
Abstract
Due to the development of modern internet-based technology, the electronically stored information is growing exponentially with time. It is highly challenging to select relevant and non-redundant features of the real-valued high dimensional datasets. Feature selection, a preprocessing technique, refers to the process of reducing the dimension of the input data in order to extract the most meaningful features for processing and analysis. One of the numerous useful applications of rough set theory is the attribute or feature selection, but it has certain limitations as it cannot be applied on real-valued data sets directly because rough set based feature selection can handle discrete data only. In order to deal with real-valued data sets, discretization method is applied to convert dataset from real-valued to discrete, which usually leads to information loss. Fuzzy rough set theory is profitably applied to address this problem and retain the semantics of real-valued datasets. However, intuitionistic fuzzy set can deal with uncertainty in a much better way when compared to fuzzy set theory as it considers membership, non-membership and hesitancy degree of an object simultaneously. In this paper, an intuitionistic fuzzy rough set model is established by combining intuitionistic fuzzy set and rough set. Furthermore, we propose a novel approach of feature selection derived from this model. Moreover, we develop an algorithm based on our proposed concept. Finally, our approach is applied to some benchmark data sets and compared with the existing fuzzy rough set based technique. The performed experiments show the superiority of our approach.
Introduction
Nowadays, all business organizations regularly receive data due to advancement of internet-based technology on millions of observations across diverse subjects, at regular time periods, brands, predictor variables and storage locations. Every day quintillions bytes of data are recorded at diverse sources like sensor data pertaining to climate information, agricultural information, and census information, etc., that get posted to many related social media sites like digital pictures and videos, purchase and sale transaction records and GPS signals of cell phones etc. to name a few [9, 10]. Such huge amount of data from various sources may lead to lots of difficulties in learning by the system through various classifiers because of several redundant features available in datasets. The operational cost of computation and time needed during classification process are extremely sensitive to the number of features used to build a rule-based classifier. The existing features in a dataset can be categorized as redundant, irrelevant, misleading and predictive or relevant features. The presence of irrelevant and redundant features increases the computational load and the availability of misleading features in a dataset reduce the overall classification accuracy as it leads the classification task negatively. However, predictive or relevant features are better performing in the process of interclass discrimination and always lead to better average classification accuracy. So, it is essential to remove misleading, redundant and irrelevant features available in a dataset by preserving predictive features. To achieve this, various dimensionality reduction techniques are applied to acquire more significant and less or no redundant features. Feature selection or attribute reduction is the most frequently used dimensionality reduction technique. Several factors motivate for dimensionality reduction in various problem solving systems [12]. Feature Selection can be applied as the valuable preprocessing step for the application in tasks that involve high dimensional datasets, such as gene expression microarray data, which might be impossible to process further for some learning algorithms. Feature Selection is successfully applied to small and medium sized datasets with the purpose of finding the most informative features. Feature selection is used as preprocessing step in various important fields like data mining, signal processing, machine learning and bioinformatics, etc. [1–8].
Rough set theory (proposed by Pawlak) [13–15] can be used as a tool to determine data dependencies and to reduce the dimension of the dataset using the information from data alone without any additional information. Rough set based attribute selection approach has been successfully implemented to reduce the number of features with preserving the essence of the features. Rough set theory can produce the most informative subset of features from original attribute set of a dataset with discretized feature values. In case of real-valued datasets, rough set theory struggles as it can be applied to the datasets having features containing symbolic values only. So, discretization is applied to the real-valued datasets before using rough set based approach for feature selection, which usually leads to information loss. This problem was solved by using fuzzy rough set based approach for feature selection, which can tackle real-valued datasets in a better way.
D. Dubois and Henry Prade [16, 17] combined fuzzy set [23, 24] (proposed by Zadeh [18, 19]) and rough set (proposed by Pawlak) and presented the concept of fuzzy rough set. Fuzzy-rough set theory is evolved to address the two analogous and complementary concepts, viz., vagueness (for fuzzy set) and indiscernibility concept (for rough sets) with distinct notions and both the concepts are generated as the results of uncertainty in knowledge, which can be implemented for feature selection of datasets containing either discrete or continuous or heterogeneous attributes. The concept of a dependency function in a traditional rough set model into the fuzzy occurrence was proposed by Jensen and Shen [35] and introduced a feature selection algorithm using fuzzy rough set concept and improved in [11, 29–34] and [36–42].
Many uncertainty problems cannot be suitably handled by fuzzy set. For example, some base patterns exist in most of the medical diagnosis problems, and decisions are made by the experts on the basis of similarity between unknown sample and the base patterns, but the uncertainty is not found just in the judgment, but also in the identification. Hence, there is a necessity for different kind of fuzzy sets which could support the latter uncertainty.
State of the art
Intuitionistic fuzzy set [20–22] is an extension of Zadeh’s fuzzy set. Intuitionistic fuzzy sets have the better ability of narrating and describing ambiguities of the objective world than the traditional fuzzy sets as it considers the positive, negative and hesitancy degrees of an object simultaneously. Intuitionistic fuzzy sets have been efficiently applied to solve many of the decision problems. In recent years, IF set theory has been effectively applied in the field of pattern recognition, decision analysis, medical image processing, etc. In spite of the fact that rough sets and IF sets both capture specific aspects of the same idea-imprecision, the combination of IF set theory and rough set theory are rarely discussed by the researchers. Jena and Ghosh [55] demonstrated that lower and upper approximations concept of IF rough sets are again IF sets. In the last few years, some of the IF rough set models have been proposed by the researchers in [23–25] and [44–46]. Coker [43] established relationship between rough set and IF set and revealed the fact that fuzzy rough set is admittedly an intuitionistic L-fuzzy set. Bing Huang et al. [26] presented dominance intuitionistic fuzzy rough set and showed its various applications. Moreover, some research articles have presented intuitionistic fuzzy rough set based feature selection or attribute reduction approaches [57–64]. However, none of the proposed feature selection techniques based on intuitionistic fuzzy set theory considered individual objects of information system and none of them are implemented for real-world datasets.
In the current work, we present a novel approach for the feature selection based on intuitionistic fuzzy rough set model by considering individual objects details in the information system. We define lower and upper approximations by combining intuitionistic fuzzy set and rough set and propose a novel intuitionistic fuzzy rough set framework. Furthermore, we define a dependency function based on this framework to calculate degree of dependency between decision attributes and conditional attributes. Moreover, a suitable algorithm is given for the wide applicability of our proposed concept to calculate the reduct set. Finally, this algorithm is applied to the benchmark datasets and a comparison has been presented with already existing fuzzy rough set based approach.
Preliminaries
Rough set theory
Rough set theory (RST) [13–15] can be used to extract knowledge from a domain in a concise way while retaining the information content. In RST, discernibility of two objects plays crucial role for feature selection. Suppose (U, A) be an information system, where U is a non-empty collection of finite objects and A is a non-empty collection of finite attributes such that a : U → V
a
for every a ∈ A. V
a
is the set of values that attribute a may take. For any P ⊆ A there is an associated equivalence relation R
P
on U defined as:
If (x, y) ∈ R
P
, then x and y are said to be indiscernible by attributes from P. We denote equivalence classes generated by equivalence relation R
P
as [x]
P
. Now, lower and upper approximations of X ⊆ U are defined as below:
The ordered pair 〈R P ↓ X, R P ↑ X 〉 is known as rough set.
Since most datasets contain real-valued attributes. Hence, discretization methods are applied in order to tackle real-valued information system before attribute selection using rough set based concept, and this may lead to loss of some information. This is main drawback of RST and can be overcome by fuzzy rough set theory (FRST), which proposes an alternate method by calculating the similarity between the values using a fuzzy relation that assigns to each distinct pair of objects with their corresponding degree of similarity. Given a fuzzy set X ⊆ U and a fuzzy tolerance relation R, the lower and upper approximations of X can be calculated in several ways. From [16, 39], a general definition can be given as follows:
Here, i and t represent a fuzzy implicator and a fuzzy norm respectively.
Let U (≠ φ) be an universe of discourse of objects. An intuitionistic fuzzy set B in U is collection of objects represented in the form B ={ 〈 x, l B (x) , m B (x) 〉 |x ∈ U }, where l B : U → [0, 1] and m B : U → [0, 1] are called degree of membership and degree of non-membership of the element x respectively, satisfying 0 ≤ l B (x) + m B (x) ≤1, ∀ x ∈ U . π B (x) =1 - l B (x) - m B (x) represents the degree of hesitancy of x to B. It is obvious that 0 ≤ π B (x) ≤1, ∀ x ∈ U.
Any fuzzy set B ={ 〈 x, l B (x) 〉 |x ∈ U } can be recognized as a particular case of intuitionistic fuzzy set in the form {〈 x, l B (x) , 1 - l B (x) 〉 |x ∈ U }. Therefore an intuitionistic fuzzy set is considered as an extension of fuzzy set.
The cardinality of an intuitionistic fuzzy set B is defined by [56]:
Intuitionistic fuzzy information system
An intuitionistic fuzzy information system can be defined as a quadruple IFIS = (U, J ∪ K, S, T), where U (≠ φ) is collection of finite number of objects, called universe of discourse, J (≠ φ) and K are finite sets of conditional and decision features such that J ∩ K = φ, S is the collection of all intuitionistic fuzzy values such that S = S1 ∪ S2, where S1 and S2 are domains of conditional and decision features and T is called information function which is defined as T : U × J ∪ K → S such that T (x, j) ∈ S j , ∀ j ∈ J, S j ⊆ S1 and T (x, d) ∈ S2 for K ={ d }, where T (x, j) and T (x, d) are intuitionistic fuzzy values.
Intuitionistic fuzzy rough feature selection (IFRFS)
In 1998, Chakrabarty et al. [23] proposed a concept to design an intuitionistic fuzzy rough set (IFRS) (L, M) of a rough set (A, B), where L and M are both intuitionistic fuzzy sets in U (non-empty set of objects) such that L ⊆ M, i . e . μ L ≤ μ M and υL ≥ υ M . In this case, lower approximation L and upper approximation M are both intuitionistic fuzzy sets. In 2001, Samanta and Mondal [46] proposed their method to define IFRS, where they defined a couple (E, F) as intuitionistic fuzzy rough set such that E and F are both fuzzy rough sets (as proposed by Nanda and Majumdar [44]) and E ⊆ Complement (F). From [44], it is obvious that IFRS is a generalization of an intuitionistic fuzzy set, in which membership and non-membership functions are fuzzy rough sets. In 2002, Rizvi et al. [45] reported their proposal as rough intuitionistic fuzzy set, which also contains hesitation margin on lower and upper approximations.
In 2003, Cornelis et al. [24] defined the lower and upper approximations of X ⊆ U (Universe of discourse) as follows:
However, all above proposed definitions do not consider memberships and non-memberships of individual objects to obtain the approximations. From literature [16, 35], we can define intuitionistic fuzzy lower and upper approximations by considering individual objects as follows:
A relation is said to be an intuitionistic fuzzy tolerance relation if it is reflexive and symmetric [54]. Now, we define an intuitionistic fuzzy tolerance relation as follows:
Let
Then,
Where, μ R a (x, y) and ν R a (x, y) are membership and non-membership grades of intuitionistic fuzzy tolerance relation between x and y. μ a max , μ a min and ν a max , ν a min represent maximum and minimum membership and non-membership grades for attribute a.
If R
P
[24, 39] is the intuitionistic fuzzy tolerance relation induced by the subset of feature P, then,
Let IFIS be an intuitionistic fuzzy information system as defined in section 3.4. So, we can define lower and upper approximations of X ⊆ U over a set of attributes P ⊆ J by:
Taking intuitionistic fuzzy triangular norm T
w
and intuitionistic fuzzy implicator I
w
as follows [24]:
Where, x =〈 x1, x2 〉 and y =〈 y1, y2 〉 are two intuitionistic fuzzy values.
Now, the lower approximation of X over a set of features P can be redefined as:
Now, the intuitionistic fuzzy positive region can be defined by:
Any object does not belong to the positive region, only if the equivalence class, it belongs to, is not an element of the positive region.
Therefore, the degree of dependency can be defined by [63]:
Now, we can calculate the reduct set by using concepts from [35].
Algorithm for reduct computation
Now, we present an algorithm to calculate the reduct of a high-dimensional information system based on our above proposed technique.
Intuitionistic FuzzyRoughQuick Reduct (C,D)
Input: C, Collection of all conditional features;
D, Collection of all decision features
Output: L,the feature subset
1. L ← { },
2. do
3. K ← L
4.
5. ∀x ∈ (C - L)
6. if
7. K ← L ∪ { x}
8.
9. L ← K
10. until
11. return L
Application example
In the current study, the performance evaluation of the proposed intuitionistic fuzzy-rough feature selection is widely studied and compared with existing fuzzy-rough feature selection. All the algorithms are implemented in WEKA [49]. Fuzzification of the conditional features is performed using a simple algorithm, which generates membership function for every conditional feature. Moreover, Fuzzy information system is converted into intuitionistic fuzzy information system by using Jurio et al. [27] concept and hesitancy is selected as the minimum value apart from zero in the corresponding fuzzy information table. Hill climbing is used as the search method.
We use following experimental setup in order to perform our experimental results:
Dataset
We select eleven benchmark datasets from the University of California, Irvine, Machine Learning Repository [28] and another Mass Spectrometry dataset from Lu et al. [50] to represent the performance of our proposed approach. The details of these datasets are mentioned in Table 1. The dimension of the datasets indicates that these are small to medium size datasets as instances and attributes are ranging from 214 to 6118 and 6 to 51 respectively.
Dataset characteristics and Reduct size
Dataset characteristics and Reduct size
Seven different classifiers namely: Naive Bayes (NB), Multilayer Perceptron (MLP) [53], Rotation Forest (ROF) [52], Support Vector Machines with sequential minimization optimization (SMO) [51], Nearest Neighbor method (IBK), Random Forest (RF) [47] and PART [48] from different families of machine learning algorithms available in WEKA are employed to demonstrate the average percentage classification accuracies on reduced data sets. Furthermore, we perform a comparative study of intuitionistic fuzzy-rough feature selection with the previously existing fuzzy-rough feature selection based on the change in overall accuracies of different classifiers along with standard deviation for reduced datasets obtained by using both the techniques.
Dataset split
We apply 10-fold cross validation on the twelve benchmark datasets during the process of classification. Dataset is randomly divided into ten parts, and nine of them are used for training purpose and rest one as testing set. After completion of ten rounds, average value is calculated as the final performance measure.
Bioinformatics dataset
In this section, we have selected the protein data set of Lu et al. [50] for our experiments. This data set was generated out of the forty most abundant proteins from the shotgun sequencing of the yeast proteome and it contains about 3309 unobserved peptides and 714 observed peptides. The ratio of positive (observed) to negative (unobserved) class is 1:4.6. So, the data set is an imbalance data set where the positive class has become the minority class as the number of the observed peptide is less than that of the number of the unobserved peptide. The data set can be downloaded from the web page - http://www.nature.com/nbt/journal/v25/n1/suppinfo/nbt1270_S1.html.
Performance evaluation metrics
The prediction performance of the six machine learning algorithms are evaluated relatively using threshold-dependent and threshold-independent parameters. The values of these parameters are calculated from the values of the confusion matrix, namely: true positives (TP) that is the number of correctly predicted observed peptides, true negatives (TN) that is the number of correctly predicted unobserved peptides, false negatives (FN) that is the number of incorrectly predicted observed peptides and false positives (FP) that is the number of incorrectly predicted unobserved peptides.
It is broadly used as performance parameter for binary classifications. An MCC value of 1 is defined as the best for a predictor.
In this study, entire experiment is performed using open source Java based machine learning platform WEKA [49].
Table 1 represents the dimension of the datasets and the size of the reduct produced by fuzzy rough feature selection (FRFS) as well as IFRFS. It can be observed that our proposed method generally provides smaller subsets than already existing FRFS approach. IFRFS generally provides highly reduced datasets compare to FRFS in case of high dimensional datasets. Many researchers have experimentally evaluated FRFS with other leading feature selection approaches and have revealed to outperform these in form of better classification performance. So, we have compared our proposed method to FRFS approach only. Tables 2 and 3 show average classification accuracy with standard deviation in terms of percentage, which was obtained by using 10-fold cross validation for reduced datasets by FRFS as well as IFRFS methods. It can be observed that IFRFS has either improved or remained the same to overall classification accuracies for most of the datasets with more reduced dimension. For some of the datasets, such as Ionosphere and Cardiotography, IFRFS provides less reduced datasets than FRFS but classification accuracy is found to be high. Hence, IFRFS gives more accurate reduct [35].
Comparison of classification accuracies of reduced dataset by FRFS
Comparison of classification accuracies of reduced dataset by FRFS
Comparison of classification accuracies of reduced dataset by IFRFS
In section 6.4, we have conducted experiments with six different machine learning algorithms, namely: Naive Bayes (NB), Multilayer Perceptron (MLP), Nearest Neighbor method (IBK), Rotation Forest (ROF), Random Forest (RF), PART. The values of different performance metrics for the six classifiers trained on the imbalanced training data set are recorded in the Tables 4 and 5 for reduced datasets by using FRFS as well as IFRFS.
Performance metrics for different classifiers using reduced dataset by FRFS
Performance metrics for different classifiers using reduced dataset by IFRFS
By observing the performance evaluation metrics, it is obvious that the values of different performance parameters are similar or sometimes better also for reduced dataset by using IFRFS than FRFS. Since, IFRFS provides highly reduced dataset compared to FRFS, hence, IFRFS enhances interpretability also.
By observing the performance evaluation metrics, the sensitivity, specificity, accuracy, auc and mcc values are either better or similar for all the six classifiers when these algorithms were trained on the reduced balanced training set as produced by IFRFS when compared to FRFS. This indicates that the average accuracy of the predicting negative class is predominant over the accuracy for predicting the positive class by using IFRFS. Based on the values of the performance evaluation parameters, it was observed that RF has performed much better than the other five machine learning algorithms.
A convenient way to observe the overall performance of different classifiers at different decision threshold is the Receiver Operating Characteristic (ROC) curve, which gives a visual representation of the classifier performance. The ROC curves by using different classifiers for reduced datasets by FRFS and IFRFS are given in Figs. 1 and 2 respectively. It can be seen that the performance of different classifiers are almost invariant or better in case of reduced dataset obtained by using IFRFS method than for reduced dataset produced by FRFS.
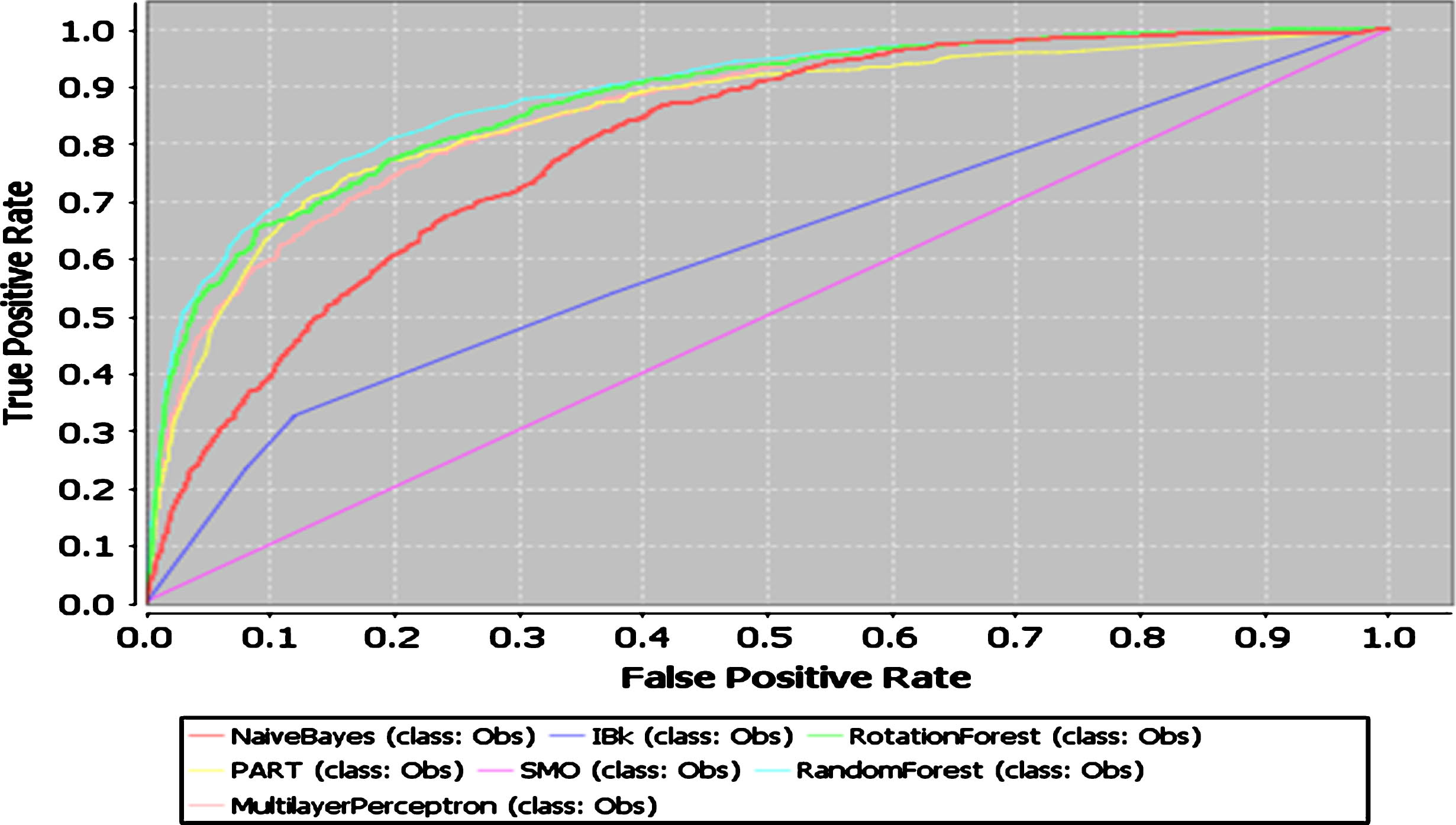
AUC of seven machine learning algorithms for Reduced Dataset by FRFS.
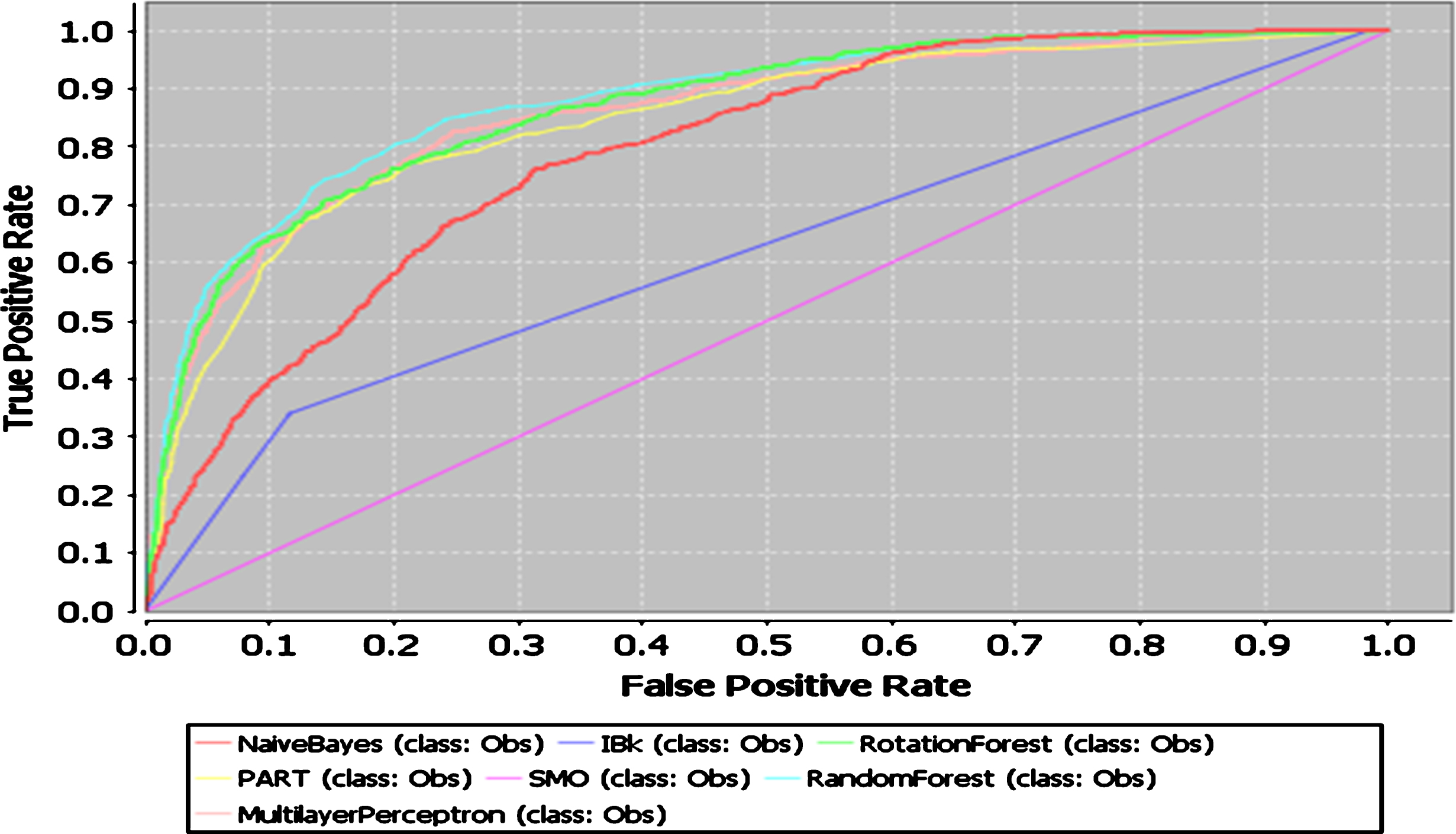
AUC of seven machine learning algorithms for Reduced Dataset by IFRFS.
In this paper, an intuitionistic fuzzy rough set assisted attribute selection technique is proposed, which can be applied on high-dimensional data sets in order to get more reduced data sets with higher classification accuracy. A novel pair of lower and upper approximations has been proposed by combining intuitionistic fuzzy set and rough set. Furthermore, a novel feature selection approach has been developed by using lower approximation expression. Moreover, we have given an appropriate algorithm based on our proposed concept. Finally, our concept is applied on twelve benchmark datasets and it is observed that our proposed method provided more reduced datasets andbetter classification accuracies than by already existing FRFS technique. In this work, the hesitancy is calculated from the information available in the dataset itself.
In the future, we can propose more accurate conversion of fuzzy information system into intuitionistic fuzzy information system by defining the hesitancy available in data. Moreover, we can define some more accurate intuitionistic fuzzy rough set models like type-2 intuitionistic fuzzy rough set model and probabilistic variable precision intuitionistic fuzzy rough set model which can tackle uncertainty in much better way.