
Abstract
Artificial neural network (ANN) has been well applied in pattern recognition, classification and machine learning thanks to its high performance. Most ANNs are designed by a static structure whose weights are trained during a learning process by supervised or unsupervised methods. These training methods require a set of initial weights values, which are normally randomly generated, with different initial sets of weight values leading to different convergent ANNs for the same training set. Dealing with these drawbacks, a trend of dynamic ANN was invoked in the past year. However, they are either too complex or far from practical applications such as in the pathology predictor in binary multi-input multi-output (MIMO) problems, when the role of a symptom is considered as an agent, a pathology predictor’s outcome is formed by action of active agents while other agents’ activities seem to be ignored or have mirror effects. In this paper, we propose a new dynamic structural ANN for MIMO problems based on the dependency graph, which gives clear cause and result relationships between inputs and outputs. The new ANN has the dynamic structure of hidden layer as a directed graph showing the relation between input, hidden and output nodes. The properties of the new dynamic structural ANN are experienced with a pathology problem and its learning methods’ performances are compared on a real well known dataset. The result shows that both approaches for structural learning process improve the quality of ANNs during learning iteration.
Keywords
Introduction
Artificial neural network (ANN) has been applied in numerous areas for a period of time. It has been widely studied and many ANN models have been introduced, which are normally categorized in terms of ANN architectures, activate functions and learning methods [32]. Most ANNs are designed with
Let us consider pathology prediction (aka medical diagnosis), which is a binary multi-input multi-output (MIMO) problem, as an example to illustrate
Dealing with these drawbacks,
Gaunt et al. [9] accelerated the Dynamic Neural Network through Asynchronous Model-Parallel Training. Mustafa, Allen and Appiah [18] used Dynamic Multi-Layer Perceptron to minimize the required computational resource for an effective mobile-based speech recognition system. Torabi et al. [29] proposed a dynamic fuzzy neural network based on sequential fuzzy clustering for fault diagnosis. It uses Adaptive Neural Fuzzy Inference Systems (ANFIS) to generate a set of IF-THEN fuzzy rules. After training, a prune process is applied to eliminate neurons that are less important or present redundant fuzzy rules to construct more precise neural network structure. Online dynamic neutral networks, on the other way, focus on online training algorithms.
Pan et al. [22] used both online structure learning and online parameters learning to form an efficient online training progress of ANFIS. They also used an adaptive fuzzy control for online learning progresses [21, 23]. Pratama et al. [24, 25] proposed condition monitoring approaches on learning progress, particularly improving two meta-cognitive what-to-learn and when-to-learn. They modified the original pClass by adding a process that initializes new fuzzy rules from an empty set so that a new model called pClass+ has the ability to end up with open and dynamic structure network [26].
Ghiassi et al. [10] proposed a successful dynamic architecture for Artificial Neural Networks called DNN2, in which the hidden layer includes many layers. A layer in the hidden layer has four nodes fixed but the number of layers is dynamically determined. This architecture has been well applied in forecasting time series events [10] and Pre-Production Forecasting of Movie Revenues [11]. Inspired by dynamic structure ANN, Han et al. [12] have introduced a new dynamic structure neural network for adaptive dissolved oxygen control issue. Their approach initializes the hidden layer with zero or few units and updates the hidden layer by adding more units during training process. The other success of using dynamic structure ANN is presented in [16], where the authors developed a modification of Weiner-Type dynamic ANN for Modeling of Nonlinear Microwave Devices that can be implement in both software and hardware devices. Other works regarding the dynamic neural network can be seen in [17, 20].
Even though there have been recent advances on the dynamic neural networks, they are either too complex or far from practical applications. For example, a pathology predictor in MIMO problems works like a multi-agent system in which the combination of each separate insiders’ activities influences the final prediction result. In fact, the appearance of a symptom itself would not be a clear indication for a specific illness but a set of co-appearance of symptoms. Moreover, within a set of symptoms some of them might not strongly belong to a specific illness; they are just precedents for other symptoms that directly belong to the true diagnosed illness. Capturing this aspect, when the role of a symptom is considered as an agent, a pathology predictor’s outcome is formed by action of active agents while other agents’ activities seem to be ignored or have mirror effects. The current dynamic neural networks are incapable to model such the cases.
In order to mimic the relationship between agents in a system, we have to think about a new dynamic structural ANN model (e.g. for MIMO) including three layers with the most important different layer being the hidden layer. The hidden layer, which is modeled by the dependency graph, includes the set of nodes within dynamic adaptive topology. It means that the structure of the proposed ANN can represent the relationship between outputs and inputs; and the structure can be learnt or be updated during the learning process. By doing so, the dynamic structural ANN is able to handle the variation of input data as well as the limitations above.
In this paper, we propose
The rest of paper is organized as follows. Section 2 describes the proposal dynamic structural ANN and several proposed learning methods. Section 3 shows the experimental results on pathology prediction problem. Finally, the main results and further works are discussed in Section 4.
Dynamic structural ANN
In this section, the new dynamic structural ANN will be presented and it will be applied to the pathology prediction problem for illustration purposes. Specifically, Section 2.1 addresses the main ideas of the proposed ANN, including its theoretical validation. Section 2.2 proposes the design of the new dynamic structural ANN, while Section 2.3 focuses on two learning algorithms for the proposed ANN: greedy algorithm and Genetic Algorithm (GA). Lastly, Section 2.4 summarizes the advantages of the proposal against other works.
Main ideas
Considering pathology prediction as a multi-agent system, each of its symptoms has a different impact on a body and their insiders’ activities influence a prediction result. An agent mimics the action of a symptom or a set of similar effect symptoms. In fact, the appearance of a symptom itself might not give an insight direction for any specific illness because that symptom may belong to many illnesses. This is the case with fever, which is a symptom of wide spread diseases. However, a set of co-appearance symptoms provides a more confident clue of a specific illness. Even though the symptoms of an illness change during the time of such illness, in its middle stage symptoms are stable. In any case, within the set of symptoms, some might not directly belong to an illness; they just are precedents for other symptoms that directly belong to a diagnosed illness. This means that the outcome of pathology prediction is formed by action of active agents while other agents’ activities seem to be ignored. This relation would be clearly represented by a dependency graph [13].
The outcome of a dependency graph is not evaluated if there is a circular dependency [13]. Indeed, if no specific order is rationally applied for a circular of dependencies then no object is calculated first. To overcome this for a dependency graph, a directed acyclic graph needs to be formed. Combining features of dependency graph and properties of a real pathology diagnosis, a new dynamic structural ANN is proposed whose structure mimics real role of symptoms in a disease prediction system. The proposed new ANN mimics different effects of an agent to others and different agents’ roles to the result.
In principle, the proposed ANN has three layers: an input layer, a middle layer, and an output layer (Fig. 1). Each agent has different view for input signals and is represented by different input vectors. The output vector shows different roles of an agent in a specific economic factor. The different roles of agents are also represented by connections between agents. Therefore, an active agent effect on others can be represented by high number of nodes connections, while the output vector can be used to represent its effect on the output.
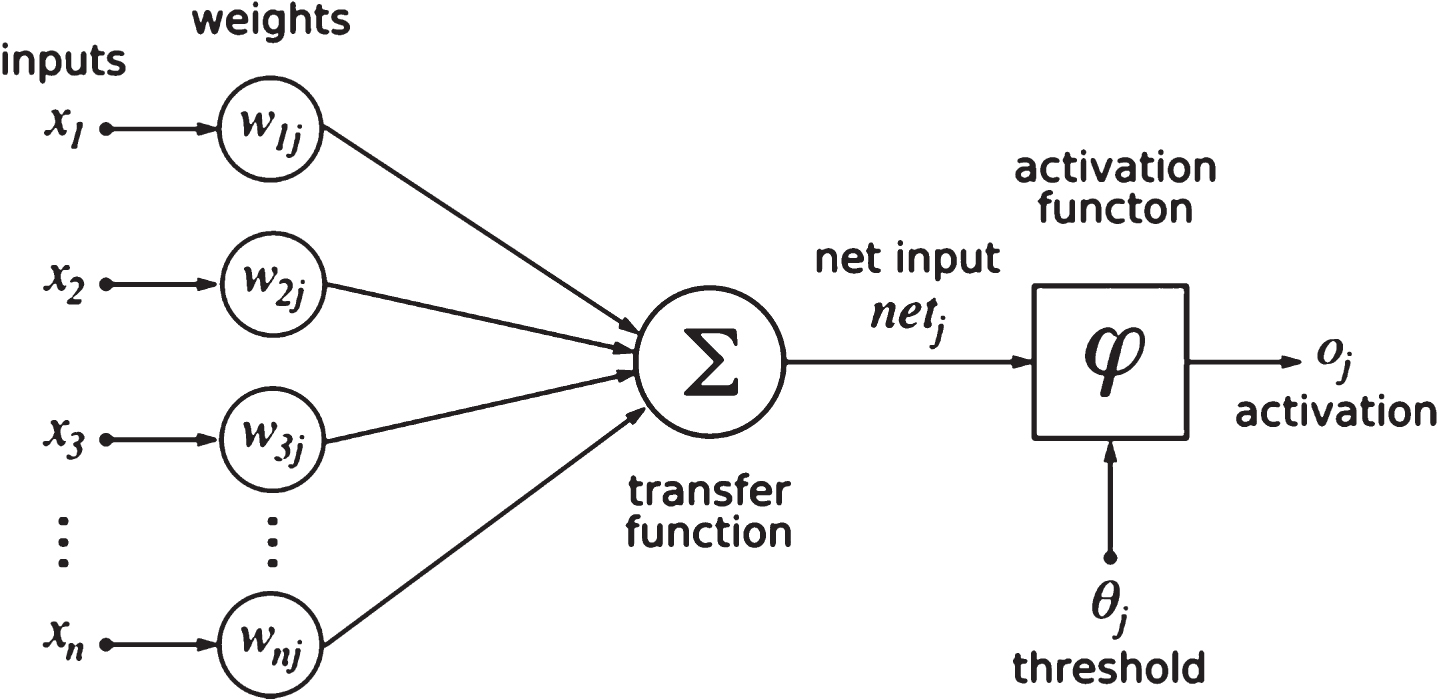
Architecture of static ANN.
In the new dynamic structural ANN, the role of nodes is strongly represented by its topology of connection rather than connections’ weights. Therefore, a fixed weight is applied to all edges to avoid the affection of weight in this type of ANN. Certainly, it needs to be proved that the proposed ANN using dynamic topology and a fixed weight works as the original ANN. Figure 1 depicts the architecture of a traditional static ANN.
The existence of an ANN with a single fixed weight
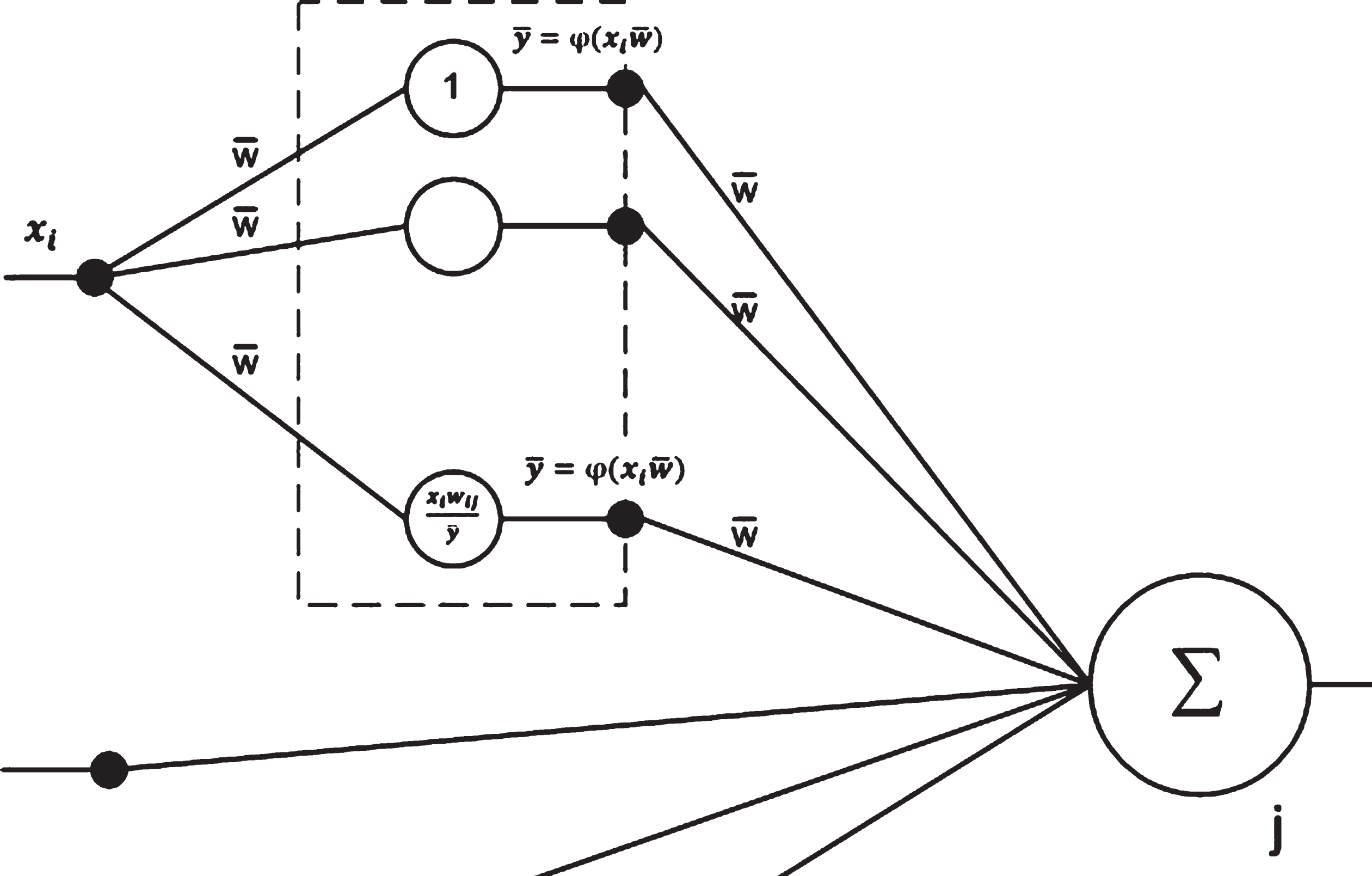
A neuron with fixed weight.
Node j would be completely replaced by a sub ANN having fixed weight if all its inputs are replaced by the same way above. Therefore, Lemma 1 is proved. □
However, the
From the above idea, we propose a new ANN that shares several important properties with the original ANN: the topology of a neuron; and three layers architecture. However, a dynamic structural ANN has the following key differences: every connection between nodes in the ANN has the same weight; and the hidden layer is represented by an acyclic directed graph. Each neuron of a dynamic structural ANN has multiple inputs, a fixed weight w and one output with a bias, as depicted in Fig. 3.
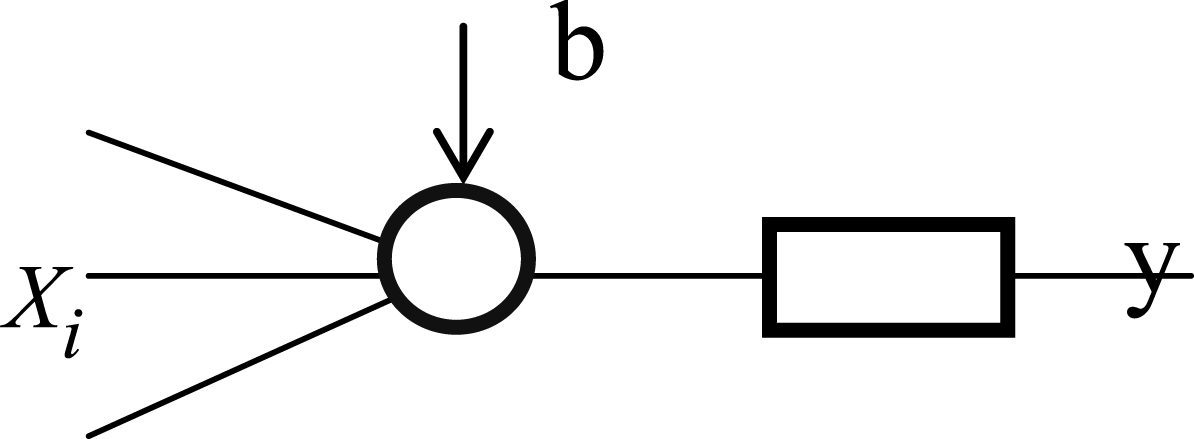
A neuron of dynamic structural ANN.
The activation function is sigmoid as defined below:
The network architecture has three layers: an input layer, a hidden layer and an output layer (Fig. 4):
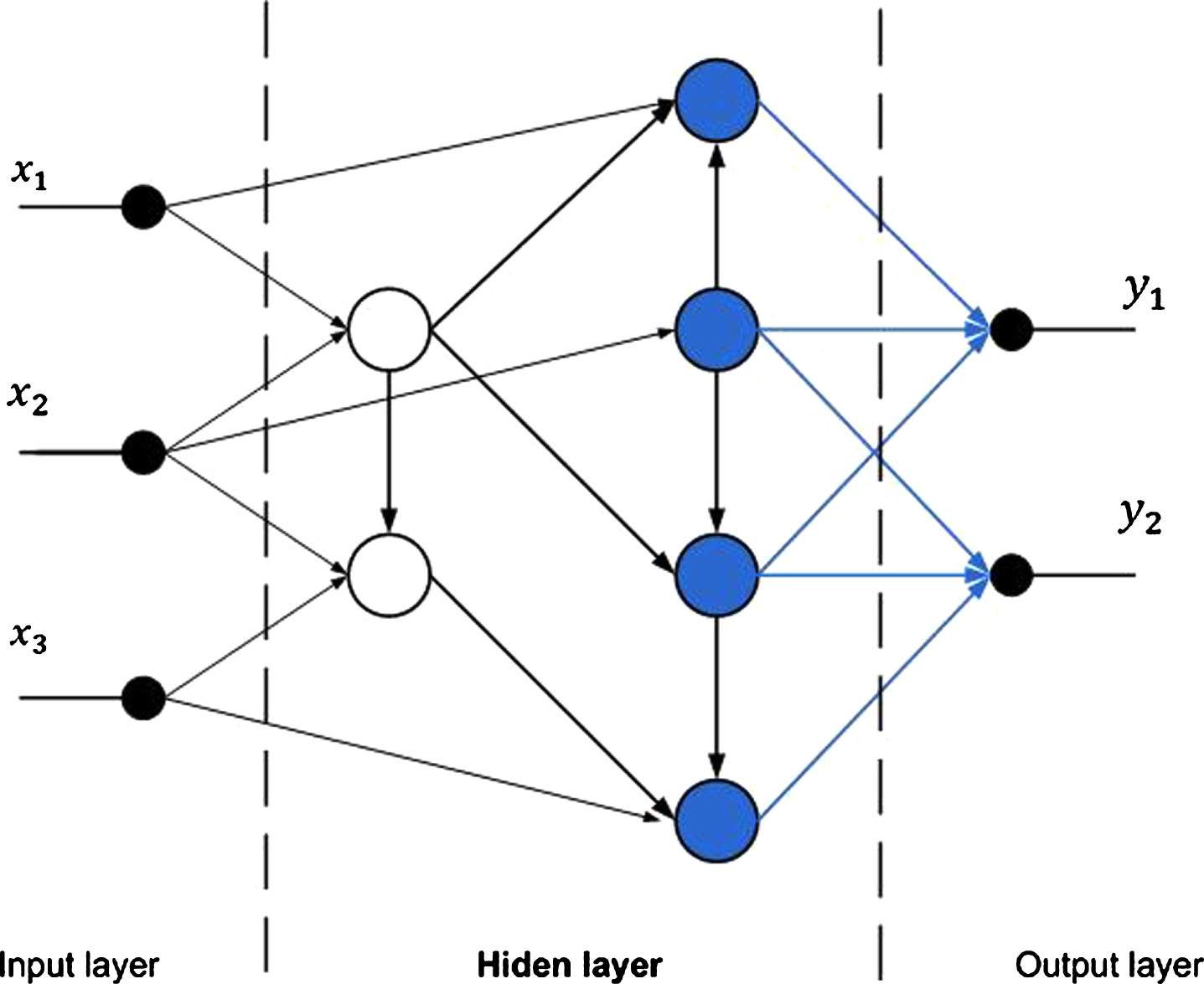
Architecture of the proposal ANN.
One hidden node can connect to any node in the same layer. The number of connections of a node shows its effect on others and, therefore, its indirectly effect on the output. A hidden node having direct connection to an output j is an active node of j. A hidden node that does not have direct connection to an output j is regarded as a normal/inactive node of j. All connections have same weights. The hidden layer’s structure shows the roles of nodes and can be represented by a directed graph. If a node A has a directed connection to node B, this means that output of node A is an input of node B. There is no cycle in a directed graph that represents the hidden layer.
The output value depends on the active hidden nodes’ output. An output vector U
j
represents the effect of active nodes on the output j, and has the same weight.
Outputs of NN are calculated through the activation function and the directed graph of the hidden layer. As described in the design, the structure of the hidden layer aims to avoid any directed cycle because a cycle will prevent the calculation process of outputs. In general, the structure of the hidden layer must be represented by an acyclic directed graph.
When applying the new dynamic structural ANN to a real problem, the input and output layers assign its numbers of nodes according to the requirement of the problem at hand. The target of the structural learning process of the new dynamic structural ANN reduces thus to learning the structure of the hidden layer. A directed graph form the structure of all layers represents the number of nodes and their connections. Therefore, the leaning algorithm has to learn a suitable number of nodes and the topological connections for a training data set. Learning the structure of ANN is a new learning process without clear previous instructions [4].
In this section, we propose two approaches for structural learning. The first one learns directly by calculating output errors and uses these errors to update the number of active hidden nodes based on the Greedy algorithm [5]. Then, back propagation process is applied to calculate the active hidden nodes, output errors and update its income connections. This process repeats until an expected error or maximal iteration is reached. The second approach uses Genetic Algorithm (GA) as a key of structural learning. A set of ANN structures is initialized as a population, and then using the output errors as fitness function. The GA will lead to the best possible structure of the ANN even if it is not a global optimal structure.
Greedy algorithm
The structure of the hidden layer is learnt using Propertys 1 and 2: increasing the number of connections or active nodes in the hidden layer when using a positive monotonic activation function leads to increasing the output values. However, as the network structure forms a full connection network and a new connection cannot be added, the only option, according to Property 2, is to add a new node. The priority between the two above factors determines the final resultant structure with high number of nodes. Therefore, in this section we use the approach with priority of topological connections. The designed learning method has two stages. The first stage initializes the parameters of the ANN, and the second stage learns the hidden layer structure by input data stream.
Randomly initialize a number of hidden nodes N in the interval [2n- MAX_INT] where n is the number of inputs, MAX_INT is the maximum value for a 32 bit integer and a structure of hidden layer (with small number of connections). The number of connections in the initial structure should be small in order to capture the basic information from patterns. A tuple of bias and weight is also important in this structural learning, and they are set by the ANN designer [15]. The bias is set as high enough, much higher than the weight, to ensure that the number of hidden nodes required for a specific problem is acceptable [15].
In general, minimizing the error of a trained structural ANN on a specific training data set is the target of the structural ANNs’ learning algorithm. In case of fixed-weight dynamic structural ANNs, the learning process has to change the connection between nodes for better outcome according to Property 1. This stage points out that in an iteration of learning only active nodes are learnt directly under the output errors [15]. And then, the active nodes request the input ones to learn.
Algorithms 1–4 change the connections to minimize the output errors. The learning algorithm based on greedy algorithm has rate of convergence dependent on the characteristic of a problem. However in one iteration, the learning algorithm updates all output nodes and continues the update of relevant active nodes in the hidden layer. The number of active nodes is Smaller than or equal to the total number of nodes of the hidden layer. Updating an active node in worst case has to update all nodes in the hidden layer. Update one node is simple task by turning a selection connection on or off. Therefore, the complexity of the learning algorithm is O (N, |Y|) = (|Y| · N2) where N is the number of hidden nodes and |Y| is the number of output nodes.
Genetic algorithm
This section uses GA algorithm for learning the structure of the dynamic structural ANN. In general, the GA algorithm has four stages. The first stage initializes a population of problem solutions. The three remaining stages are selection, crossover and mutation, which are repeated until the population converges or a fixed number of iterations is reached [5]. In order to use GA algorithm, the first task is to represent the problem as a chromosome. The structure indeed includes the number of hidden nodes, the connections between them and the connections between hidden nodes and output nodes. Assume the number of input nodes is l, the number of hidden nodes is n and the number of output nodes is m. The structure of the ANN is represented by a binary matrix of dimension (n) * (l + n + m). Each row ith of the matrix represents the out connections of a hidden node ith to other hidden nodes and input, output nodes. A chromosome to represent the above structure matrix is a chain with (n) * (l + n + m) bits [5].
However, this representation of a chromosome would not guarantee that crossover generates two new valuable chromosomes for dynamic structural ANN. The fact is that, a chromosome must represent an acyclic directed graph, but the crossover of two chromosomes would generate new chromosomes that represent a directed graph having cycle. Therefore, a modification of crossover is introduced here for dynamic structural ANN. In an acyclic directed graph, there is an order of nodes and the connections are fixed from lower rank node to higher rank node. Therefore, in order to use GA, all chromosomes have the same order of nodes, which can be set as {1, 2, …, n } without loss of generality. New modification of crossover for dynamic structural ANN has to keep the order of nodes to guarantee that new chromosomes are still acyclic directed graph. Subject to this constraint, the crossover process has to choose the cut point at the end of the nodes in a chromosome. In this case, as two chromosomes exchange their part, the new chromosomes represent two acyclic directed graphs with the same order of nodes. The purpose of GA is finding the network structure that has smallest error on the training data set. Therefore a fitness value of a network is estimated by the below Equation (2) where ∂
jk
is the error of output j for an instance of inputs k. This fitness function satisfies the requirements of GA: the value of fitness function is positive and this value increases when the fitness of solution increases.
There are several remarkable advantages of the designed GA for NN structure learning problem. First, the simplicity of chromosome encryption and the selection, crossover and mutation mechanisms lead to easy implementation. Second, the underneath mathematical process of GAs guarantees to reach local optimal solution. Third, if an initialized population of GAs is large enough and diverse, the final solutions of NN structure will be close to the global optimum.
However, the most important disadvantage of GA is computing cost. GA requires calculating fitness values for all chromosomes of each generation, and these values are estimated for all input instances of training set making it computationally expensive. Reducing the number of chromosomes or the number of generations will not solve this issue because they directly influence to quality of GA. However the computation time of GA can be reduced by using Parallel GA [5]. The second disadvantage of GA is that it works as a “gray-box”, meaning that although the GA has a clear reaching target, such as the fitness of a structure for a specific input set, it does not show the relationship between fitness convergence and structural change. In other words, the algorithm does not have a specific method to change the NN structure based on target error. The process of GA algorithm for the dynamic structural ANN is depicted in Algorithm 5.
In the learning method based on GA, the rate of convergence is depended on the characteristics of a problem where it is applied. However, the complexity of algorithm in one iteration of GA depends on selection, crossover and mutation processes.
The proposed dynamic structure ANN differs from other dynamic ANNs mentioned in the surveyed literature by using a dependency graph to mapping between multi-inputs and multi-outputs. In the scope of this paper, we used fixed weights for any connections between nodes of the three layers: input layer, hidden layer and output layer. This approach turns the dynamic structure into the center of research, where it has also been proved that a suitable dynamic would be constructed by a suitable learning process.
Two learning algorithms are used in the new ANN including the greedy and genetic algorithm approaches; however in future, new other efficient learning processes could be implemented.
The capacity of the proposed dynamic structure ANN depends on the number of nodes of the hidden layer that a computing system can process. Ideally, this number will be extended as the system need (the number of hidden node will increase as the size and diversity of data increase), but in practice, system designers will have to balance computing time with the number of hidden units.
Evaluation
This section reports on the experimental results of the proposed dynamic structural ANN on training data of heart attack from UCI [30]. The data has 1 output and 22 inputs; the 22 inputs represent the symptoms of patients and the output is the conclusion about their heart problem. The training set has 80 instances and the testing set has 187 instances. In order to validate the properties of the proposed dynamic structural ANN, we used the two learning methods separately and then compare their accuracy. At first, each learning methods’ performance is tested on the training database to figure out the best parameters, and then, the results of the two algorithms are compared.
Greedy algorithm based learning method
For running the test of greedy algorithm based learning method, we use different sets of parameter (N, r, w, b) where N is the number of hidden node, r is the ratio of initial connections, w is the weight of connection and b is the bias of neuron. However, for the purpose of showing the inside properties of the learning method, we have run the test with N = 100, r = 5%, w = 0.05, b = 0.1. Each training process runs a maximum of 100 iterations, and the result is estimated by 5 time testing. The training shows several interesting results as below.
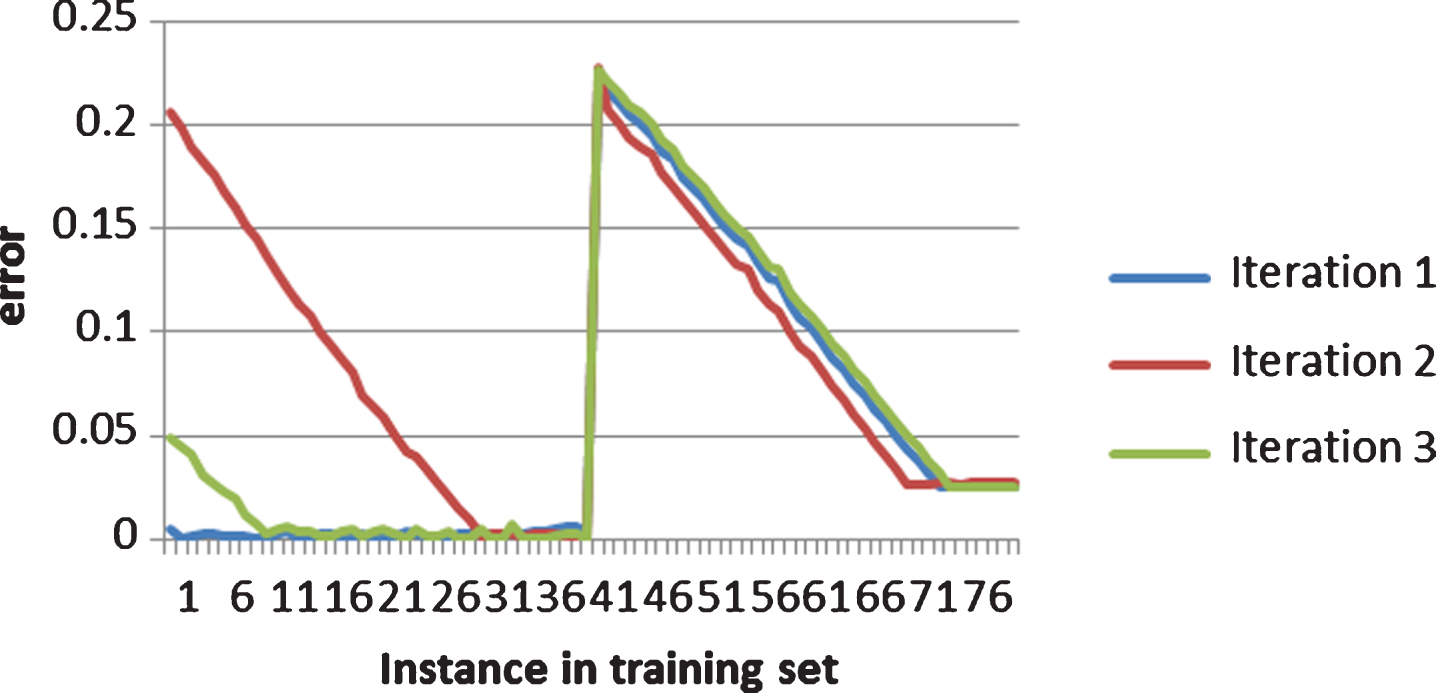
Learning method performance.
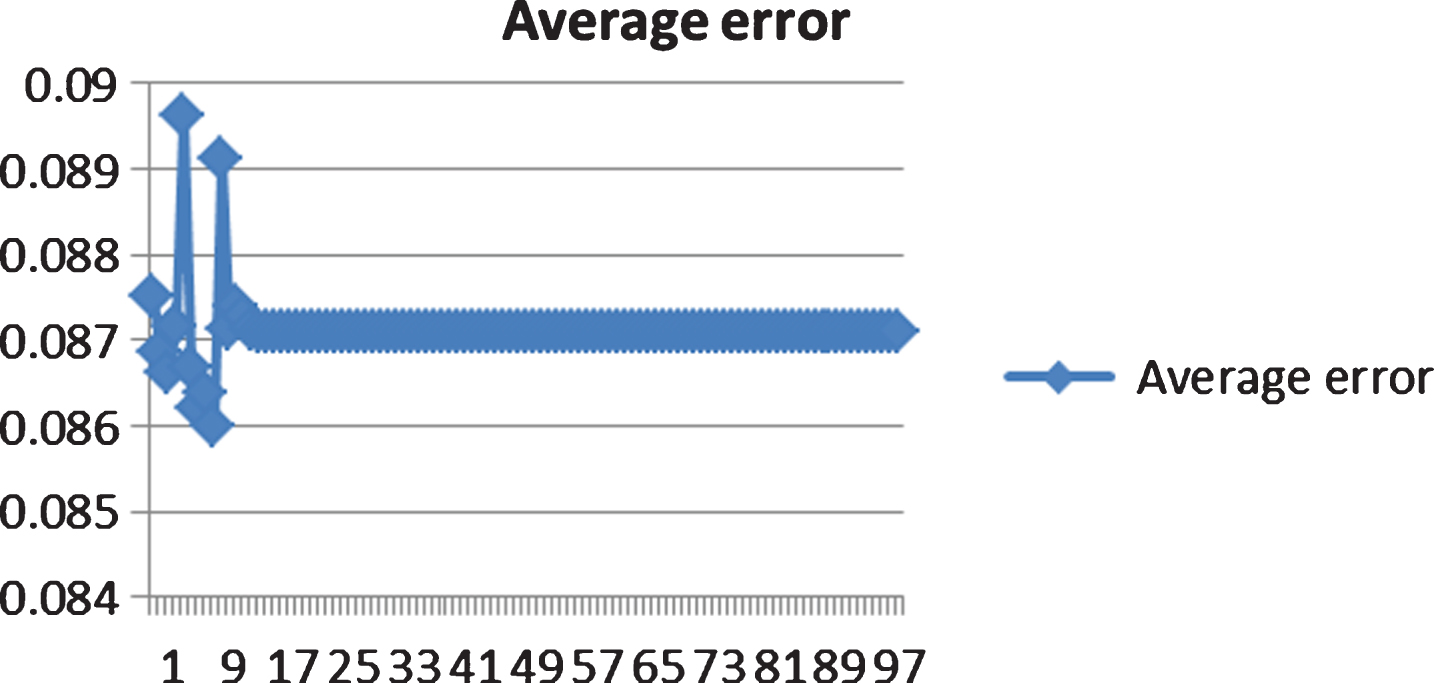
Average error during training iteration.
We applied GA algorithm with the same number of hidden node tested by the greedy algorithm. In general, GA has several important parameters to test and choose the good candidate. The number of candidates in tournament of selection stage is set at 10% of the population. The rate of mutation is set at 10% of connection in a chromosome. The performance of the GA based learning method is shown in Figs. 7, 8. In experience, the algorithm leads to local convergence after a short number of iterations. This situation can be improved by increasing the population size, because a larger population gives a more diversity generation, and then the GA will search in larger space, or increasing the mutation rate [5]. The result shows the problem of convergence in GA using tournament selection, with the best chromosome having high possibility to reproduce in next generation. Besides, we have to limit the number of cross point selection in the crossover stage; therefore the searching space is limited. The consequence is that the GA converges fast to a local optimum.
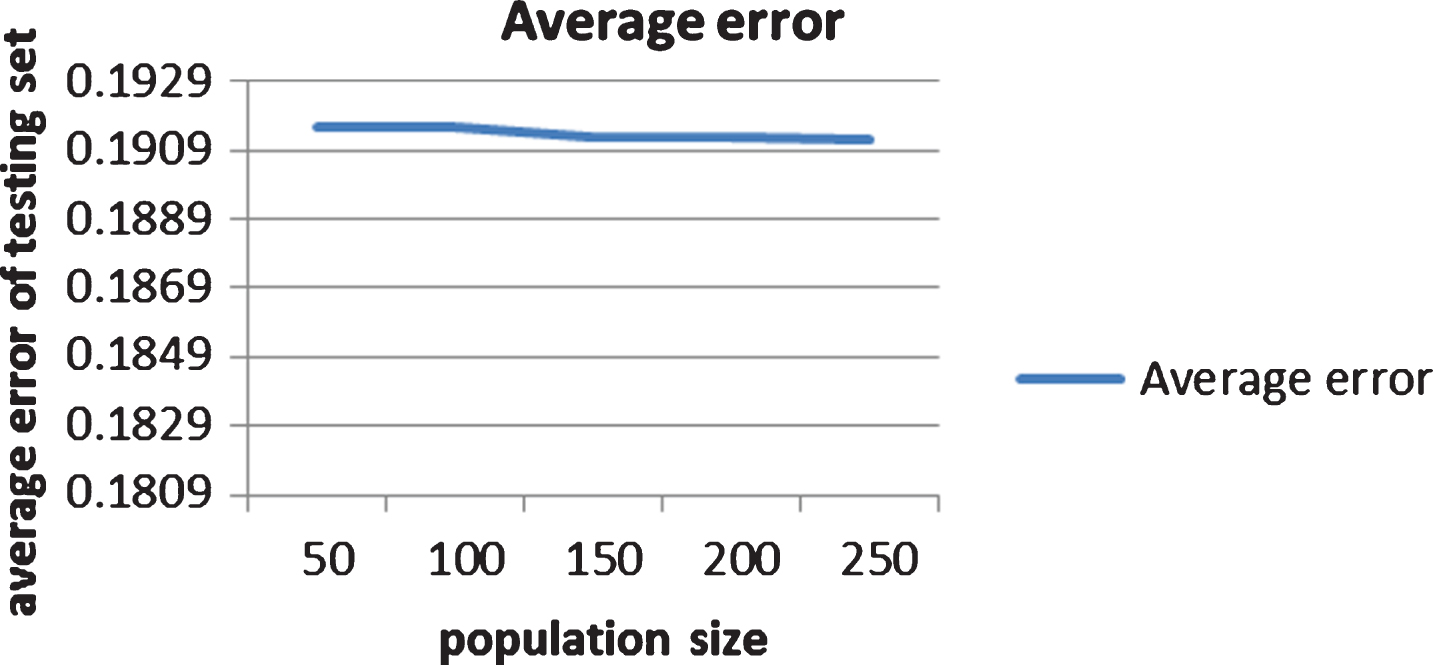
Average testing error vs. number of population.
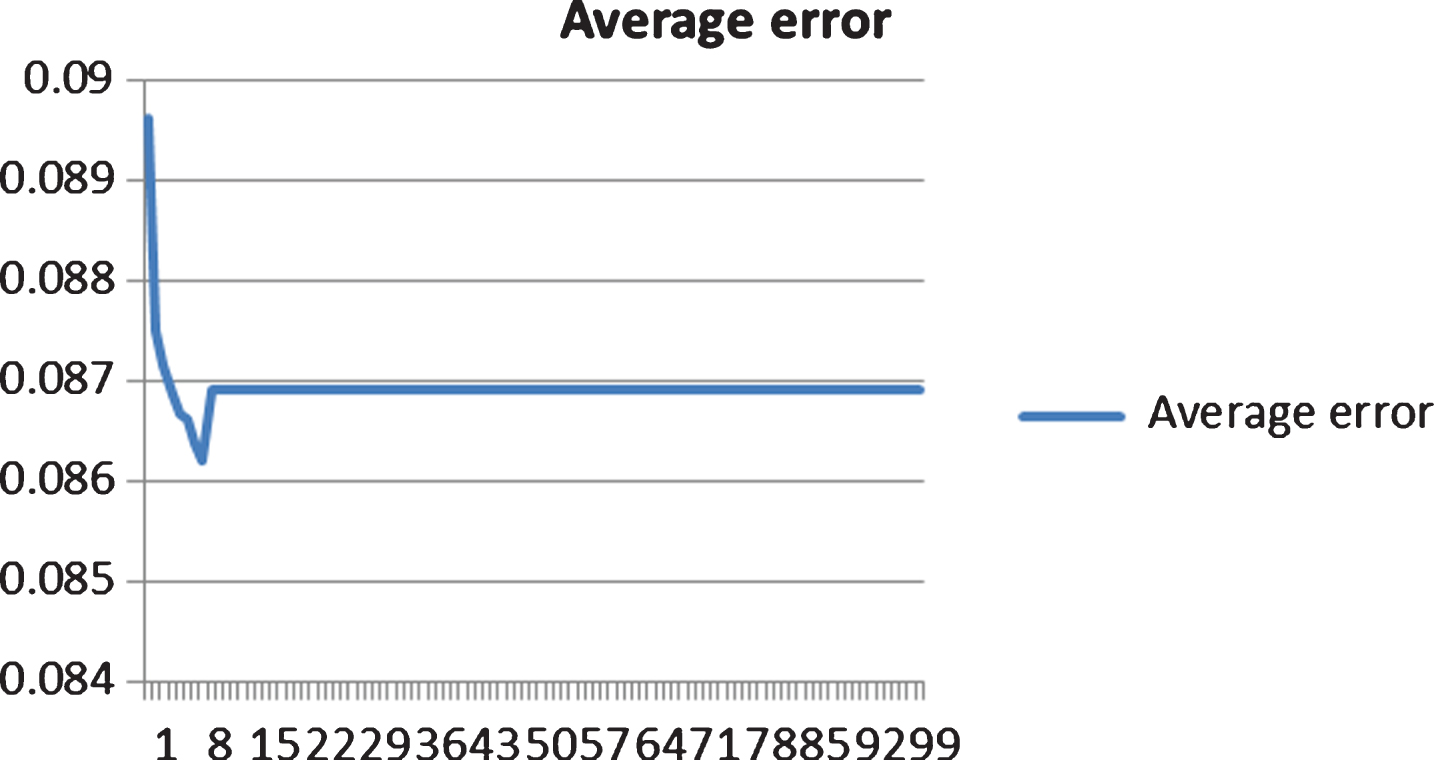
Average error in training iteration.
In case of using 100 hidden nodes, the performance of both learning methods in the testing set is depicted below (Fig. 9). The experimental results show that GA algorithm gives better prediction for most cases in the testing set.
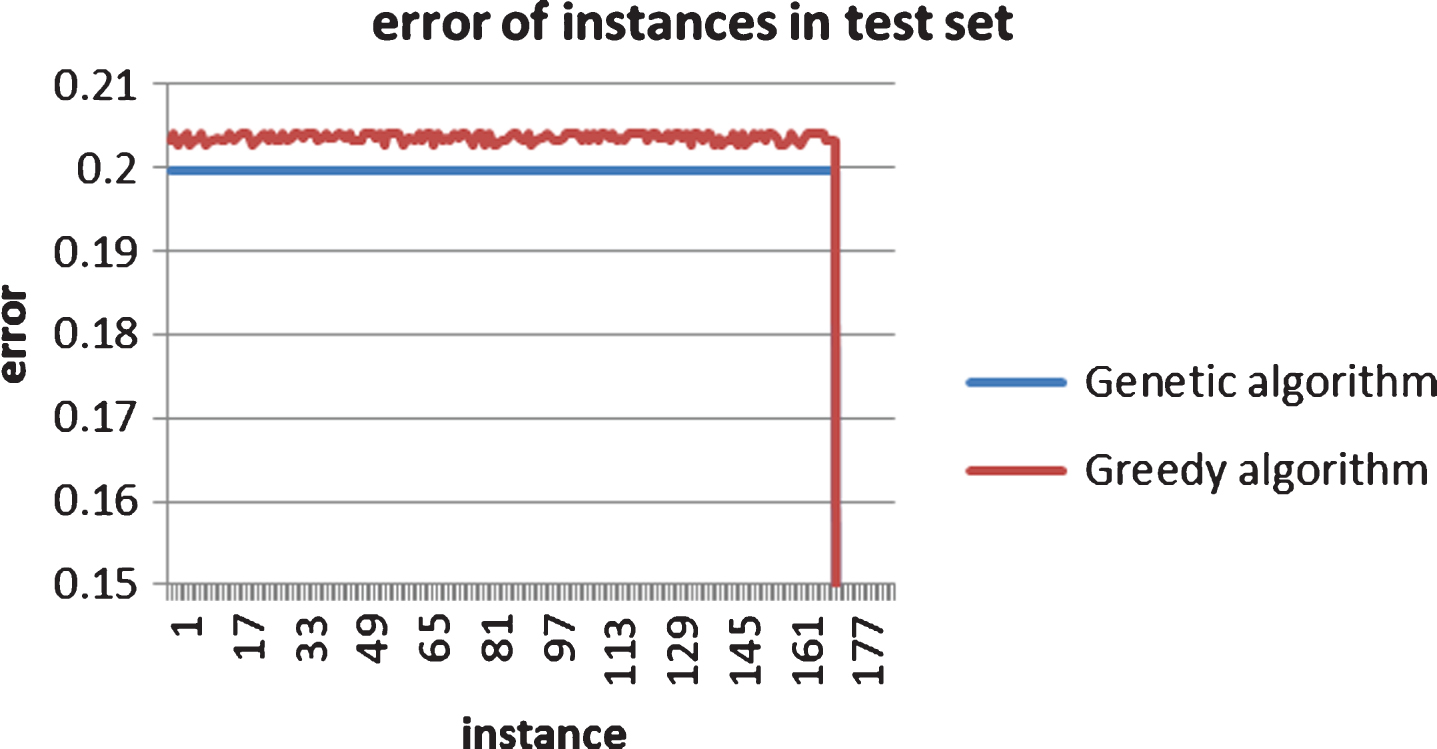
Two learning methods’ performance.
In this paper, we focused on designing a novel dynamic structural artificial neural network (ANN) for binary multi-input multi-output (MIMO) problems. We introduced the fundamental knowledge for the dynamic structural ANN and its comparison with respect to the static structural ANN. The important definitions and properties of the dynamic structural ANN regarding positive activation functions, such as sigmoid functions, have been theoretically examined. Considering as the first effort to present the dynamic structural ANN for binary MIMO problems, we believe that it is valuable in reality thanks to the dynamically relationship between inputs and outputs with the support of dependency graph. This fosters the adaptability and survival capability of the proposal for a wide variety of practical problems.
The proposed model of dynamic structural ANN has been validated using a real data set of heart attack in UCI. The result shows that both approaches for structural learning process improve the quality of ANNs during the learning iteration. In experience, the drawback of both learning methods is caused by the limitation of computing power, which curbs for running test with large number of hidden nodes.
In future, we will expand this research with other learning methods to construct better results for the dynamic structural ANN. Large number of hidden nodes will be tested for better performance, and suitable areas for applications of the new dynamic structural ANN to benefit from the cause and result relationship represented by the ANN’s structure will be studied.
Footnotes
Acknowledgments
This research is funded by Graduate University of Science and Technology under grant number GUST.STS.ĐT2017- TT02.
The authors are grateful for the support from the Institute of Information Technology, Vietnam Academy of Science and Technology. We received the necessary devices as experiment tools to implement proposed method.