
Abstract
A knowledge base is one basic notion in rough set theory. In a knowledge base, one can approximately describe target notions by using existing knowledge structures. This paper investigates invariant characteristics of knowledge structures in a knowledge base under homomorphisms and their uncertainty measures. First, partial dependence knowledge structures in the same knowledge base is proposed and the concept of knowledge structure bases is presented. Then, invariant and inverse invariant characteristics of knowledge structures in a knowledge base under homomorphisms are obtained. Next, measuring uncertainty of knowledge structures in the same knowledge base is investigated. Finally, two examples are employed to illustrate that knowledge granulation, rough entropy, knowledge entropy and knowledge amount of knowledge structures, and knowledge distance between knowledge structures are neither invariant nor inverse invariant under homomorphisms, and third example shows the feasibility of the proposed measures for uncertainty of knowledge structures in the same knowledge base. These results will be helpful for building a skeleton of granular computing in knowledge bases.
Keywords
Introduction
Rough set theory, presented by Pawlak [21], is an effective tool to copy with uncertainty. It has been applied to some fields such as intelligent systems, expert systems, knowledge discovery, machine learning, pattern recognition, inductive reasoning, image processing, decision analysis and signal analysis [21 –24].
From the angle of rough set theory, knowledge implies the capacity to classify objects [4 , 21]. Initially, rough set theory just addresses equivalence relations. Every equivalence relation on a given universe ascertains a classification on this universe and vice versa. One handles not only a single classification, but also a collection of classifications [4, 13]. This causes the notion of knowledge bases.
In a knowledge base, a given equivalence relation divides the universe into some disjoint classes, these classes are said to be equivalence classes with respect to this equivalence relation. An equivalence relation may be viewed a special kind of similarity between objects from a data set. If two elements of the universe belong to the same equivalence class, then we may say that they cannot be distinguished under this equivalence relation. Thus, every equivalence class can be viewed as an information granule consisting of indistinguishable objects [14 , 26]. All these equivalence classes or information granules constitutes a vector, this vector is referred to as a knowledge structure of this equivalence relation. Obviously, a knowledge structure is a granular structure in the meaning of granular computing [36 –39]. In a knowledge base, one can approximately describe target notions by using existing knowledge structures.
The study of a knowledge base is an important issue. Some scholars have done some research contributions. For example, Qian et al. [26] studied knowledge structure in a tolerance knowledge base by means of set families and proposed knowledge distance between knowledge structures; Li et al. [8] discussed relationships between knowledge bases and proved that knowledge reductions, coordinate families and necessary relations in a knowledge base are invariant and inverse invariant under homomorphisms; Li et al. [9] studied properties of knowledge structures in a knowledge base by means of condition information amounts, inclusion degrees and lower approximation operators, and gave group, lattice, mapping, and soft characterizations of knowledge structures in a knowledge base; Qin [25] showed that *-reductions in a knowledge base are invariant and inverse invariant under homomorphisms.
To evaluate uncertainty of a system, Shannon [29] introduced the concept of entropy. Some scholars have applied the extension of entropy and its variants to rough sets. For example, D
On invariant characteristics of knowledge structures in a knowledge base, the facts that the equality and dependence between knowledge structures in a knowledge base are invariant and inverse invariant under homomorphisms have proved (see [9]). In this paper, we will show that the partial dependence and independence between knowledge structures in a knowledge base are invariant and inverse invariant under homomorphisms. Moreover, we will propose some tools for measuring uncertainty of knowledge structures and employ examples to illustrate that the proposed tools and knowledge distance between knowledge structures are neither invariant nor inverse invariant under homomorphisms.
The remaining part of this paper is organized as follows. In Section 2, some basic notions on knowledge bases, relation information systems and homomorphisms are recalled. In Section 3, some of dependence between knowledge structures in the same knowledge base are introduced. In Sections 4, invariant characteristics of knowledge structures in a knowledge base under homomorphisms are obtained. In Sections 5, we introduce some tools for measuring uncertainty of knowledge structures in the same knowledge base. In Sections 6, some examples are given. Section 7 summarizes this paper.
Preliminaries
In this section, we recall some basic notions about knowledge bases, relation information systems and homomorphisms.
Throughout this paper, U, V denotes two non-empty finite sets, 2
U
denotes the family of all subsets of U, |X| denotes the cardinality of X ∈ 2
U
, 2
U×U
denotes the family of all binary relations on U and
In this paper, put
U = {x 1, x 2, ⋯, x n }, V = {y 1, y 2, ⋯, y m },
δ = U × U, ▵ = {(x, x) : x ∈ U}.
Knowledge bases
Recall that R is a binary relation on U if R ∈ U × U. If (x, y) ∈ R, then we denote it by xRy.
Let R be a binary relation on U. Then R is referred to as
(1) reflexive, if xRx for any x ∈ U;
(2) symmetric, if xRy implies yRx for any x, y ∈ U;
(3) transitive, if xRy and yRz implies xRz for any x, y, z ∈ U.
Let R be a binary relation on U. Then R is referred to as equivalence if R is reflexive, symmetric and transitive.
Given
Given
By the aid of a given element of a knowledge base, one can construct a rough set of any subset on the universe in the following definition.
Relation information systems
Given B ⊆ A. Define (x, y) ∈ R B ⇔ ∀ a ∈ B, a (x) = a (y). Then R B is an equivalence relation on U.
Wang et al. [31] introduced the following notion of relation information systems as a simplified model of information systems.
Clearly, a relation information system is not an information system, and an information system is also not a relation information system. But, the following definition illustrates the fact that there are certain relationships between information systems and relation information systems.
In fact, (U, R) in Definition 2.5 is a knowledge base.
Clearly,
(U, R) is a knowledge base ⇒ (U, R) is a relation information system.
Homomorphisms between relation information systems
Large database often appears in production practice. Homomorphism between relation information systems, proposed by Wang et al. [31], are a kind of tools to study data compression in relation information systems.
Given R ∈ 2 U×U . Put R s (x) = {y ∈ U : xRy}. Then R s (x) is referred to as the successor neighborhood of x ∈ U with respect to R ([33]).
[x] f = {u ∈ U : f (u) = f (x)}, (x) R = {u ∈ U : R s (u) = R s (x)}.
If [x] f ⊆ R s (u) or [x] f ∩ R s (u) ≠ ∅ for any x, u ∈ U, then f is referred to as type-1 consistent on R. If [x] f ⊆ (x) R for any x ∈ U, then f is referred to as type-2 consistent on R.
Given R ⊆ 2 U×U . If f is type-1 (resp. type-2) consistent on R for every R ∈ R, then f is called type-1 (resp. type-2) consistent on R.
Clearly,
Some notions of knowledge structures in a knowledge base
In this section, we recall some notions of knowledge structures in a knowledge base.
K (▵) = ({x 1}, {x 2}, ⋯, {x n }).
One can investigate relationships between information structures in a knowledge based from the two aspects of separation and dependence.
To characterize the difference between knowledge structures in the same knowledge based, Qian et al. [26] propose the following concept of knowledge distance between knowledge structures.
Definition 3.5 depicts the dependence, partial dependence and independence between knowledge structures in the same knowledge base.
(1) K (Q) is called to depend on K (P), if for each i, [x i ] P ⊆ [x i ] Q . We write K (P) ⊏ K (Q).
(2) K (Q) is called to depend partially on K (P), if there exists i, [x i ] P ⊆ [x i ] Q . We write K (P) ⊑ K (Q).
(3) K (Q) is said to be independent of K (P), if for each i, [x i ] P ⊈ [x i ] Q . We write K (P) ⋈ K (Q).
The following definition makes some changes to Definition 3.5 above.
(1) K (Q) is called to depend on K (P), if for each i, [x i ] P ⊆ [x i ] Q , we write K (P) ⪯ K (Q); K (Q) is called to depend strictly on K (P), if K (P) ⪯ K (Q) and K (P) ≠ K (Q), we write K (P) ≺ K (Q).
(2) K (Q) is called to depend partially on K (P), if there exists i, [x i ] P ⊆ [x i ] Q , we write K (P) ⊑ K (Q); K (Q) is referred to as to depend partially strictly on K (P), if K (P) ⊑ K (Q) and K (P) ≠ K (Q), we write K (P) ⊏ K (Q).
(3) K (Q) is said to be independent of K (P), if K (P) ⋈ K (Q).
In Fig. 1, (a) means K (P) ≺ K (Q), (b) means K (P) ⊏ K (Q), (c) means K (P) ⊏ K (Q) and K (Q) ⊏ K (P), (d) means K (P) ⋈ K (Q) and K (Q) ⋈ K (P).

Clearly,K (P) = K (Q ⇔ K (P) ⪯ K (Q), K (Q) ⪯ K (P) ;K (P)⪯ K (Q) ⇒ K (P) ⊑ K (Q), K (P) ≺ K (Q) ⇒ K (P) ⊏ K (Q) ;K (P) ⋈ K (Q) ⇔ K (P) ⋢K (Q).
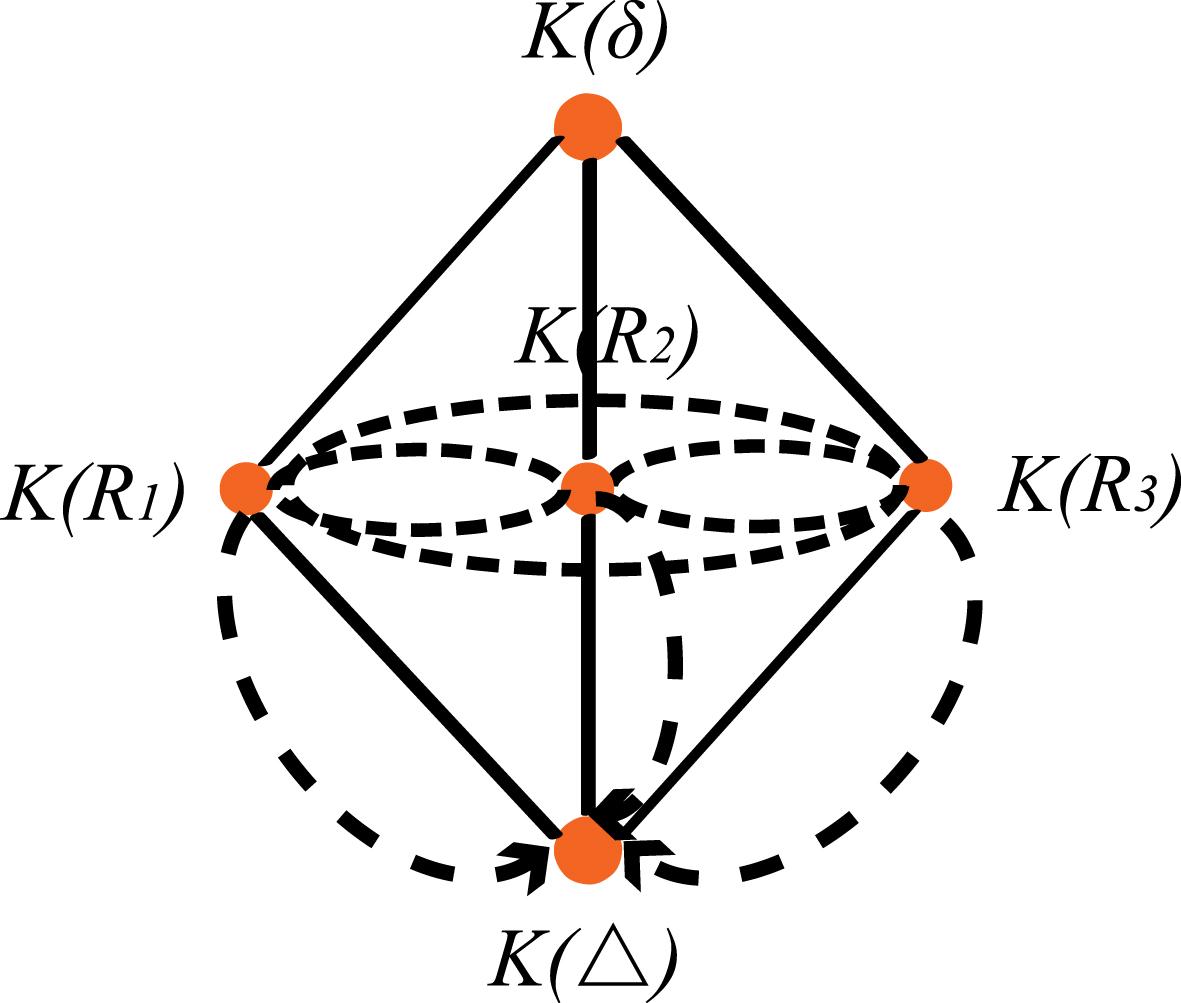
Obviously,
R 0 =▵,
R 1 = ▵ ∪ {(x 1, x 2), (x 2, x 1)},
R 2 = ▵ ∪ {(x 1, x 3), (x 3, x 1)},
R 3 = ▵ ∪ {(x 2, x 3), (x 3, x 2)},
R 4 = δ. Then (U, R) is a knowledge base. So
K (R 1) = ({x 1, x 2}, {x 1, x 2}, {x 3}),
K (R 2) = ({x 1, x 3}, {x 2}, {x 1, x 3}),
K (R 3) = ({x 1}, {x 2, x 3}, {x 2, x 3}),
We have
K (▵) ≺ K (R 1) ⊏ K (▵), K (R 1) ⊏ K (R 2) ⊏ K (R 1), K (R 1) ⊏ K (R 3) ⊏ K (R 1), K (R 1) ≺ K (δ) ⋈ K (R 1);
K (▵) ≺ K (R 2) ⊏ K (▵), K (R 2) ⊏ K (R 3) ⊏ K (R 2), K (R 2) ≺ K (δ) ⋈ K (R 2);
K (▵) ≺ K (R 3) ⊏ K (▵), K (R 3) ≺ K (δ) bowtieK (R 3) (see Fig. 2).
(1) K (P) = K (Q);
(2) U/P = U/Q;
(3) P = Q.
(1) K (P) ⊏ K (Q);
(2) U/P refines U/Q, i.e., for each A ∈ U/P, there exists B ∈ U/Q such that A ⊆ B;
(3) P ⪯ Q.
In this section, invariant characteristics of knowledge structures in a knowledge base under homomorphisms are obtained.
f (x i ) = f (x′) implies x′ ∈ [x i ] f . Since f is type-2 consistent on P and Q, we have [x i ] f ⊆ (x i ) P , [x i ] f ⊆ (x i ) Q . Then x′ ∈ (x i ) P , x′ ∈ (x i ) Q . So P s (x′) = P s (x i ) = [x i ] P , [x′] Q = Q s (x i ) = [x i ] Q .
It should be noted that [x i ] P ⊆ [x i ] Q . Then P s (x′) ⊆ [x′] Q .
x′Px″ implies x″ ∈ P s (x′). So x″ ∈ [x′] Q , i.e., x′Qx″.
It should be noted that y
j
= f (x′), v = f (x″) and x′Qx″. Then
Hence
“⇐". Suppose
∀ u ∈ [x
i
]
P
, we have x
i
Pu. Then
Since
∃ x′, x″ ∈ U, f (x i ) = f (x′), f (u) = f (x″) and x′Qx″.
f (x i ) = f (x′) implies x′ ∈ [x i ] f . Since f is type-2 consistent on Q, we have [x i ] f ⊆ (x i ) Q . Then x′ ∈ (x i ) Q . So x′ ∈ Q s (x′) = Q s (x i ). This implies x i Qx′.
f (u) = f (x″) implies x″ ∈ [u] f . Since f also is type-2 consistent on Q, we have [u] f ⊆ (u) Q . Then x″ ∈ (u) Q . So x″ ∈ Q s (x″) = Q s (u). This implies uQx″.
It should be noted that x′Qx″, x i Qx′ and u Q x″. Then x i Qu. This implies u ∈ [x i ] Q .
Thus [x i ] P ⊆ [x i ] Q . This shows K (P) ⊑ K (Q). □
(1)
(2)
(2) This follows from Theorem 4.5. □
Theorem 4.2, Theorem 4.3, Corollary 4.4, Theorem 4.5 and Corollary 4.6 mean that the equality, dependence, partial dependence and independence between knowledge structures in a knowledge base are invariant under homomorphisms. But the image knowledge base
Let U = {x i : 1 ≤ i ≤ 15}. Put
U/R 1 = {{x 1, x 2, x 4, x 7, x 8, x 9, x 10, x 11}, {x 3, x 5, x 6, x 12, x 13, x 14, x 15}},
U/R 2 = {{x 1, x 4, x 11, x 12, x 13, x 14, x 15}, {x 2, x 3, x 5, x 6, x 7, x 8, x 9, x 10}},
U/R 3 = {{x 1, x 2, x 4, x 7, x 8, x 9, x 10, x 11, x 12, x 13, x 14, x 15}, {x 3, x 5, x 6}},
U/R 4 = {{x 1, x 2, x 4, x 7, x 8, x 9, x 10, x 11}, {x 3, x 5, x 6, x 12, x 13, x 14, x 15}} ; R = {R 1, R 2, R 3, R 4}. Then (U, R) is a knowledge base.
Pick V = {y
1, y
2, y
3, y
4, y
5, y
6}. A mapping f : U → V is defined as follows:
It is easy to check that f is both type-1 and type-2 consistent on R. Thus
By Theorem 4.1,
It should be noted that K (R 1) = K (R 4);
K (R
1) ⊏ K (R
3) ⊏ K (R
1), K (R
2) ⊏ K (R
3) ⊏ K (R
2), K (R
3) ⊏ K (R
4) ⊏ K (R
3). Then, by Theorem 4.6 and Corollary 4.10(1),
(1)
(2) If
Thus
"⇐". Suppose
∀ v ∈ [y
j
]
S
, we have y
j
Sv. Let f (u) = v. It should be noted that f (x
i
) Sf (u). Then
Hence K (S) ⊑ K (T). □
(1) K (S) ⊏ K (T) ⇔
(2) K (S) ⋈ K (T) ⇔
(2) This holds by Theorem 4.12.
Theorem 4.9, Theorem 4.10, Corollary 4.11, Theorem 4.12 and Corollary 4.13 mean that the equality, dependence, partial dependence and independence between knowledge structures in a knowledge base are inverse invariant under homomorphisms.
Measuring uncertainty of knowledge structures in a knowledge base
In this section, we propose some tools for measuring uncertainty of knowledge structures in the same knowledge base and give their properties.
Granularity measures for knowledge structures in a knowledge base
In a knowledge base, knowledge granulation is the average measure of knowledge granules of a given knowledge structure. It may be used to characterize the classification ability of a given knowledge structure [17 , 33].
We first propose axiom definition of knowledge granulation of knowledge structures in the same knowledge base, which makes a little adjustment to Definition 5 in [26].
(1) Non-negativity: ∀ P ∈ R* (U), G (K (P)) ≥0;
(2) Invariability: ∀ P, Q ∈ R* (U), if K (P) = K (Q), then G (K (P)) = G (K (Q));
(3) Monotonicity: ∀ P, Q ∈ R* (U), if K (P) ≺ K (Q), then G (K (P)) < G (K (Q)).
Here, ∀ P ∈ R* (U), G (K (P)) is called knowledge granulation of the knowledge structure K (P).
Similar to Definition 2 in [16], knowledge granulation of a given knowledge structure in the same knowledge base is given in the following definition.
Suppose X i = {x i1, x i2, ⋯, x is i }, |X i | = s i . Then
So | [x i ] P | = | [x i1] P | = | [x i2] P | = ⋯ = | [x is i ] P | = s i .
Thus, ∀ i,
Hence
□
Propositions 5.3 shows the fact that knowledge granulation of a give knowledge structure is fully based on knowledge granules of this knowledge structure.
By Proposition 5.3,
If P is an identity relation, then ∀ i, | [x
i
]
P
|=1. So
If P is a universal relation, then ∀ i, | [x i ] P | = n. So G (K (P)) =1.
Since K (P) ≺ K (Q), we have ∀ i, [x i ] P ⊆ [x i ] Q and ∃ j, [x j ] P ⊊ [x j ] Q . Then, ∀ i, | [x i ] P | ≤ | [x i ] Q | and ∃ j, | [x j ] P | < | [x j ] Q |.
Hence G (K (P)) < G (K (Q)). □
This theorem illustrates the fact that the knowledge granulation measure increases when the available knowledge becomes coarser, and it decreases when the available knowledge becomes finer. That is to say, the more uncertain the available knowledge is, the bigger the knowledge granulation value becomes. Thus, we can come to the conclusion that the knowledge granulation introduced in Definition 5.2 may be used to measure the certainty degree of a given knowledge structure in the same knowledge base.
(2) Given
By Proposition 5.3, G (K (P)) = G (K (Q)).
(3) “Monotonicity" follows from Theorem 5.5.
Entropy measures for knowledge structures in a knowledge base
In physics, entropy is often used to measure out-of-order degree of a system. The bigger the entropy value is, the higher out-of-order of a system will be. Shannon [29] applied the concept of entropy in physics to information theory for measuring uncertainty of the structure of a system.
Similarly, knowledge entropy of a knowledge structure in the same knowledge base is given in the following definition.
Suppose X
i
= {x
i1, x
i2, ⋯, x
is
i
}, |X
i
| = s
i
. Then
So | [x i ] P | = | [x i1] P | = | [x i2] P | = ⋯ = | [x is i ] P | = s i .
Thus, ∀ i,
Hence
□
Propositions 5.9 shows the fact that knowledge entropy of a give knowledge structure is fully based on knowledge granules of this knowledge structure.
Since K (P) ≺ K (Q), similar to the proof of Theorem 5.5, we have ∀ i, 1 ≤ | [x i ] P | ≤ | [x i ] Q | and ∃ j, 1 ≤ | [x j ] P | < | [x j ] Q |.
Then, ∀ i,
and ∃ j,
From Theorem 5.10, we can come to the conclusion that the knowledge entropy proposed in Definition 5.8 may be used to measure the certainty degree of a given knowledge structure in the same knowledge base. That is to say, the more uncertain the available knowledge is, the smaller the knowledge entropy value becomes.
Rough entropy, introduced by Yao [35], is used to measure granularity of a given partition. It is also called co-entropy by some scholars [1]. Similarly, rough entropy of a given knowledge structure in a knowledge base is proposed in the following definition.
Similar to Definition 6 in [16], rough entropy of of a knowledge structure in the same knowledge base is given in the following definition.
Suppose X
i
= {x
i1, x
i2, ⋯, x
is
i
}, |X
i
| = s
i
. Then
Hence
Propositions 5.12 shows the fact that rough entropy of a give knowledge structure is fully based on knowledge granules of this knowledge structure.
Moreover, if P is an identity relation, then E r (K (P)) achieves the minimum value 0; if P is a universal relation, then E r (K (P)) achieves the maximum value log 2 n.
By Proposition 5.12,
If P is an identity relation, then ∀ i, | [x i ] P |=1. So E r (K (P)) =0.
If P is a universal relation, then ∀ i, | [x i ] P | = n. So E r (K (P)) = log 2 n.
Since K (P) ≺ K (Q), similar to the proof of Theorem 5.5, we have ∀ i, 1 ≤ | [x i ] P | ≤ | [x i ] Q | and ∃ j, 1 ≤ | [x j ] P | < | [x j ] Q |.
Then ∀ i,
and ∃ j,
This theorem illustrates the fact that the rough entropy measure increases when the available knowledge becomes coarser, and it decreases when the available knowledge becomes finer. That is to say, the more uncertain the available knowledge is, the bigger the rough entropy value becomes. Thus, we can come to the conclusion that the rough entropy proposed in Definition 5.11 may be used to measure the certainty degree of a given knowledge structure in the same knowledge base.
(2) Given
By Proposition 5.12, E r (K (P)) = E r (K (Q)).
(3) “Monotonicity" follows from Theorem 5.14.
Knowledge amounts of knowledge structures in a knowledge base
Similarly, knowledge amount of a knowledge structure in the same knowledge base is given in the following definition.
Suppose X
i
= {x
i1, x
i2, ⋯, x
is
i
}, |X
i
| = s
i
. Then
So | [x i ] P | = | [x i1] P | = | [x i2] P | = ⋯ = | [x is i ] P | = s i .
Since {X 1, X 2, ⋯, X m } is a partition on U, ∀ i, we have
Then
Thus, ∀ i,
Hence
Proposition 5.18 shows the fact that knowledge amount of a give knowledge structure is fully based on knowledge granules of this knowledge structure.
Since K (P) ≺ K (Q), similar to the proof of Theorem 5.5, we have ∀ i, 1 ≤ | [x
i
]
P
| ≤ | [x
i
]
Q
| and ∃ j,
Hence E (K (Q)) < E (K (P)). □
From Theorem 5.19, we can come to the conclusion that the knowledge amount proposed in Definition 5.17 may be used to measure the certainty degree of a given knowledge structure in the same knowledge base. That is to say, the more uncertain the available knowledge is, the smaller the knowledge amount value becomes.
Properties
Suppose X
i
= {x
i1, x
i2, ⋯, x
is
i
}, |X
i
| = s
i
. Then
Since {X 1, X 2, ⋯, X m } is a partition on U, ∀ i, we have
Then
Then
By Theorem 5.20, E (K (P)) =1 - G (K (P)).
Thus
Suppose X
i
= {x
i1, x
i2, ⋯, x
is
i
}, |X
i
| = s
i
. Then
Thus
By Theorem 5.22, H (K (P)) = log 2 n - E r (K (P))
Thus 0 ≤ H (K (P)) ≤ log 2 n.
Examples
R
1, R
2 ∈ R and
By Definition 3.4, one can obtain that
Thus
Pick
This example illustrates the fact that knowledge distance between knowledge structures in a given knowledge base is neither invariant nor inverse invariant under homomorphisms.
U/R 2 = {{x 1, x 4, x 11, x 12, x 13, x 14, x 15}, {x 2, x 3, x 5, x 6, x 7, x 8, x 9, x 10}},
By Definition 5.2,
By Definition 5.8,
By Definition 5.11,
By Definition 5.17,
Thus
Pick
Thus
This example illustrates the fact that knowledge granulation, knowledge entropy, rough entropy and knowledge amount of knowledge structures in a given knowledge base are neither invariant nor inverse invariant under homomorphisms.
Below, we give a numerical experiment example to show the feasibility of the proposed measures.
The information system (U, A) of postoperative patients
The information system (U, A) of postoperative patients
(1) Denote P i = ind ({a i } (i = 1, 2, 3, 4, 5, 6, 7, 8, 9),
PP = {P 1, P 2, P 3, P 4, P 5, P 6, P 7, P 8, P 9}. Then (U, PP) is the knowledge base induced by the information system (U, A).
From Table 1, we have
U/P 1 = {{x 1, x 2, x 4, x 5, x 7, x 9, x 10}, {x 3, x 6, x 8}},
U/P 2 = {{x 1, x 3, x 4, x 6, x 7, x 10}, {x 2, x 9}, {x 5, x 8}},
U/P 3 = {{x 1, x 2, x 4, x 5, x 7, x 9, x 10}, {x 3, x 6, x 8}},
U/P 4 = {{x 1, x 6, x 8, x 9, x 10}, {x 2, x 3, x 4, x 5, x 7}},
U/P 5 = {{x 1, x 2, x 3, x 4, x 5, x 6, x 7, x 9}, {x 8, x 10}},
U/P 6 = {{x 1, x 2, x 3, x 5, x 6, x 7, x 9, x 10}, {x 4, x 8}},
U/P 7 = {{x 1, x 2, x 5, x 8, x 9}, {x 3, x 4, x 7, x 10}, {x 6}},
U/P 8 = {{x 1, x 4, x 6}, {x 2, x 3, x 5, x 8, x 9, x 10}, {x 7}},
U/P 9 = {{x 1, x 3, x 4, x 5}, {x 2, x 6, x 7, x 8, x 9, x 10}}. By Proposition 5.3,
By Proposition 5.9,
The knowledge granulation and knowledge amount are shown in Fig. 3. It can be seen that G (K (P)) + E (K (P)) =1. The rough entropy and knowledge entropy are shown in Fig. 4. It can be seen that E r (K (P)) + H (K (P)) = log 2 10.


(2) Put
Q i = ind ({a 1, a 2, ⋯, a i }) (i = 1, 2, ⋯, 9).
Then
U/Q 1 = {{x 1, x 2, x 4, x 5, x 7, x 9, x 10}, {x 3, x 6, x 8}},
U/Q 2 = {{x 1, x 4, x 7, x 10}, {x 2, x 9}, {x 3, x 6}, {x 5}, {x 8}},
U/Q 3 = {{x 1, x 7, x 10}, {x 2}, {x 3}, {x 4}, {x 5}, {x 6}, {x 8}, {x 9}},
U/Q 4 = {{x 1, x 10}, {x 2}, {x 3}, {x 4}, {x 5}, {x 6}, {x 7}, {x 8}, {x 9}},
U/Q 5 = {{x 1}, {x 2}, {x 3}, {x 4}, {x 5}, {x 6}, {x 7}, {x 8}, {x 9}, {x 10}},
U/Q 6 = ! {{x 1}, {x 2}, {x 3}, {x 4}, {x 5}, {x 6}, {x 7}, {x 8}, {x 9}, {x 10}},
U/Q 7 = {{x 1}, {x 2}, {x 3}, {x 4}, {x 5}, {x 6}, {x 7}, {x 8}, {x 9}, {x 10}},
U/Q 8 = {{x 1}, {x 2}, {x 3}, {x 4}, {x 5}, {x 6}, {x 7}, {x 8}, {x 9}, {x 10}},
U/Q 9 = {{x 1}, {x 2}, {x 3}, {x 4}, {x 5}, {x 6}, {x 7}, {x 8}, {x 9}, {x 10}}.
By Proposition 5.3,
By Proposition 5.9,
The results of uncertainty measures are shown in Fig. 5. It can be seen the fact that with the attribute subset B ⊆ A growth, the knowledge granulation and rough entropy of K (ind (B)) are both monotonically decreasing. Meanwhile, the knowledge amount and knowledge entropy of K (ind (B)) are both monotonically increasing with the attribute subset B ⊆ A growth. This means that knowledge granulation, rough entropy, knowledge amount and knowledge entropy can be applied to measuring uncertainty of a given knowledge structure in the same knowledge base. □

In this paper, knowledge structures in the same knowledge base are further studied and invariant characteristics of knowledge structures in a knowledge base under homomorphisms have been obtained (see Table 2). Moreover, measuring uncertainty of knowledge structures in the same knowledge base is investigated. These results will be important in establishing a framework of granular computing in knowledge bases. In the future, we will study the other invariant characteristics of knowledge structures in a knowledge base under homomorphisms and consider applications of the proposed measures in knowledge discovery of knowledge bases.
Invariant and inverse invariant characteristics of knowledge structures in a knowledge base under homomorphisms