
Abstract
Human communication has been studied from different approaches and resulting in contributions to several disciplines. From the computer sciences point of view, the findings made in the area have inspired the development of Natural User Interfaces (NUI), interaction mechanisms aimed at replicating the way in which people communicate, so the information exchange with computational systems happens in similar fashion. Gestural interfaces are a specific type of NUI focused on analyzing the relationship between body motion and semantic meanings. Although, from a technical perspective, proposals found in the literature had proven high efficiency and accuracy on gestural recognition, several authors had reported lack of naturalness in the interaction with gesture-based applications, leading to the conclusion that NUIs are not usually as natural as they claim to be. Moreover, gestures are culture and language specific, which makes them ambiguous, incompletely specified, and difficult to match with semantic meaning when the context is unknown. In this paper, we propose a methodology for enabling the development of gesture-based applications, considering that accuracy and efficiency in recognition tasks must not be affected, and prioritizing the flexibility for allowing the use of gestures that are suitable for different user contexts through the exploration of user-defined gesture sets and Machine Learning techniques, and using a one-shot learning approach.
Keywords
Introduction
Human communication has been studied from different approaches and resulting in contributions to several disciplines. From the computer sciences point of view, the findings made in the area have inspired the development of interaction mechanisms aimed at replicating the way in which people communicate, so the information exchange with computational systems happens in similar fashion. Thus, as efforts in the Human-Computer Interaction (HCI) field, works have been addressed deriving on the coining of the term Natural User Interfaces (NUI) [1], and enclosing projects related to the use of touch screens, interactive surfaces, tangible interfaces, vocal interaction, and gestural interaction among others.
Despite the fact multiple investigations mention that approximately 65 percent of human communication is carried out through nonverbal mechanisms [2], it is possible to observe in the literature that most of the research is focused on analyzing speech (either vocal or written), and that emphasis on gesture recognition (considering facial expressions and body motion) has been given in the last two decades as consequence of the development of processing techniques like Machine Learning (ML) algorithms as well as signal and image digital processing techniques, and of hardware devices such as depth cameras, stereoscopic cameras, and wearable devices.
Analysis and interpretation of gestures, is on itself a challenging complex problem which is traditionally faced by following a three-step approach: data gathering from a source; identification of regions of interest, this is, depending on the gesture to be recognized, it is necessary to identify candidate gestures in terms of time and space; and recognition of the gesture, usually achieved through the use of ML techniques, and resulting on gesture association to specific meanings. It is important to point out that for this process to properly work, previous training is required, and therefore, gestures that can be recognized are limited and predefined by user experience designers.
Although from a technical perspective, proposals found in the literature had proven a high efficiency and accuracy on gestural recognition [3–5], works such as [6–8], reported lack of naturalness in the interaction with gesture-based applications, leading to the conclusion that NUIs are not usually as natural as they claim to be. Moreover, gestures are culture and language specific, which makes them ambiguous, incompletely specified, and difficult to match with semantic meaning when the context is unknown [9].
The problem that we presented in previous lines, leads us to define the following research question: How can gesture-based interaction be achieved, in a way that results natural to users?
With the purpose of answering the question posed, in this work we introduce a methodology for enabling the development of gesture-based applications, considering that accuracy and efficiency in recognition tasks must not be affected, and prioritizing the flexibility for allowing the use of gestures that are suitable for different user contexts.
The remainder of the paper is divided into sections. In section two we report a literature review for presenting related works and for settling the bases for this research. Section three contains the description of the proposed methodology, detailing each of its phases. In section four, we show preliminary studies related to the definition of the methodology. Then, in section five, we discuss and interpret the results of such preliminary studies, along with the findings and insights of the experiments. Finally, we provide conclusions and describe future work in section six.
State of the art
When carrying out any research project, an early literature review, allows to define the foundations of the research, avoids focusing on non-relevant topics, and promotes the definition of open research questions. In this section, we report a summary of a systematic review performed following the eight-steps methodology proposed in [10]. As part of the protocol for the literature review, we determined to consider only works with less than 10 years, written in English and published in journals, conferences organized either by IEEE or ACM or as book chapters.
The search string included the following key terms and combinations of them: “gestural interaction”, “gesture-based application”, “Natural User Interface”, “one-shot learning”, “gesture recognition”, “user-defined gestures”, “gesture identification”, “human action recognition”, “human activity recognition”, and “motion recognition”. Using such criteria, and considering the scope of this research work, we selected a total of 60 works. In the following subsections, we briefly describe our findings from such papers, categorizing the information according to its relevance for our proposed methodology.
Works on gesture recognition
Most of the reviewed works include as part of their objectives the development of gesture-based applications. We analyzed those proposals in terms of the three stages that are commonly used to achieve gestural interaction, getting information about the devices that are used as source (see Fig. 1), the body parts for which gestures are recognized (see Fig. 2), and the classification techniques that were employed on them (see Fig. 3).
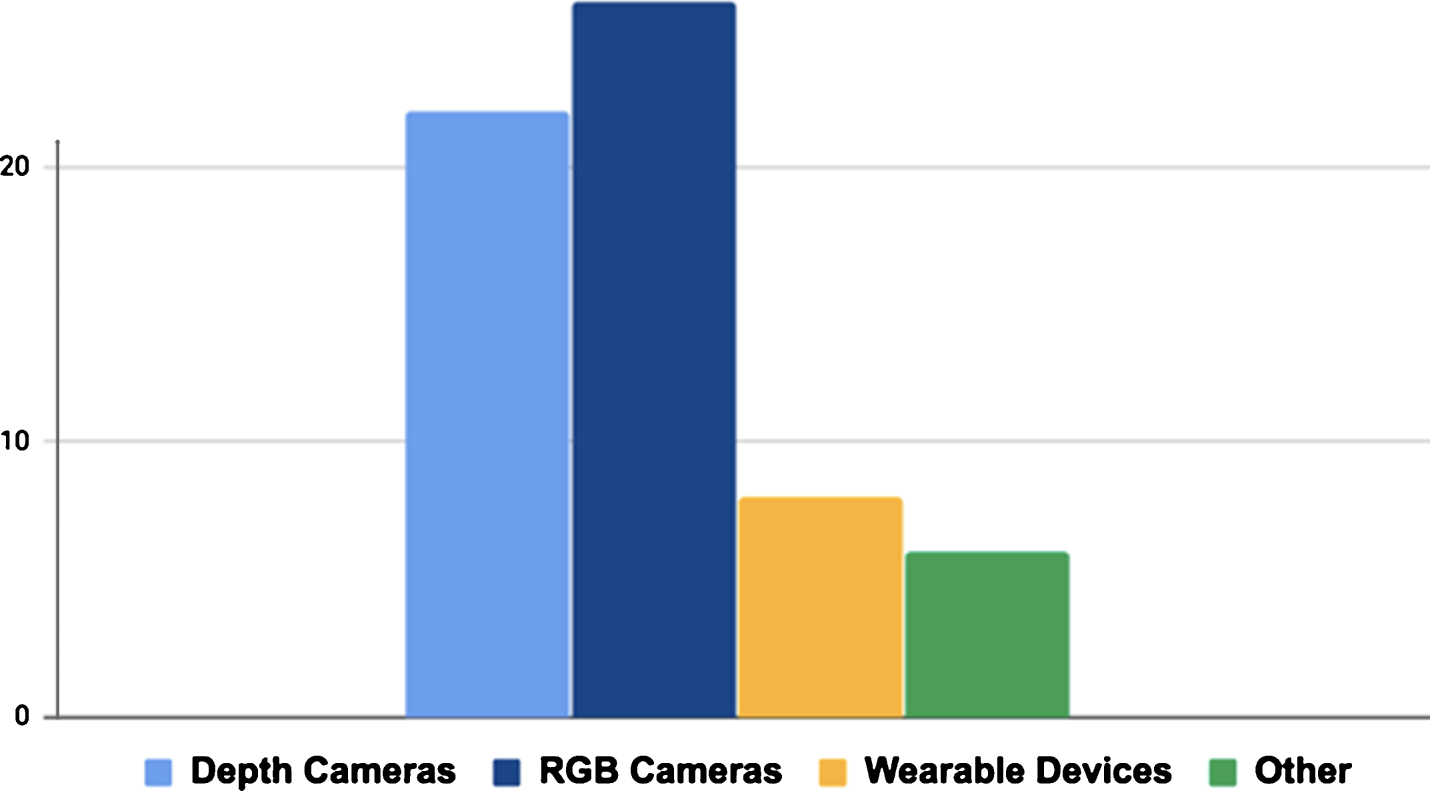
Data acquisition devices used in the literature.
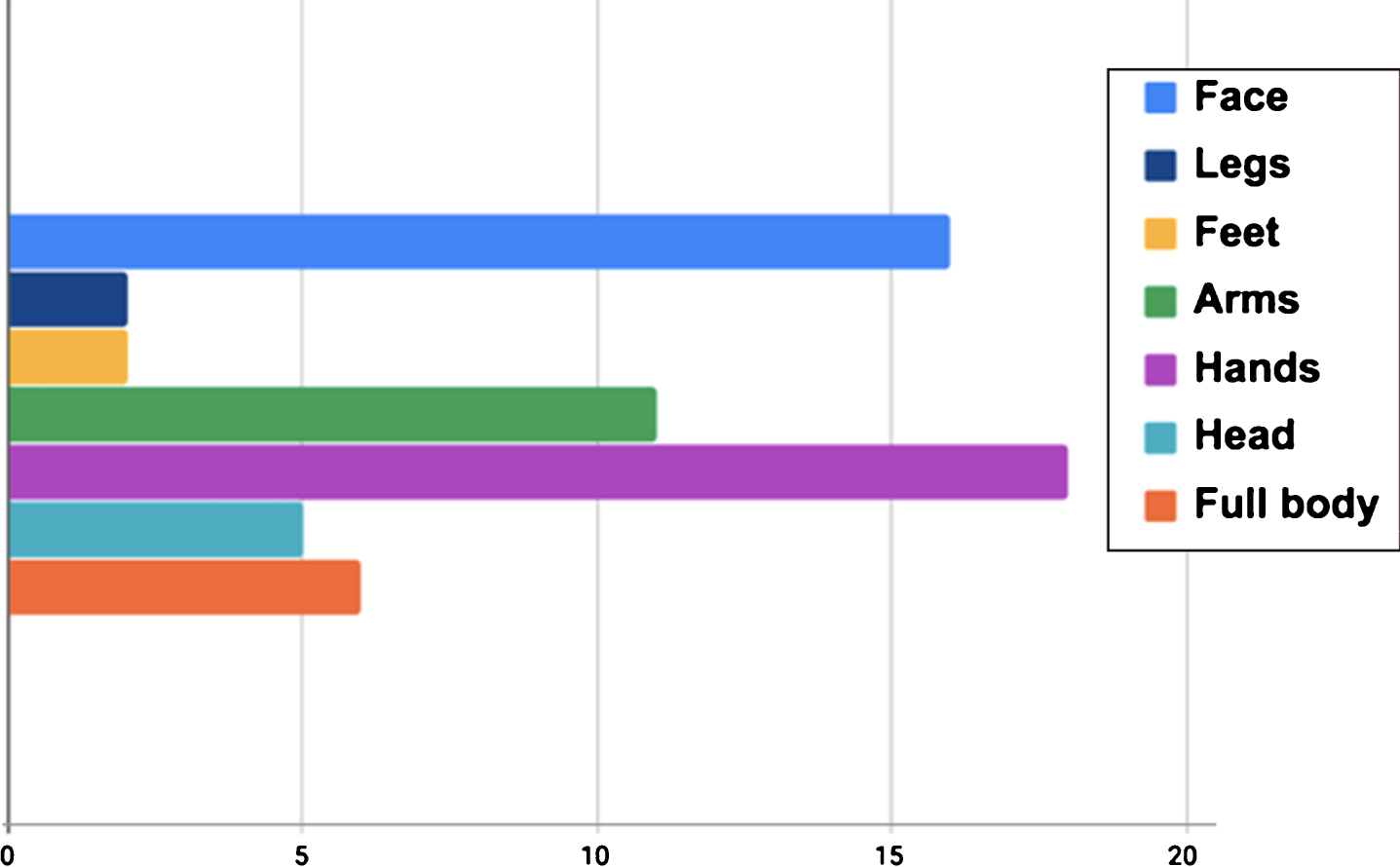
Body parts for which gesture recognition is done in the reviewed literature.
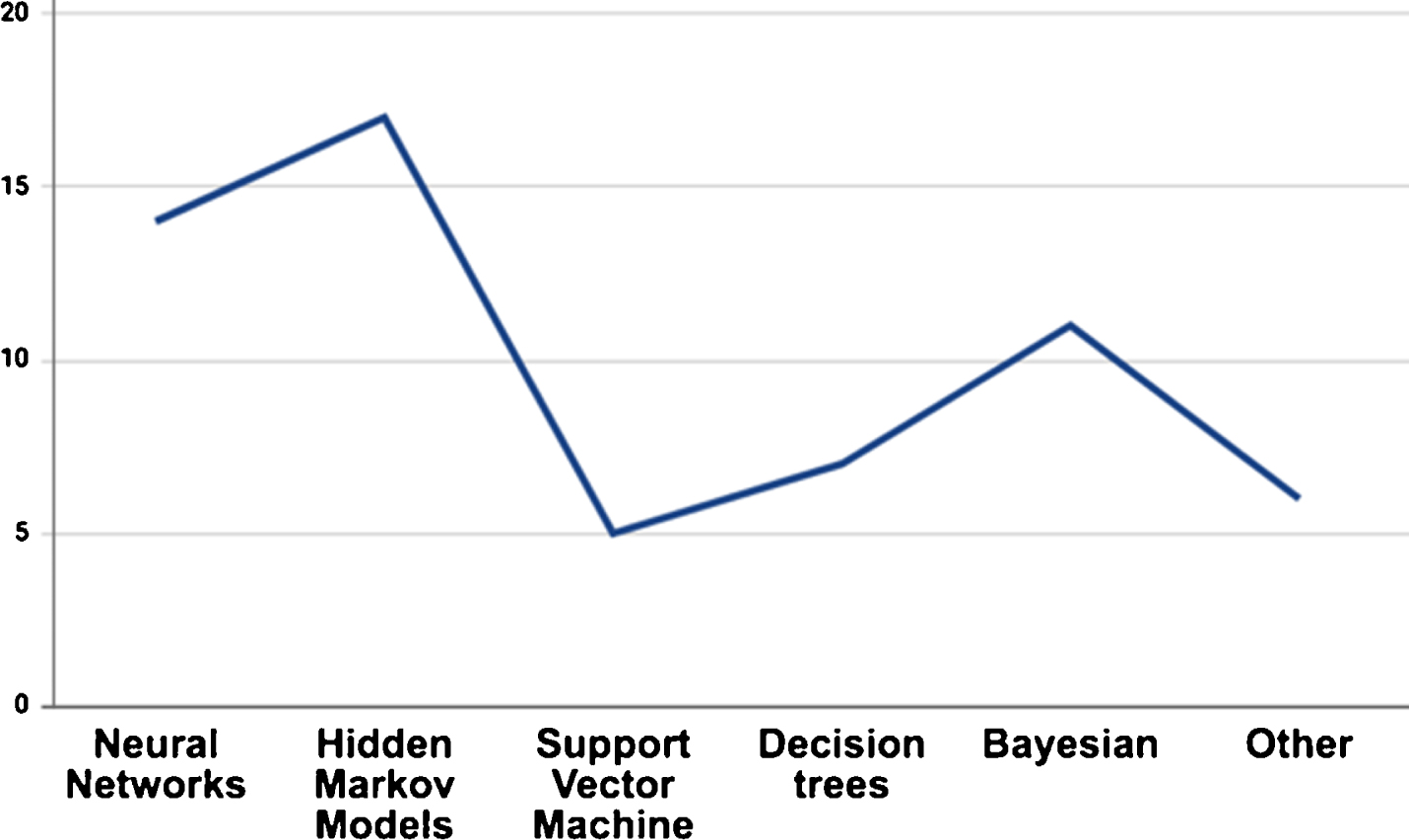
Classification techniques employed for gesture recognition in the reviewed literature.
We observed that most of the works (around 77%), relied on vision-based devices for gathering information. The rationale for using such type of mechanisms is on that devices like cameras and leap motion sensors are less invasive than wearable devices. Vision-based approaches are affected by occlusion issues mainly, but this problem has been commonly faced using more devices for getting the information without significant losses [11, 12].
Meanwhile, 13% of the analyzed works propose the use of wearable devices such as interactive gloves, augmented reality glasses, bracelets for getting arm motion, and full-body suits equipped with sensors. If well, wearable devices are attached to the users’ bodies and allow a better tracking of motion delivering high accuracy and efficiency on motion detection, the real challenge when developing or using them to enable gestural interaction, is on providing comfort and to avoid interference on the task due to the addition of equipment that users must wear at every time to interact with the application [6].
The remaining proposals explore the use of other means such as Wi-Fi and radar signals achieving promising results, close to the vision-based alternatives in terms of accuracy and efficiency, but with the disadvantage of higher cost and lack of availability of devices for massive use [13, 14].
Regarding the body parts for which gesture recognition is done within the analyzed works, at first, we noticed that 27% of the works are focused on the study of gestures of the hands using leap motion sensors, depth cameras, wearable devices, and RGB cameras. This finding is consistent to what has been reported in surveys on the field of study [15] and may be related to two main motives: users commonly interact with electronic devices using only their hands, and several works study gestural interaction for developing applications for the translation of sign language [16, 17].
On the other hand, only 7% of the works are aimed at describing interaction by means of lower limbs, using wearable devices and depth cameras. Lower limbs are said to be less expressive, but if we consider the scenario of navigating on virtual environments, having users with restricted motion on upper limbs, or contexts on which upper limbs are being already used for another purpose than interacting with applications, vocabularies including lower limbs gestures become relevant.
It was interesting to see that only 10% of the analyzed works consider full-body interaction and that most of them (83%) use depth cameras as data acquisition devices. In addition to this, a deeper literature review revealed that there was a significant increase of patents and papers on full-body motion detection as of 2007, coinciding with the introduction of depth cameras and infrared sensors for domestic purposes, and with the investment on NUIs of companies such as Microsoft, Sony, and Google.
Finally, in order to have a better idea of the classification tools that are currently being applied for gesture recognition and promoting their implementation as part of the proposed methodology, it is possible to notice that the most commonly used techniques, are hidden Markov models, and Neural Networks, while Support Vector Machines and Decision trees had not been widely explored.
As it was described before, a current challenge in gesture recognition is on that gestures are specific to cultures and languages. Hence, allowing interaction using such modality requires users to be trained or applications to be tailored for a determined group of users within similar contexts. According to the literature, training users may not be the best alternative, since users must learn lots of gestures in order to interact with common applications [18] and considering that usability and User Experience (UX) principles indicate that user interfaces must be self-explanatory, easy to use, easy to remember, and intuitive to users [19].
Typically, gesture elicitation studies, based on the guessability study procedure [20], are driven with the purpose of identifying gestures that match with specific tasks according to the mental model of a group of users. The idea that is followed with this approach is that after obtaining gestures sets from users’ income and using such gestures as commands within an application, usability and UX will be positively impacted and had become a standard approach in HCI.
Nevertheless, even though proposals on gesture elicitation report good results in terms of user preference and user motivation towards gesture-based interaction [21], it is an important insight that most of the studies on the field are non-statistically representative, making them limited and once again, specific to determined groups of users within similar contexts, leading to think that if an application is meant to be available for multiple different populations, the same number of gesture elicitation studies must be conducted, reducing the viability of projects.
Another relevant challenge that has been adverted when carrying out gesture elicitation experiments, is on isolating users from the influence of digital products and technology. It is common to see on these studies that the presence of technology in multiple areas of daily life, modifies the way in which humans communicate as users frequently try to emulate digital metaphors when asked to perform gestures for specific commands [22].
In this sense, researchers in the field have proposed the use of different strategies to be applied to elicitation experiments. Such is the case of [23] in which Morris et al. Propose kinesthetically priming participants via physical activity and ask users to produce several gestures per instruction as a mean to reduce legacy bias. However, other works like [22] refute that idea, showing that replication of the proposed strategies is not always successful and introducing new alternatives.
One-shot learning approach
Since the decade of 1960, researchers on human cognition and human interaction have used the term one-shot learning as a reference of the acquisition of knowledge from being exposed to information only once (or a few times) [24]. During 1980, researchers started to propose methods for reproducing such approach as an improvement and desirable feature of ML algorithms [25]. Moreover, in 1985, Vo [26] proposed the use of one-shot learning techniques in order to allow adaptation of recognition systems to new users.
Nowadays, it is common to find in the literature different proposals making use of a one-shot learning approach for Natural Language Processing (NLP) [27], but still exhaustive training reports better results on accuracy and response time.
Based on the assumption that body language is part of human communication and considering that tasks that are comprehend in NLP are equivalent to those that are carried out for gesture, along with the need of allowing multiple users to interact with systems using gestures, the cultural differences that may exist among them, and that it is not viable to ask users to constantly repeat a gesture enough times like for training a typical classifier, it is possible to understand why one-shot learning methods for gesture interaction have been proposed and explored lately [28–30].
The current challenge on applying one-shot learning specifically to gesture-based applications is on achieving high-level accuracy equivalent to other alternatives, and on decreasing response time in order to improve the perception that users have towards them on usability and UX tests.
The study of gestures and the possibility of recognizing them as a means to enable natural interaction is a challenging problem which requires intervention from different areas of computer and social sciences. In the following section, we introduce a methodology for promoting the development of gesture-based applications, considering the creation of user-defined gesture sets and making use of a one-shot learning approach while contemplating that accuracy and efficiency must not be impacted and prioritizing good usability and UX by allowing the use of gestures for different user contexts.
Methodology description
As previously stated, gesture recognition is a task that is typically carried out following three-steps methods: data gathering, identification, and recognition. This approach works properly under controlled circumstances, on which only specific gestures from determined body parts are expected, but if the definition of new gestures is allowed, additional work needs to be done. Hence, in this section, we propose a seven-stages methodology for user-defined gestures recognition enabling the processing of user-defined gestures.
The proposed methodology depicted as a block diagram in Fig. 4, is detailed in the subsequent paragraphs.
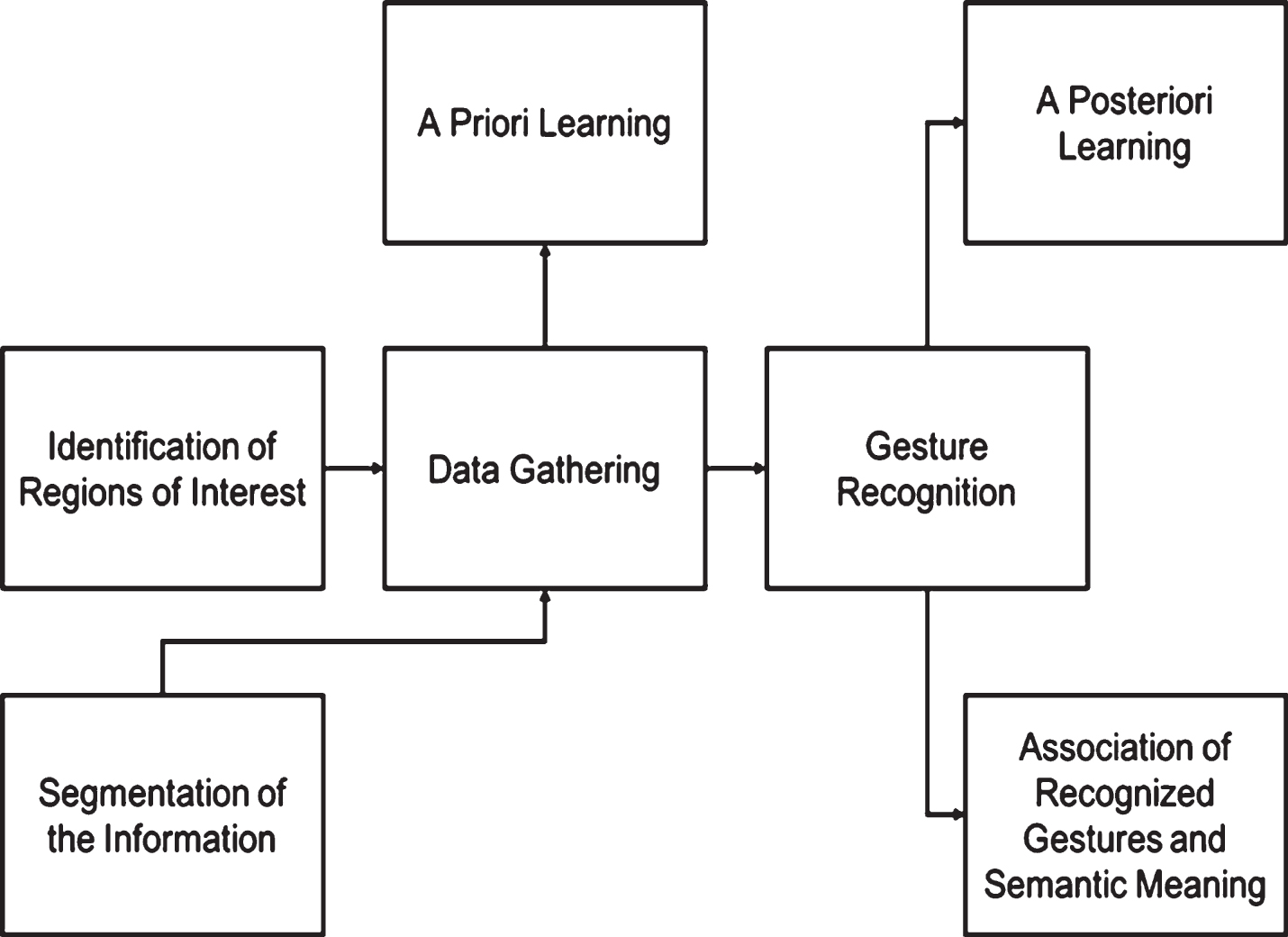
The seven-stages methodology proposed for gesture-based interaction.
Human movements are physically limited only by body joints and their degrees of freedom. The number of possible poses that users may adopt, if well is finite, is large enough to avoid thinking on training a classifier for recognizing them all. Moreover, considering that gestures may be static or dynamic, and adding characteristics of the movements such as direction and speed, the number of records to be fed to the classifier increases dramatically making it unviable to be implemented.
However, during our literature review, we noticed that a relevant insight on elicitation studies is on that users declared some gestures to feel more natural and preferable than others [31], leading to think that from the complete set of possible gestures that people can do, users would prefer to use only a limited number of them to interact with systems.
Commonly, elicitation studies are focused on finding gestures with which users like to interact with specific applications. This is correct for determined tailored developments, but when thinking of something generic, elicitation studies may also give important feedback on how users behave during the interaction.
We propose the use of such types of studies, for obtaining information about gestures without associating them to specific meanings. This is, on the experiments the focus must be on the movements which users perform when asked to achieve a goal, then characterization of the movements according to anatomic taxonomies using models such as the proposal of Generic Virtual User Model (GVUM) [32] should be done, common gestures according to co-agreement rates need to be selected, and finally it is necessary to label the gestures and train a classifier in a typical way with that information.
From this stage, the result is a trained classifier which for a given gesture, returns either a label if the gesture is known, or a null value if it is not. Besides, the analysis allows proposing candidate meanings in terms of abstract tasks. To this purpose, it is important to ensure the awareness of the correspondence between the tasks which users are asked to perform during the gesture elicitation studies, and canonical abstract tasks [33].
Data gathering
In the literature, it is possible to see several alternatives to data gathering for gesture recognition projects as described in the State of the Art section. In our proposal, we consider the use of vision-based techniques. However, its applicability to projects relying on wearable devices and on wireless signal processing is possible as well, as this methodology is not technology or platform dependent.
Data gathering within this methodology occurs in two different moments, first when carrying out the training of the classifier as described in the previous section, and then when users are interacting with the system allowing either to recognize a gesture or to update the gesture dataset with information from the user.
We specifically focus on the use of an array of depth cameras for this purpose and the goal is to generate 3D user models from the data they deliver while avoiding occlusion. Such models ease the extraction of features for the classification and for the one-shot learning processes. Succeeding in this stage is possible only after identifying regions of interest and segmenting the information in terms of space and time.
A Posteriori learning
Commonly, proposals on gesture recognition consider either having a training stage prior to interaction or being open to allow ML on-the-fly. Our proposal consists of a mixed approach on which an already trained classifier is enriched with information that users may feed.
Thus, in addition to the previously described training of a gesture classifier as result of elicitation studies, an a-posteriori learning stage is necessary. Typically, when adding information to a classifier to allow new classes on it, a lot of data is gathered and labeled, then, the classification is trained once more, and tests are driven. However, for the gesture-based interaction domain, the acquisition of the needed data implies that users may have to repeat the same gesture hundreds of times before being able to use such a gesture for interaction. This is a major problem as it would considerably impact UX and requires the investment of extraordinary time and effort.
Hence, we consider the use of a one-shot learning approach, in which users provide new gestures only once, and the system, as mentioned in the data gathering stage description, creates a 3D model of the user, and applies minor variations on the information in order to generate as many samples as needed to retrain the gesture classifier. So far, we consider varying scales and direction, but additional features may be added for achieving higher accuracy.
Identification of regions of interest
Preprocessing information is a good practice on classification projects as it aids on the reduction of computing time and prevents unnecessary effort. For gesture recognition specifically, preprocessing data in order to identify where and when gestures are present, is desirable. In terms of space, as our methodology relies on the use of depth cameras, we already get information on where users are located, and the background and other objects are easy to remove from further stages due to the use of APIs. However, if using other devices such as RGB cameras, it will be necessary to isolate users’ bodies from noise sources.
Meanwhile, in terms of time, proposals such as [34] provide metrics and allow the detection of possible gestures, resulting in slides of information annotated as candidate gestures.
Segmentation of the information
Our methodology includes a second preprocessing step fed from the identification of regions of interest that was previously described. This stage consists on taking the candidate gestures, label them, and prepare the information to either be recognized or processed for on-the-fly training.
In the literature, it is possible to find works dedicated to the research of automatic mechanisms for custom labeling gestures reporting promising results [35]. In this case, the idea is to keep using generic labels that are independent of meanings since they are going to be assigned on further stages.
The output of this stage is information annotated and ready to be either recognized or included in the classification model depending on its current existence on it.
Gesture recognition
When user interaction begins and after obtaining the segmented information from it, data is fed to the classifier to see if it is already capable of recognizing the gesture that is currently being performed by users. If gestures are not recognized a posteriori training is triggered, else, semantic meaning is to be assigned to the performed action for deciding what action to take.
The output of this stage is the label of the gesture which was either recognized or added to the classification model.
Association of recognized gestures and semantic meaning
Depending on the context of use, gestures may get different meanings. Labels allow mapping such gestures in a way they are meaningful to the context of use. Therefore, the context of use needs to be characterized as well, as it contains information that is relevant to the meaning of a specific gesture.
This last stage of the methodology is focused on associating gestures to the most probable meaning and to trigger actions on the system corresponding with that information. In this phase, it is necessary also to develop a mechanism such that users can use it to say if what the system interpreted was not correct. In this way, gesture-based applications can actually get adapted to how users interact and provide richer interaction.
Preliminary studies
As a means for assessing the first two stages of the proposed methodology, we have driven preliminary studies as described in the following subsections.
Gesture-based navigation on virtual reality environments
We designed an experiment, in which users are asked to perform a specific task on a Virtual Reality (VR) environment using gesture-based interaction following a Wizard of Oz approach [36]. For that specific domain, the minimum necessary tasks for interacting with an inter- active virtual world application, are: Zoom (in and out), fly to place, tilt view, and save location.
The setup of the experiment, as shown in Fig. 5, included two computers (PC1 and PC2), the first one for controlling a Microsoft Kinect sensor and a webcam in order to retrieve users’ movement information, and allowing to document the experiment; while the second one was connected to a projector for providing the user with feedback and simulating users’ interaction with the system.
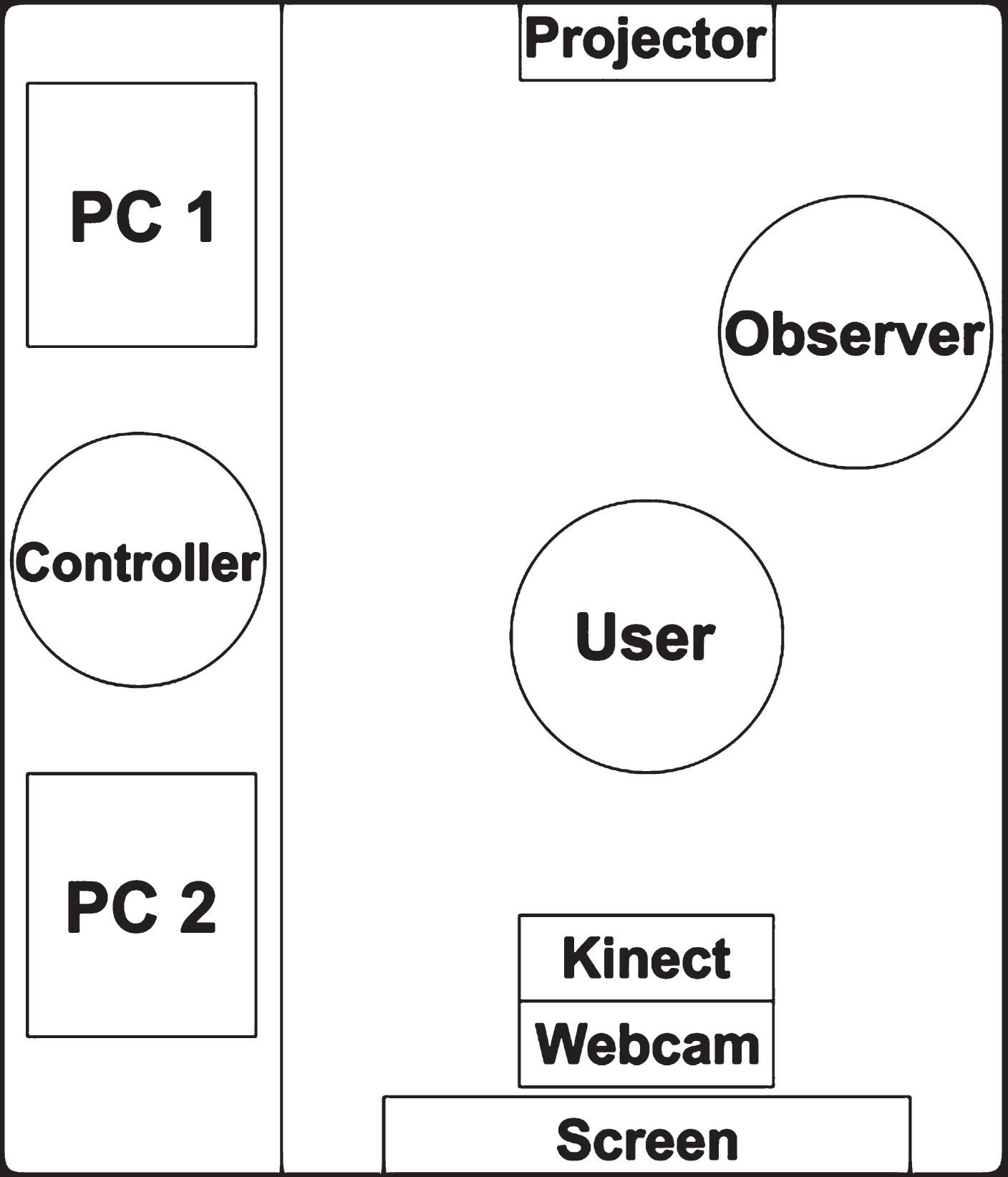
Wizard of Oz experiment setup.
The test subjects who took part in the experiment were responsible for providing gestures for a simulated platform configuration, and for interacting with the application following a set of instructions. An observer of the experiment was also designated and located next to the user in order to provide support in case any doubt arises. The experiment controller managed the devices to document the experiment and to explain how each user performed the activity.
In the experiment, eight undergraduate students participated. Each of them was asked to indicate what body gesture would he/she do to perform a series of tasks, repeating this process until users were satisfied with the gestures he or she gave. Thus, a set of 64 body gestures was obtained. Those 64 gestures were characterized, compared and grouped, resulting in a user-defined gestures set for training a classifier.
A second experiment was conducted for proposing a full-body language for enabling gesture-based interaction in different contexts, focusing on the movements of the neck tracked through the position of the head, upper limbs observed as arms and hands, and lower limbs to be analyzed considering legs, and feet.
As a total, 70 participants with limited experience on the use of software applications were recruited and separated into 5 groups with 14 users each. The first group, dedicated to neck gestures, consisted of 9 female and 5 male between 19 and 79 years old. The second group which was created for arm gestures observation consisted of 7 female and 8 male aged between 17 and 67 years. The third group, for hand gestures, was composed by an equal number of female and male users between 20 and 63 years. The fourth group, for legs gestures, involved 7 female and 7 male aged between 13 and 53 years. Finally, the fifth group in which feet gestures were observed, was composed of 7 female and 7 male between 12 and 52 years.
Once the participants were selected and the groups were defined, it was time to realize experiments for finding interaction vocabularies for each of the above-mentioned body parts. This kind of experiments is commonly carried out by implementing applications. Nonetheless, the implementation of systems based on gesture interaction represents a challenge itself, and as our objective was on identifying gestures sets, and not on assessing the interaction of a specific application, a Wizard of Oz approach was used again and using the configuration as depicted in Fig. 5.
During the experiment, users were asked to provide the gestures they would use to perform 14 commands within different applications and contexts. Such commands were attached to concrete versions of canonical tasks like such as turn on, turn off, open, close, move up, and move down. As a total, 980 records were acquired and then processed through manual labeling, manual comparison, and calculation of agreement rate using AGreement Analysis Toolkit (AGATe) 1 .
It was interesting to see that even though users were asked to use only movements from a determined part of the body and that it would be correct to use the same gestures for different commands, they mostly felt more comfortable using different gestures for each command, and particularly in the case of head and feet motion groups, they commented that the use of the single part of the body was not enough to express what they thought, extending motions to shoulders and ankles respectively. Therefore, the final gestures set contains such type of movements as well.
Finally, a total of 70 gestures was obtained (14 per group), characterized using the GVUM from [32] and manually labeled with a generic notation e.g. G001, G002, and G003. A summarized set of them is presented in Fig. 6 and Table 1. Such information is prepared to be fed to a classifier for gesture recognition. In the next section, discussion on the preliminary studies and about the methodology is presented.
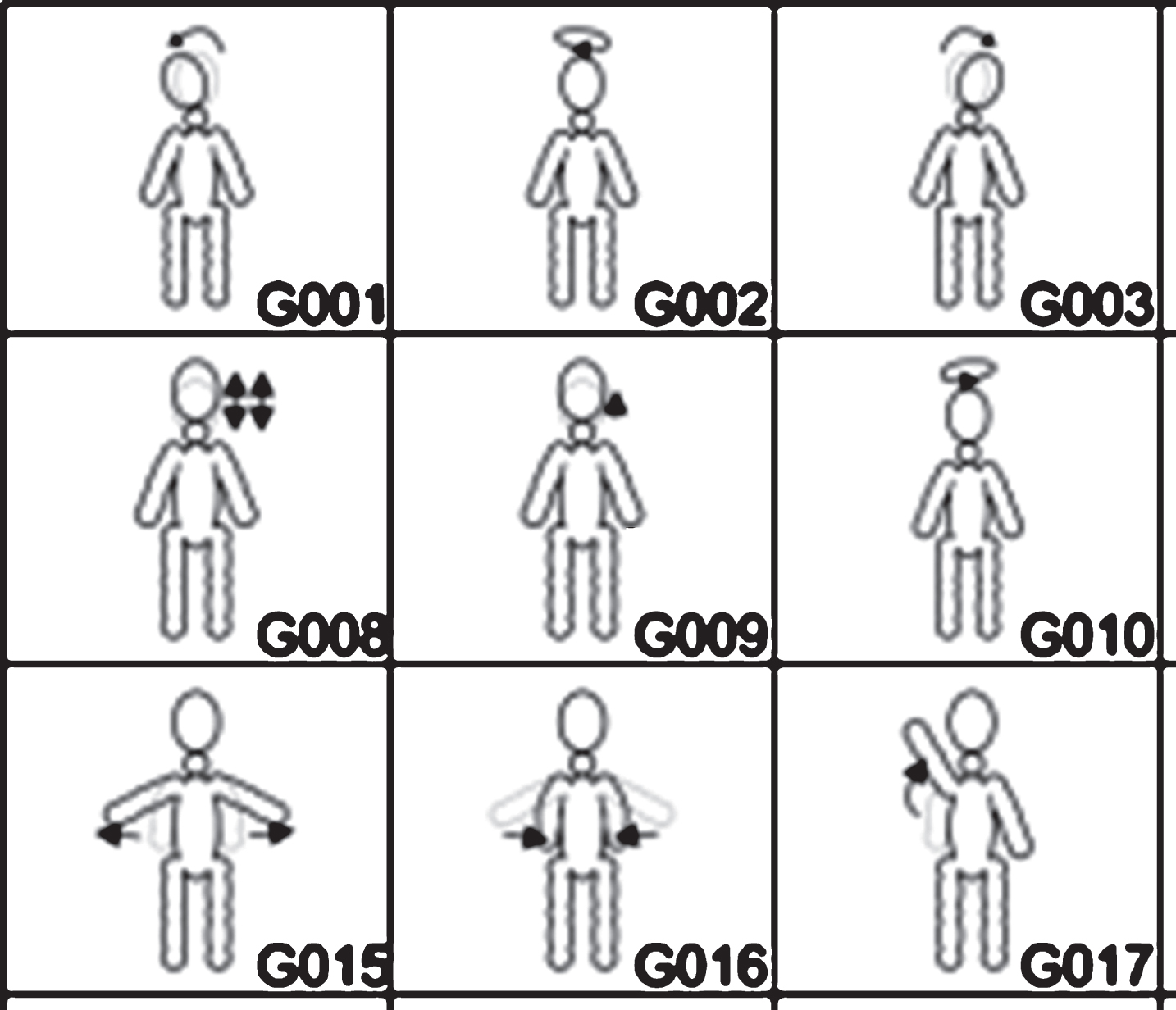
Summarized set of generic gestures obtained during elicitation experiment.
Gestures characterization from the elicitation study
Currently, two preliminary studies have been driven in order to assess our methodology. In such experiments relevant insight has been found. In the first experiment, it was interesting that no user did gestures from lower limbs even when they were asked to perform any gesture that seemed natural to them and they were aware of the use of a full-body tracking system. This is corresponding to the findings of the second experiment on that agreement scores for gestures from the head, legs and feet were not as high as they were for gestures from hands and arms. From the observation during the experiment, that disparity was caused by two reasons, the first one regarding the mental model that users have, and that it is not common to interact with applications using only head, legs, and feet movements; and the second one concerning lack of expressiveness, comfort, and degrees of freedom of each of the analyzed body parts.
During the navigation experiment as well, it was observed that tasks, such as, save place, move to marker, and add a marker, were discarded as there was a lot of confusion on how to move the body to communicate that functionality to the system. Therefore, vocal communication was the solution when users required to use those functionalities leading to think that on the mental model, there is no direct correspondence of some abstract tasks and corporal movement and that other interaction modalities may be used as a support of gesture-based applications.
Regarding the methodology assessment, it is important to consider that so far, through the preliminary studies, it is only possible to evaluate the stages of data gathering, identification of regions of interest, and segmentation of the information and that most of this evaluation has been done manually. The realization of such stages, considering that the currently obtained gestures were obtained for canonical tasks, is aligned with the requirements for the training of the gesture classifier to satisfy the a-priori training phase, while the gesture recognition and a-posteriori training parts will still need to be implemented and assessed.
In the next section, we present the conclusions to the work and future lines of research to be explored.
Conclusion and future work
In this paper, we present a methodology for enabling the development of gesture-based applications, considering that accuracy and efficiency in recognition tasks must not be affected, and prioritizing the flexibility for allowing the use of gestures that are suitable for different user contexts. The proposed methodology consists of seven stages: 1) A-priori learning: consisting on obtaining movements which users perform when asked to achieve a goal, characterize them according to anatomic taxonomies, select common gestures according to co-agreement rates, label the gestures using a generic notation, and train a classifier in a typical way with that information. 2) Data gathering: happening first when carrying out the training of the classifier, and then when users are interacting with the system allowing either to recognize a gesture or to update the gesture dataset with information from the user. 3) A-posteriori learning: Our proposal consists of a mixed approach on which an already trained classifier is enriched with information that users may feed. We consider the use of a one-shot learning approach, in which users provide new gestures only once, and the system, as mentioned in the data gathering stage description, creates a 3D model of the user, and applies minor variations on the information in order to generate as many samples as needed to retrain the gesture classifier. So far, we consider varying scales and direction, but additional features may be added for achieving higher accuracy. 4) Identification of regions of interest: In terms of space, it will be necessary to isolate users’ bodies from noise sources. Meanwhile, in terms of time, it considers the detection of gestures, resulting in slides of information annotated as candidate gestures. 5) Segmentation of the information: Consists on taking the candidate gestures, labeling them, and preparing the information to either be recognized or processed for on-the-fly training. 6) Gesture recognition: Involving the labeling of the gesture which was either recognized or added to the classification model. 7) Association of recognized gestures and semantic meanings: Focused on matching gestures to the most probable meaning and to trigger actions on the system corresponding with that information, considering feedback from the user in order to update the probability of gestures to represent specific commands.
To our knowledge, this is the first work proposing a mixed approach for allowing gesture recognition, considering the initial training of a classifier and then enriching it with on-the-fly information. Also, this is the only proposal currently considering taking only one sample and applying minor variations to it in order to satisfy a one-shot-learning approach.
Finally, after the realization of this work, it was noticed that there is still working to do towards the complete implementation of the methodology. First, it is needed to formally define the metrics and features that will be considered as part of the variations for enabling a-posteriori learning.
During the elicitation studies for obtaining generic gestures, ergonomic evaluation was omitted. This type of assessment would allow determining gestures that are more suitable to be performed by users in general contexts.
As commented in lines above, manual labeling and segmentation had only been applied, it is necessary to implement automatic methods for such purposes. It is also required to formally define a gestures taxonomy and to declare for which of the classes that form such taxonomy, this methodology is applicable. For instance, determine limitations related to gesture continuity and granularity.