
Abstract
Similarity searching is the core of many applications in artificial intelligence since it solves problems like nearest neighbor searching. A common approach to similarity searching consists in mapping the database to a metric space in order to build an index that allows for fast searching. One of the most powerful searching algorithms for high dimensional data is known as the permutation based algorithm (PBA). However, PBA has to collect the most similar permutations to a given query’s permutation. In this paper, how to speed up this process by proposing several novel hash functions for Locality Sensitive Hashing (LSH) with PBA is shown. As a matter of fact, at searching our technique allows discarding up to 50% of the database to answer the query with a candidate list obtained in constant time.
Introduction
Similarity or proximity searching consists in retrieving the most similar objects to a query from the database. This kind of searching is the core of many applications in artificial intelligence, specially nowadays most databases include multimedia data. In these databases, the main problem is to solve queries where it is not possible to apply exact searching, however, there is a way to estimate how similar objects are. Furthermore, almost all of these databases have a huge amount of elements, making it unthinkable to solve similarity searching via a sequential scan. Therefore, a solution is to preprocess the database to build an index which then allows answering queries efficiently Chávez and Navarro [2], Samet [12], Zezula et al. [14].
The similarity searching problem can be approached using a metric space, which is a pair
The distance is assumed to be expensive to compute. Hence, it is customary to define the complexity of the search as the number of distance evaluations performed, disregarding other components such as CPU time for side computations.
Basically, there are two kind of queries: range queries and k-nearest neighbors queries. The first one consists in retrieving elements from
Several algorithms have been proposed to solve range and k-nearest neighbors queries. Many of them are very effective only in low dimensional spaces, but their performance worsens as the intrinsic dimension increases. This problem is known as the curse of dimensionality Chávez and Navarro [2] (which has been extended from vector spaces Chávez et al. [3]). It is not easy to measure the difficulty of searching in a metric space Navarro et al. [9], the search costs depend on the shape of the histogram of distances of the dataset. In the case of high-dimensional, the performance of many of these algorithms grows to such extent that their search costs end up being similar to compare the query with any database element (sequential search) Chávez et al. [3]. There are only a few algorithms that are capable of successfully facing searches on high-dimensional metric spaces.
An effective way to deal with the problem of similarity searches on very large or high-dimensional databases is obtaining an approximate and very efficient answer to the query. That is, we could achieve faster query answers if we admit that the returned set does not contain all relevant elements or contains some that are irrelevant.
In this context, there are two techniques whose performance can be unbeatable: the first is based on Locality Sensitive Hashing (LSH) Gionis et al. [8], the second one is based on the permutation based algorithm (PBA) Chávez et al. [4]. LSH is an effective strategy that has not been used with the permutations of a PBA.
In this article, we propose to combine LSH and PBA by using a new family of hash functions to avoid sequential scanning in PBA. The rest of this paper is organized as follows. In Section 2 we introduce some basic concepts: locality-sensitive hashing and permutation-based algorithm. In Section 3 we describe our proposal and finally, we present some experimental results in Section 4 and conclusions in Section 5.
Previous Work
As we mentioned previously, we consider a metric space
There exists several indexes Chávez et al. [3], Samet [12], Zezula et al. [14] that usually are clasiffied according to the approach they to partition the dataset. The usual classification considers pivot-based algorithms, compact partition algorithms, and permutation-based algorithms. As pivot-based and compact partition algorithms have not a very good performance in high-dimensional spaces, in this work we only focus on permutation-based algorithms.
Since our proposal involves locality-sensitive functions and permutation-based algorithms, we describe their main characteristics below.
Locality-Sensitive Hashing
Locality Sensitive Hashing was introduced in Gionis et al. [8]. This strategy hashes each element and similar elements on the same buckets with high probability. The hash functions of LSH maximize collision for similar objects.
The main idea consists of using a set of hash tables ( if u ∈ R (u, r1) then if u ∉ R (u, r2) then
Permutation-Based Algorithms
The other approach that we use is the Permutation-Based Algorithms (PBA) Chávez et al. [4]. A permutation for an object is a representation of it that considers in which order this object “sees” the elements of a subset of distinguished objects called permutants. Formally, we select a set of objects of the database
When a query q is given, we compute the distance between q and all the elements in
There are basically two measures to evaluate similarity between permutations. As we describe: Spearman Footrule
Spearman Rho
In Chávez et al. [4] authors proposed, at query time, to compute all permutations against the query using Spearman Footrule (equation 1), then, to sort them and compute the most similar permutations by the distance function d. Authors proposed to compute just a few fraction of the whole database.
In the literature of PBA, there are some proposals that use auxiliary data structures to avoid the examination of the whole dataset. For example, in Amato and Savino [1] it was proposed to use an inverted index (MI-File) in order to find the list of candidates of nearest neighbor. In Esuli [5], the authors proposed to use a suffix tree to find the most similar permutations (list of candidates). However, some of these techniques need a lot of permutants in order to get a high recall (i.e. 512, 1024, etc).
Authors in Tellez and Chavez [13] introduced an strategy to map permutations to bits and to use well-known LSH. However, their strategy is based on Spearman Footrule metric (equation 1). Unfortunately, they needed a lot of permutants to get an acceptable recall, i.e. 256 permutants.
The LSH concept was presented in Novak et al. [11] for general metric spaces. They used the well-know M-Index Novak and Batko [10] in order to extend the applicability of the LSH approach. All strategies presented were adaptable to the original LSH.
In this article, we propose a new set of hash functions, the core of the Locality Sensitive Hashing algorithm. This set of functions is specifically designed for permutation-based technique. In order to introduce our proposal, we firstly define the notation used.
Let us consider a permutation split in δ small subpermutations, for example, if we split Π q in δ = 3 permutations we can divide the permutations as:
Let the function
Locality Sensitive Hashing of Permutations (LSHP)
Let
One of the main concepts of hashing is that different objects may go to the same bucket which is known as collisions. Our proposal makes use of this concept, the functions defined below generate equivalence classes each of them allocate similar objects.
Definitions of Hash Functions
In this section, we present the hash functions proposed for permutations. For each function we are just considering the closer and far permutants, because these permutants are more significant for the distance between permutations. In other words, the evaluated differences of the i-th permutant in two permutations (i.e,
{Let δ = 3,
Considering ψ = 3 elements at the beginning and at the end of permutation:
Let δ = 4,
Considering ψ = 3 elements at the beginning and ω = 4 at the end of permutation:
Considering ω = 4 elements at the beginning and ψ = 3 at the end of permutation:
Let be δ = 4,
Considering ω = 4 elements at the beginning and at the end of permutation:
We use the sum operation because it is robust under inversion of relatively close permutants which is good for our purpose Chávez et al. [4]. We use ψ = 3, ω = 4 and c = 100, because the first and last elements of the permutations are the most important according to Figueroa and Paredes [6].
During indexing time, each hash table t
i
, for 1 ≤ i ≤ τ is computed with the whole database and organized in buckets according to the its own hash function. This process is described in algorithms 1 and 2;
1:
2: t i ← build-HT(i)
3:
1:
2: v ← f i (Π u )
3: t i [v] ← add (u)
4:
List of Candidates
When the index is built, we can answer the queries. Hence, when a query q and a radius r are given (i.e. we want to solve R (q, r)), we compute every hash table and we get the list of candidates. For lack of space, we only consider range queries.
Formally, let
Example
Let be Π
u
= {2, 4, 6, 3, 5, 1} a permutation, and γ = 11,
If we have another element x whose permutation is Π
x
= {4, 2, 6, 3, 1, 5}, it can be noticed that also the
Experimental Results
In order to evaluate the performance of our proposal, we selected some real-life databases available from SISAP Metric Library benchmark set Figueroa et al. [7]. For each dataset we randomly chose 500 objects as queries and we index all the other database elements.
We have tested several alternatives for the parameters of our proposal. We show here the results obtained considering τ = 7 different functions and using γ = 57 with permutations size m = 8, 12, 16.
It can be noticed that our technique is just using O (τ × n) integers to store the buckets of hash tables. We need m evaluations of the distance d to obtain the query permutation Π q , but the list of candidates can be obtained without performing any additional distance evaluation of d.
On the other hand, the original technique of PBA uses O (m × n) memory space, but m ⪢ τ. Another advantage is that we can get the candidate list without making a sequential scan. Actually, we can obtain this list in constant time. Therefore, we do not need to use an index to accelerate this process. For this reason, it is not necessary to compare our technique with MI-File, P-Index or PPP-Index; that is, these indexes need more than constant time to get the candidate list.
COLORS database
This database consists of 112,682 color histograms of images, represented as 112-dimensional vectors. We use the Euclidean distance for this metric space.
In Figure 1 we show the search performance of our proposal. Figure 1(a) depicts the experimental results when we retrieve the NN1 (q), comparing different values of τ; i.e. different numbers of hash tables used. As it can be seen, using only 1 hash table we can get the 75% of recall with the 30% of the database in the list of candidates (m = 8). Moreover, when we use 2 hash tables we get up to 93% of the recall with 55% of the elements in list of candidates. Figure 1(b) illustrates the performance obtained when we answer NN2 (q) queries. In this case, we obtain again a similar performance. In all plots, Distances represents the number of evaluations of distance d performed to respond the query; that is, when we compare directly q with all the elements in the list of candidates.
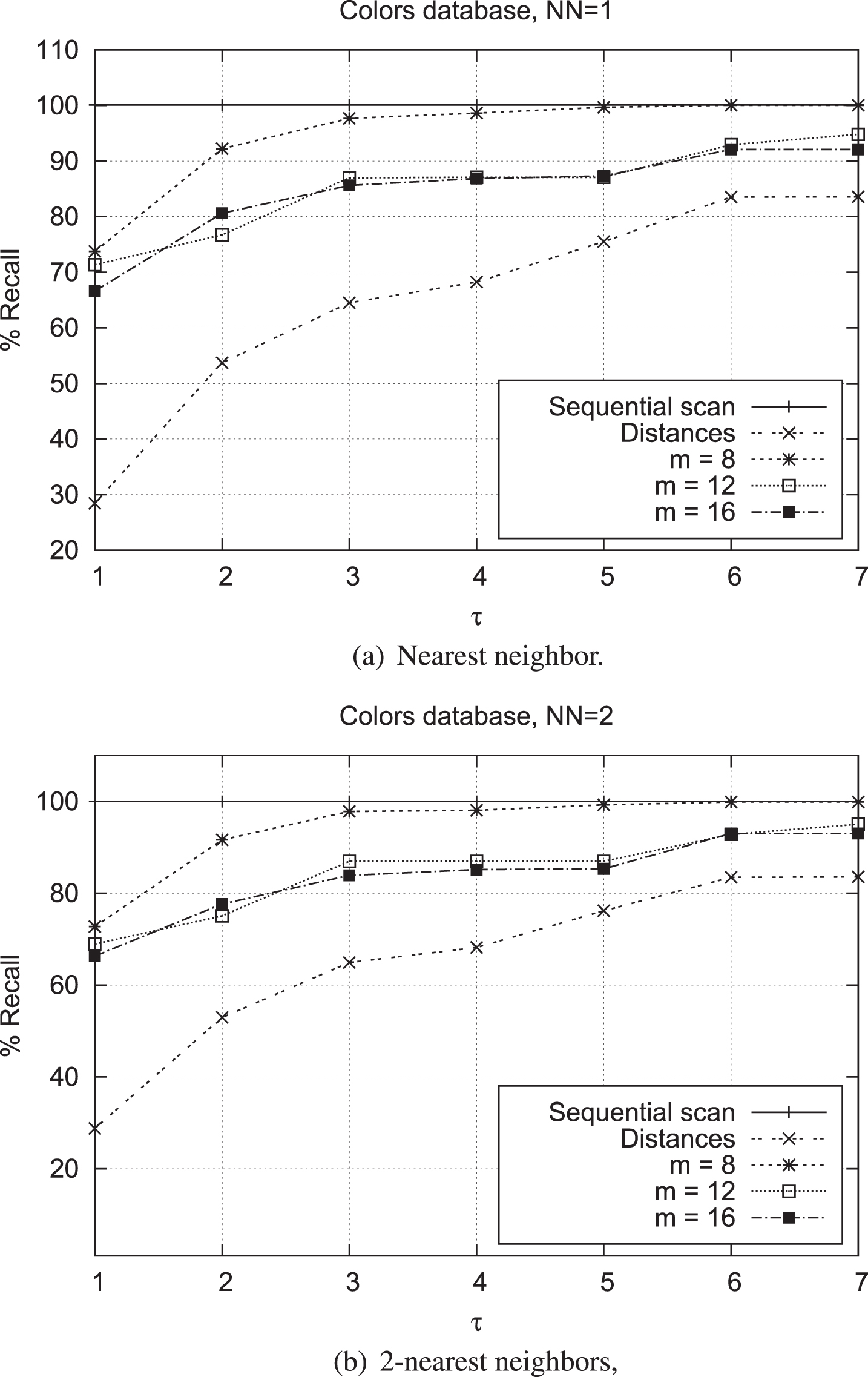
Performance of our proposal using COLORS database.
It is remarkable that our proposal improves as the permutation size decreases and the permutations are used just during indexing time.
This dataset consists of 40,150 feature vectors in
The performance of our technique at searches in NASA database is shown in Figure 2. In this case, we show the results when we answer range queries with low selectivity. Hence, we illustrate the costs of range searches that retrieve 600 elements (Figure 2(a)) and 700 elements (Figure 2(b)). For this metric space, we can get 100% of the recall using only 6 hash tables and the list of candidates with 50% of the database. As it can be noticed, the recall of our proposal increases as the number of tables grows. The better recall is obtained when the number of permutants used is the lowest value considered (m = 8).

Performance of our proposal using NASA database.
One of the main issues in hashing is the one related to collisions. On Figures 3(a), and 3(b) the performance of the hash functions regarding how well they distribute the objects in the hash tables is shown for t1 to t6 using COLORS database and m = 16. Notice that the hash functions from f1 to f6 have uniform distribution across the buckets.
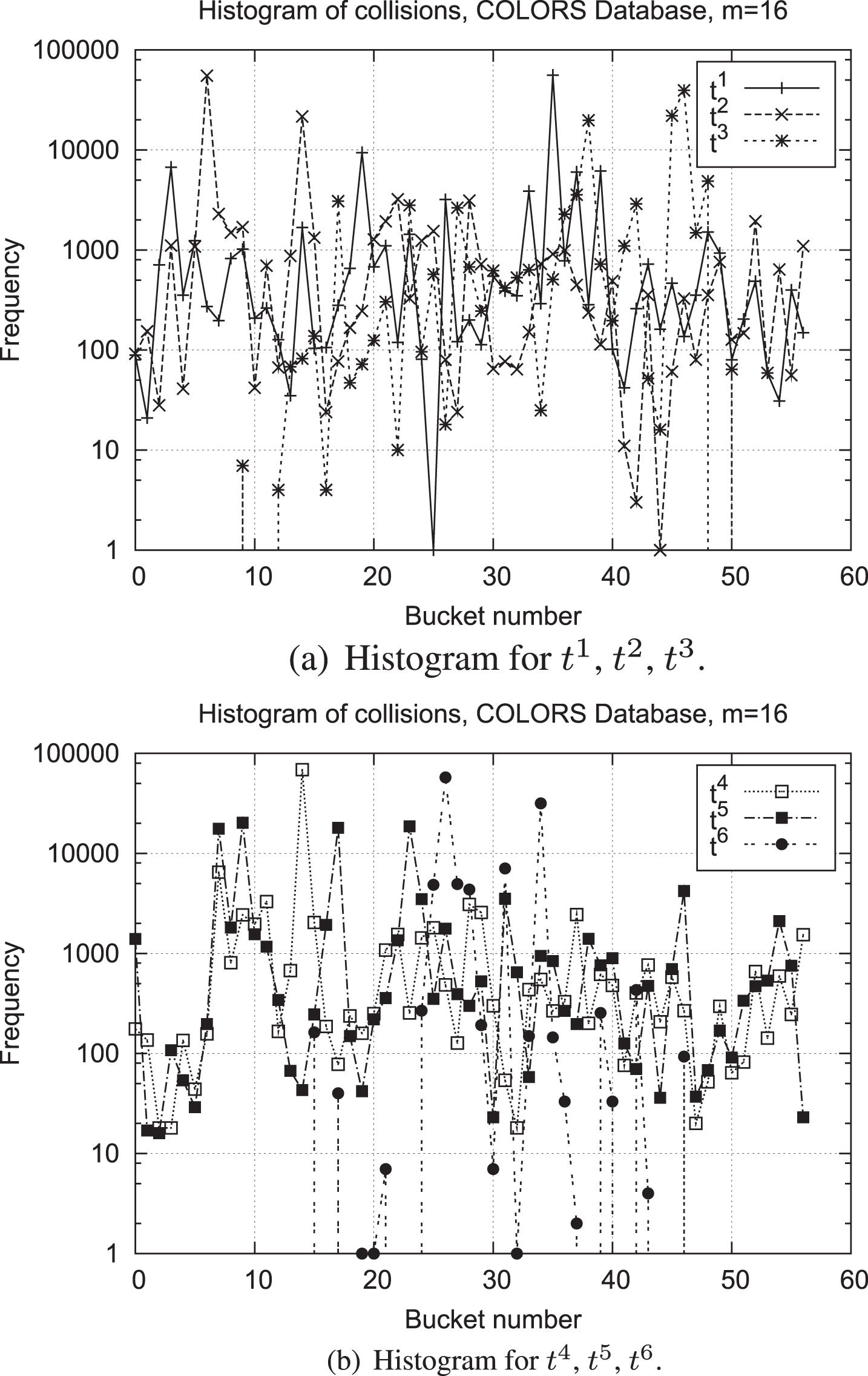
Database COLORS.
In the case of the NASA Database, the performance of hash functions from t1 to t6 is shown on Figures 4(a), and 4(b).
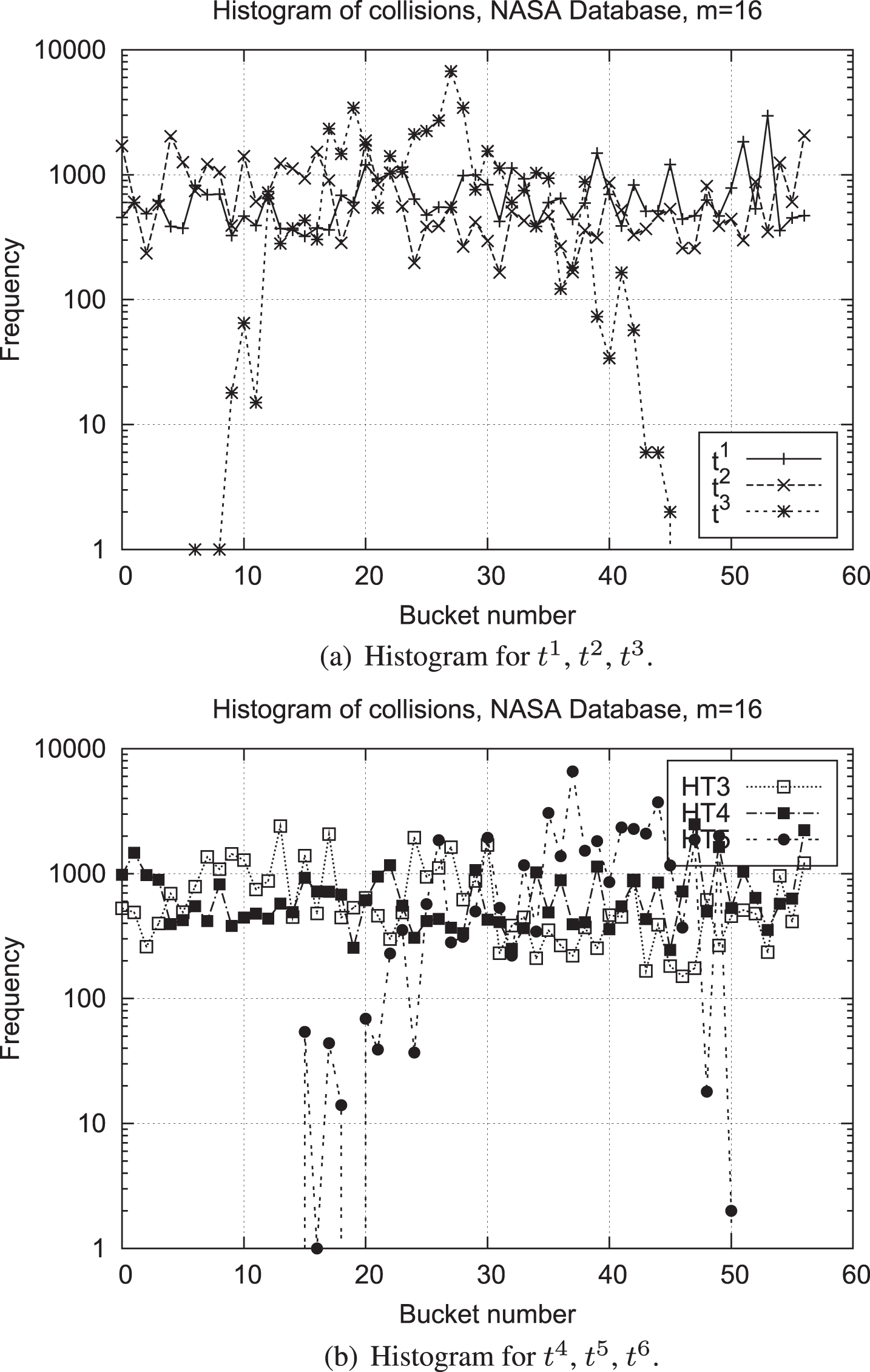
Database NASA.
Approximate similarity search is a very useful operation for several real applications because it allows obtaining a good tradeoff between answer quality and the needed time to respond the query. In this work, we combine the good aspects of two highlighted techniques in the proximity search field: LSH and PBA. Our proposal introduces a new family of hash functions to use in a LSH index. This family can be used in LSH for finding the most similar permutations defined with a permutation-based algorithm. As it is aforementioned, we surpass other techniques (i.e. MI-File, P-Index, and PPP-Index) because we obtain the candidate list in constant time. Moreover, we show empirically that our new alternative achieves a very good search performance. It takes advantage of using the information provided by permutations in LSH and avoiding the traditional sequential scan on all the permutations (as original PBA must perform). By this way, we also prevent the need of using an index like the inverted index or the PP-Index.
In this article, we tested several values for ψ, ω, τ and γ. The values shown are those that maximized the performance. Some values for γ were not considered because their use had the effect of clustering the computed bucket numbers on the first locations of the hash tables. In the case of ψ and ω, the most important and significant permutants are the first and sometimes the last ones.
Even more, it is still possible to improve the search performance of our technique by storing also the permutations of the elements into the buckets, this way we will need more memory space for the index, but we could compare the list of candidates by using any permutation distance and then keeping only the candidates whose are deemed promising. We are also interested in designing other hash functions for LSH based on bits.