
Abstract
In this paper, a novel learning frameworks–multiple rank multi-linear twin support matrix classification machine (MRMLTSMCM) is outlined, as an extension of twin support vector machine (TWSVM). Different from TWSVM, MRMLTSMCM uses two pairs of projecting matrixes to construct the pair of functions, which are used to establish decision function. Compared with the vector-based method, the matrix-based could not only keep the structure of the matrix data but also reduce computational complexity. In addition, a regularization term is considered adding to improve the performance of MRMLTSMCM. Moreover, a novel algorithm for MRMLTSMCM is introduced. Finally, experimental results show the effectiveness of the method by classification accuracy, convergence behavior and computation time.
Introduction
Nowadays, the tensors, as common forms are more and more widely used in various kinds of real applications. For example, visual recognition [1, 2], face recognition [3] photorealistic image of palms [4], medical images [5, 6] and so on. In fact, the matrix is a two order tensor, which can build a bridge between the vector and the higher order tensor. So we mainly consider the classification problem with the matrix inputs in this paper.
However, traditional classification methods are usually vector-based. The representation of inputs in algorithm is assumed as the vector, not matrix or tensor. When they are applied to matrix data, the matrix data have to be transformed to vector inputs. The most commonly way is to reformulate a vector by connecting each row or column of a matrix.
Although traditional classification methods have achieved satisfactory result in many cases, they may lack efficiency when the matrix data are transformed into vector form data [7]. There are many reasons: firstly, the structural information of these matrix data would be destroyed; secondly, the computation time will increase drastically with the increase of dimensionality because the dimensionality of reformulated vector is often very high; thirdly, the spatial correlations of the matrix will be lost when a matrix is collapsed as a vector. In order to settle these problems, there are mainly two types of methods. The first type of methods is projecting matrixes into vectors to reduce dimensionality, such as principal component analysis (PCA) [8], linear discriminant analysis (LDA) [9]. Nevertheless, since most of these methods are unsupervised, label information will be lost in learning subspace. The other type of method, support tensor machine (STM) [10 –14], is extended by support vector machine (SVM) [15 –18]. STM classifies tensor inputs directly. Obviously, the computation time is reduced in a large scale, however, there maybe some problems, such as large training error and under fitting. Recently, multiple rank multi-linear SVM (MRMLSVM) [7] combine SVM with STM, introduce a novel matrix classification model, using left and right multiple rank projections instead of STM’s left and right projecting vectors. MRMLSVM has achieved more higher accuracy compared with SVM and STM and less computation time compared with SVM in many matrix data classification. Nevertheless, the results of MRMLSVM for some matrix data classification are not too well, e.g., image of palms. As an extension of MRMLSVM, a novel nonlinear classifier for linear inseparable multiple rank matrix data classification problem by means of a matrix kernel function, named as multiple rank multi-linear kernel SVM(MRMLKSVM) [19]. Different from MRMLKSVM, this paper focuses on the multiple rank multi-linear structure of the matrix data and has a try to improve the performance for matrix data classification, seeking a pair of nonparallel hyperplanes by solving two smaller programming problems such that each one is closer to one of the two classes and keep away from the other. Besides, this paper introduces a novel matrix classification model, using left and right multiple rank projections instead of the left and right projecting vectors of twin support tensor machines (TSTM). It’s called multiple rank multi-linear twin support matrix machine (MRMLTSMCM). Similar to MRMLSVM, MRMLTSMCM is based on matrix input and stop the structural information of matrix data from being destroyed, as well improve the performance of model by choosing a suitable rank for left and right projecting matrix. However, there are some difference: 1), MRMLTSMCM constructs two functions by solving two smaller programming problems. 2), for each objective function of MRMLTSMCM, a regularization term is added and the parameter of regularization term can play a role as a weighting factor which determines the tradeoff between the regularization term and empirical risk. Both on the vector and the matrix inputs, compared with SVM, MRMLSVM, TWSVM, TSTM, MRMLSTMCM obtains the best classification accuracies on different training sets from UCI datasets [20].
The paper is organized as follows: in Section 2, background and methods are introduced, such as linear TWSVM and MRMLTSMCM, the model definition of MRMLTSMCM and corresponding algorithm is developed, in addition, the motivation and extension will be showed too. Computational comparisons on UCI datasets are done in Section 3. Section 4 gives some concluding remarks.
Background and methods
Background
In this section, firstly, two representative models related with our method will be introduced, linear TWSVM and MRMLSVM. For convenience, thefollowing several definitions are given:
Twin Support Vector Machine
Formally, let
The decision function is represented as
Let
Next, the multiple rank multi-linear twin support matrix classification machine is developed, shorten as MRMLTSMCM, to solve the binary classification problem with the matrix inputs. For convenience, the training set (6) is rearranged as the following form
where U 1 = [u 1,1, u 1,2, ⋯, u 1,K ], U 2 = [u 2,1, u 2,2, ⋯, u 2,K ] ∈R m×K , V 1 = [v 1,1, v 1,2, ⋯, v 1,K ], V 2 = [v 2,1, v 2,2, ⋯, v 2,K ] ∈R n×K , and u 1,k ∈ R m , u 2,k ∈ R m , v 1,k ∈ R n , v 2,k ∈ R n , k = 1, 2, ⋯, K. The parameter K is the rank of U 1, U 2 and V 1, V 2. C 1, C 2 are the penalty parameters and C 3, C 4 are the regularization term parameters.
Now, the optimizing alternative algorithm will be used to solve the pair of optimization problems (10)–(11). Now, the optimization problem (10) is just considered to solve because the ways to solve the optimization problems (10) and (11) are similarly.
For the optimization problem (10), firstly, fixing V 1, solving U 1 and b 1. Denote
Next, repeating the above two steps until all of V 1 and U 1 are convergent, b 1 will be convergent too. The same way will be used to obtain U 2, V 2, b 2 by solving the optimization problem (11).
Finally, constructing the decision function
The above procedure can be summarized as following algorithm:
The procedure of MRMLTWSMCM.
For the training set (8) and the parameter K ≤ min {m, n}, select the penalty parameter C 1, C 3 > 0;
Initialize
Solve the QP problem (28) and get the solution α *, compute
and
and
If
Compute U 2, V 2, b 2 by solving the optimization problems (11) similarly;
Output the decision function:
A number of motivations for MRMLTSMCM are outlined here.
Efficiency
For matrix data, compared with the traditional approaches, MRMLTSMCM uses the left and right projecting matrices U 1, V 1 and U 2, V 2 instead of traditional projecting vector w. The efficiency of MRMLTSMCM will be introduced from two points. Compared with TWSVM, the number of variables will be 2K (m + n) +2 reduced from 2 (mn + 1). In addition, reducing the variables can help ameliorate over fitting and improve classification accuracy.
Regularization
For the significance of regularization terms, two points as well compare with TWSVM will be stated. If there were no regularization terms
In order to ensure the optimization problems (35)–(36) are solvable, namely avoid the matrices both H
T
H and G
T
G are singular. An usual way is to approximately replace the inverse matrices (H
T
H) -1 and (G
T
G) -1 by (H
T
H) -1 + ∈I and (G
T
G) -1 + ∈I respectively, where I is an identity matrix of appropriate dimensions, and ∈ is a positive scale, small to keep the structure of data. In the QP problems (28), regularization term
Three propositions about convergence behaviour are going to be given in the following section, to support
Proof of
Obviously, when
In many cases, the input is more likely represented as a matrix or a high order tensor. For example, colour image are naturally represented as a three order tensor. For the n order tensor
The classification model for the above training set (38) corresponding to the optimization problems (10)–(11) are represented as follows
where
In this section, different benchmark data sets are trained by our algorithm introduced in Section 2. Besides, many other methods are compared with MRMLSTMCM in classification accuracy and computational complexity. Classification accuracy, convergence behaviour and the CPU computational time are used to evaluate our method. Finally, some experimental results with different parameter K are given.
Data Sets and Evaluation Index
Ten data sets, from the UCI Repository of machine learning database [20], are Sonar, CMC, Hill-vally, Ionosphere, Madelon, Pedestrian, Pollen, FingerDB, Binucleatet and RGB respectively. In the first five data sets, the inputs are vector, and in the rest are matrix data sets. Especially, Binucleatet is high dimensional matrix data set and RGB is matrix structure image data set. The detail of ten data sets are given in Table 1.
The detail characteristic of the data sets
The detail characteristic of the data sets
#Size is the number of the data points; #Scale is the dimension of the inputs; #Class number is the number of class.
All methods are implemented by using MATLBAR2013b on a PC with an Intel(R)(2.83Hz) with 2GB RAM, respectively.
The ‘Accuracy’, denoting the accuracy of classification result, is used to evaluate methods is defined as follows:
In order to compare the classification accuracy of MRMLTSMCM with SVM, MRMLSVM, TWSVM, TSTM, two groups of data set, vector and matrix data set are chosen. The results of numerical experiments are summarized in Table 2 and 3, respectively. And the inputs of the vector data sets are reformulated into the matrix inputs by the function Mat (·) when the MRMLSVM, TSTM and MRMLTSMCM are implemented (In
The classification accuracies for the vector data set, black font denotes best accuracy
The classification accuracies for the vector data set, black font denotes best accuracy
For each data set, there are two corresponding rows, the first row means the classification accuracies by different methods, the second row means the training time, and the L-SVM and TSVM record one CPU time, while MRMLSVM, TSTM, MRMLS- TMCM record one CPU time with 5 times iterations of U 1, U 2, V 1, V 2 and under the condition K = 2. It’s similar for Table 3.
The classification accuracies for the matrix data set, black font denotes best accuracy
For Pollen data set, we choose 1-th class vs 2-th class, and 2-th class vs 7-th class. For FingerDB data set, we choose 1-th class vs 8-th class. For Binucleate data set, we do singular value decomposition for each data point firstly, and then get the singular values σ 1, σ 2, ⋯ the new input is a diagonal matrix formed by the ahead 100 singular values. □ means this experiment can not be done under the prevailing condition.
In Table 2, the classification results on five vector data sets in five different methods are listed, and the best accuracy is shown by boldface. It is obvious that the accuracy of our method MRMLTSMCM is much better than the other methods on vector data sets. In the process of matrixing, to discovery the influence for accuracy by the different way offolding vector into matrix, we choose two data sets, Sonar and Hill-vally, to train in different ways, respectively. The results are respectively listed in Table 4 and 5. From the two tables, it can be found that different folding ways would affect the classification accuracy when compared each row, and little difference between the best accuracy of eachcolumn.
The classification accuracies for Sonar in different folding ways
–means this experiment has not been done
The classification accuracies for Hill-vally in different folding ways
In Table 3, the accuracy of MRMLTSMCM is as well better than the other methods on all data sets and we obtain an obviously better result than SVM and MRMLSVM for FingerDB. Especially, for Binucleate, do singular value decomposition for each data point firstly, and then get the singular values σ 1, σ 2, ⋯ the new input is a diagonal matrix formed by the ahead 100 singular values. For the new data sets, every method obtain 100% accuracy.
The training time on the several data sets with different scales is listed in Table 2 and 3. Where L-SVM and TSVM record one CPU time, while MRMLSVM, TSTM, MRMLTSMCM record one CPU time with 5 times iterations of U 1, U 2, V 1, V 2 and under the condition K = 2. The CPU time for MRMLSVM, TSTM, MRMLTSMCM is compared and analyzed in follows. From Table 2, the CPU time of MRMLSVM is the most except for Madelon data set, however in Table 3, the CPU time of MRMLSTMCM more than MRMLSVM except for Binucleate data set. There is no doubt that the performance of TSTM is the best.
Finally, for the data set RGB is a set of 40 different classes of colour leaf images. When each image is digitized, a 3-order tensor is obtained. Three sub matrices will be obtained by unfolding the tensor, the first matrix is chosen as training point. Then, we reduce the dimensions of each image by reducing pixel size of image from 720 × 960 into 50 × 66. Seven classes leaf image sets are selected to experiment, we choose only one in each classes and display them in turn in Fig. 1. They are the 11-th(Acer palmaturu), the 18-th(Papaver sp), the 20-th(Pinus sp), the 31-th(Podocarpus sp), the 34-th(Pseudosasa japonica), the 35-th(Magnolia grandiflora) and the 39-th(Schinus terebinthifolius), respectively. Except the 11-th class is obvious broad leaf, the other classes are not broad leaves, and they trend gradually to be broad from the 20-th class to the 39-th class. The results are showed in Fig. 2. From the figure, it can be seen that with difference between classes decreasing, accuracy will cut down too, however keep above 80%.

They are seven different classes of colour leaf images from the 11-th(Acer palmaturu), 18-th(Papaver sp), the 20-th(Pinus sp), the 31-th(Podocarpus sp), the 34-th(Pseudosasa japonica), the 35-th(Magnolia grandiflora) and the 39-th(Schinus terebinthifolius), respectively.
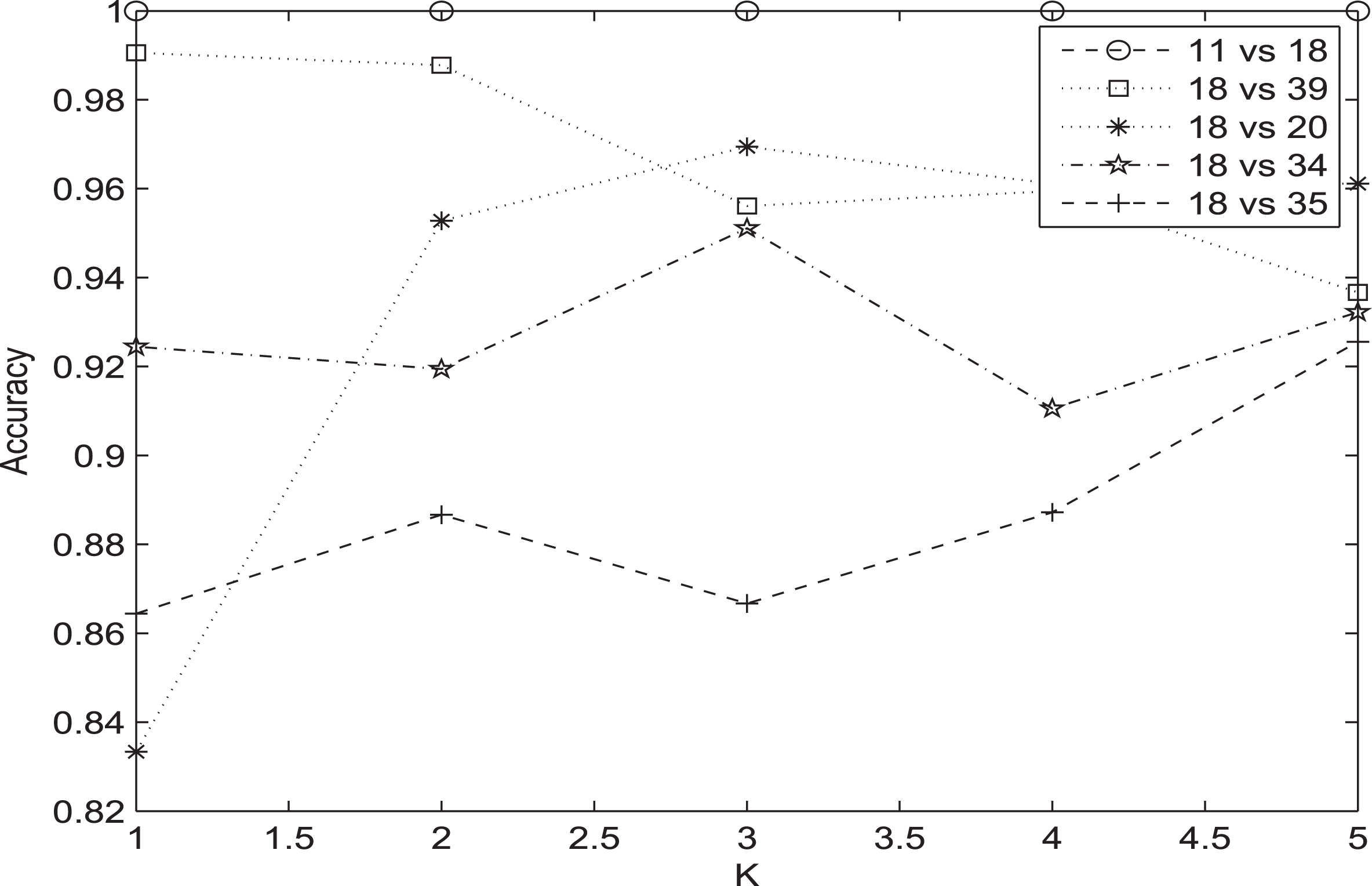
Accuracy-axis represents the classification accuracies for different kinds of leaf image from the data sets RGB, where the 11-th class is obvious broad leaf, the other classes are needle, and trend gradually to the 18-th class from the 20-th class to the 39-th class. The K-axis represents the rank of U 1, U 2 and V 1, V 2.
In this section, some convergence behaviours will be illustrated, corresponding to the accuracy experiments. From the
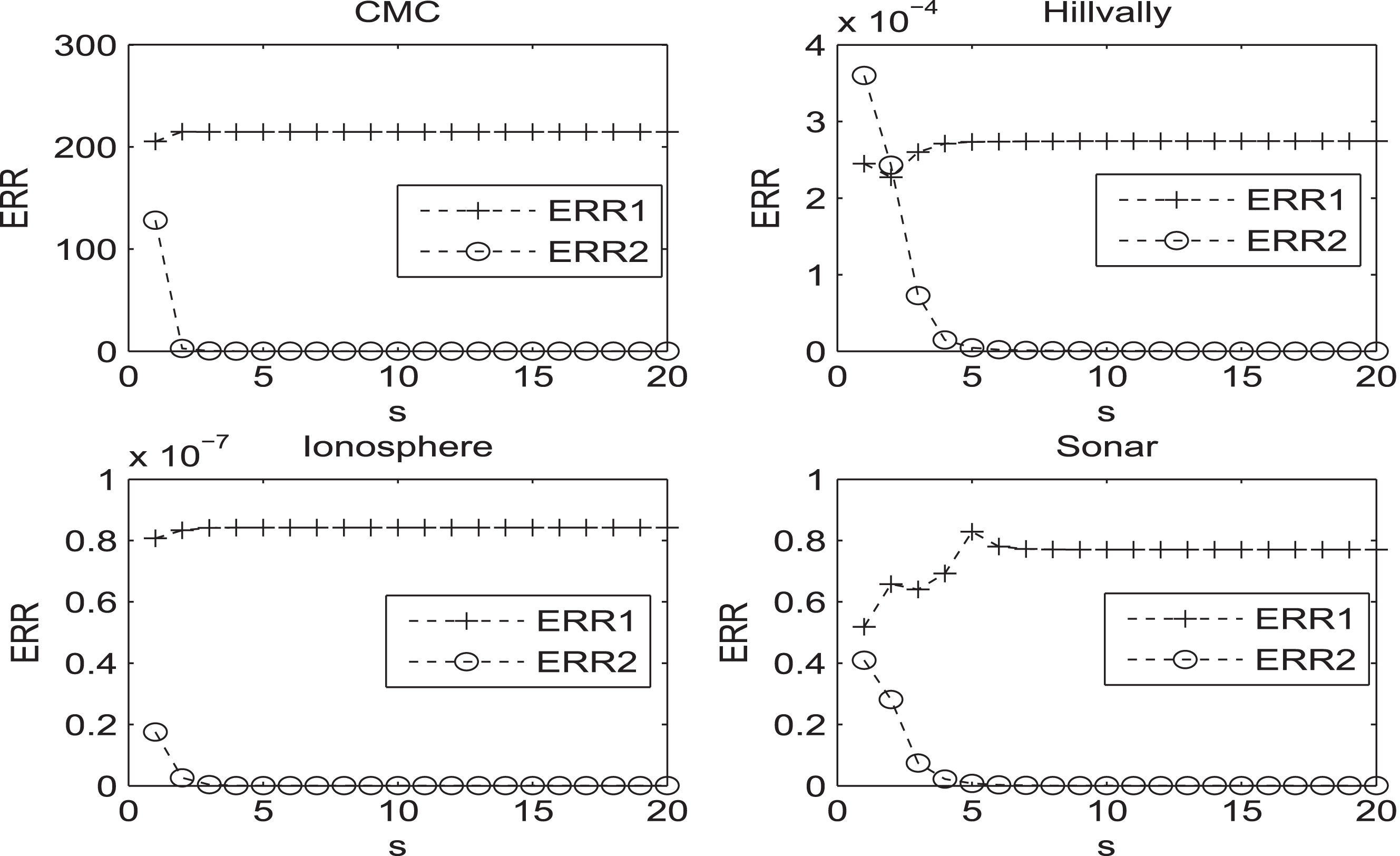
The convergence behaviours, about
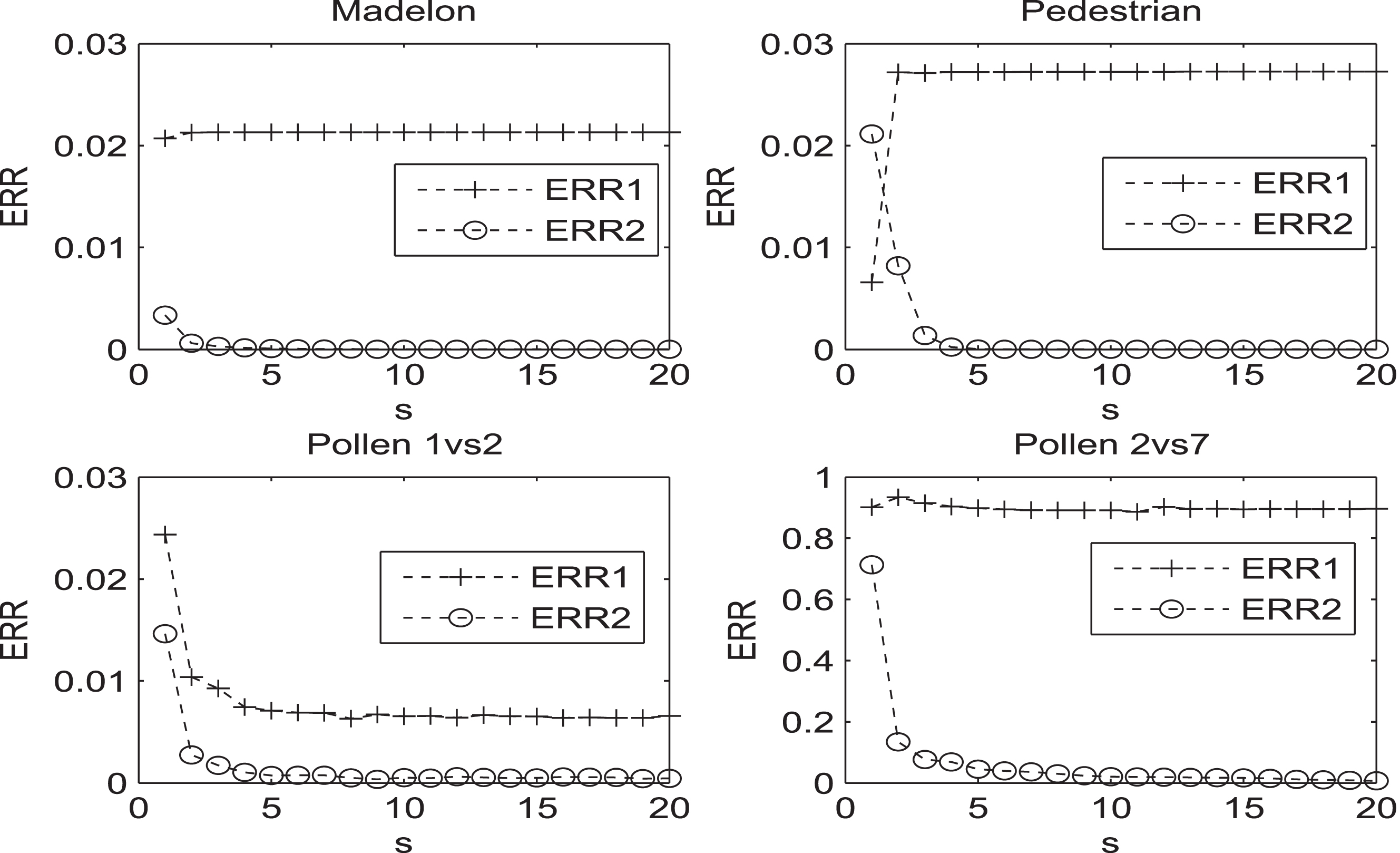
The convergence behaviours, about

The convergence behaviours, about
By the analysis in the Secetion 2.5, the parameter K and C i , i = 1, 2, 3, 4 are related to the performance of MRMLTSMCM. In following parts, we simply analyze the selection for parameter K. Hill-vally, Pedestrian, Pollen(1 vs 2) and RGB(18 vs 31), four different date sets are selected to train. The parameter K is varied from 1 to 10. We use 5-cross validation to choose parameter C i , i = 1, 2, 3, 4 with best classification accuracy. Finally, 15 independent runs and the average classification accuracy are shown in Fig. 6. As seen from the results in Fig. 6, With different parameter K, the accuracy would be different, and the best accuracy corresponding to parameter K are 6, 3, 5, 5, respectively. The results reflect the analysis in Section 6.1, the suitable parameter K reduces the variables can help ameliorate over fitting then improve classification accuracy.
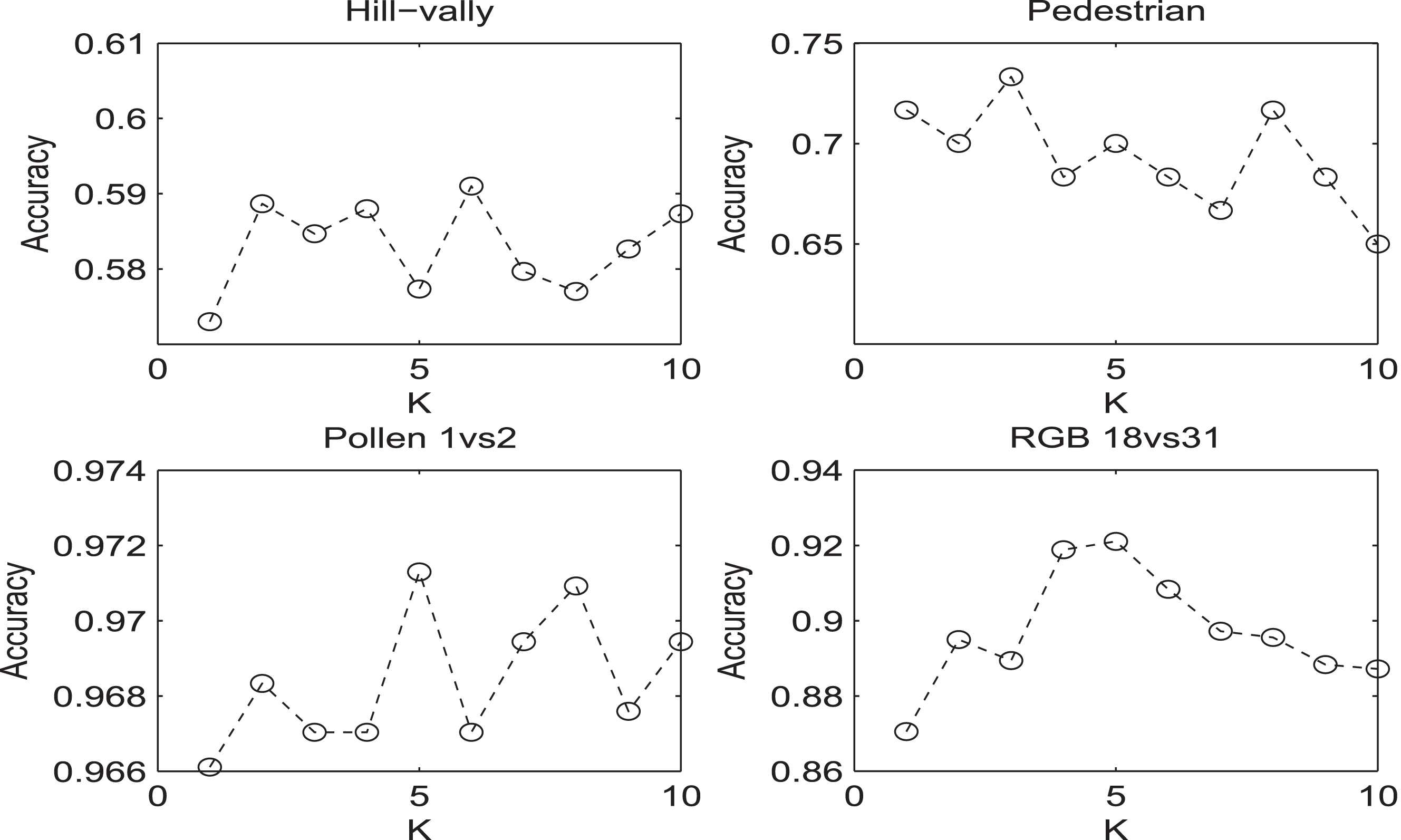
Classification accuracies with different parameter K on Hill-vally, Pedestrian, Pollen (1 vs 2), RGB (18 vs 31) data set, respectively.Where Accuracy-axis represents the accuracies of classification results and the K-axis represents the number of parameter ‘K’.
In this paper, a novel method for matrix data classification is proposed, called as multiple rank multi-linear twin support matrix machine (MRMLTSMCM), which is an extension of TWSVM. In addition, a regularization term is used to improve the performance of MRMLTSMCM. For different kinds of data sets, MRMLTSMCM gets the best classification accuracies compared with some methods. In addition, some experimental results have been proposed to show the effectiveness of our method in convergence behavior, computation time and parameter determination. Nonlinear cases and tensor data classification will be searched in further works.
Appendix
The variation of Scale for the vector data sets
#Prime Scale is the dimension of vector data; #Matrix Scale is the Scale after folding.
Declaration
The authors declare no competing financial interest.