
Abstract
Micro-expressions reveal a person’s true feelings and motivations, and they can be so subtle that they are difficult to recognize. Micro-expression recognition can be used for criminal justice and national security. The existing methods usually extract the same micro-expression features from three different orthogonal planes, but cannot accurately reflect the characteristics of different space features, so the actual recognition rate is low. According to the motion and appearance information of micro-expression sequences in the temporal domain and spatial domain, this paper proposes a micro-expression recognition method based on spatiotemporal features selection. The Improved Local Directional Number Pattern (ILDNP) in the spatial domain and the Pyramid of Histograms of Orientation Gradients without Edge Extraction (PHOG-WEE) in the temporal domain are extracted individually and fused in the spatiotemporal domain to be a micro-expression feature, and then classified by the Support Vector Machine (SVM). Compared with the state-of-the-art LBP-TOP, HOG-TOP, HIGO-TOP, LBPSIP and Gabor algorithms on the SMIC, CASME and CASME II databases, experiments show that the proposed method has a better performance in describing the texture features of different planes, as well as a higher recognition rate on micro-expressions.
Introduction
Face recognition and facial expression recognition have been widely studied in the field of pattern recognition [1–4], and micro-expression is a special type of facial expression. The main difference between micro-expressions and ordinary facial expressions is that the former are spontaneous and thus cannot be subjectively controlled. They may be the result of emotional suppression and repression which a person may not be able to perceive themselves. Because of these characteristics, micro-expression recognition has received tremendous attention in the field of psychology, image process and pattern recognition. However, due to its short duration and low intensity, research of automatic micro-expression detection and recognition is still a great challenging task [5]. Compared with ordinary facial expression, micro-expressions usually appear in a specific part of the face, and do not appear in the upper half and lower half of the face simultaneously [6]. Therefore, the establishment of micro-expression databases is quite difficult. The existing micro-expression databases are USF-HD [7], Polikovsky [8], SMIC [9], CASME [10] and CASME II [11]. USF-HD and Polikovsky which are posed micro-expression databases built by participants imitating micro-expressions. SMIC, CASME and CASME II are databases of spontaneous micro-expressions established through a specific inducing mechanism. The establishment of these databases promotes the development of micro-expression recognition. On the SMIC, Zhao et al. [9] used the Temporal Interpolation Model (TIM) and Local Binary Pattern from Three Orthogonal Planes (LBP-TOP) to extract micro-expression features from the image sequences, and classified them by Support Vector Machine (SVM). As a result, the recognition rate was 48.78%. On the CASME II, Fu et al. [11] used Active Shape Model (ASM) and LBP-TOP to do the same experiments, and the recognition rate was 63.41%. These two are the baseline of the micro-expression recognition.
Micro-expression recognition methods usually extract optical flow features or the spatiotemporal features and then use the classifier to recognize micro-expressions. By calculating the optical flow field, the optical flow features are extracted which characterize the facial changes. The representative methods are the Main Directional Mean Optical-flow (MDMO) [12] and Facial Dynamics Map (FDM) [13]. The MDMO method extracts the optical flow field of each facial Region of Interest (ROI) and then uses the average optical flow in the main direction of the optical flow in each ROI as the feature to identify and classify micro-expressions. The FDM method calculates the dense optical flow field between two frames in the video sequence and corrects it in the horizontal and vertical directions, respectively. Furthermore, the principal direction of optical flow of each spatiotemporal cuboid is calculated iteratively, and the angle is quantified. Finally, the third-order tensor FDM is formed to represent the feature of micro-expressions. These methods based on optical flow are sensitive to illumination and have high computational complexity.
LBP-TOP is a typical method which extracts feature in the spatiotemporal domain, and it is an extension of Local Binary Pattern (LBP) from two-dimensional space to three-dimensional space. Besides the X-orientation and Y-orientation of a single frame image, a video or image sequence has an orientation along the axis of time, i.e., T-orientation. LBP-TOP extracts LBP features from three orthogonal planes (XY, XT and YT planes), and concatenates them to be a feature of micro-expressions. LBP-TOP not only uses the texture information of XY plane but also records the dynamic texture information of XT and YT planes. Based on LBP-TOP features, SVM, Random Forest (RF) and Multiple Kernel Learning (MKL) are used to detect and classify micro-expressions. This is the initial attempt at recognizing spontaneous micro-expressions [14]. Some researchers improved LBP-TOP on local descriptor methods [15–17]. Because of the simplicity and efficiency of the local descriptor methods in the spatiotemporal domain, they have become the current leading research in micro-expression recognition.
In addition to the optical flow and spatiotemporal features, Zhang et al. [18] used Gabor to extract micro-expression features. The Principal Components Analysis (PCA) and Linear Discriminant Analysis (LDA) are used to reduce the feature dimensions for recognizing micro-expressions. Gabor can extract texture features on a multi-scale and in a multi-direction with a variety of coarse and fine granularity; it closely approximates to the human visual system in the frequency and direction, and Gabor is particularly suitable for texture representation and discrimination. But it is difficult for the human eye to recognize micro-expressions, so Gabor has limitations in this area. Moreover, the recognition efficiency is affected by large feature dimensions, because Gabor parameters setting is more complex. The existing hand-crafted features have a limitation in a sense, because they rely on some prior knowledge, Kim et al. [19] used Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) to learn the spatial and temporal features of micro-expressions. CNN and LSTM require a large number of samples for training and learning, so the existing micro-expression databases cannot meet this need.
Most of the spatiotemporal feature extraction methods simply extend a feature into three-dimensional space by extracting the same feature from the XY, XT, and YT planes, and concatenating them into a feature histogram with setting the same or different coefficients. For example, the radius, or the weight of LBP feature, is set differently in three planes. Such methods do not differentiate the information between the spatial domain (XY plane) and the temporal domain (XT and YT planes). For micro-expression recognition, single features cannot reflect the changes in all planes. In the image sequence, the spatial and the temporal domain reflect the appearance and motion information of the object, respectively. This paper proposes a spatiotemporal features selection method by fusing different features to recognize micro-expressions. The contribution of this paper is as follows: Two kinds of features are proposed: the Pyramid of Histograms of Orientation Gradients without Edge Extraction (PHOG-WEE) from the XY plane and the Improved Local Directional Number Pattern (ILDNP) from the XT and YT planes, respectively. PHOG-WEE reflects the appearance information, and ILDNP reflects the direction and intensity information, these two features from the three planes are concatenated into a single micro-expression feature histogram. The proposed method can reflect the changes in micro-expressions from the appearance of the face, the direction, and the intensity.
The remainder of the paper is organized as follows. Section 2 briefly reviews the related work. Section 3 introduces the proposed ILDNP and PHOG-WEE features. In Section 4, the micro-expression recognition method based on spatiotemporal features selection is described. Experiment results and analysis are given in Section 5. The paper is summarized with a conclusion in Section 6.
Related work
Micro-expression recognition methods based on spatiotemporal features generally extract the same features from three orthogonal planes and recognize them by classifiers.
Due to the short duration and low intensity of micro-expressions, the data is sparse, and so the video sequence is usually preprocessed and magnified by Eulerian Video Magnification (EVM) [20]. Different features are extracted on the preprocessed micro-expression sequences. After using EVM to magnify the sequences, Wang et al. [21] extracted LBP-TOP feature, and Li et al. [22] extracted Histograms of Oriented Gradients from Three Orthogonal Planes (HOG-TOP) and Histograms of Image Gradient Orientation from Three Orthogonal Planes (HIGO-TOP) features to recognize micro-expressions. According to the literature [15], other researchers did not use EVM but directly applied Robust Principal Component Analysis (RPCA) to extract sparse information, and then extracted Local Spatiotemporal Directional Features (LSTD) from the subtle motion video sequences. LSTD can extract more information in the spatiotemporal domain than LBP-TOP, but it considered only the horizontal and vertical intensity differences, without considering diagonal and other directions. However, the muscle motion on the human face is not always along horizontal or vertical directions.
As mentioned above, LBP-TOP is a simple and efficient feature for micro-expression recognition, but it only extracts sign information between pixels, without considering magnitude and direction information, and thus leads to a low recognition rate. Some researchers try different strategies to improve it. Huang et al. [16] proposed Completed Local Quantization Patterns (CLQP) by extracting the information about the sign, magnitude, and orientation from the center pixel and its neighboring pixels based on the LBP algorithm. Similar to LBP-TOP, the CLQP features from XY, XT, and YT planes are extracted and then concatenated into one feature histogram, which is called SpatioTemporal Completed Local Quantization Patterns (STCLQP). Then, vector quantization and codebook selection are used to code the three components of CLQP in each plane to analyze micro-expressions, the result is that STCLQP has a better performance. In the LBP-TOP, six intersections of three orthogonal planes are used twice and obtain redundant information. Wang et al. [17] proposed the algorithm of LBP with Six Intersection Points (LBP-SIP) to reduce the redundancy of LBP-TOP, the six intersections of three orthogonal planes are divided into a set of spatial neighborhood points and a set of temporal neighborhood points, and each point is used only once to extract the spatial and temporal texture features. With this method, the feature dimensions are significantly reduced and the time efficiency is improved.
Considering the shape information of micro-expressions, Huang et al. [23] proposed SpatioTemporal Local Binary Pattern with Integral Projection (STLBP-IP) by combining the integral projection with the LBP. STLBP-IP calculated horizontal and vertical integral projections on difference images for extracting shape attribute. One-dimensional local binary pattern (1D-LBP) is calculated on the integral projection in an image, and the LBP feature is extracted from the texture images which are obtained by formulating the horizontal integral projections from all difference images in a video clip. STLBP-IP not only preserves the shape attribute of the micro-expressions but also extracts the appearance and motion information, and enhances the micro-expression recognition ability. Further, Huang et al. proposed Discriminative Spatiotemporal Local Binary Pattern with Revisited Integral Projection (DiSTLBP-RIP) [24]. The DiSTLBP-RIP feature is extracted by RPCA to get subtle motion images, and then the group feature selection based on Laplacian method is used to improve the discriminating power of the features.
Combining LBP-TOP with other features is also a common method for micro-expression recognition. Liong et al. [25] used the Optical Strain Features (OSF) to describe the pixel-level motion features and the weighted block-based LBP-TOP to encode the dynamic texture features of face image blocks, then concatenated the two kinds of features to recognize micro-expressions.
Wang et al. [26] extracted the LBP-TOP in different color spaces and proposed the tensor independent color space (TICS), in which LBP-TOP features are extracted from the three color channels of TICS. The recognition rate of this method increases, in comparison with gray and RGB color spaces, but is no more superior to CIELab and CIELuv color spaces.
The existing micro-expression recognition methods based on spatiotemporal features extract the same feature in the spatial domain and the temporal domain, but cannot catch the real micro-expression changes, and thus they lead to a low recognition rate. Therefore, in this paper, a micro-expression recognition method based on spatiotemporal features selection was proposed which extracts different features in the spatial and temporal domain according to the different characteristics of micro-expressions.
Feature extraction
In this paper, two kinds of features are extracted to recognize micro-expressions: they are (1) the ILDNP, which extracts both the direction and intensity information from the XT, YT planes, and (2) the PHOG-WEE, which extracts appearance information from the XY plane.
ILDNP
LBP is a first-order derivative local descriptor, which encodes the relationship between a pixel and its neighboring pixels. LBP is not sensitive to direction, but it is susceptible to non-monotonic illumination, random noise, and pose. In order to overcome these drawbacks, Jabid et al. [27] improved LBP and proposed the Local Directional Pattern (LDP). There are three steps for LDP calculation: (1) Kirsch edge operators (see Fig. 1) are applied to each pixel to get eight edge response values; (2) the edge response values are arranged in descending order by their absolute value, and the first t edge response values are set to be 1, while the others are set to be 0; (3) a binary encoding of 8-bit is obtained by bit string coding. LDP uses the absolute value to code the edge response values with binary strings and ignores the information contained in the response sign, resulting in a loss of direction information. To solve these problems, Ramirez et al. [28] proposed a local descriptor, the Local Directional Number Pattern (LDNP), which encodes direction information of the facial texture in a more concise manner using the main direction number and its sign to form a 6-bit binary pattern. LDNP enables to encode different textures with similar structure patterns. Thus LDNP is widely used in facial expression recognition.
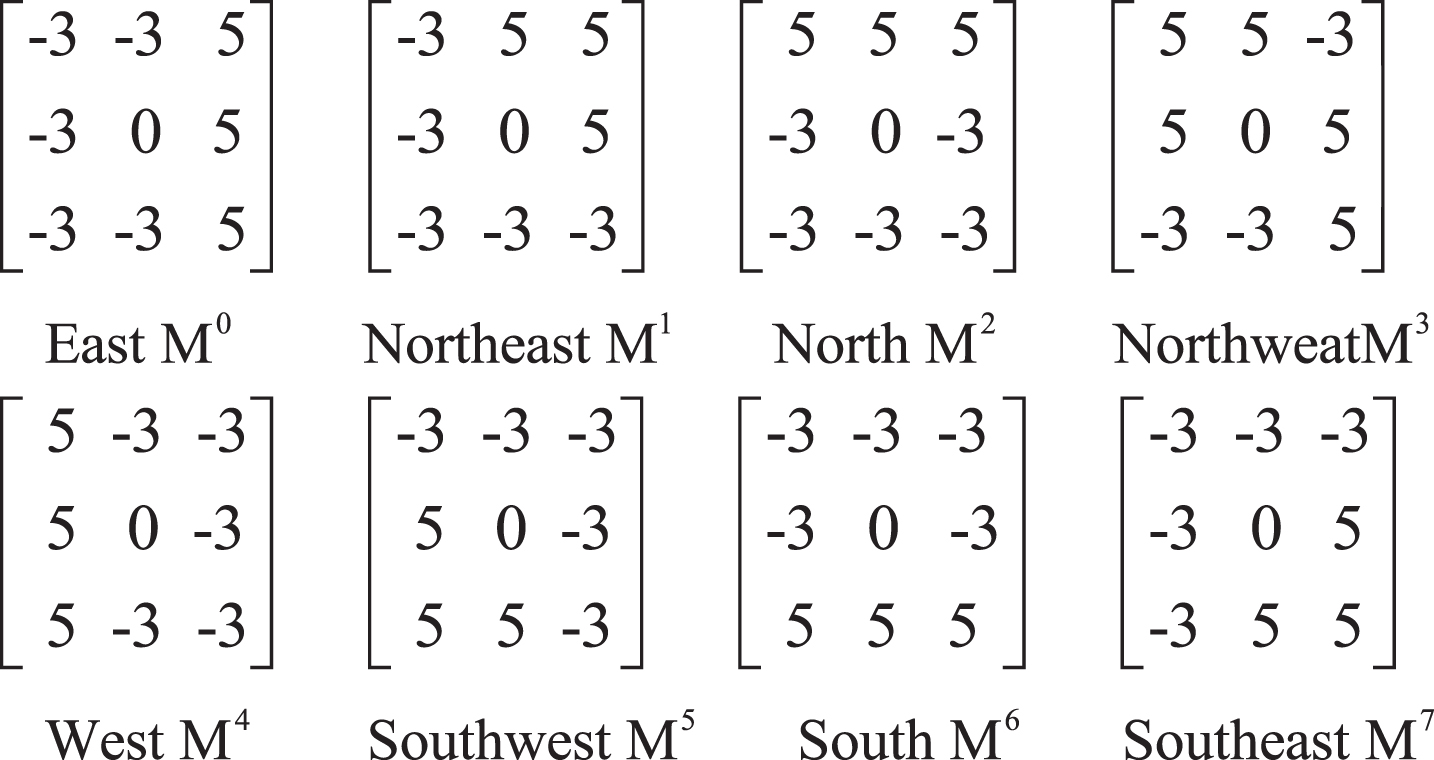
Kirsch edge operators in eight directions.
The calculation of LDNP is shown in Fig. 2, and the procedure includes two steps:

LDNP edge response values calculation. (a) LDNP computation; (b) The LDNP code of center pixel g c .
Firstly, calculate the eight edge response values m0 ∼ m7 by convoluting the 3×3 window with the Kirsch edge operators M0 ∼ M7, then mark their positions as 0 to 7, as shown in Fig. 2(a);
Secondly, encode the position of the maximum positive edge response value maxIndex and the position of the minimum negative edge response value minIndex by the position information. The LDNP value is defined as follows:
LDNP implicitly stores the local direction microstructure information of the image by recording the position information of the principal edge responses, which is consistent with the subtle variation in the intensity of the micro-expressions. Therefore, LDNP is used to extract the micro-expression features in this paper. However, since LDNP only encodes the direction information, using this value to represent the central pixel value, it ignores the relationship of intensity information between the two principal direction pixels and the central pixel.
In this paper, LDNP is improved by fusing the direction and intensity information. The calculation of ILDNP consists of two parts: direction information ILDNP
direction
and intensity information ILDNP
intensity
. The calculation of the ILDNP
direction
is the same as that of LDNP, as shown in Equation (2).
The ILDNP
intensity
is calculated as follows:
Where U (x) is a Unit Step Function, dmax and dmin are the pixel difference between the maximum and minimum with the central pixel g c , respectively.
There are two strategies when fusing the direction and intensity information: one is early fusion which is denoted as ILDNP early , and the other is late fusion which is denoted as ILDNP late .
Early fusion means fusing the direction and intensity features at the pixel level and concatenating the binary codes of the two features into a binary code. Late fusion brings together the direction and intensity features at the image level and computes the two histograms of the two features, respectively, and then concatenates them into a single histogram.
Early fusion is an 8-bit binary string which is obtained by concatenating the 6-bit binary string of direction information and 2-bit binary string of intensity information for each pixel. The ILDNP
early
value of each pixel is calculated by the Equation (4), and its histogram feature is calculated by the Equation (5):
where
Where k1 is the value of ILDNP early (g c ) and k1 ∈ [0, 255]. H and W are the height and width of images.
Late fusion calculates the direction and intensity information histogram by using the Equations (7 and 8), respectively and then concatenate them into a single feature histogram.
ILDNP effectively exploits the intensity and direction difference information between the two principal pixels and the central pixel, so it can better describe the texture feature of micro-expressions. The efficiency of two fusion strategies are discussed in the experiments.
Anna Bosch et al. [29] proposed Pyramid of Histograms of Orientation Gradients (PHOG), which described the shape attribute of objects with spatial and gradient information. The PHOG calculation principle is as follows: Use Canny operator to calculate the edge of the image; Divide the edge image into l levels (l = 0, 1, 2, …, L - 1), the original image in the lth level is divided into 2
l
× 2
l
block regions; Calculate the orientation gradients using a 3×3 Sobel mask without Gaussian smoothing for each sub-region at each level. The orientations are in the range of [0°, 180°] or [0°, 360°], and are quantized the orientations into K bins. Each bin in the histogram depends on the gradient magnitudes that have orientations within a certain angular range. The final PHOG feature for the image is a concatenation of all the histograms.
PHOG describes the gradient feature and the shape attribute of the image. It is widely used in image retrieval, target detection, scene classification and other fields. Because PHOG can calculate the distribution of gradient direction at different levels, it can directly reveal the local and spatial gradient structure information of the facial image, and the gradient information is not sensitive to illumination change. Therefore, PHOG is used to extract the XY plane feature of micro-expressions in this paper. Due to the subtle variation of micro-expressions, it is difficult to distinguish by shape features, so the Canny edge detection in step 1 is removed when calculating the PHOG, namely PHOG-WEE. Then pyramid segmentation is performed on each facial micro-expression image, and the gradient features of all pixels are calculated in each sub-region to obtain the PHOG-WEE feature of micro-expressions.
Spatiotemporal features selection
Micro-expression recognition usually has three steps: preprocessing, feature extraction, and classification. In 2012, Wu et al. [20] applied spatial decomposition followed by temporal filtering for each frame to propose EVM algorithm, and the obtained signal was amplified to reveal hidden information. The EVM can capture tiny changes in the video that are invisible to the naked eye. In this paper, EVM algorithm is used to preprocess micro-expression videos and then the videos are decomposed into image sequences. The faces are cut out, and the median filter is further used to reduce the noise caused by EVM.
As mentioned above, micro-expression recognition methods based on spatiotemporal features, such as LBP-TOP, usually extend LBP to spatiotemporal three-dimensional space (XY, YT, and XT planes) [30]. However, in a micro-expression video sequence, the XY plane reflects the changes in the spatial domain, but the changes are not obvious. The XT and YT planes are the changes in the temporal domain. The motion feature has larger changes than that of the appearance feature. A single feature cannot reflect the appearance and motion characteristics at the same time. In this paper, the proposed method extracts the ILDNP feature for the motion feature and the PHOG-WEE feature for the appearance feature. Firstly, in the micro-expression sequence, the PHOG-WEE feature is extracted from the XY plane; the pyramid segmentation is performed on the facial expression images in the XY plane, and the gradient features of all the pixels in each sub-region are calculated to obtain the feature histogram of XY plane. Secondly, the ILDNP values of all pixels from the XT/YT plane of the micro-expression sequence are calculated by Equation (4), and the histogram of the XT/YT plane is calculated by Equation (5). Finally, the feature histograms of the three planes are concatenated into a single histogram as the feature of micro-expression sequence. The PHOG-WEE extracts appearance feature at different levels and describes the spatial layout feature, which has the reliable robustness to noise and rotation of the face.
The schematic diagram of the feature extraction method in this paper is shown in Fig. 3. Figure 3(a) is a micro-expression image sequence; the first frame is the XY plane which characterizes the appearance of the micro-expressions. The upper part of Fig. 3(b) is the XT plane which characterizes the horizontal movement of the micro-expressions when the Y-orientation is fixed. The lower part of Fig. 3(b) is the YT plane which characterizes the vertical movement of the micro-expressions when X-orientation is fixed. Figure 3(c) are the histograms of the XY, XT and YT planes, which are obtained by extracting PHOG-WEE feature from XY plane, ILDNP feature from XT and YT planes. And Fig. 3(d) is the concatenated feature histogram formed by the three feature histograms in Fig. 3(c). It can be seen that the XY plane is the appearance image of the human face. The XT plane is the image, which is formed by the pixels on each line of the XY plane varying with time, and the YT plane is the image, which is formed by the pixels on each column of the XY plane varying with time. The texture of the XY plane is different from the texture of the XT and YT planes. It is necessary to select different feature extraction methods for different planes. The concatenated feature histogram describes the appearance and motion information and provides more details for micro-expression recognition. Thus the proposed method is summarized in Algorithm 1.

Feature extraction of micro-expression based on spatiotemporal features selection. (a) A micro-expression image sequence; (b) The XT and the YT planes of the micro-expression image sequence; (c) The PHOG-WEE feature histogram of XY plane and ILDNP feature histograms of XT, YT planes; (d) The final concatenated feature histogram formed by the feature histograms of XY, XT and YT planes.
Algorithm 1 Spatiotemporal Features Selection for Spontaneous Micro-expression Recognition
Databases
SMIC
The SMIC database contains 16 participants and 164 micro-expression samples, which are recorded by a high-speed camera with a resolution of 640×480 and a frame rate of 100 fps. The videos are divided into three categories: Positive, Surprise and Negative. Figure 4 shows a Negative micro-expression sequence in the SMIC database, using cropped faces. Obviously, the changes are very subtle to the human eye, and the naked eye hardly finds any changes in the sequence.

A Negative micro-expression sequence in SMIC.
The CASME database contains 195 samples of micro-expressions, which are labeled onset, apex and offset, as well as action unit (AUs) and micro-expression category. CASME is divided into two parts, CASME-A and CASME-B. The CASME-A is recorded by a BenQ M31 camera with a resolution of 1280×720 and a frame rate of 60 fps. The CASME-B is recorded by a Point Gray GRAS-03K2C camera with a resolution of 640×480 and a frame rate of 60 fps. The samples of CASME are divided into seven categories: Positive (Happiness), Negative (Sadness, Disgust, Fear), Surprise, Tense (Repression, Tense). Figure 5 is a Happiness micro-expression sequence in CASME, the first image is the onset frame, the 14th and 21st images are the apex frames, and the 26th image is the offset frame. For the human eye, there may be no difference between these images.

A Happiness micro-expression sequence in CASME.
In 2014, Fu’s team of the Chinese Academy of Sciences also released an enhanced version of CASME, called CASME II, which contains 247 micro-expression samples recorded at a resolution of 640×480 and a frame rate of 200 fps, and also marks the onset, apex, offset, action unit (AUs) and micro-expression category. The micro-expression samples are divided into five categories: Happiness, Disgust, Surprise, Repression, and Others. Figure 6 is a micro-expression sequence of Repression in CASME II. As in Fig. 6, the first image is the onset frame, the 11th image is the apex frame, and the 26th image is the offset frame.

An Others micro-expression sequence in CASME II.
The experiments are carried out from three aspects: (1) experiments on the fusion strategies when fusing direction and intensity information of ILDNP; (2) experiment parameters selection of PHOG-WEE; (3) experimental comparison on the proposed algorithm and LBP-TOP, LBP-SIP, Gabor, HOG-TOP, and HIGO-TOP. All experiments are on three publicly available databases SMIC, CASME and CASME II. In the experiments, micro-expression samples of each category are randomly selected: on third as the test set, the remaining two thirds as the training set, and the classifier is SVM. All experiments are in Windows 7 system, 6G RAM, processor for Intel (R) Core (TM) i5-2410M CPU @ 2.30GHz, on the MATLAB R2014b platform.
Fusion experiments of ILDNP
In order to validate the recognition effect of ILDNP on micro-expressions, experiments were carried out on LDNP-TOP and ILDNP-TOP with two fusion strategies, ILDNP early -TOP, ILDNP late -TOP. ILDNP early -TOP means to combine direction and intensity features at the pixel level, while ILDNP late -TOP refers to combine the direction and intensity features at the image level. The recognition rates are shown in Table 1.
Recognition rates of LDNP-TOP, ILDNP
early
-TOP, and ILDNP
late
-TOP
Recognition rates of LDNP-TOP, ILDNP early -TOP, and ILDNP late -TOP
From Table 1 it can be seen that the late fusion method has the highest recognition in the three methods. Therefore, ILDNP late is used in this paper.
To validate the recognition rate of ILDNP late in different planes, the ILDNP late feature is extracted from the XY, XT and YT planes, respectively. Table 2 is the recognition rate of ILDNP late on the SMIC, CASME, CASME II with different planes.
Recognition rates of ILDNP late with different planes
It can be seen from Table 2 that on the three databases, the recognition rates of ILDNP late on XT and YT planes are higher than that of XY plane, while the ILDNP late performs relatively poor in the XY plane. So ILDNP late is selected to extract features in XT and YT planes, not in XY plane.
In this paper, the angle of PHOG-WEE is set to [0°, 360°], the number of levels L and the number of quantified angle K need to be determined experimentally. Since PHOG-WEE is used to extract the XY plane feature, the experiments of the PHOG-WEE parameters are performed on the XY plane on CASME II. Table 3 shows the recognition rates of PHOG-WEE from the XY plane on the CASME II when L takes 0, 1, 2, 3, 4, 5 and K takes 3, 6, 9, 12, 15.
Recognition rates of PHOG-WEE from the XY plane with different L and K
Recognition rates of PHOG-WEE from the XY plane with different L and K
As can be seen from Table 3, when L is fixed and K = 12, the four highest recognition rates are obtained. When K is fixed and L = 3, the three highest recognition rates are obtained. The parameters L and K of the PHOG-WEE take 3 and 12, respectively.∥In order to validate the effectiveness of PHOG-WEE in the XY plane, this paper extracted the PHOG-WEE from the XY, XT and YT planes, respectively. Table 4 shows the recognition rates of PHOG-WEE with different planes.
Recognition rates of PHOG-WEE with different planes
From Table 4 it can be seen that on the CASME and CASME II, the recognition rate of the PHOG-WEE in the XY plane is higher than elsewhere. On the SMIC, although the recognition rate of PHOG-WEE in the XY plane is lower than that of the YT plane, it is higher than that of XT plane. From Tables 2 and 4, on SMIC, CASME and CASME II, the recognition rate of PHOG-WEE is higher than that of ILDNP from the XY plane. Therefore, PHOG-WEE is used to extract the XY plane features of micro-expressions.
To validate the effectiveness of the method, we add the confusion matrix in the experiments. Figure 7–9 are the confusion matrices of the proposed method on SMIC, CASME and CASME II, respectively. It can be seen that on the SMIC, it did not perform well in the Positive class which is the result of the broad classification in this database. On the CASME, the proposed method also has a poor recognition rate in the Positive class. Most of the Positive class has been recognized as an Others class, because the Others class represents uncertain emotions, and further inference is needed in CASME. On CAMSE II, the recognition rate in Disgust class is low. Most of the Disgust class is recognized as Surprise and Repression, because these three classes have similar expression changes. As a whole, good recognition rates are achieved.

Confusion matrix of the proposed method on SMIC.

Confusion matrix of the proposed method on CASME.

Confusion matrix of the proposed method on CASME II.
To further validate the effectiveness of the proposed method, it is compared with state-of-the-art micro-expression recognition methods. LBP-TOP [21] is a classical representative micro-expression recognition algorithm in the spatiotemporal domain. HOG-TOP [22] and HIGO-TOP [22] are micro-expression automatic recognition methods based on the gradient. LBP-SIP [17] is successful in many improved methods of LBP-TOP. The frequency and direction of Gabor filters are similar to those of simple cells in the human visual system, and so they are particularly suitable for texture representation and discrimination [18]. Since these methods do not publicly make available the source code, all the comparative methods adopt the same preprocessing as the proposed method in this paper and use SVM as a classifier. All codes are encoded by the authors. These codes are available at https://github.com/DuanHuiyan/CODES. Table 5 shows the comparison of the proposed method and other state-of-the-art methods on SMIC, CASME, and CASME II. It can be seen that on SMIC, the proposed method has the same recognition rate as LBP-TOP, and is higher than that of other algorithms. On CASME and CASME II, the proposed method has the highest recognition rate. LBP-TOP, HOG-TOP, and HIGO-TOP extend a feature into three-dimensional space and extract the same feature from XY, XT and YT planes, respectively, but the same feature may not be suitable for all planes. LBP-SIP only use the six intersections of three orthogonal planes which can be seen as four neighborhoods of LBP features from the XY plane and two neighborhoods of LBP features using the previous frame and the latter frame at the same location; thus some information in the temporal domain is lost. Gabor’s multi-scale and multi-direction cause high-dimensional micro-expression features, resulting in low classification efficiency. The proposed method extracts different features from the XY plane and XT, YT planes, and experiments show that the extraction of appearance and motion information by different features is beneficial to the recognition of micro-expressions.
Comparison with other algorithms on SMIC, CASME, CASME II
The existing micro-expression recognition methods based on the spatiotemporal domain usually extract the same feature from three orthogonal planes and cannot reflect the motion and appearance feature. This paper proposes a new spatiotemporal features selection method where the spatial domain (XY plane) features and the temporal domain (XT and YT planes) features are extracted respectively. Because the XY plane describes the facial appearance, and the XT and YT planes describe the facial movement of the micro-expressions, such as the information about how the eyes, mouth, eyebrows, etc., change over time. PHOG-WEE is extracted from the XY plane and ILDNP which fuses direction and intensity information is extracted from the XT and YT planes. Then we use SVM for micro-expression recognition, achieving a higher recognition rate than existing methods. The method of calculating the edge response takes a long time in this paper. Also, the same feature is extracted from the XT and YT planes. However, the XT and YT planes express horizontal and vertical motion information, respectively and perhaps should be treated differently. Exploring new feature extraction methods and trying to extract novel feature extraction methods in three planes will be the focus of future research.
Footnotes
Acknowledgments
This work was granted by the National Natural Science Foundation of China (Grant No. 60302018), Tianjin Sci-tech Planning Projects (Grant No. 14RCGFGX00846), Tianjin Sci-tech Planning Projects (14JCYBJC18500), Tianjin Sci-tech Planning Projects (Grant No. 15ZCZDNC00130), Tianjin Sci-tech Planning Projects (Grant No. 17ZLZDZF00040) and the Natural Science Foundation of Hebei Province, China (Grant No. F2015202239). The authors would like to thank the editors and anonymous reviewers for their helpful comments and suggestions.