
Abstract
E-commerce websites provide an easy platform for users to put forth their viewpoints on different topics-ranging from a news item to any product in the market. Such online content encourages authors to express opinions on various aspects of an entity. Aspect based sentiment analysis deals with analyzing this textual content to look for the aspect in question. After locating the aspects, corresponding sentiment bearing words are looked for. This paper describes an integrated system that generates the opinionated aspect based graphical and extractive summaries from a large set of mobile reviews. The system focuses on three tasks (a) identification of aspects in given field, (b) computation of sentiment polarity of each aspect, and (c) generates opinionated aspect based graphical and extractive summaries. The system has been evaluated on three mobile-reviews dataset and obtains better precision and recall than baseline approach. The system generates summaries from reviews without any training.
Introduction
With the advancement of social media platforms (such as Twitter, Facebook) and e-commerce sites (such as Amazon, Flipkart, etc.), the generation of unstructured data increased rapidly. According to the International Data Corporation (IDC) assessment, 90% of data generated today is accounted as unstructured data. Due to the availability of massive volumes of unstructured data, there is a major challenge for industries and organizations to analyze and to extract meaningful insights out of it. A large volume of unstructured data is human generated in the form of reviews, blogs, forums, pictures, and videos, and other media which do not follow any structure. Generally, reviews are about different items ranging from product and movie reviews to holiday trips and hotel services. The growth of reviews, ratings, online expressions and opinions has turned businesses into a kind of virtual currency to sell the products/services, and identify new flaws to maintain reputation in the market. Many firms and enterprises are now looking into the field of sentiment analysis to understand the voice of the customer, to automate the process of filtering noise and to identify appropriate content to make an appropriate organizational decision.
Sentiment analysis is a natural language processing (NLP) task that utilizes an algorithm formulation to classify a subjective piece of text into either positive, negative or neutral class. Sentiment analysis is achieved at three levels (a) sentence level (to label the sentiment polarity of a sentence), (b) document level (to assign the sentiment label to the whole document) and (c) aspect level (to compute the sentiment polarity of a particular aspect). It becomes more challenging when a review of product contains opinions about multiple aspects of a specific product. The buyers of product are more swayed by the previous consumers’ opinions of various aspects rather than to glance only at star rating of the product. Formerly, large volume of sentiment analysis research have been executed at document level and sentence level. In recent times, sentiment analysis researchers are more motivated towards aspect level as it is more granular. Aspect-level sentiment analysis guides the prospective buyers along with each specific dimension that the product in question might have. A reviewer or user might express his outlook about multiple aspects in an item, while being positive for one and negative for the other. For instance, a customer may be strongly happy with the service quality of a restaurant but might not be happy with the food quality of the restaurant.
However, analyzing sentiments at this granular level is not a straightforward process. Performing aspect-level sentiment analysis presents some challenges. Firstly, there may be comparative opinions, for example A is ‘more good’ than B, or C is ‘better than’ D. Searching these comparison words and then analyzing the sentiment is an interesting process. Secondly, the opinion sentences may be conditional. The user might be providing his suggestion that “if A would have something like this, then it would be really useful”. The challenge is to identify whether the reviewer is positive about the aspect or he is putting some condition forward. Tracing negation is yet another challenge. Generally, layman users don’t express their views via antonym words, and use negative words in conjunction with the positive ones such as ‘not good’, ‘not upto the mark’. Finally, aggregating the sentiments is a useful and important case. Providing aspect level rating or profile is yet not completely subjective. A typical user who reads and writes the reviews, will search for his answers intuitively. There comes the role of text summarization which helps to provide a gist of sentiments. Text summarization is a process to generate concise form of a particular text which presents valuable information to a user in a brief manner. Generally, there are two techniques for text summarization; (a) abstractive summary (understanding and processing the text using advanced natural language techniques to generate the summary) and (b) extractive summary (detecting important fragment from the text to generate summary). Sentiment summarization is quite similar to text summarization, only the difference is, it requires an opinionated text to generate a summary.
In this paper, we have worked on aspect-based sentiment analysis on mobile reviews and generated opinionated aspect based extractive summary of mobile phone. The mobile reviews are crawled from Amazon. An integrated system has been implemented which takes review as input, preprocesses the review, identifies different aspects, computes the sentiment polarity of each aspect and generates the graphical and extractive opinionated aspect based summary of mobile.
The rest of the paper has been organized in the following manner: Section 2 discusses the existing work in literature. Section 3 presents the problem statement. Section 4 describes the proposed system architecture. Section 5 presents the experimental work. The conclusion and future work is presented in Section 6.
Related work
Overall, the combined approaches to detect aspects and corresponding sentiment bearing words can be categorized into the following approaches-supervised, unsupervised, hybrid and rule-based. Each of these approaches has its own pros and cons. Some of these approaches have been briefly discussed in this section. Various machine learning (ML) and natural language processing (NLP) approaches exist in literature for aspect identification. Hu and Lu [1, 2] proposed unsupervised approach by employing association rule mining algorithm to extract aspects explicitly. Supervised methods such as Conditional random Field (CRF) and Hidden Markov Model [3, 4], Naïve Bayes [5] and Maximum entropy (ME) [6] have also been used for aspect identification. Two-phase co-occurrence association rule mining method [7] has been applied for matching implicit aspect with explicit aspects. The most common NLP technique which is used commercially for aspect detection is to detect all noun phrases (NP) from a review and select those aspects whose occurrence frequency is greater than the predefined threshold [8]. Agarwal et al. [9] have incorporated this concept with the most popular approach pointwise mutual information (PMI) proposed by Turney [10]. The main purpose is to identify all the NP from text then for each NP, PMI values have been computed from the specified reference set of phrases which is closely associated with the product domain. Only those aspects were selected whose PMI value is greater than a predefinedthreshold [11].
The next task is to identify opinion bearing words from a piece of text and compute their sentiment polarity. Various lexical dictionaries are available to calculate sentiment score of the words. The most popular lexical dictionary is SentiWordNet (SWN) [12], it is publicly available for use. SWN contains three numerical scores: positive, negative and objective associated with each term occurring in WordNet. Several linguistic approaches have been implemented for computation of sentiment score based on SWN [13, 14]. Venumbaka has incorporated SWN with Stanford dependency parser for finding sentiment orientation of words [15]. New lexicon [16] have been developed by merging SWN and MPQA subjectivity lexicon for computation of sentiment orientation of words. Singh et al. proposed two schemes (adverb-adjective combination (AAC) and adverb adjective adverb-verb combination AAAVC) based on SWN [17]. Khan et al. implemented a framework that extracts mutual information from SentiMI developed from SWN [18]. Tweet smiley and hashtags can also be used as sentiment label to reduce manual annotation work, Davidov et al. have used this concept to categorize into either positive class or negative class [19].
Text summarization is a natural language processing task to generate a summary of an entity from a set of documents associated with the entity. Some past work takes an integrated approach to develop summarization system [20, 21]. Gu and Kim have developed an integrated summarization system which classifies reviews aspect-wise and then generate summary [22]. Topic modeling can also be used for summarization [23–25]. Sentiment Summarization is quite similar to text summarization, but the only difference here is that the set of document holds an opinion about the entity. Dabholkar et al. [26] have proposed the framework to detect and extract important sentences from document, then to compute the sentiment analysis of extracted sentences and generate coherent summary. Li et al. have used user credibility and sentiment quality factors to generate sentiment summary [27]. Various machine learning techniques have been employed for event-based soccer match [28].
This paper proposes to develop an integrated system that extracts reviews from the web, identifies features/aspects about the product, and does sentiment analysis at the aspect level. The system focuses on aspect-based sentiment analysis and opinionated aspect-based extractive summary generation; it involves three subparts (a) identification of aspect from a piece of text (b) computation of sentiment polarity of each identified aspect, and (c) generation of opinionated extractive summary for each aspect from opinionated sentences. Our proposed work is different from existing work in various aspects. First of all, ontology has been created from GSMArena 1 , which is then incorporated with aspect vector to detect the aspects from a given piece of text. The system thus created takes review and mobile name as input, crawls the mobile’s metadata if it is not already existing in the system, preprocesses the review, identifies the aspect using aspect vector and mobile metadata, computes the sentiment score and generates graphical and opinionated aspect based extractive summaries of a particular mobile.
Problem statement
In this paper, the work done focuses on aspect-based sentiment analysis of mobile reviews and generation of opinionated aspect based extractive summary of mobile. The problem can be described as follows:- For each mobile, R = {r1, r2, …, r
n
}, is the set of reviews. Each review may contain opinion about different aspects and different aspects can be denoted/described by various terms or phrases in the review text. For this purpose, we have considered AC
k
= {at1l, at2l, at3l, …, at
ml
} is the set of aspect terms and AC = {AC1, AC2, …, AC
l
} is the set of aspect categories. For instance, a reviewer might mention the word ‘screen’, ‘size’ or ‘touchscreen’, while he actually want to talk about the display of the mobile. So, ‘display’ can be taken as the aspect category, and words ‘screen’, ‘size’, ‘touchscreen’ are associated aspect terms to display category. The problem is to identify aspect-based opinion polarity summary for each review. This summary can be generated by aggregating aspect based sentiment score (SS) of each review. SS of an aspect category AC
l
(sentiment score at aspect level) in a review is defined as:
The aspect-level sentiment summary (ASS) for a mobile can be defined as by aggregating SS (AC
l
over the set of review R:
and,
For each review, sentiment score can be computed by aggregating polarities of all aspect categories found in that review. The sentiment score of review (SS) can be defined as:
The review level sentiment summary (RSS) for a mobile can be generated as:
And,
The objective is to detect aspect based opinionated graphical summary. An integrated system has been implemented which takes review as input, preprocess the review, identifies different aspects, computes the sentiment polarity of each aspect and generates the graphical and extractive opinionated aspect based summary of mobile. This graphical summary is created by summing up the sentiment polarity of each aspect present in all reviews.
Figure 1 shows the architectural block diagram of the proposed system. The system takes the mobile name, and reviews as input, crawls the metadata from GSMArena site if it doesn’t exist in the system, preprocess the review by removing repeated punctuation marks and breaking the review into sentences. POS tagging module tags sentences with parts of speech and passes it to aspect identification module which identifies the aspects from sentences by using mobile metadata and aspect vector. The final step is to compute the sentiment of the polarity of identified aspect and generate the opinionated aspect-based extractive summary of a particular mobile.
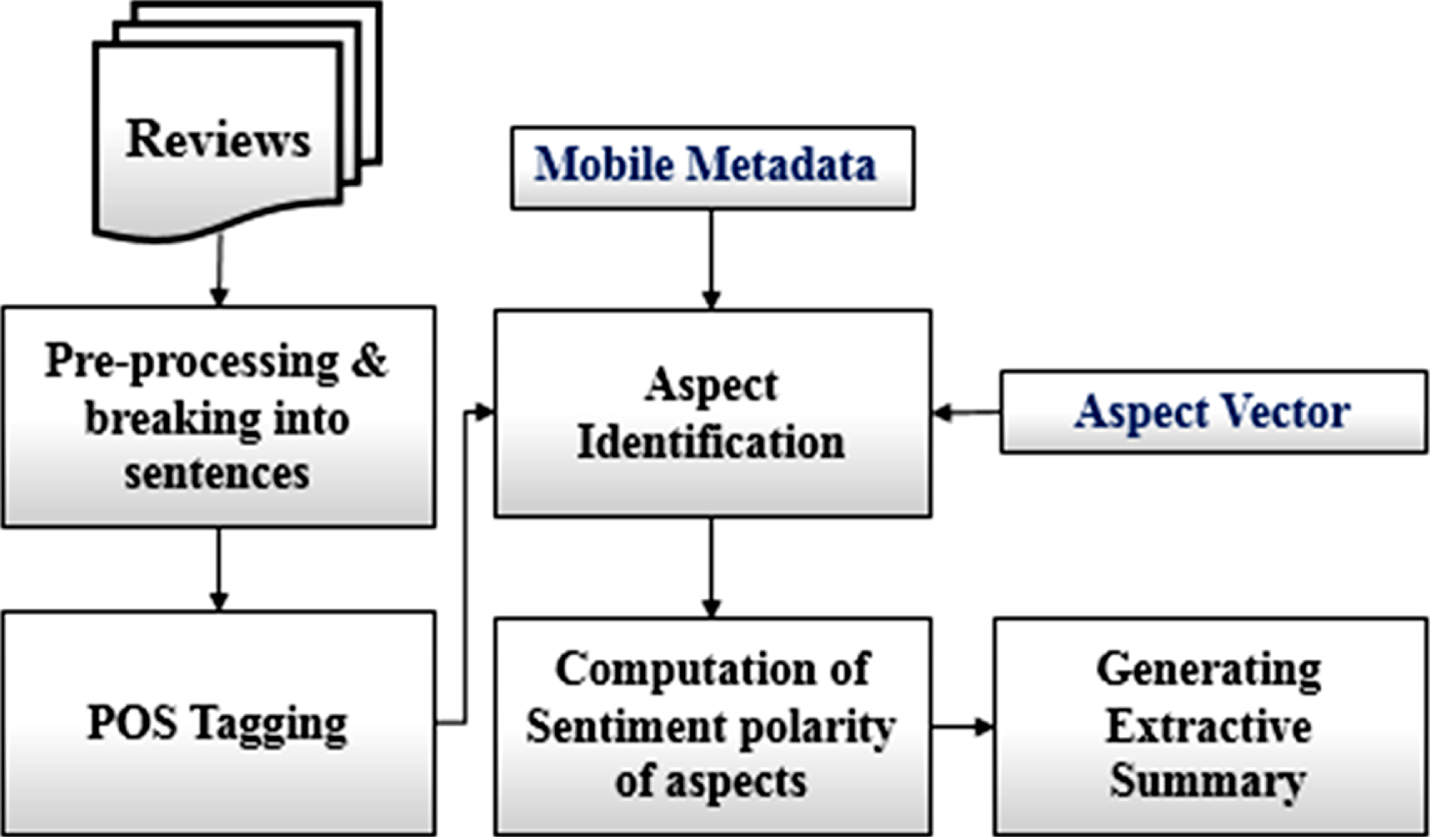
Architectural block diagram.
As our work is focused on the mobile domain, first we have identified aspect categories of mobile by looking at various mobiles’ metadata/ specification from GSMArena. We have observed around 500 mobile specifications from GSMArena. The names of identified aspect categories are: network, body, display, platform, performance, memory, camera, sound, communications, features, battery, overall and accessories. Next, the words that are indicating mobile aspects are added as aspect terms to the specific aspect category. These aspects terms are gathered from 1000 mobile review dataset. Table 1 shows the final aspect vector. We have also created the ontologies from metadata/ specification of mobile. The ontologies contain the name of mobile, brand of mobile, processor names.
Aspect Vector
Aspect Vector
For aspect identification, first, preprocess the review by removing repeated punctuation marks and then breaking it into sentences. Now, to identify the aspect from the sentence, we have used algorithm 1. The pseudocode of algorithm is described below:
1. For each sentence s, s ∈ S
1.1. AspectList = {}
1.2. PS = Parsed s through Stanford POS Tagger
1.3. For each word exist in PS
1.3.1. if(word detect in Aspect Vector(AV))
1.3.1.1. AspectList.add(w, position)
1.3.2. if (word is Noun)
1.3.2.1. Extract Noun Phrase (NP)
1.3.2.2. If ((NP detect in AV) && (NP absent in
AspectList))
1.3.2.2.1. AspectList.add(NP, position)
1.3.2.3. Else If ((NP identified as Aspect through
OD)&&(NP not found in AspectList))
1.3.2.3.1. AspectList.add(NP, position)
1.4. Extract CDP through Stanford Parser
1.5. For each cdp∈CDP:
1.5.1. if ((cdp exists in AspectVector) && (cdp
not found exist in AspectList)
1.5.1.1. AspectList.add(cdp, position)
Here S, OD and CDP represent the set of Sentences, online dictionary, and compound dependency relation respectively. TechTerms 2 used as an online dictionary. We have also used CDP from Stanford dependency parser for aspect identification.
Sentiment polarity computation of aspects
The main objective is to compute sentiment score of each aspect from the review. We have used algorithm 2 to perform this task. The pseudo-code of algorithm 2 is given below:
We have used generic lexicon [16] derived from MPQA subjectivity lexicon 3 and SentiWordNet.
Extractive sentiment summary generation
For opinionated extractive summary evaluation, we have created manually five positive and five negative reference summaries for the camera and battery aspects. Rouge-L [33] algorithm has been used for evaluation of summaries. Table 5 shows the opinionated aspect-based extractive summary results. It can be observed from the table, we have achieved 0.435 and 0.415 F-measure values for the camera and battery aspect respectively.
For extractive sentiment generation, cluster the sentences aspect wise. The clustering for each aspect will separate positive sentences into one cluster and negative sentences into another cluster. After clustering, next step is to do a ranking of sentences, for this LexRank [29] algorithm has been used. For each aspect, positive and negative summary is generated from top 5 ranked sentences. Example of positive summary for camera aspect is given below:
“I will suggest this phone to anyone who wants a great camera and performance phone under 15K budget. Camera is good. Best camera to take photos in high quality. Great display and best camera quality in the range. Looks very nice, Smooth performance and Camera Quality also Superb.”.
Experimental work
Dataset
We have carried out our experimental work on three mobile datasets. These datasets are created from mobile reviews which have been crawled from Amazon. Three independent annotators have been engaged to manually annotate the entries of each dataset and finally, reviewed by two annotators. The annotators were asked to annotate each aspect with sentiment polarity identified in the dataset. The quality of annotation has been measured by two standard agreement parameters: Inter-Indexer Consistency (IIC) [30] and Cohen’s Kappa [31]. The datasets are named as D1, D2, and D3 respectively. Table 2 shows the dataset details.
Dataset detail
Dataset detail
The performance of system is evaluated through standard performance measures: precision (P), recall (R), and F-measure. The macro-averaging method has been used for computation of precision. Table 3 shows the aspect level results. From the table it is observed that the proposed aspect identification algorithm achieved nearly 77% recall, 78% precision and 0.80 F-measure for all three datasets better than baseline approach. The baseline approach takes sentence as input and identify Noun Phrases from sentence as aspects [32]. Table 4 shows the sentiment level results. It is observed that for D1, D2 dataset sentiment computation algorithm achieves nearly 80% precision, 80% recall, and 0.81 F-measure which is comparatively greater than the D3 dataset. In Table 4, Z refers to total number of aspects whose sentiment polarity is found correctly by sentiment computation algorithm. Figures 2–4 are showing the graphical aspect level summary of dataset D1, D2, and D3 respectively. The red bars on the left side depict the negative reviews, while the green bars on the right side depict the positive reviews. Figure 2 depicts that reviewers were completely satisfied and happy with the platform i.e. the operating system of Dataset 1 (iOS). On the other hand, they were not at all satisfied with the accessories that the vendor offered. This kind of graphical summaries is easier to comprehend rather than reading all the reviews and reaching to a conclusion.
Accuracy of aspect detection
Accuracy of aspect detection
Sentiment level result
Rouge – L aspect level extractive summary result
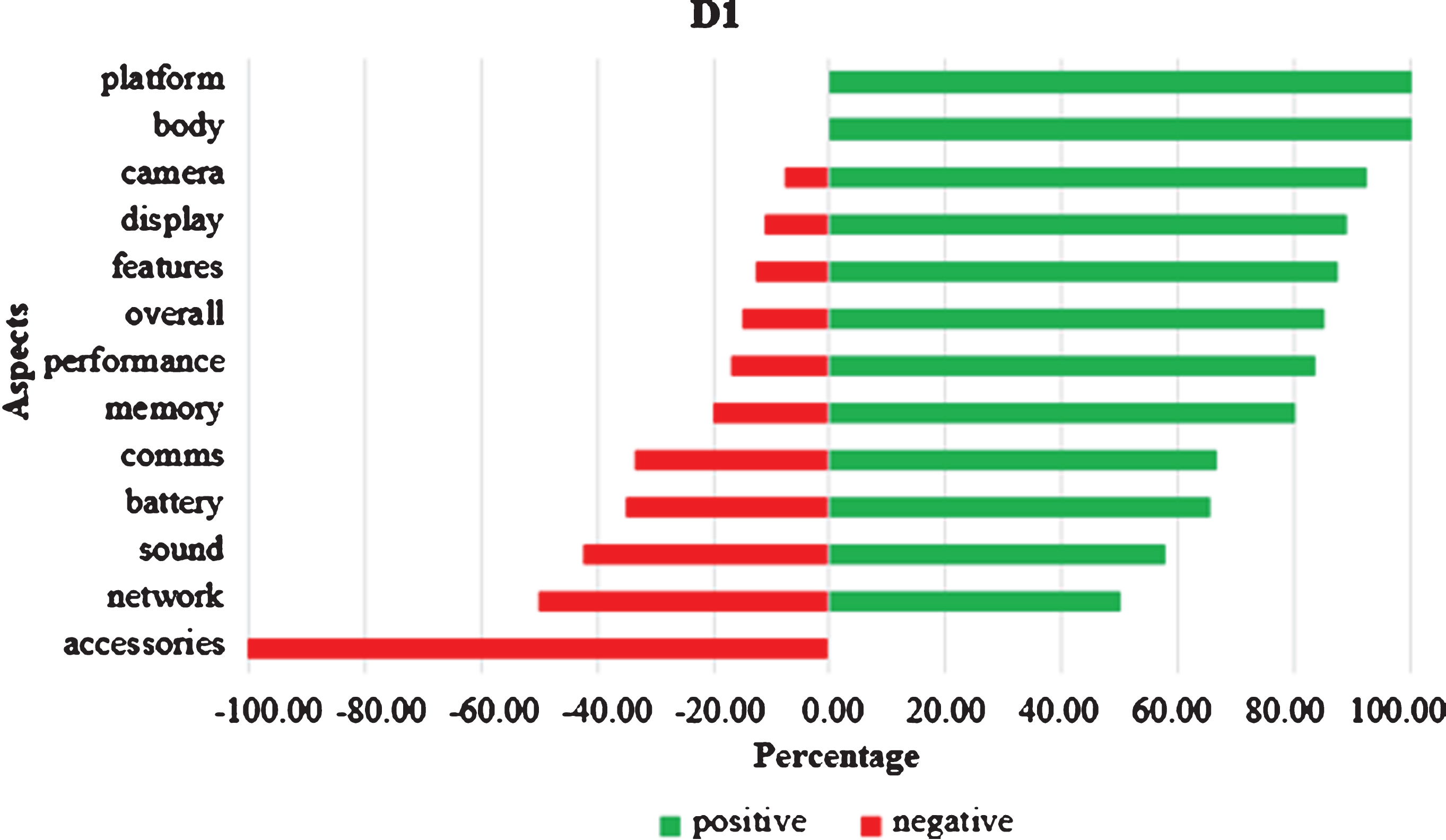
Graphical aspect level summary for dataset D1.
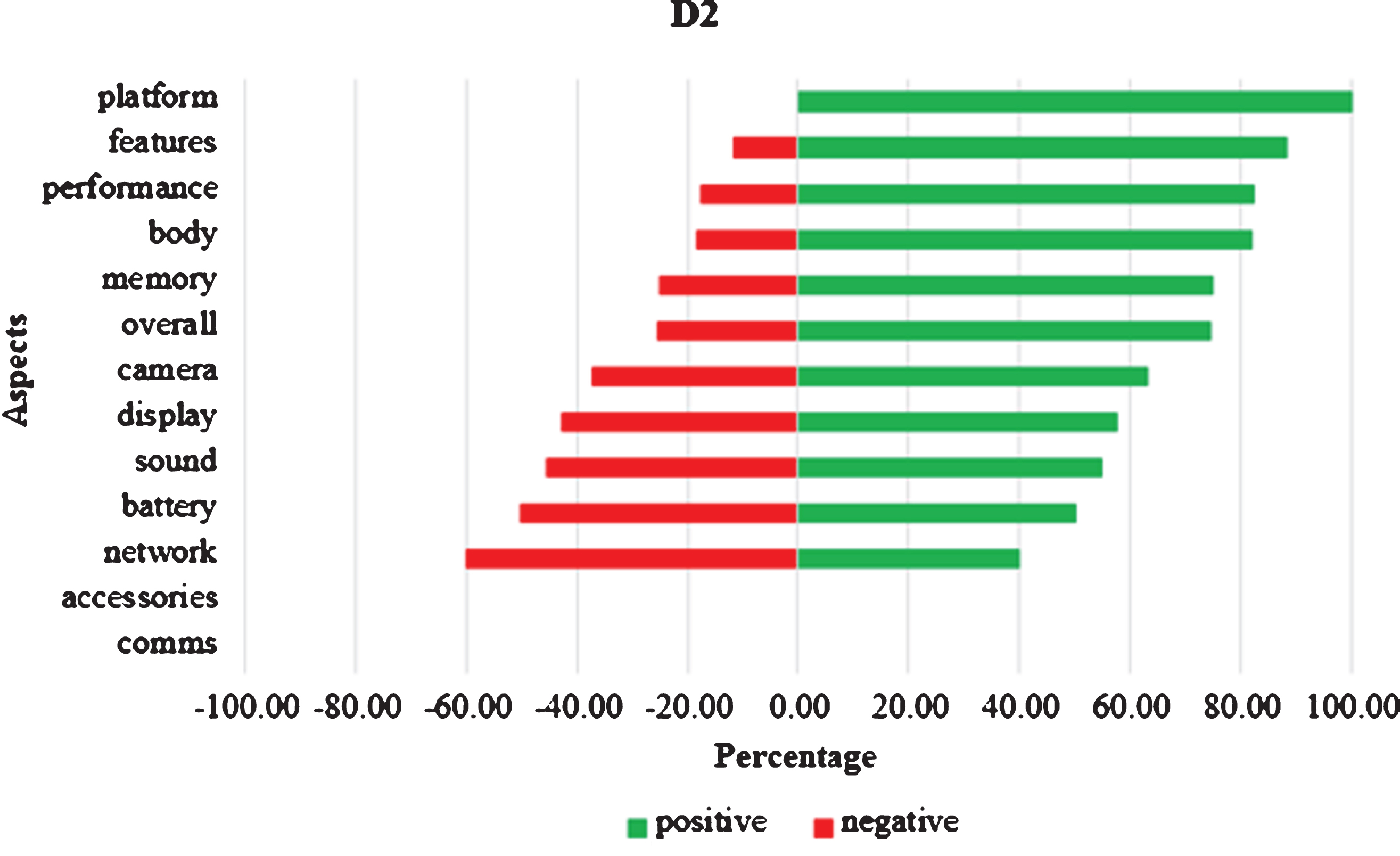
Graphical aspect level summary for dataset D2.
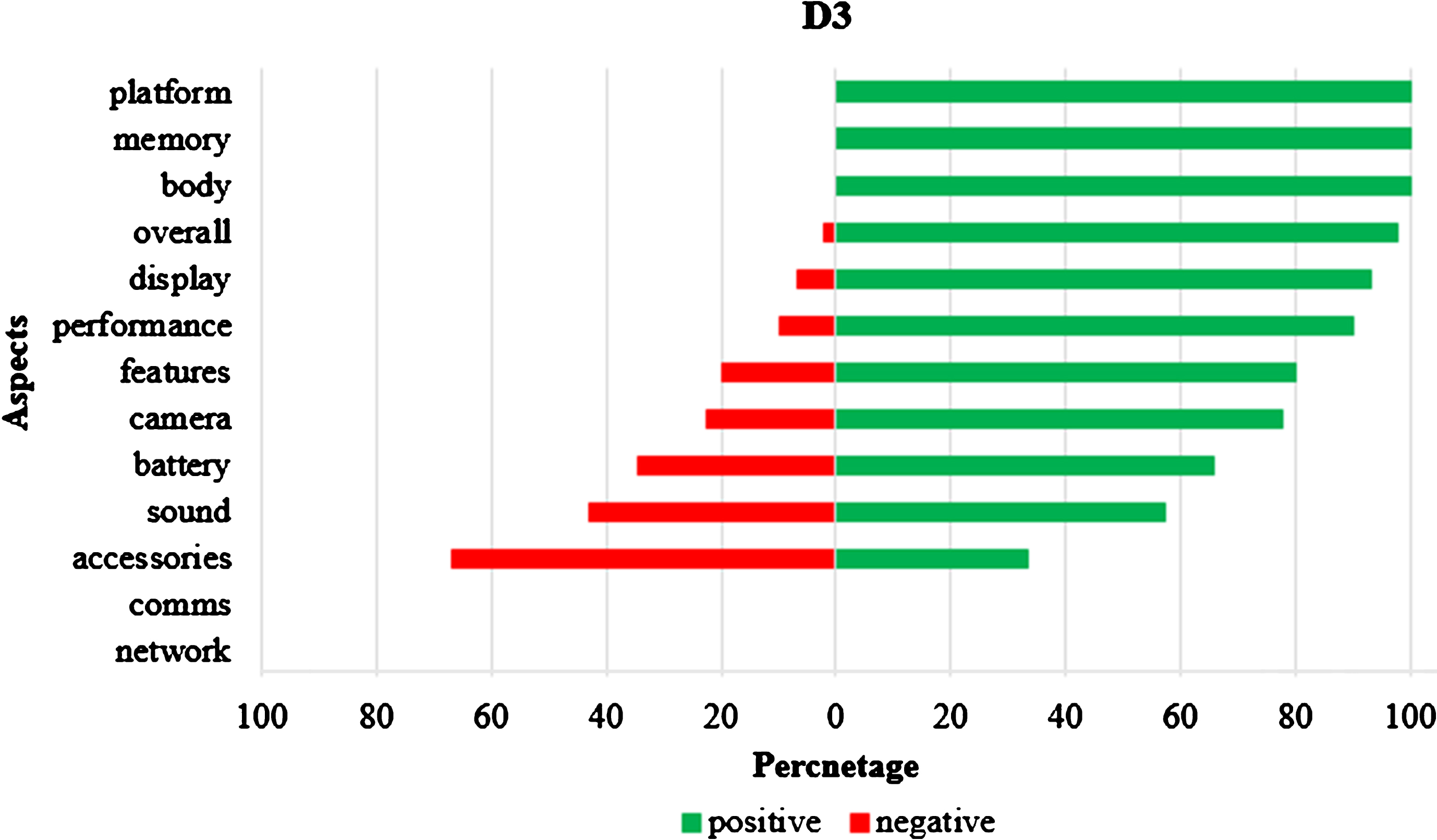
Graphical aspect level summary for dataset D3.
Aspect based sentiment analysis provides analysis of users’ opinions at a more granular level. In this paper an integrated system has been developed that generates the opinionated aspect based graphical and extractive summaries from a large set of mobile reviews. The system so developed extracts implicit aspects in a given field, computes sentiment polarity of each aspect, and generates opinionated visual summaries. The system has been evaluated on three mobile reviews dataset. The system generates summaries from reviews without any training. The main objective was to develop such a system that fetches real time user reviews and decipher aspect level sentiments from the reviews. However, the system as of now doesn’t deal with opinion shills that might be a part of reviews collected. This work can be extended by collecting more data about the products that can boost up the sentiment summary. For instance, data about the product sales throughout all the territories can be amalgamated with the sentiment analysis. This would further help to harmonize the sentiment summary results with the actual performance of the product in the market. Similarly, expert opinions about the fidelity of the product by leading technocrats in the field may be gathered by technical reports released about that product. These supplementary information can further make the system more comprehensive.