
Abstract
The recommendation system is an important means to solve the “information overload” of e-commerce today. Consumer psychology believes that consumer psychology dominates consumer behavior, and consumer behavior is the external manifestation of consumer psychology. Therefore, the personalized recommendation algorithm of user consumption psychology is studied based on the specific perspective of local group-buying e-commerce. By constructing a user social relationship network, the personalized recommendation algorithm is evaluated and the final recommendation result is obtained. A personalized recommendation model is proposed based on multi-dimensional space, which is compared with the existing personalized recommendation model. The simulation results show that the improved collaborative filtering recommendation method has a large recall rate and accuracy during the daytime. And F value; when the number of recommended results is small at night, the traditional recommendation method has a slightly larger recall rate, accuracy rate and F value, but as the number of recommended results increases, the recommended effects decrease. In general, the proposed method of the recommended algorithm has a good effect. The method proposed in this paper can improve the accuracy of recommendation and partially eliminate the cold start problem of users, which has certain enlightenment for the expansion of personalized recommendation algorithm and the improvement of e-commerce user management.
Introduction
E-commerce websites also provide “information overload” problems for their users while providing a large number of products. Users need targeted products that meet their needs and interests [1]. The e-commerce recommendation system is considered to be one of the important means to solve the “information overload” in today’s e-commerce field, and its purpose is to recommend the product to users interested in it [2]. With the improvement of consumers’ living standards and consumption power in today’s society, consumers not only pay attention to the use value of goods, but also pay more attention to the satisfaction of goods to their inner psychological needs [3]. Consumer psychology believes that consumer psychology dominates consumer behavior and is a relatively stable psychological situation. Consumer behavior is the external manifestation of consumer psychology [4]. The e-commerce recommendation system was proposed by P Resnick and HR Varian in 1997, which refers to the use of e-commerce websites to provide product information and advice to customers, to help users decide what products should be purchased, and to simulate sales personnel to help customers complete the purchase process [5]. The recommendation algorithm is the core part of the overall recommendation system, which largely determines the performance and recommended effects of the recommendation system [6].
Personalized recommendation is a recommendation based on obtaining existing user data and making recommendations based on it. However, the rapid increase in the amount of data makes the existing recommendation technology less and less able to meet the changing needs of users. Therefore, how to promptly and accurately recommend users in explosive growth information is getting more and more attention from experts. Studies have shown that trust between users has a certain relationship with similarity, which means that the introduction of trust does not conflict with user preferences. In summary, the personalized recommendation algorithm is studied based on the consumption psychology of local group-purchasing e-commerce users by constructing a multi-dimensional space model.
The research in this paper is mainly divided into three parts. The first part is based on the problem that the sparseness of personalized recommendation data in the multi-dimensional recommendation space is more serious than the problem of personalized recommendation data sparseness in the traditional recommendation space. The problem of data sparsity is alleviated, so as to preprocess the data in the multi-dimensional recommendation space and improve the recommendation accuracy. The second part quantifies the trust degree by the method of social network analysis, thus improving the personalized recommendation algorithm based on collaborative filtering. According to the characteristics of personalized recommendation under the multi-dimensional recommendation space, the improved recommendation algorithm is applied to the personalized recommendation under the multi-dimensional recommendation space, so as to eliminate the cold start problem of some users and increase the recommendation accuracy and acceptability; In the third part, through the data collection and processing, the empirical research on the personalized recommendation model under the multi-dimensional recommendation space is carried out, and finally the conclusion is drawn.
Related work
With the popularization of Internet technology and the development of e-commerce, the recommendation system has gradually become an important research content, and more and more researchers have paid attention. Yang M built the recommendation space through three dimensions (user-project-time), establishing a multi-dimensional recommendation model that considers context information, and implementing a recommendation system that supports the function of data warehouse [7]. Sun K integrated contextual information into a multidimensional recommendation model, leveraging the ability of data warehousing and OLAP to handle hierarchical aggregation calculations to solve recommended problems and improve recommendation accuracy [8]. Liu X M divided the situation into user-associated contexts and project-associated contexts, and extends the simple time dimension to a situational dimension that can include multiple feature factors [9]. Po LI added context information to the two-dimensional space of traditional user information and project information, the project recommendation evaluated and predicted in the two-dimensional space and the information recommendation of the three-dimensional space. The latter is better than the former conclusion [10]. Qingxia LI proposed a user-and project-based e-commerce personalized collaborative filtering recommendation algorithm for the data sparseness and scalability of traditional collaborative filtering algorithms in e-commerce systems. The results show that the algorithm is recommended quality, Accuracy and recall are significantly better than other recommended algorithms [11]. Luo P proposed a personalized recommendation algorithm based on BP neural network, how to establish a hybrid recommendation model studied, using BP neural network training to improve the accuracy of the user similarity algorithm. Experiments show that the algorithm can effectively reduce the user similarity. The bias and improve the quality of personalized recommendations is calculated [12]. Zheng C D focused on the consumer perception dimension of the personalized recommendation system and its impact, and found that system trust is negatively correlated with consumers’ acceptance of personalized recommendations, and other factors were positively correlated [13]. From the perspective of the network platform, Zhang P extracted commodity attributes, building a clothing model, and the validity of the model verified [14]. Based on the hierarchical space vector model, Jueliang H U established the r-preference model and the user interest feature vector was used to represent the model. The hybrid recommendation algorithm was used to match, and the comprehensive score of each garment in the target set was calculated to complete the recommendation [15].
All in all, the current research on personalized recommendation has been rich, scholars apply personalized recommendation method to various types of systems, including shopping system, teaching system, etc., and optimize the algorithm in many aspects, improve the algorithm. The stability of the algorithm reduces the sparseness and scalability of the algorithm. However, there are few related researches on the personalized recommendation algorithm based on the consumer psychology of local group-buying e-commerce users [16, 17]. Therefore, based on the previous research, this paper is based on group purchase. The research on the recommendation algorithm of e-commerce users has certain innovation [18].
Personalized recommendation algorithm based on local group purchase E-commerce user consumption psychology
Personalized recommendation algorithm evaluation method
There are many evaluation methods for the recommended algorithm, but the most commonly used evaluation index is accuracy. Among them, the average absolute error, root mean square error and standard average error are the most direct and typical indicators to measure accuracy [19]. The average absolute error is obtained by averaging the absolute values of the deviations between the single value and the arithmetic mean, and the root mean square error can be used to evaluate the degree of change in the data. The calculation formulas of the three indicators are as shown in Equations (1 to 2):
The number of items that the user i has scored is represented by n, and the predicted value and the true value of the score are represented by p
ia
and r
ia
, respectively. The minimum and maximum values of the user score interval are indicated by rmin and rmax, respectively. In addition to the above three methods, the recall rate and accuracy rate are also indicators for judging the accuracy of the recommendation. The recall rate is the ratio of the items selected by the user in the recommendation result to all items selected by the user. The accuracy rate is the ratio of the items selected by the user to all recommended items in the recommendation result, as shown in Equations (4) and (5). Show:
The number of items selected by the user in the recommendation list is represented by N
rs
, and the number of all items selected by the user is represented by N
r
, and the number of all recommended items is represented by N
s
. The recall rate and accuracy rate must be used at the same time to evaluate the recommendation algorithm in order to comprehensively evaluate the quality of the recommendation algorithm. Therefore, the two are combined to propose the F index, as shown in Equation (6):
In addition to calculating the accuracy of the recommendation, the data mining capabilities of the algorithm are also one of the criteria for evaluating the recommendation algorithm. Coverage is the ability of the recommendation algorithm to explore the long tail of the project, ie the ratio of recommendations to the total set of projects [20]. Assuming that the user set is represented by U, the recommended result is that the length N is represented by R (u), as shown in Equation (7):
A personalized recommendation model is constructed under the multi-dimensional recommendation space by analyzing and measuring the similarity of group purchase users, the trust degree of group purchase users, and the relevance of group purchase users. Among them, the functions of each part are as follows: input: “group purchase user one item” score data, “group purchase user group purchase user” relationship data; output: calculated recommendation result; personalized recommendation computer system: realization of target group purchase user item. It is recommended to obtain a m×n order recommendation item matrix, and the i-th row of the matrix contains recommended items for the i-th group purchase user.
The similarity of group purchase users is the degree of similarity calculated based on the score of group purchase users. When there is no score, the value is set to 0. Let the total set of group purchase users be V, and compare the similarity between users u ∈ U and a ∈ U by cosine similarity measure, then the similarity between a and u in context d is simu,a,d, as in Equation (8), where ru,i,d ∈ Ru,i,d and ra,i,d ∈ Ra,i,d And Ru,i,d and both belong to the data-filled scoring matrix.
Personalized recommendation is to recommend projects with similar evaluations to group purchase users, but most of the current recommendations are based on group purchase users’ preferences. This group purchase user preference is calculated. In fact, the social relationship of group purchase users also has an important influence on the recommendation, that is, people are more likely to accept recommendations from friends and family, which is precisely because there is a trust relationship between group purchase users and group purchase users with social relationships. There is evidence that the trust between group purchase users is related to the similarity of group purchase users, which means that the introduction of trust does not conflict with the interest preferences of group purchase users.
User trust is the degree of trust between users and users calculated based on the social relationships existing between users. By constructing user social relationship graphs and relationship matrices, the trust between users is calculated and a trust matrix is established. Social relationships between users can be analyzed by constructing social networking methods. In a social network, a user is represented by a node, and a relationship between users is represented by an edge, and the constructed social network diagram is an undirected graph. There are multiple reachable paths between nodes, that is, there are direct and indirect trust relationships between them. The transfer of the relationship between nodes can be measured by matrix multiplication. The direct connection between nodes is represented by matrix C1 (the connection is 1, otherwise it is 0, the diagonal of the matrix is 0), and then the two steps between the nodes, the indirect connection relation matrix is:
Let the trust degree between the directly connected nodes be 1, and the trust degree between the nodes connected indirectly through the two steps is 1/2, and then decay, then the trust matrix between the nodes is as shown in Equation (10):
Wherein, the number of steps connected by two nodes is represented by n, the processed n-step connection matrix is represented by
The relevance of group purchase users is to combine the similarity and trust between group purchase users, so as to get the correlation degree between group purchase users. The ways in which they are merged include multiplication and linear combination. If the fusion is performed by multiplication, when at least one of the two is 0, the calculated group purchase user correlation is also 0, which not only relieves the cold start problem of the group purchase user, but makes the problem more serious; if linear combination is adopted. The way to merge is only when both are 0, the calculated group purchase user correlation is 0, which makes the cold start problem of group purchase users relieved. Therefore, the similarity and trust between group purchase users are linearly combined to calculate the relevance of group purchase users. Then, the calculation method of the correlation CORu,a,d of the group purchase user u and the group purchase user a under the scenario d is as shown in the formula (11):
Among them, A indicates the similarity of group purchase users and the trust degree of group purchase users in the proportion of group purchase users respectively. The value needs to be determined by a large number of experiments. At the same time, the value may vary depending on the amount of data.
Experimental environment and data sources
Considering the approach and difficulty of data acquisition, for the multiple dimensions under the multi-dimensional recommendation space, the three-dimensional recommendation space of time dimension is only used, namely the time-user-one project recommendation space for simulation experiments, S:U×I×T, where the time dimension contains two attributes, day and night, T = {day, evening}. In this paper, the data set used in the simulation comes from the public data set used for experimental research in Data Hall (http://datatang.com/). At present, the data set provided by the data church site is rich and clear, and the data is true and accurate, and is widely used in various fields of research. The data set consists of two parts: user rating data and user social relationship data. The user rating data is a rating value of the movie for the user under day and night conditions, and the range is 1–5; the user social relationship data indicates whether the user and the user are friends, and if yes, the value is 1. The original data set includes ratings for millions of movies and social relationships between tens of millions of users. Since the amount of data is too large and the degree of dispersion is high, data preprocessing is required before the simulation. A total of 8762 scores of 120 movies in the day and night and 1279 social relationships between 150 users are selected as the final simulation data. Each movie gets at least 30 ratings, and each user makes at least 20 ratings for the movie. The final data is converted into a matrix, the user’s scoring matrix for the project during the day and night, and the relationship matrix between the user and the user. The day and night score data are 150*120 matrices, each row represents the rating of each movie for each user, and each column indicates that each movie is scored by all users, and the score is not filled with 0; the data of user relationship is a matrix of 150*150. The value of the buddy relationship is filled with 0, and the value of each user’s buddy relationship is filled with 0. The simulation environment of this paper has the following two parts: hardware environment configuration: Intelcorei5 processor, 2G memory, 500G hard disk. Software environment configuration: simulation tool Matlab, social network analysis tool Ucinet, Win7 operating system. Among them, the simulation tool Matlab is used to perform matrix operations, algorithm development and implementation, simulation results visualization and other operations; social network analysis tool Ucinet is used to construct social relationships between users and visualize social relationships.
Model simulation and verification
User rating matrix under daytime conditions (part)
User rating matrix under daytime conditions (part)
User rating matrix under night conditions (part)
According to the data filling algorithm applied to the project score prediction under the multi-dimensional recommendation space, the project prediction scores under day and night conditions are respectively calculated, and the score data of the project is filled by the group purchase users under day and night conditions. It can be seen that the coverage rate of daytime scores and evening scores of group purchase users after data pre-processing is 24.36% and 24.31%, respectively. After the data filling method based on project score prediction is filled, the coverage rates of group users and daytime scores are respectively It reaches 73.26% and 71.77%. According to the cosine similarity, the similarity of group purchase users under day and night conditions is calculated respectively, and the similarity between group purchase users and the trust degree of group purchase users are linearly added, and the correlation of group purchase users is obtained. A large number of simulation experiments prove that under the daytime conditions of the data set, when
The simulation results are compared with the traditional multi-dimensional recommendation results of collaborative filtering based on group purchase users. The results are shown in Figs. 1 and 2.
Comparison of MAE Recommendation Algorithms under Day Conditions. Comparison of MAE recommendation algorithms under night conditions.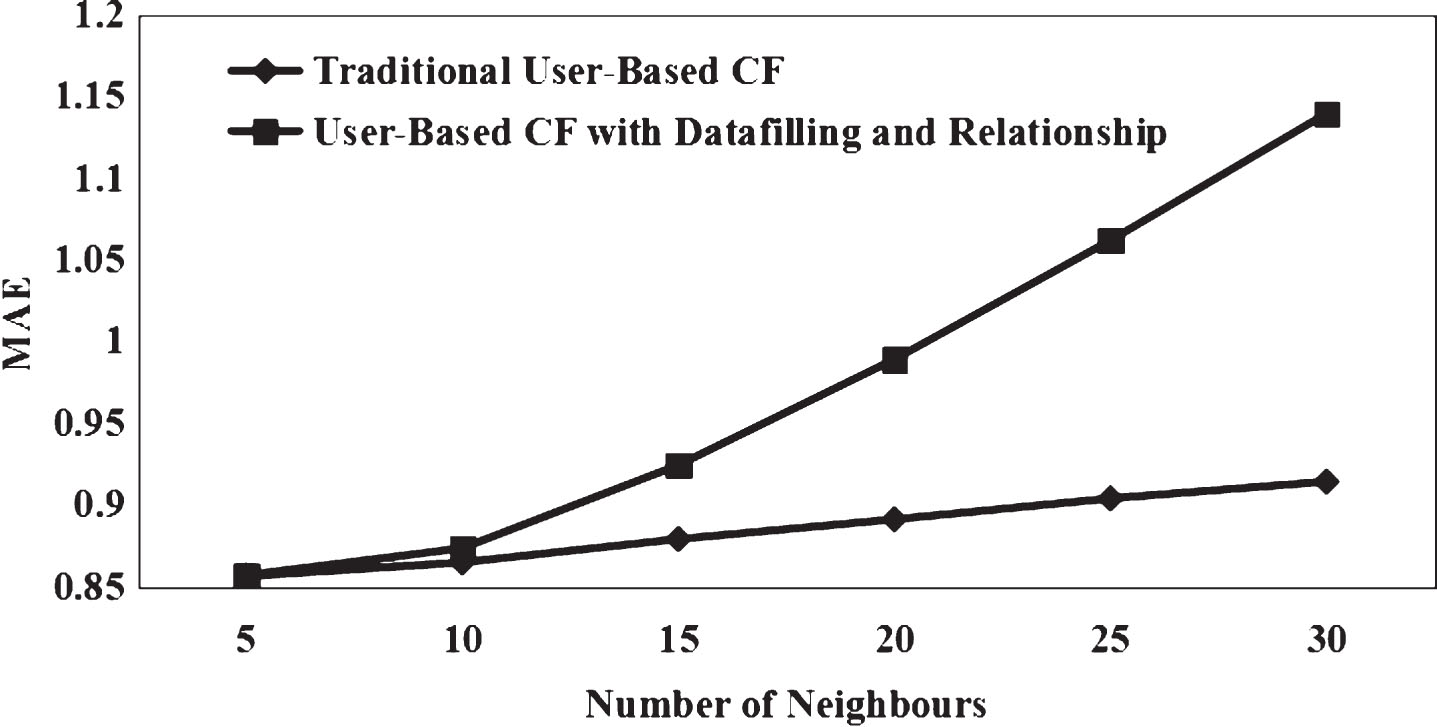
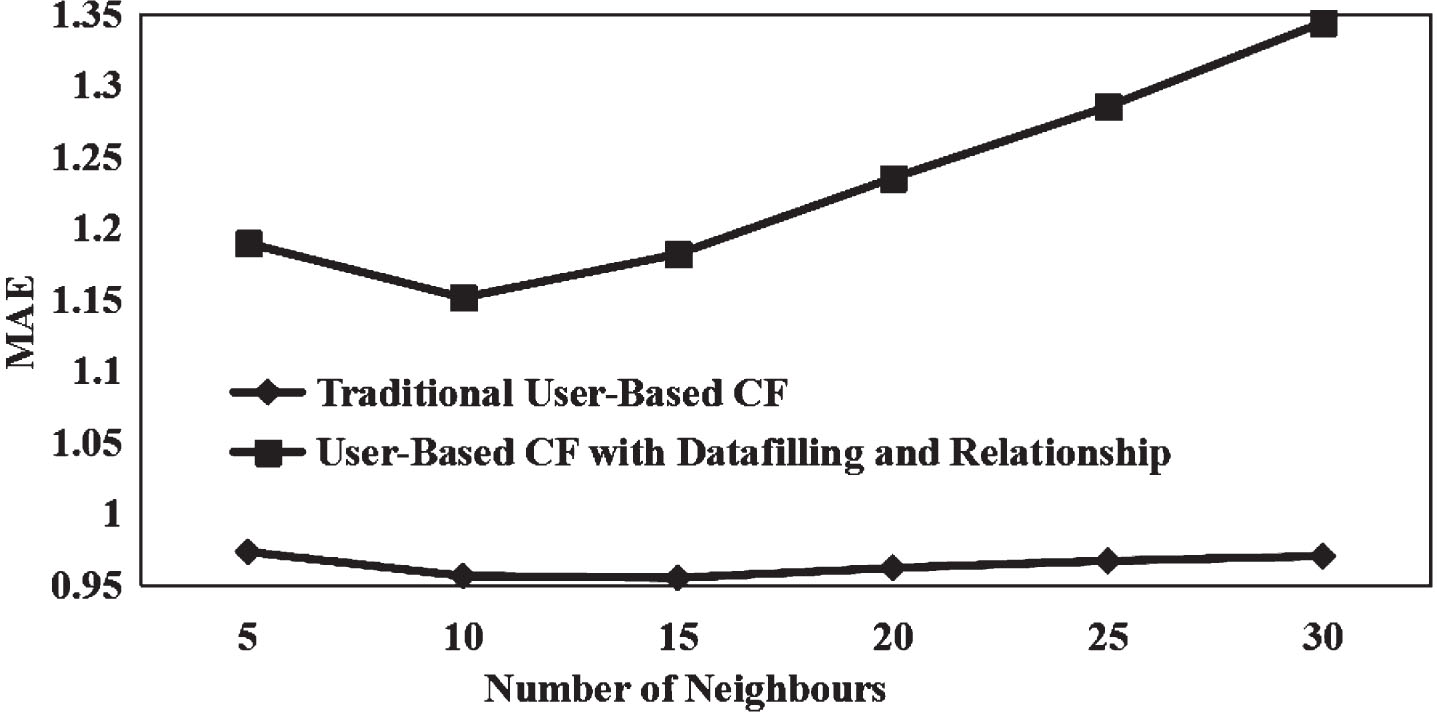
It can be seen from Figs. 1 and 2 that the recommendation result of collaborative filtering based on group purchase users through data filling and group purchase user correlation under the multi-dimensional recommendation space has a small average error.
Therefore, in the multi-dimensional recommendation space, compared with the traditional recommendation method based on group-purchasing user collaborative filtering, the recommendation method based on group-purchasing user collaborative filtering improved by data filling and group-buying user relevance can significantly improve the recommendation quality. The recommendation result of collaborative filtering based on group purchase users through data filling and group purchase user correlation under the multi-dimensional recommendation space has a small root mean square error. In the multi-dimensional recommendation space, the simulation results are compared with the traditional recommendation results of collaborative filtering based on group purchase users. The Recall results of the two recommended methods are shown in Figs. 3 and 4; the Precision results of the two recommended methods are shown in Figs. 5 and 6. The F index values of the two recommended methods are shown in Tables 3 and 4.
Comparisons of recommended algorithms recall under daytime conditions. Recall comparison of recommendation algorithms under night conditions. Comparisons of recommended algorithms precision under daytime conditions. Comparison of recommended algorithms precision under night conditions. Comparison of F indicators under daytime conditions Comparison of F indicators under night conditions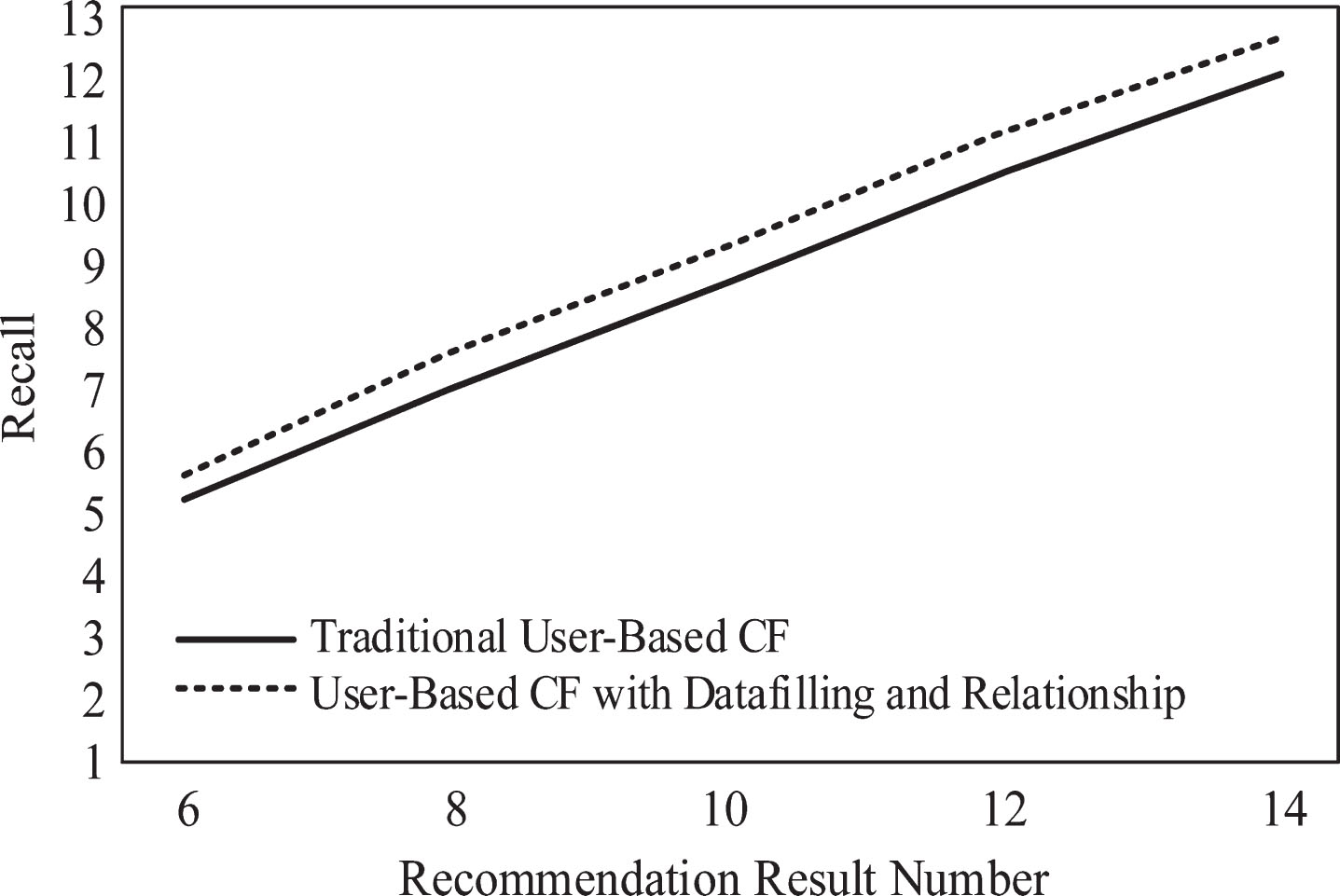
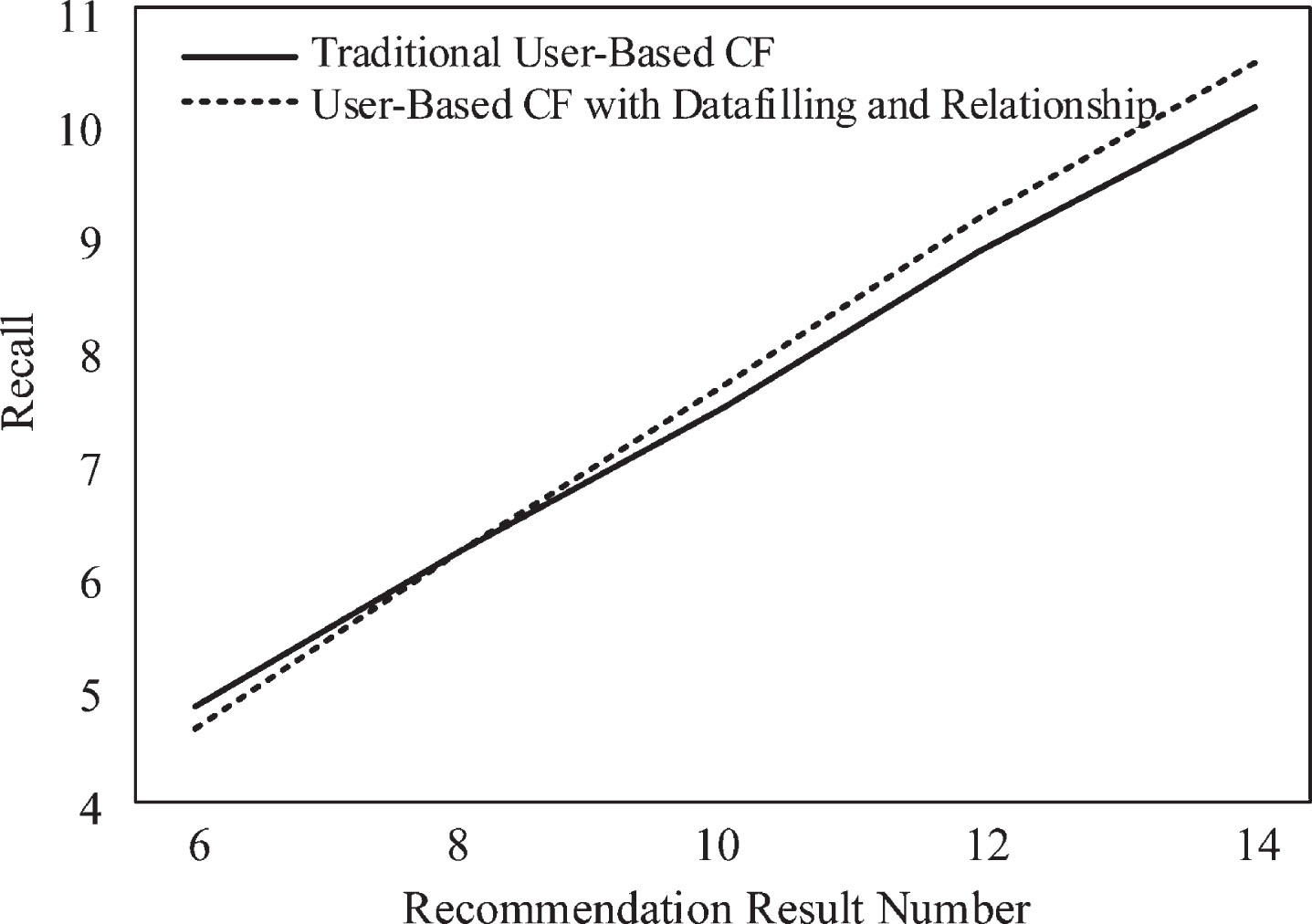
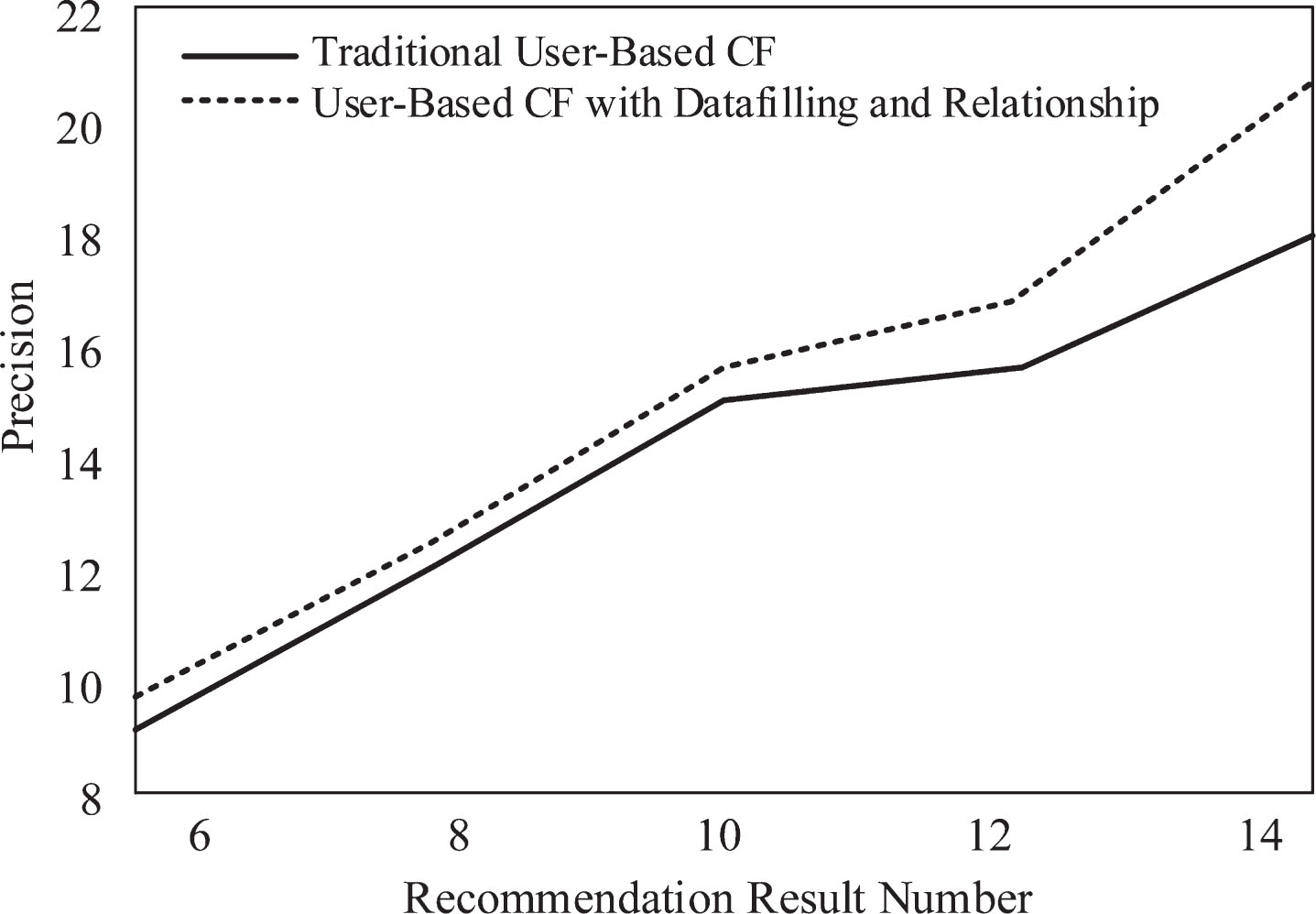

Under the daytime conditions, the recommendation method based on group purchase user collaborative filtering improved by data filling and group purchase user correlation has large recall rate, accuracy rate and F value under different conditions of recommendation results; under night conditions, when the number of recommended results is small, the traditional recommendation method has a slightly larger recall rate, accuracy rate, and F value, but as the number of recommended results increases, the data-filled and group-buy user correlations are improved based on group-purchased user collaborative filtering. The recommended method has a large recall rate, accuracy and F value. This situation, on the one hand, verifies that the results of the experiment may be biased in different data environments; on the other hand, from the overall results of the evaluation indicators, under the multi-dimensional recommendation space of traditional collaborative filtering based on group purchase users, compared with the personalized recommendation method, the personalized recommendation based on the multi-dimensional recommendation space of the group-purchased user collaborative filtering improved by the data filling and the group purchase user correlation can improve the recommendation quality.
The development and popularization of the Internet has led to the rapid development of e-commerce. The information in the network is increasing exponentially. Users cannot find the information they need or want from such massive information, and they are caught in the vortex of information overload and data mining. Effective recommendations have gradually attracted people’s attention. In this context, a personalized recommendation algorithm is proposed for group-purchased e-commerce users. For the problem of personalized recommendation data sparsity in multi-dimensional recommendation space, the data filling method based on project score prediction is used to fill the data under multi-dimensional recommendation space. The social network analysis method is used to measure the social relationship between users, and is defined as the trust between users. Under the multi-dimensional recommendation space, the personalized recommendation algorithm based on user-based collaborative filtering is improved. Through experiments, it can be seen that on the one hand, the algorithm of this paper improves the accuracy of recommendation, especially in the case of high consumption frequency during the day, the recall rate, accuracy and F value of the optimized algorithm are more recommended by traditional algorithms. The result is closer to the actual recommendation of the society, and can partially eliminate the user’s cold start problem. On the other hand, the proposed algorithm is simpler and faster, and it is more convenient to use the system and use the algorithm after being introduced into the system and a good result is gotten. However, the algorithm of this paper still has some shortcomings. The personalized recommendation under the multi-dimensional recommendation space becomes more and more extensive. When the amount of data increases, the operation of the algorithm becomes unsatisfactory, so the information of the algorithm will be used in the subsequent work. The carrying capacity is further enhanced.
Footnotes
Acknowledgments
The study was supported by “Project supported by the Natural Science Foundation of Guangdong Province, China (Grant No. 2016A030310020)”.