
Abstract
This work focuses on bolstering the pre–existing Interpretable Semantic Textual Similarity (iSTS) method, that will enable a user to understand the behaviour of an artificial intelligent system. The proposed iSTS method explains the similarities and differences between a pair of sentences. The objective of the iSTS problem is to formalize the alignment between a pair of text segments and to label the relationship between the text fragments with a relation type and relatedness score. The overall objective of this work is to develop a 1:M multi chunk aligner for an iSTS method, which is trained on SemEval 2016 Task 2 dataset. The obtained result outperforms many state–of–art aligners, which were part of SemEval 2016 iSTS task.
Introduction
Assessing Semantic Textual Similarity (STS) between text is a central problem in Natural Language Processing (NLP) due to its importance to a variety of applications. It has wide range of applications such as: ad–hoc table retrieval, question answering, text classification, Natural Language Understanding (NLU) and controversial agent in Intelligent Tutoring System (ITS). Text similarity is measured at various level, starting from word to phrase followed by a sentence to paragraph and ends with the similarity between documents.
A metric over a set of documents defines the semantic similarity between them, by measuring the direct and indirect relationships [11, 33]. These relationships can be measured and recognized by the presence of any semantic relationships. The similarity between short text was reported in [22, 26] and similarity between two parallel sentences was introduced in Semantic Evaluation (SemEval) workshop 1 . In SemEval a pair of sentences have been given as input, and a score ranging from 0 (having different semantic meaning) to 5 (complete semantic equivalence) was considered as a similarity score 2 between them. After that, the STS problem has seen a large number of solutions in a relatively small amount of time. The central idea behind most of the solution is the identification and alignment of semantically similar or related words across the two sentences and the aggregation of these similarities to generate an overall similarity [16, 38].
This paper does not only measure the similarity score, but it will also explain why two sentences are related or unrelated, and in literature, this problem is known as Interpretable Semantic Textual Similarity (iSTS), which adds fine–grained information while evaluating the similarity between text snippets [2, 4]. Adding an explanatory layer will help an artificially intelligent agent to prove its ability to a user, which requires an explanation to understand their behaviour [14]. This explanatory layer is achieved by aligning the text segments of one sentence with another, and for each alignment an aligned type with a relatedness score is assigned. Details about the alignment type and relatedness score is reported in Section 2.
This paper is organized as follows. Section 2 describes the interpretable STS (iSTS) problem with its required components. Section 3 discusses about the related works, and individual modules of this proposed method has been discussed in Section 4. System performance and result analysis of the various components are discussed in Section 5, and Section 6 mentions the conclusion of the proposed method.
Defining the interpretable STS problem
An interpretable STS (iSTS) can explain the differences and commonalities between two sentences. To understand this, consider the following two parallel sentence, which are taken from the headline dataset of SemEVal 2015 iSTS pilot task
3
: US drone strike kills 5 militants in Pakistan Drone strike kills four suspected militants in Pakistan
The output of such method would be something like the following: two sentences talk about a Drone strike in Pakistan conducted by the US. But they differ in number of ways, such as the number of militants killed (5 vs. 4) and level of detail: the first one specifies as US drone, which is missing in second sentence. The first one clearly mentioned about the militants, whereas second sentence talked about suspected militants.
It is very natural for human to give such explanations, but for an algorithm or a computational model, it’s like a Natural Language Understanding (NLU) problem. In computation, the problem is conventionally named as interpretable STS (iSTS), and an architecture comprising of five different modules to solve the problem is shown in Fig. 1.

Modules of an interpretable STS method.
The alignment types can be one of the following:
With these reasoning types, two other types can be used either in isolation or together, meaning either use both the types or none.
Before assigning any of these labels, the relatedness score from 0 (no relation) to 5 (maximum similarity) will be measured first. 5, if the meanings of both the chunks are completely similar/equivalent. 4 or 3, if the chunks are very similar or closely related. 2 or 1, if chunks are similar or somehow related. 0 for unaligned chunks NOALI should not have any score EQUI should have a score 5 and if meaning of aligned chunk is completely opposite, EQUI must be replaced by OPPO The other labels must have score greater than 0 and less than 5
For an aligned pair of chunk, the similarity is always above 0, which means that chunks can be left as unaligned. For an unaligned chunk, ‘NOALI’ label will be assigned. After alignment it is compulsory to check the following things:
Early work on adding an explanatory layer is an important task for a tutorial system, where Intelligent Tutoring System (ITS) interacts with the students through natural language. In most cases, applications have focused on problem–dependent and question–dependent knowledge [5, 18]. However, some alternatives are also available those are based on NLP techniques [28]. Work reported in [28], is related to an educational domain and much more similar to a textual entailment problem. It defines facets (words under some syntactic/ semantic relation) in the response of a student answer (called the hypothesis), was linked to a reference answer. The link would signal whether each facet in the response was entailed by the reference answer or not. The initial motivation for this proposed method is similar to this entailment work. As best of our knowledge, we think interpretability is related to Natural Language Understanding (NLU) problem and especially useful in the field of ITS.
Towards the development of such method, SemEval 2015 and 2016 took the first initiative. In this event, the participant systems has to explain why two sentences are similar or unrelated by supplementing the similarity score with an explanatory layer. In 2015, it was introduced as a pilot task with the restrictions of chunk alignment and allow the systems only 1:1 chunk alignment. For the unaligned chunks, two other class labels are considered. Such as (i) not aligned and (ii) context alignment [4]. In 2016, this restriction was withdrawn and 1: M (multi) aligner (means one chunk can be aligned with multiple chunks) was considered. The proposed work is inspired from SemEval, and the results of the proposed method have been analyzed and compared against the methods those were reported in SemEval 2015 and 2016 [3].
In SemEval 2015 iSTS pilot task, a modular approach was proposed to identify the chunks [2]. At first, Stanford NLP parser was used to extract the information like part of speech analysis and the dependency structure. The Apache OpenNLP API was used to train the ixa–pipes–chunker to identify the system chunks. Further, to improve the chunking result, four rules were developed to handle the preposition, conjunction, and punctuations. For alignment, a ready–to–use monolingual word aligner was used, which provides all token to token alignment information of two sentences [36]. Finally, the Hungarian–Munkres algorithm was used to decide the maximum link ratio, when a token of one sentence was aligned with multiple tokens of other.
For classification, two approaches like näive based and a machine learning were used to assign an alignment type. The näive approach, directly assigns the equivalence (i.e. EQUI) tag for the alignments with the highest weight, and –not aligned–for the unaligned chunks. To improve the efficiency of näive approach the Support Vector Machine (SVM) was used as a classifier and features like (i) Jaccard overlap; (ii) segment length; (iii) WordNet similarity among the segment heads and (iv) WordNet depth were considered. In näive approach relatedness score was assigned directly for ‘EQUI’ and –not aligned–chunks. For the other tag those similarity score ranges between 1 to 4, a regression approach was used and resources like (i) Euclidean distance between Collobert and Weston word vector [10]; (ii) Euclidean distance between Mikolov Word Vector and (iii) PPDB Paraphrase database values were considered.
A system called VRep [15], considered the WordNet Vector relatedness measure [30] with a threshold value to compute the similarity between the two words. Further, the similarity between the chunks were identified as the sum of the maximum word to word similarities, and the similarity score was normalized by the number of words in the shorter of the chunk pair. For alignment, chunk similarity was the key and was computed between each chunk of two aligned sentences. For alignment, highest chunk similarity score was considered, which prevents wrong chunk alignment.
To classify an alignment, a set of syntactic and semantic features for each chunk pair was considered. These features were extracted from the chunk pair itself and in literature methods like NeRoSim [7] and SVCSTS [19] also followed the same procedure for chunk alignment. NeroSim gave its focus over the semantic relationship, and SVCSTS shifted its focus more on the syntactic form, such as the number of words or part of speech in a chunk pair to align a chunk. But, VRep combined both the feature set, and SemEval 2015 Task 2 test data was used to train the classifier. The JRIP algorithm [9], which creates a decision list for classification and WEKA machine learning tool was adopted for classification purpose.
In SemEval 2016, iUBC represented the iSTS as a problem of classification and regression. To solve this, a set of RNNs and LSTMs were used to assign a relation type and measure the similarity score for an aligned pair of chunk [23]. This method was introduced as iUBC at SemEval 2016 task 2, which composed of three components. Such as (i) input handling and chunking; (ii) alignment and (iii) joint classification and scoring.
For alignment, a token–token alignment matrix was initialized, in which each element determines there exist a connection. To initialize the token–token matrix, a weighted sum of lowercase token overlap, lemmatized token overlap, cosine similarity between pre–trained word vector and the alignment prediction of monolingual word aligner was taken into account. Further, Hungarian–Munkres algorithm was used to find the strength of each segment connection and developed a chunk–chunk matrix, by considering the chunk boundary.
Proposed method
The proposed method is composed of five modules. The first module, preprocessing (Section 4.1), is responsible for reading inputs and identifying part–of–speechs, named entities, tokenization and lower case convertion. The second module, chunking (Section 4.2), identifies the individual chunks of each sentences. The third module (Section 4.3), explains the individual components and required features to align the corresponding chunk of two sentences. The classification and scoring modules are listed in Section 4.5 and 4.4 respectively.
Preprocessing
Following five (5) preprocessing steps have been carried out such as: – UK/LOCATION alert on Syrian chemical arms John Demjanjuk, convicted John Demjanjuk, convicted China stocks close China stocks close
Here in the given example, first two tokens are part of the NEs and these tokens remain unchanged.
Chunking
According to Abney: a chunk is an intra–causal constituent including pre–head as well as post–head modifiers, but not pp–attachment or sentential elements [1]. Stanford Dependency Parser [21] is used to process the source and translation sentences linguistically. The output of the parser, such as lower-cased token information, part–of–speech (POS) analysis and dependency structure have been recorded. Based on the POS tags, an automatic chunking algorithm is developed to identify the chunks (a group of words) and for this CoNLL–2000 Chunking shared task guidelines are adopted here [35]. The proposed algorithm is summarized in possessive NP constructions are split in front of the possessive marker [Shinzo Abe] [is] [Japan] an ADJP constituent inside an NP constituent becomes part of the NP chunk [Gunman] two VP constituents did not overlap [US allies] adverbs/ adverbial phrases are marked as different chunk, if they are part of the VP chunk [G20 Summit] predicate adjectives of the verb are not part of the VP chunk [Hundreds] ADVPs that contain an NP make two chunks [Militants] [kill] all NP chunks inside a PP chunk is marked as PP [Drone strike] [kills] [four suspected militants]
Penn Treebank POS tags [24], are considered here to implement this algorithm and to understand the flow of the algorithm following things need to be considered. parsetree is the analysis of a sentence and have the information like (i) phrases; (ii) POS tags of tokens; (iii) lower case tokens; and (iv) dependency structure chunk is a segmented version of a sentence phrase and pos are the collections of each phrases and POS tags of individual tokens N, V, A, R represents all POS tags of noun, verb, adjective and adverb class
The system generated chunks are considered as ‘SYS’ chunks and evaluated against the manually identified chunks, which are identified by human annotator and considered as gold standard ‘GS’ chunks. These GS chunks are publicly available with the SemEval – 2016 Task 2 dataset
8
and details about the dataset have been reported in Section 5.1. The headlines training dataset had 756 sentence pair and proposed chunking method has identified the correct chunking for 572 pairs of sentences. Based on an experiment result three reasons are listed here, which affect the performance of the proposed chunking module. In these examples, errors are marked in boldface, in which square brackets ([]) represent chunks boundary. punctuations - in alignment punctuations remain as unaligned chunks. [Mall attackers] [used] [ [Mall attackers] [used] [ ADJP followed by NP - for this task ADJP considered as a different chunk [South Africans [South Africans] [ phrasal verb - for this task chunks are identified by considering the POS tags only. Words like strikes off are part of two different SYS chunks. [6.8 quake [6.8 quake] [
Alignment
The proposed token to chunk multi aligner is a collective approach of two primary components. The first component, 1:1 token aligner, which operates as a pipeline of alignment modules that differ in the types of word pairs. The second component, 1:M (multi) chunk aligner considers all the 1:1 token alignment information and a set features to align the tokens into chunk level as well as to handle the unaligned tokens or chunks. This alignment module is developed and verified on the SemEval 2015 and 2016 iSTS dataset and to satisfy the criterion of alignment task following rules are adopted: contextual meaning is key for the alignment, which means that the deep sense of the sentences is considered instead of surface meaning. [Red double decker bus] [driving] [Double decker passenger bus] [driving] after 1:1 token alignment, if alignment results suggest multiple alignments for a token, the strongest (based on similarity score) alignment will be considered [Hundreds] [of Bangladesh clothes factory workers] [Hundreds] [fall] during alignment, it is possible to align one chunk with multiple chunks and 1: M chunk aligner is performing this task [2 dead], [2 injured] For unaligned chunks, followings rules are adopted: insert the unaligned chunk or group of chunks to 1:1 aligned chunks measure the similarity score of newly aligned chunk and chunks can be remained unaligned if no similarity exist punctuation is left unaligned
The surface representation of the sentences are different and deep meaning of the chunks shares the same meaning, so chunks are aligned with each other.
In the given example, ill can be aligned with fall or sick. But, similarity score between (ill vs. sick) is higher than (ill vs. fall). So, ill is aligned with sick.
Here, Nevada and in middle school shooting of second text is aligned with in Nevada middle school shooting of the first.
1:1 token aligner
It is one of the primary components of this alignment module, and in this section, the alignment procedure related to individual word pairs are discussed. Before aligning individual tokens of parallel sentences, each word pair are categorized into four groups, such as (i) identical words; (ii) named entities; (iii) content words; and (iv) stop words. [ [
Measuring word similarity
Three level of similarities are defined to identify the semantic similarity between words. The first level is an exact word or lemma matching, which considers the similarity score of 5. The next level represents the word similarity for nonidentical word pairs and has a similarity score (<5). The WordNet relatedness score and Paraphrase Database score are the keys to align a non–identical word pair. An average similarity score is measured to identify such word pairs, and for these JCN Distance [17], WUP similarity [39], and Resnik score [33] and Paraphrase Database (PPDB) score (of value in (0, 1)) of the most massive lexical package are considered [29]. Later, this similarity score is used to assign similarity score to an alignment.
Gather contextual evidence
Contextual evidence is collected from two sources: syntactic dependencies and cosine similarity between word vectors. To understand how this module works consider w
i
∈ S and w
j
∈ T as candidate pair for alignment and S and T are the two given sentences, which satisfy the following criteria: (w
i
, w
j
) shares some semantic information, in this case existence of a WordNet relatedness score and PPDB score is an evidence for alignment assume there exist a w
s
∈ S and w
t
∈ T, such that (w
i
, w
s
) of S have same dependency like (w
j
, w
t
) in T
For alignment of non–identical word pairs, dependencies are the important source for contextual evidence. If
Direct dependency between (w i , w j ).
We have also measured the contextual evidence for intra–category alignment of content words in four major categories: noun, verb, adjective, and adverb. The Stanford POS tagger is used to identify the categories. Table 1 shows each equivalence type dependency for each lexical category of S and T. This list of dependency relation constitutes the key feature for a bi–directional alignment of (w i , w j ) and (w s , w t ). This intra–category alignment of content words is considered as equivalence type dependency and an example of such alignment is shown in Fig. 3. The dobj dependency in S is equivalent to the nsubj dependency in T, since they represent the same semantic relation.
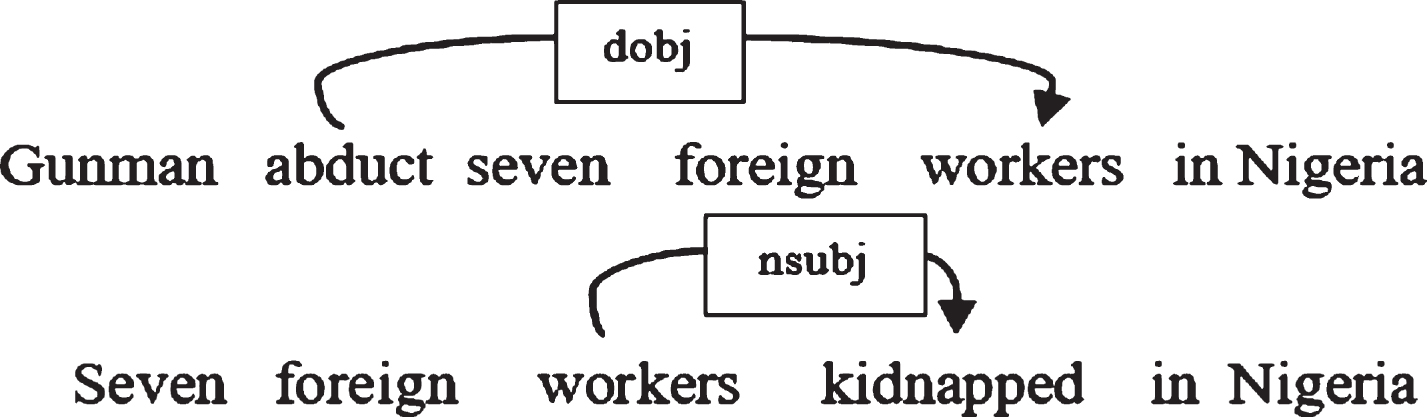
Equivalence dependency between (w s , w t ).
Direct and equivalence dependency structures
At first, without considering all semantically similar word pairs, the aligned pairs are only examined. A window length of n = 3 is considered here for aligning stop words those appear with the identical words. Secondly, many stop words such as determiners and modals have a very little effect on the dependency structure they engage in, so only exact matching of dependencies is considered here.
This is the second primary alignment component, which accepts all the 1:1 token aligned pairs and the chunks of S and T as input. The fundamental goal of this module is as follows: aligning the chunks by considering all 1:1 token alignment information and leaving minimum chunks as unaligned, by considering minimum to maximum contextual evidence between word pairs. The formation of contextual evidence is already discussed in Section 4.3.2 and 4.3.3. the unaligned chunks of S can be aligned with any one of the aligned chunks of T or vice versa if alignment is possible by considering the minimum similarity or contextual evidence, then assign a new relation to this alignment and a new similarity score to this. Assignment of a relation type and similarity score is discussed in Section 4.5 and 4.4. on failing of above conditions chunks left as unaligned
To align chunks of S and T, the system has taken two inputs, all the chunks those are identified during chunking of individual sentences and output of 1:1 token aligner. To shift from a token-alignment to chunk alignment following features set is considered: Consider the boundary of each chunk of S and T, if token t
i
∈ c
i
of S is already aligned to a token of c
j
of T, all token of c
i
is aligned with c
j
. The cosine similarity between the chunks is the final consideration for alignment of an unaligned fragment with a threshold value (th ≥ 0.3) and (th < 0.7). Reason to choose this threshold value are discussed in Section 5.3.
Table 2, represents an output of token to chunk multi aligner. At first, individual tokens of S and T are aligned, where t
i
and t
j
represents the token of S and T. Then chunking of S and T is carried out and output of 1:1 token aligner is refined, by considering the chunk boundary. At last unaligned chunks of S and T are considered for alignment.
Output of a token to chunk multi aligner
Output of a token to chunk multi aligner
Alignment scores are assigned as direct assignment between the aligned chunks or average similarity/ relatedness score for each token [20]. For direct assignment, 0 and 5 are assigned for ‘NOALI’ and ‘EQUI’ relation types, respectively. To measure the chunk similarity, we have adopted the method described by [15], given in Equation 1.
Measuring WordNet relatedness score between content words and the SEMILAR Toolkit is used here [34]. The available similarity score between word pair in the largest (XXXL) PPDB’s lexical praphrase package [29]. Google pre–trained Word2Vec model (of 300 dimension) [27] is used to measure the cosine similarity between the two word vectors and Python implemented gensim [32] library is used for this purpose.
This module takes a pair of chunk as an input and provides a reason why the particular pair is aligned. This reasoning module get inspired from NeroSim [7], VRep [15] and SVCSTS [20] methods, and these methods classified a pair of chunks using the features extracted from the chunk itself. We have adopted all the semantic (such as antonyms, synonyms etc.) and syntactic (such as number of word counts, part of speech etc.) features used in NeroSim and SVCSTS and jointly a set of features have been designed to assign the relation type. In Table 3, we have listed out required features for assigning a relation to each aligned chunk pair.
Relation Types with Required Feature Sets
Relation Types with Required Feature Sets
Dataset information
The SemEval–2016 Task 2 dataset is used for experimentation which comprises of sentence pair from news headlines (tagged as Headlines) and image description (tagged as Images). The Headlines dataset gathered by the Europe Media Monitor engine from several different news sources (from April 2nd, 2013 to July 28th, 2014) mentioned in [8]. The Images dataset is a part of PASCALVOC-2008 dataset [31] which consists of 1000 images with around 10 descriptions each. The different statistics of dataset is reported in Table 4.
Statistics of Dataset with Relation Type
Statistics of Dataset with Relation Type
The Word Alignment Evaluation method is adopted here, which is based on F1 score of precision and recall of token alignments [25]. In literature, it has been argued that F1 is better measure than Alignment Error Rate [13]. Precision and recall are measured as the ratio of token–token alignments of SYS and GS files. For precision the ratio is divided by the number of alignments in SYS files and for recall it is divided by the number of alignments in the GS file.
Performance of the proposed method is measured by four distinct evaluation matrices such as: (i)
Significance of threshold (th) value
From the analysis of train and test dataset, it is clear that the availability of ‘EQUI’ type is higher than other types and detail statistics on dataset is listed in Table 4). Required features with individual alignment types have been listed in Table 3, and cosine similarity is one of the features that we have used for this task. To extract the cosine similarity score between two chunks, the Google pre–trained Word2Vec model is used here.
The goal of the alignment module is to align as many as chunks of S and T. For this purpose, all unaligned chunks are aligned against the aligned chunks of each sentences to find any semantic relation. On the availability of semantic relations, 1: M multi chunk aligner extracts the cosine similarity score from Google pre–trained data. To assign correct alignment (by considering minimum evidence), an experiment has been conducted to fix a threshold value (th). It is found that if th considers a value of 0.7 or above as similarity score, chunks are sharing maximum semantic relation, which is valid for ‘EQUI’ type. But if system considers a th value as less than 0.3 (cosine similarity score), chunks having no semantic relationship also get aligned. This simple heuristic achieves an F1–Ali score of 0.95.
Result analysis
In this work, a 1:M (multi) chunk aligner is proposed, which is based on two major modules. The proposed chunk aligner is verified over the data of two individual domains. Next, we have reported the performance of all modules and also compared the performance of proposed aligner against the other state-of-art alignment methods. Results of the proposed method, with other state–of–art methods are listed in Table 5.
Results of Headline (H) and Image (I) Dataset with other State-of-Art Methods
Results of Headline (H) and Image (I) Dataset with other State-of-Art Methods
We have compared the performance of the proposed alignment method against the alignment methods, which are reported in SemEval 2016 Task 2 [3]. UBC [2] had adopted the monolingual word aligner [36] for 1:1 token alignment and Hungarian–Munkres assignment problem was used to align chunks. In VRep [15], a similarity score between a pair of the chunk was considered for alignment. To measure the similarity score, the vector relatedness measure [30] was used. A token–token aligner was proposed in iUBC [23] and similarity matrices like lowercased token overlap, stemmed or lemmatized token overlap, cosine similarity between Mikolov’s pre–trained word vectors were used [27] and based on different semantic relations and scores an aligner was proposed in DTSim [6], which was based on 1:1 token aligner [7].
The proposed aligner uses the features like word vectors and adopts the dependency structures those were reported in [36], to measure the contextual evidence between a pair of word. The difference with the aligner as mentioned above is measuring three level of similarity score between words and divide the 1:1 alignment task into four sub–modules. For this task, the minimum contextual evidence is considered to align an unaligned chunks. Majority of the state–of–art methods have used two matrices for alignment, which cost an extra burden of computation. In proposed method, it only considers the chunk boundary, until the alignment of all tokens of each chunk, which reduces the computational burden.
Conclusion
In this paper, we have proposed a token to chunk multi aligner as a part of an interpretable semantic textual similarity method. The proposed work is inspired from SemEval 2016 Task 2, which has addressed the issues related to interpretability of two sentences. Three level of word and contextual similarity of word are considered for 1:1 token alignment. The proposed method has been evaluated and tested over SemEval 2016 Task 2 dataset and experimental results shows that the proposed aligner outperforms many state–of–art aligner which were part of SemEval 2016 Task 2. These comparisons have been performed on state–of–art methods, which were developed over same datasets.