
Abstract
Question-and-answering (Q&A) sites are information systems that allow users to ask and answer questions. Users can learn by frequently discussing, answering questions, or exchanging opinions with other experts using Q&A systems. In addition, they can arrange the existing top answers using a number of upvotes and downvotes from experts and crowd wisdom. The number of knowledge-sharing sites has increased significantly in recent years. However, some Q&A sites began to shrink (Yahoo Answers) or were shut down (Google Answers). The main reason is low-quality answers because they do not connect visitors and experts with the right questions. In addition, a question may contain several subtopics with which the expert is unfamiliar. The recommendation of a list of experts closest to the question will lead to a long-tail problem. In this paper, we propose an expert group recommendation method for Q&A systems by taking into consideration users’ behaviors and diversity criteria in the group. Users’ behavior is analyzed to determine a group of experts or non-experts on specific topics. Diversity is an important factor in promoting the sustained comprehensible growth of Q&A sites and avoid following the crowd. Experiments on a Quora dataset show that our method achieves better results in terms of accuracy in comparison with other methods.
Introduction
Today, owing to the rapid increase in use of the Internet, the amount of available information is growing significantly. It is difficult for users to find information to solve some common problems in the real world because of information overload. Some raw information is not accessible on the Internet, or it can be time-consuming for users to find, learn and aggregate related information from other resources. In this case, people can use question-and-answer (Q&A) sites and post questions to experts who provide the right answers. Q&A sites have been developed more and more quickly in recent years. Users can ask questions, obtain answers, befriend experts, and follow topics in which they are interested. Many Q&A platforms such as Quora 1 , Yahoo Answers 2 , Google Answers 3 , and Stack Overflow 4 have been developed. However, some of them had limitations and began to shrink (Yahoo Answers) or were shut down (Google Answers). There are three principal reasons: (i) The majority of users are not enthusiastic to answer questions or are not able to answer questions. (ii) Users are willing to answer questions, but they do not recognize new questions related to their expertise. (iii) Once the Q&A sites are developed, a large number of low-value questions flood the system. This is difficult for users to find interesting or helpful information [18].
Unlike other Q&A systems, Quora is growing. The primary difference between Quora and other Q&A sites is the way users can connect with others to create their networks. While users on other Q&A sites use a global network, Quora permits users to follow each other to generate a social network. A relationship between users on Quora is not necessarily bi-directional. A user can befriend experts, but the following actions might not be reciprocated. A user u can follow user v without express permission from v. The activities of v such as new comments, answers, questions, or topics will show in u′s homepage. We say that u is a follower of v, and v is u′s follower. In addition, users can follow the topics that they interested in, and obtain the update information about the questions and answers on the topics.
Quora users have profiles that reveal their personal information and activities such as past questions and answers, followed topics, and social relationships (follower and following). The best answer is not the questioner’s choice but is determined by the community through voting and criteria for evaluation so that the process becomes more objective [5]. Only accepted majority responses can be placed ahead. Poor quality rests, and may even be crushed by the system. Moreover, each user has a “Top Stories” page that shows recent activities and shared questions from followers, as well as new questions on the topics that they followed [25]. Finally, a Quora question has its own page that combines a list of related questions and a list of answers. Users also can comment, edit, and vote on existing answers or write new answers. As of April 2017, Quora announced that it possessed 190 million monthly unique visitors, up from 100 million a year earlier. Owing to the large datasets, it’s difficult for users, especially new users, to find experts who can give the right answers to their questions. Fortunately, a recommender system can help solve this problem.
Recommender systems aim at providing a list of suggestions to a target user via content-based or collaborative-based filtering [19]. Content-based filtering uses the features and the user’s historical activities while collaborative-based filtering generates a model to suggest the items that the target user may. In some cases, the hybrid method that is a combination of collaborative filtering and content-based filtering might be useful. Developing a recommender system to suggest experts answer new questions is essential because it addresses the issue of low-participation rates and also provides high-quality answers [12, 28].
Some recommender systems have been proposed to find experts on Q&A sites [8, 29]. Recent works for finding experts can be classified into two kinds of approaches. The first approach was seeking suitable answers to a new question [5]. The contributions of users to those answers was computed and ranked to find a list of experts [18]. This approach is limited to addressing the context and fails to take advantage of user preferences. In particular, new users, who do not have the experience to ask questions, will lead to misleading results.
The second approach aimed at building a profile of each user used the activities and past answers of the user. The content similarity between the user’s profile and the new question was computed and ranked to find experts. This approach is familiar and productive [4]. Nevertheless, many questions contain several subtopics that are not familiar to an expert. Existing approaches try to suggest the most suitable expert for the given question. This leads to the most of highly recommended experts with the same expertise, and they will not satisfy other subtopics in the given question. Assume that a question has a 60% probability of belonging to the Computer Science topic, a 30% probability of belonging to the Health and Medicine topic, and a 10% probability of belonging to other topics. In this case, current methods will recommend a list of experts, most of whom are computer science experts, and the list will lack answers from Health and Medicine experts. Current methods will provide a list of experts who have expertise in “Computer Science.” Therefore, the system will ignore experts who are very well in Health and Medicine and other topics. This may lead to low accuracy development of the systems. In addition, we need to know that the main goal of Q&A sites is to create new knowledge rather than search or organize knowledge already available as Google. In order to overcome the weaknesses of previous works, we develop a system to recommend expert groups that have the diversity of expertise to answer a new question. We will try to show that the diversity of expertise is essential to ensure the development of the system. Fortunately, research on Inconsistent Knowledge Management [14] had demonstrated that “the intelligence of the crowd is better than the smartest.” This means that a combination of expert groups provides better answers than only single expert.
Surowiecki [23] pointed out that the individuals should use their own information, do not know what the others have responded, and answer independently, without social impact from others. If they know each other and can understand or follow the previous answers of others, they may shift into the background where they follow the crowd owing to social influence to agree. They may also experience the information waterfall effect, and there will be no reason to expect average opinion as well. Nguyen et al. [15] proved that using heterogeneous collections requiring different members is an effective way to obtain the collections accurately. Diversity can be known as a variety of personal knowledge or backgrounds to solve a particular problem and is one of the essential criteria in collective intelligence [14]. In particular, diversity rules play an essential role in the system of decision-making in an expert group [11]. A lack of diversity may seem a potential conflict of interest and brings about a situation in which experts start neglecting their expertise and watching the crowd due to the social influence to follow or because of the information waterfall effect.
This study is a revised and expanded version of our conference paper [9]. In the conference paper, we extracted the features and used machine learning to classify an expert or a non-expert. However, for each topic, the features are the difference; thus, the accuracy of the expert detection is lower than this proposed method. In addition, we considered the diversity of the system based on the mutual following of users without calculating the social impact between them. The contribution of this paper can be summarized as follows: To the best of our knowledge, we are the first to study diversity in Q&A systems. We prove that diversity is an important factor in the expert group recommendation method. A data collection module is built to collect data from a Q&A site and create user’s profiles. Feature extractions are implemented to classify experts. A topic-modelling module is built to determine the topics of the questions and match them to experts. A social graph is created to find expert groups by taking into account the diversity criteria and the social impact of expert members.
In order to avoid regarding the crowd and reduce potential social impacts between group members, we require that the members of the group not only match the skill requirements to answer the question but also be diverse. The main goal of our system is to create new knowledge by experts rather than looking for existing knowledge. Hence, diversity is more necessary in the creation of new knowledge. It is a vital factor in promoting the development of Q&A sites.
The rest of this paper is organized as follows. In Section 2, we shortly summarize the related work of expert findings on Q&A systems. In the next section, details of the proposed method are shown. In Section 4, we describe experimental results and evaluations of the system. Finally, conclusions and future work are presented in Section 5.
Related work
In recent years, Q&A sites have successfully grown as sizeable knowledge containers, each directed by a large number of questions and answers not only from user communities but also from experts. Despite their success, however, some of the sites have been restricted (Yahoo Answers) or have been shut down (Google Answers). The main reason is that the data of Q&A systems grow so fast that it is difficult to find the most suitable expert to answer a given question. Our goal is to reduce waiting times while increasing the quality of answers. Recommender systems are the core to solving this problem. The problem of selecting an expert to answer a given question has considerable attention in recent years. The current work for finding an expert on a Q&A system can be classified into two groups: the first is based on the user activity approach, and the second is based on the topic-modeling approach [18]. The user activity approach for finding experts is based on examining the question-answer connection between users in a rating matrix. A personalized learning-to-rank algorithm is employed to recommend experts to the target user. The topic-modeling approach for finding experts has modeled the content of the questions by using the topic-modeling methods [18, 27].
First, with the user activity approach, there exist several works. Song et al. [22] found leading users in professional Q&A services by considering three criteria: authority, activity, and influence. The authority of a user was computed by using the number of questions and answers that the target user had viewed in the past. The activity of a user was based on the level of frequency of the user on the Q&A site. The influence of the user was computed by calculating the ratio between the number of followers and those being followed. GunWoo et al. [8] introduced the InfluenceRank algorithm to suggest reliable experts to answer a given question on a Q&A site. The InfluenceRank algorithm was based on users’ communication on Q&A sites. Trust and activity were considered as main agents to measure the influence of users. Zhao et al. [29] introduced a technique to find experts for a new user by considering the “following relations.” Topical interests and the relationships between users were investigated to generate a user-to-user graph. The experimental results on Quora proved that this method achieved good performance in solving the cold-start problem. Patil and Lee [16] developed a system to identify experts on Quora following three steps. First, users’ profiles from Quora were collected to examine the attributes of experts and non-experts. Second, the user’s behaviors were analyzed to quality the answer features. Then, statistical models were created based on the proposed features to discover experts on a particular topic and familiar topics. In addition, the authors studied extracted features from users who had a Twitter account. Another approach applying the deep neural network to Q&A communities was introduced by Azzam et al. [2]. They developed a question routing system named QR-DSSM in which the textual features were extracted to measure semantic similarities between the posted question and the users’ profiles. Second, in the topic modeling approach, Ji et al. [10] proposed a question-answer topic model to detect the latent topics arranged across the question-answer pairs to relieve the lexical gap problem. They assumed that a question and its paired answer shared the same topic distribution. Yang and Amatriain [28] studied various recommendation problems on Quora such as recommended related questions, digest answers, and home feed. They also revealed their methods were working on these recommendation problems with various machine learning models such as ask-to-answer (A2A) and personalized learning-to-rank. Zolaktaf et al. [31] proposed a statistical topic model for modeling Q&A systems. The model explicitly caught relationships between questions and their answers by modeling topical dependencies. They compared the model with the latent Dirichlet allocation (LDA) model, and the results showed that the model obtained better performance in retrieving the correct answer for a query question. Most current methods tend to find a list of experts who are most fit to write correct answers to a new given question [8, 22]. The problems that previous studies addressed can be summarized as follows: Given a new question Q, we need to find a ranked list of experts e1, e2, e
n
who are best suited to answer Q. The probability of an expert e
i
who answers question Q is:
Nevertheless, in some cases, a question contains several subtopics that are not within the areas of an expert. Previous approaches favor recommending a list of suitable experts for the given question. This drives to a list of experts with the same expertise will be highly recommended, and they will not satisfy other subtopics in a given question. These situations are known as the long-tail and overfitting problems in the recommendation.
Fortunately, Surowiecki [23] pointed out that “under the right circumstances, groups are remarkably intelligent, and are often smarter than the smartest people in them.” This proved that a combination of expert groups provides better answers in comparison with a single expert. In order to avoid long-tail and overfitting problems, we need to consider the diversity of the group. Kunaver et al. [11] proved that diversity had become one of the leading topics of recommender system research. Diversity is not only a way to resolve the overfitting problem but also an approach to improving the quality of the user’s experience in recommender systems [17].
Nguyen et al. [15] investigated the impact of diversity on the quality of collective prediction. They considered some adjustments in a collective to execute it become more consistent. Simulation experiments revealed that diversity led to a better collective prediction. That is, the more diverse the collective, the better the collective prediction. Inspired by these studies, we propose a group expert recommendation method that can combine experts with each other to provide the best solution [5]. Furthermore, we also examine the diversity of the group members to avoid following the crowd and gain knowledge.
In this section, we present the method to develop a recommender system for finding group experts to answer a new question. The workflow of the expert group recommendation method is shown in Figure 1. Our proposed method consists of two main algorithms: expert detection and expert group selection. The following subsections present the details of the proposed method.
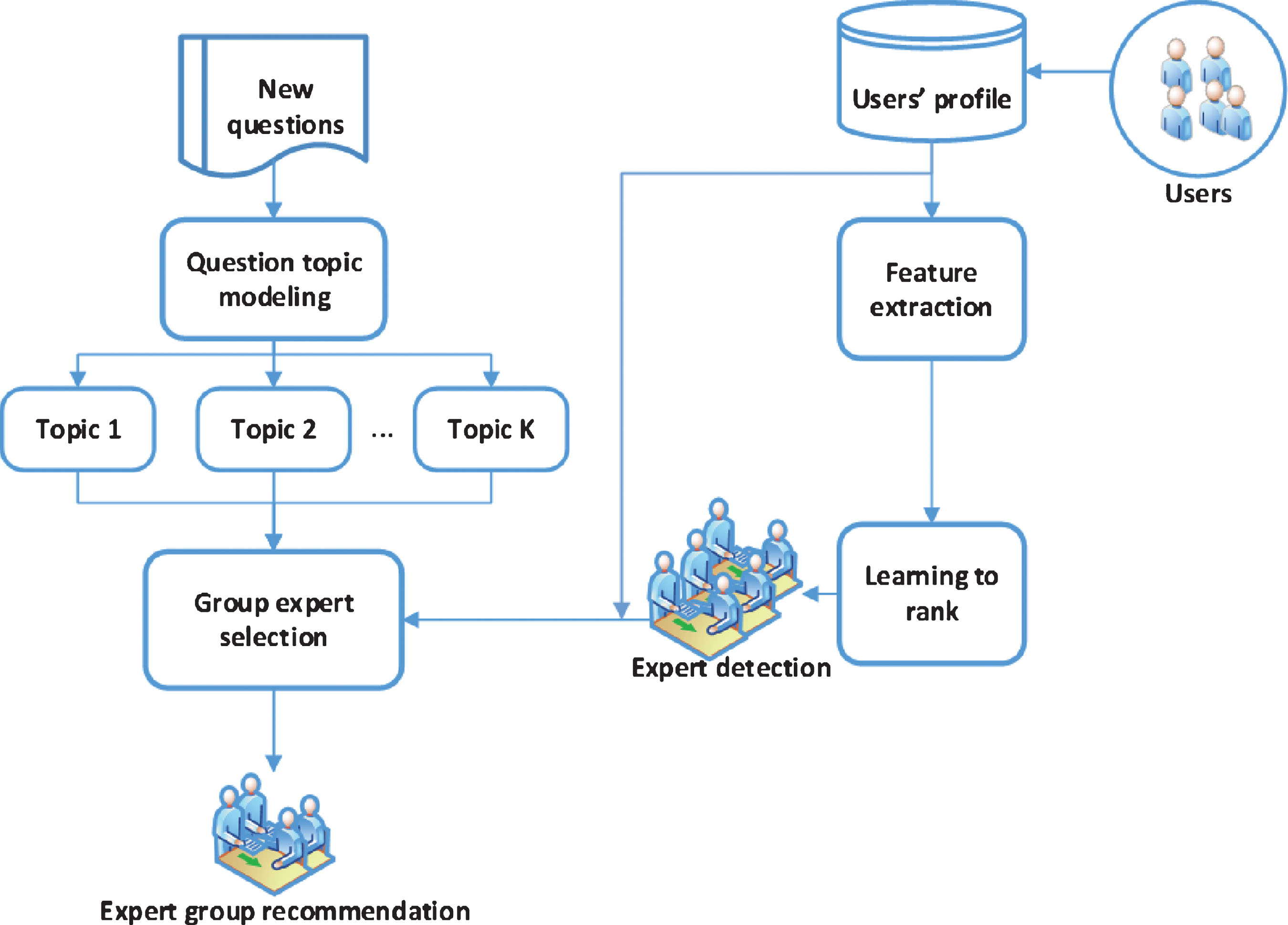
Workflow of group expert recommendation method.
The problem is divided into two small issues: (i) given that the expert in the particular topic will provide a right answer, we need to distinguish who is the expert on each the specific topic. (ii) We need to choose the best expert group to answer a new question. Let U = {u1, u2, . . . , u q } be a set of users that are collected from Q&A sites. Let T = {t1, t2, . . . , t m } be a set of m predefined topics. For each topic t i ∈ T we need to find N users who are experts, by considering the popularity, the activity and the expertise. Assume that E = {e1, e2, . . . , e n } is a set of candidates consisting of n experts who might answer a given question Q. Each expert e i has a connection to a set of topics T i , so that T i ⊆ T. Expert e i has expertise t j if and only if t j ∈ T i . Let T Q , be a set of topics that is determined from given question Q, (T Q ⊆ T) by using topic modeling method. For each t j ∈ T Q , we have a set of experts E t j = {e i |e i ∈ E ∧ t j ∈ T i }. Assume that K topics are determined from question Q, we have K sets of experts, E K = {E t 1 , E t 2 , . . . , E t K }. Let C (E K , T Q ) be the cover of a group of experts E K , with respect to T Q topics. That is, C (E K , T Q ) = T ∩ (⋃ e i ∈E K T i ). Let S (e i , e j ) be the value of social impact between experts e i and e j . Since given a question Q has K topics, we try to find a group of experts E Q ⊆ E K , where C (E K , T Q ) = T Q ; social impact of S (E Q ) is the minimum value.
Expert detection
In this subsection, an expert detection methodology is introduced by taking into account the user profiles and behavior to classify a user is an expert or a non-expert. Some previous works used learning machines to find experts by extracting features such as the number of questions, answers, and followers [18, 30]. However, with different topics, the numbers of people are different. For example, politicians will often be followed more than a pure scientist will, or a hot topic will have more questions or answers. Therefore, we extract features for each topic and use the learning-to-rank approach for detecting experts. The workflow of the expert detection module is shown in Figure 2. Inspired by that fact the user behavior can reflect their knowledge contribution in social Q&A communities [7], we consider three important factors: popularity, activity, and expertise. First, on Q&A, when a user is popular with more people follow (followers), there is a higher chance that more people will be familiar with the user’s posts. If a user’s post is good, it is more likely that other users will vote or follow. Thus, popularity is necessary. Second, the activity of a user is an essential factor that indicates the dynamics and enthusiasm of the user in the Q&A community. Third, the expertise of a user can let more and more users trust and affect many people. The detail of the expert detection method is shown in Algorithm 1. As a case study, we extract the features for expert detection on Quora that is shown in Table 1.

The workflow of the expert’s detection method.
Features used in detecting experts on Quora
In social Q&A, a user can be friend with experts, choose to follow other users’ posts and to become their follower. However, the following might not be returned. Hence, the number of expert followers is usually higher than the number of non-expert followers [16]. If users have more followers or their posts have more followers, there is a higher chance that more people will know these users’ posts. Moreover, this situation reflects their good knowledge.
The number of answers, questions, or edits can reflect how active a user is in Q&A. Usually, users who have good knowledge, are confident to write the answers, ask questions and edits their posts. Thus, the number of questions, answers, or edits of an expert more than a non-expert. This indicates that experts are users who are more active than non-experts are. Therefore, we use the number of questions, answers, and edits as features to classify between an expert and a non-expert.
The quality of answers determines the expertise of the user [24]. On a social Q&A site, the asker does not choose the best answer; rather, this is done by the community via voting operations. The higher the answer value, the higher it will be, and it will show up at the top of the relevant search query. This indicates that the expertise of a user can be used to distinguish between an expert and a non-expert.
The ranking score of user u is calculated by aggregating the popularity (u), the Activity (u) and Expertise (u) as follows:
Parameters α, β and γ are constants that control the rates of reflecting three important values to the popularity, activity, and expertise of the user, respectively, such that β + β + γ = 1. The top N users who have highest the ranking score in each topic will be considered as N experts. Here, we predefine T topics. Thus, we have T lists of N experts. As shown in Algorithm 1, the online time required for the running of the algorithm is O (|T| × |U|). The worst-case running time of Algorithm 1 is O (n2).
Given that a question can include a mix of topics. Each topic is a distribution of words. This presumption is proper for a Quora dataset because of a question can contain various topics. Some question modeling methods have been proposed, such as Term Frequency-Inverse Document Frequency (TF-IDF) [20], Latent Dirichlet Allocation (LDA) [3], and Word2Vec [13]. We predefine the topics from our dataset and try to determine the topics that a given question belong to. Therefore, the LDA algorithm is most suitable for the requirements. The expert’s profile is modeled as a mixture of topics, and a question is modeled as a vector of N w words where each w i is picked from a vocabulary of size V.
Let μ be a matrix of expert-profile probabilities for K topics selected separately from a symmetric Dirichlet θ prior. Let η be a matrix of topic probabilities for all words in the vocabulary selected from a symmetric Dirichlet η prior. Let Z be the topic assigned to word W from the μ distribution, in which W is drawn from the topic distribution corresponding to Z. The process of creating the user’s profile consist of three steps: Choose a topic K ∈ {1, . . . , K} from the μ distribution. From distributionη, pick word w
Loop the process S
w
times, in which S
w
is the total number of words in a user’s profile.
The number of topics in a question is estimated by using Gibbs sampling [6].
Diversity measurement
The diversity criterion is preferred when selecting an expert group. In order to meet the diversity criterion, we set a rule whereby the experts in the group should not follow each other. A group is considered to be diverse if its social impact is the smallest possible.
The value of S (e m , e n ) ranges from 0 to 1 and its low corresponding to the low social impact between experts e m and e n . Therefore, those experts freely express their opinions and avoiding the tendency to follow the crowd.
Group recommender systems produce suggestions in contexts where users perform in groups. The goal of this subsection is to find a group of experts to answer a given question. Let G (X G , E G , W G ) be a social graph among experts, where X G is a set of experts that represents as vertices in the graph, E G is a set of edges, considered as connections between experts, and W G is the weight of the graph that represents the social impact among experts. Since the cost of computing the social influence among experts is expensive, we choose to precompute the social influence of two experts offline and save the results to a social influence matrix M where M (e i , e j ) denotes S (e i , e j ), the social influence between e i and e j . With K topics that are determined from question Q, we have a set E K = {E t 1 , E t 2 , . . . , E t K } where each topic t i has a list of experts E t 1 respectively. The details are shown in Algorithm 2. We begin by choosing one expert of E t 1 , and then loop the selection of the subsequent expert until all topics of question Q are covered. There are many groups that meet the requirement, we choose the expert group E Q that has the smallest social impact. As shown in Algorithm 2, the online running time for the execution of the algorithm is O (|T Q | × |E K |). The worst-case running time of this algorithm is O (n2). However, the number of topics in a question is usually small; thus, the running time of the algorithm in practice is much less than the worst-case.
Experiments
In this section, we will try to show the proposed method provides better performance than other methods by considering two hypotheses:
In the next subsection, experiments are performed to prove these hypotheses.
Dataset
There are no official Quora APIs, so we developed our crawler to collect Quora datasets based on pyquora module 5 . We collect question datasets based on a dataset released by Quora that consists of over 400, 000 questions 6 . From each question, we collect the users’ profiles, which include user activity associated information such as lists of answers, the number of answers, the number of followings, and the number of followers. We remove the users who have no answers or questions. In addition, questions that have no or one answer are deleted. In total, we collect over 85, 000 users and 800, 000 answers. Then, we label the dataset to obtain the ground truth. To predefine the topics, we used the topics that were organized by Quora 7 . In order to evaluate group recommendation, we only consider the questions that contain at least two topics. We set the threshold to choose the questions. In summary, we select 2, 500 questions and ask some persons as experts to label the dataset.
Evaluation results
There are three common ways to evaluate the recommendation system: offline methods, user surveys, and live systems. Offline methods evaluate a recommender system on existing datasets, whereas live systems work in real-world domains and user surveys test the effectiveness by asking users to answer questionnaires. We chose the offline method because it is convenient and makes it easy to run experiments. First, we evaluate the expert detection stage. Second, the performance of the recommender systems is measured by using precision, recall, and F-measure values. Third, we use the Normalized Discounted Cumulative Gain (nDCG) [26] as another method to evaluate our system. For evaluation, we require the true group ratings for all experts in the topics of the question.
The confusion matrix is shown in Table 2. True positive (TP) represents the number of exactly classified experts, True negative (TN) is the number of exactly classified non-experts, False positive (FP) is the number of misclassified experts, and False negative (FN) is the number of misclassified non-experts. The values of precision, recall, accuracy, and F_measure are computed.
Confusion matrix
Confusion matrix
We evaluate the influence of the parameters α, β, and γ such that α + β + γ = 1. For objectivity, we measure the degree of influence of each parameter on the system by the average accuracy of the various values of N users such that N = [10, 15, 20, 25, 30].
First, we evaluate the influence of parameter α, which determines the rates of popularity of a user. As can be seen in Figure 3, the value of α is set between 0 and 1 and is increased by 0.1. At α = 0, only the activity and expertise of the user are considered for detecting expert. Conversely, at α = 1, only the popularity of a user is used for detecting an expert. As shown in Figure 3, the accuracy of the system is low at α = 1. This shows that considering only the popularity of a user for detecting an expert will lead to low accuracy in the system. In addition, the accuracy of the system is low at α = 0 and quite good at α = [0.2, 0.3]. This means that the popularity of a user is an important factor in determining an expert or a non-expert.
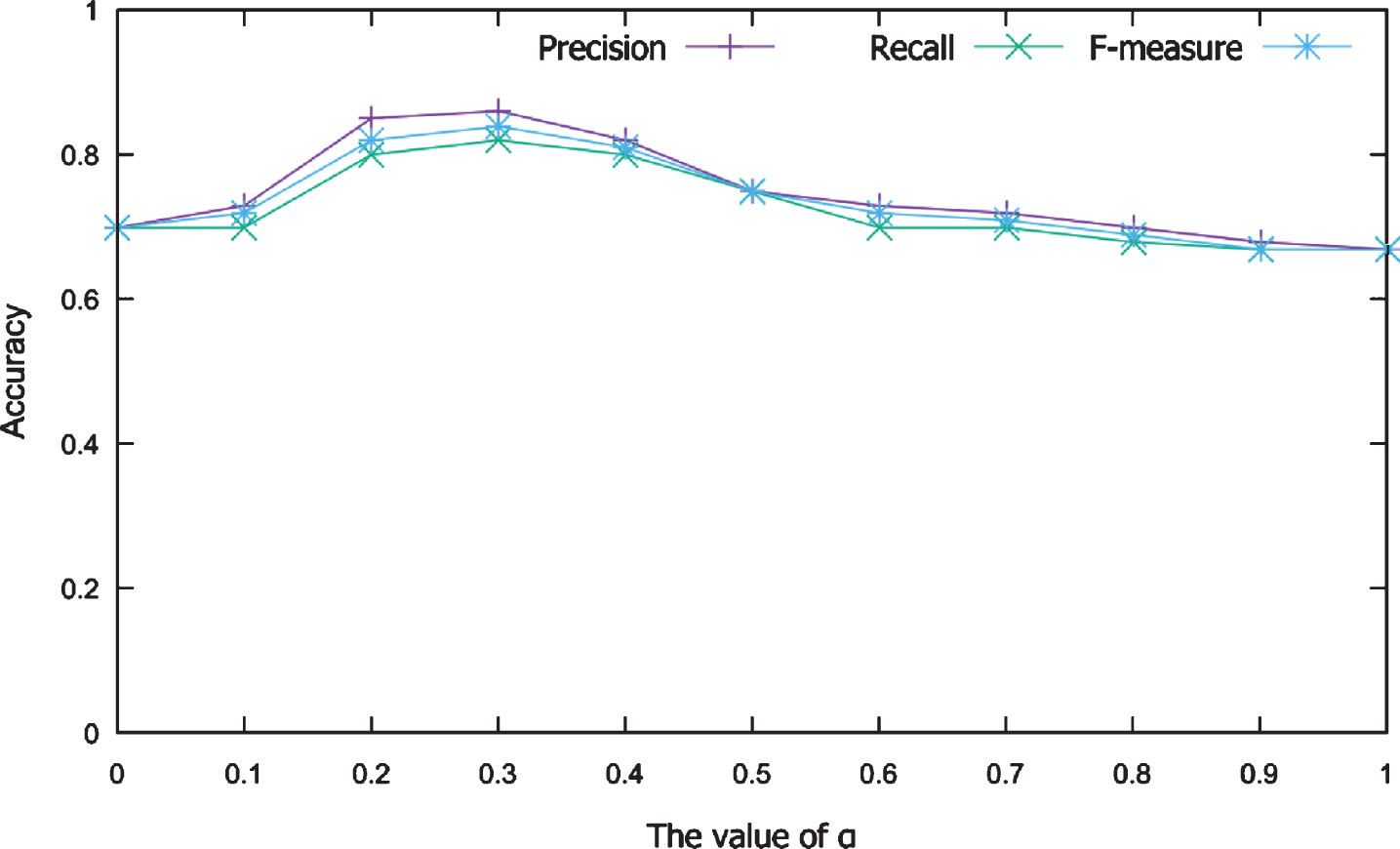
Influence of parameter α on system
Second, we analyze the influence of parameter β, which controls the rates of activity factors in the ranking score. The value for β is also set between 0 and 1 in increments of 0.1. The value of the activity factor depends on the number of questions, answers, and edits. Thus, a large β tends to identify an expert based on the user’s activity. As shown in Figure 4, the accuracy is low at β = 0. This indicates the importance of the activity factor in determining an expert or a non-expert.
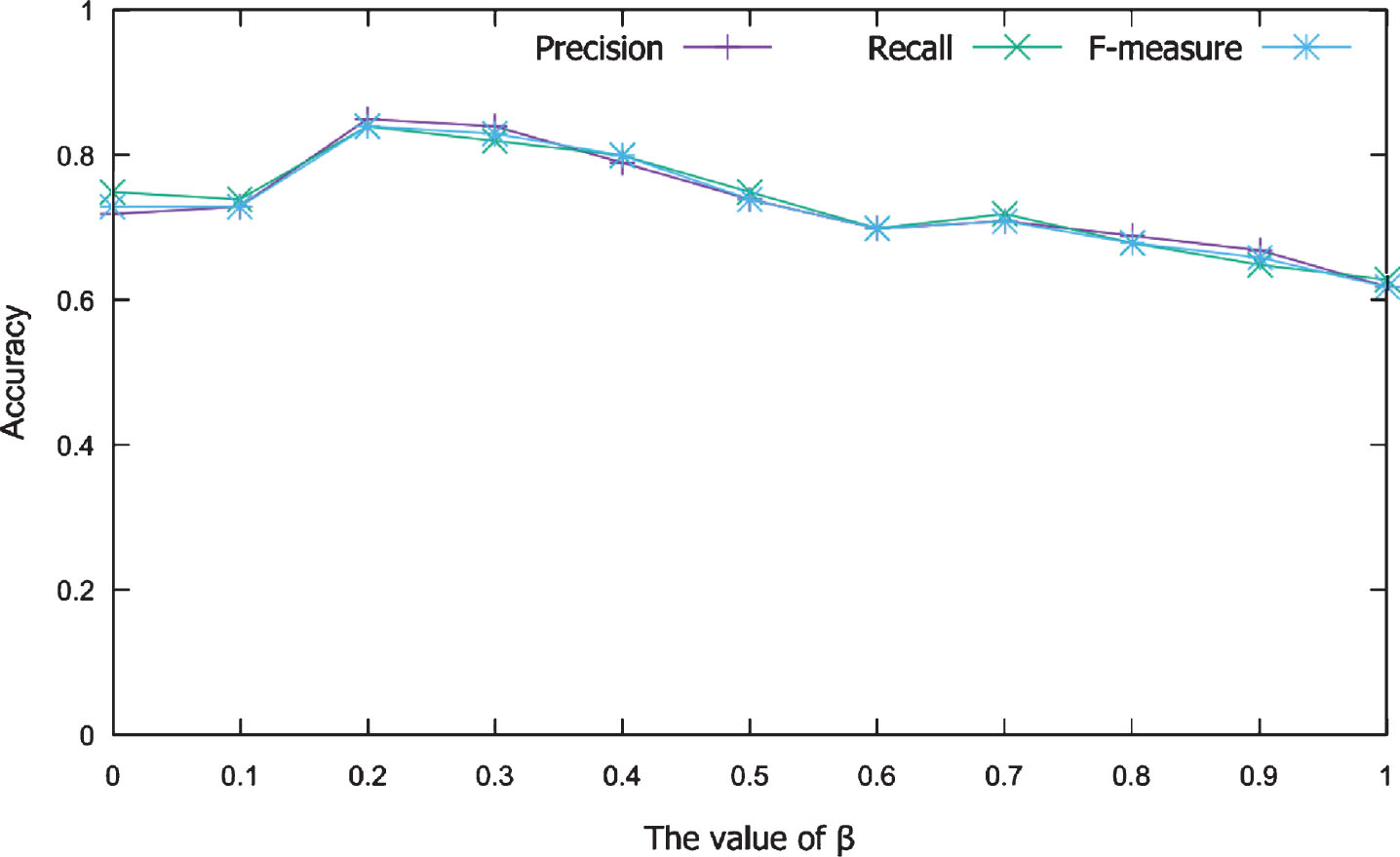
Influence of parameter β on system.
Third, we evaluate the influence of parameter γ, which represents the importance of the expertise factor in determining an expert or a non-expert. We also set the value of ? between 0 and 1 in increments of 0.1. As shown in Figure 5, the accuracy of the system is high when the value of γ is large. In particular, the accuracy of the system is low at γ = 0 and high at γ = 1. This indicates that expertise is the deciding factor in determining whether a user is an expert or a non-expert. Therefore, expertise is a more important feature than the activity and popularity features. This is understandable because, with Q&A, the quality of answers is decided by the crowd through voting. This is objective and fair. The quality of answers reflects the expertise of users in their fields. If a person with good expertise gives quality answers, he or she will be voted on and watched by other users [21]. Moreover, people with good expertise are often more confident to write more answers. However, the accuracy of the system is highest at γ = 0.5. Therefore, a combination of other factors to increase the accuracy of the system is necessary. The experimental results show the best precision at α = 0.2, β = 0.3, and γ = 0.5.
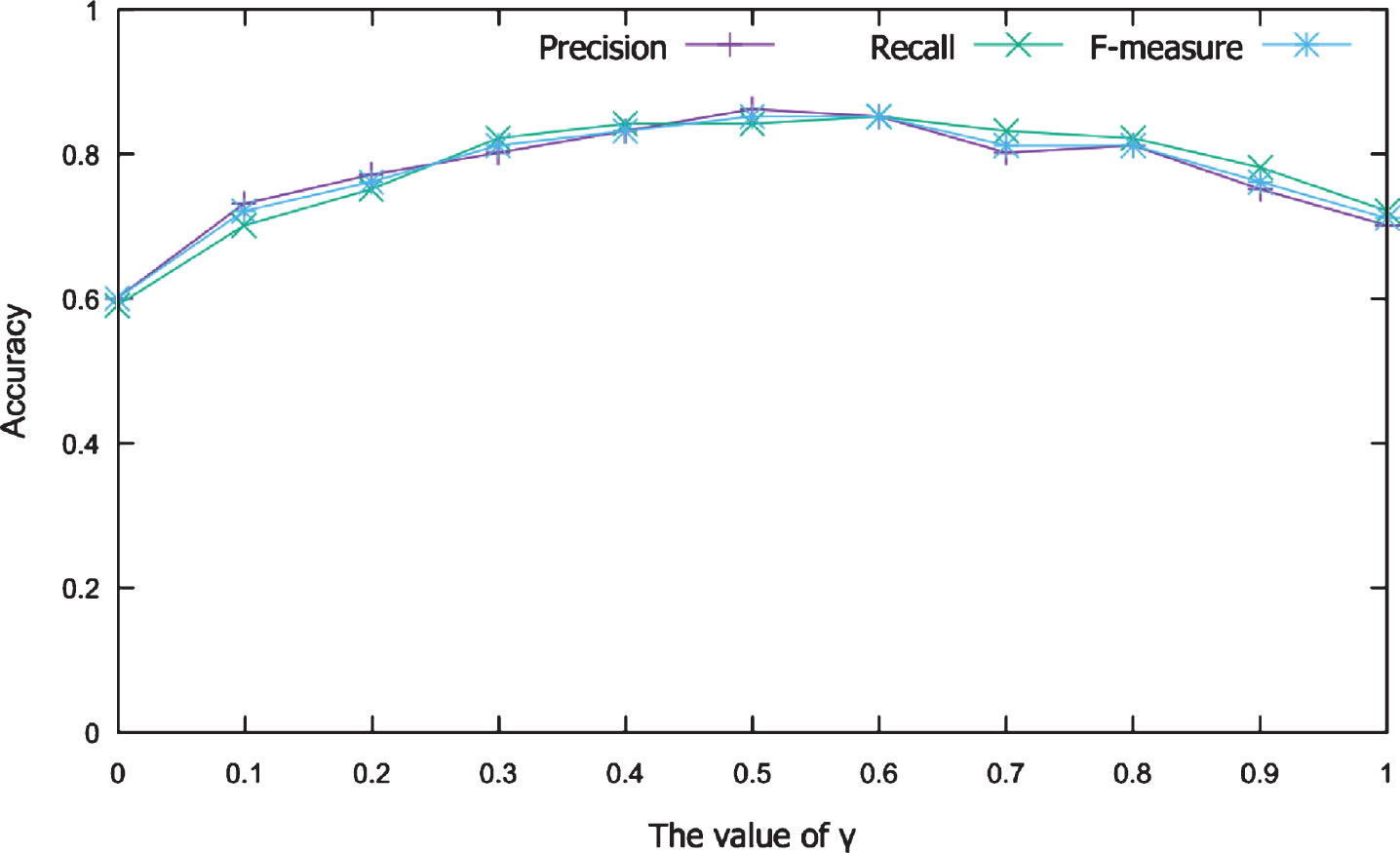
Influence of parameter γ on system.
Finally, we evaluate the influence of parameter N, which is the number of users who are chosen to compute the accuracy of the system. The value of N is set at 5, 10, 15, 20, 25, 30, 35, 40, 45, and 50. Parameters α,β, and γ are set at 0.2, 0.3, and 0.5, respectively.
As shown in Figure 6, the accuracy of the system reaches 100% for the top 10 users and 90% for the top 20 users. The accuracy of the recommendation system decreases when N becomes large. Intuitively, the highest number of experts is selected at first, and when the value of N increases, there are fewer and fewer experts to be found.
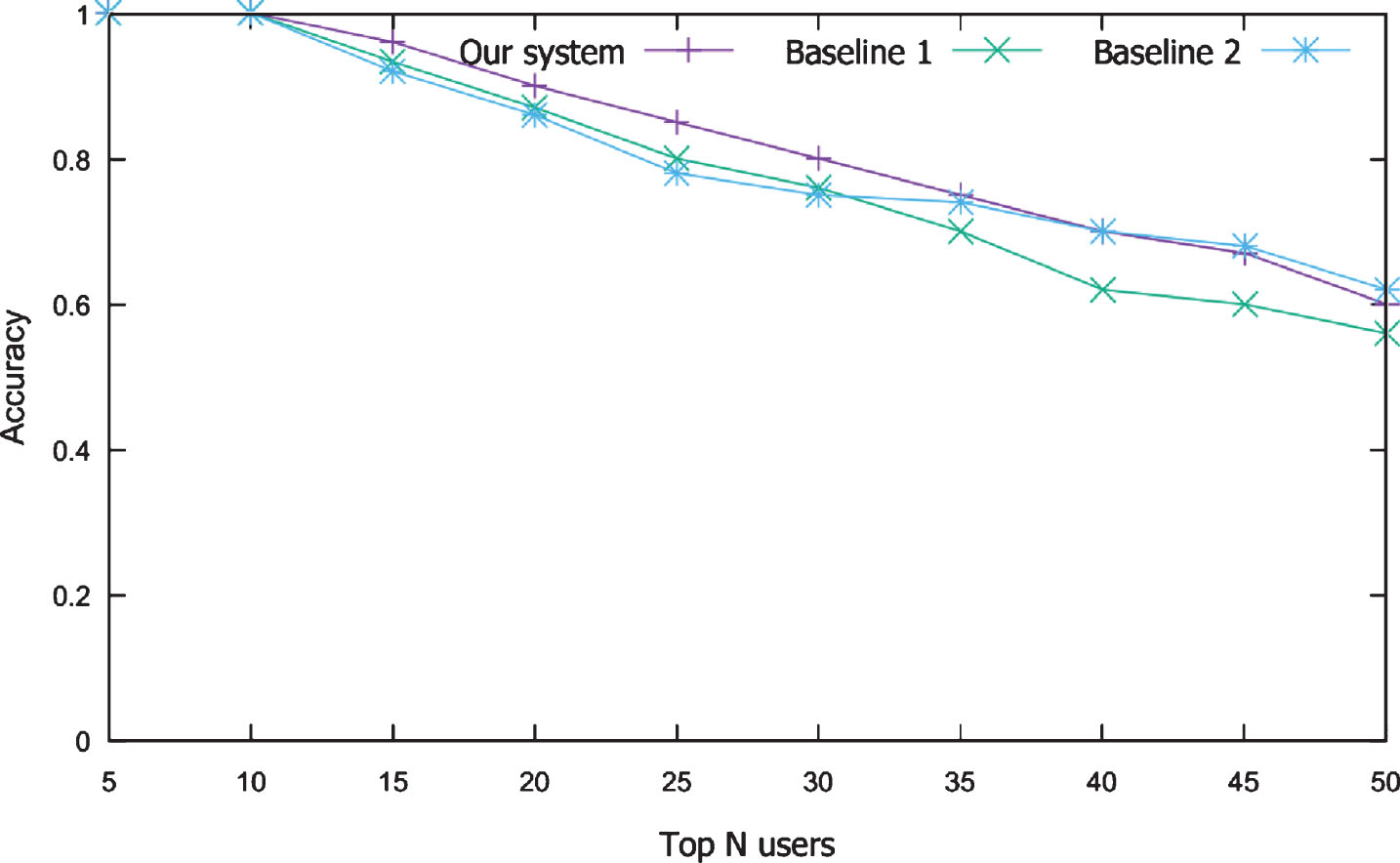
Accuracy of expert detection for top N users compared with two baselines.
We apply Normalized Discounted Cumulative Gain (nDCG) [26], which is applied to evaluate the ranked relevance of the recommended items. The formulation of nDCG and the Discounted Cumulative Gain (DCG) [4] are computed as follows:
In order to compute the nDCG value of a given group, we compute the nDCG value of each group’s member and obtain the average nDCG values of all group members. The greater is the value of nDCG, the more relevant the group recommendation list.
There are many experts will meet the requirement to be recommended to answer new questions. However, most experts are not willing to answer questions. Therefore, in the offline scenario, we evaluate and measure only the questions that the expert answered.
Figures 7 and 8 show the results of the proposed method. The accuracy of the results is quite good at a group size of K or 2K and decreases as the size of the group increases. This is understandable because generally, a question contains only a few topics. If an expert has written a right answer, then the other experts do not rewrite anymore and give upvote. In addition, there are many questions created by the users. However, the expert answered only a few questions among them. Thus, the accuracy of small group size is higher than big group size. The accuracy of the system is not high. However, our main goal is to generate new knowledge. We do not focus on distributing existing knowledge. Hence, diversity is necessary. It is an important factor in promoting the development of Q&A sites.
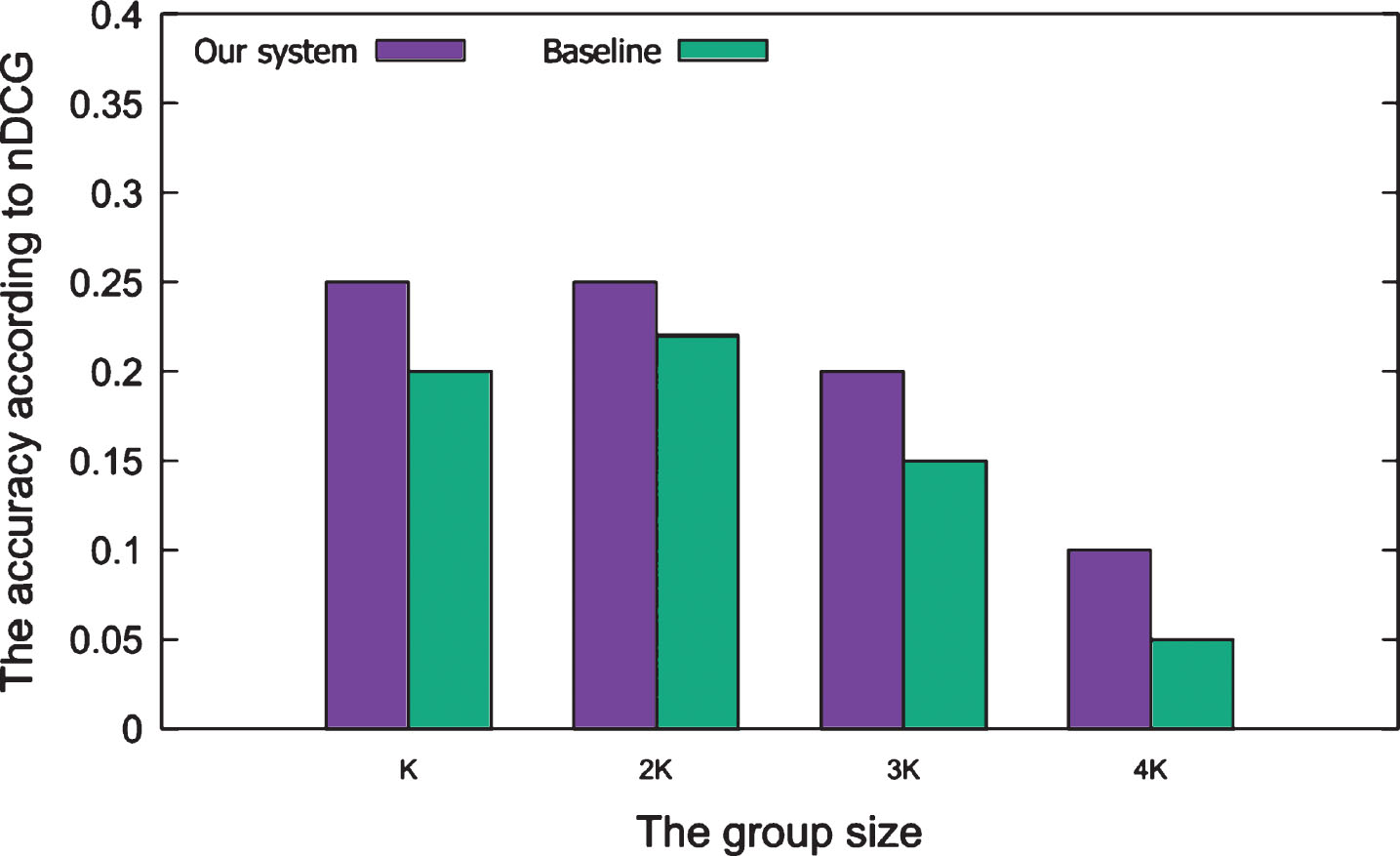
The accuracy according to nDCG of our system compares with baseline.
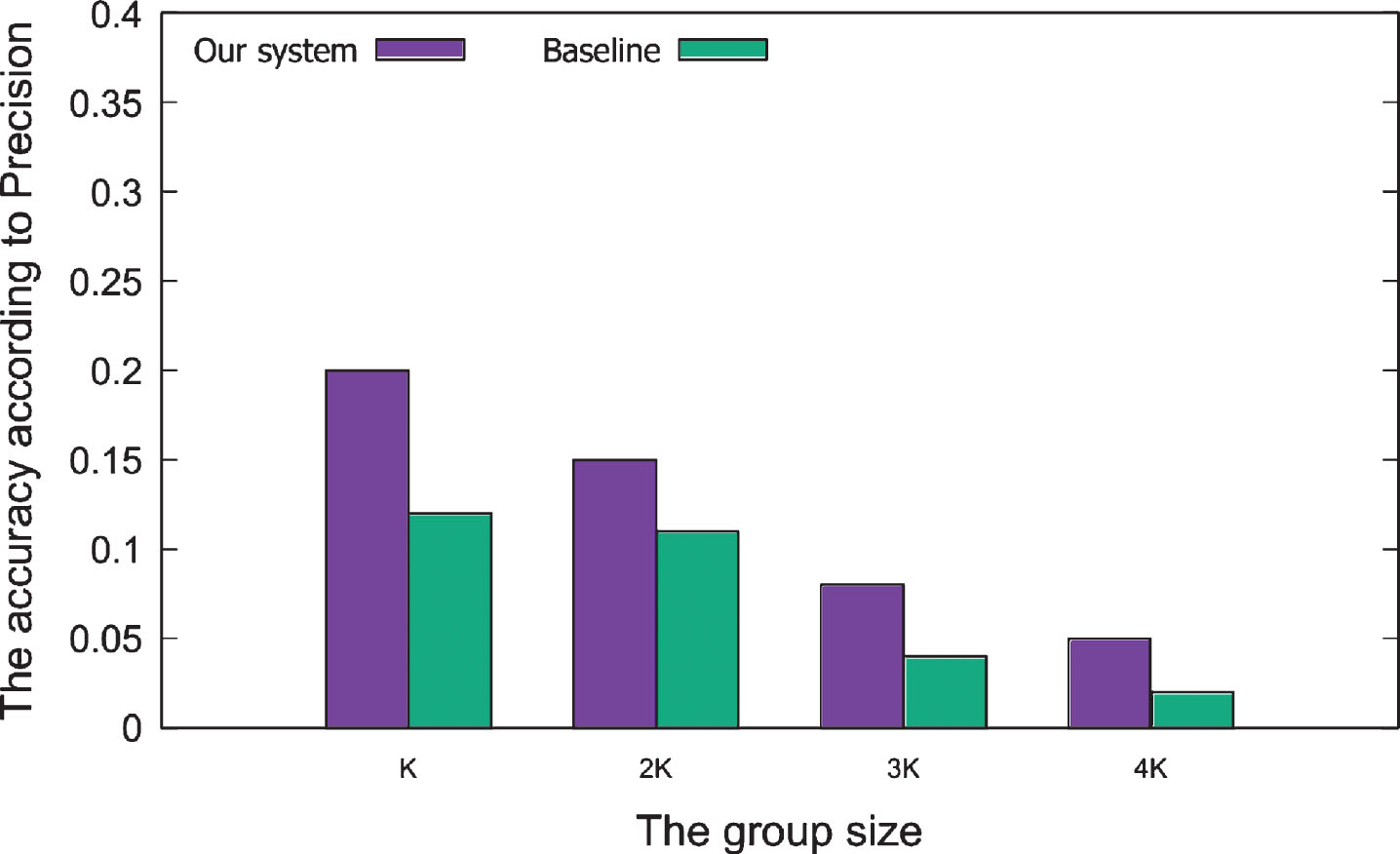
The accuracy according to Precision of our system compares with baseline.
With regard to expert detection evaluation, the proposed method was compared with two baseline methods. The first baseline (Baseline 1) was proposed by Song et al. [22], and the second baseline (Baseline 2) was introduced by Hoang et al. [9]. To ensure that the comparison was fair, we conducted experiments using the same dataset and domain. The leave-one-out procedure used in the previous experiment was again employed. The length of the recommendation list was also identical. Correctly, Song et al. considered three features such as authority, activity, and influence for determining an expert or a non-expert. The values of these features were computed as follows:
In Baseline 2, the authors used machine learning to determine an expert or a non-expert. Several features were extracted such as the number of followers, followings, questions, and answers. As shown in Table 3, our system achieves better results in terms of accuracy than other methods for the following reasons: according to our experimental results, the quality of the answers determines whether a user is an expert or a non-expert. However, in Baseline 1, the authors did not consider the average number of votes for each answer or the number of edits, topics, etc. Moreover, we consider the top N users (N ≤ 50). It is quite detrimental to machine learning algorithms, where data need to be large enough for good accuracy. Thus, the Baseline 2 method has a lower accuracy than the proposed method. This result demonstrated the Hypothesis 1.
Accuracy of expert detection compared with baselines
In the expert group recommendation method, to the best of our knowledge, we are the first to study diversity in Q&A systems and use it in the expert group recommendation for a new question. We use a previous version [9] as a baseline to evaluate our method. We set the number of experts for each topic to 10 because the expert detection achieved 100% accuracy. If groups are created that do not meet the criteria, we increase the number of experts in each topic. As shown in Table 4, our system achieves better results than the baseline method. This result has proven for Hypothesis 2. The main reason is that in the baseline, the diversity is considered based on the mutual follow without calculating the social impact of the experts. The diversity plays an essential role in a group that has also proved by other works [15, 23].
Accuracy of our system compared with baseline
This work presented an approach for recommending a group of experts to answer a new question. First, the user’s profile and behaviors are extracted to categorize an expert or a non-expert. Second, a topic-labeling method is conducted to identify the topic of a given question and match it to experts. Third, a suitable group for a given question is created by taking into account the social impact among experts. In addition to growing knowledge and avoid following the crowd, we require that the members of expert groups not only match the skill requirements to answer the question but also be diverse. Diversity plays a significant role in the process of decision-making in an expert group. The experimental results show that the proposed method provides higher accuracy in comparison to other methods.
In future work, we will develop a real-time system, because knowledge changes over time. A correct answer in the past may not be accurate in the present. Therefore, considering the time of posting can improve the accuracy of our system. Moreover, the number of questions, answers, and experts in other topics is an imbalance. Hot topics can be larger than other topics; thus, solving the imbalance data can achieve better results.