
Abstract
This paper proposes a novel image processing method to extract the gender feature from frontal face combining Principal Component Analysis (PCA) and an improved Genetic Algorithm (GA) to reduce the interference of facial expression, lighting or wear. The collected facial images are first cropped and aligned automatically, then the gray-level information can be converted to feature vectors via PCA. After eigen-features are extracted with high classification performance by the aid of an improved GA, the neural network classifier can be trained accordingly. Compared to the classification methods based on global gray-level information, the obtained classifier has better identification rate but less used feature dimension, so the calculation load can substantially be reduced during training and classification procedures, which benefits to the development of a real-time identification system. Furthermore, FERET dataset and FEI dataset are used to validate the generality of the proposed method, where 94% and 96% accuracy rates of the gender recognition can be achieved respectively.
Keywords
Introduction
Gender recognition currently plays an important role in the video surveillance, human-machine interaction such kinds of monitoring systems. Along with the advent of the concept of big data, new technologies are more focused on the classification and arrangement such detailed information and feature of the detected targets, i.e., gender, age, interest. Moreover, gender is one of the most basic criteria to discriminate people, which has been studied for decades and applied in various recognition scenarios.
Gender recognition can be achieved via the measurement of people’s gait [1, 2], and specifically focused on clothing, posture or voice [3]. Facial feature can also be considered for classification, where the methods of gender recognition based on frontal face can be divided into two categories, geometry-based and appearance-based [4].
The geometry-based approach requires to extract various distances of feature points, for instance, the width and height of the face, eye distance, etc, which are used to form a feature dataset for further analysis. Viola Jones (VJ) algorithm is applied to crop eyes, nose and mouth from facial images [5], then the measured distances between eyebrow to eye, eyebrow to nose top, nose top to mouth, are input to the artificial neural network as feature vectors to be trained.
As for the appearance-based approach, each pixel value of the facial image is regarded as one input sample with equal weight in the classifier. Its recognition accuracy mainly depends on the preprocessing of the images and the chosen classifier. In [6], a three-layer neural network is used to identify sex from a group of 8 × 8 low resolution face images, which include neither the head hair nor the outline of the faces. [7] presented a comprehensive evaluation of various classification methods for determination of gender and found that a Gaussian kernel Support Vector Machines (SVM) can achieve the least error rate.
According to the recent literature review [8, 9], more and more research concerns to find features that represent gender and has the least correlation to other facial characteristics, such as race, color, expression, age, wearable. Such less useful information or disturbance should be rejected in order to enhance the calculation speed.
The combination of dual-directional dimension of Principal Component Analysis (PCA) and SVM could obtain a high performance [10]. A feature subset is extracted from the PCA eigen-vectors with Genetic Algorithm (GA), and applied to four classifier models for comparison [11]. A mixed features of the facial images were taken for analysis, including intensity, shape and texture, and a best classification rate of 99.13% was obtained on the FERET database which included 199 female and 212 male images, but a large number of selected features (18,900) were used in the experiments [12]. In [13], a fast gender classification method was developed using features selected from mouth and chin only, which could reduce the number of features and make the identification system simpler. The proposed method was tested on a small size dataset containing 75 male and 35 female face images with 94.34% accuracy.
The classification accuracy on the experimental database can not completely represent the quality of the method or used classifier. It is imperative to evaluate the feasibility of training classifier on a large-scale database, whether the time spent on the training or testing is acceptable. On the other hand, the adaptability of the gender recognition should be considered, in order to ensure the accuracy on general images collected in natural light conditions, different facial expressions, even for skewedheads.
This paper proposes a feature selection based method for gender recognition on facial images. Two standard databases and a group of web images are collected to verify its effectiveness. Firstly, Eigen-Features can be extracted from gray images via PCA and an improved GA. An efficient neural network classifier is then trained for the gender recognition. While applied to another dataset with simple projection, this obtained Eigen-Features are proved to possess highly flexibility and adaptability in the gender recognition.
The remainder of the paper is organized as follows. Section 2 introduces the sources of experimental data and the preprocessing method. Section 3 presents the procedure of feature selection. Experiments are performed to examine the performance of the proposed gender recognition algorithm in Section 4 and 5. Conclusions and future work are given in Section 6.
Data sources and preprocessing procedure
Data sources
In the paper, one standard data subset from the FERET database, FERETs, is applied which contains 1400 randomly selected frontal facial images, 700 for men and the other 700 for women [14]. The images have various facial conditions, i.e., some wearing glasses. The resolution of each image is 116 × 80 pixels, with 256 gray levels per pixel. The obtained dataset, FERETs, is used to develop a feature subset, and test the recognition rate for classifiers as well. In the experiments, 4/5 samples are used for training the classifier and the rest samples are used for verification.
Another dataset is FEI face data which is a Brazilian facial database [15]. There are two image groups, each containing 180 images with 90 images of male and 90 images of female. One group images are with non-smiling expression and the other group includes all kinds of smiling faces. The resolution of each image is 260 × 360 pixels with RGB color per pixel in JPEG format. This dataset is used to validate the adaptability of feature projection algorithm. In the experiments, 2/3 samples are used for training and the others are used for validation.
Besides the two standard datasets, a group of web face images are downloaded via a crawler tool [16]. Totally 100 adult facial images are selected randomly, 18% of which are in skew orientation. The resolution of each image is greater than 300 × 300 pixels (benefit to the face detection), with RGB color per pixel, in JPEG format. These samples are applied to verify the robustness of the proposed classifiers.
Image preprocessing
The initial acquired facial images have to be preprocessed for the facial feature extraction via squaring out from the forehead to the mouth with a subgraph acquirement. This subgraph is achieved by the VJ algorithm [17]. So the interference caused by hair, headwear and background can be avoided generally [18]. Furthermore, all the faces are aligned automatically via the image clipping, which is the premise for classifier training. Then each image resolution is compressed to 30 × 30 pixels for less calculation load without loss of generality and necessary information. Two random facial images in the FERET are selected and the results of the images preprocessing are illustrated in Table 1.
The preprocessing of facial images from FERET
The preprocessing of facial images from FERET

During the preprocessing, the general image dealt steps such as smoothing, sharpening, frequency domain transformation are unnecessary. Instead, feature selection is used to reduce the disturbance, i.e., lighting, color, and spots, which could decrease the calculation burden greatly. Some cropped faces in three datasets are randomly selected and illustrated in Fig. 1.

The cropped face in 3 datasets.
A method with the combination of PCA and GA to extract facial feature set for gender identification is described in this section. With the processed FERETs, firstly, the gray-level information of the images is converted to the feature vectors by PCA. Then an improved GA is proposed to extract a feature set with high classification performance, called Eigen-Features, together with redundant and noise elimination. Fig. 2 demonstrates the procedure of the feature selection.

The flow chart of the feature selection.
The image edge and facial features could be greatly influenced by the facial expressions, age or wear on the face [5, 19]. Moreover, it is difficult to detect the facial features (i.e., eye, nose, mouth, eyebrow) practically, which constrains the applications on the basis of such features. However, it is found that the feature vectors yielded by PCA involve abundant information in the experiments [11], which can be used for the purpose of gender recognition.
The module of feature vector extracted via PCA (see Fig. 2) is responsible for the data conversion. Its input is the gray-scale map with 30 × 30 pixels, and the output is the orthogonal feature vector with 900 dimension. The processing steps are illustrated as follows. Load the dataset (FERETs) containing 1120 training samples with the vector I
j
(p), where j ∈ [1, 1120], p ∈ [1, 900], and the mean face image M (p) can be calculated as,
The difference between the initial face image and the mean face image, D
j
(p), is defined as,
The eigen-vectors can be obtained from the covariance matrix C, [V, D] = eig (C), which returns a diagonal matrix D of the eigen-values and matrix V whose columns are the corresponding eigen-vectors, so as to hold the equation,
Load all samples from the FERETs with the sample vector S
k
(p), k ∈ [1, 1400], then the expectation difference SD
k
(p) is computed as,
All the face variations, SD
k
(p) are projected to the obtained eigen-vectors to acquire the feature vectors, called Eigen-Projects, EP
k
(p), with the size 1400 × 900,
So far the new feature set, Eigen-Projects EP k (p) have been obtained by PCA. However, the large eigen-values should not be used for gender classification directly which would result in low accuracy. Therefore, an improved GA is proposed for the gender feature selection in Eigen-Projects to extract optimal subset instead of sorting Eigen-Projects based on the whole eigen-values set.
Through feature selection, the dimension of the dealt data would be reduced greatly and the noise or disturbance is filtered accordingly while the useful information is preserved. However, if the optimal subset is extracted directly from the Eigen-Projects set, there are 2900 combination options to be compared. For such large-scale NP-Hard problem, both [11] and [20] used a canonical GA to search the expected feature set.
GA is one of the most popular searching heuristic algorithms that is capable of selecting the feature subset close to the optimum solution [21], in which the candidate solution is encoded in the chromosome with the form of binary genes. The searching procedure starts from a randomly initialized population formed by a certain number of individuals with different feature genes, then it carries out operations of selection, crossover and mutation on individuals to produce a new generation iteratively, so that the individual fitness can be optimized generation by generation.
In most cases of high dimensional feature space, GA is capable of finding a near-optimal solution, but it has limitations as well. Firstly, while a super individual arises in the early group, whose fitness is much better than the mean value of the current population, it will spread its chromosome rapidly among the population, which will lead to much similar individuals and steeply population diversity reduction. Thus the group would quickly lose the evolutionary capability but run into local minima, i.e., "premature" problem.
Secondly, in high-dimensional space, a stochastic mutation without guidance can not make obvious improvement for the solution due to different initial population and parameters (e.g. crossover probability). The third is the fitting deviation, in PCA based feature selection, the fitness of the individual is undermined and varied in certain range, here, evolutionary direction to the next generation could be misled by the pseudo elites.
Therefore, there is still improvement space for PCA based feature selection. An improved GA searching algorithm is then proposed, which can obtain optimal feature sets via the combination of current excellent individuals and best memorial individuals. The disadvantages of the GA can be compensated via mutation guidance approach so as to improve the solution accuracy effectively under the limited resources (time and computational load).
The parameters of the GA selector
The parameters of the GA selector
Initialize a population formed by NP individuals, each of which is represented by a gene sequence G (d). The number of genes (NG) is equal to the dimension of Eigen-Projects, here is 900, so each gene denotes selecting or discarding the corresponding PCA feature vector via binary value.
Compared with the population initialized randomly, those distributed uniformly in high-dimensional space will benefit to improve global searching performance [22]. A method for maximizing the dissimilarity of original individuals is applied here.
where i denotes the individual, d is the feature dimension, G i (d) is the gene code of the d feature in the i individual, F md is the difference maximization function on each gene.
Evaluate the fitness of each individual representing the error rate of the gender classification, the lower value is closer to the optimum solution. The fitting function used to calculate the error rate is implemented through SVM algorithm with randomly selected 4/5 of samples for training and the rest for validation via five-fold cross algorithm. Extract Eigen-Features, EF
k
(p), by feature genes in each individual sample,
4/5 of 1400 samples are randomly selected for SVM training, each of which consists of Eigen-Features. Then a SVM classifier is trained with the dot product as kernel function. The obtained SVM classifier is applied to predict the gender of the rest 1/5 of samples, i.e., 280 samples. The accuracy rate (AR) is achieved by comparing the predicted values with the actual ones. Then the fitness (F) of feature genes is achieved by F = 1.0 - AR.
Record the historical best gene sequence (P i ) for each individual, see Alg. 3.
The top
Crossover operation. Two individuals are selected randomly from the hybrid group (H i ) and their chromosomes crossover to produce new offsprings, see Alg. 5. The genomic hybridization among historical best and current population firstly helps to reserve excellent genes, which will lead the evolution in the right direction. On the other hand, the genes in current population possess diversity, which can avoid prematurity. With the proportion taken as 0.8, the number of crossover children will be: NC = 100 × 0.8 = 80.
Mutation operation. The top NM fittest individuals are selected from historical best P i and their genes mutate in certain rate (R m ), see Alg. 6. The individual with lower fitness could be regarded as closer to the optimum solution, so the mutation on these individuals could increase the probability of better offsprings. In addition, the mutation rate of genes is positively correlated with its fitness. In that way, the searching range could be enlarged in the early iterations, and the search around the best solution will be refined gradually. The number of the mutation children is: NM = 100 × 0.2 = 20.
Combining these crossover and mutation children into a new group, see Alg. 7. It implies the population size as: NP = NC + NM = 100.
The iteration will be stopped when reaching the iterative number, otherwise, goto STEP (2).
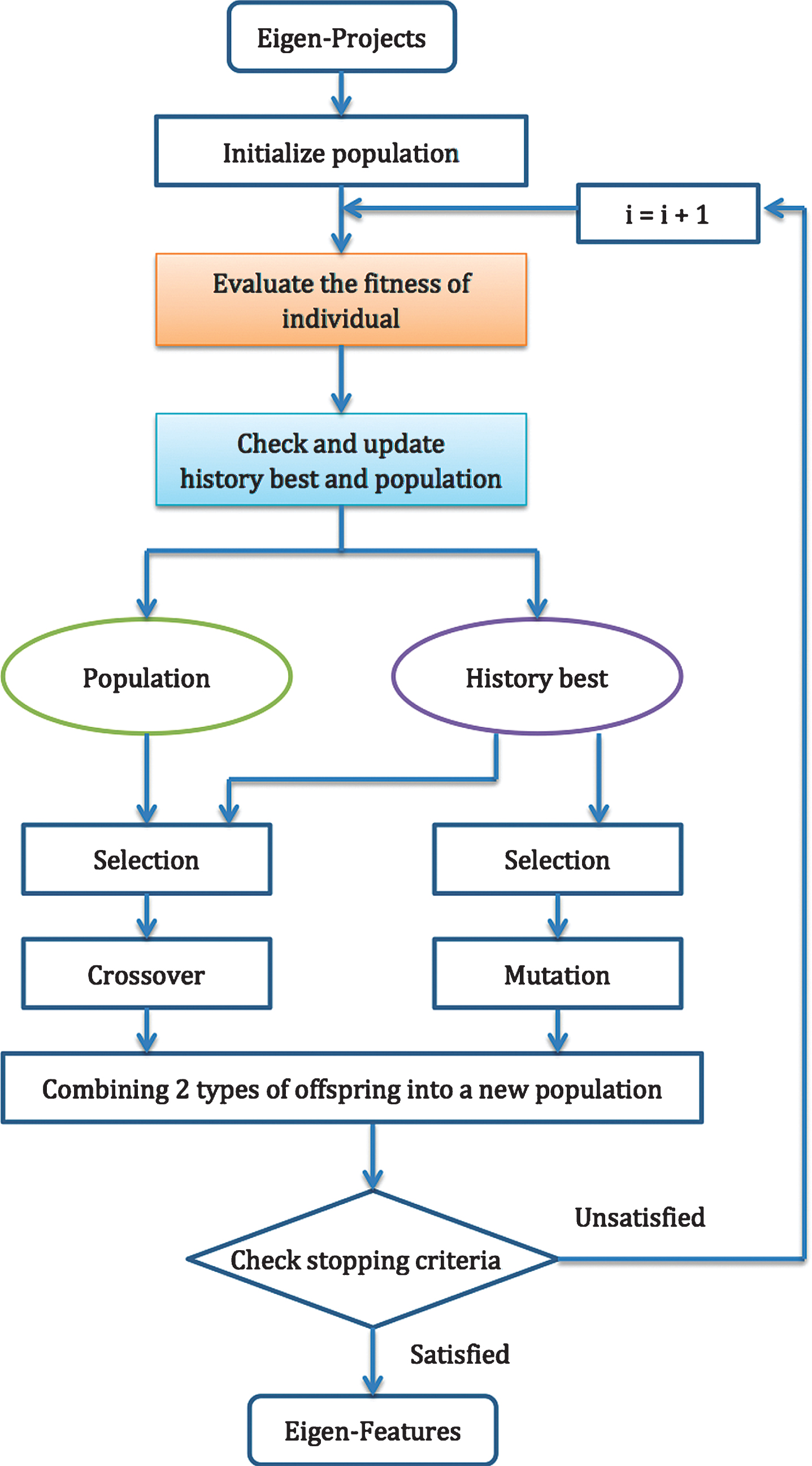
The flow chart of the improved GA.
Record the historical best gene sequence
Selection operation
Crossover operation
Mutation operation
New group
In the improved GA, the individuals in a group mixing the current population and the historical best one will be randomly selected as parents instead of the elites. Then the crossover operates in these selected parents, and the known optimal solutions lead the evolution direction while the contemporary population keeps diversity, so that the solution can be improved in a global searching scope.
Besides, the mutation operates only in the historical best group, which targets to refine the optimal solutions in local scopes. Due to the adaptive mutation rate associated to the fitness, the searches can be broaden at the early evolution stage, while it is concentrated on the optimal neighborhood later. The experiments in Section 5.1 are designed to prove the fast convergence and global searching capability of this novel GA for the PCA based feature selection.
While the Eigen-Features that contain gender information for recognition have been extracted from the FERETs, gender can be identified via a neural network. A gender recognition system is depicted in Fig. 4, composed of three validation procedures (three datasets). On the Eigen-Features generated from FERETs, a classifier is trained with a neural network algorithm. The purpose is to test the accuracy and efficiency of the feature selection method. On the Eigen-Features generated from FEI dataset through a projection algorithm, a classifier is trained with the neural network as well. It is common that the obtained gender feature set is used for different facial databases. The aim is to validate the adaptability of the proposed gender feature vector on different facial databases for gender recognition. A group of web face images is used for gender recognition as well. The purpose is to validate the feasibility and robustness of the proposed gender recognition algorithm on facial images with different expressions and orientations.
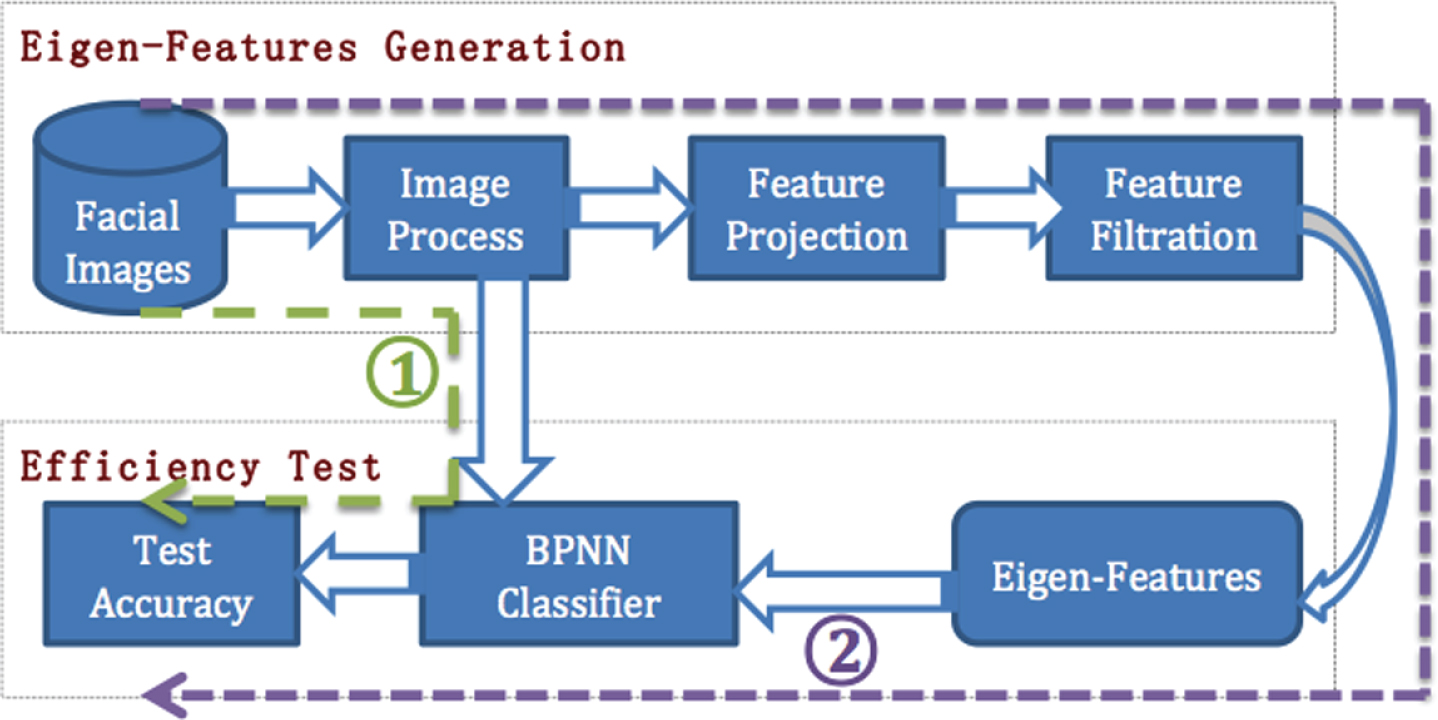
The gender recognition system (Flow 1: Global gray-level + BPNN, Flow 2: Eigen-Features + BPNN).
In order to test the classification capability of the Eigen-Features on FERETs, two categorization methods based on Error Back Propagation Neural Network (BPNN) are designed, see the Categorization method ①: send the gray-level values of the images in the training set (1120 samples × 900 pixels) directly to BPNN for training, then perform the gender identification on the testing set (280 samples × 900 pixels) by the trained classifier. Categorization method ②: instead of the gray-level values, data in training set is formed by a group of Eigen-Features (1120 samples × 255 features), and the testing set is constructed by the same structure (280 samples × 255 features). The same process is applied for training and testing with BPNN.
A model of three-layer neural network is developed for classification: input layer, hidden layer, and output layer (containing two neurons with ‵10′ denoting male and ‵01′ denoting female). The basic parameter settings of BPNN for each training are shown in Table 3. The architecture of BPNN is updated by varying the nodes of hidden layer from 2 to 12 during the training process until a gender classifier with satisfied performance is obtained.
The parameters involved in BPNN
The parameters involved in BPNN
Here it introduces a feature projection algorithm for adapting the Eigen-Features from FERET to FEI dataset to examine the gender recognition adaptability. The upper flow The projection process: First, Step (4) described in Section 3.1 is used to calculate the expectation difference, SD
k
(p), with the FEI dataset. Second, Eigen-Projects are calculated as described in Step (5) in Section 3.1. The difference is that the dataset used to calculate SD
k
(p) is FEI face data and V is calculated with FERET dataset. The filtration process: Since a group of feature genes, G (i) has been selected by GA introduced in Section 3.2, the Eigen-Features can be simply extracted from the Eigen-Projects of FEI dataset via Eq.(9).
The calculation load of the described two-step process is rather low, which will be quantified and verified in Section 5. Besides, the two categorization methods are applied on the FEI data, where its Eigen-Features are used for examining the recognition capability.
The robustness of the Eigen-Features
To better verify the practicality of our proposed Eigen-Features based gender recognition system, frontal face images selected randomly on the website are adopted in the experiments. A total 100 adult facial images are crawled from web, 50 for male and 50 for female. After the extraction of Eigen-Features, the recognition rate of BPNN on global gray-level information and Eigen-Features are evaluated respectively (see Fig. 4). Notably, the trained classifier obtained on FERETs (see Section 4.1) is still used to categorize the web face. In this way, the anti-interference ability of the Eigen-Features and the robustness of classifier based on feature selection can be examined simultaneously.
Experimental results and discussion
As described in Section 4 of the proposed gender recognition method, the experiments are performed to verify the effectiveness of the method. MATLAB is used as the tool to develop the recognition system on the operational system with Intel Core i5 (2.4 GHz) and DDR3 (4 GB, 1333 MHz). Two standard datasets (FERET and FEI) as well as a group of web face images are adopted in the experiments.
Convergence performance
On the FERET dataset, the standard GA and our improved GA are applied to the PCA feature selection. After 200 iterations, both algorithms converge, as shown in Fig. 5, where the improved GA has a faster convergence speed and produces better solutions during the searching procedure. Furthermore, the dimension of the resulted feature space is reduced from 900 to 413 with the standard GA while it is dropped to 255 with the improved one, which also demonstrates that our method has better capacity in dimension reduction.
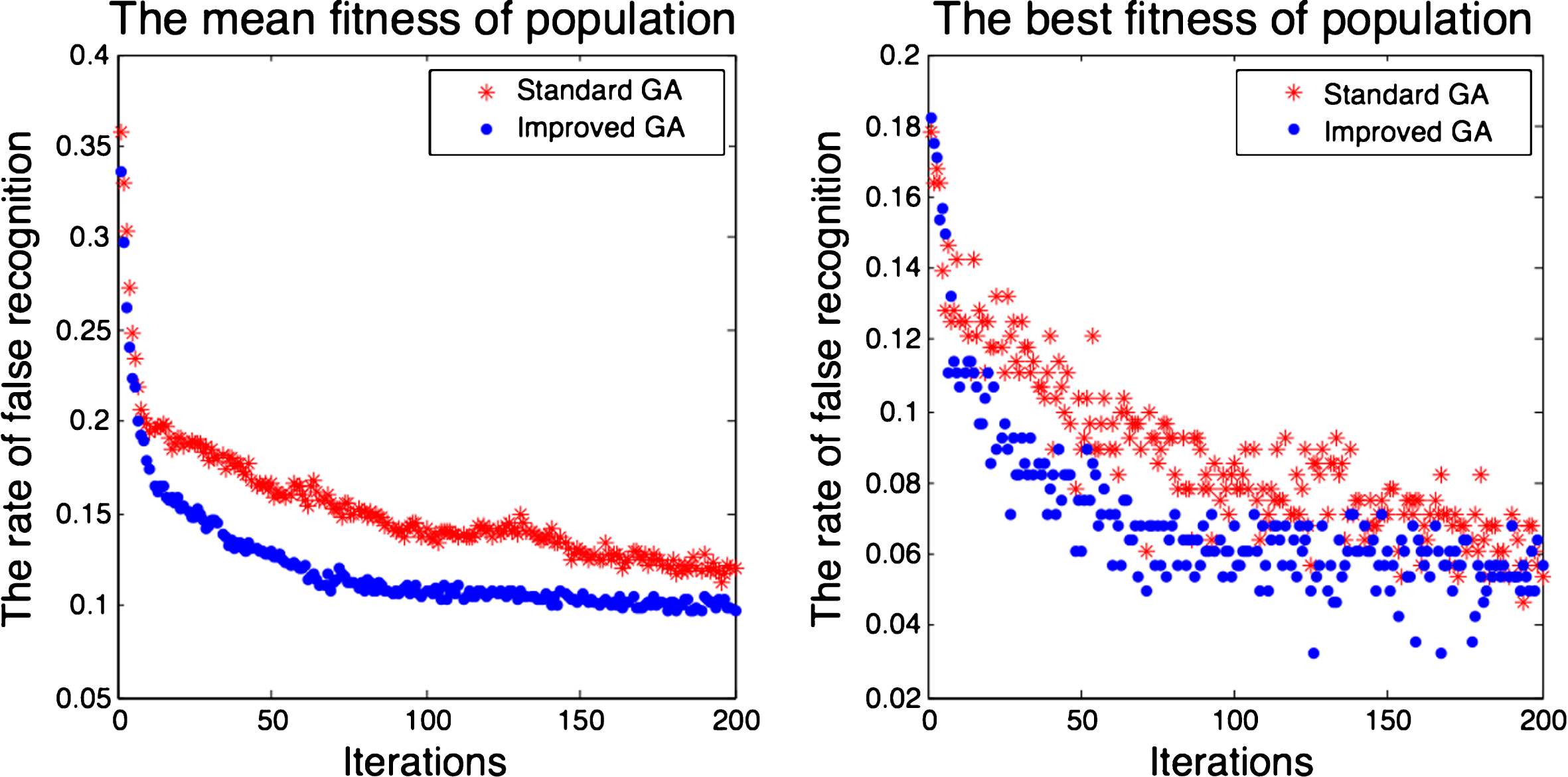
The convergence state of standard GA and improved GA method.
In the FERET and FEI datasets, a subset of 4/5 and 2/3 samples, respectively, are applied to train BPNN, and the rest are used to validate the recognition rates. Compared with the classifier via gray-level of images, the experimental results in Tables 4 and 5 show that both Eigen-Features based classifiers can achieve higher accuracies and the features extracted via improved GA perform the best, 94% and 96% respectively, with less than 1/3 of feature dimensions.
Classification results on FERET dataset (280 samples)
Classification results on FERET dataset (280 samples)
The results on FEI dataset (see Table 5) also demonstrate that the 255 feature genes G (d) obtained in Section 3.2 show the superior performance of gender classification on different dataset through a simple projection process. It implies that there is a subset in PCA features which can characterize gender on face well, with minor correlation to other factors, such as race, expression, lighting etc. Moreover, the adapting method introduced in Section 4-2 suggests that the Eigen-Features generated from a small-scale face dataset can be used to compress image for large-scale dataset, which will contribute to classification accuracy improvement and substantial calculation load reduction.
Classification results on FEI dataset (120 samples)
As for the group of web face images, aligned images obtained by VJ algorithms are sent to the classifier which is trained with FERET data in advance. Due to insufficient training data and the skew orientation on some web faces, the recognition rate with the 255 Eigen-Features is 84% (see Table 6). However, it still outperforms that with the other two types of features.
Classification results on web face images (100 samples)
The accuracies of the male and female identification of the three categorization methods have a slightly difference but with acceptable level (see Fig. 6). Therefore, it can be used for both genders recognition.
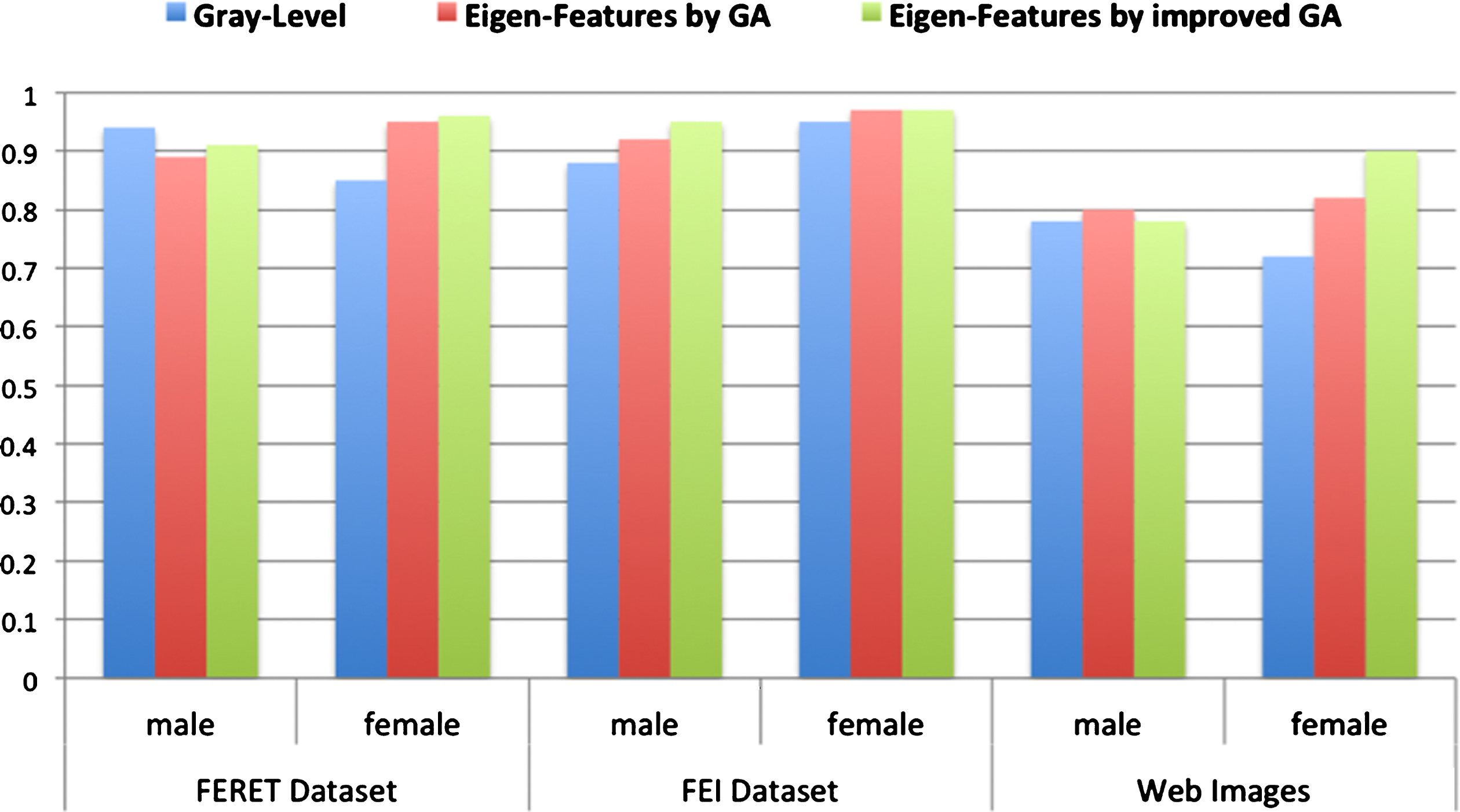
The recognition accuracy of the two categorization methods for male and female genders.
The receiver operating characteristic (ROC) curves for three datasets are depicted in Fig. 7, where x-axis denotes the rate of female classification incorrectly while y-axis denotes the rate of male classification correctly. Through varying the threshold values for classification, three curves representing the accuracy rates of the categorization methods can be drawn. As seen from the three plots, the Eigen-Features method always has a larger area under the ROC curve than the method via gray-level information, which means that it can perform a better classification indeed.
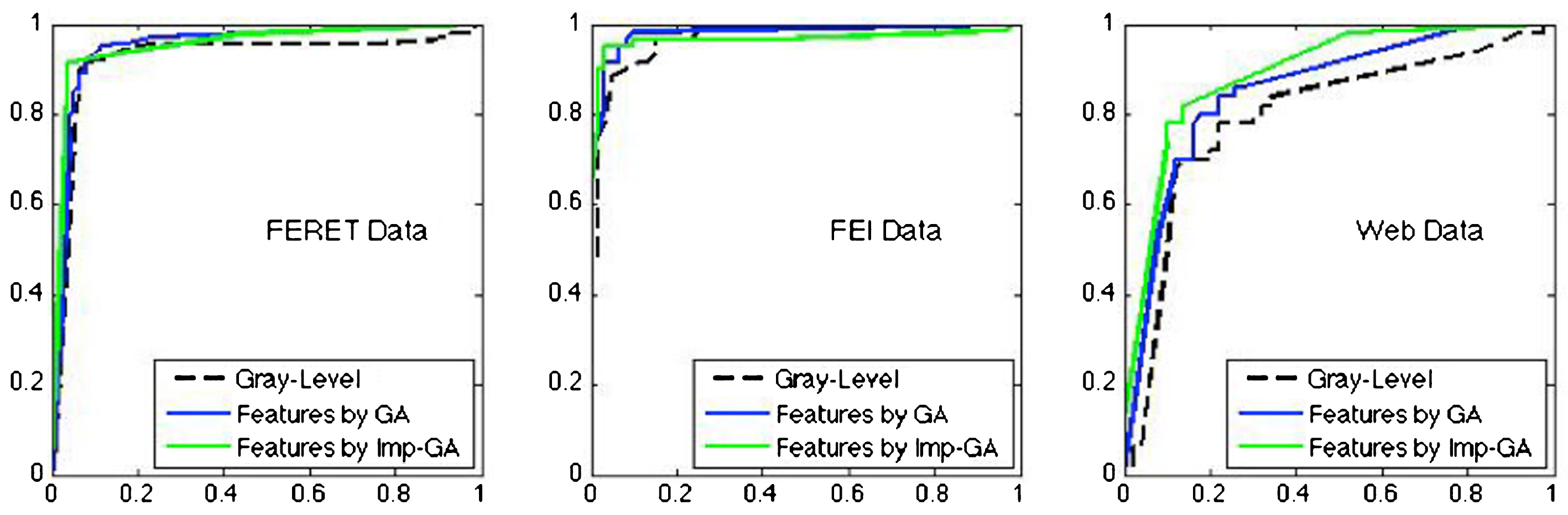
The ROC curves of the two categorization methods.
Compared to the standard GA, the proposed improved GA for feature selection can be used to search feature set with higher classification rate but lower feature dimension, i.e., 28% of the original feature dimension. It indicates that the reduced feature dimension can still effectively express the information of the facial gender. In addition, the test results show that the developed Eigen-Features transplanted to the FEI dataset and web image dataset possess satisfied robustness and adaptability.
The performance of the classifier based on Eigen-Features can be reflected from the recognition rate and the feature dimensions. Due to less dealt features, computation time spent on either training or recognition can be substantially reduced. The calculation duration in the procedure is defined as: Global Gray-Level + BPNN time span = T[image preprocess] + T[train (test) samples] Eigen-Features + BPNN time span = T[image preprocess] + T[data conversion] + T[train (test) samples]
where T [·] is the time spent on the processing.
Since the three classification methods are based on the same image process, the time spent on this process can be neglected. With the similar training and testing procedures on the different datasets, time analysis only embodies on the FERET dataset. According to the results in Table 7 and 8, even though the step of data conversion is added to the Eigen-Features based method, it deals with less feature dimensions which can substantially reduce the calculation burden and the data conversion cost little computation. Therefore, its time performance is still superior.
Training duration spent on data in FERETs (1120 samples)
Training duration spent on data in FERETs (1120 samples)
Testing duration spent on data in FERETs (280 samples)
Gender identification is a basic and useful method to discriminate people. In this paper, it investigates the method of feature selection based on PCA and an improved GA so as to achieve gender recognition with high accuracy and computational efficiency. The main contributions are summarized as follows:
(1) Facial feature selection method plays an important role in enhancement of classification accuracy and recognition efficiency, this paper proposes an improved GA for gender characteristics based PCA extraction. Genetic memory is introduced in the classical crossover and mutation operations in GA, so that the group diversity can be preserved and population evolution can be guided by the best memorial gene simultaneously to form a new feature selection algorithm in both local and global searching capability.
(2) A group of Eigen-Features that can characterize gender are extracted and used to develop a BPNN for the gender recognition system. Compared with the classifier only trained by BPNN, the developed system can achieve a higher recognition rate, which is up to 94% and 96% on FERET and FEI dataset, respectively. Furthermore, due to less used feature dimensions, the calculation load on the training and testing can be reduced greatly. This indicates that a gender classifier with high accuracy and fast identification speed can be realized effectively through PCA based feature selection.
(3) Besides, the Eigen-Features generated from a dataset demonstrate excellent performance on different dataset after adaptation by a projection algorithm. It confirms the adaptability of PCA based features in recognition, which has minor correlation with other factors, such as race, expression, wearables. The methodology of feature selection also implies a novel image compressing manner by which a super-scale face database can be trained efficiently.
The robustness of the recognition method is also verified via testing on web frontal faces. Due to the impact of relatively skew face orientation, the recognition rate (84%) is not so much satisfying, but with acceptable level, which promotes the potential research on facial image captured from different views for an improved gender recognition. In addition, the feature selection approach proposed in the paper can be applied to other identification fields, such as age, face or expression, for pursuing a fast, accurate, and strong robustness technique.
Footnotes
Acknowledgments
This work is supported under the Shenzhen Basic Research Program Ref. JCYJ20160510154736343 and Ref. JCYJ20170818153635759, and Science and Technology Planning Project of Guangdong Province Ref. 2017B010117009.