
Abstract
At present, distributed systems have been widely used, and a lot of research has been done on the reliability of distributed systems. However, trusted 3.0 based distributed system node trust behavior recognition research is still relatively rare. This paper focuses on the identification process and evaluation method of distributed node trust behavior. In this paper, call links and resource consumption of software behavior are obtained by burying points during the development phase. Based on the idea of “sense of words and deeds”, this paper compares the pre-acquired trust call links with the resource consumption sample data, in order to obtain a credible real-time software behavior model. This paper will focus on the analysis and extend to the distributed environment, and conduct a trusted analysis of software behavior, which provides a new idea for software trusted behavior analysis.
Introduction
The mainframe was born in the 1960 s, and in the next 20 years led the development of the computer industry and large commercial computers with its outstanding computing and I/O processing capabilities and its outstanding performance and security. In the era of booming mainframes, centralized computer system architecture has also become a mainstream development. Due to the good performance and excellent stability of the mainframe, its ability to process business and data in a single machine is also very prominent. Therefore, the IT system has rapidly developed into a centralized processing stage, and its corresponding computer systems are collectively referred to as centralized systems. A centralized system refers to one or more computers forming a central node, and all data, business units, and system functions are processed at the central node. Simply put, the terminal is only responsible for data entry and display, and all data storage and processing and control are done by the host. The centralized system is characterized by a simple deployment structure.Since the 1980 s, with the increasing trend of computer miniaturization and networking, and the increasing volume of business and data, the traditional centralized processing model has gradually failed to meet the actual needs. Until the beginning of the 21st century, IOE-based systems have been widely used in China’s government and finance industries for its excellent stability and ultimate performance. With the rise of the Internet industry and the development of trusted computing, such systems have slowly exposed many problems. For example, the proliferation of Internet services has placed very high demands on back-end IT systems, and it is aimed at minicomputers and high-end storage. Equipment is constantly expanding, creating huge cost issues. Another important issue is the data security issue caused by untrusted software behavior. A distributed system is a system in which hardware or software components are distributed across different network computers, communicating and coordinating with each other only through messaging. In general, distributed systems have the following characteristics without specific business constraints: distribution, equivalence, concurrency, lack of global clock, and failures that always occur [1–3].
Based on the previous understanding of the characteristics of distributed environment and distributed environment, this paper believe that trusted computing is an important means to ensure transparent and controllable data security and calling behavior of distributed systems. Because distributed systems are distributed, the differences in the environment in which the nodes are located will affect the credibility of the data. Nodes in a distributed system are flat and cannot operate other nodes. Therefore, this paper believes that corresponding monitoring and early warning mechanisms are needed to avoid untrustworthy behavior of untrusted nodes. In addition, for various operational scenarios, this paper believes that the factors of trusted computing need to be added to the solution to ensure that the distributed system can ensure reliable operation of processing and data under high access conditions.
In this paper, based on the theoretical basis of Trusted 3.0, the author has conducted an in-depth discussion on the trusted behavior recognition of nodes in a distributed environment. The research premise of this paper is based on the trustworthiness of data sources and the research on the behavior of software in distributed environment. The research content of this paper includes the connection between active immune framework and distributed environment software, and the distributed node trusted behavior recognition model. In the specific research stage, this paper mainly studies the collection and formatting of log content, and calculates the standard confidence interval based on the formatted data collected in the trusted environment. In addition, this paper also discusses the collection method and preprocessing method of logs in a distributed environment. Finally, this paper discusses behavior recognition based on the generated standard log and standard confidence interval, and develops a defense strategy.
In section 2, this paper will introduce the relevant papers and research status at home and abroad. In section 3, this paper introduces the Active Defense Framework based on Trusted 3.0 and the distributed node trusted behavior recognition model based on its paper. And in this section it will also introduce the process of trusted behavior recognition of distributed nodes in detail, including data collection, processing and prediction. In section 4, this paper will introduce related experiments and results. Finally, we conclude this paper in Section 5.
Related work
At present, the authoritative research in the distributed environment lies in the extraction of credible evidence in the cloud computing environment [4] or based on historical information data to provide reward and punishment methods to influence the trust value [5], or to establish a set of The authentication mechanism of the letter [6] does not study the promotion of the trusted behavior and untrustworthy behavior of distributed nodes. For the trustworthy study of nodes in a distributed environment, most of the literature is mainly for in-depth discussion of the most trusted path selection [7] and trusted constraint path selection [8], or the interaction behavior of distributed nodes. Analysis and research have not conducted in-depth research on software behavior. According to a large number of literatures, the current research on the trusted behavior of nodes based on trusted 3.0 active immunization is not sufficient, which is also the necessity of this paper.
Trusted 3.0 and distributed node trusted behavior recognition process
Trusted 3.0
With the rapid development of information technology in China, trusted computing technology is also making continuous progress. At present, trusted computing technology has experienced the following stages [9]. Trusted 1.0 phase, in which more credibility refers to the reliability of the computer, mainly through the means of troubleshooting and backup, is a security measure based on fault-tolerant methods. Trusted 2.0 is marked by the TPM1.0 issued by the Trusted Computing Group (TCG). The main idea of Trusted 2.0 is to use hardware chips as trusted roots, with trusted metrics, trusted storage, and trusted reports. Means to achieve stand-alone protection of the computer. The main disadvantage of Trusted 2.0 technology is that it does not fully consider the computer architecture and it is difficult to achieve active defense. China’s trusted computing technology has evolved to the 3.0 stage, which is the active defense of the application, ensuring visibility during the running of the application, intercepting dangerous behaviors, and thus implementing active defense functions.
Active immune triple protection active defense framework
The research focus of this paper is on the study of the trusted behavior of computing nodes in a distributed environment. After extensive literature review, the active defense triple defense active defense framework proposed by Academician Shen Changxiang (shown in Fig. 1.) is an important theoretical basis for studying the credibility of computational nodes in distributed environments.
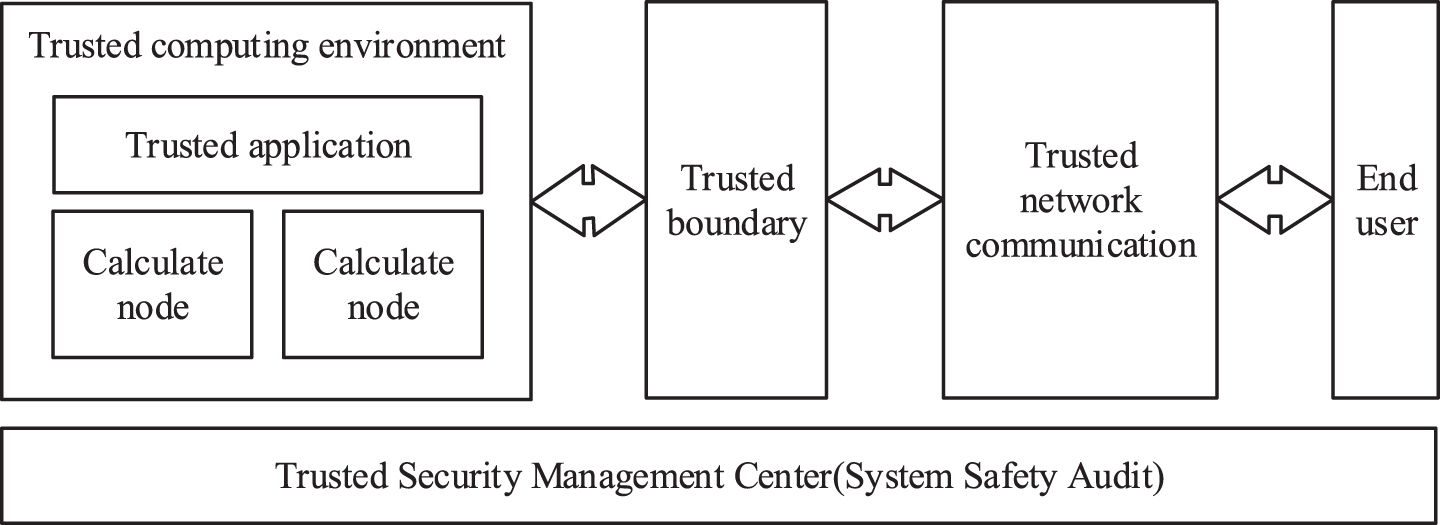
Active immune triple protection active defense framework.
The core idea of the Active Protection Triple Protection Active Defense Framework is trusted computing. A deep and active defense system consisting of a secure computing environment, a security zone boundary and a secure communication network is formed around the security management center, and a strategic linkage between the protection mechanism, the response mechanism and the audit mechanism is established at various levels of the defense system [9]. This paper will take the trusted computing environment and trusted security management center in the framework as the research object, and deeply discuss the trusted analysis of software behavior among distributed computing nodes and the monitoring defense and early warning of the entire distributed system.
Based on the active protection triple defense active defense framework, this paper will further refine the trusted computing environment. Trusted computing environments include components that are trusted for use in compute nodes, and most of these components are deployed in distributed environments from the current production environment. Therefore, the identification of trusted behavior in a distributed environment will be very important.
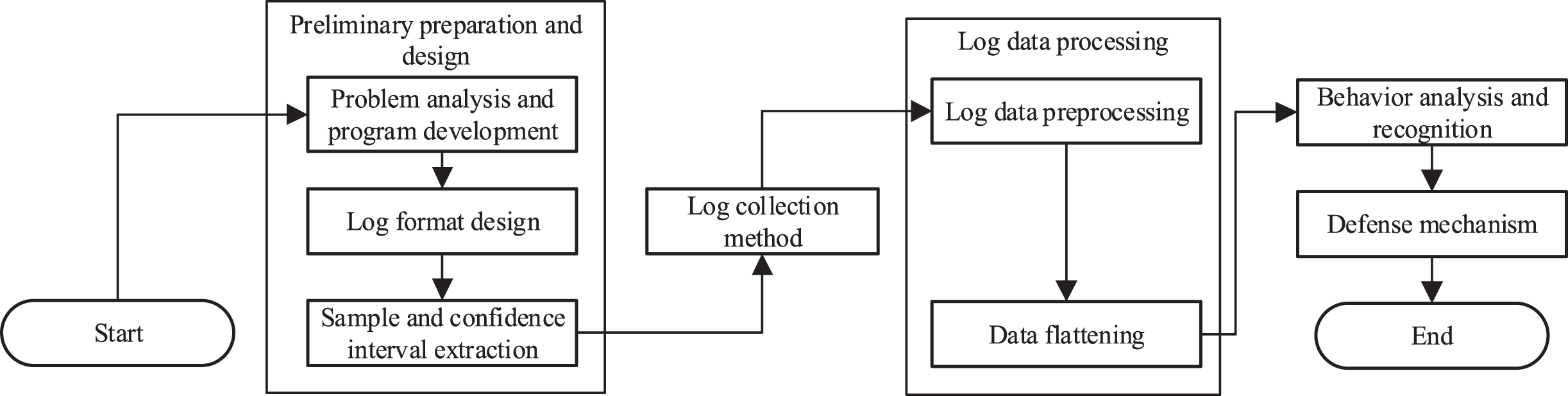
Since the distributed environment is more complicated and has many influencing factors, this paper will assume that the incoming service processing node data is reliable and effective. The research in this paper focuses on the software behavior of general business requests. Therefore, this paper do not consider uploading/downloading and a large number of uncertain I/O operations, as well as other special business operations. Excluding the interference and special factors in the study, it will focus on the identification of trusted behaviors from the following two focuses. Sample and log data collection: pre-thinking and design, log format design, standard sample dataset and confidence interval formulation, and data validation and processing. Analysis and identification of trusted behavior: identification analysis and defense measures of trusted software behavior.
Based on the active protection triple defense active defense framework, this paper will conduct in-depth research on the trusted computing environment module. This paper will discuss the detailed design of trusted computing environment module based on distributed application, and propose a trusted evaluation and active defense model combining trusted 3.0 and distributed environment. The specific model is shown below.
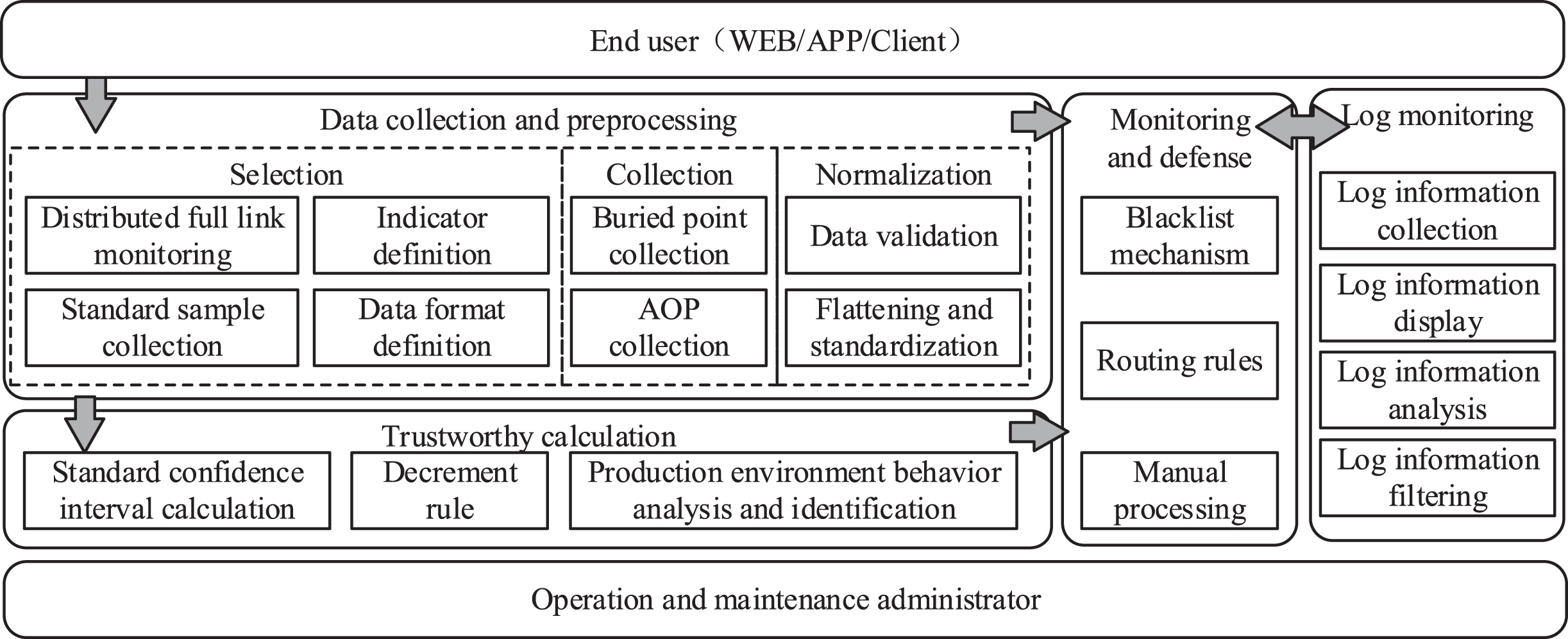
Trusted behavior recognition model in distributed environment.
Schematic diagram of trusted node trust behavior recognition.
The starting point of the model data is the end user, and the end user initiates a network request by operating an end program (app, web page, etc.). When the request arrives at the distributed service application, it will formally enter the trusted behavior recognition model in the distributed environment. The model is divided into three main parts: data collection and preprocessing, trustworthy calculation, and monitoring and defense.
In addition, the model also has log monitoring, which provides log storage and query services for the entire model. The operation and maintenance administrator can observe the running status of the distributed application, and can configure defense measures to prevent dangerous behaviors in time.
The request data is passed to the data collection and preprocessing component. The main function of the component is to process and record the user’s request data in detail. This component is also discussed in the first, second and third subsections of Chapter 3. Among the components, it is necessary to analyze the characteristics of the distributed environment to develop specific plans, as well as definitions of data formats and collection indicators. In the process of writing the program, the logging function should be added at the key points of each method, for example, the logging function needs to be added to the log at the beginning and end of the transaction, when the I/O occurs, and when the exception is caught. Before the application is officially online to the online environment, this article performs multiple simulation tests in a highly simulated environment to collect sample and data fluctuations for the software behavior data of the application. Among the computing trusted components, the software behavior interruption and feedback mechanism is integrated. The main function of the mechanism is to interrupt the target method according to the service address and name in the blacklist in the Control and Prevention Center, and feedback to the monitoring. Among the defense centers, the function of active immunity highlighted by Trustworthy 3.0 is truly achieved.
The role of the Monitoring and Defense component and the Log Monitoring component is in the Trusted Security Management Center of the Trusted 3.0 Active Immunity Triple Protection Active Defense Framework. The main functions of the monitoring and defense component are the services and registration of distributed applications, access control, trusted behavior assessment, identification and recording, and early warning and feedback on untrusted behavior. In distributed applications, the log information generated by each node and method is managed and analyzed by the log collection center. For suspicious or untrusted software behavior, the Monitoring and Defense Center will display its corresponding behavior log to the monitoring user terminal, and the responsible personnel will promptly repair the system.
Log collection main attribute table
Based on the active protection triple defense active defense framework, this paper will conduct in-depth research on the trusted computing environment module. This paper will discuss the detailed design of trusted computing environment module based on distributed application, and propose a trusted evaluation and active defense model combining trusted 3.0 and distributed environment. The specific model is shown below.
Analysis and design
A. Problems with log collection in a distributed environment
In a distributed environment, each computer is equivalent to a compute node. The relationship between distributed application services and computing nodes is generally a one-to-one relationship, that is, only one application service is deployed on one computing node. For core services with large traffic, the common method in the industry is to deploy the same application service to multiple nodes, register the deployment information to the service center, and configure a customized routing policy in the service center. Make concurrent access.
Based on the deployment characteristics of distributed applications, the solution adopted in this paper is a global ID method to record the logs of the complete call link. When the request initiates a call, the process responsible for processing the request generates a global call ID and saves it to the log and saves the log to the distributed cache. If there is a service access across the node in the subsequent operation, because the call is in a process, the PID of the process will not change. According to the PID of the process, the corresponding log ID is found in the cache, and the corresponding call information can be obtained. Append to the same log. The advantage of this is that the complete call link of a service can be recorded in a log record, which overcomes the difficulty of collecting cross-node logs in a distributed environment and lays a foundation for subsequent trusted behavior analysis.
B. Log collection content and forma t
The log data records information such as the use of system resources and method calls by the operating system and user programs. Based on the log data, it is easy to determine whether the system meets the expected performance requirements and foreseeable system bottlenecks. From the perspective of trusted computing, log data records a large number of actual running traces of calls, transactions, I/O, and exceptions during application running, so log data also provides an objective basis for analyzing application behavior.
Based on the idea of Trusted 3.0 for application monitoring and active defense, the log record model proposed in this paper contains the main contents of call information, resource indicators and system indicators. Based on these three aspects of information, it is relatively easy to judge credible behavior, suspicious behavior and untrustworthy behavior, and also provide an important basis for the active defense system. The specific record content and corresponding description are as follows:
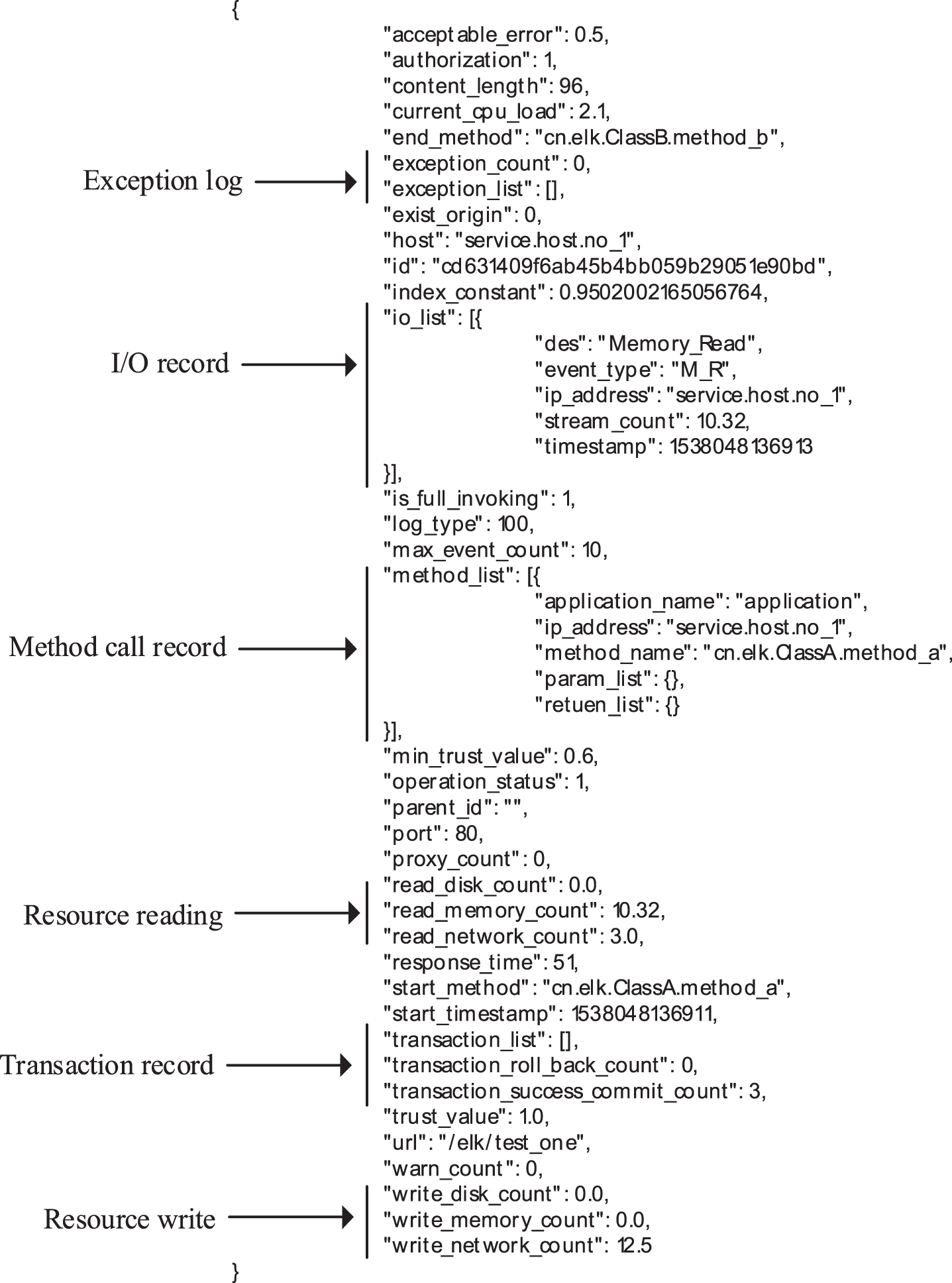
JSON log format example.
In order to facilitate the collection, storage, retrieval, analysis and visualization of log data, this paper defines the log data as the format of the JSON string. Put the generated log string into the cache for later processing. The generated log string is as shown below:
C. Standard sample set generation and determination of confidence intervals
Before the official online deployment of application services, an important task is to generate a standard set of log samples for each method call. In addition, another important task is to obtain fluctuations in data I/O and response time through a large number of simulation runs.
The acquisition of the standard log sample set is relatively simple. The developer manually initiates a request, and the application uses the logging method that will be discussed in the next section during the execution process to collect a complete log record of the service. Check if the call is complete after the collection is complete. In the case of a full call, if the existence of the transaction is satisfied and all successful commits, no timeout error occurs, no non-disruptive exceptions and warnings, this article considers that the call information of the sample is accurate and reliable. For the next step, we should determine the credible fluctuation range of the inspection data such as I/O and response time.
In an ideal situation, the resource metrics, system metrics, and call information consumed by the same application service should be the same each time. However, due to the relatively complicated situation of the actual online environment, the size of the result returned to the client is different for each request. Therefore, it is necessary to determine the confidence interval of the fluctuation data. Based on a large number of literature references and research, this paper will use the Gaussian distribution model to determine the confidence interval. First, multiple concurrent operations have been determined to call the service of the link, and the obtained logs are collected and recorded. Taking the memory read amount as an example, the collected log record is read and the memory read data amount field is parsed. Finally, based on the total memory read data field, calculate the variance σ2 and the mathematical expectation μ. This paper considers that the monitoring data of the memory read data is a compliant Gaussian distribution obeying X ∼ N (σ2, μ). For the obtained Gaussian distribution probability density function, the inverse function can be obtained:
Substitute the probability of the occurrence of our custom trusted data, and solve for τ1, τ2. Therefore, this paper define the confidence interval of the volatility data as [τ1, τ2]. The calculated confidence interval and sample data will be stored in the Monitoring and Defense Center to provide a credible criterion for the software behavior generated by the real online environment.
JSON log format example.
Log data verification entry table
In addition, in the case of logs with suspicious events, this paper will use the exponential decrement method to make the number of suspicious events affect the trusted analysis value of the log. This paper asked the monitor to set two parameters that would accept the number of suspicious events (α) and the minimum acceptable confidence value (δ). Then use the following formula to calculate the constant value (ω) of the exponential function. And stored in the exponential decrement constant field.
There are two main methods of log collection used in this paper, namely Aspect Oriented Programming(AOP) weaving method and buried point reporting method.
In the existing log collection strategy, the collection application is generally monitored through the AOP entry point. In AOP, a pointcut is a collection of join points, which are a set of predefined program execution points. In the field of AOP-based log monitoring and collection, monitoring and collection operations are generally defined as the actions of entering and exiting the connection point. During the running of the program, when the log collection and monitoring code is woven into the actual program, a mapping between the nature symbol and the program running event needs to be established. In the process of establishing this mapping, the event selection expression is generally used to represent the event set in the running of the program, which is implemented in the AOP entry point [10]. Therefore, in this paper, the entry point is defined for the start and end of each method, and most of the log content can be collected.
For more fine-grained behavior log collection and monitoring, such as: I / O data volume, transactions, exceptions and warnings, etc., using AOP weaving method cannot be flexibly acquired. Therefore, for these monitoring data items that cannot be woven with AOP, this paper will adopt the strategy of burying points collection. Manually invoke the logging method at the location where the operation data needs to be monitored, and create it according to the predefined buried point attribute. After the method execution is completed, the aggregated log operation is performed, and the generated log record is added to the overall call of the service according to the process PID. Among the logs [11].
In summary, this paper will use AOP weaving and buried point collection to jointly generate a complete application service call log.
Log data preprocessing
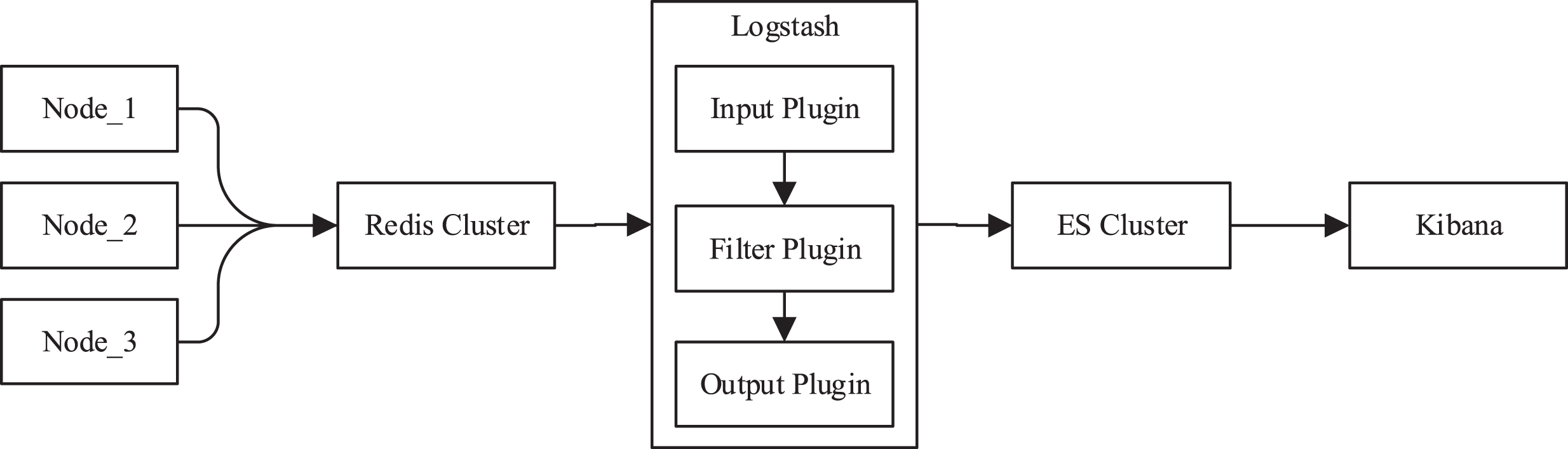
In this paper, I will use the ELK enterprise-level log platform to collect, store and visualize log data. ELK stack is a data processing tool chain based on distributed search engine Elasticsearch (ES), log collection and analysis tool Logstash, and analysis visualization interface Kibana. In real-time data retrieval and analysis, the three are usually coordinated. Use, to provide a one-stop solution for rapid data response, retrieval, and visualization in the era of big data [12]. Specific to this paper, it will adopt the ELK architecture design as shown below:
In the architecture, the log data generated by the application running on each node will be uniformly written into the Redis cache cluster for temporary processing. The log data that has not been added after each log data is added or exceeded will be processed in the following process for preprocessing. After the processing is completed, the application will post the processed log data to the corresponding Key in the Redis cluster through the publish/subscribe mechanism provided by Redis. Since Logstash needs to configure the subscribed key before starting, Logstash will automatically receive the push data of the key. Log data is collected and analyzed by Logstash. Finally, the ES will be output and saved and indexed. At this point, the data collection work is completed.
A. Verification of log data
In order to improve the accuracy and efficiency of subsequent software behavior trust analysis, this paper believes that the log data needs to be filtered before doing log analysis. Filtering generally refers to the removal of invalid or apparently erroneous data. The specific filter conditions are shown in the following table:
B. Log data flattening and statistic s
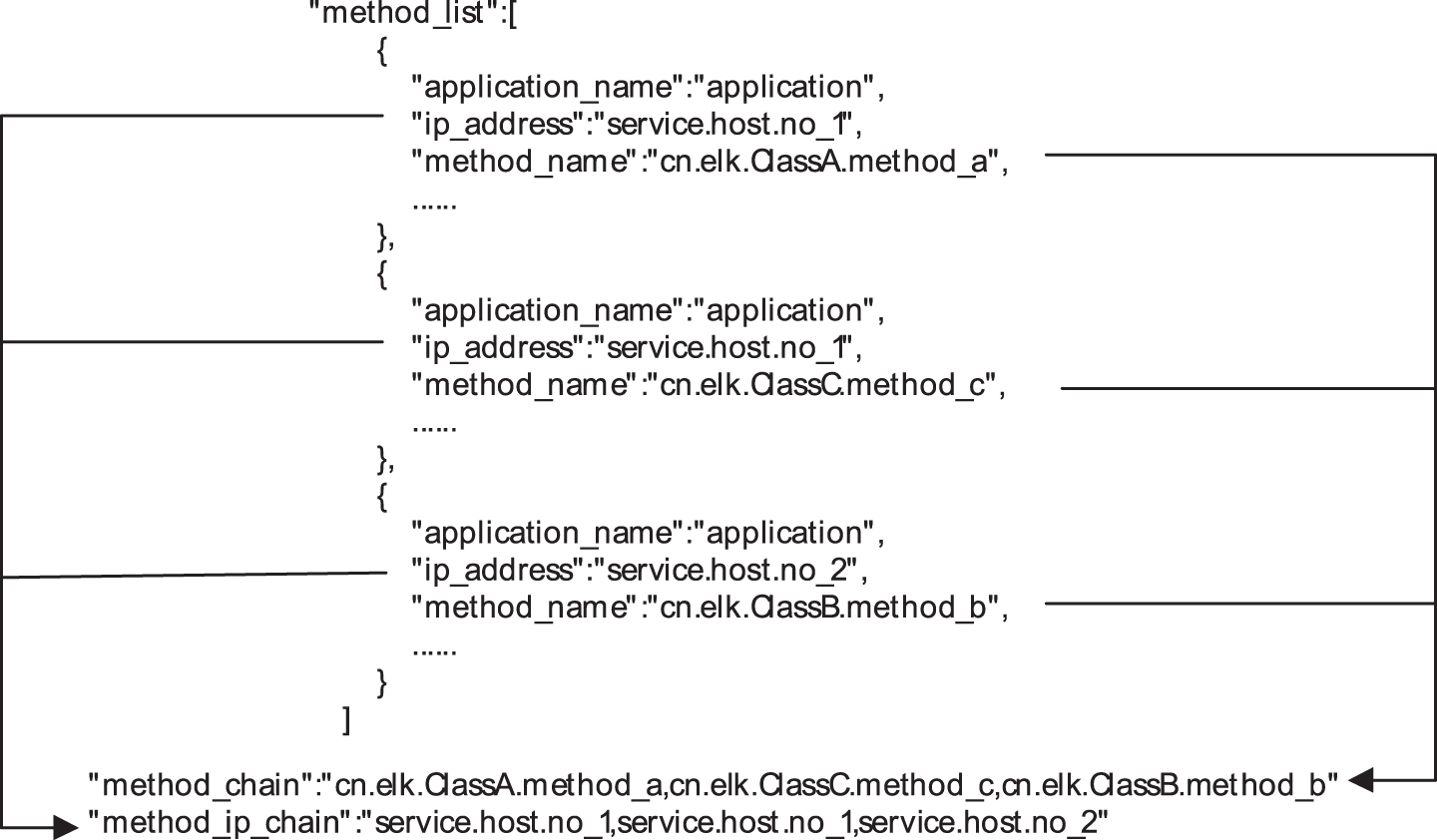
JSON flattening schematic.
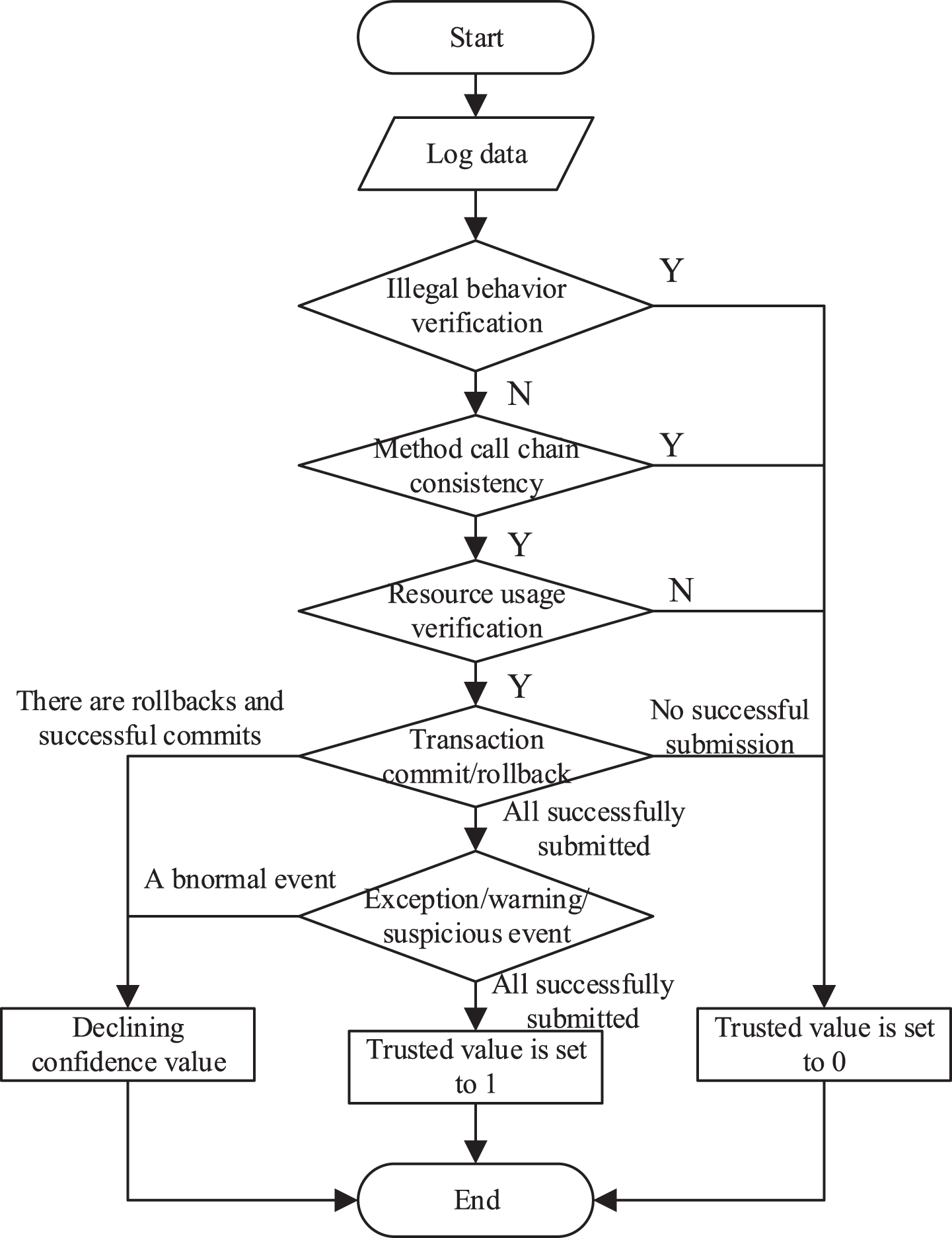
Trusted behavior assessment process.
After the log data is collected and verified, the final data is valid data, which can be further processed. Before submitting to the ELK stack via publish/subscribe mode, this paper need to take a closer look at flattening and statistically processing the detailed version of the log to form a standard version. The purpose and necessity of this is mainly based on the following points: First, the consistent log format is conducive to ES storage and index maintenance work, improving performance. Second, flattening and statistical processing facilitate subsequent analysis and comparison of log data. Third, the standard log format facilitates the graphical display of Kibana components. The process of flattening is as follows:
The process of flattening the log is relatively simple. The main purpose is to split and combine the set data in the JSON string to form one or more JSON fields. For example, the method calls the link. The detailed version of the log is recorded in the order of the sequence table and the entity class. In the standard version, I split it into two string fields: the method name string and the IP address string. The statistical work of the log means that the accumulation operation is performed according to the amount of data generated by the event type, and finally stored in the corresponding total data item field. For example, write to the disk operation, find all the write disk events in the event sequence table, accumulate the write amount, and the result is stored in the total disk write amount field.
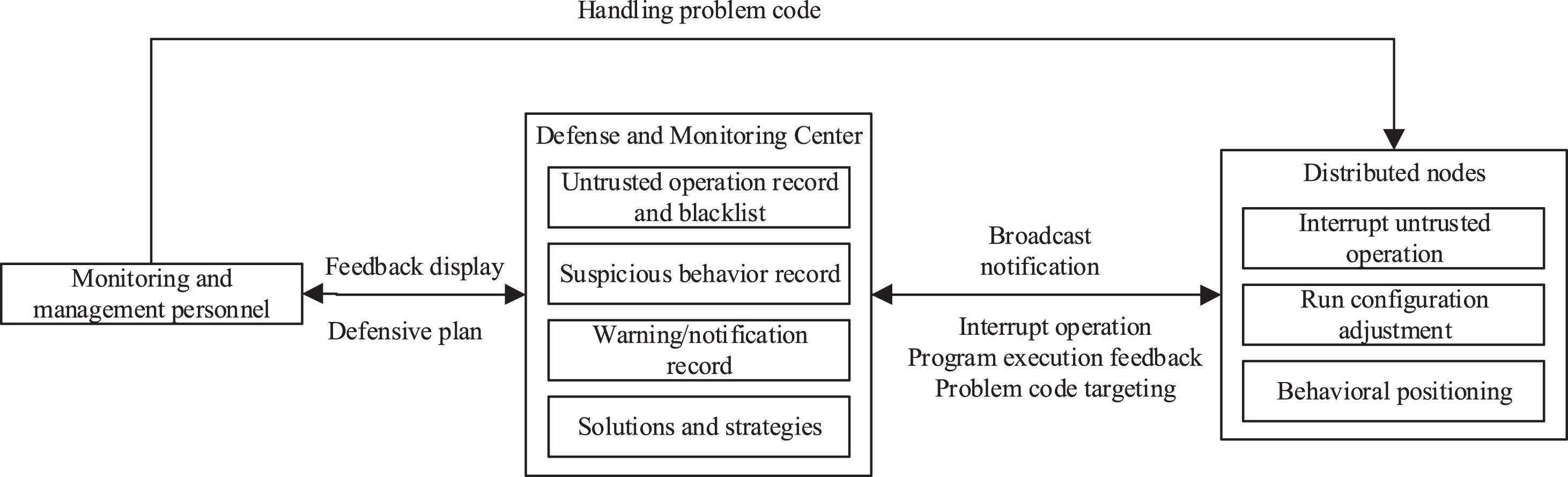
Active defense process diagram.

Log submission record.
Real-time log analysis and monitoring.
According to the log collection and processing method studied in the previous article, this paper can obtain the log data set generated by the standard effective real environment. The following article will need to analyze the trusted values of these data sets one by one, and finally put them together and display them in real time through the Kibana component. In addition, this paper will extract logs that are not trusted or have very low credibility values, providing a basis for manual location problems. The specific process is shown in the following figure:
In the process of log-by-item evaluation, this paper first obtain the sample data of the call from the monitoring and defense center, and then start the evaluation according to the flow of the above figure. As shown in the figure, this paper first verify the network behavior of the call. If the information of the cross-domain call and the proxy call is inconsistent with the sample data, the trusted value is directly set to 0 and terminated. In the second and third steps, this paper will compare the method call link and resource usage with the sample data. If the method call link is inconsistent or the resource usage exceeds the trusted range, it set the trusted value. Is 0. In the fourth step, the trusted evaluation for transaction submission is mainly divided into three cases. In the case of all successful submissions and unsuccessful transactions, this paper set the trusted values to 1 and 0 respectively. In the final step, it need to record the number of times and have an impact on the trusted value for situations where there is an exception warning or an event or a transaction rollback. According to the above, the exponential constant item field in the sample log field is taken out, and the value thereof can be calculated as the base number, and the value is the trusted value of the suspicious event.
Defense mechanism
Based on the idea of trusted 3.0 center separation and active immunity, this paper will discuss the active defense mechanism based on the trusted values analyzed in the previous chapters. The specific architecture diagram is as follows:
According to the previous article, this paper can identify software behaviors with certain risks. As shown in the figure above, the Defense and Monitoring Center first needs to record the blacklist when it recognizes untrustworthy behavior. Second, the Monitoring and Defense Center sends broadcasts to other nodes in the distributed environment to notify untrusted services and providers. Finally, access to the untrusted method of the problem node is circumvented in the routing rules of the monitoring center. After manually checking and resolving the untrustworthy factors, the service of the problem node is replied.
Experimental design and analysis
Experimental environment
The specific experimental environment of this paper is JDK1.8 and CentOS operating system. The Java environment provides logical analysis processing, and CentOS provides a basic environment for the ELK architecture to provide massive data storage and query services.
The main process of this experiment is mainly to collect logs by burying points among various application nodes, and then use Java code for processing according to the log processing and analysis methods described above, and then output to the ELK architecture system. The final result is that the behavior of the node can be displayed in real time on the Kibana page.
Experimental result
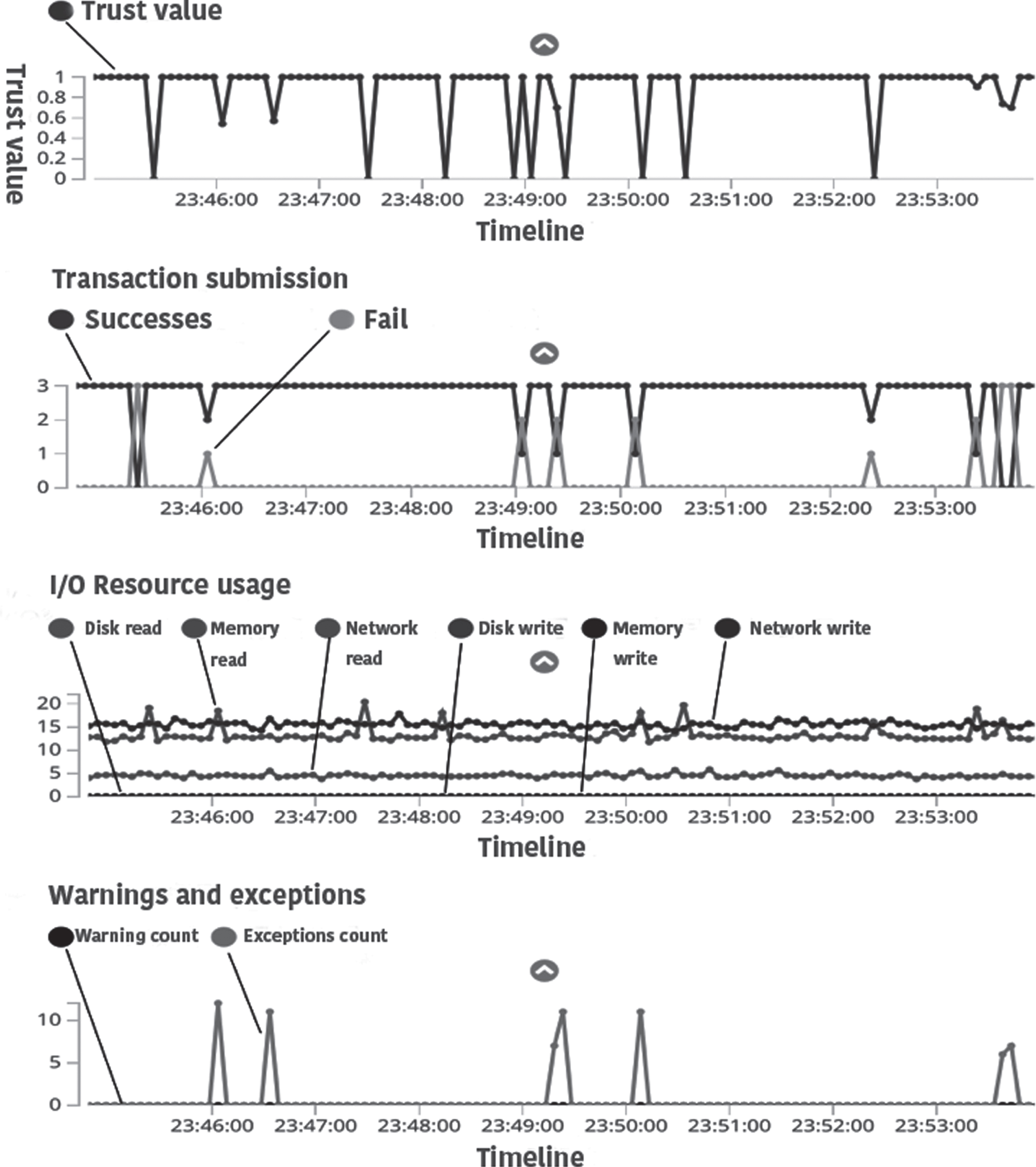
In this paper, the log collection line is submitted to the Java logic analysis end. After the entire analysis process is completed, the log data can be submitted to the ELK log platform. The Kibana component will generate real-time images based on the custom of the monitor. as follows:
The image shows the quantity map submitted per second of the log, which can visually observe the QPS (number of services/sec) change of the service application. To lay the foundation for further research on the reliable identification of QPS and software behavior.
The above figure shows the data monitoring graph after log analysis. From top to bottom, it is trusted value change, transaction commit situation, I/O resource usage, warnings and exceptions, and monitoring timetable map of corresponding time. From the figure it can clearly see that when there are obvious fluctuations in the transaction, I/O resources and abnormal warning light factors, they can all be projected to a certain level of change in the credible value. Therefore, this paper can also identify untrustworthy behavior based on fluctuations in the value of the credible value.
Conclusions
This paper conducts an in-depth study on the trusted behavior recognition process of distributed nodes, and finally forms a trusted behavior recognition model for distributed nodes. Compared with the traditional software behavior recognition model, the model breaks through the limitation of single machine, which is more in line with the needs of today’s distributed environment, and also provides a new idea for the trusted research of distributed environment. The limitation of this paper is that it only monitors the predictable resources, but does not find a reasonable research plan for unpredictable behaviors such as uploading and downloading. In addition, the way in which the confidence interval is determined in this paper is only a qualitative determination scheme, which is not flexible and scientific. In the future research, this paper believes that it will combine the relevant knowledge of artificial intelligence to find more scientific solutions to the above limitations.
Footnotes
Acknowledgments
Thanks to Associate Professor Yu for her guidance on this paper.
Thanks to the National Key R&D Program (2017YFF0211801) for funding this paper.