes with high fitness values are chose to replicate and a new generation of group is generated by genetic manipulations (selection, crossover, mutation). Through generations of continuous breeding evolution, finally the population converged to a group of individuals with the highest fitness or the number of iteration reached a preset threshold. The result which is the optimal classification rule set could be output.
The flow chart of the hybrid algorithm is shown in Fig. 3:
The flow chart of the hybrid algorithm.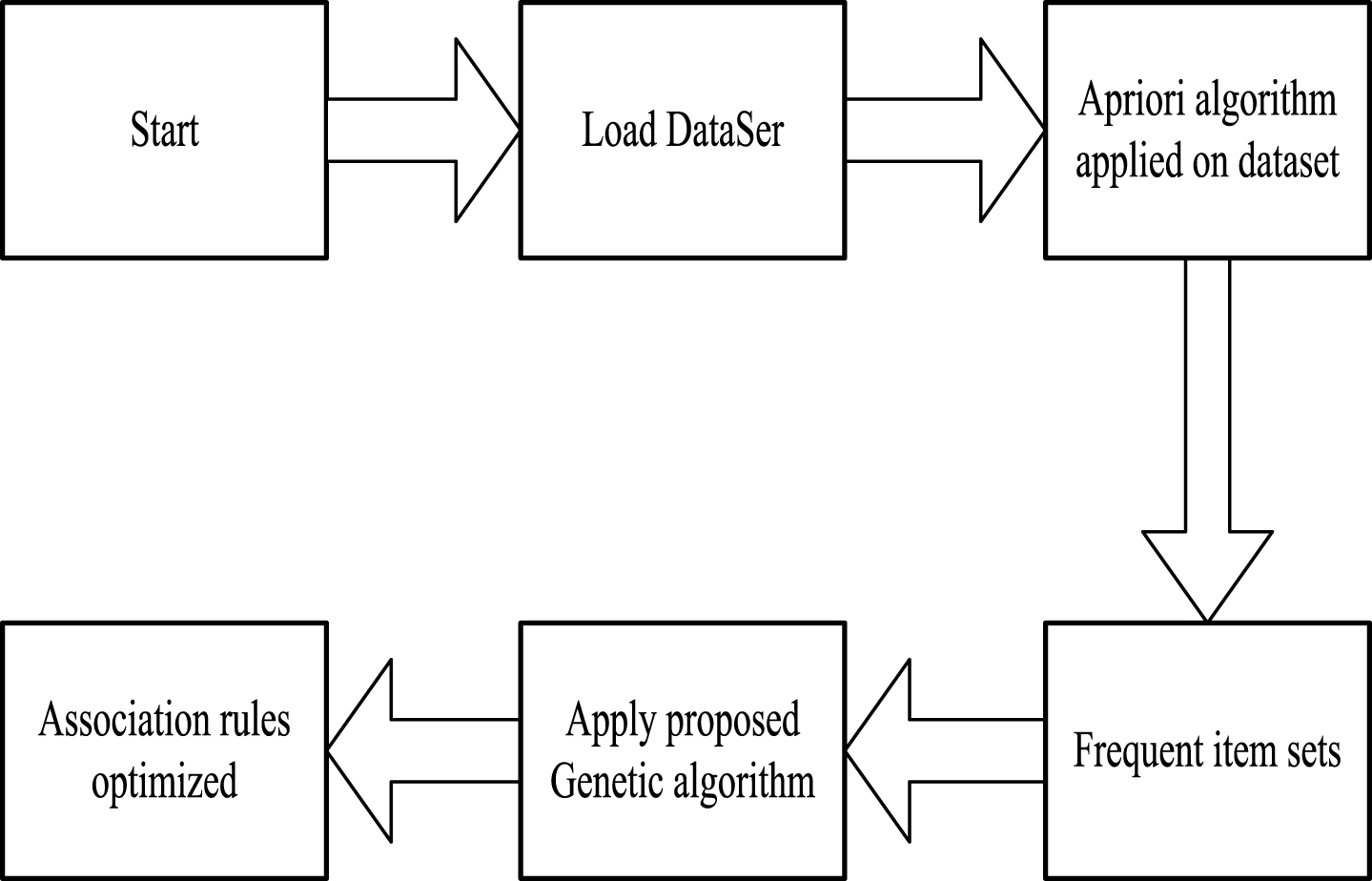
For the traffic accident data set, the factors that affect the traffic accident are taken as the rule antecedent and the type of cause about traffic accident as consequent. The rules of form about “driving age, age, training school, time and other fields => driver1fault” are expected to be found. Each attribute (such as driving age) in the rule has n categories, then the corresponding×bit binary is used to represent the attribute. The×and n satisfy the relationship:
The consequent of rule (driver1fault) is taken as a classification attribute. It represents the type of cause about the accident. They are 9 kinds of the cause. The method to represent driver1fault in binary is same as the attribute in the rule antecedent. In order to facilitate the subsequent calculation, we preprocess fields in the raw data. The following table describes the classification and the label of the type of cause about the accident (see Table 10) and driving age (seeTable 9).
The classification and comparison of accident type
The classification and comparison of driving age
The classification and comparison of other fields are seen in Table 11. For the frequent itemsets obtained by the Apriori algorithm, item which contains both the feature attribute and the classification attribute is selected. Then the chosen itemsets are encoded as the initial group. For example, if a frequent item - [Driver age = ‘Driving experience 1’, Driver training = ‘school training’, driver1fault = ‘1’] is got, the classification of Driver training has two categories which are ‘school training’ and ‘self training’. So in formula (3),×should be 2. ‘School training’ corresponds to ‘01’, ‘self training’ corresponds to ‘10’. ‘Driving experience 1’ is encoded as ‘001’, ‘Driving experience 2’ is encoded as ‘010’, ‘Driving experience 3’ is encoded as ‘011’, ‘Driving experience 4’ is encoded as ‘100’; driver1fault = ‘1’ is encoded as ‘0001’. Other attributes which not appear in this frequent item correspond to a binary string of 0. The corresponding number of bits is x and the value of×depends on the number of classification of the characteristic attribute. In the programming, a list is constructed for storing the binary chromosome which corresponding to frequent item. The length of the list is 23, corresponding to seven feature attributes and one classification attribute. The code corresponding to each attribute field is stored in fixed order in the list.
The classification and comparison of part field
The fitness function is used to evaluate the ability of individual to adapt the environment and is the basis for natural selection. Because each chromosome can be seen as the rule with the form of “driving age, age, the way of training, time, weather and other fields => driver1fault", so the chromosome can be evaluated by support, confidence, coverage and other metrics. The support and confidence of the rules reflect the usefulness and certainty of the found rules, and the coverage expresses the coverage of the rules. In the design of fitness function, based on the comprehensive consideration, the fitness function F(r) is calculated by Equation (4).
The variable r represents the rule, a, b, c are constant coefficients and the range of a, b, c all is [0, 1]. S(r) is the support of the rule, C(r) is the confidence of the rule and R(r) is the coverage of the rule.
Let N be the number of record for the entire data set. C is the rest attributes of rule, after the driver1fault attribute is removed. The number of occurrences of C in the data set is represented as R
C
; the attribute of driver1fault denoted as D in the rule, the number of occurrences of D in the dataset is represented by R
D
. The number of occurrences of C and D together in the data set is represented by R
C
∪ R
D
. So S(r) is defined as [10]:
C(r) is defined as [10]:
R(r) is defined as [25]:
The values of the constant coefficients a, b, and c are adjusted by the user as required, which can make the emphasis on the rule evaluation changed and make evolution takes place in the desired direction.
The operator of Select
The operation of select uses the roulette algorithm. The specific process is described below:
For each chromosome in the population, after its corresponding fitness value is calculated, all of the fitness values are plotted on a disc. The magnitude of the fitness value represents the area on the disc. The larger the area of a single module (the fitness of individual), the greater the probability of being selected in the process that the wheel rotated. Assuming that the number of initial populations is p, a total of p random numbers between 0 and 1 are continuously generated. The corresponding chromosome is selected according to the module where the random number located.
The operator of Crossover:
The probability of the crossover is set to 0.6. In order to speed up the evolution of the population without destroying the genetic diversity of the population, after the male and female parent are selected by using the select operator, k times crossed by single point crossover will be done and the cross-bit is randomly generated. String which before and after the cross-bit about two parents are exchanged to form two new individuals. A total of 2k individuals will be produced. Taking into account to find a better rule set in the mining of traffic accident data, the newly generated individuals are sorted by fitness and then the individual which fitness is more than the fitness threshold is selected from the 2K individuals to be added to the result. At the same time, these selected individuals are also added to the original population to form a new population. In this way, the genes of male parent and female parent are preserved and the performance of individuals in the population is also greatly improved in the process of evolution.
For each generated rule, if the sum of support, confidence and coverage is greater than a certain threshold, it is suitable for the next genetic evolution. For the rules of the final result, the validity of each rule can be judged by it’s incidental support, confidence and coverage.
The operator of Mutation
The method of using the variability probability is described as follows (P m means the probability of mutation):
If (the fitness value of individual > the average fitness of the population)
Then {P m is small or close to zero;}
Else {P m is relatively large;}
Parallelization of hybrid algorithm
In order to improve the running speed of the hybrid algorithm, the hybrid algorithm is parallelized. The idea of Apriori algorithm is that the frequent k-itemsets L_k with length of k is generated by multiple scanning the database, and the candidate set C_(k+1) is generated by serial self connection. The number of occurrences about all the candidate set C_(k+1) of length k+1 in the transaction set DB is counted, until no frequent itemsets can be found. It is clear that to scan the database once is needed when a L_k is found and the candidate sets are huge. Similarly, each new rule produced in iteration needs to scan the database once to calculate its fitness in the genetic algorithm. Therefore, when the candidate itemsets are large, the hybrid algorithm has a large time consumption on the system I/O. In the implementation of the program, by opening the multi process (multi-threaded mechanism in Python is not perfect, so Python provides multi process to parallel processing, which is called multiprocessing module) to read the transaction set DB. The implementation of the algorithms is described below:
Input: The preprocessed traffic accident data set DB, a frequent item or rule r
Output: Frequency of r in DB
Begin
Initialize parameters. BlockSize = fixed value, num = fixed value, shared list-array = [0, ·,0], the length of array is num; Initialize synchronization lock-lock; For i in num: Open the process i, and then the process i executes the function found(i, array, lock, DB, r); Wait for each process to be completed and returns to the main process, merging the return value.
End
The results of association rules found by the hybrid algorithm
The results of association rules found by the hybrid algorithm
The function found(i, array, lock, DB, r) is described below:
The process i adds the lock to array, so other processes cannot read the value of array due to congestion; Take the maximum value-max in array, update the array[i] = max + BlockSize, and then release the lock; If (max+BlockSize) <size of DB: Read the data from max to max+BlockSize in DB, and count the frequency of r-count in this region; Else: Read the data from max to end of DB in DB, and count the frequency of r-count in this region; Return count;
Similarly, the fitness value of the rule can be derived from the Equations (6–9) after the corresponding frequency are calculated.
Experimental design
Comparing with the data in Table 8, it can be found that the weight of Driver in the criterion layer relative to Accident in the goal layer is 0.4773. While the weight of the Driving years in the scheme layer relative to Driver in the criterion layer is 0.4909, So the weight of Driving years relative to Traffic Accident is 0.4773*0.4909 = 0.2343. After the weight of each field in the scheme layer relative to Traffic Accident is calculated, the field which weight is greater than the threshold is selected as the main factor of the accident.
Finally, the experiment selected driving age, sex, age, way of training, time, weather condition and wind direction as the main factors about the cause of traffic accident. The data of these fields and the driver1fault as input for the hybrid Apriori and genetic algorithm. Then the data is processed by data denoising, discretization, concept stratification and other data preprocessing work. A part of the processing results are shown in Table 11. The traditional Apriori algorithm, simple genetic algorithm and hybrid Apriori-Genetic algorithm are used to deal with the historical data of traffic accidents on Guiyang in 2015 respectively, and the data mining results are compared to see which has a better performance.
After data preprocessing, the range of the ‘Age’ field is {0–24, 25–35, 36–47, 48–53, 54-the above} in the data set, and there are marked with {age1, age2, age3, age4, age5} respectively; The value of the ‘way of training’ is {self training, school training} The value of the ‘sex’ is {male, female} The field of ‘time’ is marked with {time1, time2, time3, time4} after discretization and hierarchical process; The range of the ‘weather’ field after hierarchical process is {Weather1, Weather2, Weather3, Weather4, Weather5, Weather6} The range of the wind direction is {Wind1, Wind2, Wind3, Wind4, Wind5, Wind6} after hierarchical process. The handling of the driving age is seen in Table 9 and the handling of the type of the accident is seen in Table 10.
Mining results about classification rule
The constant coefficient a, b, c in the fitness function F(r) (see equation 4) all is 1. After the vacancies in original data is deleted, data preprocessing and other operations have done, there is remaining 42389 data in the set. The apriori-Genetic algorithm is used to deal with the pre-processed data and the support threshold is set to 0.1. The association rules which has a higher value of fitness are find by the hybrid algorithm are list in the Table 12. The corresponding fitness, support, confidence, and coverage are followed by the rule.
The fitness value of first rule-‘male, time3 => 1’ is 1.72, and its support is 0.28, confidence is 0.71, coverage is 0.73. It can be knew from the rule that if the driver is male and the time is the time3 (13–18 pm), the accident with the type ‘1’ (rear-end) is often happened. And the rule has a high value of coverage. The fitness value of the rule-‘male’, ‘rain’ => ‘1’ is 1.73. The rule shows that if the driver is male and the weather is rainy day, the accident with the type ‘1’ (rear-end) is also often happened. It has higher support, but the confidence and coverage is smaller.
The rule of ‘self training =>7’ shows that the accident with the type ‘7’ (Not give way according to the rule) is often happened when the driver’s way of training is self training. And when the driver’s way of training is school training & the time is the time3, the probability of the accident with the type ‘7’ (Not give way according to the rule) is also higher.
Through detailed analysis of the results of the traffic accident rules set, certain and meaning rules can be found and it has important significance on the targeted prevention and scientific management about traffic accident.
Compared with Apriori algorithm and genetic algorithm
The Apriori algorithm is used to deal with the data which’s fields are selected by the analytic hierarchy process. Then the association rules are obtained directly. The simple genetic algorithm is also used to deal with the data which’s fields are selected by the AHP. The initial population was randomly generated, and the size of initial population was equal to the size of initial population about the hybrid Apriori-Genetic algorithm. The design of the function fitness is the same as the equation 4, and a = b = c = 1. The design of the genetic operators in the genetic algorithm is the same with the hybrid Apriori-Genetic algorithm.
These algorithms are implemented in the condition that the hardware environment is intel Core i5-4200H @ 2.80GHZ 2.79GHZ processor, 8GB memory and the operating system is windows 10, software is python2.7. The experimental results of different algorithms are compared by setting different support degree and genetic algebra.
Figure 4a shows the number of expected accident rules(the definition of expected rule is that the fitness of the rule is more than 1.0, which guarantees the reliability of rule.) obtained by the hybrid algorithm and apriori algorithm in different support degree. The genetic algebra of the hybrid algorithm is 100. Figure 4b also shows the number of expected accident rules generated by the hybrid algorithm and the simple genetic algorithm in different genetic algebra. The support degrees are both 0.1. It can be seen that because the hybrid algorithm uses support, confidence and coverage as the evaluation index of a rule and Apriori algorithm searched aimless, the hybrid algorithm can find more expected rules which are much meet user expectations in the same support and reduces the generation of useless rules. When the genetic algebra is less, the number of expected rules found by simple genetic algorithm is less relative to the hybrid algorithm due to the random search of simple genetic algorithm. However, with the increase of genetic algebra, the search space is increased. The number of expected rules found by simple genetic algorithm and hybrid algorithm tends to approach. The effect between two algorithms is not much different.
(a) The number of association rule obtained by Apriori algorithm and hybrid GA algorithm. (b) The number of association rule obtained by genetic algorithm and hybrid GA algorithm.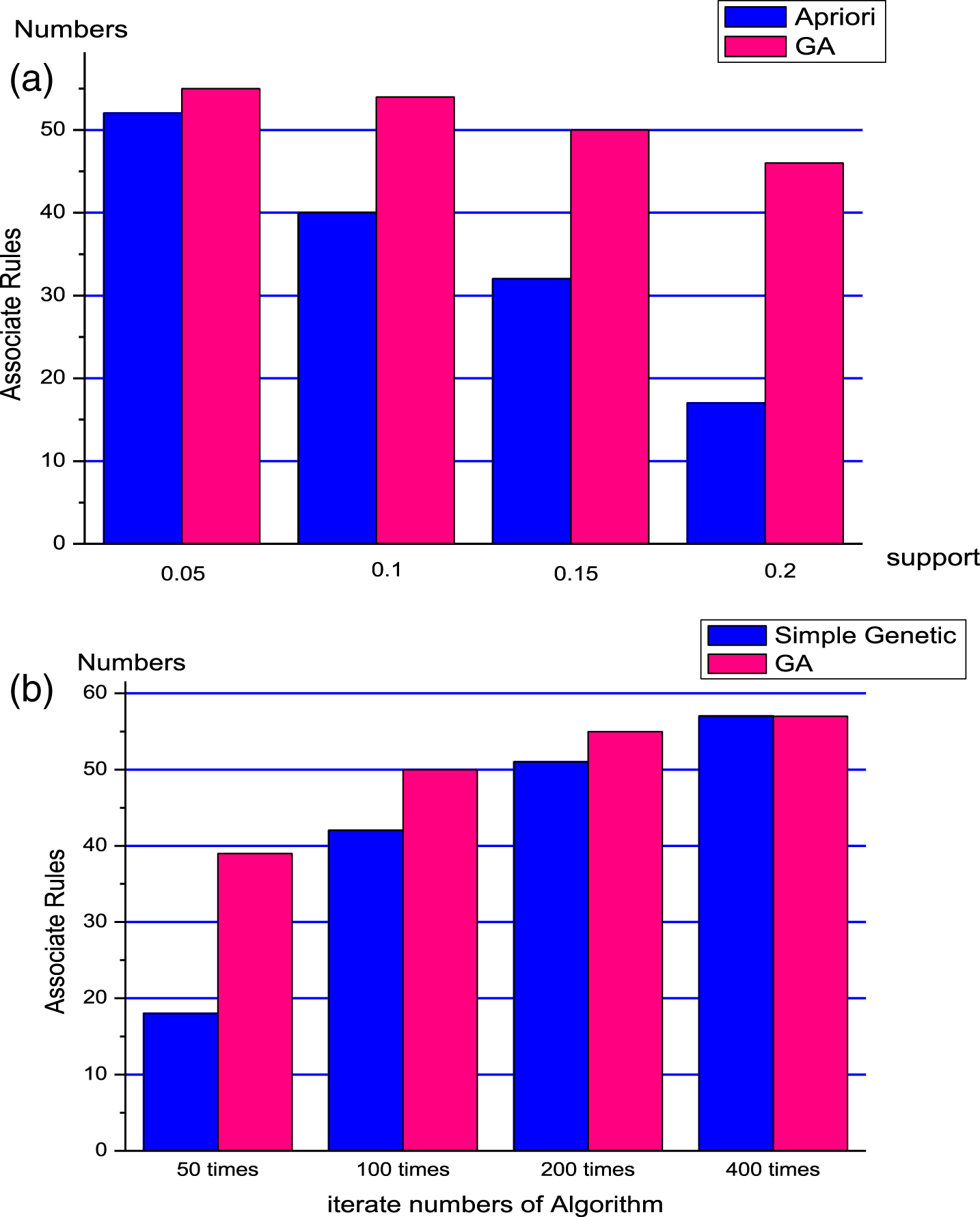
Figure 5a shows the comparison on execute time about the hybrid algorithm and the apriori algorithm which running at different degrees of support. Figure 5b also shows the comparison on execute time between the hybrid algorithm and the simple genetic algorithm under the same support (0.1) and different genetic algebra.
(a) The runtime of Apriori algorithm and hybrid GA algorithm. (b) The runtime of genetic algorithm and hybrid GA algorithm.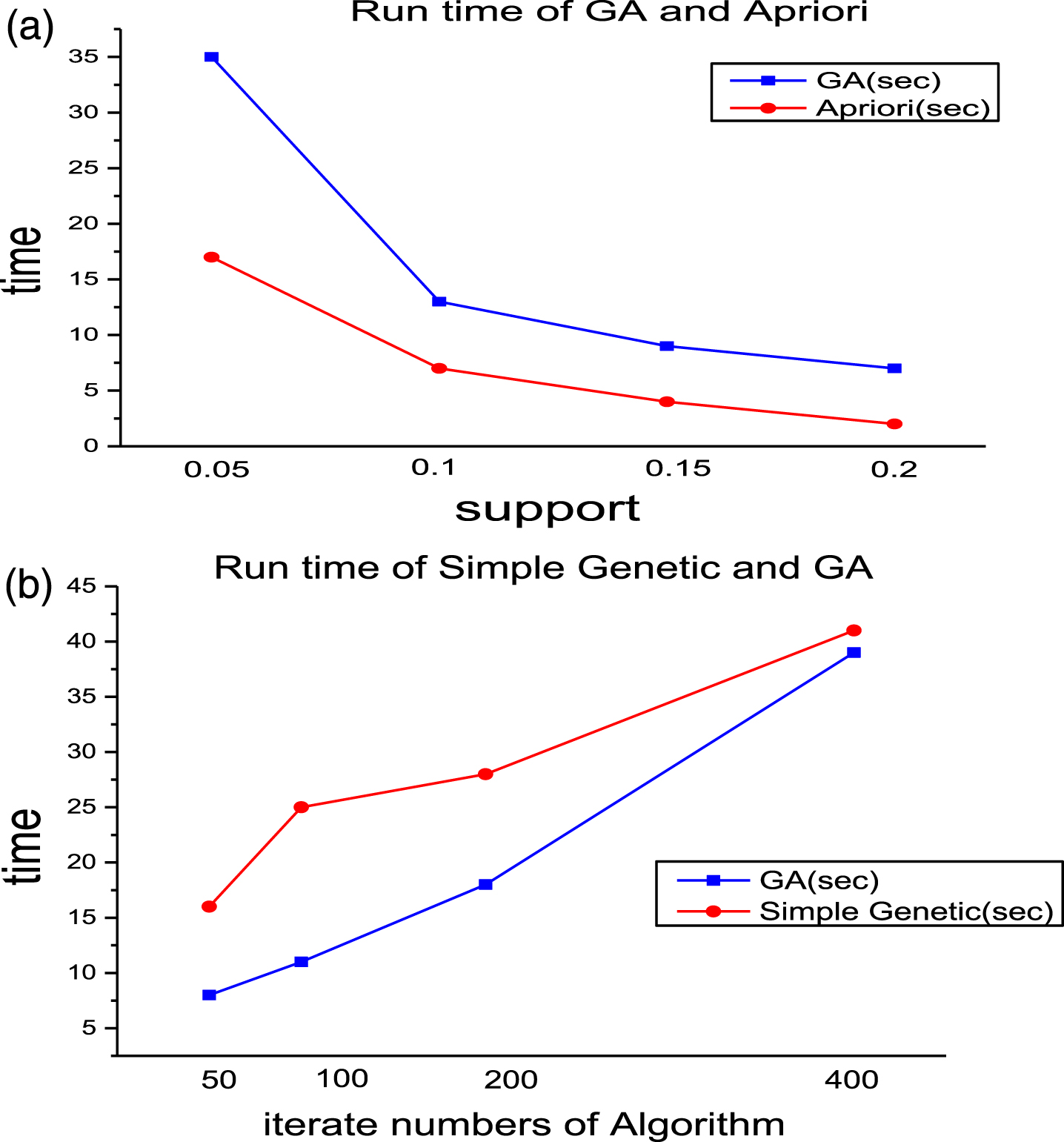
It can be seen from the figure that the hybrid algorithm performs better than the simple genetic algorithm when the genetic algebra is not large, but the spent time of the hybrid algorithm is worse than the Apriori.
Figure 6a and 6b show the comparison of the execute time about the hybrid algorithm after parallelized and other algorithms. It can be known that the parallel hybrid algorithm has a better performance than the simple genetic algorithm on execute time. At the same time, the time complexity of the parallel hybrid algorithm is obviously reduced compared with the algorithm without parallelization.
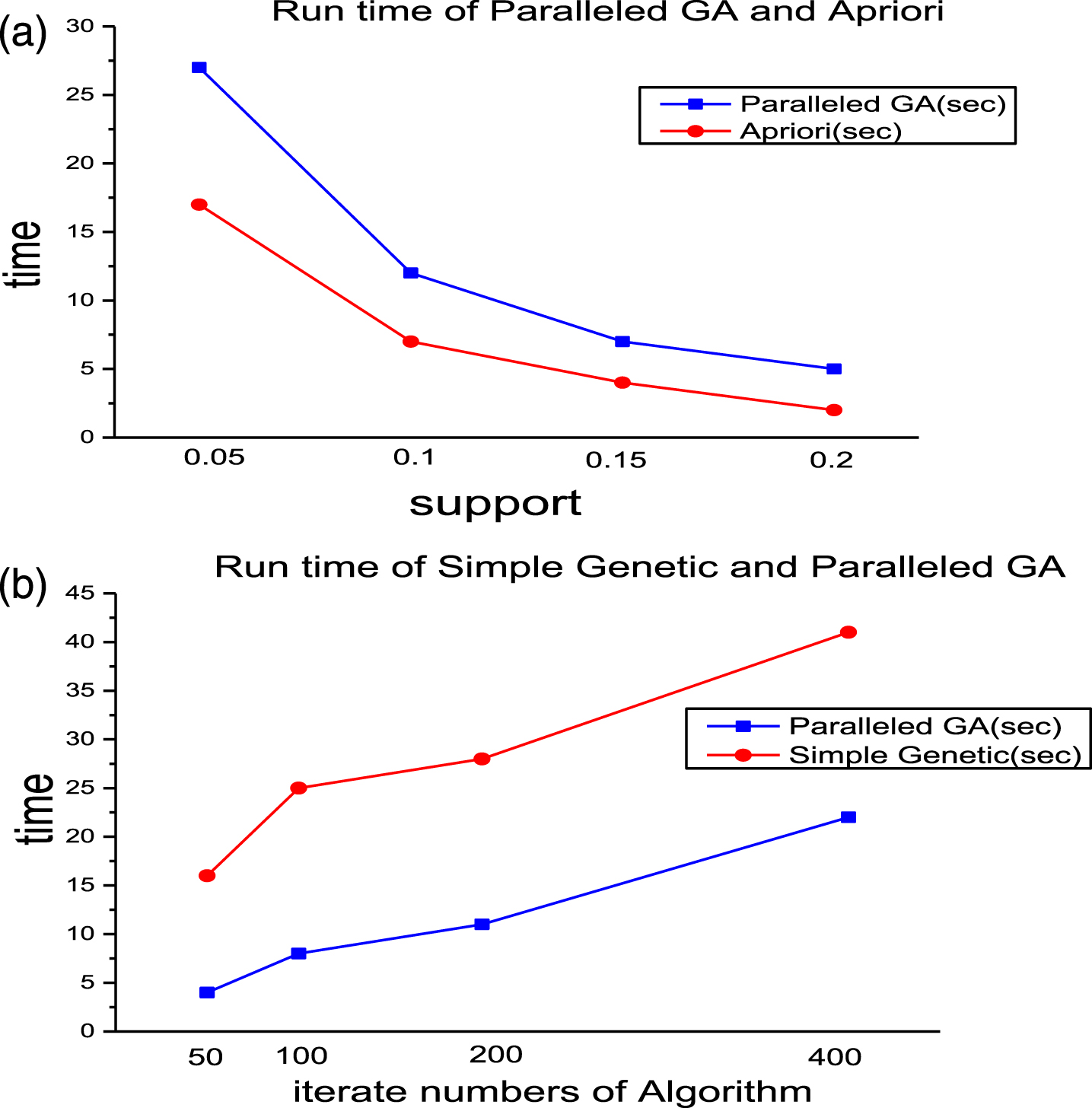
(a) Comparison of running time between Apriori algorithm and parallel hybrid GA algorithm. (b) Comparison of running time between genetic algorithm and parallel hybrid GA algorithm.
This paper mainly focuses on the data mining of traffic accident data. According to the multi-dimensional and multi-layer characteristics of traffic accident data, an accident causation analysis model which based on AHP and the hybrid Apriori-Genetic algorithm is proposed to mine the cause of the accident. By comparing the existed traffic accident processing algorithms and making the hybrid algorithm parallel, the experiment results show that the model can improve the accuracy of mining and find more expected association rules, and has a good application potential. Through the model, we find out some meaningful traffic accident laws, but the construction of matrix in AHP is always subjective. So how to eliminate this error will be the next research work.
Footnotes
Acknowledgments
This work was supported by National Natural Science Foundation of China, under grant No. 61772553 and No. 61379058, Technology Plan Project of Hunan Province, under grant No.2015TP2017, the Fundamental Research Funds for the Central Universities of Central South University under grant No.2016zzts359.