
Abstract
At present, the CAAC has established the only “Aircraft Cabin Sound Information Sample Library” in China, which provides strong support for the theoretical analysis method based on the CVR non-discourse sound blind source separation. The separation of aircraft background acoustic blindness based on EEMD-ICA is studied. The performance of different algorithms for the separation of CVR non-discourse background acoustic typical observation signals is compared, and an incompletely constrained adaptive natural gradient algorithm is found for signals that change drastically over time and have a near-zero amplitude over a more extended period. In addition, when there is redundant information or noise on the CVR background acoustic signal, an independent component analysis method is used to reduce the dimensionality of the observed signal, which is essential for extracting valuable information from confounded signals and provides a reference for dealing with changing mixed signals.
Introduction
At present, CAAC has established the only “aircraft cockpit acoustic information sample library” in China. The sound separation will improve the accuracy of CVR non-speech signal recognition, and artificial neural network technology can identify and classify critical voices. The result of the analysis of CVR’s non-discourse information by these two methods is of great significance to find out the cause of the accident [1]. In the future, according to this process, the automatic separation and recognition of non-utterance voices in CVR will be realized through a program to reduce the possibility of misunderstanding by accident investigators. At the same time, by detecting the sound of particular frequency, it can also be used to detect the damage and fatigue of aircraft parts as soon as possible before the disaster, so as to be used for aircraft maintenance, filling the blank of civil aircraft (large aircraft) accident investigation technology and CVR information analysis method. The research of ICA algorithm and CVR non-speech background acoustic signal separation is the current hot spot and difficult point [3].
The blind source separation algorithm based on independent component analysis (ICA) is studied, and the cost function of ICA algorithm based on information maximization is constructed. The performance of different separation algorithms for typical acoustic signals in CVR non-discourse background is compared. It finds that there exists an incomplete constrained adaptive natural gradient algorithm for signals whose amplitude is close to zero and varies sharply with time.
Independent component analysis (ICA) proposed in this paper can reduce the dimension of the observed signal, which is very important for extracting valuable information from mixed signals. This paper is divided into five parts. The first part introduces the background and significance of the study. The second part summarizes the previous literature, laying a theoretical foundation for writing. The third part discusses the research methods, including the blind source separation algorithm and the construction of cost function based on information maximization ICA algorithm. The fourth part validates the constructed function and gets the evaluation results. The fifth part summarizes the full text.
Related work
At present, research on the background acoustic separation of aircraft based on EEMD-ICA has gradually begun to enrich. Because of the shortage of airborne FDR recording parameters (part of the old FDR records only a few flight parameters) and some types of aircraft (maximum allowable takeoff weight below 5700 kilograms), the FDR is not forced to install. The foreign aircraft accident investigation agency proposed to use the CVR as a potential signal sensor to analyze the voice and non-discourse acoustic information recorded on the CVR. At present, some human factors have been investigated and analyzed in the field of speech sound recorded by CVR abroad. For example, through discourse analysis, discourse analysis and conversational analysis, the pilot’s fatigue, alcohol, drugs, etc. are judged [4]. Foreign countries have also paid more attention to the CVR recorded cabin sounds, but they are limited to testing the cabin sounds of specific aircraft flight accidents, and the application of CVR non-discourse information is still in the initial stage, only through a single aircraft airspace case analysis, there is no complete, systematic method and technology. In the field of CVR non-discourse information research, China has been in the brewing stage. In recent years, advanced accident investigation experience has been learned in countries such as the United States, France, and Australia. Combined with the actual situation of domestic work, in the civil aircraft of various type of recorder accident, accident symptoms such as unsafe events under the decoding, the structure of the aircraft noise and acoustic analysis method and made much work to measurement technology, etc. Accumulated experience for effective use of CVR non-discourse information [5]. Therefore, how to obtain more characteristics through the recording of cockpit sounds that are dependent on today’s aviation, in order to grasp the flight status of the aircraft, it is necessary to analyze accurately, handle, and find the cause of the aircraft accident [6].
At present, the research of aircraft background acoustic separation based on EEM-ICA is gradually enriched. In view of the lack of on-board FDR recording parameters (some old FDR records have only a few flight parameters) and some types of aircraft (the maximum allowable take-off weight is less than 5,700 kg), FDR is not forced to install. Foreign aircraft accident investigation institutes suggest using CVR as a potential signal sensor to analyze voice and non-voice acoustic information recorded on CVR. At present, foreign scholars’ research on CVR voice mainly focuses on some human factors. For example, through discourse analysis, discourse analysis and conversational analysis, the fatigue, alcoholism and drug abuse of pilots can be judged. Other foreign scholars have paid more attention to the cabin sound recorded by CVR, but only limited to the detection of cabin sound in specific aircraft flight accidents. The application of CVR non-discourse information is still in its infancy, only through a single aircraft airspace case analysis, but there is no complete and systematic method and technology. In the field of CVR non discourse information research, China has been in the embryonic stage. In recent years, the United States, France, Australia and other countries have accumulated advanced experience in accident investigation. Considering the actual situation of domestic work, a great deal of work has been done on the measurement technology in various types of civil aircraft recorder accidents, such as the decoding of accident symptoms under unsafe events, the structure of aircraft noise and acoustic analysis methods. Accumulated experience in the effective use of CVR’s non discourse information.
To sum up, it is necessary to analyze, deal with and find out the causes of aircraft accidents accurately how to acquire more features by recording the cockpit sounds related to aviation in order to accurately grasp the flight state of the aircraft.
Blind source separation algorithm and information maximization
Blind source separation algorithm based on independent component analysis
At present, the research of blind source separation algorithm based on independent component analysis is mainly focused on the following aspects: the determination of the probability density function of source signals, such as the accurate description of the PDF characteristics of Gauss, super Gauss and sub Gauss source signals. According to ICA’s hypothesis, each source signal is statistically independent, so each source signal s
i
can be described by its PDF to p
i
(s
i
). It can be seen that the signal can be divided into Gaussian, Super Gaussian, and Sub-Gaussian signals. Many noises have Gaussian characteristics. Nature-based speech signals and certain music signals have super Gauss characteristics, while images in nature have sub-Gaussian characteristic. If the PDF of the prior source signal is known, ICA can achieve better signal separation. Conversely, if the characteristics of the PDF of each signal source are not known, measures should be taken to include p
i
(s
i
) learning during the learning process. So how to infinitely approach the PDF of the source signal or how to avoid the determination of the source signal PDF in learning is an important issue in ICA research [7]. According to the different definitions of the cost function and the different learning algorithms, various independent component analysis algorithms can be constructed [21–28]. The common ICA algorithm usually proposes a cost function with W is a variable, which is a function of measuring the independence of each component of the y (t) signal, and there are many methods for measuring independence, and thus many cost functions are formed. After the cost function is given, a proper learning algorithm can be used to optimize the cost functions, such as the gradient method and the quasi Newton method. However, whatever algorithm is used, the residual error of the steady state should be small and the convergence speed should be fast. Different cost optimization algorithms can be applied to the same cost function, and the same optimization algorithm can be applied to different cost functions. The statistical properties (such as consistency and robustness) of the ICA algorithm depend on the selection of the cost functions, and the algorithm characteristics (convergence speed and stability) depend on the selection of learning algorithms. Therefore, the characteristics of the ICA algorithm depend on the cost function and the learning algorithm. The study of cost function and learning algorithm has always been the central task of ICA researchers [8]. To illustrate the concept of stability, for simplicity, the case of one-dimensional signals is discussed y = wt, where x and y are random variables. In order to find that the cost function J(w) with the one-dimensional variable w is the dependent variable reaches the minimum value, the following iteration formula can be used to calculate:
In the formula, μ is the step size, j (w) = - ∂J (w)/∂w. If
The Infomax principle of information maximization proposed by some scholars can be simply described as: when the mutual information of the input and output ends of the network reaches the maximum, it is equivalent to the removal of redundant information between the components of the output terminal. Some scholars have further explained that: For a neural network with a linear link at one output end [21–28], when the information transmitted through the network reaches its maximum, the mutual information between the components of the output will reach a minimum [11]. Applying the Infomax principle to the blind source separation problem is equivalent to maximizing the combined entropy of the separated signals [12]. The vector form of the combined entropy of the separation signal y(t) is:
In the formula, H (y i ) is the edge entropy of the output components, and I (y) is their mutual information. Therefore, maximizing the joint entropy H (y) of the split signal means that the mutual information of the output component is minimized. Maximizing H (y) is not a direct target for ICA, but H (y) can minimize I (y) by means of statistical independence of each component of the network separation signal. The idea of algorithm is to get an intermediate vector y (t) = Wx (t) through linear transformation for each observation vector x (t) first. Then the vector u (t) is obtained through nonlinear transformation u i = g i (y i ). Second problems and third problems in ISODATA algorithm are analyzed [13]. The initial selection method and K value determination of cluster centers are considered. Both the original ISODATA algorithm and the ISODATA algorithm using the standard function have a common feature that first select the K points as the initial cluster center, and then iterate on this basis [14]. It is difficult to get a stable clustering result from clustering randomly selected initial clustering centers. In order to solve this problem, the selection of clustering center is improved, the dependence of initial value selection in clustering algorithm is improved, and the stability of clustering results is improved, and the experimental results are given.
From the above discussion, it is can be seem that the stochastic gradient ∂J (W)/ - ∂W provides the cost function J (W) the fastest rising direction. The stochastic gradient is based on the assumption that the parameter space Q is based on the Euclidean space with the orthogonal coordinate system W, but the more common case is that the parameter space is the Riemann space. Euclidean space is only a special case of Riemann space. Can the stochastic gradient ∂J (W)/ - ∂W in the Riemann space still provide the fastest rising direction of the cost function J (W) ? This is a place worthy of study. Some scholars have studied this problem seriously and gave a reasonable explanation. In Euclidean space, the length of the increment dW of the coefficient vector can be expressed as:
But if the coordinate system is not orthogonal, then the length of dW is expressed as:
It can be seen that Euclidean space is a special case of Riemann space. Except for Euclidean space, the stochastic gradient can’t provide the fastest rising direction of cost function in Riemann space. Some scholars have also proved that natural gradients can solve the problem of stochastic gradients. In Riemann space, the fastest rising direction of function J (W) is provided by the following:
However, the solution of matrix G needs to know the concrete structure of the parameter space, which is difficult to realize in practice, and even if the problem is solved, formula (5) involves the inverse of the matrix to increase the complexity of the algorithm. Especially when the dimension of the parameter space is large, the matrix G inversion must have a large amount of computation. It is very difficult to implement, and it is inconvenient to be applied in practice. In order to solve this problem, some scholars have put forward a more concise and effective way to replace G-1 (W) with W
T
W, so that the natural gradient algorithm becomes further:
The number of sample points is 500, where the function rem (u, v) represents the remainder of the variable u divided by v. Take random mixing matrix A = rand(size(sig,1)) and perform Monte Carlo analysis for 100 times. As shown in Table 1, the natural gradient algorithm has advantages in terms of stability, separation performance, and algorithm speed.
Evaluation results of image and base and modulation and demodulation function. Comparison of evaluation results after normalization. adjacent judgment value. Comparison of signal separation effects SIR value [d B] and total time consumption (s) The separation index and time consuming PI of each algorithm The separation index and time consuming PI of each algorithm
Comparative study of separation performance
Selection algorithm Fast ICA, EFICA, joint algorithm, SANG, JADE. The test sample takes 10000 to 80000 and the step length is 10000. The separation performance of the algorithm is measured by two criteria: statistical standard and computation time [15]. It is found in simulation experiments that the separation effect will change with the increase of sample points for each signal. As shown in the figure. For the real aircraft cabin sound signal, as the sample signal has a continuous zero amplitude signal segment, the statistical SIR value will decrease in the low amplitude segment, and the SIR value increases accordingly when the amplitude increases. When the number of sampling points per observation signal is greater than 25000, the SIR value tends to be stable [16]. When the sample number is less than 25000, the SIR value fluctuates. Autopilot alarm S1 and machine speech reminder signal S3 are more regular. As the number of sampling points increases, the fluctuation becomes stable. S2 is a dense, regular continuous signal of APU fire alarm [17]. After the beginning of a SIR value fluctuation, as the amplitude of the signal becomes smaller, the value of SIR becomes smaller. The S4 pilot’s operation engine switch sound signal is relatively sparse, the amplitude of the longer period is close to zero, and the signal changes with time, and the SIR value increases accordingly when the instantaneous amplitude increases.
It can be seen from the diagram that, for real aircraft cabin sound signals, the SIR values tend to be stable after a certain number of sample points (such as 25000), and a satisfactory separation effect can be obtained, and the average SIR value is above 20d B. The combined algorithm has better separation effect for more dense non Gauss signals (such as Y1, Y2, Y3), and for the switching signal Y4 with more zero value, the separation effect has no other advantages. The natural gradient learning algorithm (SANG) with incomplete constraints of adaptive learning rate can still work very well for the source signal amplitude changing with time or at a certain time zero, so the SANG algorithm is more effective for the separation of Y4 such as signals.
The computer hardware is configured as: the operating system Windows XP, CPU P4 3.0G, memory 1GB. Through simulation experiments, the separation index PI and the average time consuming of each algorithm are gotten, as shown in Table 5.2. It can be seen that the joint algorithm and the improved natural gradient algorithm have better separation effect, and the joint algorithm is more general. Fast ICA algorithm and its optimized and extended EFICA algorithm and joint algorithm, SANG algorithm and JADE algorithm are studied for blind separation and processing of CVR non-speech background acoustic signals. Combining these typical algorithms, the blind separation of CVR background sound signals based on independent component analysis is realized by estimating the evaluation function of the separated signal [18]. The simulation shows that it is feasible to separate and study the background sound signals used by the independent component analysis in the CVR record, and the separation effect of the SANG algorithm and the joint algorithm is better. The SANG algorithm has a better separation effect on the amplitude of the source signal at a time zero or non-stationary signal which changes rapidly with time. The combined algorithm makes full use of the advantages of the two algorithms of EFICA and WASOBI, and has the overall optimal separation performance [19].
Comparative study of multidimensional observation signal separation simulation
The separation performance index and time consumption after the number of signals are changed are compared. The comparison between the PI value and the SIR value of the graph shows that the joint algorithm is optimal in terms of the average separation performance of multiple signals, followed by the EFICA algorithm [20]. From the SIR curve, it can be seen that each algorithm changes in varying degrees when the number of source signals changes. The separation performance becomes worse and the consumption time increases, as shown in the diagram.
As shown in Fig. 4, the sound insulation curve simulated by Simulink is similar to the sound insulation data curve obtained by the impedance tube sound insulation experiment. And the sound insulation curve shows that when the stiffness of the system dynamic vibration absorber connection spring steel piece is small, the effective frequency band in the low frequency region of 100Hz–500Hz is wider, the frequency of the peak of the sound insulation is lower, and the weight of the weight is different. It will cause the peak of the sound insulation to be different. It can be seen from the above figure that in the impedance tube sound insulation experiment, under the action of the random white noise emitted by the power amplifier, the dynamic vibration absorber sample devices with different spring system cooperation modes have significant noise isolation. The role (Fig. 5). The observation signal obtained by mixing the source signals in the figure is compared with the algorithm proposed by using a better performance of the current algorithm. These algorithms are: SANG algorithm, Fast ICA algorithm, EFICA algorithm, EEFICA algorithm, JADE algorithm, joint algorithm and the dynamic piecewise refinement online algorithm (DSF) proposed in this chapter. The segmentation criterion used in this experiment is: the absolute value of the amplitude of 300 consecutive sampling points is less than 2. That is, if the four source signals are all approximately zero (k value is set up for all I), this k is the breakpoint, and then get the k = 66168. In order to perform performance comparison under suitable sampling points, only the segment is taken as the experimental object. It is found that the separation effect will change with the increase of sample points. In particular, there is a continuous signal segment approaching zero amplitude, and the SIR value will decrease in the low amplitude segment. When the number of sampling points per observation signal is greater than 30000, the SIR value tends to be stable. This also provides a basis: the minimum length of a segment should not be lower than this value. At the same time, it is concluded that the performance of the improved DSF is improved by introducing the adaptive selection nonlinear function and the correction of the weight of the separation matrix on the basis of SANG. The separation performance of DSF is slightly better than that of the joint algorithm, EFICA and EEFICA, mainly because SANG is superior to Fast ICA in a large number of near zero values, but EFICA and EEFICA are improved on the basis of Fast ICA. Joint algorithm is a combination algorithm of EFICA and WASOBI. In general, the joint algorithm, EFICA and EEFICA are more stable and excellent algorithms, while the separation of SANG and DSF involves the setting of the learning step, which has a great impact on performance. But the online algorithm makes the separation process a great flexibility, can dynamically set the segmentation points, and a slight time variant mixing also has a very good separation effect.
Simulation curve of sound insulation quantity under three hole main system.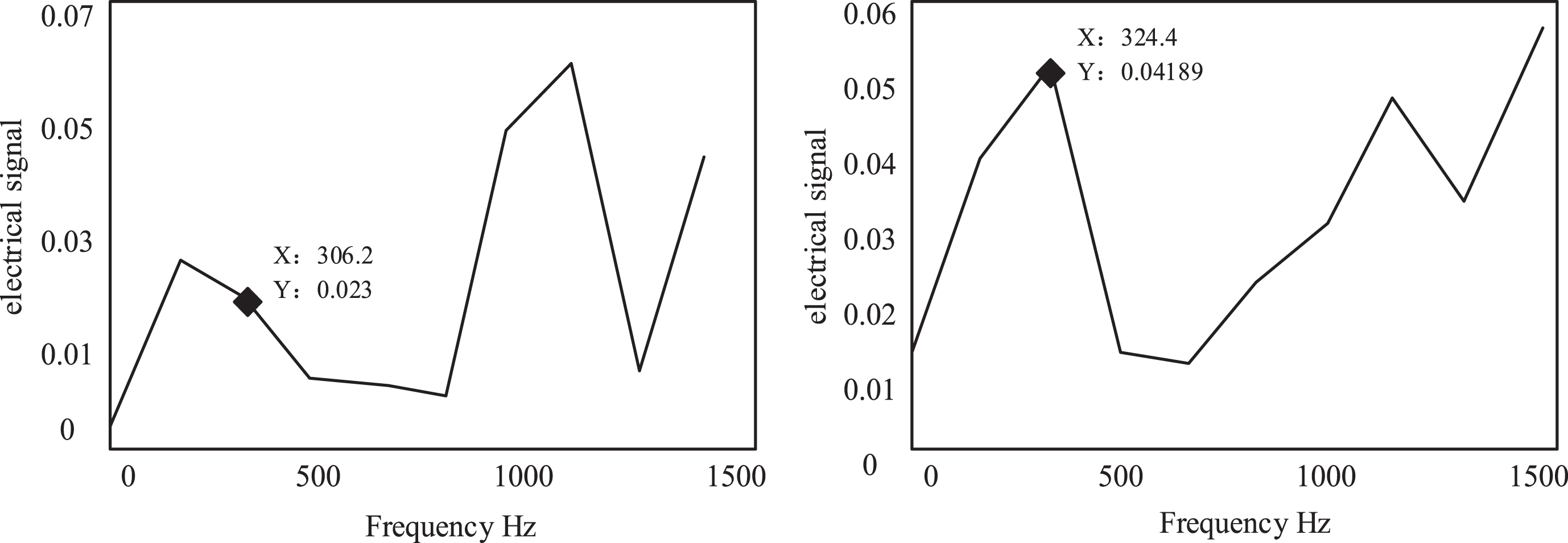

Sound insulation curve diagram of three hole two piece wide spring block small mass dynamic vibration absorber device.
The background sound signal samples recorded by the CGA provided by the CAAC are used to separate multiple observation signals. The performance of the algorithms is further compared. In order to deal with different types of signals, a more suitable algorithm is found, such as the sound of the switch button in the background sound, which has the characteristics of violent change with time, the amplitude of a longer period of close to zero and so on. The performance of different algorithms for the separation of typical observation signals is studied. The separation of switching acoustic information is found under the separation of incomplete constraint adaptive learning rate natural gradient algorithm and has better results. The joint algorithm is more versatile, which provides an effective way to solve the problem of voice separation in CVR non-discourse speech background. After the number of source signals changes, the performance of each blind separation algorithm is compared. In addition, when there is redundant information or noise on the CVR background acoustic signal, an independent component analysis method is used to reduce the dimensionality of the observed signal, which is important for extracting valuable information from confounded signals and provides a reference for dealing with changing mixed signals.
Footnotes
Acknowledgments
The study was supported by “National Natural Science Foundation, China (Grant No. 61271387 and No. 61071203)”.