
Abstract
There are many problems were the objects under study are described by mixed data (numerical and non numerical features) and similarity functions different from the exact matching are usually employed to compare them. Some algorithms for mining frequent patterns allow the use of Boolean similarity functions different from exact matching. However, they do not allow the use of non Boolean similarity functions. Transforming a non Boolean similarity function into a Boolean one, and then applying the previous algorithms for mining frequent patterns, could lead to loss some patterns, and even more to generate some other patterns which indeed should not be considered as frequent similar patterns. In this paper, we extend the similar frequent pattern mining by allowing the use of non Boolean similarity functions. Several properties for pruning the search space of frequent similar patterns and a data structure that allows computing the frequency of patterns candidates, are proposed. Also, three algorithms for mining frequent patterns using non Boolean similarity functions are proposed. Experimental results show the efficiency and efficacy of the algorithms. The proposed algorithms obtain better patterns for classification than those patterns obtained by traditional frequent pattern miners, and miners using Boolean similarity functions.
Introduction
Frequent pattern mining has become an important task in data mining research [1, 2]. Frequent patterns have been used in many applications to discover useful information, as user’s profiles [3], malicious software instructions [4], risk factors [5], human behaviours [6], etc. Also, frequent pattern mining is usually the first and more expensive step of association rule mining [7], another well known and widely studied data mining task. Moreover, frequent patterns have been useful for other tasks like classification [8] and clustering [9].
A frequent pattern is a combination of feature values that appears in a dataset with a frequency greater than or equal to a user-specified frequency threshold.
In the first researches on frequent pattern mining [10], the objects under study were described through Boolean features. Nonetheless to the simplicity of the domain of the features, frequent pattern mining is a difficult task, since the search space grows exponentially regarding to the number of features. There are other situations that make dificult the frequent pattern mining task: I) In real world problems datasets usually contain objects described by mixed data (numerical and non numerical features). II) In real life objects almost never exactly match. III) Not all similarity functions are Boolean. There are many problems in which the available similarity function is not Boolean. For example, they have been used to compare documents [11], for modeling semantic relations [12, 13], for differential diagnosis of glaucoma, for comparing somatotypes, and for prognosis of the rehabilitation of patients with cleft lip and palete [14].
All algorithms for mining frequent similar patterns reported in the literature (ObjectMiner [15], STreeDC-Miner [16], STreeNDC-Miner [16] and RP-Miner [17] and CFSP-Miner [18]) have focused on Boolean similarity functions. Therefore, we have two options for mining frequent similar patterns with non Boolean similarity functions: transforming the non Boolean similarity functions into Boolean similarity functions; or developing new algorithms for mining frequent similar patterns that use non Boolean similarity functions. However, transforming the non Boolean similarity function into a Boolean one could lead to loss some frequent similar patterns and/or to generate some frequent similar patterns, which should not be generated.
In the present work, we focused on frequent similar pattern mining using non Boolean similarity functions. Thus, STreeDC-Miner [16], STreeNDC-Miner [16] and RP-Miner [17] which use Boolean similarity functions, are extended for using non Boolean similarity functions. Preliminary results on this topic, where presented in the short conference paper [19]. The main differences of the current paper with the short conference paper are: I) we formalize and prove theoretical properties in which our frequent similar pattern mining algorithms are based, II) we provide more details about the algorithm STree*DC-Miner [19], for using non Boolean similarity functions that holds the f S -downward closure property, and III) based on the theoretical properties we introduce two new algorithms STree*NDC-Miner and RP*-Miner for using non Boolean similarity functions that do not hold the f S -downward closure property.
Basic concepts and results
Let Ω = {O1, O2, …, O n } be a dataset. Each object O i is described by a set of features R = {r1, r2, …, r m } and represented as a tuple (v1, v2, …, v m ) where v i ∈ D i (D i is the domain of the feature r i , 1 ≤ i ≤ m). A subdescription of an object O for a subset of features S ⊆ R denoted by I S (O), is the description of O in terms of the features in S; O [r] denotes the value of the feature r ∈ R in O; and f S : Ω × Ω → [0, 1] a similarity function between O and O′ using their subdescriptions I S (O) and I S (O′) respectively. For simplicity we will denote f S (O, O) instead of f S (I S (O) , I S (O′)). Two examples of similarity functions are:
where C
r
: D
r
× D
r
→ [0, 1] is a comparison function between the values of the feature r. Three examples of comparison functions are:
Notice that the similarity function (1) can be Boolean (if ∀r ∈ S, C r is Boolean) or non Boolean (if ∃r ∈ S, C r is non Boolean). The similarity function (2) is non Boolean.
Let I
S
(O) be a subdescription, O ∈ Ω, ∅ ≠ S ⊆ R, and f
S
be a Boolean similarity function; then the frequency of I
S
(O) in Ω for f
S
was defined in [16] as:
It can be noticed that if f S were a Boolean similarity function, (7) and (6) would be equals.
Also, we say that I S (O) is a frequent similar pattern in Ω, also called f S -frequent subdescription, if its frequency is greater than or equal to a frequency threshold minFreq. Given a dataset of objects Ω described by a set of features R, a non Boolean similarity function f S , and a frequency threshold minFreq, the frequent similar pattern mining problem consists in finding all frequent similar patterns in Ω using the non Boolean similarity function to compute the frequency of the subdescriptions by using (7).
The downward closure property (dcp) is used in frequent itemset mining for pruning the search space [20]. This property ensures that all supersets of a non frequent itemset are also non frequent itemsets. An analogous dcp, in the context of frequent similar pattern mining, expresses that: all superdescriptions of a non f S -frequent subdescription are also non f S -frequent subdescriptions. This property is called f S -downward closure property (f S -dcp). Given a non-Bolean similarity function, we can define the dcp for non Boolean similarity functions as follows:
However, this property, unlike the dcp for frequent itemset mining, is not always true. Its fulfillment depends on whether the frequency and similarity function are monotonic.
The similarity function (1) from section 2 is a non increasing monotonic similarity function, while the similarity function (2) is not.
The dependencies among the dcp, the monotony of the frequency and the monotony of the similarity function can be expressed as follows:
For non Boolean similarity functions, we define the following concept which will be used for pruning.
In contraposition, a subdescription I S (O), O ∈ Ω, is considered a nonf S -interesting pattern if f S freq (O) < minFreq and ∀O′ ; O′ ∈ Ω; I S (O′) ≠ I S (O) [f S freq(O′)≥minFreq]⇒[f S (O′, O) =0].
Notice that, those non f S -interesting patterns neither are frequent similar patterns nor contribute to the frequency of any frequent similar pattern. Additionally, from Proposition 4, all superdescriptions of a non f S -interesting pattern are not frequent similar patterns. Therefore, all non f S -interesting patterns can be pruned without losing frequent similar patterns.
In order to compute the frequency and to reduce the number of similarity function evaluations, for non Boolean similarity, functions we propose a data structure, that we name STree*,1. Given a set of features S ⊆ R, a
Given a
In this expression
On the other hand, if the non Boolean similarity function is non increasing monotonic then the number of similarity function evaluations can be reduced even more.
Using the Proposition 5, let f
S
be a non increasing monotonic non Boolean similarity function, Let
Consequently, the frequency of a subdescription
In this expression the second term of the sum in the numerator is the sum of the similarities different from 0, between
In general a Building the empty Adding all object subdescriptions that the Computing the set Computing
When the
On the following subsections, the 3 frequent similar pattern mining algorithms proposed for using non Boolean similarity functions are described.
STree*DC-Miner algorithm
The STree*DC-Miner algorithm (Algorithm 1) allows mining frequent similar patterns using non Boolean similarity functions that hold the f S -dcp.

The STree*DC-Miner algorithm is based on the following points: Assuming that f
S
holds the f
S
-dcp. As a consequence: Non interesting patterns are pruned. For this, the search space is explored starting from the interesting patterns described by only one feature and then by means of successive expansions, in which a feature and a feature value are added to each interesting pattern. For each expansion of an interesting pattern, we verify if the expansion is a frequent similar pattern, larger patterns are explored. The frequencies of expansions of the interesting but non frequent similar patterns, are not computed, since only superdescriptions of frequent similar patterns can be frequent similar patterns. Additionally, it is not needed to compute the similarity between expansions of patterns that are interesting but non frequent similar patterns. If the similarity of a subdescription P to another subdescription P′ is equal to 0, it is not needed to compute the similarity of a superdescription Considering identical subdescriptions as an unique subdescription (using
Let ≺ be a linear order on R and f
S
a non increasing monotonic non Boolean similarity function, we consider that: A subset of features S is expandable, if S =∅ or there is at least one similar frequent pattern I
S
(O). A subset of features A subset of features
The STree*DC-Miner algorithm (Algorithm 1) starts with an empty set of features
STree*NDC-Miner algorithm
The STree*NDC-Miner algorithm (Algorithm 2) allows mining frequent similar patterns using non Boolean similarity functions that do not hold the f S -dcp.

If a non Boolean similarity function does not hold the f
S
-dcp then we cannot ensure that non interesting patterns can be pruned without losing frequent similar patterns. Also, the similarity from all subdescriptions P to all subdescriptions P′, such that P ≠ P′, should be computed; otherwise, some frequent similar patterns could be lost. Therefore, in order to avoid the lose of frequent similar patterns, it is needed to search the frequent similar patterns for all S ⊆ R, S≠ ∅. However, STree*NDC-Miner prunes this search based on the following points: Considering identical subdescriptions as a unique subdescription reduces the number of similarity function evaluations. The search space is explored from subdescriptions with all features to subdescriptions with only one feature, by means of successive reductions removing one feature each time. Notice that, given a subdescription P, the number of repetitions of P is equal to the sum of the number of repetitions for each superdescription
Let ≺ a linear order on R and f
S
a non Boolean similarity function that does not hold the f
S
-dcp, we consider that: A subset of features S is reducible, if S≠ ∅ A subset of features A subset of features
The STree*NDC-Miner algorithm (Algorithm 2) starts from the whole set of features
RP*-Miner algorithm
For a non Boolean similarity function which does not hold the f S -dcp, some superdescriptions of the non frequent similar patterns could be frequent similar patterns. Therefore, if all non f S -interesting patterns are removed (like STree*DC-Miner does), then some frequent similar patterns could be lost. On the other hand, if the search space of frequent similar patterns is exhaustively explored (like STree*NDC-Miner does), then all frequent similar patterns are found, but this process is very expensive. We propose the RP*-Miner algorithm as an alternative.
The general idea of RP*-Miner is as follows: First, all frequent similar patterns with only one feature are obtained. Then, each frequent similar pattern is successively expanded by adding a feature and a feature value. It is important to highlight that a pattern with k features could be obtained by expanding different patterns with k - 1 features. In our expansion process, if a pattern has been previously obtained then the repeated pattern is neither analyzed, nor expanded.
The RP*-Miner algorithm (Algorithm 3) starts with an empty set of features

Experiment results
In this section, we show the performance of the proposed algorithms. For comparing the performance of our algorithms we use the following measures: Efficiency of an algorithm in terms of its runtime. Less runtime implies more efficiency. Efficacy of an algorithm in terms of the number frequent similar patterns obtained. More patterns implies more efficacy Quality of the patterns found by an algorithm in terms of the accuracy achieved by a simple supervised classifier based on frequent patterns. This classifier, in the training phase, obtains the set of frequent similar patterns from each class and removes all frequent similar patterns that appear in more than one class, keeping only patterns that represent objects from a single class. In the classification phase, each object of the test collection is classified into the class where there are more frequent similar patterns similar to its subdescriptions. The accuracy is measured as the percentage of objects correctly classified. For each collection and for each value for the minFreq parameter, we repeated the experiment 10 times, randomly selecting 50% of the collection for training and using the remaining objects for testing.
Table 1 gives a description of the collections 2 used in our experiments.
Description of the datasets used in the experiments
Description of the datasets used in the experiments
In section 6.1, the proposed algorithm STree*DC-Miner is compared to STreeDC-Miner using a non Boolean similarity function that holds the f S downward closure property. For applying STreeDC-Miner the similarity function was Booleanized. In section 6.2, STree*DC-Miner, STree*NDC-Miner and RP*-Miner are compared using a non Boolean similarity function that does not hold the f S -dcp.
For this experiment, as a non Boolean similarity function that holds the f S -dcp we use the similarity function (1) from section 2 jointly with the comparison function (4) for numerical features and the equality (3) for non numerical features. We use the similarity function (1) using the comparison function (5) with α = 0.9 for numerical features and the equality (3) for non numerical features, as Boolean similarity function that holds the f S downward closure property. Notice that the function (1) by using (5) for numerical features, and the equality (3) for non numerical features, is a Booleanization of the non Boolean similarity function obtained by using (1) and (4).
In this experiment, for mining frequent similar patterns with the non Boolean similarly function we use STree*DC-Miner, and for mining frequent similar patterns with the Boolean similarly function we only use STreeDC-Miner although ObjectMiner, STreeDC-Miner, STreeNDC-Miner and RP-Miner obtain the same set of frequent similar patterns (they have the same efficacy) but STreeDC-Miner is the most efficient [16].
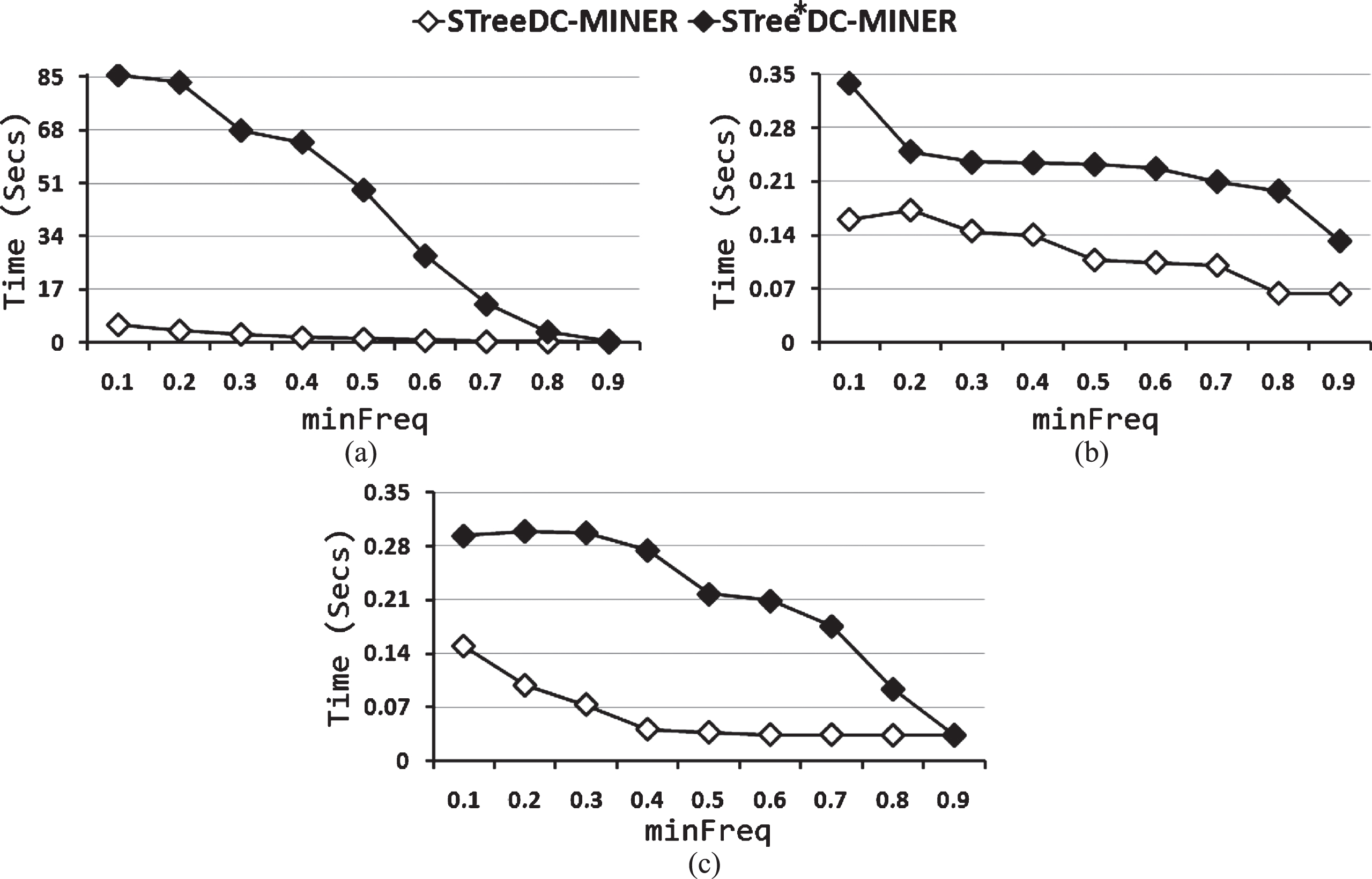
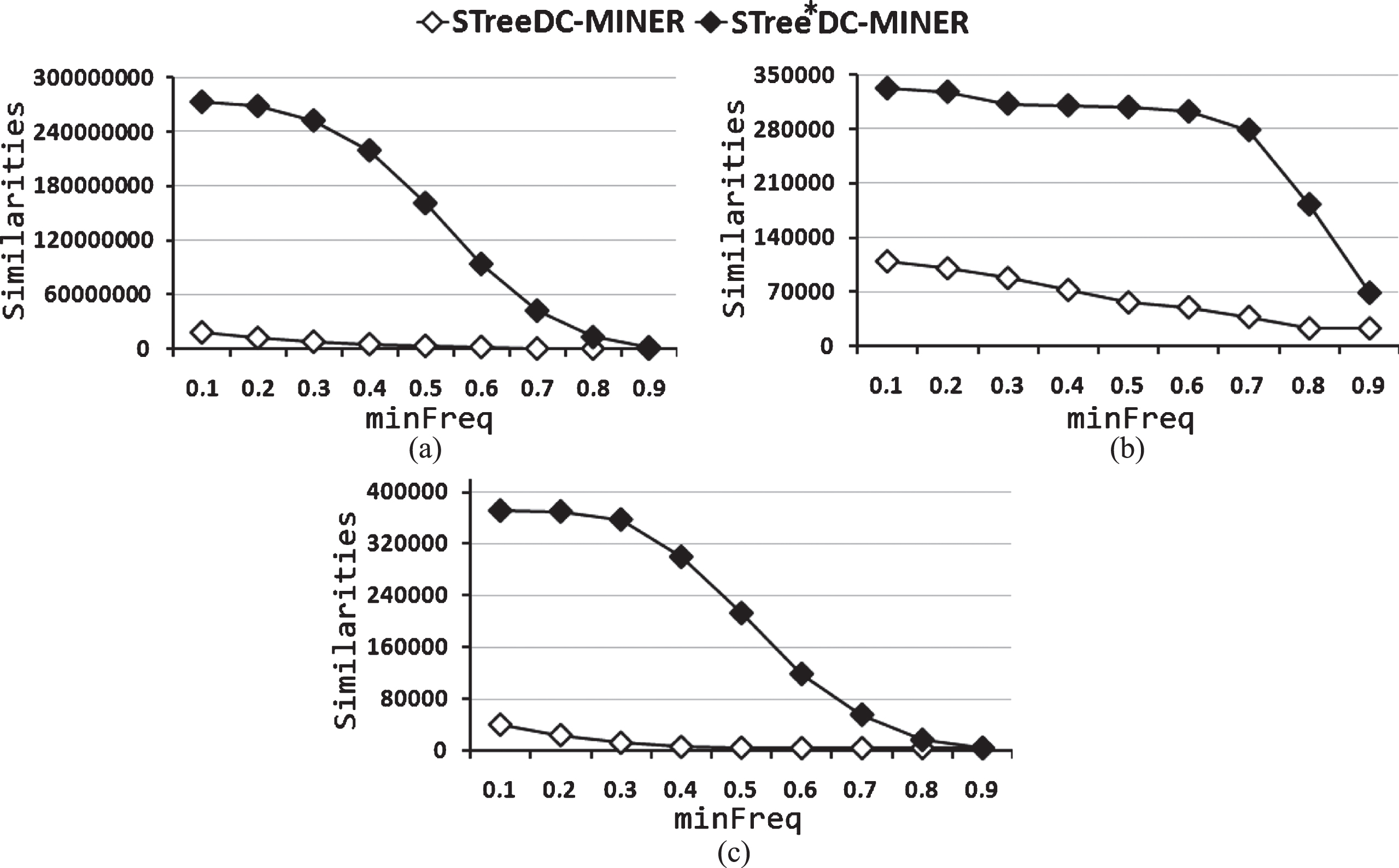
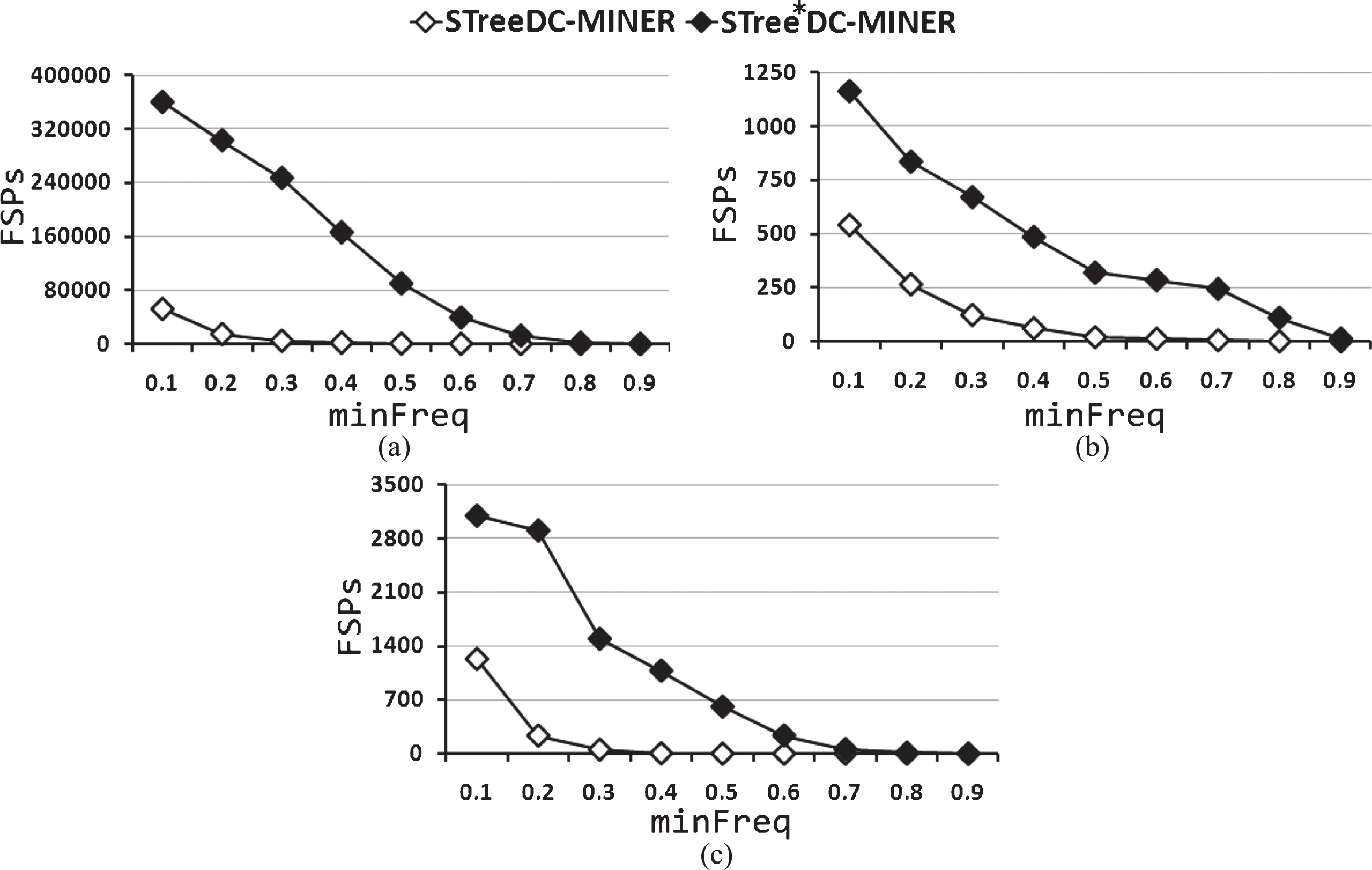
Figure 1 shows the runtime of STree*DC-Miner and STreeDC-Miner for several values of the minFreq threshold for the collections Diabetes, Liver Disorders and Iris. From this figure, we can see that STreeDC-Miner is more efficient than STree*DC-Miner. This result can be explained by the following reasons: STreeDC-Miner uses arithmetic operations with integer numbers (similarity values are 0 or 1), which are faster than float point arithmetic operations, which are used by STree*DC-Miner (similarity values are in [0, 1]). The number of similarity function evaluations made by STreeDC-Miner is less than the number of similarity function evaluations made by STree*DC-Miner (see Fig. 2). The number of frequent similar patterns obtained by STreeDC-Miner is smaller than the number of frequent similar patterns obtained by STree*DC-Miner (see Fig. 3). Runtime using a non Boolean similarity function, which holds the f
S
downward closure property and a Booleanization of this function, for (a) Diabetes, (b) Liver Disorders and (c) Iris. Number of similarity function evaluations using a non Boolean similarity function, which holds the f
S
-dcp and a Booleanization of this function, for (a) Diabetes, (b) Liver Disorders and (c) Iris. Number of frequent similar patterns using a non Boolean similarity function, which holds the f
S
-dcp and a Booleanization of this function, for (a) Diabetes, (b) Liver Disorders and (c) Iris.
The quality of the set of frequent similar patterns obtained by using the non Boolean similarity function and its Booleanization is shown in Table 2. As a reference, we included the quality of the set of frequent similar patterns obtained using the equality as similarity function, like in the traditional approach. For each collection and for all the algorithms used for mining frequent similar patterns, the classification was done by testing different values of the minFreq threshold from minFreq = 0.1 until minFreq = 0.9 with increments of 0.1.
From Table 2, we can observe that the classification accuracies achieved by using the frequent similar patterns obtained by our algorithm (STree*DC-Miner) are better than the classification accuracies achieved using the frequent similar patterns obtained by STreeDC-Miner using a Booleanization of this function. These results confirm the negative effect of transforming a non Boolean similarity function into a Boolean one.
It can be also noticed from Table 2 that using the equality, as in the traditional approach, the classification accuracies reached by the set of frequent patterns are lower than the classification accuracies reached by using the set of frequent similar patterns obtained using either Boolean or non Boolean similarity functions (different from the equality).
Quality of the sets of frequent similar patterns using a non Boolean similarity function, which holds the f S -dcp, a Booleanization of this function, and the Traditional Approach
Additionally, in Table 2, it can be seen that when the minFreq threshold increases, the classification accuracy decreases because the number of frequent patterns also decreases. However, the use of non Boolean similarity functions allows our algorithm to find more similar frequent patterns, even for high values of the minFreq threshold, and therefore, the accuracy decreases slower than using the frequent patterns found by algorithms that use Boolean similarity functions. Moreover, when the equality was used as similarity function, the number of frequent patterns found for the Diabetes collection was too low even for small values of the minFreq threshold. Therefore, for this collection, the classifier was unable to correctly classify any object in the testing set.
We used the similarity function (2) from section 2 as a non Boolean similarity function that does not hold the f S -dcp. For this similarity function we used the comparison function (4) for numerical features and the equality (3) for non numerical features.
Figure 4 shows the runtime of STree*DC-Miner, RP*-Miner and STree*NDC-Miner for several values of the minFreq threshold over the Diabetes, Liver Disorders and Iris datasets.
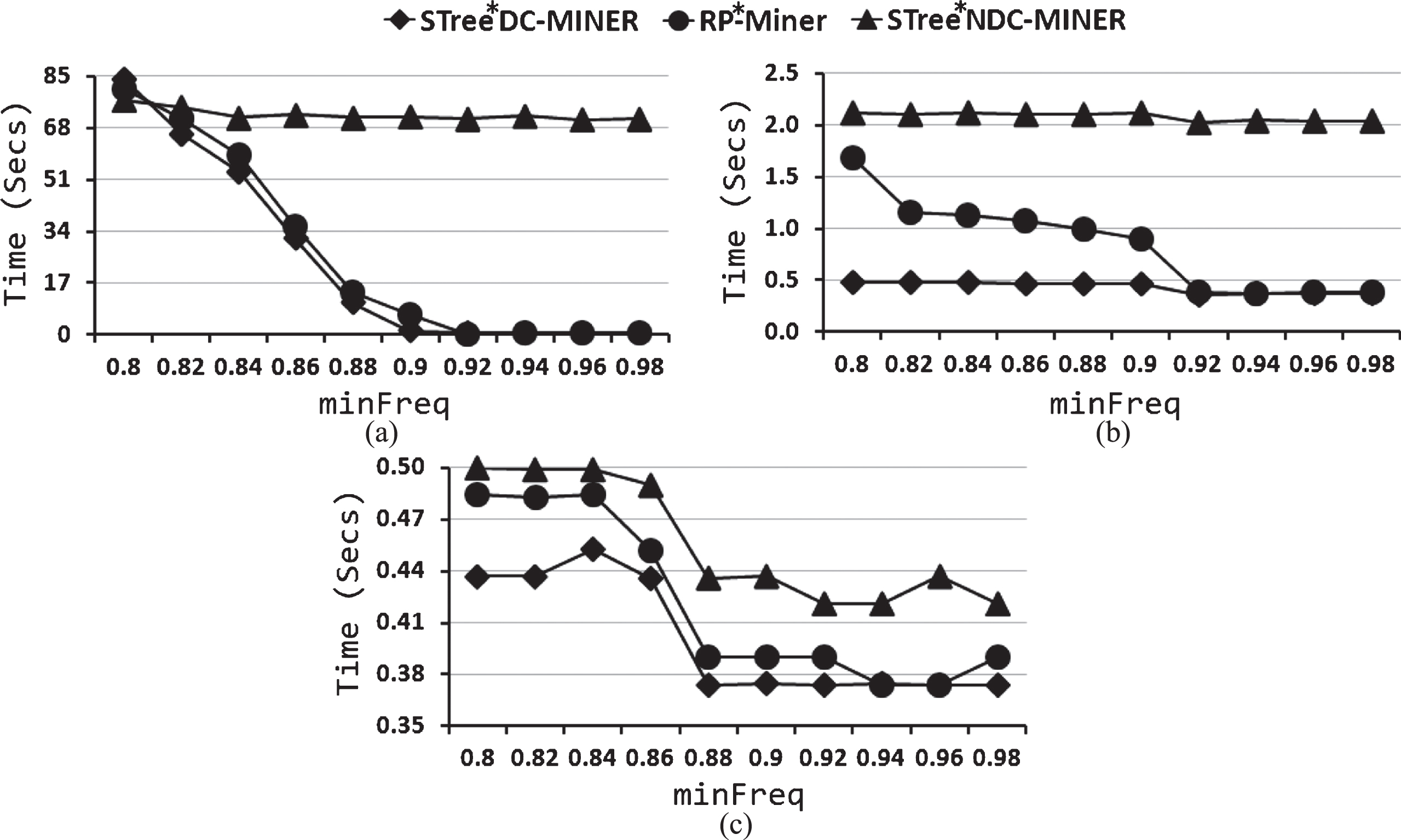
Runtime using a non Boolean similarity function, which holds the f S downward closure property and a Booleanization of this function, for (a) Diabetes, (b) Liver Disorders and (c) Iris.
For all collections, the faster algorithm was STree* DC-Miner, followed by RP*-Miner. The runtime of STree*NDC-Miner was almost always greater than the runtimes of STree*DC-Miner and RP*-Miner. This is a consequence of the number of frequent similar patterns obtained (see Table 3) and the number of similarity function evaluations(see Figure 5). Nevertheless, the runtime of STree*NDC-Miner was always less than 76 secs for the tested collections.
Number of frequent similar patterns using a non Boolean similarity function, which does not hold the f S -dcp
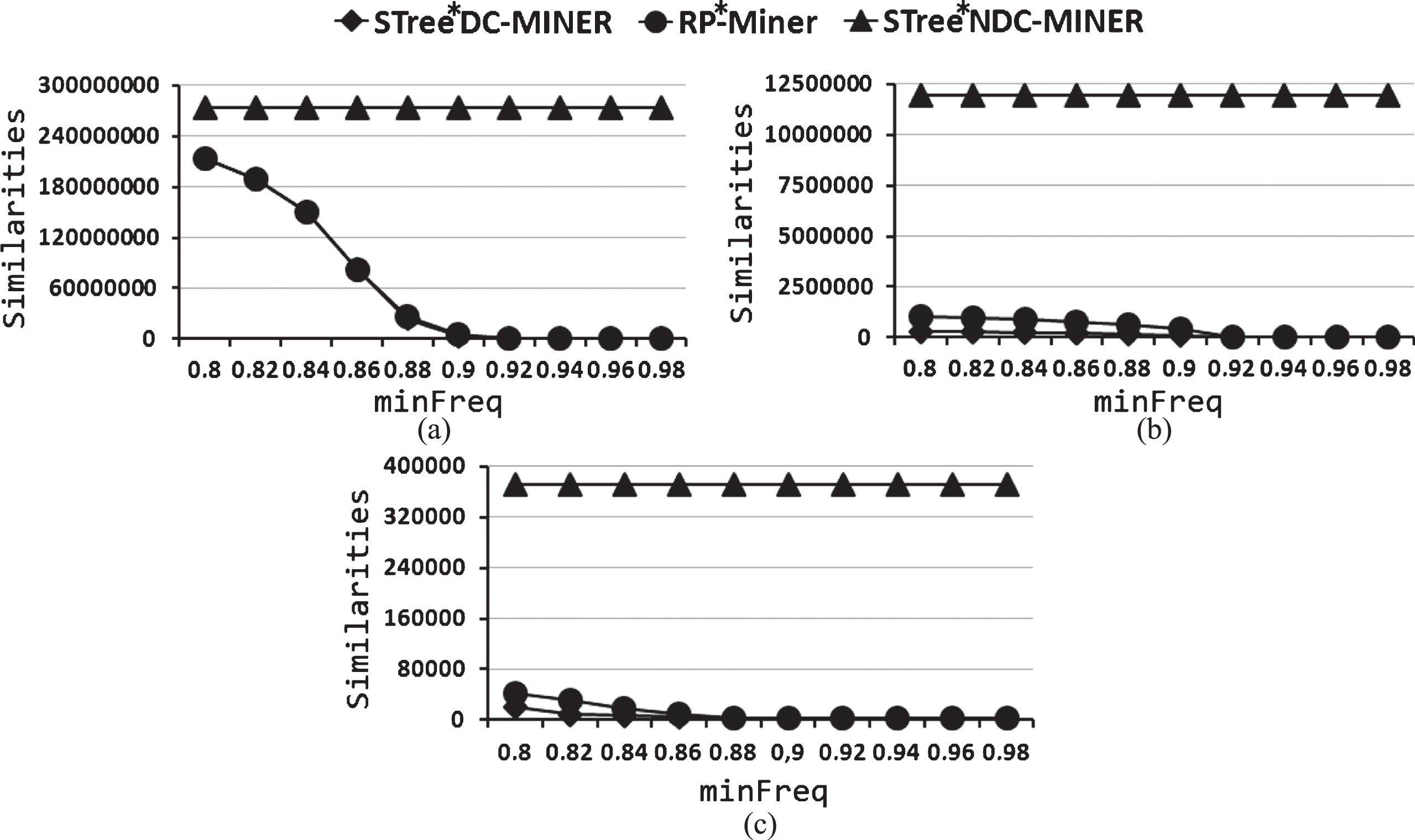
Number of similarity function evaluations using a non Boolean similarity function, which holds the f S -dcp and a Booleanization of this function, for (a) Diabetes, (b) Liver Disorders and (c) Iris.
It is important to highlight that STree*NDC-Miner always found all frequent similar patterns, since it follows an exhaustive strategy, while STree*DC-Miner, which assumes that the similarity function holds the f S -dcp, could not found all frequent similar patterns. On the other hand, RP*-Miner due to its relaxed prune, generally found more frequent similar patterns than STree*DC-Miner.
The quality of the set of frequent similar patterns obtained by RP*-Miner, STree*DC-Miner and STree*NDC-Miner using the non Boolean similarity function that does not hold the f S -dcp is shown in Table 4. Again, we included the quality of the set of frequent patterns obtained using the equality as similarity function, like in the traditional approach. For each collection and for all the algorithms used for mining frequent similar patterns, the classification was done testing different values of the minFreq threshold from minFreq = 0.80 to minFreq = 0.98 with increments of 0.02.
Quality of the sets of frequent similar patterns using a non Boolean similarity function, which does not hold the f S -dcp
In most of the cases, the quality of the set of frequent similar patterns found by STree*NDC-Miner was better than the quality of set of frequent similar patterns found by STree*DC-Miner and RP*-Miner. In fact, the best classification accuracies (cells with bold text in Table 4) were obtained by STree*NDC-Miner followed by RP*-Miner.
In this paper, we focused on frequent similar pattern mining using non Boolean similarity functions. We proposed and proved several properties that allow pruning the search space of frequent similar patterns when a non Boolean similarity function is used. Also, we proposed three novel algorithms: STree*DC-Miner, RP*-Miner and STree*NDC-Miner. The STree*DC-Miner algorithm assumes that the similarity function holds the f S downward closure property and uses it to prune the search space of frequent similar patterns. The STree*NDC-Miner algorithm does not assume that the similarity function holds any property, therefore it does not prune the search space. Finally the RP*-Miner algorithm performs a relaxed prune of the search space of frequent similar patterns, in this way RP*-Miner finds more frequent similar patterns than STree*DC-Miner with less computational effort than STree*NDC-Miner.
From our experiments, we can conclude that, for problems where the similarity function holds the f S downward closure property, our proposed STree*DC-Miner algorithm obtains a set of frequent similar patterns with better quality than those obtained when the similarity function is Booleanized. This confirm the negative effect of transforming a non Boolean similarity function into a Boolean similarity function for computing frequent similar patterns with the miners reported in the literature. Moreover, the quality of the frequent similar patterns obtained by STree*DC-Miner is also better than the quality of the frequent patterns obtained using the equality as similarity function (traditional approach).
For problems where the similarity function does not hold the f S downward closure property, we can conclude that, RP*-Miner finds more frequent similar patterns with better quality than STree*DC-Miner. For this kind of functions STree*NDC-Miner is the only algorithm that finds all frequent similar patterns, however, RP*-Miner is faster.
As future work, we visualize extending closed frequent similar patterns mining and association rules mining for non Boolean similarity functions and non-monotonic similarity functions.