
Abstract
Energy consumption and performance metrics have become critical issues for scheduling parallel task-based applications in high-performance computing systems such as cloud datacenters. The duplication and clustering strategy, as well as Dynamic Voltage Frequency Scaling (DVFS) technique, have separately been concentrated on reducing energy consumption and optimizing performance parameters such as throughput and makespan. In this paper, a dual-phase algorithm called EATSDCD which is an energy efficient time aware has been proposed. The algorithm uses the combination of duplication and clustering strategies to schedule the precedence-constrained task graph on datacenter processors through DVFS. The first phase focuses on a smart combination of duplication and clustering strategy to reduce makespan and energy consumed by processors in an effort to execute Directed Acyclic Graph (DAG) while satisfying the throughput constraint. The main idea behind EATSDCD intended to minimize energy consumption in the second phase. After determining the critical path and specifying a set of dependent tasks in non-critical paths, the slack time for each task in non-critical paths was distributed among all dependent tasks in that path. Then, the frequency of DVFS-enabled processors is scaled down to execute non-critical tasks as well as idle and communication phases, without extending the execution time of tasks. Finally, a testbed is developed and different parameters are tested on the randomly generated DAG to evaluate and illustrate the effectiveness of EATSDCD. It was also compared against duplication and clustering-based algorithms and DVFS-based algorithms. In terms of energy consumption and makespan, the results show that our proposed algorithm can save up to 8.3% and 20% energy compared against Power Aware List-based Scheduling (PALS) and Power Aware Task Clustering (PATC) algorithms, respectively. Furthermore, there is 16% improvement over Parallel Pipeline Latency Optimization (PaPilo) algorithm with Encur = 1.2Enmin (G). In comparison with Reliability Aware Scheduling with Duplication (RASD) algorithm, the execution time has been reduced in heterogeneous environments.
Keywords
Introduction
Nowadays, energy consumption has become a critical issue in high performance distributed computing systems (HPDCSs). Therefore, green computing attempts to minimize energy consumption, carbon footprint and CO2 emissions in HPDCSs, including clusters, grids and clouds made up of a large number of parallel processors [1].
Recent studies suggest that nearly 1.5–2% of total energy worldwide is consumed by datacenters. Such tremendous growth can be attributed to popularity of distributed computing platforms such as clusters, grids and clouds. Moreover, previous studies indicated that about 52% of energy in datacenters is consumed by computing systems, while the rest is consumed by support systems. In fact, it has been estimated that the electricity consumed in the American datacenters will expand from 91 billion kWh in 2013 to roughly 140 million kWh in 2020 [2].
Hence, it is crucial to schedule precedence-constrained parallel applications, one of the models applied in science and engineering fields, on homogeneous and heterogeneous computing systems like cloud computing infrastructures with regard to energy consumption and other performance parameters [3, 4]. Scheduling is also considered a well-known NP-Hard optimization problem [5], for which numerous heuristic algorithms have so far been proposed [6, 7].
The data analysis steps can be expressed as DAG, which operates on a stream of input data-task in DAG repeatedly receiving input data items from their predecessors, while writing the output to their successors. Makespan and throughput are typical performance-related metrics to measure the performance of a DAG (precedence-constrained parallel application). Makespan is the maximum time to process an individual data item, in which the task in the DAG has been completed [4], while throughput simply counts the number of tasks completed over the makespan [8].
Hence, it is essential to create a compromise between performance and energy consumption, thereby to decrease makespan and energy consumption while increasing throughput. Green computing is therefore crucial for ensuring the future growth of cloud computing will be persistent. The design and development of green software for scheduling precedence-constrained parallel applications can directly affect performance parameters as well as energy consumed by processors and communication networks in cloud datacenters.
Our objective in this paper was to propose an energy-efficient, time-aware, scheduling heuristic strategy called EATSDCD for energy-aware task duplication-based scheduling algorithm of parallel tasks on cloud datacenters. In order to achieve good performance and energy consumption for a given parallel application, we proposed a novel task scheduling algorithm based on clustering and duplication design pattern and dynamic voltage frequency scaling (DVFS) technique. The proposed algorithm aims to reduce the communication energy through task duplication and clustering. However, these duplicate-based scheduling strategies replicate tasks and clustering by another task only according to the energy difference between current task computation energy and communication energy of these two tasks. We have developed an application which can be represented as a DAG.
This application involves four tasks called t1, t2, t3 and t4, the execution timed of which are 3, 10, 3 and 4 time units with four communication links called d12, d13, d24 and d34, the communication times of which are 10, 4, 7 and 5, respectively.
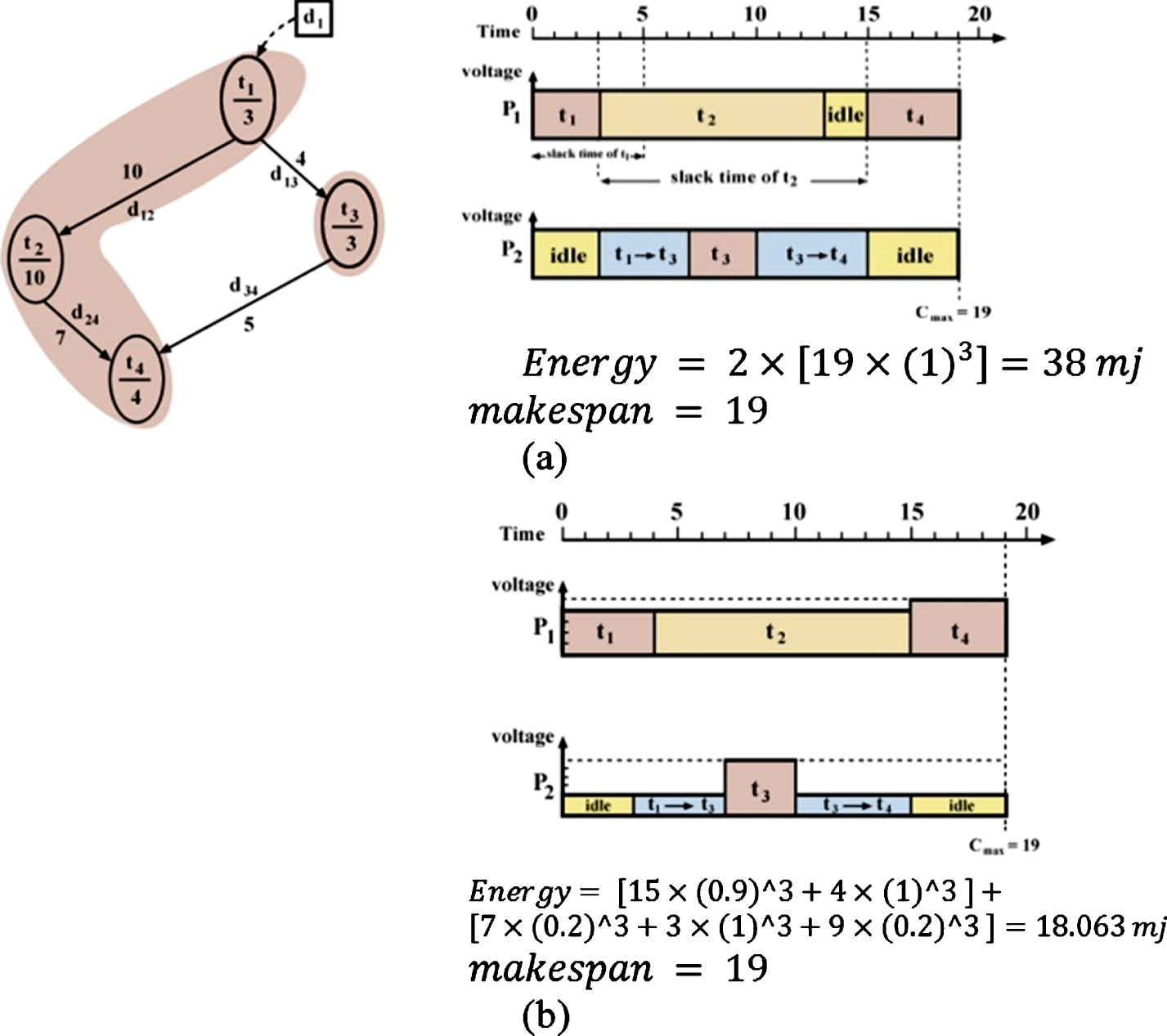
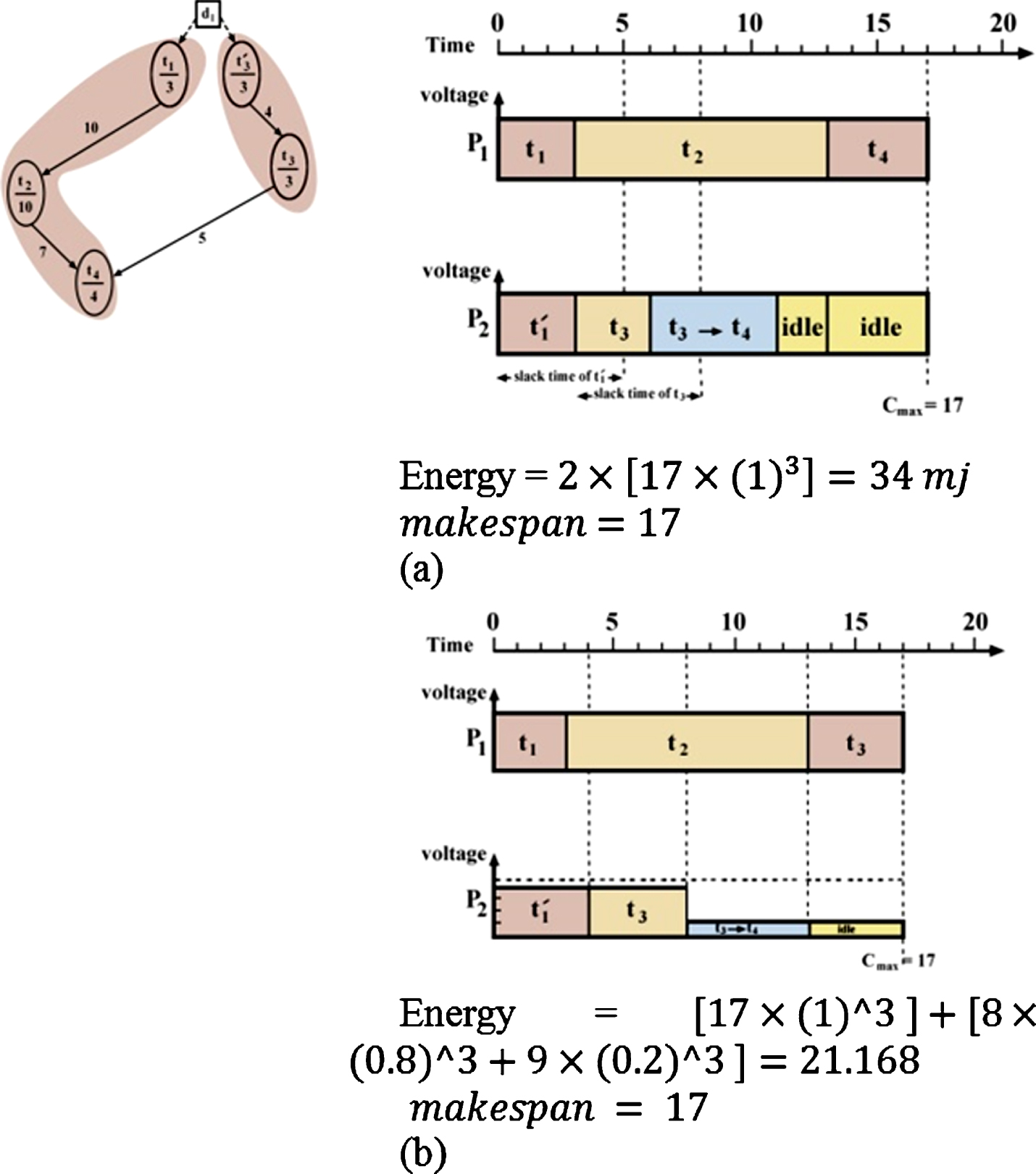
Figure 1 illustrates an example of processor allocation, and the values of makespan, throughput and energy consumption, without using duplication, clustering and DVFS technique. Figure 2 provides a DAG example using clustering and DVFS technique, while Fig. 3 displays a DAG example using clustering, duplication and DVFS technique. A DAG scheduling example without using clustering, duplication and DVFS. (a) Gantt chart for P1 and P2 after clustering, (b) Energy Gantt chart after stack time distribution (employ DVFS). (a) Gantt chart for p1 and p2 after duplication & clustering, (b) Energy Gantt chart after stack time distribution (employ DVFS).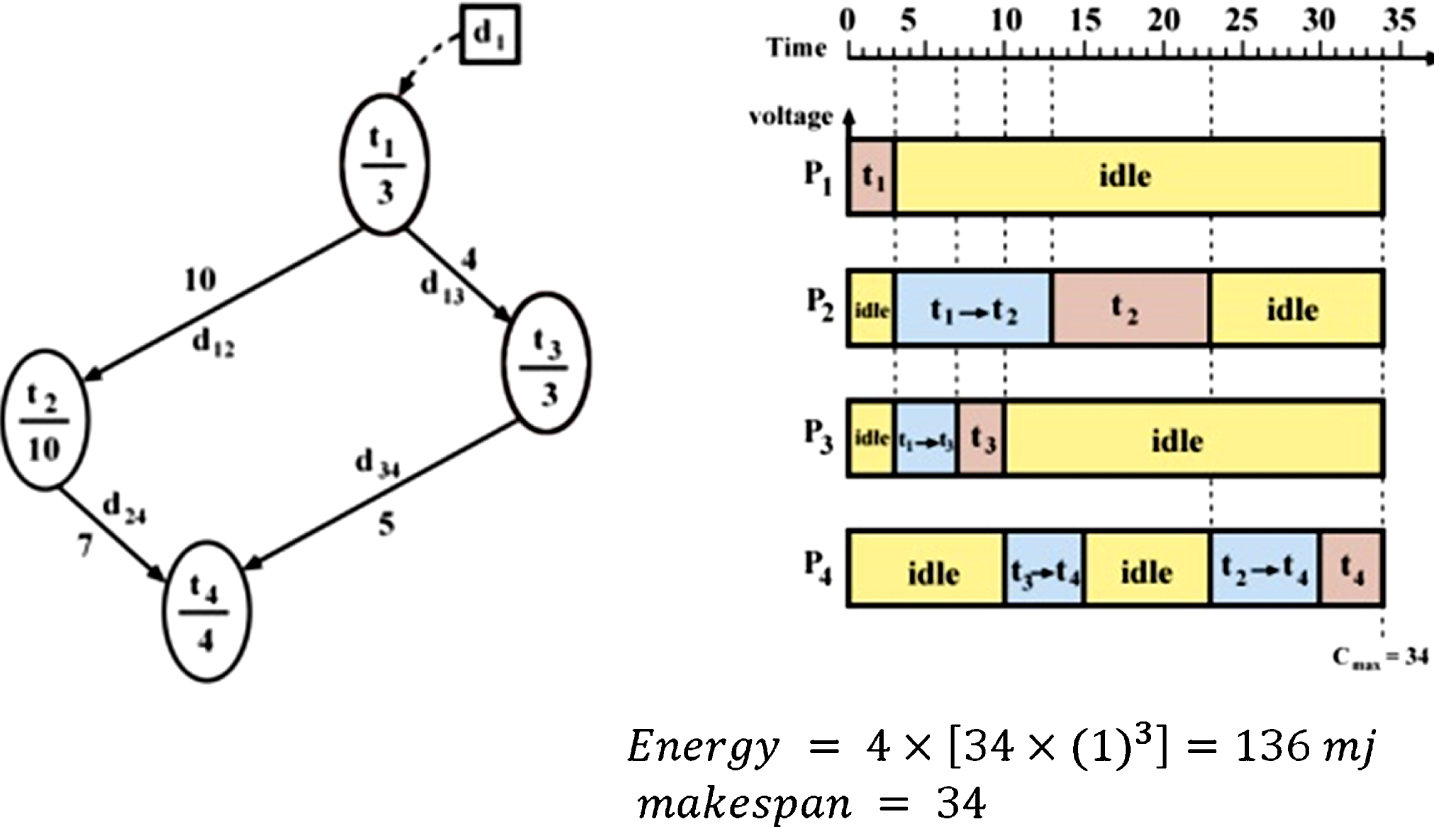
Task clustering is a technique to minimize and eliminate the expensive communication cost during data transfer between tasks through tasks allocation to same processors. In practice, cluster refers to a set of tasks executed on an identical processor. Applied correctly, this technique can mitigate makespan and energy consumption, maximize throughput and minimize the number of active processors for task scheduling [50].
Task duplication is a technique that causes to prevent the communication cost between processors assigned to the tasks, which are in communication, by creating data locality. The data locality is generated by replicating and copy of specific tasks on multiple processors. In fact, this technique prevents data transfer between predecessor and successor, thereby to reduce communication costs. This technique can be far more effective in reduction of makespan and energy consumption for DAG with greater CCRs [6, 9–13].
DVFS technique, modern processors are equipped with dynamic voltage frequency scaling (DVFS) technique, which reduces energy consumption by switching between processor‘s voltage and frequency pairs to execute tasks during slack times and idle or communication phases [14]. The processor dispatch strategy of tasks is assumed to allocate each cluster on an independent processor.
As can be seen in Fig. 2, t1 has been clustered with t2 and t4 so as to avoid their expensive communication link. This in turn mitigates energy consumption and makespan, while enhancing throughput. Duplication can reduce communication costs by allocating the copies of tasks to extra processors. Figure 3 shows that t1 is duplicated and simultaneously allocated to two processors. This can hide the communication cost of d13. Compared to clustering, the combination of duplication and clustering techniques has delivered better results. After applying the clustering and duplication techniques on the primary DAG sample, the results of the two strategies can be seen in Figs. 2 and 3, where DVFS should be adopted. To that end, the critical path was first determined and slack times of non-critical paths were calculated. Then, the idle and communication phases were specified by reducing the voltage and frequency of processors through the DVFS technique, which significantly reduces energy consumption. Given the fact that dynamic power consumption of processors has been calculated by Equation P = ACv2f, and the values of A and C are constant for each processor in addition to vαf consequently Pαf3. Given that = P × t, therefore Enαf3 × t will be true [29]. At this stage, we can calculate the amount of energy consumed by processors by executing the given graph sample.
The rest of the paper has been organized as follows. In Section 2, we present the related work and the current state-of-the-art in energy-aware scheduling based on DVFS and duplication technique. System model including an architecture model, parallel task model, resource model, DVFS model and the multi-objective estimation model are illustrated in Section 3. In Section 4, we introduce our new EATSDCD algorithm for solving the problem. This algorithm includes two phases called EATSDC and EADVFSA. The time complexity analysis for the proposed algorithm and the tracing EATSDCD algorithm on given DAG are presented in Sections 5 and 6, respectively. Section 7 explores the performance constraint setting, randomly generated DAG and experimental results compared with other algorithms. Finally, Section 8 concludes this paper and plans for future work.
Traditional algorithms mainly focused on scheduling of precedence-constrained parallel applications on distributed platforms such as clusters, grids, and clouds, minimizing the total completion time or makespan without worrying about the energy consumed in datacenters [15, 16]. As the Information and Communication Technology (ICT) has developed over the last few years, there have been a growing number of datacenters and accordingly a dramatic increase in energy consumption. This has subsequently left negative impact on the environment through generation of greenhouse gases and excessive emission of CO2 [49]. In recent years, great efforts have been made to mitigate the energy consumed by processors at datacenters using 1) DVFS techniques [17–21, 53], 2) changing the scheduling policies for allocating tasks on available processors [21], 3) dynamic power management (DPM) [22], 4) Working Vacation [23–25] and 5) redesign of algorithms using energy-efficient pattern in compilers [26]. These efforts have replied on several design patterns such as clustering and duplication. This section will discuss relevant studies previously conducted on a few conventional techniques.
Energy reduction based on DVFS technique
Dynamic voltage and frequency scaling (DVFS) has been recognized as an effective technique to reduce energy consumption of processors through simultaneous minimization of frequency and supply voltage for slack time slot of tasks as well as communication and idle phases.
The authors in [20] employed an energy-aware scheduling heuristic algorithm called PALS and PATC to simultaneously reduce makespan and energy consumption for scheduling parallel tasks in a cluster through DVFS technique. After determining the critical path and non-critical paths, the proposed algorithm assigns jobs in the critical paths to processors with the highest voltage/frequency. Then, the slack time of each jobs is calculated in the non-critical paths, and the voltage/frequency of the assigned processors is scaled down to process the non-critical jobs. This strategy mitigates energy consumption without increasing makespan. By negotiating with users, based on the Green service-level agreement (SLA) negotiation, a compromise is made between further reducing energy consumption and thus increasing makespan. Another approach to scheduling tasks has been proposed to reduce energy consumption using the DVFS technique [27]. This technique has been adopted to dynamically control the frequency and voltage of cloud computing servers.
The scheduling algorithm takes into account the maximum job (Fmax) and minimum job (Fmin) frequencies given to each job and multiple server Si running at maximum Si (Fmax) and minimum Si (Fmin) frequencies. For specific jobs, the scheduling algorithm efficiently assigns proper servers that run between (Fmin, Fmax) to jobs according to requirements of job frequencies.
Juarez et al. [26] proposed a real-time dynamic scheduling method called Multi-heuristic Resource Allocation (MHRA) for efficient execution of task-based applications on a distributed computing platform of cloud computing. This served to mitigate energy consumption and makespan. This method involved a polynomial time algorithm combining a set of heuristic rules and resource allocation techniques. In order to balance the two-objective function, a weight factor was introduced α 0 ≤ α ≤ 1, by which the user can specify the significance of each objective.
Yikun Hu et al. [19] developed an algorithm called Energy Aware Service Level Agreement (EASLA) for scheduling parallel applications through DVFS technique, while maintaining the SLA on a cluster platform.
The main idea behind EASLA algorithm is to allocate each slack to a maximum set of independent tasks for each task using a compatible task matrix and scale frequencies down to minimize energy consumption within certain extension rate of makespan mutually accepted by user and service provider.
Furthermore, Mezmaz M et al proposed a hybrid, parallel, multi-objective genetic algorithm to solve the problem of scheduling parallel precedence-constrained applications in an effort to simultaneously mitigate the overall execution time of tasks and energy consumed in cloud computing. The energy storage involved DVFS, where each processor can operate at different clock frequencies. This approach has been evaluated with the Earliest Finish Time (FFT) task graph, which is a real-world application [3].
Cloud computing offers utility-oriented IT services to consumers based on pay-as-you-go model. This model involves a payment method for services charging based on usage only for resources needed [47].
Datacenters have extensively grown to provide service to clients globally. Hence, the datacenter hosts consume a huge amount of power for Infrastructure as a Service (IaaS), Software as a service (SaaS), Platform as a Service (Paas) applications. This consequently leaves an adverse impact on the natural environment. Beloglazov A et al. proposed an architectural framework for energy-aware, heuristic allocation of data center resources to consumer applications, while considering the quality of services (QOS) and power usage characteristics of the devices [28].
Reducing energy consumption in an idle servers and running a server with CPU utilization controlled by DVFS techniques, and authors’ approach has been evaluated through CloudSim toolkit.
The authors in [29] proposed a new task slack time algorithm for task scheduling in distributed computing systems using DVFS technique.
In [30], a scheduling algorithm called Energy Aware DAG Scheduling (EADAGS) was developed on heterogeneous distributed processor system using dynamic voltage scaling (DVS) with decisive path scheduling (DPS) to achieve minimal finish time and energy consumption.
In [53], the problem of scheduling precedence-constrained parallel applications on multiprocessor system was proposed to increase throughput and minimize energy consumption by dynamic voltage scaling.
H.K Imura et al. [31] introduced an algorithm reclaims slack time, where slack time in parallel applications was executed on a power-scalable cluster computing using DVFS. Moreover, the newly proposed method was evaluated by a toolkit called Powerwat, which includes a monitoring and control tool.
Ding et al. [14] proposed an energy consumption optimization algorithm known as Energy Efficient virtual machines scheduling (EEVS) for scheduling of virtual machines given the deadline constraint using DVFS.
Shu et al. have offered other examples of how to optimize resource allocation using an improved clonal selection algorithm with bi-objective criteria in cloud computing. The authors proposed an improved clonal selection algorithm (ICSA) based on makespan optimization and improvement of energy efficiency in datacenters, capable of effectively meeting the SLA requested by consumers [55].
Energy reduction based on scheduling policy and duplicate technique
Previous studies on task duplication technique
Previous studies on task duplication technique
In this section, formal definition for system architecture model, parallel task model, DVFS model, resource model, energy consumption model in processors as well as interconnections, performance model under some assumption and restrictions, which are employed in problem formulation has been proposed. Table 2 summarizes the notations used in this paper.
Definition of notations
Definition of notations
This section introduces our proposed architecture model for the parallel task scheduling environment on cloud datacenters. The architecture model illustrated in Fig. 4 comprises three layers each including different sections.
Comprises three layers each including different sections.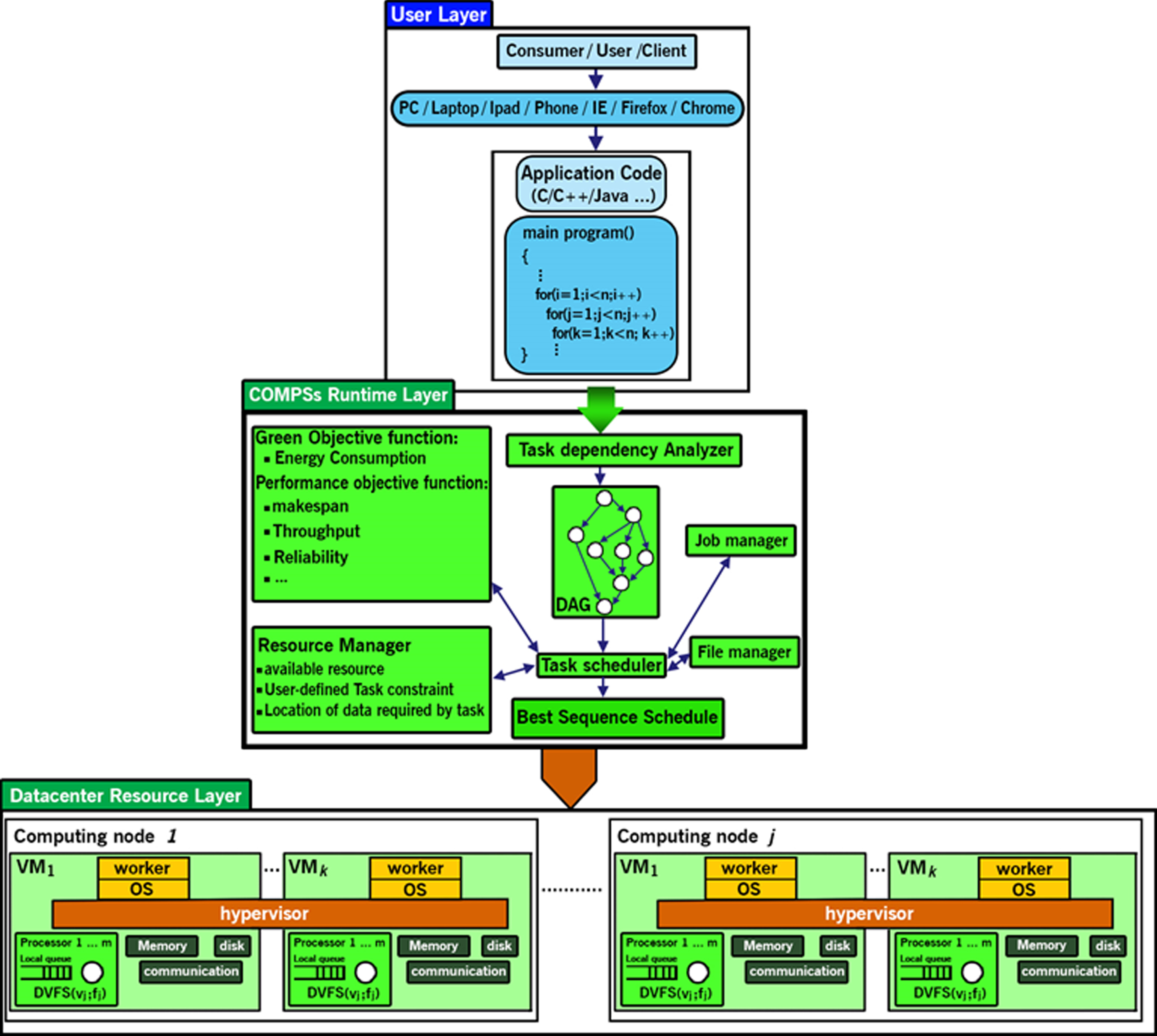
COMP Superscalar (COMPSs) layer is a framework aiming to ease the development and execution of task-based applications for distributed infrastructure, such as clusters, grids and clouds, and a runtime system which manages several execution aspects of applications. Besides, it keeps the underlying infrastructure transport to the application [26].
Datacenter resource layer
This layer contains several computational nodes, each including multiple virtual machines. Each virtual machine includes multiple processors, disks, memories, and communication networks. Processors are DVFS-enabled and are assigned to execute tasks.
Parallel task model
The sequential program sent by the user to COMPSs is converted into DAG by the task dependency analyzer component. The created DAG, called task dependency graph, is displayed as G (T, D), where: T: consists of a set of tasks in G, which can be represented by Equation 1. All tasks ∀t
i
∈ T are the components of the application code (nodes in a DAG). These tasks are scheduled to run over different processors in the systems.
Where
t
i
is a task ith in DAG. n is the total number of tasks. w
i
is weight on task, t
i
represents the instruction number of task t
i
.
et (t
i
, p
j
) is execution/computation time of task t
i
on processor p
j
, which is indivisible and its execution cannot be interrupted. The task execution time t
i
is calculated as indicated on Equation 2.
CPI denotes the number of clock cycle per instruction for a task by processor. The ideal CPI is 1.
ct (d
ij
) is communication time/cost of an edge d
ij
, for transfer message d
ij
, this time/cost is incurred if t
i
and t
j
are scheduled on different processors and is considered to be zero if t
i
and t
j
are scheduled on the same processor.
We model the cloud datacenter resource layer as CDR = {j, k, m, l}, where:
j represents the set of computational nodes, while there is a |j| computing node in CDR
k represents the set of virtual machines, while there is a |k| virtual machine in each computing node. m represents the set of processors, while there is a |m| processor in each virtual machine. The resource layer consists of multiple computing nodes CN = {cn1, cn2, …, cn
j
}, where node j represented by cn
j
, each computing node cn
j
consists of a set of virtual machines V
j
= {Vj1, Vj2, …, V
jk
}, where virtual machine k of computing node j is represented by V
jk
. Each virtual machine V
jk
has a set of processors C
jkm
= {Cjk1, Cjk2, …, C
jkm
}. l; all computing nodes, virtual machines and processors are fully interconnected with the same communication link l.
DVFS model
Nowadays, DVFS-enabled processors are employed to mitigate energy consumption in HPC systems [42].
DVFS-enabled processors can execute tasks during slack times as well as idle and communication phases using a discrete set of voltage and frequency pairs, (v
i
f
j
). Assume that each processor has k DVFS levels in other words k processing operating points. Hence, supply voltage and frequency processor j can be described by Equation 4.
Where (v kj , f kj ) is the voltage and frequency for processor j at level k.
Furthermore, the execution time of task t
i
on processor p
j
with the set of working frequencies from f1j to f
kj
can be calculated through Equation 5. In fact, the greater the frequency level the shorter the execution time.
In this section, a few models are adopted by evaluation of DAGs at different sizes to estimate throughput, makespan and energy consumption.
Makespan estimation
Makespan (Cmax) is defined as the amount of time, from start to end for completing a set of sequences. The best effort in a scheduling algorithm is to minimize the maximum completion time (makespan). Equation 6 describes how the makespan of a DAG is calculated
Critical Path (CP) of a DAG is the longest path from the entry node to the exit node in the graph. The lower bound of a schedule length is the minimum critical path length (CPMIN). If any task on the critical path is late, the tasks scheduling in graph is late. Since the number of processing sources for tasks execution is unlimited, Cmax can be considered equal to the length of critical path for G graph.
The proposed model for evaluation of throughput has been adopted from [41]. It is essential to include communication rate (CommR(G)) and computation rate (CompR(G)) for the given DAG, G.
Since all tasks in a cluster such as C
i
should be executed on one processor, the data elements are processed sequentially. The computation rate for cluster C
i
is equal to
Moreover, the communication rate for each edge d
ij
is equal to
Since the computation and communication for different processors can be carried out simultaneously, the overall throughout can be calculated through Equation 10.
The energy consumed for scheduling of dependent tasks in computational systems is equal to total computation energy of processors for task execution as well as energy consumed to transfer data between processors across communication networks.
Computation energy
Nowadays, most processors are constructed using CMOS circuits. In such processors, power consumption is divided into two parts (dynamic power consumption and static power consumption) which are obtained through Equation 11.
Static power consumption, i.e. the main source of static current, is leakage current and reverse based PN junction when there is no circuit activity, whereas dynamic power consumption involves charging and discharging of capacitances when inputs are active [20, 32].
Given that the total energy consumed to execute parallel tasks involves computation energy by processors and communication energy between processors, the static part of power consumption can be ignored.
The dynamic power consumption of processors can be calculated through Equation 12 [52].
Where A is the percentage of active logic gates, C is the effective load capacitance, v is the supply voltage and f is the frequency of processor.
Given that modern processors are equipped with DVFS technology, the maximum power consumption of processor Pproc.highest occurs when it operates at maximum voltage v
highest
and frequency f
highest
. Therefore, it can be concluded that the active power consumption for a processor under the voltage and frequency set (v
j
, f
j
) is calculated through Equation 13.
Since the proposed algorithm adopts the task duplication strategy for scheduling a DAG with n tasks on DVFS-enabled processors, the total energy consumption can be calculated through Equation 14.
When there are no processing and execution tasks, processors switch to idle mode, where the energy consumed by processors is calculated by Equation 15. Where m is the total number of processors, makespan is the maximum time for completion of tasks by processors, also known as scheduling length.
Finally, the total energy consumed by processors to execute the task dependency graph can be obtained through sum of Equations 14 and 15.
Since the processors in each datacenter have been assumed to be homogeneous, the data transfer speed and power consumption are identical.
The communication energy consumed by edge d
ij
∈ D can be denoted as ec
ij
, where PC is the power of interconnect. ec
ij
is calculated through Equation 17.
Therefore, the total communication energy for the entire network can be calculated through Equation 18.
In Equation 18, element x
i
j is expressed by Equation 19 below:
Finally, the total energy consumed by cloud datacenters can be obtained through sum of Equations 16 and 18.
This section describes the proposed algorithm (EATSDCD) for scheduling dependent tasks, in order to mitigate energy consumption under throughput and makespan constraints. Based on the performance and energy models shown in Section 3, we can demonstrate the effects of combined duplication and clustering strategy together with the DVFS technique to achieve the stated objectives. The new algorithm consists of two phases namely EATSDC and EADVFSA.
In the first phase, a schedule serves to reduce communication energy and increase throughput. It is obtained through the energy-aware task duplication-clustering algorithm (EATDC). The second phase focuses on implementation of DVFS technique for each processor to decrease computation energy consumption of DAG, using the energy-aware dynamic voltage/frequency scaling algorithm (EADVFSA). The following sub-section describes both phases in greater details.
Energy-Aware Task Duplication-Clustering Algorithm (EATSDC)
Energy - Aware Task Scheduling with Duplication - Clustering Algorithm (EATSDC)
Energy - Aware Task Scheduling with Duplication - Clustering Algorithm (EATSDC)
Given that one of the scheduling objectives is to reduce makespan, task scheduling based on descending order of their b-level can lead to earlier scheduling of tasks on a critical path.
In fact, b-level is a priority assigned to each task. The b-level of task ti is the length of longest path from ti to an exit node. The b-level of a task is bounded from above by the length of a critical path. b-level is calculated through Algorithm 2.
Computation of b - level
Computation of b - level
After applying the duplication and clustering strategy on the input graph, which leads to lower energy consumption and makespan, and also higher throughput, we intend to further mitigate the energy consumed by processors by determining the critical path and non-critical paths. We also specify the slack time of non-critical tasks, and calculate the voltage and frequency of processors assigned to processing of tasks in non-critical paths as well as idle and communication phases through scaling down DVFS. For this reason, it is essential to first explore the important parameters used in applying DVFS techniques to reduce energy consumption. These parameters have been listed in Table 3.
Important parameters used in DVFS technique
Important parameters used in DVFS technique
The parameters in Table 3 are used to calculate the slack time of tasks and determine the critical path. Calculation of Earliest Start Time (EST) is a top-down method, which starts with the first task and ends with the last task, calculated by Equation 21.
After calculating EST, the Earliest Finish Time (EFT) can be calculated for task t
i
by Equation 22.
Moreover, the calculation of Last Finish Time (LFT) is a bottom-up method, which starts with the last task and ends with the first task, calculated by Equation 23.
The Latest Start Time (LST) for task t
i
is also calculated by Equation 24.
Critical path is the longest path through a DAG from entry task to exit task. It consists of the set of tasks that, if delayed in any way, would cause a delay in completion of the all tasks. The tasks, whose LST is equal to their EST, make up the critical path (or, equivalently, whose LFT is equal to their EFT).
Calculating the slack time of tasks
The non-critical tasks in a DAG are distinguished by the presence of slack. Slack is the amount of time by which the start of an activity can be delayed without delaying the makespan. Critical tasks have zero slack, while non-critical tasks have slack value, This is known as slack time. For each task ith, slack time is calculated through Equation 25.
The pseudo-code of calculating slack time, critical and non-critical path have been described in Algorithm 3.
Calculate Slack time & Critical Path
This section shows how to employ the DVFS technique to scale down the voltage/frequency of processors assigned to non-critical tasks, reduce the idle and communication phases, and scale up the voltage/frequency of processors assigned to critical tasks, thereby to mitigate energy consumption.
The critical path (CP) of scheduled task graph in a Gantt chart is a set of time slots of task execution and data communication from the first task to the last task, of which the sum of computation time and communication time is the makespan. Assuming that The CP is t1 - t3 - t5 - t6, the best-effort scheduling algorithm does not extend the makespan, the voltage/frequency of processors during the time slots of task execution in the CP is not changed. Voltage and frequency of other time slots in a Gantt chart are considered to be scaled down.
voltage/frequency scaling
Given that the input of the proposed algorithms is DAG (T, D), in which |T| and |D| represent the number of tasks and edges, respectively, we want to analyze the time complexity of algorithms presented in the previous sections.
Analysis of EATSDC
Algorithm 1
This algorithm executes the clustering and duplication strategies on the input graph. Lines 3 and 4 require |T|, while Lines 5 to 8 require |D| operation times to calculate CompR(G) and CommR(G). Sorting in Line 9 can be done at time |D| log |D| based on quick sort. Lines 10 to 16 require 2 × (|T| + |D|) 2 operations, calculation of CP in Line 17 requires (|T| + |D|) 2 operations, and Lines 19 to 25 require |D|2 operations to satisfy the energy consumption. Moreover, the calculation of b-level for all tasks in the integrated cluster requires (|T| + |D| + |D|) operations. As a result, the time complexity of EATDCA is equal to O (|D| × (|T| + |D|) 2).
Algorithm 2
This algorithm computes the b-level for tasks. The construct RevTopList of Line 2 can be done in o (|T| + |D|) time. Lines 3 and 5 are a double-loop.
Given that the number of iterations in the two loops is equal to the number of children of each node to which they are connected, the total duplications of Lines 3-11 is |D| times. Therefore, the total number of iterations of the algorithm is equal to (|T| + |D| + |D|), with time complexity of 0 (|T| + |D|).
Analysis of EADVFSA
Algorithm 3
This algorithm computes the slack time for task and then produces a CP. The sorting of Line 2 can be done in |T| log |T| time using quick sort. Assuming task has k successors or predecessors, Lines 3–5 occur k|T| times. Lines 6–12 compute the slack time for each task in the DAG, determine CP, and execute |T| times. Thus, the total number of iterations is equal to (|T| log |T| + k|T| + |T|) and the complexity for algorithm 3 is O (|T| log |T|).
Algorithm 4
This algorithm scales the frequency of processors. Assuming each virtual machine has |m| processors, with s time slots, Line 2 and 3 are double-loop. Hence, the complexity of Algorithm 4 is O (s|m|).
Performance analysis with simulation
This section presents the experiments carried out to evaluate the proposed heuristic algorithm, Energy-Aware Task Scheduling with Duplication Clustering Dynamic voltage/frequency Algorithm (EATSDCD) and compare EATSDCD against previous work, namely power aware task clustering (PATC) [20], power aware list-based scheduling (PALS) [20], Energy Aware Duplication Scheduling (EADUS) & TEBUS [44] with objective energy saving, RASD [33], Heterogeneous Earliest Finish Time (HEFT) [51] with objective execution time and PaPilo [41], Throughput Constrained Latency Optimization heuristic (TCLO) & Throughput Constrained Latency Optimization Pipelined (TCLO-P) [8] in homogeneous and heterogeneous environments while considering energy consumption and throughput.
Energy, throughput and makespan constraint settings
The solution described in the proposed method for best-effort scheduling optimizes energy consumption while meeting makespan and throughput requirements. We define lower bound of the energy constraint denoted as Enmin and upper bound of throughput constraint, denoted as Thmax and lower bound of the makespan or critical path, denoted as CPmin.
The minimum consumed energy by processors to execute tasks occurs when the communication cost is excluded and no duplication takes place (numr(t i ) = 1). To that end, it is essential to execute all tasks on a single processor.
Therefore, the minimum energy consumption can be calculated as shown in Equation 27.
Moreover, the maximum throughput is achieved when we have |m| processors in the system as indicated by Equation 28.
The minimum makespan or critical path, denoted as CPmin (G), is achieved by clustering all tasks on one processor.
This discard the communication time and achieves the makespan constraint, as represented in Equation 29.
Since it is impossible to simultaneously obtain the minimum energy consumption and maximum throughput, it is crucial to consider a coefficient for Enmin (G) and Thmax (G).
For that purpose, three energy constraints Enmin (G) are set: 1.2Enmin (G), 1.5Enmin (G) and 2.0Enmin (G) and three throughput constraints Thmax (G).
In this paper, we first considered the randomly generated application task graph. Currently, there are many random graph generator tools to generate weighted application DAG, such as STG (standard task graph) [45]. STG is a kind of benchmark for evaluation of proposed scheduling algorithms. Three fundamental characteristics of the DAG are considered: DAG size, (n): The number of tasks in DAG. Communication-to-Computation Ratio, (CCR): it is the ratio between average communication time to the average computation time of the application DAG. Equation 30 describes how the CCR of a DAG is calculated.
Parallelism factor, (λ): the number of levels of the application DAG.
In our simulation experiments, the DAG sizes vary between 40 to 1000, in steps of 40, with random node and edge weights. CCR was varied as 0.1, 1 and 10. The number of levels is determined by λ, which varied as 0.5, 1.0, 2.0 and 5.0. in total about 200 graphs were generated for evaluation of the proposed method with other algorithms.
Power consumption for different voltage/frequency of processors [34]
Power consumption for different voltage/frequency of processors [34]
Firstly, we compare the proposed EATSDCD against the other four algorithms namely PALC, PATC, EADUS & TEBUS. According to the simulation results, the parameters of DAG size and CCR can greatly affect the extent of energy saving.
Comparison of energy-saving between our proposed EATSDCD and the other four algorithms
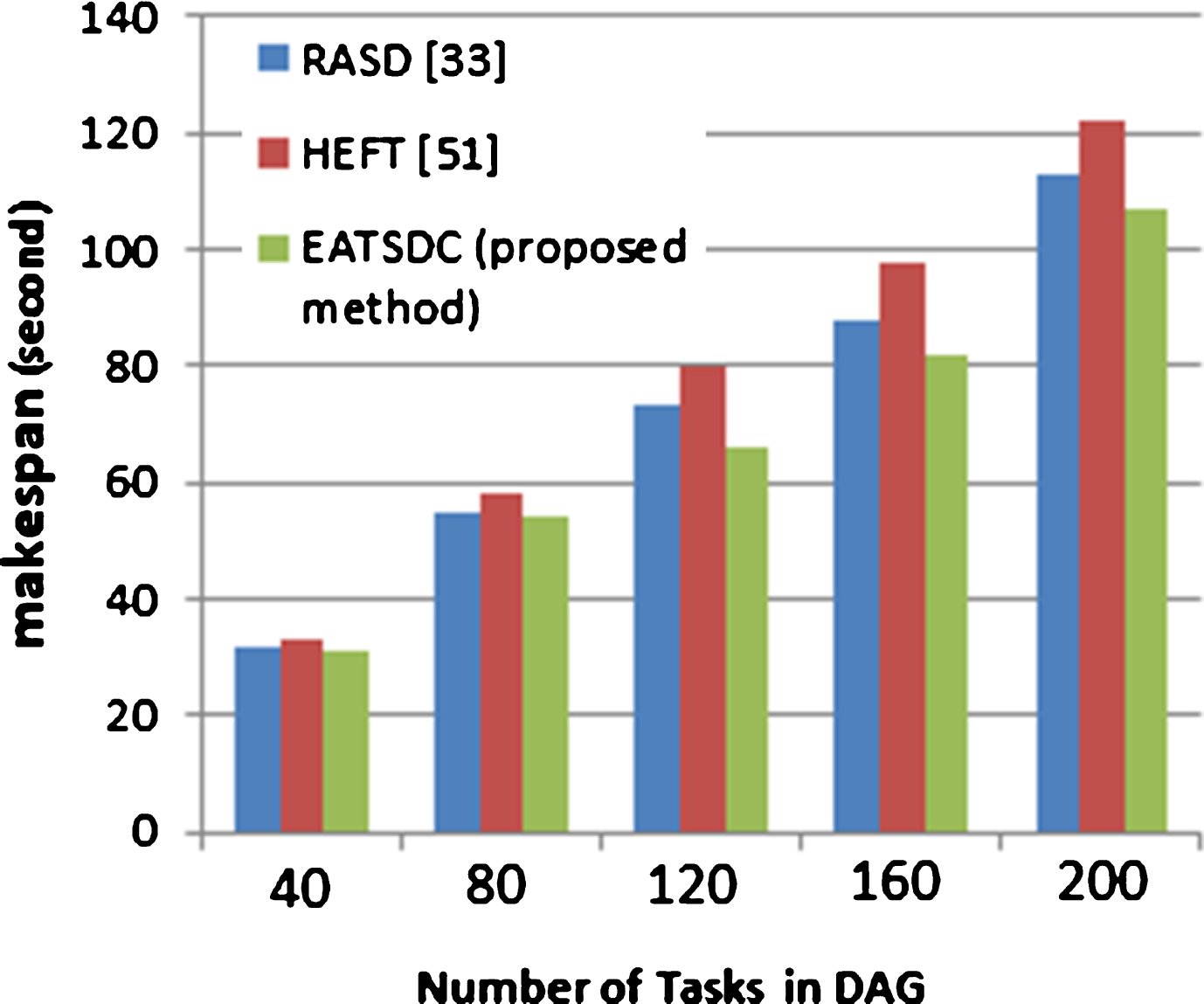
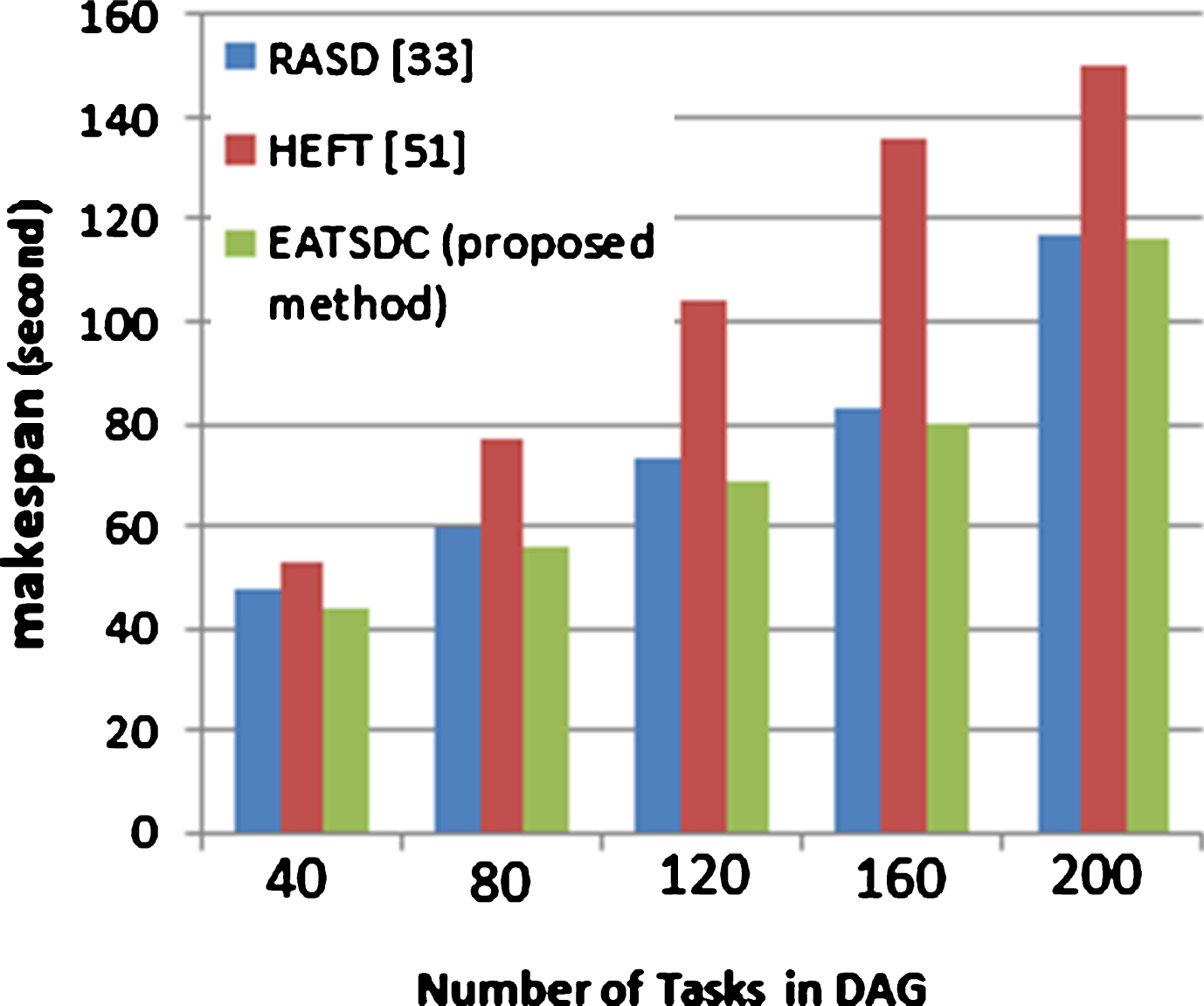
The second set of simulation is to compare the proposed EATSDC algorithm against the other three algorithms namely RASD [33], HEFT [51]. According to the simulation results, Figs. 5–7 show the makespan of the EATSDC varies with respect to the DAG size (40, 80, 120, 160, 200) and the CCR size (0.1, 1, 5).
Comparison of makespan between EATSDC and RASD, HEFT for CCR = 0.1. Comparison of makespan between EATSDC and RASD, HEFT for CCR = 1. Comparison of makespan between EATSDC and RASD, HEFT for CCR = 5.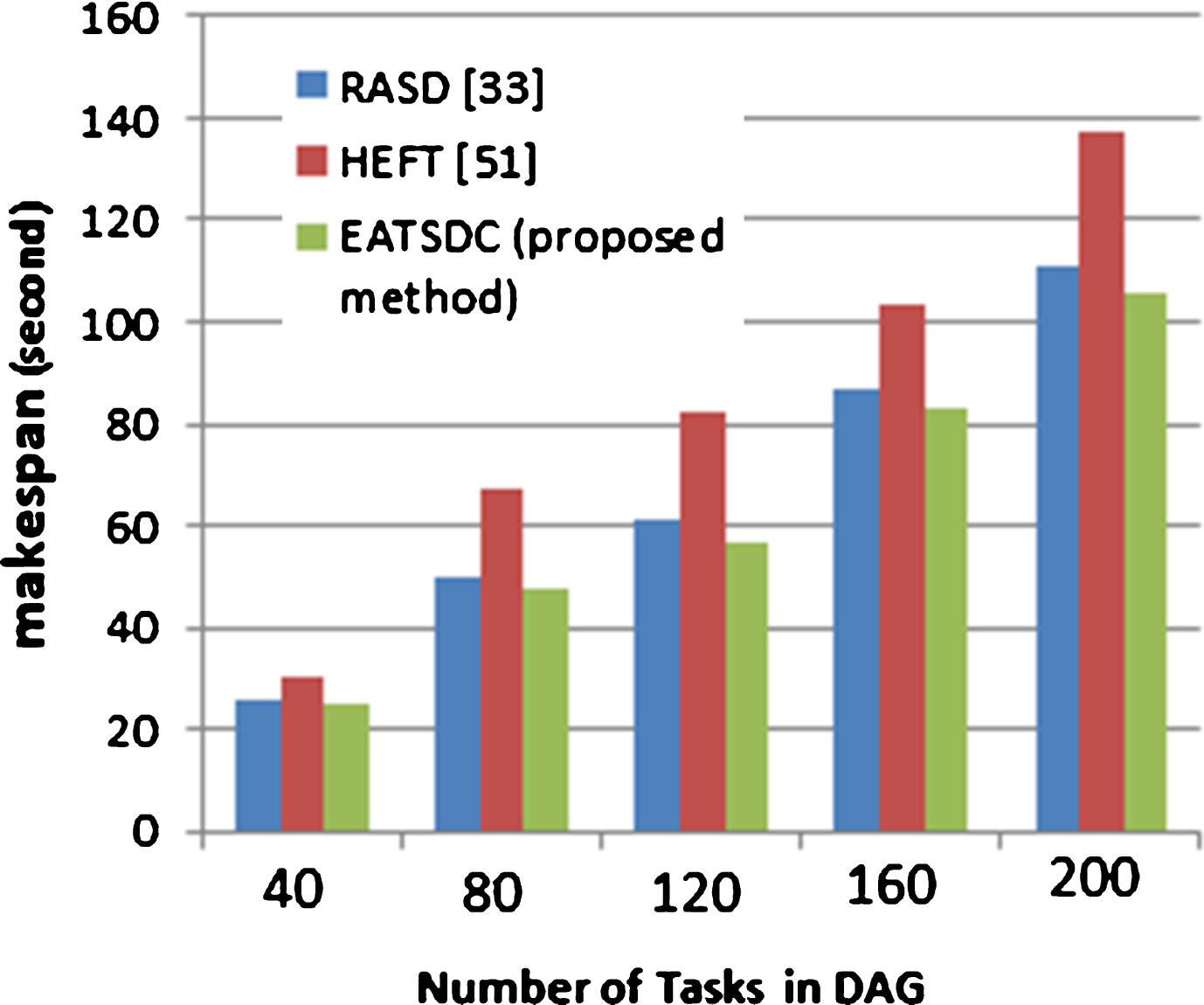
The third set of simulation shows the performance of the EATSDCD algorithm with CCR = 1 and throughput set to 0.25Thmax (G), 0.5Thmax (G) and 0.75Thmax (G). against previously proposed schemes: PaPilo [41], TCLO & TCLO-P [8].
Number of feasible solutions for 100-node random task graph, with different Energy and throughput constraints, for CCR = 1
Meanwhile, as the energy constraints changed to Encur = 1.2 Enmin (G) at the same throughput constraints, only EATSDCD achieved the specified constraint in all 200 sample graphs. The objectives were realized because after applying the duplication and clustering technique on the input graph samples and calculation of slack time for all tasks, the DVFS technique was adopted to mitigate the voltage and frequency of processors assigned to process non-critical tasks as well as idle and communication phases. This in turn minimized the energy consumption and thus fulfilled the specified constraints.
The results of simulation indicated that the newly proposed algorithm can save greater energy than other algorithms for the following reasons. EATSDCD uses task duplication and clustering to reduce the necessary communication between processors. EATSDCD reduce the energy consumption during the communication phase. EATSDCD reduce energy consumption when processors are idle. EATSDCD employs the DVFS technique to extend the task slack time.
In this paper, we proposed a novel green energy-aware scheduling algorithm, called Energy Aware Task Duplication Clustering Dynamic voltage/frequency scaling (EATSDCD). It employs the clustering & duplication technique on homogeneous/heterogeneous DVFS-enabled cloud datacenter processors. EATSDCD can be applied to application DAGs such as STG so as to optimize energy efficiency at the premise of meeting the throughput and makespan constraints. In the first phase, a schedule serves to reduce communication energy and increase throughput. It is obtained through the energy-aware task duplication-clustering algorithm (EATDCA). The second phase focuses on implement ion of DVFS technique for each processor that can scale down clock frequency and supply voltage whenever tasks have slack time and during idle and communication time slots to decrease energy consumption of DAG, using the Energy-Aware Dynamic voltage/frequency scaling Algorithm (EADVFSA).
testbed is developed and different parameters are tested on the randomly generated DAG to evaluate and illustrate the superiority and effectiveness of EATSDCD. It was also compared against duplication and clustering-based algorithms and DVFS-based algorithms. In terms of energy consumption and makespan, the results show that our proposed algorithm can save up to 8.3% and 20% energy compared against PALS [20] and PATC [20] algorithms without performance loss, respectively. Furthermore, there is 16% improvement over PaPilo [41] algorithm with Encur = 1.2Enmin (G). In comparison with RASD [33] and HEFT [51] algorithm, the execution time has been reduced in heterogeneous environments.
The future works can be divided into three areas. Firstly, the user and service provider initiate negotiations to reach a green SLA concerning the makespan extension rate. An agreement on η rate (makespan ≤(1+ η) × makespan best) will achieve the service quality parameters and minimize energy saving by up to 52.7% in the newly proposed method. Secondly, a few samples of real applications, such as MPEG-2 decoder [41], can be run through the new algorithm. Thirdly, a model can be proposed to mitigate energy consumption in task scheduling for other components such as disk, memory and network.
Footnotes
Acknowledgments
The authors would like to thank the anonymous reviewers and the editor for their insightful comments and suggestions.