
Abstract
Machine translation is one of the parts of language processing within linguistic computing for automatic translation from one language to another. The paper introduces one of the most critical areas of soft computing and natural language processing, i.e. machine translation technique that is based on deep model structure of rough sets with capability to transfer learning. A deep rough set learning is developed to support machine translation to recognize and translate tens of thousands of words/sentences automatically. To our knowledge, this is the first attempt aiming to use rough sets in machine translation rather than Arabic language translation. A deep information table is learned by assigning the morphemes-similar objects with similar learning complexities into same class and it can identify the inter-related learning tasks automatically. To account for the differences among source-languages domains, we proposed a partial transfer learning scheme in which only part of source information is transferred. The experiments have demonstrated that the proposed model can achieve competitive results and significantly outperformed other methods for translation on both accuracy rates and the efficiency for machine translation.
Introduction
Internet is no longer monolingual as non-English content (Arabic, Hindi) is growing rapidly [1, 2]. The diversity of languages is becoming barrier to understand the digital content and querying for information where the people get the information in their local languages, it has been majorly accepted. Therefore, the users can access the information in local language without knowing in which language the information is stored in database. Google currently supports searching and translation between above 78 languages. The dictionary-based translation approach used bi-lingual database for translating text from one language to another. Morphological analyzer senses morphemes of an input word and can find the root word of a given word to search with in dictionary. Rule-based translation approach is used for words, which are not found in the dictionary [2, 3]. Neural machine translation systems recently have marked a good achievement and produced user acceptable translations. While in many cases, machine translation system need to be corrected or retranslation.
Arabic is the language in twenty-two countries spoken by more than 300 million people. It is one of the official languages in United Nations. Arabic is very rich language in vocabulary, meanings and flexible where it forms sentence from putting words together. The Arabic words are three types: Noun, Verb and Particle. Arabic nouns consist of name, things, pronouns, question, connection, signal and others. Arabic nouns are not countable and still growing more and more. The tenses of verbs are past tense, present, and command tense. Arabic particles are: from ( ), to (
), to ( ), on (
), on ( ) and with (
) and with ( ). Any Arabic words can be singular, dual, or plural. For example, person (
). Any Arabic words can be singular, dual, or plural. For example, person ( ), two persons (
), two persons ( ), and persons (
), and persons ( ). Arabic language is classified as Quran Arabic, standard Arabic, and dialect Arabic. Standard Arabic has two different sub-languages (old and modern Arabic). Modern standard Arabic is the official nowadays and it is the language of literature and media. Modern standard Arabic is either written or spoken without any different in the form and it was the language used for all cultural and religious purposes. Modern standard Arabic uses simpler numeral systems and includes some more recently words and borrowed ones [4, 5]. Old pure Arabic language was pre-Islamic used language. The main Arabic dialects are Gulf Arabic, Iraq Arabic, Levantine Arabic, Maghreb Arabic and Egyptian Arabic.
). Arabic language is classified as Quran Arabic, standard Arabic, and dialect Arabic. Standard Arabic has two different sub-languages (old and modern Arabic). Modern standard Arabic is the official nowadays and it is the language of literature and media. Modern standard Arabic is either written or spoken without any different in the form and it was the language used for all cultural and religious purposes. Modern standard Arabic uses simpler numeral systems and includes some more recently words and borrowed ones [4, 5]. Old pure Arabic language was pre-Islamic used language. The main Arabic dialects are Gulf Arabic, Iraq Arabic, Levantine Arabic, Maghreb Arabic and Egyptian Arabic.
Rough set theory [6–10] that was introduced in 1982 is a powerful mathematical tool to deal with vagueness and uncertainty in many applications. Rough set method is a valuable tool of soft computing research area. In many applications, a set may appear in some of the attribute values for an object, in others, the system should investigate non-deterministic information and non-deterministic approximate sets and objects. This paper proposes a new machine translation model to label terminal and non-terminals words with classes on the target side of aligned sentence pairs. Labeling of the sentences is performed with word clusters trained on the source and target languages using deep rough set approach. The proposed model extracts hierarchical set of rules from trained dataset (huge dictionary as 90k-word) that gives significant improving on translation quality. The set of rules is extracted from information table that is built from word-translation task merged with set of rules that is induced from phrased-translation task to construct hierarchical set of rules. This set of rules can be used in proposed machine translation.
Deep learning [11, 12] has emerged as one of the fastest growing machine learning paradigms in artificial intelligence and human-centric systems. The notion of deep learning is the use of deep information, multiple levels and multiple views of data for learning processing and problem solving algorithms.
This paper is organized as follows. The description of rough set theory is given in Section 2. Section 3 discusses the proposed model of translation system. Section 4 presents the experiments on Arabic machine translation with evaluations. Section 5 states some related works and Sections 6 concludes the present paper with discussion and future extensions.
Rough sets basic notations
Let us represent any known data as an information table T = (U, C, D), U is non-empty finite set of objects called the universe, C is non-empty finite set of features C : U → VC where VC is called the domain of the attribute set C, and the attribute set D where C ∩ D = φ is called the classification attribute. The indiscernibly relation I ⊆ U × U on U can be defined as follows [8, 13]:
Where A ⊆ C is a subset of attributes. The equivalence class of x, x ∈ U on relation I is defined as follows:
According to the relation I, two crisp sets
A reduct [9, 16] is a minimal set of attributes B that can classify objects with the same accuracy as the original set of attributes C and none of the attributes in the reduct can be eliminated without decreasing its classification capability, i.e.
Decision rules [6, 17] are the data patterns that represent the relationship between the attributes’ values of a classification system. If V = ∪ {v c : c ∈ C} ∪ v D , is a set of values for the attributes, then the decision rule is in the form: IF p THEN q, where p is the conditional part of the rule and q is the decision part of the rule.
This section proposes ideas to build an effective machine translation with superior quality of estimating to words translation. We propose deep structure classifiers and integrate them into conventional features set for translating to Arabic sentences. Our main contribution is a novel text translation method as a deep rough set translation machine. The main challenging issues in machine translation are word ambiguity, word order, word sense, idioms, pronoun resolution, syntactic ambiguity and structural ambiguity [1, 4]. We also propose an incremental learning method of deep rough translation machine to successfully train such many classes. If we consider word-level confidence classification, then the objective is to estimate and judge each word in machine translation hypothesis as correct or incorrect translation. The classifier task, which has been trained using rough set method beforehand to induce the confidence rules for machine translation, output word. The human translator multitasks learning [12, 21] to translate from language to another are:
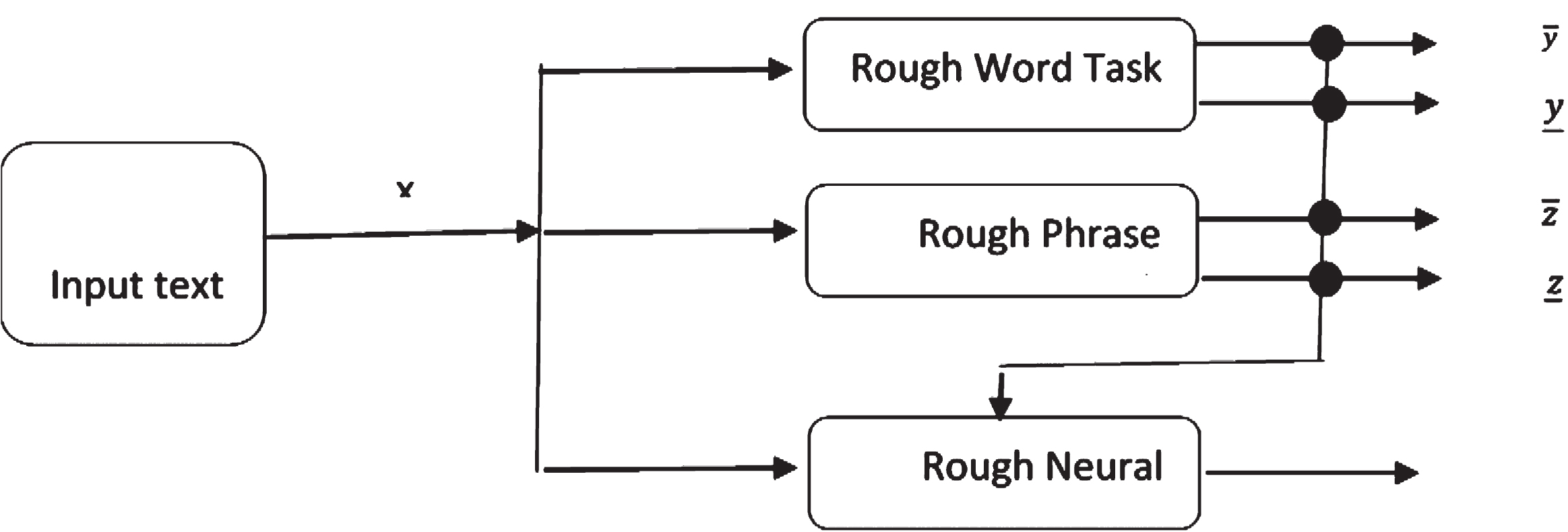
The proposed model of machine translation contains three set of features from deep layers as in Fig. 1. The raw sentence passes through the tokenizer, which splits the sentence into words. These words pass through the rough-based rule of word translator. At the same time, the raw sentence passes to rough phrase-based translation system and neural-based translation system. The deep structure of translation system is shown in Fig. 2. The source text inputs to Rough phrase model, rough word model and rough neural translation model. Rough translation machine finds the approximation sets lower and upper approximations and generates their similarity classes under the selected feature set. Each word (phrase) has a set of candidate translation target, some of them can be considered as lower approximation of this word (phrase). The target translation words (phrase) which can be shared for more than one source word (phrase) can be considered as upper approximation of word (phrase). In Fig. 2, the source text inputs to word, phrase, and neural translation at the same time. Neural translation takes the output of word-based and phrase based model to find translation for source text. The target translation text can be taken from word based, phrase based or neural based translation output.
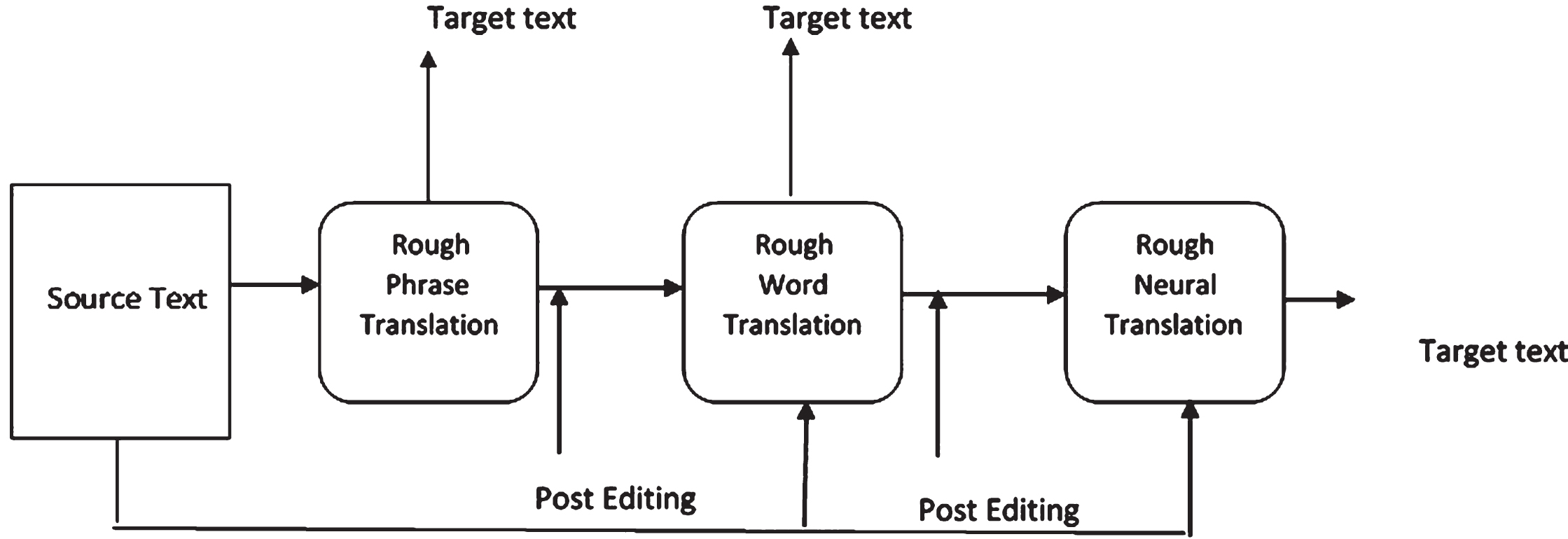
The proposed translation system.
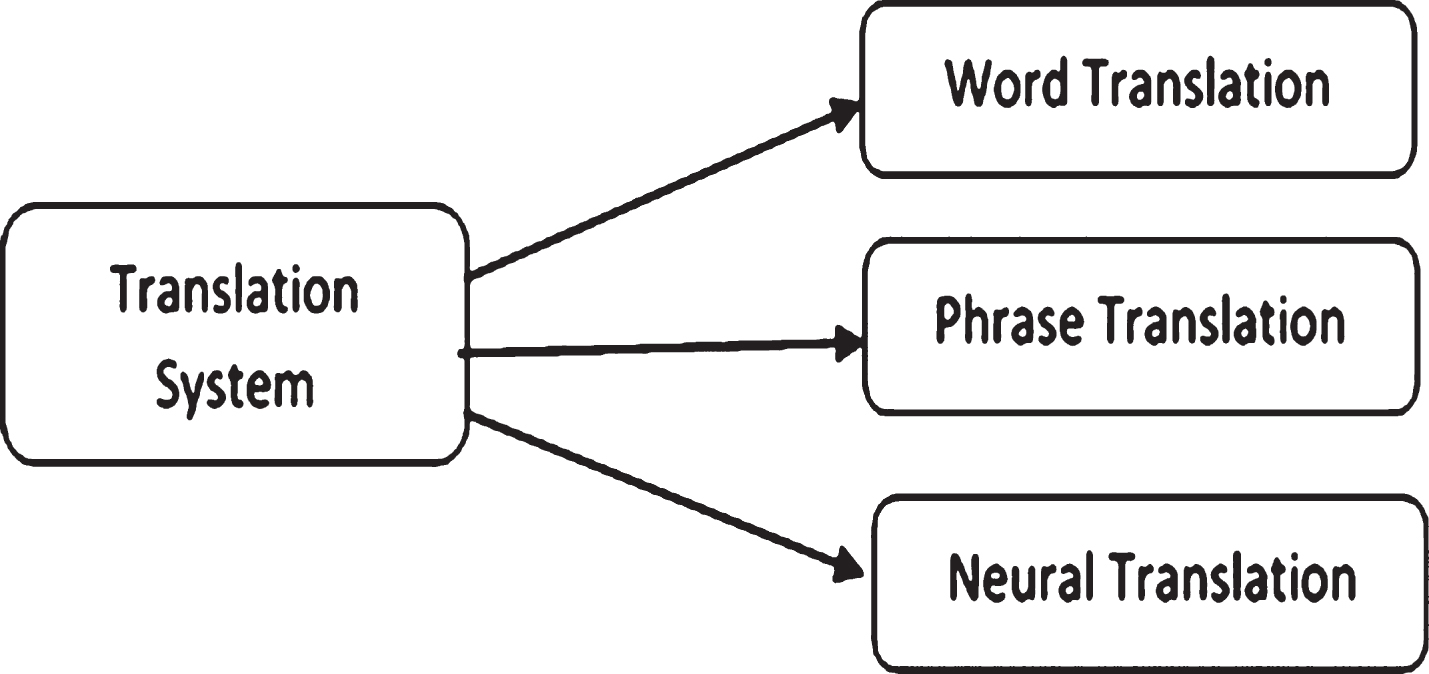
Deep translation system.
We will consider here many-to-one translation, where any source language can be embedded translate to Arabic language. Proposed model can attend two or more source languages combined into input text at the same. We will focus here on language pairs English/French/Spanish to Arabic, which can be extended to multiway multilingual model.
The Important task in our machine translator is to classify the atomic word. The information table will be created for this task (as in Table 1). The dictionary is used to find for each word in the sentence the corresponding equivalent translated word. There are multiple target words for each one source word. So, rough approximation rule is chosen to translate word to best classified output (show Fig. 3).

Rough translation system-word translation machine.
The information table for classification word class
It is worth noting that the information table provides a good environment to identify the learning tasks of training the atomic word classes. Given N atomic words and their training sentences, we are interested in learning using an information table T = (U, C, D) that comprises a set of objects (words) U, a set of features C and a set of values for features V. Each group of objects u ∈ U is associated with a set of atomic object class X(u) and features set cu ∈ C for object partitioning.
The proposed algorithm finds the approximation rough vector Y with highest and lowest approximation among the choices considering in language models. Considering s as the source word and t any of its translations into target language. The upper (probable) translation of s is given by the following equation:
Where T is the set of all words in the target language, p(s|t) is the probability that the source word s is the translation of the target word t, and p(s) is the probability of appearance of that target language word. The Lower (most probable) translation of s is given by the following equation:
The phrase-based translation model is using phrases instead of words (see Fig. 4). The phrase classes can be determined by clustering phrases on the target training corpus. The information table (Table 2) describes the attributes that are needed for each phrase stored in the translation system. Rough set method can find lower approximation for each class of sentences that exactly match the target phrase to source phrase. While, the upper approximation of phrase class will describe a set of target sentences close to source sentence. The attribute “phrase entropy” is similar to [20].
English sentence and the equivalence sentence in Arabic.
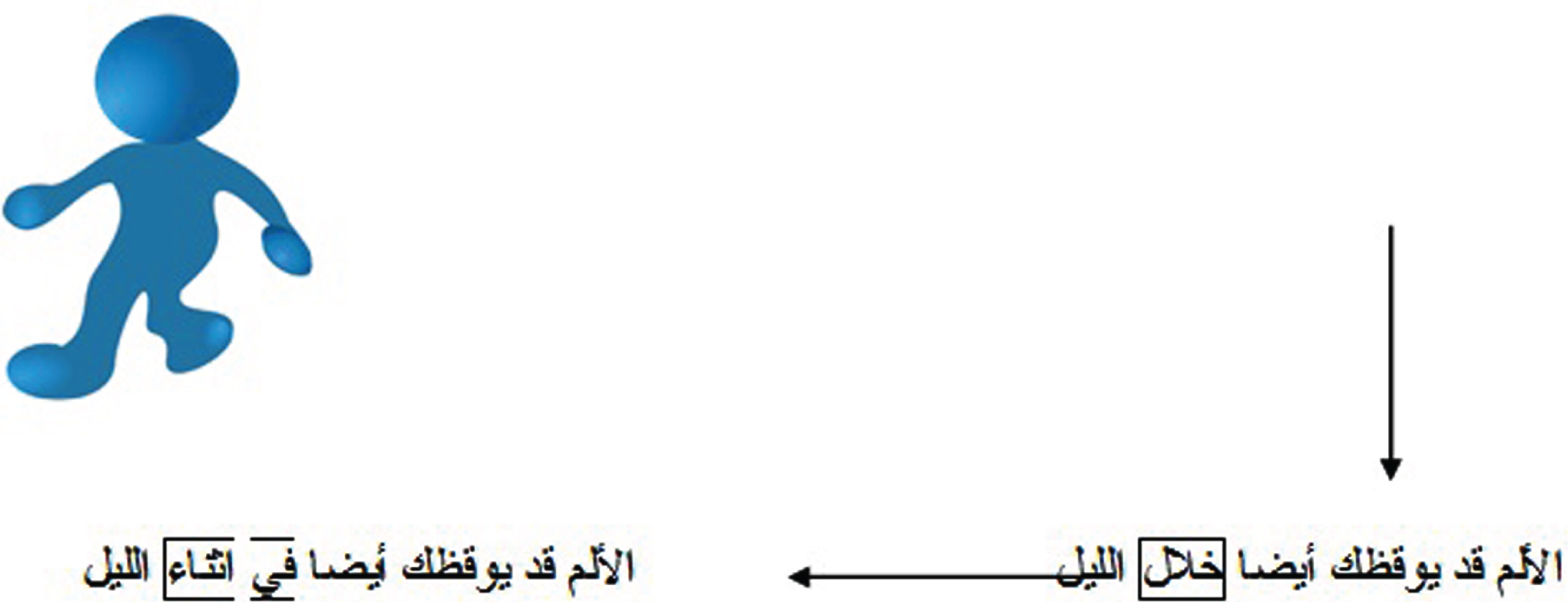
The feedback example from user for translation sentence “the pain may also wake you up during night”.
The information table for phrase translation
For the phrase pair (s, t, I) where s (i → j) stands for the source substring from position i to j, I is rough indiscernibly relation, and t (k → l) stands for the target substring from position k to l, then (s, t, I) is indiscernibly phrase if:
(7)
Where s_m and t_m’ stand for words in positions m and m’ of the source and target sentences, respectively. The proposed model suffers from ambiguity by using number of induced rules. The proposed model defines rules that extracted from sentences pairs of the parallel training dataset. The output of phrase model is context also rough vectors whose length varies with respect to source sentence. This context set of vectors consists of upper vector -Z and lower vector
The proposed model supports post-editing [19, 22] by adding an interactive algorithm to the translation model. Since the translation by machine is not error-free, the supervision and correction by human is added here (see Fig. 4). Each time the user corrects a word, the model reacts and add new object to information table for modified translation hypothesis. We do not replace the editing translation into information table but add both (original an editing words/phrase) to the information table. The post editing can modify the output of word translation and/or phrase based translation.
A rough neural network as a computational graph is a special form of an artificial neural network rough neural network consists of a layer of input cells (rough neurons), one or more layers of hidden rough neurons and a layer of output conventional neurons. Cells in each layer are connected by fully/partial weighted connections to cells in the previous and following layers. Each cell’s output is a rough function of the weighted sum of its inputs [11].
Proposed Rough neural phase model will generate one symbol at time as translation of the source sentence based on the context vectors using rough neural networks. The input vectors must be appropriately encoded with size (dimensionality) m that is arbitrary input vector and rough neural network sizes. The words in the phrase are mapped into an m-dimensional space for each word in the vocabulary. The output of word translation model and the output of phrase translation model will be merged into vector and considered as input to rough neural networks to choose which target phrase will be selected as output of translation machine (Fig. 6). The output layer produces a probability distribution over the words in the vocabulary. Each output box represents vector (cells) of possible translated words. The word with the highest probability is selected as the target word translation.
Deep rough translation system.
The model has two transformation vales
Then the output of model is
We choose φ as sigmoid-transfer function. The relevance score of each context vector output is computed based on the transfer function φ. The error function e is calculated as:
The model of rough neural networks tries to adopt many number of hidden layers to gain better approximation capability for complex translation problem. The pretraining of the proposed network sets the initial values of connection weights and biases and then the network is trained as a while using back propagation algorithm. The update of the weights near the input layer of rough neural network is insufficient which is called a vanishing gradient problem [18]. The learning rates are scaling based on the historical values of them. The large amount of computation is commonly required here for training data.
The deep learning here is not represented in mathematical equations but in implicit mapping without explicit rules. It deals with much more complex relationship among many parameters and connection of neurons. Among input-output data given in Fig. 7, deep learning can manage to find a mapping relationship among them and reconstruct layers on themselves. The fully connected rough layers are used as classifiers which act upon complex words order learned in the deep layers. The model consists of four separate deep rough layers with variable output. Each layer learns increasingly complex pattern of input text vector data and gradually shifts closer toward recognition (translation) of the same. After these layers, a max pooling layer with rough neurons strides in both axes in inserted to increase weight of the most important words. The classification cluster has three fully connected layers with same variable output numbers. Last layer has conversional neurons with SoftMax function [11] for output.
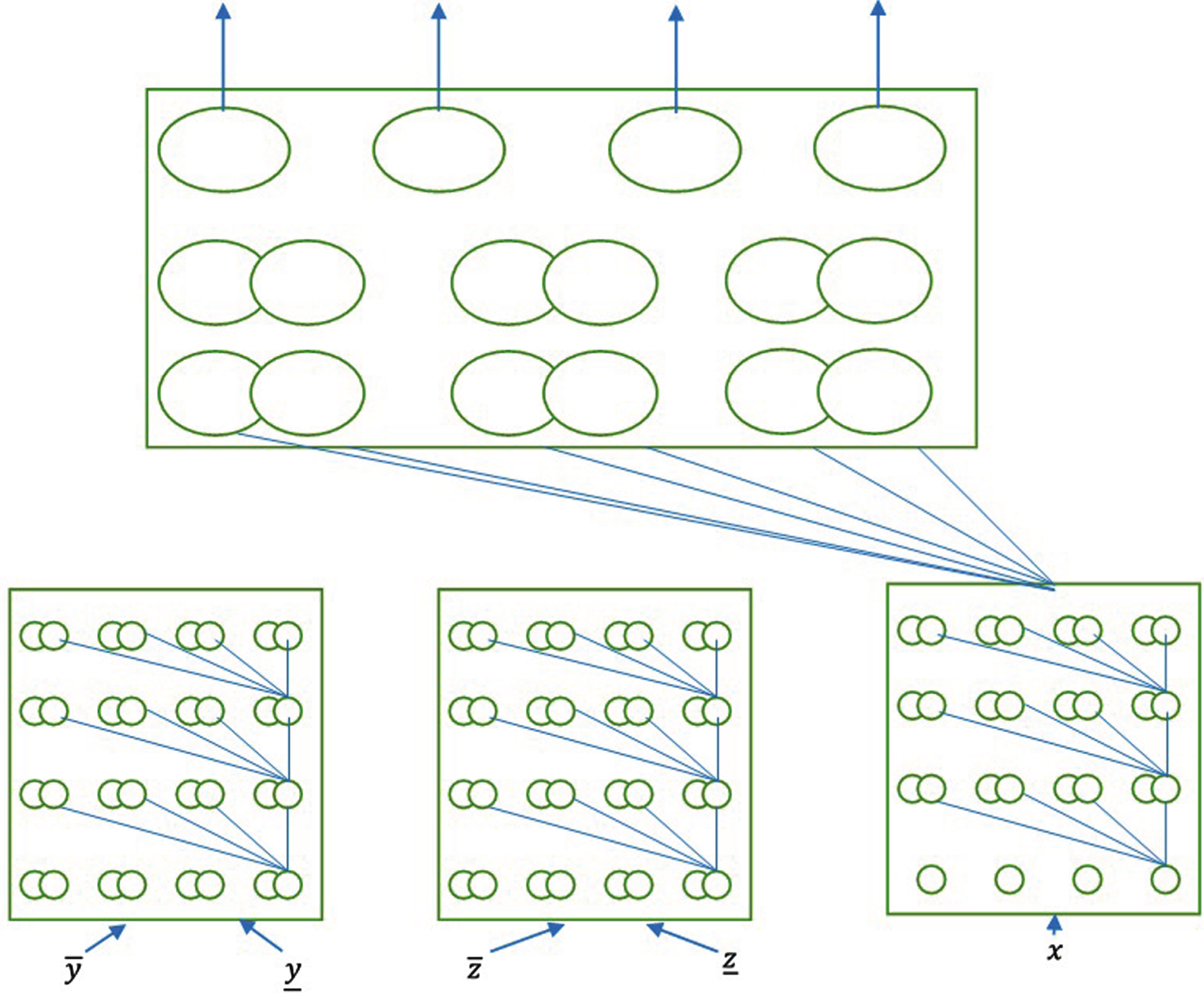
Deep rough neural networks translation system.
The word classes explicitly define word translation. The proposed model induces grammar non-terminals from training data by clustering phrases/words based on the source and target word classes using rough set method. The model will give importance to some words of phrases and shows that translation quality will be improved by reorder the target sentence. The words with higher output values appears first in the phrase.
Transfer learning refers to the knowledge from a source task to a target task [2, 21]. Rough translation machine seeks to find an optimal translation for its source text where the machine is considered as a mapping to describe how rough translation machine should behave. Ideally, we would like to create a translation machine that can learn how to accomplish more general translation in a range of languages. To account for the differences between source languages, we proposed a transfer learning scheme for parts of rough information/rules and rough neural networks parameters from one language translation model to another language translation model (see Fig. 8).
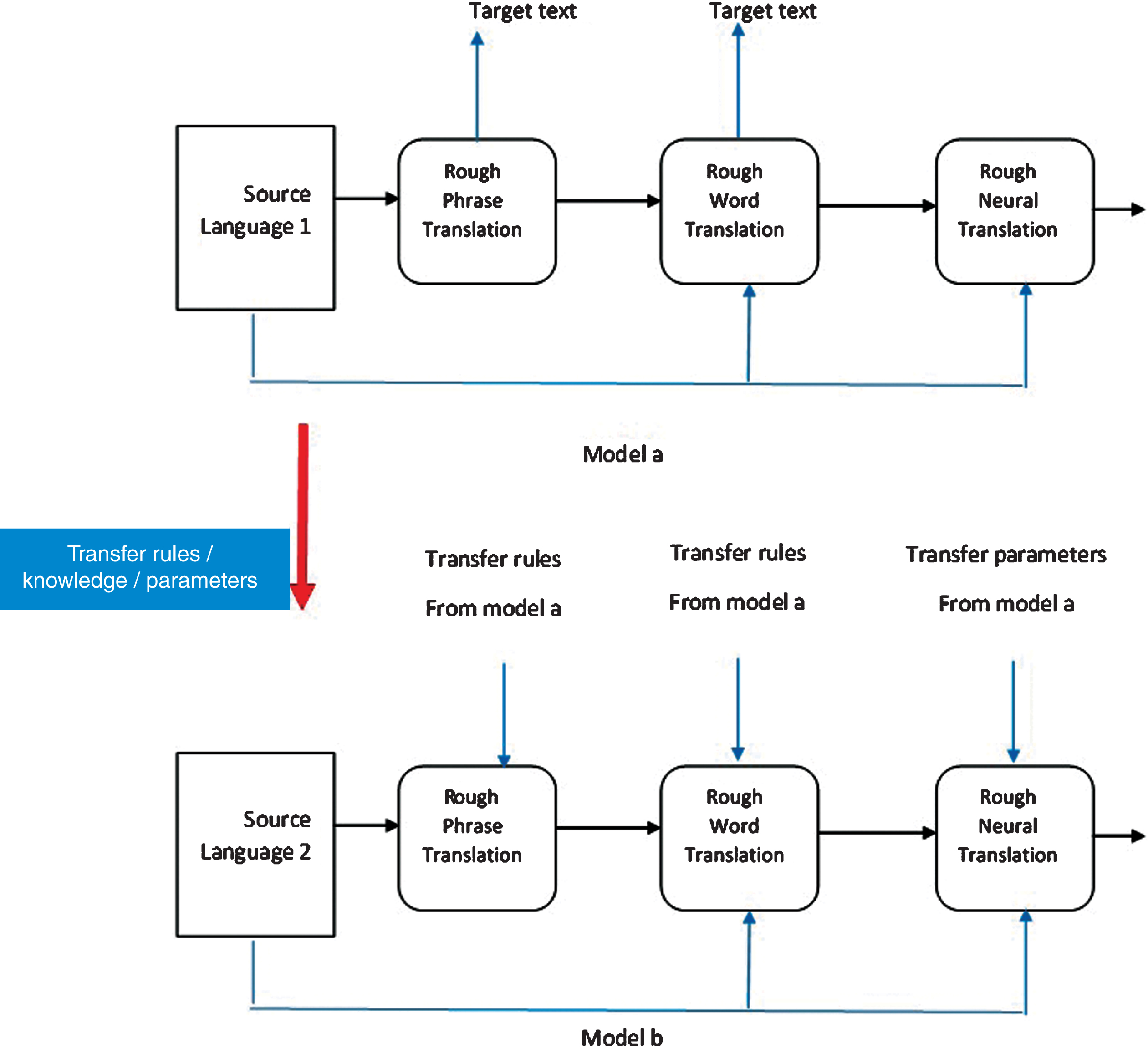
Deep transfer learning translation system.
Because of many possible source rules, providing the translation machine with option of counteract the benefits of knowledge transfer. Therefore, we score the set of rules for ranking the knowledge. We select only the best rules for use/transfer. The scoring system based on the proportion of the translation rough rule that are preserved between the source and target languages.
Transfer learning here can be implementing by transplanting the learned set of rules from rough information tables and learned feature layers from neural model (one language) to initialize another neural model (another language). Consider a set of q source tasks with corresponding training datasets {P1, P2, …, Pq} where Pi = (si, ti), si represents the source text and ti denotes the corresponding translation on them. The target dataset is divided into Te (set of test data) and Tv (set of validation data). The sizes of the training and testing data are kept small in our experiments.
There are two main steps in our proposed algorithm. (1) Deep learning the translation from language X to Arabic language. This step is to find the best translation between two samples in different languages by translation words and phrase tasks. Next, find the better arrangement of translated sentences and update translation based on user feedback tasks and preserve the properties of original sentence. (2) Transferring knowledge of translation sentences to another translation machine between another different language and Arabic language. This step is to select the samples that are related to each task from other tasks and reuse them to help translating new tasks.
Experiments and results
This section tries to collect some decisions to model system for deep rough set machine translation. We use deep rough machine translator by hardware environment as: Intel (R) Core (TM) i5-3210M CPU@2.50 GHz. The software environment is ROSETTA (Rough set toolkit), MATLAB 2014b and Java code for some classification methods.
Each sentence corpus is tokenized using the tokenizer script from Moses decoder. We train the model with learning rate 10–4. We used 20 sentences pairs and update the learning rate until reach the best value for Arabic/English language pair. We use the same model architecture for every source language. The only difference between language pair models is the number of input nodes and target classes.
Automatic evaluation of machine translation systems is still an open problem as many factors affect the translation process. The quality of translation is usually estimated by comparing the target translation with the reference corpus. The most widely used metric for evaluating machine translation systems is Bilingual Evaluation Understudy BLEU [2, 3]. This measure model between the translation generated by proposed translation system and the one produced by a human translator. Another evaluation method is Translation Edit Rate (TER) [19, 22], which is used to estimate the post-editing efforts required to modify the translation results such that it can match with the reference translation.
In general, copious amounts of parallel data in experiments do not mean an increase in the BLEU score. We think that no matter how large the data is, the Arabic translation system will be benefit. The experiments are with limited number of data. A set of experiments was performed for English-Arabic, French-Arabic and Spanish-Arabic translations. Whereas the word order in the European languages is similar, Arabic has a different word order. The model was trained and evaluated with human experts and the results were symmetrized.
The main model parameters were obtained through search (tested hidden neurons in the range [50, 1000]). We chose the model with highest BLEU in the development time. We only use sentences of length up to 150 symbols. All outputs (target text) are taken based on BLEU on the experimental time. The results indicate that the translation quality is significantly affected by applying the proposed model on training phrase pairs.
One thousand examples are selected from source text. The selection is performed based on the short and long sentences (3 to 50 words). All one thousand instances are translated as examples in information table. One hundred examples with translation are used as test examples to evaluate the proposed translation system and to identify the translation errors. Each training corpus is tokenized using the tokenizer script from Moses decoder. For each and every language, we include 90 k words in the vocabulary.
The overall comparisons of the translation results are shown in Table 3. As we observed in experiments, better scores if we shared parameters and output layers of the deep neural networks in our proposed translation machine. BLEU is computed on the tokenized true-case text and we look at the average log-probability assigned to translations by human and trained model as an additional evaluation metric independent of any error caused by approximate decoding.
Results of English to Arabic Translations using rough set deep translation system
Results of English to Arabic Translations using rough set deep translation system
Weights and set of rules (knowledge base) from the runs of the model with source dataset are saved and re-used for a different translation task that is different from the source language. The feature extraction clusters of the model are frozen for weight and rules update to transfer learning. Table 4 shows the task combinations with which transfer learning experiments are executed. We observe that the best accuracy achieved with the transferred model is on par with state of the art mentioned in this paper. It is also evident that all transferred rules are capable to recognize words from a related language source. It is also remarkable that the best accuracy is achieved in very short time compared to the original model in Table 3. Then, the proposed model can pre-trained on related but different translation language. We observe that the proposed transfer learning outperforms better than original model for all pairs considered. It happens in terms of both BLEU and TER. This is encouraging to consider transfer model learning in the complete set of original models. We should note that the results are often below state-of-the-art machine translation systems. Because they used large vocabularies and corpora source-target language.
Results of Translations using transfer learning system French to Arabic
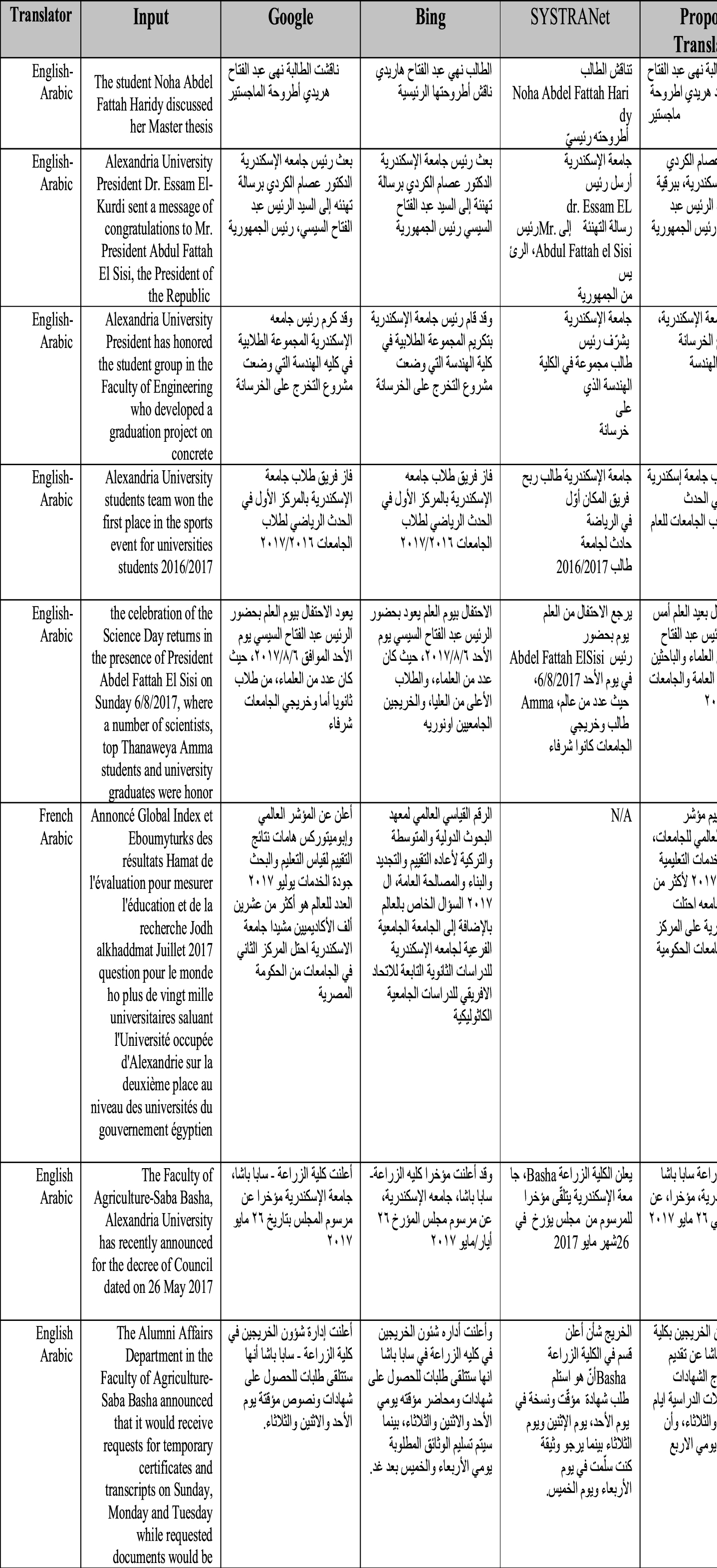
The English sentence can be translated into different Arabic sentences based on the used translation system. English sentence: “The cat is eating the rat.” Google translation “ ” (equivalent to “the cat eats rats”). SYSTRANet http://www.systranet.com/translate/: “
” (equivalent to “the cat eats rats”). SYSTRANet http://www.systranet.com/translate/: “ ” (equivalent to “the cat eats mouse”). Another example: “he suffered from crystal induced arthritis”→ “
” (equivalent to “the cat eats mouse”). Another example: “he suffered from crystal induced arthritis”→ “
 ” in google translation. “he suffered from crystal induced arthritis” → “
” in google translation. “he suffered from crystal induced arthritis” → “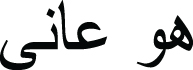
 ” in SYSTRANet. From the example, we observe the difference between translation systems in translating pair of languages. Table 5 gives some examples of translations for English, French, Spanish languages to Arabic using the proposed model, Google translator, Bing and SysTransnet systems. SysTransnet has no French/Arabic nor Spanish/Arabic translation pairs.
” in SYSTRANet. From the example, we observe the difference between translation systems in translating pair of languages. Table 5 gives some examples of translations for English, French, Spanish languages to Arabic using the proposed model, Google translator, Bing and SysTransnet systems. SysTransnet has no French/Arabic nor Spanish/Arabic translation pairs.
Examples of output Translations of general sentences to Arabic translation
The work in [2] proposed a multi-way multilingual neural machine translation. The model can translate between multiple languages by sharing pairs of languages. It used deep recurrent neural network translation model as encoder/decoder network. The encoder recurrent neural network maps input text into vector space and the other recurrent neural network decoding model generated a target context vector. This model could map any source language which means multilingual translation process. The authors applied the proposed models on English, French, Czech, German, Russian and Finnish languages.
The work [2] differs than our proposed work as we used transfer learning to support multilingual languages where the model train first on English/Arabic translation and then transfer the model parameters and knowledge to French/Arabic and Spanish/Arabic translation model. Second, the model in [2] used recurrent encoder/decoder neural machine translation while we used rough decision tables and rough neural networks in deep manner to build machine translation system.
The model in [23] presented two approaches for combining scores from neural translation language model trained on target monolingual data with neural machine translation model that trained on source language only. The model performance was measured using BLEU that give double performance accuracy over hierarchical or phrase-based pair languages. The model began with Turkish/English and extended to Chinese/English and German/English pair languages. The model differs than ours in that it proposed fusion strategies to involve low resource translation pair language into high resource translation pair language using neural mode. The main objective in model [23] is how recover small scale translation task in neural translation machine which need large training datasets.
Conclusion
Machine translation has been an active research subfield of artificial intelligence for years. Machine translation is a hard problem because natural languages are highly complex. To improve the performance of machine translation, deep rough set translator with transfer learning is presented in this paper. We have presented theoretically a proposed model that based on traditional rough sets and concept of deep learning. The proposed work can give rise to the implementation of learning procedures aiding to decision making in statistical and neural versions. The results in translation justify the accommodation of the rough set with definition of space of languages. Thus, a detailed compensatory based on the language space. The experimental implementations prove that the proposed model has high accuracy for real-life translation dataset.