
Abstract
To address the issues of insufficient utilization of data and fixed structure of grey model [GM (1,1)], this paper develops an exponential buffer operator based on the new information and variable parameter principles. Measuring and modifying the fluctuation trend of original data is an obvious advantage of this new buffer operator. Further, we prove the weakening, smoothness, new-information, and incremental-innovation properties of the exponential buffer operator. Then, the improved GM (1,1) model is proposed by combining the GM (1,1) model with the exponential buffer operator. This new model combines the fitting advantages of the GM (1,1) model in small sample environment and the additional advantages of the buffer operator of dealing with disturbance factors. Also, we compare the proposed buffer operators with the general buffer operator and the improved GM (1,1) model with the GM (1,1) model. It is found that not only the improved GM (1,1) model can effectively weaken the fluctuation trend in original data sequence, it also reduces forecasting errors and improves the calculation accuracy under the fluctuation small-sample environment. Finally, based on an empirical forecasting of the coal consumption in China, we demonstrate the feasibility and effectiveness of the improved GM (1,1) model and exponential buffer operator.
Keywords
Introduction
Grey system theory was proposed based on the cybernetics and information theories by Deng [11]. A prominent method of the grey system theory is the GM (1,1) model. The obvious advantage of the GM (1,1) model is that it can fitting and forecast the small-sample sequence, which is different from the classic forecasting approaches such as the time series forecasting [13], the artificial neural network [15], and the granular forecasting [12, 30]. For this reason, the grey system theory and GM (1,1) model have attracted a great deal of attention among experts, researchers and data miners, and have been applied into various fields [2, 27].
Generally, the GM (1,1) model has been developed from two perspectives. The first is the model optimization, namely the GM (1,1) model has been developed by optimizing its background value and other parameters. For example, Shih et al. [6] changed the calculation steps of the background and initial values to improve the accuracy degree of the GM (1,1) model, which is a general optimized method. Zhou and He [25] proposed a generalized GM (1,1) model which is a optimized GM (1,1) model, and its property is that the background value can be obtained by a calculation algorithm. Based on these approaches, Long et al. [31] given a new method to optimize the background value of the GM (1,1) model, which is a new technique can be used to develop the grey models. Liang et al. [10] developed a optimization GM (1,1) model based on a non-homogeneous background value. Recently, Zeng [2] proposed a novel grey model named TPGM (1,1) by optimizing the background and initial values simultaneously. It is found that these developed GM (1,1) models are constructed by optimizing the background value and other parameters, which is simple and limited. Moreover, the second is a comprehensive GM (1,1) model by introducing the weakening buffer operators. For example, Wu et al. [33] summarized some weakening buffer operators which show the basic principle of buffer operator. To use this operator and optimize the GM (1,1) model, Wei et al. [29] proposed an improved grey forecasting model based on the universal buffer operator by adding the axiom of invariable trend. Zhao et al. [32] improved the GM (1,1) model by introducing the different evolution buffer algorithms, which also is a weakening buffer operator. Li and Xie [23] improved the GM (1,1) model by combining the variable weight buffer operator with the background value, which can be effectively applied into the dynamic process of original data. Also, Guo et al. [4] applied the GM (1,1) model and buffer operator to analyze the meteorological catastrophic factors in Nanjing. Recently, Wu et al. [14] developed a multi-variable weakening buffer operator and proposed the corresponding GM (1,1) model, and then successfully applied it. It is found that the main objective of the above methods is to improve the accuracy degree of the GM (1,1) model from two aspects. In this paper, we focus on the second part to develop the GM (1,1) model, namely propose a improved GM (1,1) model by introducing a new buffer operator.
As a basic technique in the grey system and GM (1,1) model, Luo and Wang [8] firstly summarized the construction process of a new weakening buffer operator. Based on this process, many scholars have further extended some buffer operators, such as the universal buffer operators [29], the co-integration buffer operator [4], and the Multi-variable weakening buffer operator [14]. The above analysis describes the ways of constructing the buffer operators. The idea about the combination of new information and variable parameters in the paper is inspired by these researches. Therefore, in this paper, we focus on the buffer operator and the corresponding grey models.
Moreover, another key issue of this paper is the coal consumption predication in China. We can find that many related studies have been presented. Recently, Li et al. [3] used the vector auto regressive model and four developed predication models to forecast China’s medium and long-term coal demand. Zhao et al. [7] applied three prediction models founded on data mining method to forecast energy consumption in China. Their result showed that the artificial neural network model was the best. These studies provide some great approaches to forecasting coal consumption in China. However, an important phenomenon about the coal consumption in China is that the data are always unstable for the variable statistical standard. From National Bureau of statistics of China, we can find the earliest data of coal consumption occurs in 2000. Thus, the data of coal consumption is scant. Meanwhile, by analyzing the statistical approaches and other mathematical models, these coal consumption data could be inconveniently modeled and fitted for its limitation and fluctuation. Thus, basing on large samples or statistical theory, the prediction methods mentioned above cannot be used in this paper. To address this issue, a better approach is the GM (1,1) model which is a forecasted technique to model the small sample. Some successful cases are also presented, such as Xie et al. [16] combined the GM (1,1) model with the Markov model to forecast the Chinese energy production and consumption. Xu et al. [28] forecasted the energy consumption in Guangdong province of China using a new GM–ARMA model. Additionally, Yuan et al. [5] used the GM (1,1) model to predict Chinese energy consumption and demonstrate its effectiveness and Zeng [2] forecasted the relation of supply and demand of natural gas in China using the TPGM(1,1) model. These evidence show that the GM (1,1) model is a better method to forecast the coal consumption in China when the available data are limited and less than ten. However, it is pointed out that the coal consumption data in China has been fluctuating in recent years. Thus, the above GM–ARMA model, GM (1,1) model, and TPGM (1,1) model cannot be used to effectively fit and forecast these data. Therefore, in this paper, we further investigate an optimal GM (1,1) model to effectively forecast the coal consumption in China from the perspective of the buffer operator which can deal with the fluctuation data.
To do this, the remainder of this paper is organized as follows. Some basic concepts, axioms and properties of the buffer operator are described in Section 2. Then, in Section 3, we propose the exponential buffer operator and analyze its prominent properties. Based on these, an improved GM (1,1) model is constructed, and then the corresponding modeling steps are provided in Section 4. Moreover, a practical example is provided in Section 5 to illustrate the effectiveness and practicability of the new GM (1,1) model. The paper ends in Section 6 withconclusions.
Definitions and properties of the buffer operator
Data trap is a difficult issue during the prediction process [20]. The trap refers to the collection of data behavior when the data suffer shock-wave interference and distortion. To prevent the data behavior from being disturbed and reflect the real variation in data, this section will introduce the buffer operator, based on which a new buffer operator is constructed in the next section.
Definitions of the buffer operator
To construct a new buffer operator, the basic definitions and axioms are described as follows.
X is called monotonically increasing sequence if ∀k = 2, 3, …, n satisfies x (k) - x (k - 1) >0; X is called monotonically decreasing sequence if ∀k = 2, 3, …, n satisfies x (k) - x (k - 1) <0; X is called random oscillation sequence if k and k′ satisfy x (k) - x (k - 1) >0 and x (k′) - x (k′ - 1) <0 where k, k′ ∈ {2, 3, ⋯ , n}.
M - m is called data amplitude of the data sequence, where M = max {x (k)/k = 1, 2, …, n} and m = min {x (k)/k = 1, 2, …, n} .
Based on the above definitions, the following axioms are provided:
The operator which satisfies the three axioms is called buffer operator, where XD is the buffer sequence. The above three axioms is introduced for constructing new buffer operators. According to the different effects on the data sequence, the buffer operator can be divided into the weakening and strengthening buffer operator. The following will briefly define them.
If the growth rate (or decay rate) of the buffer sequence XD is slower than the original sequence X, then the buffer operator D is called a weakening operator; If the growth rate (or decay rate) of buffer sequence XD is faster than the original sequence X, then buffer operator D is called a strengthening operator;
The buffer operator has become a key element of the grey system theory, because it can deal with the disturbance and address the inconsistency in the prediction process. In this section, we will introduce the basic definition of buffer operator and provides its three axioms.
Three properties of the weakening buffer operator
Since the constructed buffer operators in this paper are weakening buffer operator, this section focuses on the three major properties of the weakening buffer operators.
In this subsection, we show the related properties of the buffer operators, which are designed to reduce the disturbance trend of a data sequence and make the prediction results closer to the actual values. According to the above definitions, axioms, and properties of the buffer operators, a new weakening buffer operator is proposed and analyzed in next section.
Exponential buffer operator and their prominent properties
It is found that there are some buffer operators take the regulation degree or the new information into account. However, they do not combine two aspects simultaneously. Hence, in this section, we combine the principle of new information with variable parameters to construct an exponential buffer operator. Measuring and modifying the fluctuation trend of original data is an obvious advantage of this new buffer operator. Moreover, some prominent properties of this new buffer operator are investigated.
The exponential buffer operator
The aforementioned definitions and properties of buffer operator show that traditional buffer operators are less involved with new information. Meanwhile, their structure is fixed and cannot fine-tune the interaction strength. To address these issues, this paper introduces the new information superimposed principle and combines with variable parameters to construct a new buffer operator that can reduce the disturbance of the original sequence, which is described as follows:
If k = (1, 1, …, 1), the relationship if the three types of buffer operators is shown as follows:
Furthermore, if n = 1, then we can derive the following conclusion:
Thus, the mean exponential buffer operator is a special case of the average exponential buffer operator. By adding the variable weights, the proposed buffer operator D4 contains the buffer operators D2 and D3. If the buffer operator D4 without the variable weights, then D4 = D3. If the buffer operator D3 without the variable weights, then D3 = D2. Thus, we can find that these three buffer operators can be switched each other. It is pointed out that the effectiveness will be different if the new information x (n) is used in these exponential buffer operators.
The above presentation mainly describes the properties of the new buffer operator. After that, we further introduce the following average weakening buffer operator as a compared objective to analyze theproposed buffer operator and GM (1,1) model.
The average weakening buffer operator is defined as XD5 = (x (1) d1, x (2) d1, …, x (n) d1), where
The using proportions of new information for D2 and D5 are less than that for D3 and D4. To prove a buffer operator’s prominent properties, D4 can be used to analyze the effectiveness of other buffer operators and compare their prediction ability, which are done in the next subsection.
The following introduces the properties of the proposed exponentiation buffer operators.
If X is a monotonically increasing sequence, then x (k) d4 - x (k) ≥0; If X is a monotonically decreasing or oscillating sequence, then x (k) d4 - x (k) ≤0.
where XD = (x (1) d, x (2) d, …, x (n) d).
2) If X is a monotonically decreasing sequence, we have
3) if X is an oscillating sequence and X (a) = max {x (k)/k = 1, 2, …, n} and X (b) = min, {x (k)/k = 1, 2, …, n}, then
Similarly, we can prove D2 and D3 are two weakening buffer operators when X is a monotonically increasing sequence, monotonically decreasing sequence, or oscillating sequence.
1) If X is a monotonically increasing sequence, for arbitrary k and s where k, s = 1, 2, …, n, k ≥ s, and x (k) d4/x (k) = x (s) d4/x (s), then we have
Moreover, according to the definition of the weakening buffer operator, namely x (s) d4 > x (s), and x (n) d4 ≠ x (n), we can get
As a result, we can derive that the exponential-mean innovation buffer operator D4 can be used improve the smoothness of the original sequence
2) Similarly, we can draw the same conclusion when X is a monotonically decreasing sequence or oscillating sequence.
For the same reason, D2 and D3 can improve the smoothness of the original data sequence. Thus, it can be found that the weakening buffer operator can eliminate the disturbance degree and improve the smoothness.
For the same reason, D2 and D3 can reflect this property.
We can find that the degree of using x (n) also increases if α increases. Similarly, we can obtain the same conclusions when D2 and D3 are introduced.
2) If α = 0, we can find that
3) If k = (1, 1, …, 1), then
Thus, we can conclude that the exponentiation average buffer operator is a special case of the exponential-mean innovation buffer operator D4.
4) If n = 1, then
Therefore, we can conclude that the exponentiation mean buffer operator is a special case of the exponential-mean new-information buffer operator D3.
5) By increasing the variable weights, we can find that the buffer operator D4 contains D2 and D3. If the buffer operator D4 has not the variable weight, then D4 = D3. If the buffer operator D3 has not the mean, then D3 = D2.
Thus, we complete the proof of Property 5.
According to the above properties, we can find that the proposed three types of buffer operators can improve the smoothness of original data sequence. The new buffer operator with variable parameters can regulate the intensity of original data sequence. Thus, the proposed new buffer operators can eliminate the impact of interference term on the system data caused by the distortion phenomenon. Furthermore, based on the developed new buffer operators, the following improved GM (1,1) model is proposed. It is note that this GM (1,1) model based on the new buffer operators can fit and forecast the fluctuation data sequence, which is obvious advantage.
In economics management processes and scientific research, incomplete information could present and be analyzed by the fuzzy system [9] or the grey system [1, 21] In this paper, we focus on the grey system, and its methods are defined as grey system theory. The grey prediction model, which is an important issue in this theory, has recently become a popular research topic. However, the traditional grey prediction model does not consider the disturbance factors in data-generated process. Thus, in this paper, we propose the improved GM (1,1) model based on exponential buffer operator, which not only retains the advantages of the traditional GM (1,1) model, but can also improve prediction accuracy and utility smoothness. Therefore, the following modeling steps for the improved GM (1,1) model are given.
Let a non-negative small-sample sequence X(0) = (x(0) (1) , x(0) (2) , …, x(0) (n)) be the original data sequence, x(0) (k) ≥0, and k = 1, 2, …, n. As a small-sample sequence, n is generally small at n ≤ 10. Based on the Deng’s GM (1,1) model [11] and its modeling steps, we give the following modeling steps of improved GM (1,1) model presents.
The aforementioned steps provide the modeling process and mechanism for the improved GM (1,1) model. Here,
According to the above steps, we can find that the improved GM (1,1) model is proper to be used in the small-sample data environment. Specially, the improved GM (1,1) model can obtain better results than the general GM (1,1) model when the fluctuation trend presented in the original data sequence, which is common phenomenon in the real economic society.
In this section, we use the coal consumption data (unit: million tons of coal) in China from 2008 to 2015 to fit, forecast and compare, and then demonstrate the feasibility and effectiveness of the proposed buffer operators and the improved GM (1,1) model.
Empirical application
Coal consumption takes more than 70% of the energy consumption in China in recent years. Coal consumption has become an important issue for economy development. Meanwhile, it has also produced environment pollution. If this cannot be effectively resolved, the environmental pollution caused by coal consumption will negatively influence the economy development in China. Therefore, the forecasting of coal consumption data is of a great importance for economic development of China. The coal consumption data (unit: tons of standard coal) from 2008—2015 are shown in Table 1, which can be obtained from the National Bureau of Statistics of China. From Table 1, we can find that the coal consumption data show the fluctuation trend. The general GM (1,1) models cannot be used to model and forecast these data. As aforementioned, the TPGM (1,1) model [2] is a optimized GM (1,1) model by developing the background and initial values simultaneously. However, this model could be invalid to model these data because it focuses on the dramatically increased data but not the fluctuation data. To address this issue, a reasonable method is to apply the GM (1,1) model by combining the buffer operator. Thus, the GM (1,1) model and the GM (1,1) model based on the average weakening buffer operator are used to model the above data and compare with the proposed improved GM (1,1) model.
Coal consumption from 2008 to 2015 in China
Coal consumption from 2008 to 2015 in China
(Unit: tons of standard coal).
It can be found that the improved GM (1,1) model considers the impact of the disturbance factors by adding a new buffer operator. Hence, it can be used to overcome the above issue. Thus, we conclude that the improved GM (1,1) model is a suitable method for modeling the data presented in Table 1. After that, this paper further uses the improved GM (1,1) models to predict the coal consumption data form 2014-205 in China, then analyze the forecasted results and compare with the results of the above two compared GM (1,1) models.
According to Table 1, we find that the coal consumption in 2008 decreased rapidly, same as the decay rate of the economic development, and then increased rapidly. Thus, the coal consumption data during 2008–2015 show the obvious fluctuation trend. Therefore, we use the improved GM (1,1) model based on the exponential buffer operator to forecast coal consumption and compare the results with aforementioned two GM (1,1) models. Furthermore, the results can be demonstrated to verify the feasibility and effectiveness of the new buffer operator and grey model.
According to the data from 2008 to 2015 shown in Table 1, it is found that the coal consumption from 2008 to 2013 increased rapidly. However, the consumption on a mount from 2014 to 2015 grew slowly. Thus, in this paper, we use the coal consumption data from 2008 to 2013 as the training data. The training data is used to simulate the six data of coal consumption from 2008 to 2013, based on which the prediction coal consumption data from 2014 to 2015 can be obtained by the above three GM (1,1) models and be used to compare with each other. To do this, the training data are selected and shown asfollows:
According to the above training data, the average growth rate of coal consumption from 2008–2013 was 3.289%. Meanwhile, we can find that the growth rate of coal consumption during these years was not stable. Therefore, in the following calculation, we select the proposed four exponential buffer operator with α = 1, 2, 3 to process the original data sequence, so as to reduce the impact of fluctuation trend in the original data sequence and improve the prediction accuracy. The modeling steps of the improved GM(1,1) model are given as follows:
Processed data by the exponential and average weakening buffer operators
If α = 1, then
Similarly, we can obtain the results when α = 2 and α = 3.
If α = 1, we can construct the GM (1,1) models as
Similarly, we can obtain the GM (1,1) models when α = 2 and α = 3.
If α = 1, then
Similarly, we can obtain the time response sequences when α = 2 and α = 3.
If α = 1, then
Similarly, we can obtain the restored time response sequences when α = 2 and α = 3.
Thus, we complete the modeling process of the improved GM (1,1) model. The above calculations also describe the original data processed by the proposed exponential buffer operators. In the following context, we will also use average weakening buffer operator to deal the original data and compare with the above data. The processed data by the exponential buffer operators and the average weakening buffer operator are shown in Table 2.
In Table 2, the data sequence is processed by the average weakening buffer operator and presented as
By introducing this average weakening buffer operator, we can further construct the GM (1,1) model as follows:
Based on three different α and four kinds of the buffer operators, the GM (1,1) model can be used to predict the coal consumption data from 2014 to 2015. By solving these GM (1,1) models, we can obtain the fitting results which are shown in Table 3.
Fitting and predictive values based on three GM (1,1) model
The results shown in Table 2 are detailed illustrated by Figs. 1–3.
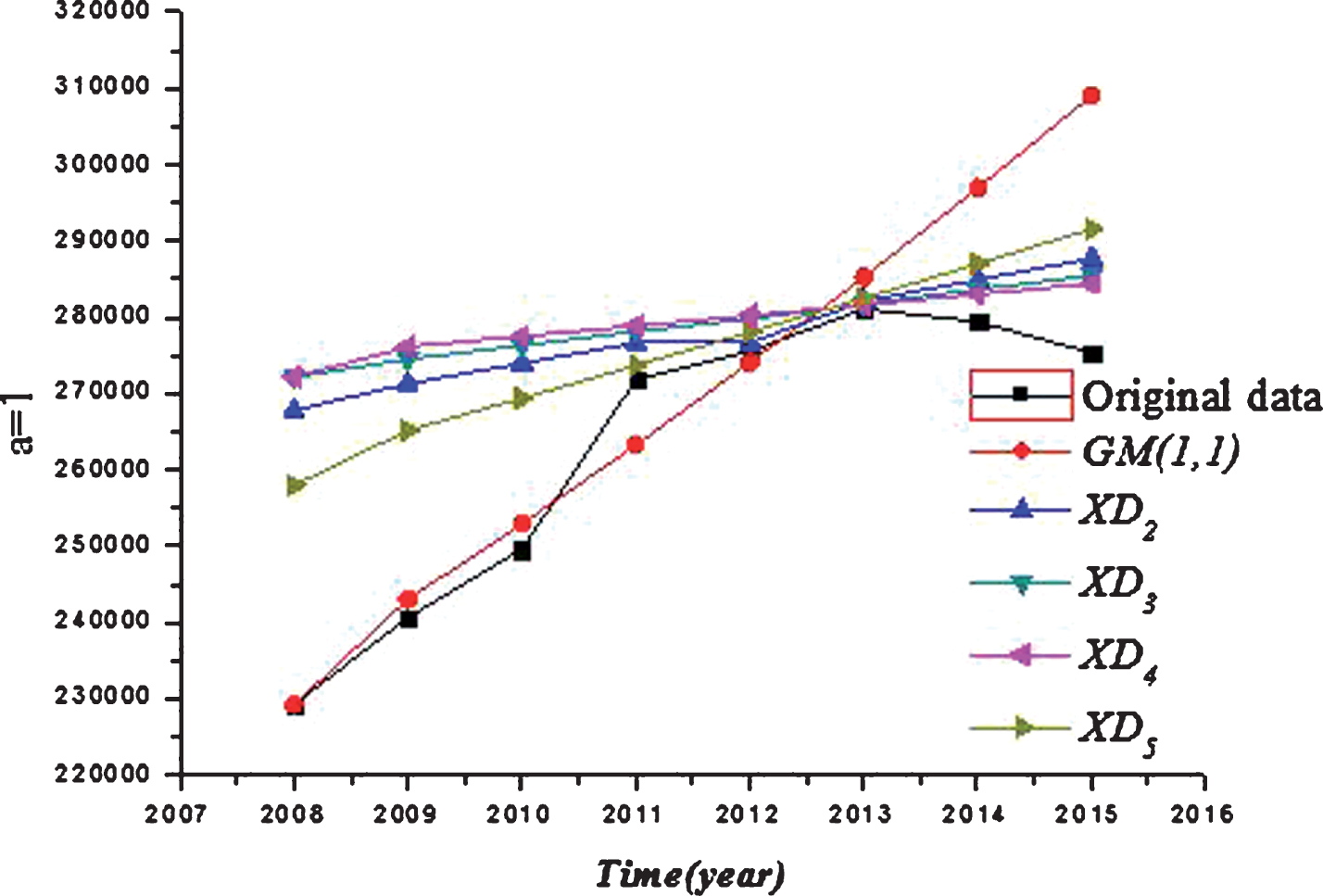
Comparative analysis when α = 1.
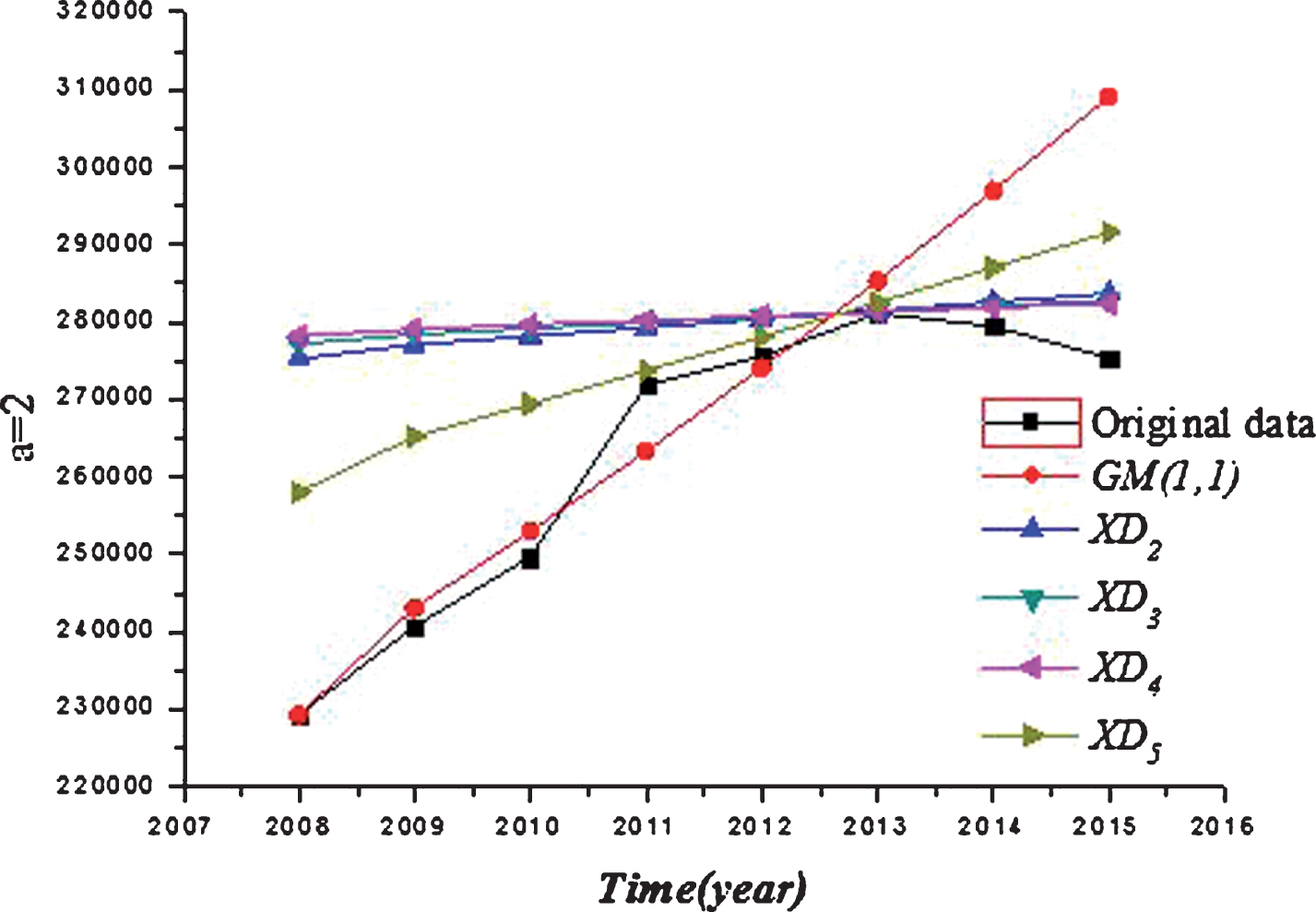
Comparative analysis when α = 2.
As shown in Figs. 1–3, the data sequence processed by the exponential information buffer operators obtained a higher degree of smoothness. The fitting data and predicted data are closer to the original data than the GM (1,1) model and the GM (1,1) model based on the average weakening buffer operator. The results also show that the improved GM (1,1) model is better than the GM (1,1) model and the GM (1,1) model based on the average weakening buffer operator.
As shown as Fig. 3, when α = 1, 2, 3, the smoothness of the processed data by the exponential buffer operator is higher than the average weakening buffer operator. The predicted data processed by the exponential buffer operators are closer to the actual data in 2014 and 2015 than that processed by the average weakening buffer operator.
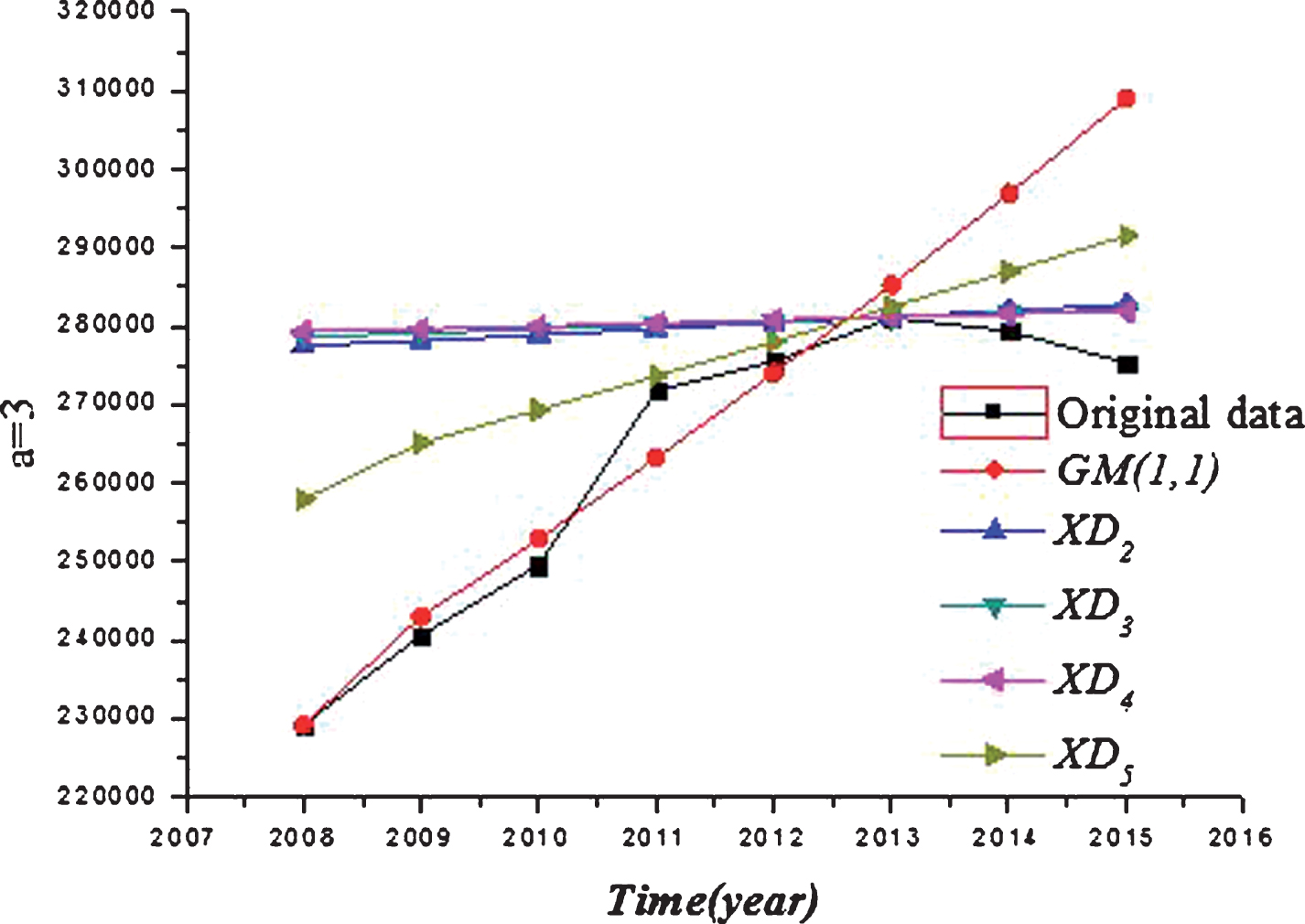
Comparative analysis when α = 3.
Figure 4 uses the histogram to show the comparative analysis of the three kinds of errors by using the general GM (1,1) model, GM (1,1) model based on the average weakening buffer operator, and improved GM (1,1) model when α = 1. Table 4 shows the specific forecasting errors based on four bufferoperators.
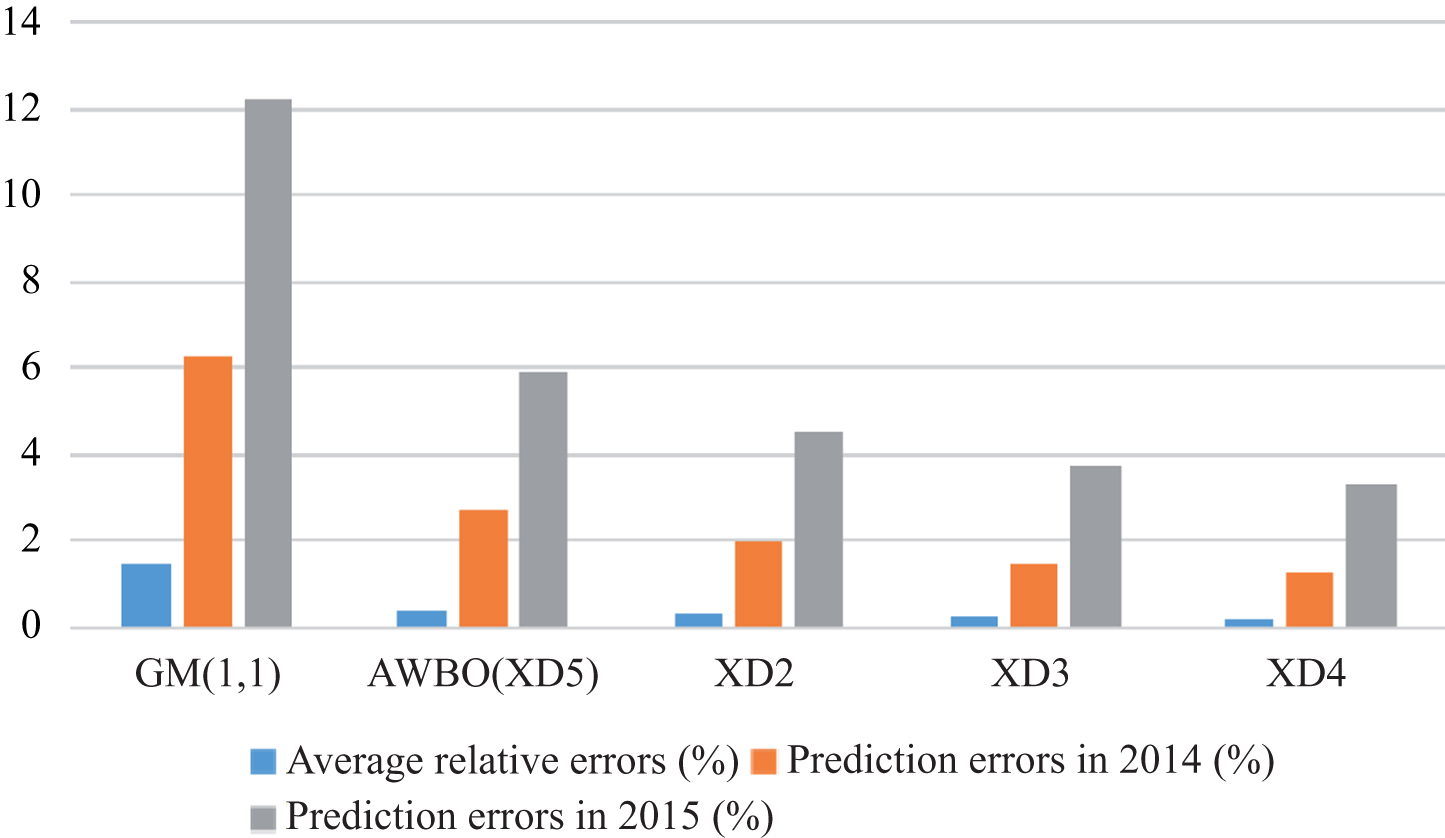
Comparative analysis of the three kinds of errors.
Forecasting error comparison based on four buffer operators
Form Table 4, we can find that the buffer operator can reduce the relative error. The average relative errors and the prediction errors of the data processed by the exponential buffer operators are higher than that processed by the average weakening buffer operator. Form Fig. 4, it is found that the buffer operator can reduce the relative error of the original data sequence. If α increases, the proportion of the error between the predicted data and the actual data reduces. This phenomenon is obvious whenα = 3.
Based on the above analysis, we can derive the following different between the improved GM (1,1) model and the general GM (1,1) model.
Compared with the general GM (1,1) model, the improved GM (1,1) model further considers disturbance factors by introducing the exponentiation buffer operator. Thus it can increase the smoothness of original data sequence. Moreover, we can find that the data sequence XD4 is smoother than the data sequences XD2 and XD3.
The processed data sequences by the average weakening buffer operator and three exponentiation buffer operators are different. Meanwhile, the processed data sequence by D4 is the most smooth than others. Thus, we conclude that the result based on the data processed by D4 and the corresponding improved GM (1,1) model is more precise than the results based on the general GM (1,1) model and other improved GM (1,1) model. This conclusion also is shown in Table 4.
As α increases, the smoothness of data sequence processed by the exponentiation buffer operator increases and the modeling results show higher prediction accuracy. The predicted error by using the improved GM (1,1) model when α = 3 is lower than the predicted errors by using other GM (1,1) model. It is pointed out that a suitable parameter α should be obtained by calculating and comparing. The better parameter α then lower predicted error.
According to the predicted data, we can find that the environmental pollution in China will be serious as the coal consumption increases. However, the growth rate of coal consumption has dropped significantly compared with previous years.
This paper has proposed a new type of weakening buffer operator, namely the exponential buffer operators, based on the new information. Then, the improved GM (1,1) model has been proposed by combining the new buffer operators and the GM (1,1) model. Therefore, the improved GM (1,1) model can present the fitting advantage of the GM (1,1) model in small-sample sequences and the additional advantages of buffer operator to deal with disturbance factors. Thus, the improved GM (1,1) model can be used to overcome the limitations of previous models when the original date sequence is fluctuant, and is suitable to model the small-simple sequence with disturbance and to further predict future data.
To illustrate the improvements and advantages of the proposed model, the data of coal consumption in China from 2008–2015 are used as an illustrated example. Three GM (1,1) models have been used in this example, namely, the improved GM (1,1) model, the general GM (1,1) model, and the GM (1,1) model based on the exponential buffer operator. The results show that the proposed model is more effective to be used in this filed than other two GM (1,1)model.
Follow-up studies will focus on how to select the parameter values of the exponential buffer operators and how to assess the validity of the improved GM (1,1) model. Furthermore, to fuse the improved grey model with other fuzzy and grey systems and solve comprehensive forecasting problems under multiple small-sample environments, the granular computing techniques should be introduced and will be a part of our future work involving the grey model and exponential buffer operator.
Footnotes
Acknowledgments
This work was supported by the Natural Science Foundation of China (grant numbers 71561026 and 71762033) and China Postdoctoral Science Foundation (grant numbers 2015M570792 and 2016T90864). The facilitation from international collaborative program and cooperation with Charles Sturt University (CSU) in Australia is gratefully acknowledged. The assistance of Professor Mark Frost and Antony Bush are also acknowledged.