
Abstract
In this paper, we present a comparative analysis of two selection policies in the General Game Playing (GGP) context: Upper Confidence Bound (UCB) and Upper Confidence Bound Tuned (UCB-Tuned). The aim of the analysis is to identify which policy has the best performance in terms of victories in the GGP domain, a measure used in most of literature with other policies. In order to carry out the comparison, two agents were programmed using the GGP-base framework and the Monte Carlo Tree Search (MCTS) method. The games Breakthrough, Knightthrough and Connect Four were used as experimental scenarios, not compared previously to the best of our knowledge. The results show that UCB-Tuned is better when less than 100 simulations are used in MCTS; however, when 1000 simulations are used, both policies have similar performance.
Introduction
One of the aims of Artificial Intelligence (AI) has been the development of intelligent agents capable of playing board game at the same level -or even better- than humans [4]. The challenge in developing playing agents drift that they must possess characteristics pertaining to human intelligence, such as deduction, reasoning, problem resolution, intelligent search, knowledge representation, planning, learning, creativity, perception and natural language processing among others [21]. AI has proposed agents capable of playing at the level of human champions in specific games, like Chinook [19] (there is a strategy that allows the player to win regardless the plays by its opponent [18]), Deep Blue for Chess [6] and Dark Knight for Banqi or Chinese Chess [13].
The field of AI that has focused its efforts in developing intelligent agents capable of playing any kind of game is General Game Playing (GGP). In GGP, agents must be able to develop their own playing strategies autonomously, without human intervention, having played the game previously and just considering the rule given at the start of the game (often using the Game Description Language) [4, 21].
Although the agents in GGP cannot be compared to specialized game agents in terms of performance, their use is higher as they can perform in different domains, even the techniques developed in GGP can be used in other areas such as business process, electronic business, military operations, among others [11, 12].
An important result in the GGP area has been the implementation of the Monte Carlo Tree Search method (MCTS) proposed by Finnsson [10] and used at the CadiaPlayer agent which have won the GGP international competition three times. MCTS method defined the state of the art of agents in GGP [11]. MCTS is guided by Monte Carlo Methods [5], using the results of previous explorations to estimate with higher precision the values of the promising results [5, 9].
Algorithms based on MCTS use a tree structure where each edge represents a possible movement and each node represents a state of the game. Each node has associated a series of statistics like the number of victories and the number of node visits. The algorithm consist of the iterative application of four steps [9]: selection, expansion, simulation and backpropagation. During the selection step, the tree is traversed from the root until a node which can be expanded is reached, using a selection criterion that determines which node should be visited in each level. Next, in the expansion step, the new node is added to the tree. Then, during the simulation step, an execution of the game is done from the state of the node added, running the moves of each player, until the game ends. Finally, in the backpropagation step the result of the previous step is propagated in each visited node.
Every time that the MCTS performs the selection step, it faces with following dilemma: which node should be visited, the one who seems to be the best at the moment or other nodes less promising that may turn out to be better in later iterations. This is known as the Exploration-Exploitation Dilemma, the Multi Armed Bandit Problem (MABP) is representative of this dilemma [15, 22]. The MABP is described as follows: given a set of K slot machines where each one has certain probability to be chosen to gain a reward, the question is: which slot machine should be activated if it is desired to obtain the greatest possible reward. Upper Confidence Bound (UCB), proposed in [3], is the most popular algorithm used in MABP, and it has been used in MCTS as selection policy with excellent results [10], UCB+MCTS is known as Upper Confidence Bounds Applied to Trees (UCT).
Due to its results in specific games UCB is the most used policy in GGP [7, 8] since it is an independent domain so no previous knowledge of the game is required. Since the conception of UCB, new policies have been developed to MABP like UCB-Tuned [3], UCB-V, PAC-UCB [2], UCB-Minimal [14], Minimax Optimal Strategy (MOSS) [1], and others [5]. So far there is no evidence of the application of said policies in GGP, this may be due to the excellent results obtained by UCB. However, these policies are also domain independent so they can be applied to GGP in order to evaluate whether they improve UCB in victories obtained.
Perick et al. [16] present a comparative study of various policies in MCTS using as study case the Tron game. The results show that UCB-Tuned is the policy with the best performance. However, if these policies are applied to GGP domain, and due to the variety of games in the literature, it is possible to obtain different results from those obtained by Perick et al. when applied to other games.
This paper shows a comparative study of the performance of the UCB and UCB-Tuned policies in GGP using the Breakthrough, Knightthrough and Connect Four games. The purpose of this comparison is to analyze the behavior of these policies and their performance in terms of victories in the GGP context. To the best of our knowledge no comparison has been done previously with these games using these policies.
In Section 2, the Monte Carlo Tree Search is described; in Section 3, the selection policies are described; in Section 4, the comparative analysis is presented; in Section 5, the results are presented. Finally, in Section 6 the conclusions are outlined.
Monte Carlo Tree Search
Monte Carlo Tree Search (MCTS) is a guided method based on Monte Carlo simulations [5], which uses the results of previous explorations for estimating the most promising moves in the game with better precision [5, 9]. In the tree structure each edge is a possible move and each node is a state of the game associated with a set of statistics values: the number of victories and the number of visits. Figure 1 shows a game tree whose nodes show the victories in the left side and the visits in the right side. The game tree starts only with the root and it is expanded according to the method used.
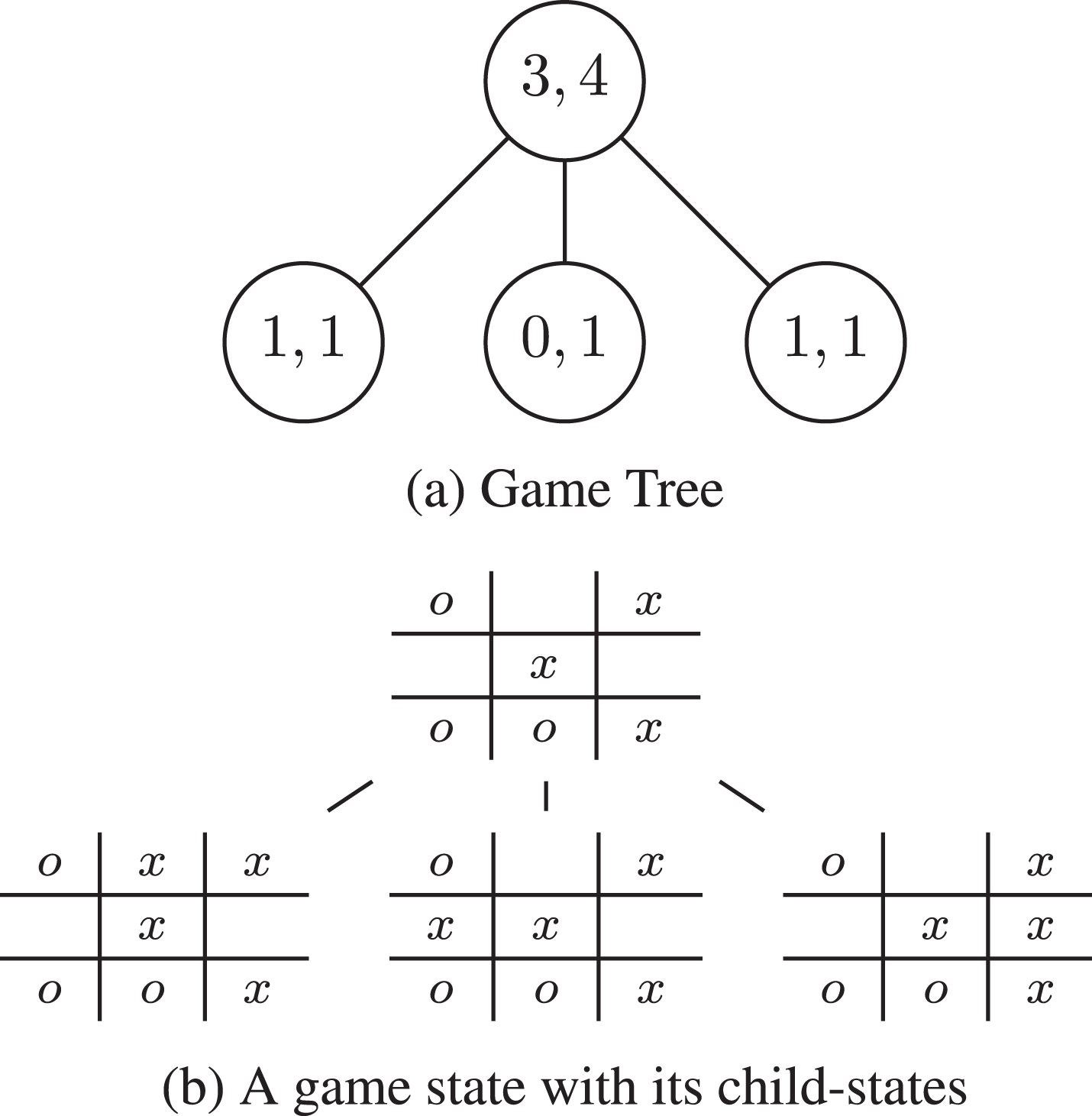
An example of MCTS for the Tic Tac Toe game.
In each interaction MCTS performs four steps which are repeated cyclically until a stop criterion is satisfied [5, 9] (see Algorithm 1 and Fig. 2): Selection, Expansion, Simulation and Backpropagation.
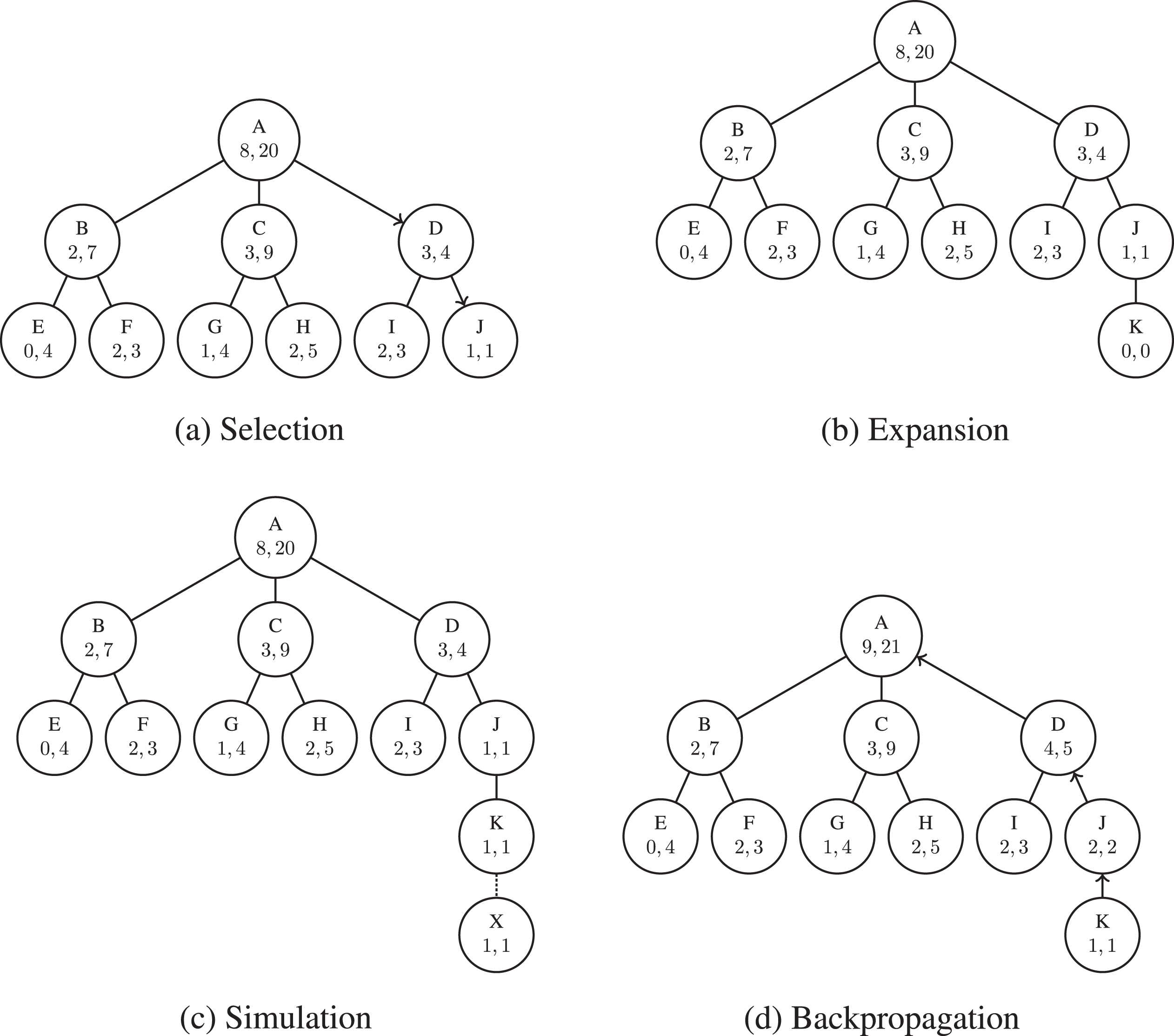
MCTS method.
These steps are repeated until a stop criterion is satisfied, this can be a limit of simulations, run time or iterations. Finally, when the method ends, the agent must choose between the child-node of the root-node considering any of the next criteria [5]:
In each iteration, in the selection step, in each level of the game tree, the MCTS method faces the following decision: Which node should be visited? The best one so far or some else that may be better than this one in future iterations? The above is known as the Exploration-Exploitation Trade-Off, which the Multi Armed Bandit Problem (MABP) also belongs.
The decision of which node should be visited in each level of the game tree is equivalent to decide which slot machine to activate in MABP, so each node can be a machine as follows: The number of victories of a node is equivalent to number of times that a slot machine has given rewards. The number of visits of a node is equivalent to number of times that a slot machine has been activated. Each level in a game tree is a MABP.
Due to their equivalence, it is possible to use the techniques developed to MABP in MCTS. A selection policy is an algorithm that allows to decide in MABP which slot machine to activate. The most popular policy is Upper Confidence Bound.
Upper Confidence Bound
Proposed by Auer et al. [3] of MABP, establishes that the slot machine to activate is the one that has the maximum value of Equation (1).
UCB is the most popular policy used in MCTS because it is easy of implement since it only requires the number of victories and the number of times that the node has been visited [5].
Auer et al. [3] propose UCB-Tuned as an improvement to UCB, establishing that the slot machine to activate is the one that has the maximum value of Equation (2).
In order to make the comparison, the GGP-Base framework was used and the Breakthrough, Knightthrough (both games used in [7, 8]) and Connect Four.
GGP-base framework
GGP-Base 1 is a framework written in Java, which allows the development of GGP agents, besides incorporating a Server application which allows to perform matches between agents. GGP-Base can connect with servers that provide games in Game Description Language that allow to test the agents in different scenarios.
Breakthrough
Breakthrough is a board game of i × j size for two players and with turn-based moves. At the beginning, the first two rows of each player had pawns (see Fig. 3). The goal is to take a pawn to the first row of the opponent; for this, the pawn, can move one square forward or diagonally, being able to capture only diagonally. Breakthrough has been solved for a board size of 6 × 5 determining that the second player has a strategy that allows it to win no matter what moves the other player does [17]. For the research here presented a 6 × 6 board was used which is available in GGP-Base.
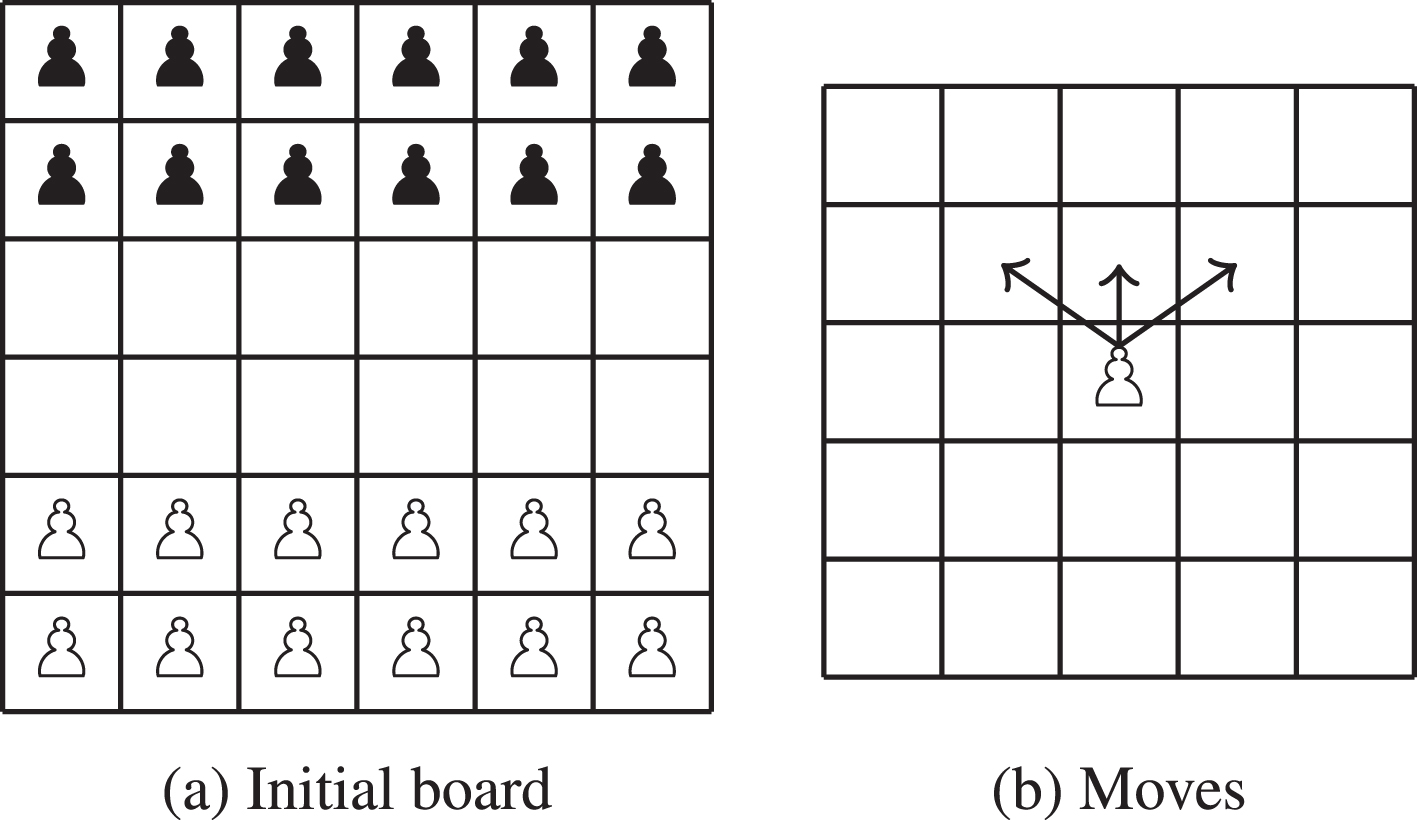
Breakthrough 6 × 6.
Like Breakthrough, Knightthrough is a board game of i × j size, for two players with turn-based moves, but with the difference that instead of using pawns it uses knights (see Fig. 4). The goal is to take a knight to the first row of the opponent. For the research here presented, a 8 × 8 board was used, which is available in GGP-Base.
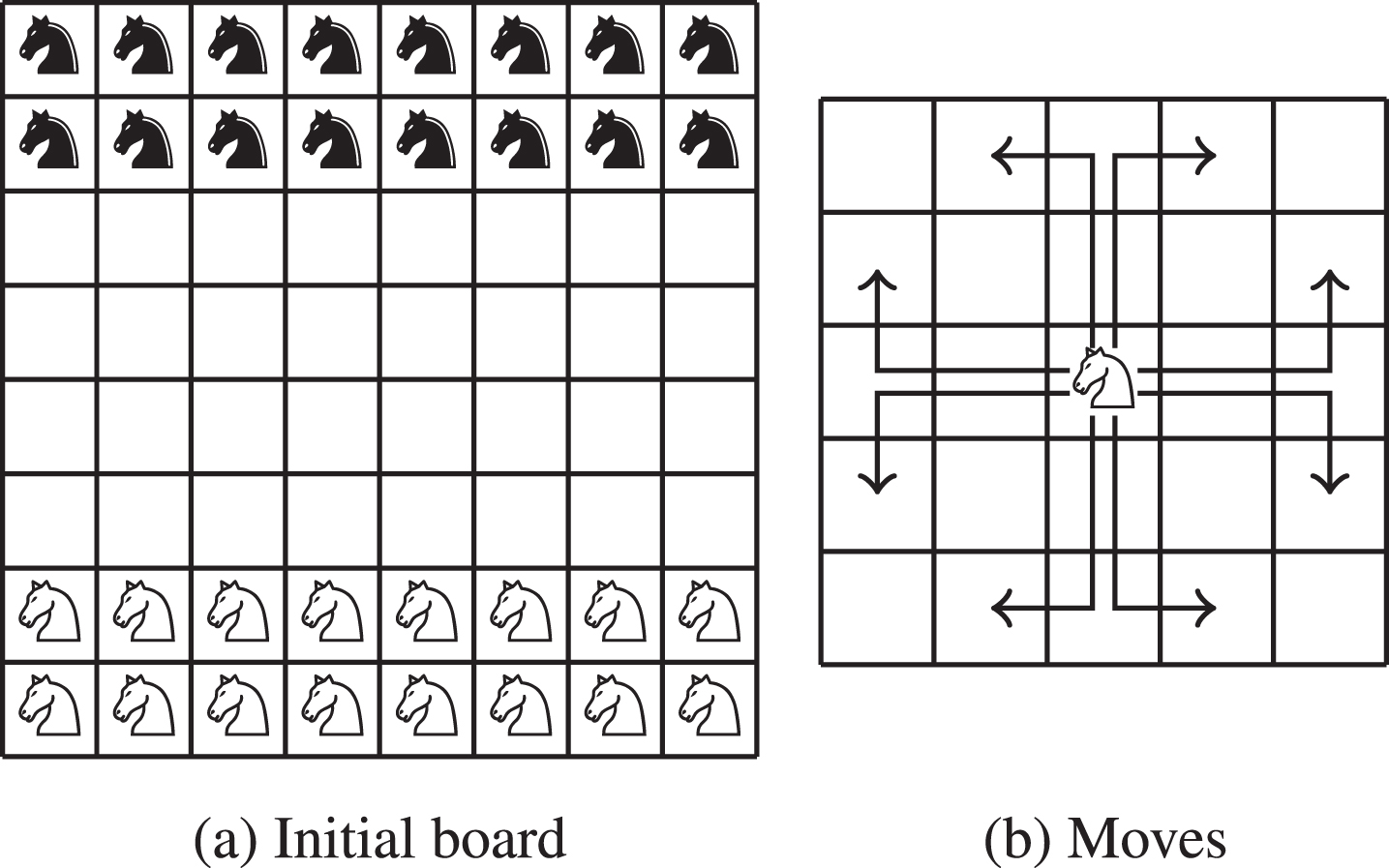
Knightthrough 8 × 8.
Connect Four is a board game for two players with turn-based moves (see Fig. 5). Each player has a set of discs of the one color which are added by the top of the board. The goal is to align four discs on the board before the other player. For the research, a 8 × 6 board was used, available in GGP-Base.
Connect Four 8 × 6.
To compare the policies, two agents were created, one base in UCB and the other in UCB-Tuned. The analysis was performed in two stages; in the first one the MCTS method was limited to 100 simulations per iteration, while in the second one the MCTS method was limited to 1000 simulations. In each stage the agents competed three times in 1000 matches of Breakthrough, 1000 of Knighttrough and 1000 of Connect Four. The results show that UCB-Tuned has the best performance in terms of victories when the MCTS method is limited to 100 simulations; however, when the method is limited to 1000 simulations UCB wins in two of the three games.
MCTS limited to 100 simulations
In the first stage the results shown in the Table 1 were obtained, where it can be observed that the agent which has the best performance in terms of victories, is the one based in UCB-Tuned, winning the 64.39% of times in the three games, in average. It should be noted that in Knightthrough game, UCB-Tuned won approximately the 80% of the times. So in this stage UCB-Tuned is the indisputable winner, meaning it is better to use it when having a limited number of simulations.
Results of 100 simulations
Results of 100 simulations
In the second stage the results shown in the Table 2 were obtained. In this case, we can observe that the UCB won in Breakthrough and Connect Four, while UCB-Tuned only won in Knightthrough. Although the difference between the victories of both players is not greater than the previous stage. For example, UCB only wins the 55.1% of the times in Breakthrough and the 58.5% in Connect Four and looses 61.9% of times in Knightthrough.
Results of 1000 simulations
Results of 1000 simulations
This paper shows a comparative analysis of two selection policies, UCB and UCB-Tuned, in the context of GGP, with the purpose of detecting which policy has the best performance in terms of numbers of victories. Taking the results obtained from the comparative analysis we can conclude that de policy with the best performance in GGP is UCB-Tuned when the MCTS is limited in the number of simulations which happens when the agents are limited in time, very common in competitions like The International General Game Playing Competition [11]. When the MCTS method has a greater number of simulations available, the best policy to use is UCB but only with a small difference over UCB-Tuned.
In the game Knightthrough, the UCB-Tuned policy wins in both stages so we can conclude that in this specific game UCB-Tuned is better to use than UCB.
As the results show that UCB-Tuned wins in four of six competitions, it may be concluded that this policy has better performance than UCB in General Game Playing.
This is a preliminary work so is left as future work: The use of other games that are more complex than the games presented in this paper, for example Amazons, Chess or Go. It is also proposed to carry out an analysis with other polices like UCB-V, PAC-UCB, UCB-Minimal y Minimax Optimal Strategy. The use of different amounts of simulations in MCTS.